
1. reasoning trace를 ‘읽는다’는 말은 하나가 아닙니다
최근 reasoning model에서는 긴 reasoning trace가 예전보다 자주 노출됩니다. DeepSeek-R1이 <think> 블록 안에 사고 과정처럼 보이는 중간 추론을 드러낸 이후, 수천 토큰짜리 추론을 사용자에게 보여주는 구성이 흔해졌습니다. 그러면서 “trace를 읽고 해석한다"는 말이 자연스럽게 따라붙었습니다.
그런데 이 말은 생각보다 여러 뜻을 담고 있습니다. 사람이 trace를 읽고 이해할 수 있다는 뜻인지(가독성), trace를 어떤 인지적 단위로 쪼개고 분류할 수 있다는 뜻인지(구조화), 아니면 trace라는 산출물 밖에서 모델 내부 신호를 읽어낸다는 뜻인지(내부 진단)에 따라 이야기가 달라집니다. 같은 “해석가능성"이라는 단어가 문맥마다 다른 것을 가리킵니다.
한 연구는 이 지점에서 불편한 사실을 하나 보고했습니다. 여러 모델에서 성능을 가장 크게 끌어올린 trace가, 정작 사람에게는 가장 안 읽히는 trace였다는 관찰입니다. 잘 읽히는 trace가 곧 좋은 trace라는 직관이 항상 성립하지는 않는다는 이야기입니다.
이 글은 reasoning trace 해석가능성을 다룬 논문 네 편을 하나의 답으로 묶기보다, “trace를 읽는다"는 말을 세 갈래로 나눠 보게 만드는 재료로 읽습니다. 먼저 인지적 구조화의 어휘를 정리한 뒤(2절), 그 어휘로 trace를 난이도 예측에 쓴 사례(3절)와 가독성과 성능이 어긋난 반례(4절), 그리고 trace 밖 내부 표현을 본 연구(5절)를 차례로 짚습니다. 한 가지 선은 미리 그어둡니다. 이 글은 trace가 모델의 실제 사고를 충실히 반영하는가(faithfulness) 자체를 판정하지 않습니다. 그 논쟁은 별개의 큰 주제이므로, 여기서는 “trace를 어떻게 읽을 수 있는가"에 집중합니다.
다루는 논문은 다음과 같습니다.
- Cognitive Foundations for Reasoning (arxiv 2511.16660): 인지 요소 taxonomy와 대규모 trace 분석
- Epi2Diff (arxiv 2606.28186): trace를 인지 에피소드로 구조화해 인간 문항 난이도 예측
- Do Cognitively Interpretable Reasoning Traces Improve LLM Performance? (arxiv 2508.16695): 가독성과 성능의 불일치
- Probing the Difficulty Perception Mechanism (arxiv 2510.05969): 난이도 신호의 내부 표현 probing
2. 좌표계: 인지 요소로 reasoning을 분류하기
논문들을 하나씩 보기 전에, 공통으로 쓸 어휘부터 정리하는 편이 낫습니다. Kargupta 등이 발표한 Cognitive Foundations for Reasoning은 그 어휘를 가장 넓은 스케일로 정리한 연구입니다. 이 논문은 인지과학에서 말하는 reasoning을 네 개의 카테고리와 28개 인지 요소(cognitive elements)로 체계화합니다. 네 카테고리는 Reasoning Invariants(추론의 불변 요소), Meta-Cognitive Controls(메타인지 제어), Reasoning Representations(추론 표현), Reasoning Operations(추론 연산)입니다.
규모가 이 논문의 강점입니다. 텍스트·비전·오디오를 아우르는 18개 모델에서 수십만 건 규모의 reasoning trace를 분석했고, 사람이 소리 내어 생각하며 문제를 푸는 think-aloud trace 54건을 함께 공개했습니다. 여기에 arXiv에 올라온 LLM reasoning 논문 약 1,600편을 메타분석해, 연구 커뮤니티가 어떤 인지 요소에 관심을 쏟는지도 정량화했습니다.
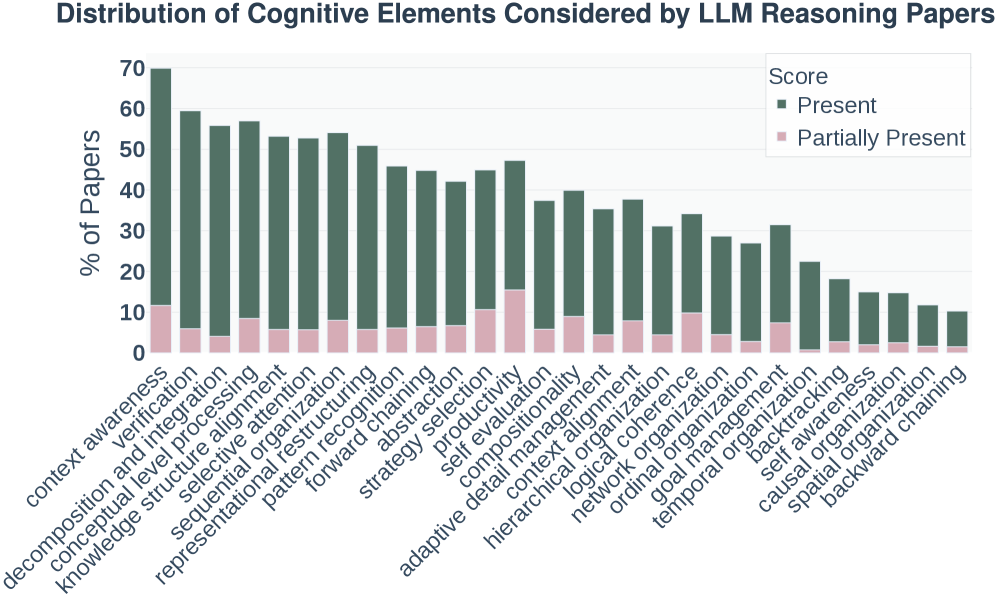
약 1,598편의 arXiv LLM reasoning 논문에서 각 인지 요소가 다뤄진 비율. 정량화하기 쉬운 요소에 관심이 몰리고, 그렇지 않은 요소는 상대적으로 방치됩니다. 출처: Cognitive Foundations for Reasoning (arXiv:2511.16660), Fig 2.
분석 결과는 두 갈래로 읽힙니다. 하나는 연구 커뮤니티의 편중입니다. 순차적 구성(sequential organization)이나 분해(decomposition)처럼 정량화하기 쉬운 요소에는 각각 절반 이상의 논문이 몰리는 반면, 성공과 상관되는 것으로 보고된 메타인지 제어, 예컨대 self-awareness는 16% 수준으로 덜 다뤄집니다. 다른 하나는 인간과 모델의 차이입니다. 사람의 trace는 더 추상적이고 개념적인 처리를 보이는 반면, 모델은 표면적인 나열로 기울고, 잘 구조화되지 않은 문제에서는 경직된 순차 처리로 좁혀지는 경향을 보였습니다. 논문은 test-time에 인지적 가이드를 주면 복잡하거나 잘 구조화되지 않은 문제에서 성능이 최대 66.7%까지 올랐다고 보고합니다. 다만 이 수치는 특정 조건에서의 최대치이므로, 일반적인 성능 향상 폭으로 확대해 읽지 않는 편이 안전합니다.
이 taxonomy가 이 글에서 하는 역할은 하나입니다. 뒤에 나올 논문들이 trace의 어느 부분을 읽는지 가리킬 때 쓸 좌표계입니다. 난이도를 다루는 논문은 아니지만, “trace를 인지 단위로 본다"는 것이 무슨 뜻인지에 대한 공통 언어를 제공합니다.
3. trace를 인지 에피소드로 구조화해 문항 난이도를 예측하다
Wang 등의 Epi2Diff는 그 “인지 단위로 본다"를 구체적인 예측 문제에 적용한 사례입니다. 다만 목적을 분명히 해둘 필요가 있습니다. 이 논문은 LLM trace를 더 잘 이해하기 위한 일반 방법론이 아니라, 인간 응시자에게 문항이 얼마나 어려운지(human item difficulty)를 예측하는 교육 측정 연구입니다. trace는 그 예측을 위한 특징 추출의 재료로 쓰입니다.
핵심 아이디어는 문항 난이도를 문항 텍스트만의 속성으로 보지 않고, 그 문항이 유발하는 문제풀이 부담의 관찰 가능한 결과로 본다는 것입니다. Large Reasoning Model이 남기는 reasoning trace가 그 부담의 흔적을 담고 있다고 가정하고, trace를 인지적으로 근거 있는 에피소드 시퀀스로 변환합니다. 여기서 쓰는 에피소드 체계가 Schoenfeld의 문제풀이 프레임워크입니다. Read, Analyze, Plan, Implement, Explore, Verify 여섯 개에 나중에 추가된 Monitor를 더한 일곱 개의 기능적 에피소드로, trace의 각 문장 구간을 라벨링합니다.
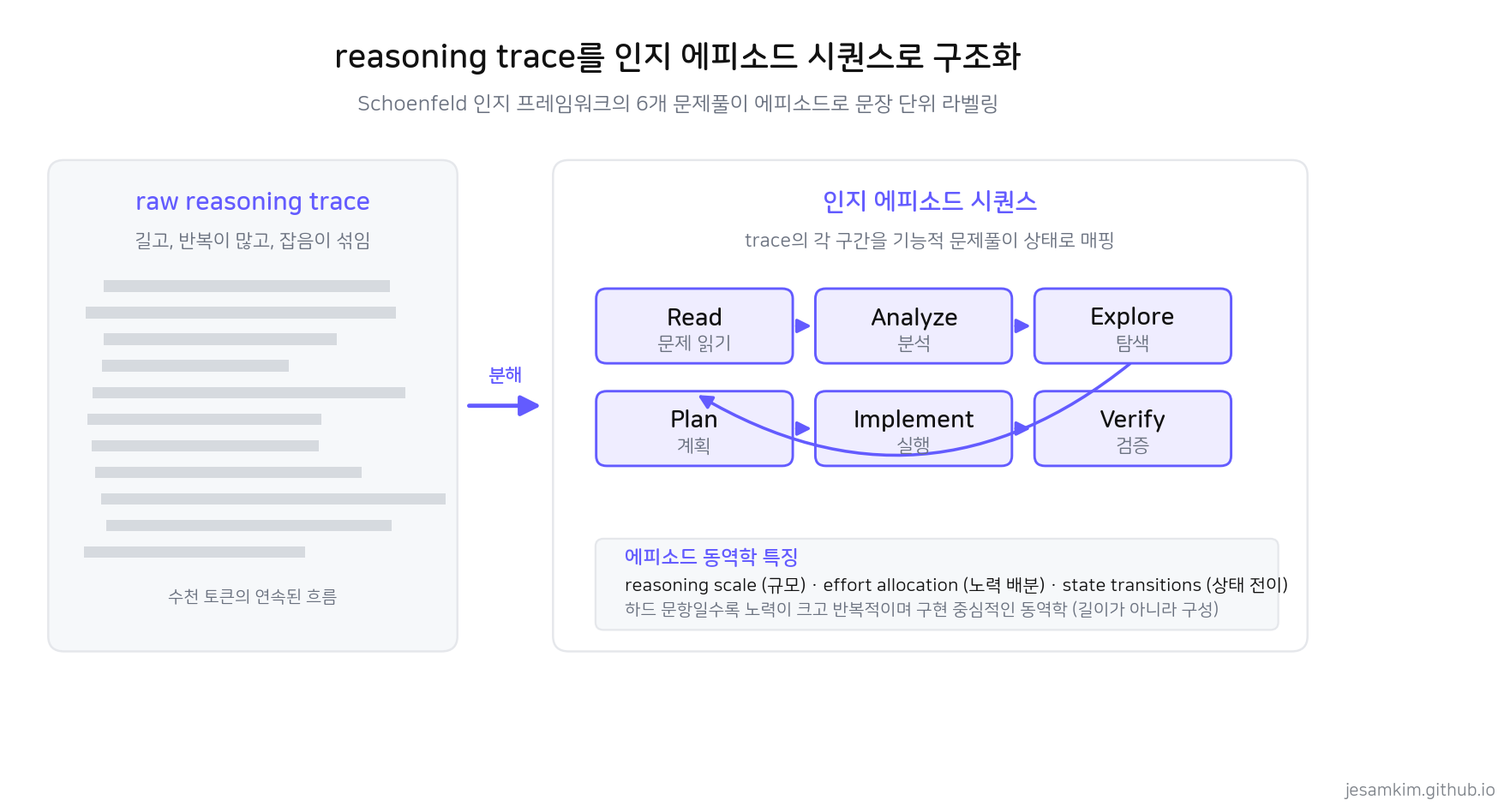
길고 반복적인 raw trace를 Schoenfeld의 7개 문제풀이 에피소드로 문장 단위 라벨링한 뒤, 규모·노력 배분·상태 전이 같은 압축 특징을 뽑아냅니다.
이렇게 라벨링한 시퀀스에서 reasoning의 규모(scale), 노력의 배분(effort allocation), 상태 사이의 전이(transitions)를 요약한 압축 특징을 뽑고, 문항 내용의 의미 임베딩과 결합해 최종 난이도 예측에 씁니다. 흥미로운 관찰은 난이도가 높은 문항일수록 응답 길이가 아니라 에피소드의 성격이 달라진다는 점입니다. 노력 투입이 크고, 반복적이며, 구현 중심적인 동역학이 나타납니다. 길이가 아니라 에피소드의 구성과 전이 패턴이 난이도를 가릅니다.
성능은 네 개의 실제 human difficulty 데이터셋(USMLE, Cambridge, SAT Reading & Writing, SAT Math)에서 측정됩니다. 이 중 SAT 계열은 Easy/Medium/Hard 같은 순서형 분류로, USMLE와 Cambridge는 연속값 회귀로 난이도를 예측합니다. 눈에 보이는 비교 대상은 BERT나 RoBERTa 같은 소형 언어모델 fine-tuning, LLM in-context learning, supervised LLM 적응 등 강한 baseline들입니다. Epi2Diff는 이들을 일관되게 앞섰다고 보고되며, 구체적인 수치로는 SAT 파생 분류 벤치마크에서 supervised LLM fine-tuning 대비 평균 8.1%의 상대 향상을 보고합니다. 이 8.1%는 네 개 데이터셋 전체 평균이 아니라 SAT 파생 분류 과제에 한정된 값이라는 점을 짚어둡니다. 나머지 데이터셋에 대해서는 구체 수치 없이 “강한 baseline을 일관되게 앞선다"고 표현합니다.
2절의 taxonomy 관점에서 보면, Epi2Diff는 trace를 인지 단위로 구조화한 뒤 그 구조를 예측 신호로 바꾼 응용입니다. 여기서 다루는 난이도가 어디까지나 인간 응시자 기준의 문항 난이도라는 점은 뒤에서 다시 필요합니다.
4. 잘 읽히는 trace가 꼭 성능에 유리한 것은 아닙니다
3절까지가 trace를 인지적으로 구조화하고 유용하게 쓰는 방향이었다면, Bhambri, Biswas, Kambhampati(애리조나 주립대)의 연구는 방향을 한 번 꺾습니다. 도입에서 던진 teaser의 정체가 이 논문입니다. 질문은 단순합니다. 사람이 보기에 해석가능한 trace가, 모델을 학습시킬 때도 더 좋은 trace인가?
실험 설계는 네 종류의 trace를 비교하는 방식입니다. DeepSeek-R1이 생성한 원본 trace, 그 R1 trace를 LLM으로 요약한 것, R1 trace에 대한 사후 설명(post-hoc explanation), 그리고 알고리즘으로 생성한 검증 가능한 정답 trace입니다. 이 네 종류로 각각 네 개의 모델(Llama-3.2-1B-Instruct, Llama-3.1-8B, Qwen3-1.7B, Qwen3-8B)을 supervised fine-tuning한 뒤 CoTemp QA(시간 관계 추론 벤치마크)에서 성능을 재고, 동시에 100명의 참가자에게 각 trace의 해석가능성을 평가받았습니다.
결과가 “striking mismatch"입니다. 네 개 모델 중 세 개에서 R1 원본 trace로 학습한 모델이 가장 높은 최종 정확도를 냈습니다. 향상 폭이 가장 컸던 것은 Llama-3.2-1B-Instruct였습니다. 그런데 사람에게는 바로 그 R1 원본 trace가 가장 안 읽혔습니다. 100명이 매긴 해석가능성 median 점수에서 R1 원본은 3.31로 최하위였고, 요약본(4.53), 사후 설명(4.29), 알고리즘 정답 trace(4.86)가 모두 더 높았습니다.
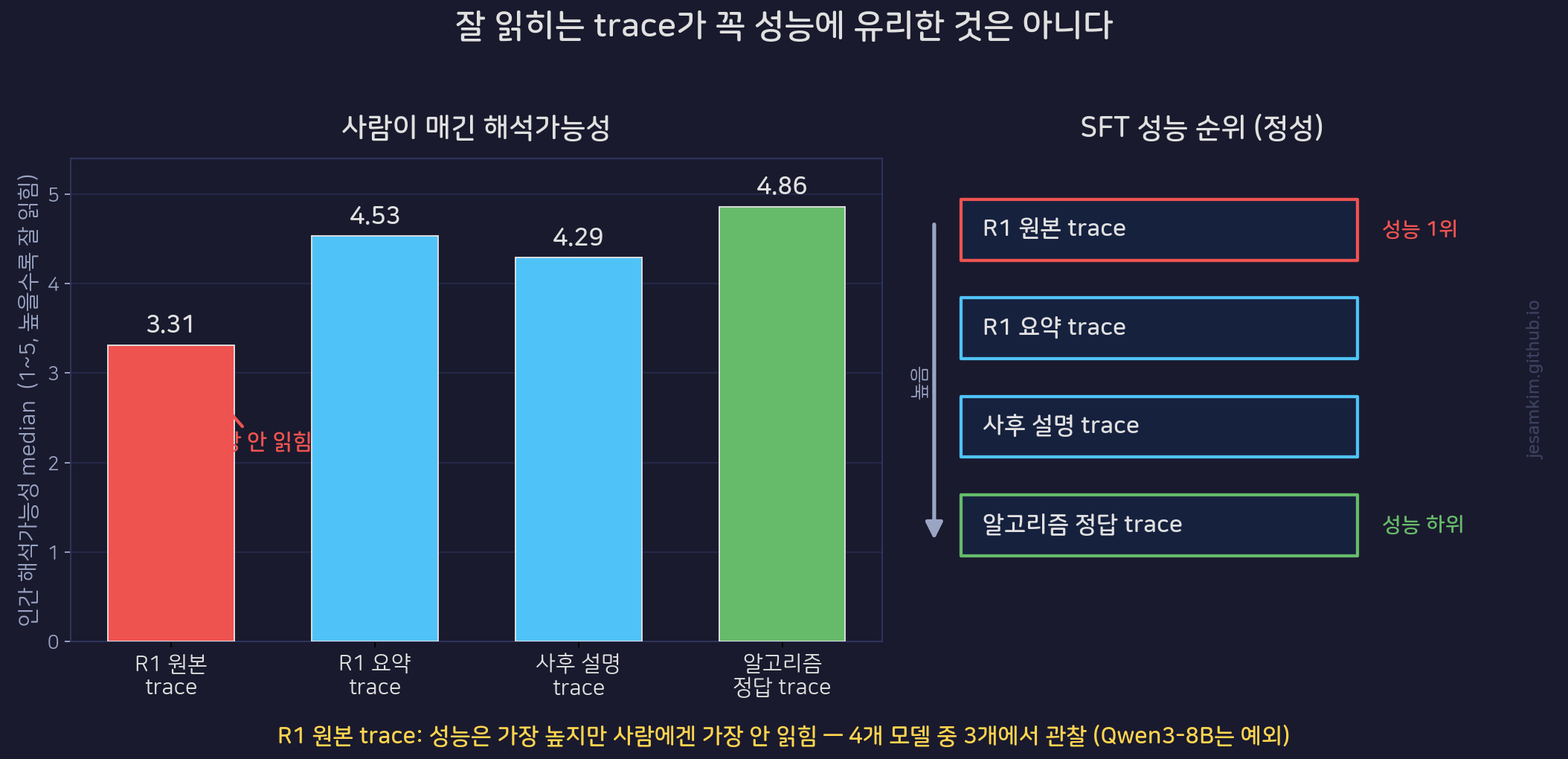
왼쪽은 4종 trace의 인간 해석가능성 median(Table 1, 높을수록 잘 읽힘), 오른쪽은 SFT 성능 순위입니다. 성능 1위인 R1 원본 trace가 가독성에서는 최하위입니다. 다만 이 경향은 4개 모델 중 3개에서 관찰되며, Qwen3-8B는 예외입니다.
정직하게 덧붙이면, 이 mismatch가 모든 경우에 성립하는 것은 아닙니다. Qwen3-8B에서는 R1 원본 trace가 성능 1위가 아니었습니다. 그래서 “R1 trace가 항상 최고 성능"이라고 단정하기보다 “대부분의 모델에서 그런 경향이 관찰된다"고 읽는 편이 맞습니다. 그럼에도 방향성은 분명합니다. 학습에 유리한 중간 토큰과 사람이 읽기 좋은 설명은 서로 다른 목적 함수일 수 있다는 것입니다.
논문의 결론도 해석가능성 무용론이 아닙니다. 오히려 중간 토큰(intermediate tokens)의 효용과 최종 사용자 해석가능성을 분리(decouple)해서 다뤄야 한다는 제안입니다. 2절과 3절이 “trace를 인지적으로 잘 읽자"는 방향이었다면, 이 연구는 “잘 읽히게 만드는 것과 성능에 유리하게 만드는 것이 같은 목표가 아닐 수 있다"는 반례를 제공합니다.
5. 난이도 신호는 trace 밖, 모델 내부에도 남는가
지금까지의 세 연구는 모두 trace라는 외부 산출물을 읽었습니다. Lee 등의 Difficulty Probing은 관측 지점을 옮깁니다. trace가 아니라 모델의 내부 표현을 직접 들여다보는 mechanistic probing 연구입니다. 다만 범위를 분명히 해둘 필요가 있습니다. 이 논문은 trace 해석의 한계를 해결하는 대체재를 제안하는 것이 아니라, 난이도 신호가 trace 밖 내부 표현에도 존재한다는 것을 보여주는 연구입니다.
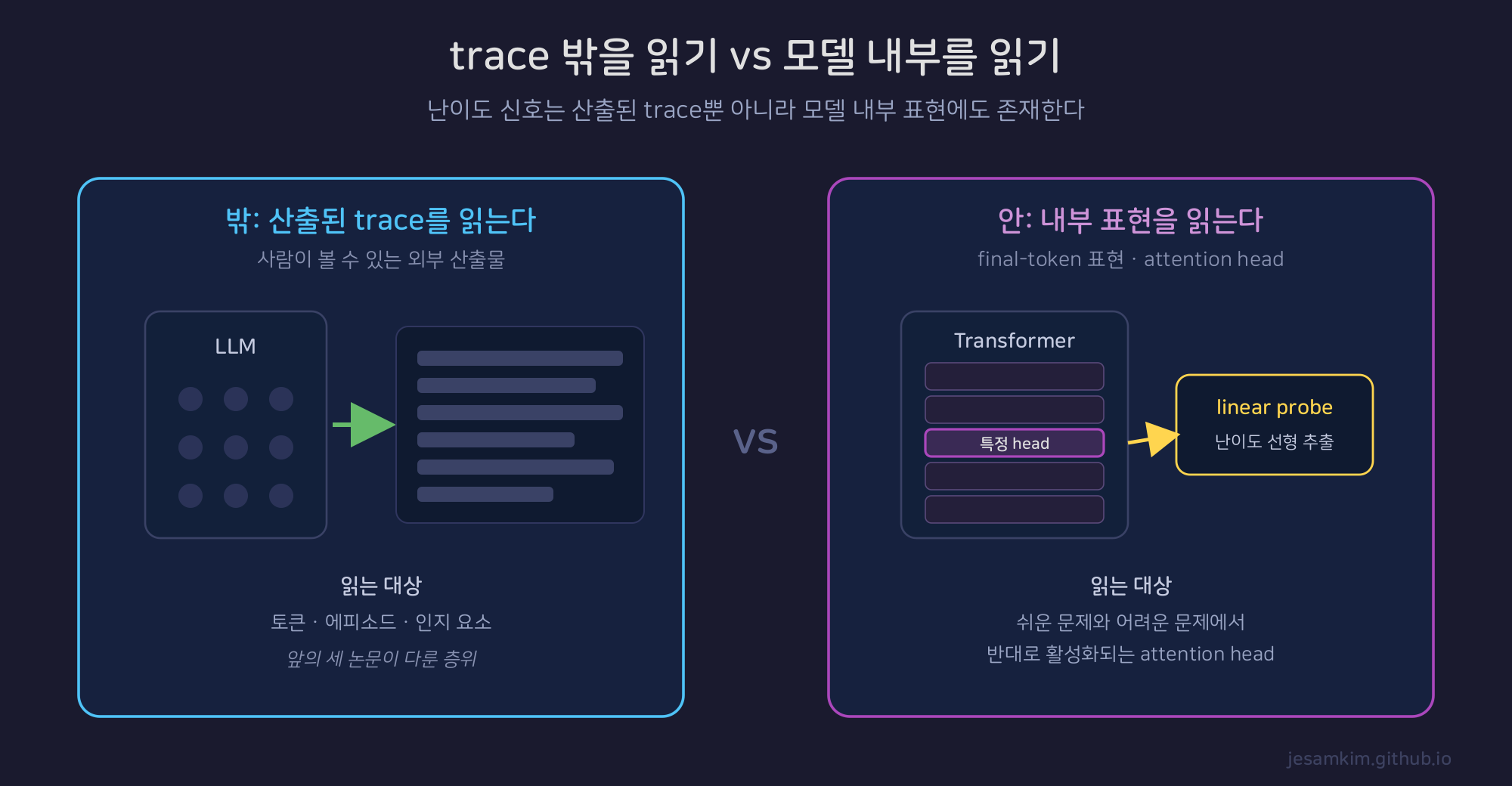
앞의 세 연구가 산출된 trace(토큰·에피소드·인지 요소)를 읽었다면, Difficulty Probing은 final-token 표현과 attention head 같은 모델 내부 신호를 읽습니다.
핵심 결과는 세 가지입니다. 첫째, 수학 문제의 난이도가 모델의 final-token 표현에 선형적으로 인코딩되어 있어, linear probe로 추출할 수 있습니다. 여기서 난이도는 수학 문제에 한정된 개념이라는 점이 중요합니다. 둘째, 마지막 Transformer layer의 특정 attention head가 쉬운 문제와 어려운 문제에 대해 반대되는 활성 패턴을 보였습니다. 셋째, 이 head들의 위치를 ablation으로 검증했습니다. 논문은 이를 근거로 LLM을 자동 난이도 주석기(automatic difficulty annotator)로 쓸 여지를 제시합니다.
probe로 읽어낸 난이도 지각은 추론이 진행되는 동안 토큰 단위로도 변합니다. 논문은 응답을 여러 지점에서 잘라(truncation) probe를 적용하거나, 토큰 수준 entropy와 나란히 놓고 비교하는 분석도 함께 제시합니다. 난이도 신호가 하나의 정적인 스칼라가 아니라 추론 과정에서 움직이는 값으로 관측된다는 뜻입니다. 다만 이런 내부 관측은 모델 가중치와 활성값에 접근할 수 있을 때 성립하므로, 가중치가 열려 있지 않은 API 기반 모델에는 그대로 적용하기 어렵습니다.
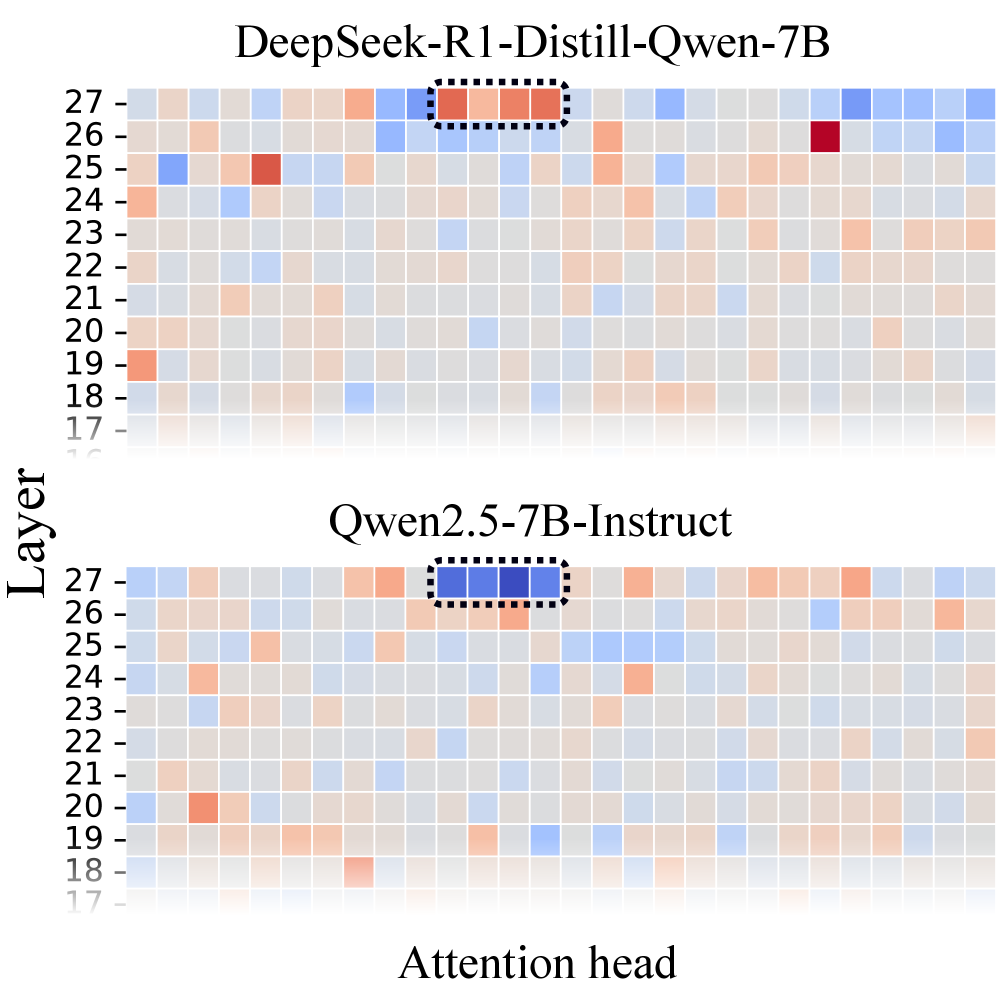
Qwen2.5-7B-Instruct와 DeepSeek-R1-Distill-Qwen-7B의 attention head 패턴 비교. 점선 박스로 표시된 일부 head에서 쉬운 문제와 어려운 문제에 대한 활성 방향이 반전됩니다. 출처: Probing the Difficulty Perception Mechanism (arXiv:2510.05969), Fig 8.
여기서 한 가지 구분이 필요합니다. 이 논문이 말하는 난이도는 3절 Epi2Diff의 난이도와 다른 개념입니다. Epi2Diff의 난이도는 인간 응시자 기준의 문항 난이도(human item difficulty)이고, 여기서의 난이도는 모델 내부 표현에 나타나는 수학 문제 난이도입니다. 둘 다 “difficulty"라는 단어를 쓰지만 측정 대상과 관측 지점이 다릅니다. 둘 사이의 대응은 검증된 등가가 아니라 비교 관점일 뿐입니다. 그리고 “난이도가 선형으로 표현된다"는 것은 probe의 성능이 시사하는 것이지, 모델이 난이도를 의식한다는 의인화로 읽을 근거는 아닙니다.
6. ’trace를 읽는다’는 세 가지 뜻
네 편을 하나의 프레임으로 정리하면, reasoning trace 해석가능성은 단일 개념이 아니라 서로 다른 세 가지 뜻으로 갈라집니다. 사람이 읽고 이해하는가라는 인간 가독성(4절의 human study), trace를 인지 단위로 쪼갤 수 있는가라는 인지적 구조화(2절 taxonomy, 3절 에피소드), 그리고 trace 밖 모델 내부에서 신호를 읽는가라는 내부 진단(5절 probing)입니다. 3절 Epi2Diff의 난이도 예측은 이 중 두 번째 갈래, 즉 구조화한 trace를 예측 신호로 바꾼 응용에 해당합니다.
하나의 해석가능성이 아니라, 서로 정렬되지 않을 수 있는 세 갈래로 4편을 배치한 정리도입니다.
4절의 mismatch가 보여준 것이 이 지점입니다. 세 갈래는 서로 정렬되지 않을 수 있습니다. 사람에게 잘 읽히는 trace가 학습 성능에 유리한 trace와 다를 수 있고, 모델 내부 표현이 담은 신호는 산출된 trace와는 다른 관측 지점에서 포착됩니다. 그래서 네 편은 “trace를 이렇게 읽으면 된다"는 하나의 답을 주기보다, 세 개의 질문이 교차하는 지점을 비춥니다. trace는 어떤 단위로 읽을 수 있는가, 그 단위는 사람에게 유용한가, 난이도 같은 신호는 trace 밖에도 있는가.
7. 엔지니어 관점에서 가져갈 세 가지
논문 리뷰를 실무 언어로 옮기면 세 가지 정도가 남습니다.
첫째, trace는 평가 신호로 쓸 수 있습니다. Epi2Diff가 보여주듯, trace의 에피소드 구조와 전이 패턴은 인간 문항 난이도를 가늠하는 신호가 됩니다. 응답 길이 같은 단순 지표보다 구조화된 특징이 더 많은 것을 말해줍니다. 다만 인간 기준 난이도와 모델 내부 난이도는 다른 개념이므로, 무엇을 측정하는지 먼저 정해야 합니다.
둘째, 보여줄 trace와 성능용 trace는 분리하는 편이 낫습니다. 4절의 decouple 결론이 실무에 곧바로 닿는 지점입니다. 그 실험 조건에서는 원본 R1 trace가 다수 모델에서 학습에 유리했고, 요약본이 사람에게 더 잘 읽혔습니다. 이 결과를 그대로 일반화할 수는 없지만, 사용자에게 노출하는 trace는 요약하거나 가독성을 높이고 모델 학습이 목적인 trace는 원본 형태를 유지하는 식으로 목적에 따라 갈라두는 접근을 검토해 볼 수 있습니다. 잘 읽히게 다듬는 일과 성능을 높이는 일이 자동으로 같이 가지 않기 때문입니다.
셋째, 신호를 찾을 때 관측 지점을 하나로 고정하지 않는 편이 좋습니다. Difficulty Probing은 trace 밖 내부 표현에도 신호가 남는다는 것을 보여줍니다. 산출된 trace만 관측 대상으로 삼으면 놓치는 신호가 있을 수 있습니다.
프로덕션에서 reasoning 시스템을 운영하는 관점을 한 가지만 덧붙이면, 긴 trace는 그 자체로 토큰 비용이자 지연 요인입니다. trace를 인지 단위로 구조화하는 작업은 해석가능성만이 아니라 관측가능성(observability)의 문제이기도 합니다. 어떤 에피소드에서 반복이 늘어나는지, 어느 구간에서 노력이 몰리는지를 읽을 수 있으면, 비용과 품질을 함께 관리할 실마리가 생깁니다. 네 편이 공통으로 남기는 메시지는, trace를 읽는다는 것이 하나의 작업이 아니라 목적에 따라 관측 지점과 방법을 골라야 하는 문제라는 점입니다.
References
- Kargupta, P., Li, S. S., Wang, H., Lee, J., Chen, S., Ahia, O., Light, D., Griffiths, T. L., Kleiman-Weiner, M., Han, J., Celikyilmaz, A., Tsvetkov, Y. “Cognitive Foundations for Reasoning and Their Manifestation in LLMs.” arXiv:2511.16660, 2025-11-20 (v2: 2025-11-24). arxiv
- Wang, C., Li, M., Zeng, X., Li, Z., Jiao, H., Zhou, T., Zhou, D. “Cognitive Episodes in LLM Reasoning Traces Enable Interpretable Human Item Difficulty Prediction.” arXiv:2606.28186, 2026-06-26. arxiv
- Bhambri, S., Biswas, U., Kambhampati, S. “Do Cognitively Interpretable Reasoning Traces Improve LLM Performance?” arXiv:2508.16695, 2025-08-21. arxiv
- Lee, S., Yin, Q., Leong, C. T., Zhang, J., Gong, Y., Ni, S., Yang, M., Shen, X. “Probing the Difficulty Perception Mechanism of Large Language Models.” arXiv:2510.05969, 2025-10-07 (v2: 2025-10-12). arxiv
- DeepSeek-AI. “DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.” arXiv:2501.12948, 2025-01-22. arxiv