
스마트폰 키보드는 제가 다음에 칠 단어를 꽤 잘 맞힙니다. “오늘 점심"까지만 쳤는데 “뭐 먹지"를 추천해 주는 식이죠. 그런데 한 가지 의문이 듭니다. 제 입력 습관을 학습하려면 제가 친 모든 문장을 어딘가 서버로 보내야 할 텐데, 그렇다면 제 메시지가 통째로 회사 서버에 쌓이고 있는 걸까요?
다행히 그렇지 않습니다. 요즘은 데이터를 한곳에 모으지 않고도 모델을 똑똑하게 만드는 방법이 자리를 잡았습니다. 이 글에서는 그 방법인 연합학습(Federated Learning)이 어떻게 동작하는지, 그 과정에서 생기는 골치 아픈 문제들(데이터가 사람마다 편향되는 문제, 느린 기기 문제, 악의적인 참여자 문제, 프라이버시가 새는 문제)을 어떻게 푸는지 차근차근 살펴봅니다. 그리고 학습이 다 끝난 거대 모델을 실제 서비스로 내보낼 때 쓰는 분산 추론(Distributed Inference)까지 이어서 다룹니다.
기본적인 머신러닝 개념(모델, 학습, gradient 정도)만 알고 계시면 충분합니다. 분산 시스템을 전혀 몰라도 따라올 수 있도록 비유를 많이 쓰겠습니다.
A. 왜 “데이터를 안 모으고” 학습해야 할까
한 줄 직관
데이터는 점점 더 우리 손안의 기기 곳곳에 흩어져 있고, 그 데이터를 한곳에 모으는 일 자체가 점점 더 위험하고 비싸졌습니다.
비유
예전 방식은 이렇습니다. 전국의 병원이 환자 데이터를 한 중앙 서버에 모두 업로드하고, 거기서 좋은 진단 모델을 학습합니다. 마치 모든 학생의 일기장을 한 교실에 모아 놓고 한 명이 다 읽어보는 것과 같습니다. 모델은 잘 만들어지겠지만, 일기장 주인 입장에서는 끔찍한 일이죠.
연합학습은 발상을 뒤집습니다. 일기장은 각자 집에 두고, 대신 “내가 일기를 읽고 깨달은 요점"만 모읍니다. 원본은 절대 집 밖으로 나가지 않습니다.
조금 더 자세히
데이터를 한곳에 모으기 어려운 이유는 여러 가지입니다.
- 프라이버시: 병원 환자 기록, 개인 메시지, 금융 거래 내역은 법적으로도 윤리적으로도 함부로 옮길 수 없습니다.
- 데이터가 흩어져 있음: 수억 대의 스마트폰, 카메라, 웨어러블 기기가 각자 데이터를 만들어냅니다. 이걸 다 모으려면 통신 비용만 천문학적입니다.
- 기관 간 경쟁: 서로 다른 병원, 기업, 법무법인이 협력해서 더 좋은 모델을 만들고 싶어도, 원본 데이터를 경쟁사에 넘기고 싶어 하지는 않습니다.
이 모든 상황에서 “데이터는 그대로 두고 모델만 주고받자"는 연합학습이 해법이 됩니다.
가장 유명한 실제 사례가 구글의 Gboard 키보드입니다. 다음 단어 예측, 자동 교정, 스마트 작성 같은 기능이 연합학습으로 학습됩니다. 여러분의 폰은 여러분의 입력 습관으로 모델을 조금 개선하고, 그 개선분(원본 텍스트가 아니라 모델 변화량)만 서버로 보냅니다. 애플과 퀄컴도 비슷한 방향으로 연구를 이어가고 있습니다.
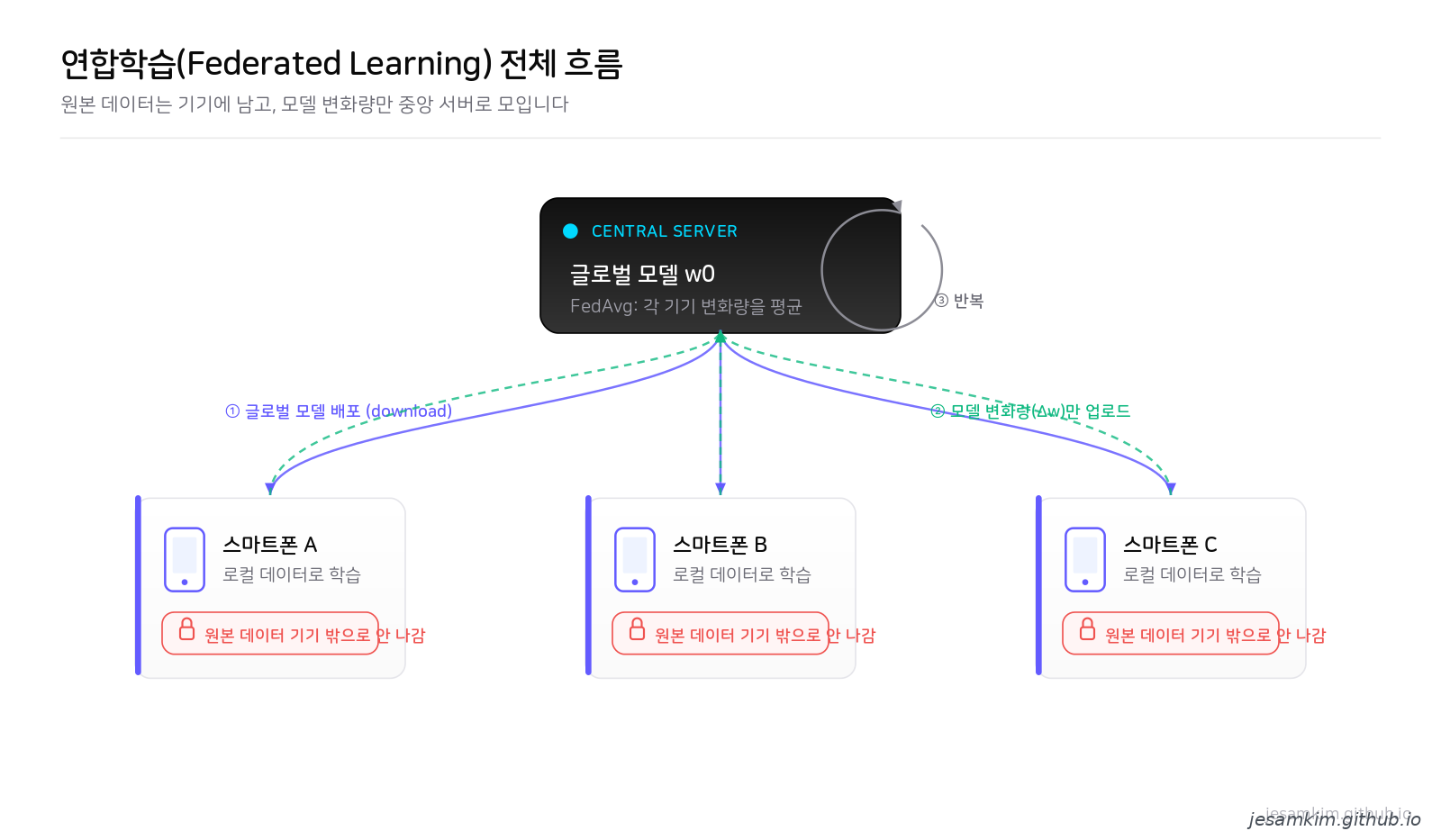 그림 1. 연합학습의 한 라운드. 글로벌 모델을 기기에 배포하고, 각 기기는 로컬 데이터로 학습한 변화량(Δw)만 올려보냅니다. 원본 데이터는 기기를 떠나지 않습니다.
그림 1. 연합학습의 한 라운드. 글로벌 모델을 기기에 배포하고, 각 기기는 로컬 데이터로 학습한 변화량(Δw)만 올려보냅니다. 원본 데이터는 기기를 떠나지 않습니다.
B. FedAvg: 연합학습은 실제로 어떻게 돌아가나
한 줄 직관
서버가 모델을 나눠주고, 각자 자기 데이터로 잠깐 공부한 다음, 공부한 결과(모델)를 모아 평균을 냅니다. 이걸 계속 반복합니다.
비유
스터디 그룹을 떠올려 보세요. 선생님(서버)이 같은 교과서(글로벌 모델)를 학생 다섯 명에게 나눠줍니다. 학생들은 각자 집에서 자기 문제집(로컬 데이터)으로 며칠 공부합니다. 그리고 다시 모여서 “각자 머릿속에 들어온 지식"을 평균 내어 하나의 공통 지식으로 합칩니다. 이 합쳐진 지식을 다시 나눠주고, 또 각자 공부하고, 또 합치고. 이걸 반복하면 다섯 명의 문제집을 한 명이 다 푼 것과 비슷한 실력에 도달합니다.
조금 더 자세히: FedAvg 4단계
이 알고리즘의 이름이 FedAvg(Federated Averaging)입니다. 2017년 구글이 제안했습니다. 동작은 네 단계로 나뉩니다.
- 모델 다운로드: 서버가 현재 글로벌 모델을 모든 클라이언트(기기)에게 보냅니다. 다 같은 모델에서 출발합니다.
- 로컬 학습: 각 기기가 자기 데이터로 모델을 여러 번 업데이트합니다. 한 번이 아니라 여러 번 공부하는 게 핵심입니다.
- 가중치 업로드: 각 기기는 학습이 끝난 자기 모델을 서버로 올립니다. 중간 과정은 버리고 최종 모델만 올립니다.
- 평균 집계: 서버가 올라온 모델들을 평균 냅니다. 단순 평균이 아니라 데이터가 많은 기기의 모델에 더 큰 가중치를 줍니다. 100개 데이터를 가진 사람의 의견이 10개 가진 사람보다 10배 무겁게 반영되는 식입니다.
이 네 단계를 한 번 도는 것을 라운드(round)라고 부릅니다. 일반 학습에서 데이터를 한 바퀴 도는 “에포크(epoch)“와 비슷한 개념입니다. 라운드를 충분히 반복하면 목표 성능에 도달합니다.
여기서 한 가지 알아두면 좋은 점이 있습니다. 모델 전체를 올리는 대신 “시작 모델과 끝 모델의 차이(변화량)“만 올려도 수학적으로 똑같습니다. 이 변화량을 gradient라고 부를 수 있고, 이 성질이 나중에 통신량을 줄이는 여러 기법의 기초가 됩니다.
데이터 병렬화(Data Parallelism)와 뭐가 다른가
여기서 헷갈리기 쉬운 지점이 있습니다. 데이터센터에서 GPU 여러 대로 학습을 빠르게 돌리는 데이터 병렬화도 “데이터를 나눠서 학습하고 합친다"는 점이 비슷해 보이거든요. 하지만 둘은 결정적으로 다릅니다.
| 구분 | 데이터 병렬화 (Data Parallelism) | 연합학습 (Federated Learning) |
|---|---|---|
| 통신 환경 | 데이터센터 내부 초고속 연결 | 무선/인터넷 (통신이 훨씬 느리고 비쌈) |
| 데이터 분배 | 중앙에서 일부러 골고루 나눠줌 (IID 보장 가능) | 각 기기에서 자연스럽게 생김 (편향이 기본) |
| 업데이트 주기 | 미니배치 1번 → 즉시 동기화 | 여러 번 로컬 학습 → 가끔 통신 |
| 목적 | 학습 속도 향상 | 프라이버시 보호 + 흩어진 데이터 활용 |
두 가지 차이가 특히 중요합니다. 첫째, 데이터 병렬화는 gradient를 딱 한 번 계산하고 바로 평균 내지만, 연합학습은 각 기기가 여러 번 로컬 업데이트를 한 뒤에 모델을 올립니다. 둘째, 데이터 병렬화는 데이터를 일부러 골고루 섞어서 나눠줄 수 있지만(이걸 IID, 독립동일분포라고 합니다), 연합학습의 데이터는 사람마다 제각각이라 골고루 섞이지 않습니다(non-IID).
바로 이 두 가지 차이가 연합학습 고유의 골칫거리를 만들어냅니다. 다음 절에서 그게 뭔지 보겠습니다.
C. Non-IID 문제 = Client Drift: 평균이 망가지는 순간
한 줄 직관
사람마다 가진 데이터가 너무 다르면, 각자 학습한 모델이 서로 다른 방향으로 멀리 가버려서, 평균을 내도 엉뚱한 곳에 도착합니다.
비유
다시 스터디 그룹입니다. 그런데 이번엔 학생들이 푸는 문제집이 완전히 다릅니다. A는 1, 2번 유형만, B는 3, 4번 유형만 죽어라 팝니다. 며칠 뒤 모여서 둘의 머릿속을 “평균” 내면 어떻게 될까요?
A는 1, 2번 전문가, B는 3, 4번 전문가가 됐는데, 둘을 산술 평균한 사람은 어느 쪽도 제대로 못 풉니다. 1, 2번과 3, 4번 사이의 관계(예: 1번과 4번을 어떻게 구별하는지)는 누구도 배운 적이 없으니까요. 두 전문 지식을 단순히 섞으면 죽도 밥도 안 되는 겁니다.
이 현상을 Client Drift(클라이언트 표류)라고 부릅니다. 각 클라이언트의 학습 방향이 자기만의 최적점(local optimum)을 향해 제각각 흘러가서, 평균낸 결과가 진짜 목표 지점에서 벗어나는 것이죠.
조금 더 자세히
실제로 간단히 실험해 볼 수 있습니다. 손글씨 숫자 데이터(MNIST)에서 숫자 두 개({1, 2})로만 모델 하나를 학습하고, 겹치지 않는 다른 두 개({3, 4})로 또 하나를 학습한 뒤, 두 모델을 평균 내보세요. 네 숫자를 잘 구분할 거라 기대하지만 전혀 작동하지 않습니다.
중요한 건, 이 문제가 두 가지 조건이 동시에 충족될 때만 심각해진다는 점입니다.
- 조건 1: non-IID 데이터. 데이터가 골고루 섞여 있으면(IID) 각자의 최적점이 비슷한 곳에 있어서 평균을 내도 괜찮습니다. 사람마다 데이터가 극단적으로 다를 때 문제가 터집니다.
- 조건 2: 여러 번 로컬 업데이트. 만약 gradient를 딱 한 번만 계산하고 바로 올린다면, 그건 그냥 데이터 병렬화와 똑같아서 편향이 안 생깁니다. 여러 번 깊이 파고들수록 각자 자기 우물로 더 깊이 빠집니다.
이 두 조건은 앞서 본 연합학습의 두 가지 특징과 정확히 일치합니다. 연합학습의 본질적인 약점인 셈입니다.
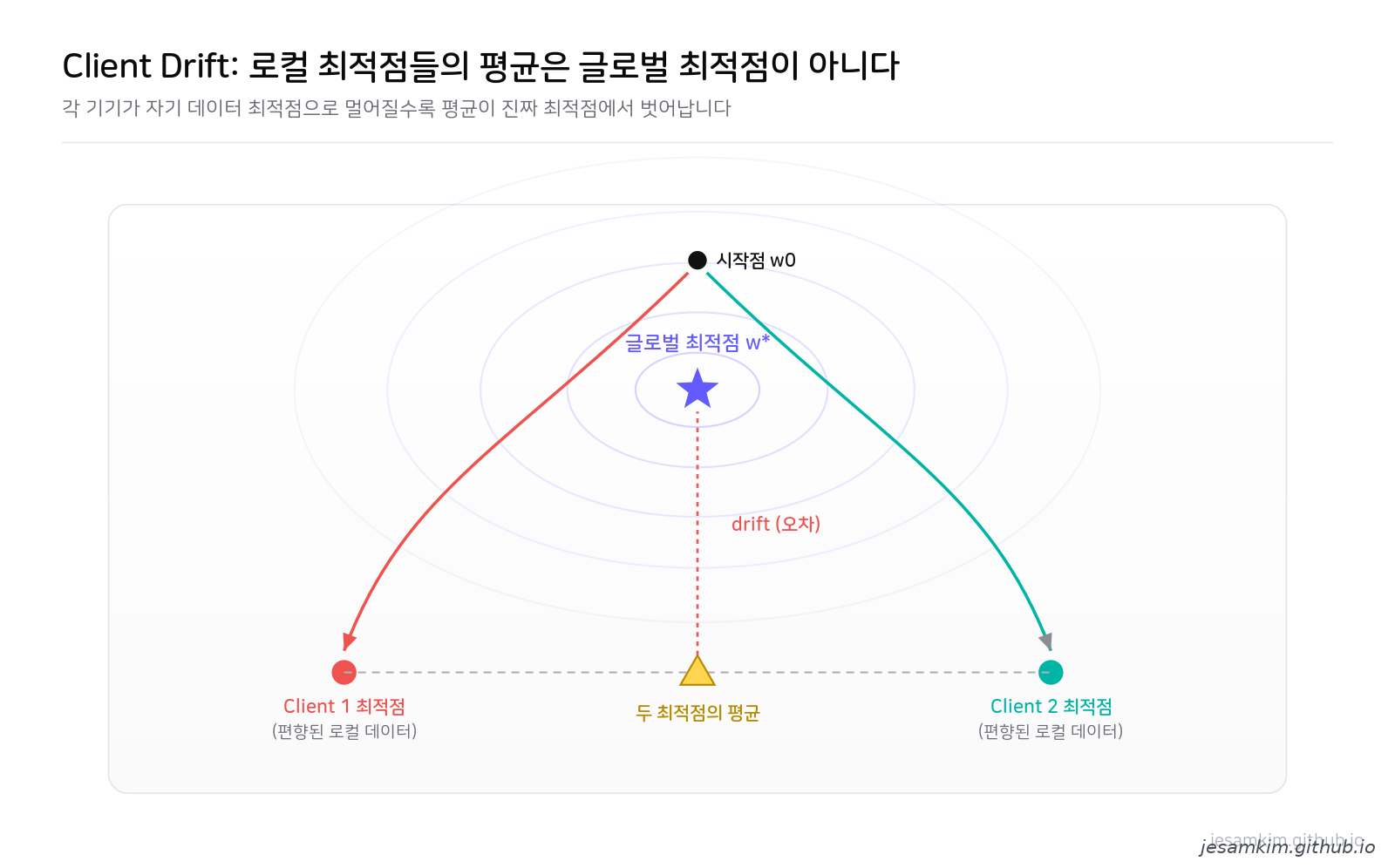 그림 2. Client Drift. 각 기기가 편향된 로컬 데이터의 최적점으로 멀어지면, 그 평균은 진짜 글로벌 최적점(w)에서 벗어납니다. 이 거리가 drift입니다.*
그림 2. Client Drift. 각 기기가 편향된 로컬 데이터의 최적점으로 멀어지면, 그 평균은 진짜 글로벌 최적점(w)에서 벗어납니다. 이 거리가 drift입니다.*
해결책 1: FedProx, “글로벌에서 너무 멀어지지 마”
가장 간단한 해법은 각 기기가 공부할 때 “받았던 원래 모델에서 너무 멀리 가지 마”라는 제약(목줄)을 거는 겁니다. 이게 FedProx입니다.
수식으로는 로컬 손실 함수에 항을 하나 더합니다. 원래 손실 + (내 모델이 글로벌 모델에서 벗어난 거리)에 비례하는 페널티. 이 페널티 항을 proximal term(근접 항)이라고 부릅니다. 페널티의 강도를 조절하는 값이 하나 있는데(보통 뮤, μ로 표기), 이 값이 핵심입니다.
- μ가 0이면 페널티가 사라져서 그냥 FedAvg와 같아집니다. 각 모델이 자기 우물로 빠집니다.
- μ가 너무 크면 페널티가 지배적이 되어 모델이 거의 안 움직입니다. 로컬 데이터를 거의 안 배웁니다.
- 적당한 중간값을 찾는 게 관건입니다. 로컬 데이터는 배우되 글로벌에서 너무 멀어지진 않는 균형점이죠.
좋은 점은 추가 통신 비용 없이 손실 함수만 살짝 바꾸면 끝이라는 겁니다. 아이디어는 단순하지만 편향이 심한 환경에서 눈에 띄게 효과가 있습니다.
해결책 2: SCAFFOLD, “네 방향이 틀렸어, 보정해줄게”
FedProx가 “멀리 가지 마"라고 말린다면, SCAFFOLD는 한 발 더 나아가 “네가 가려는 방향 자체가 틀렸으니 매 걸음마다 방향을 교정해 줄게”라고 합니다.
비유하자면, 자기 우물 쪽으로 끌려가는 학생에게 나침반을 하나 쥐여주는 겁니다. 이 나침반(control variate, 제어 변수라고 부릅니다)은 “전체가 가야 할 방향"과 “네가 지금 가는 방향"의 차이를 알려주고, 그 차이만큼 매 업데이트마다 방향을 보정합니다. 그러면 학생은 자기 우물로 빠지지 않고 계속 글로벌 목표를 향해 갑니다.
효과는 극적입니다. FedAvg에서는 로컬 학습을 많이 시킬수록(우물에 더 깊이 빠져서) 성능이 나빠지는데, SCAFFOLD는 방향이 항상 교정되니 로컬 학습을 많이 시킬수록 오히려 성능이 좋아집니다. 다만 공짜는 아닙니다. 나침반(제어 변수)이 모델과 같은 크기라서, 모델과 나침반을 둘 다 주고받아야 하므로 통신량이 2배가 됩니다.
FedProx vs SCAFFOLD 정리
| 항목 | FedProx | SCAFFOLD |
|---|---|---|
| 핵심 아이디어 | “글로벌에서 멀어지지 마” (페널티) | “방향을 교정해줄게” (나침반) |
| 추가 통신 | 없음 | 있음 (통신량 2배) |
| 튜닝할 값 | μ를 잘 골라야 함 | 추가 튜닝 거의 불필요 |
| 장점 | 통신 효율적, 구현 간단 | 로컬 학습 많이 시켜도 안전 |
| 단점 | μ값에 성능이 민감 | 통신 부담이 큼 |
둘 다 non-IID 환경에서 FedAvg보다 잘 수렴합니다. 상황에 따라 골라 쓰면 됩니다.
D. Personalization: 모두를 위한 하나의 모델이 정답일까
한 줄 직관
지금까지는 모두가 공유하는 단 하나의 글로벌 모델을 만드는 게 목표였습니다. 그런데 그 모델이 정작 나 한 사람한테는 최선이 아닐 수 있습니다.
비유
전국 평균 입맛에 맞춘 식당이 있다고 합시다. 누가 와도 60점은 줄 메뉴를 냅니다. 나쁘진 않죠. 그런데 매운 걸 좋아하는 저한테는 영 심심합니다. 차라리 제 입맛만 아는 동네 분식집이 저한테는 90점입니다.
연합학습도 마찬가지입니다. 스마트폰 자동완성을 생각해 보세요. 어떤 사람은 이모티콘을 잔뜩 쓰고, 어떤 사람은 하나도 안 씁니다. 전 세계 평균으로 학습한 글로벌 모델이 갑자기 제 자동완성에 이모티콘을 막 띄우면, 그건 “개인화가 안 된” 답답한 경험이죠.
조금 더 자세히
실제로 데이터가 사람마다 극단적으로 다른 환경에서는, 협력해서 만든 글로벌 모델(FedAvg)이 그냥 혼자 학습한 모델(Local Only)보다 오히려 못할 때가 있습니다. 예를 들어 한 실험에서 각 사용자가 단 2개 클래스만 가진 극단적 환경을 보면, 혼자 학습한 모델은 정확도 89.79%인데 FedAvg는 42.65%로 폭락하기도 합니다.
왜 이럴까요? 혼자 학습한 모델은 “자기한테 들어오는 쉬운 문제(2개 클래스 구분)“만 잘 풀면 되니까 점수가 높게 나옵니다. 반면 글로벌 모델은 모든 클래스를 다 구분하려다 보니 각자의 좁은 테스트에서는 손해를 봅니다.
그렇다고 협력을 포기할 순 없습니다. 혼자서는 데이터가 부족하니까요. 그래서 “협력은 하되, 최종적으로는 나만의 모델을 갖자"는 개인화(Personalization)가 등장합니다. 대표적인 세 가지 접근을 보겠습니다.
방법 1: Ditto: 글로벌 모델을 닻으로 삼기
Ditto는 각 기기가 두 개의 모델을 동시에 굴립니다. 하나는 모두와 공유하는 글로벌 모델, 다른 하나는 나만의 개인 모델입니다.
개인 모델을 학습할 때 FedProx와 비슷한 페널티를 씁니다. “내 데이터에 맞추되, 모두가 함께 만든 글로벌 모델에서 너무 멀어지진 마"라는 거죠. 글로벌 모델을 닻(anchor)처럼 붙잡아두는 겁니다. 개인 모델은 서버에 안 보내고 내 기기에만 둡니다.
핵심은 균형입니다. 페널티가 0이면 그냥 혼자 학습한 것과 같아지고, 페널티가 너무 세면 글로벌 모델을 그대로 따라가 버립니다. 중간값에서 “내 입맛에 맞으면서도 전체 지식에서 크게 벗어나지 않는” 모델이 나옵니다.
방법 2: Fine-tuning: 받아서 내 데이터로 마무리
가장 단순하고도 강력한 방법입니다. 글로벌 모델을 일종의 사전학습(pre-trained) 모델로 보고, 받아서 내 데이터로 몇 번 더 학습(fine-tuning)하는 겁니다.
비유하면 이렇습니다. 모두가 함께 만든 글로벌 모델은 “기본기를 두루 갖춘 신입사원"입니다. 이 사원을 내 팀(내 데이터)에 배치해서 우리 업무에 맞게 며칠 더 가르치면, 처음부터 백지로 뽑은 사람보다 훨씬 빨리 우리 팀 전문가가 됩니다.
새 데이터를 따로 모을 필요도 없습니다. 글로벌 모델 학습에 썼던 내 데이터를 그대로 fine-tuning에 쓰면 됩니다. 놀랍게도 이 단순한 방법이 훨씬 복잡한 기법들과 비등하거나 더 좋은 경우가 많습니다. “강력한 기준선(baseline)“으로 자주 언급됩니다.
방법 3: FedRep: 공통 부분만 공유, 마지막만 개인화
신경망을 두 부분으로 나눠서 생각해 봅시다.
- 앞부분(표현층, representation): 이미지의 윤곽이나 질감, 텍스트의 단어 의미처럼 누구에게나 공통인 보편적 특징을 뽑아내는 부분.
- 뒷부분(분류기 헤드, head): 그 특징을 보고 “이건 1번 클래스, 저건 4번 클래스” 하고 최종 판단을 내리는 부분.
FedRep의 통찰은 이겁니다. 사람마다 다른 건 주로 “어떤 클래스를 갖고 있느냐”(뒷부분)이지, “특징을 뽑는 방식”(앞부분)은 대체로 공통이라는 거죠. 그래서 앞부분(표현층)만 서버와 공유해서 함께 키우고, 뒷부분(헤드)은 각자 자기 것만 가집니다.
이렇게 하면 두 가지 이득이 있습니다. 첫째, 공통 특징은 모두의 데이터로 튼튼하게 학습되고 개인 판단은 각자에 맞춰집니다. 둘째, 헤드를 서버에 안 보내니 통신량도 줄고 프라이버시 측면에서도 자연스럽습니다.
개인화 세 방법 정리
| 방법 | 핵심 전략 | 비유 |
|---|---|---|
| Ditto | 글로벌 모델을 닻으로 삼아 개인 모델 학습 | 전체 지식을 참고하되 내 모델 따로 운영 |
| Fine-tuning | 글로벌 모델 받아서 내 데이터로 마무리 학습 | 기본기 갖춘 신입을 우리 팀에 맞게 재교육 |
| FedRep | 공통 표현층만 공유, 분류 헤드는 개인화 | 기초는 함께, 최종 판단은 각자 |
E. Privacy & Security: gradient만 보내도 데이터가 새어 나간다
한 줄 직관
연합학습을 쓰는 이유 자체가 프라이버시였습니다. 그런데 충격적이게도, 원본 데이터를 안 보내고 gradient(모델 변화량)만 보내도 원본을 복원할 수 있습니다.
비유
내용물은 안 보여주고 “이 상자를 들었더니 오른팔 근육이 이만큼 당겨졌다"는 정보만 알려줬다고 합시다. 그런데 그 당겨진 정도가 너무 정확해서, 역으로 계산하면 상자 안에 뭐가 몇 kg 들어 있는지 알아낼 수 있는 겁니다. “원본은 안 줬으니 안전하다"는 믿음이 깨지는 순간입니다.
조금 더 자세히: Deep Leakage from Gradients (DLG)
이 공격의 이름이 Deep Leakage from Gradients, 줄여서 DLG입니다. 2019년에 발표됐습니다. 동작 원리는 의외로 단순합니다.
서버(공격자)는 모델과, 사용자가 보낸 진짜 gradient를 갖고 있습니다. 공격은 이렇게 진행됩니다.
- 가짜 입력을 만듭니다. 그냥 랜덤 노이즈 이미지와 랜덤 정답표로 시작합니다.
- 가짜 입력으로 gradient를 계산합니다. 모델을 알고 있으니 가능합니다.
- 두 gradient의 차이를 줄입니다. 단, 평소처럼 모델을 고치는 게 아니라, 가짜 입력 자체를 조금씩 고칩니다.
- 이걸 반복하면, 가짜 gradient가 진짜 gradient에 가까워지면서 가짜 입력이 점점 원본 데이터로 변해갑니다.
처음엔 노이즈였던 이미지가 수백 번 반복 끝에 원본 사진과 거의 똑같이 복원됩니다. 손글씨 숫자, 사람 얼굴 모두 복원에 성공했습니다.
특히 무서운 점은, gradient가 모델 자체보다 데이터 정보를 더 진하게 담고 있다는 겁니다. gradient는 “이 데이터로 모델이 어떻게 바뀌어야 하는지"를 직접 담고 있으니까요. 결론은 분명합니다. 연합학습이 데이터를 안 보낸다고 해서 데이터 보호를 보장하는 건 아닙니다. 그래서 별도의 방어 기법이 필요합니다. 대표적인 두 가지를 보겠습니다.
방어책 1: Differential Privacy (DP): 노이즈를 섞는다
차등 프라이버시(Differential Privacy)는 모델이나 gradient에 랜덤 노이즈를 일부러 끼얹어서 보내는 방법입니다.
비유하자면, 설문조사에서 “당신의 정확한 연봉은?“이라고 묻는 대신 “동전을 던져서 앞면이면 진짜 답을, 뒷면이면 아무 숫자나 말하세요"라고 하는 겁니다. 개인 한 명의 답은 흐려지지만, 수천 명을 모으면 통계적 경향은 여전히 드러납니다.
여기엔 명확한 트레이드오프가 있습니다. 노이즈를 많이 넣을수록(프라이버시 예산을 작게 잡을수록) 보호는 강해지지만 정확도는 떨어집니다. 노이즈를 적게 넣으면 정확도는 유지되지만 보호가 약해집니다. 작업의 민감도에 따라 균형점을 골라야 합니다.
방어책 2: Secure Aggregation: 합만 보이게 가린다
Secure Aggregation(보안 집계)은 발상이 영리합니다. 정확도를 깎는 대신, 암호학적인 트릭으로 서버가 개별 모델은 못 보고 오직 “전체 합(평균)“만 보게 만듭니다.
비유로 설명하면 이렇습니다. 친구 셋이 각자 연봉을 밝히지 않고 평균 연봉만 알고 싶습니다. 방법이 있습니다. 서로 짝을 지어 합치면 0이 되는 비밀 숫자를 주고받습니다. A가 B에게 +500을 주면 B는 A에게 -500을 갖습니다. 각자 자기 연봉에 이 비밀 숫자들을 더해서 발표하면, 개인 발표값은 엉터리지만 셋을 다 더하면 비밀 숫자들이 서로 상쇄되어 진짜 합만 남습니다.
서버는 이 “가려진 값"들을 받아서 더하기만 합니다. 마스크가 깔끔히 상쇄되니 정확한 합을 얻으면서도, 개별 사용자가 실제로 뭘 보냈는지는 전혀 알 수 없습니다. 정확도 손실이 없다는 게 큰 장점입니다.
단점도 있습니다. 한 사람이 중간에 이탈하면(배터리가 나가거나 연결이 끊기면) 그 사람의 마스크가 상쇄되지 않아서 합 자체가 망가집니다. 이걸 dropout 문제라고 합니다. 더 복잡한 암호 기법으로 해결할 수 있지만, 기본형은 이탈에 취약합니다.
DP vs Secure Aggregation 정리
| 항목 | Differential Privacy | Secure Aggregation |
|---|---|---|
| 보호 방식 | 노이즈 추가 | 암호학적 마스킹 |
| 정확도 영향 | 손실 있음 (트레이드오프) | 손실 없음 (이론상) |
| 비용 | 계산 거의 없음 | 비밀 마스크 합의 필요 |
| 이탈(dropout)에 | 강함 | 약함 (개선판 필요) |
두 방법은 서로 보완적이라 실무에서는 함께 쓰는 경우가 많습니다. 실제로 구글 Gboard는 연합학습에 DP와 Secure Aggregation을 모두 결합한 풀스택 보호를 적용합니다.
F. Straggler 문제: 느린 기기 하나 때문에 전체가 멈춘다
한 줄 직관
라운드를 끝내려면 모든 기기의 결과를 모아야 하는데, 딱 한 대가 느리면 나머지가 다 끝나도 그 한 대를 기다리느라 전체가 늘어집니다.
비유
조별 과제에서 5명 중 4명은 자료를 30분 만에 보냈는데 1명이 사흘째 감감무소식입니다. 발표 자료를 합치려면 그 한 명을 기다려야 하니, 조 전체의 마감이 그 한 명에게 끌려갑니다. 이 느린 한 명을 straggler(낙오자, 지각생)라고 부릅니다.
연합학습에서 기기들은 성능도 네트워크 속도도 제각각입니다(이걸 heterogeneous, 이질적이라고 합니다). 그래서 straggler는 항상 존재합니다. 동기식(모두 기다리기)에서는 가장 느린 기기의 시간이 곧 라운드 시간이 됩니다.
조금 더 자세히: 네 가지 처리 전략
이 문제를 푸는 방법은 크게 네 가지입니다.
옵션 0: 모두 기다리기. 가장 단순합니다. 모든 기기가 올 때까지 기다립니다. 정확하지만 가장 느립니다. 빠른 기기들이 하염없이 놀게 됩니다.
옵션 1: 일부만 기다리기. 마감 시간(timeout)을 정하거나, 절반 정도가 도착하면 그냥 집계해 버립니다. 빠르긴 한데 문제가 있습니다. 항상 빠른 기기만 반영되면, 느린 기기의 데이터는 영원히 모델에 안 들어갑니다. non-IID 환경에서는 이게 편향을 만듭니다. 시골/원거리 사용자가 계속 누락되는 식이죠.
옵션 2: 비동기(Asynchronous). 기다리지 않습니다. 누구든 도착하는 즉시 그 한 대의 결과로 글로벌 모델을 살짝 갱신하고, 그 사람에게만 새 모델을 돌려줍니다. 가장 빠릅니다. 그런데 새로운 문제가 생깁니다. 느린 기기가 마침내 결과를 보낼 때쯤이면, 서버 모델은 이미 빠른 기기들 덕에 한참 진화해 있습니다. 느린 기기가 보낸 건 한참 옛날 모델 기준이라 시대에 뒤떨어진(outdated) 정보입니다.
이 “얼마나 뒤처졌나"를 staleness(신선도 저하)라고 부릅니다. 내가 모델을 받은 뒤로 서버가 몇 번이나 업데이트됐는지를 세는 값입니다. staleness가 0이면 받자마자 바로 보냈다는 뜻이고, 10이면 그 사이 서버가 10번 바뀌었다는 뜻이죠.
해결책은 staleness가 클수록 그 결과의 영향력을 깎는 겁니다. 오래된 정보일수록 살살 반영하는 거죠. 이렇게 하면 비동기의 속도를 누리면서도 옛날 정보에 끌려가는 걸 막을 수 있습니다.
옵션 3: Staleness-aware grouping(신선도 기반 그룹화). 동기와 비동기의 장점을 섞습니다. 마감 시간을 두고 그 안에 온 결과를 모으되, 늦게 온 기기의 결과도 버리지 않고 “몇 라운드 늦었는지(staleness)“로 그룹을 나눠 다음 라운드에 반영합니다. 그룹마다 신선도에 따라 가중치를 다르게 줍니다. 모든 기기가 결국엔 모델에 반영되되, 늦을수록 영향력이 작아집니다.
이 옵션 3의 변형으로 Tier-based 방법도 있습니다. 기기를 속도별로 등급(tier)을 매겨서, 비슷한 속도끼리 묶어 처리합니다. 동기식 버전이 TiFL, 비동기식 버전이 FedAT입니다. 느린 기기들을 한꺼번에 모아 처리하면, 빠른 기기들의 라운드에서 시간을 아낄 수 있습니다.
Straggler 처리 옵션 비교
| 옵션 | 라운드 지연 | 데이터 활용 | 신선도(staleness) | 약점 |
|---|---|---|---|---|
| 0: 모두 기다리기 | 매우 큼 | 모두 활용 | 0 | 가장 느림 |
| 1: 일부만 기다리기 | 작음 | 일부 손실 | 0 | 느린 기기 영구 누락 |
| 2: 비동기 | 가장 작음 | 모두 활용 | 큼 | 옛 정보에 끌려감 |
| 3: 그룹화 | 중간 | 모두 활용 | 작음 | 구현 복잡 |
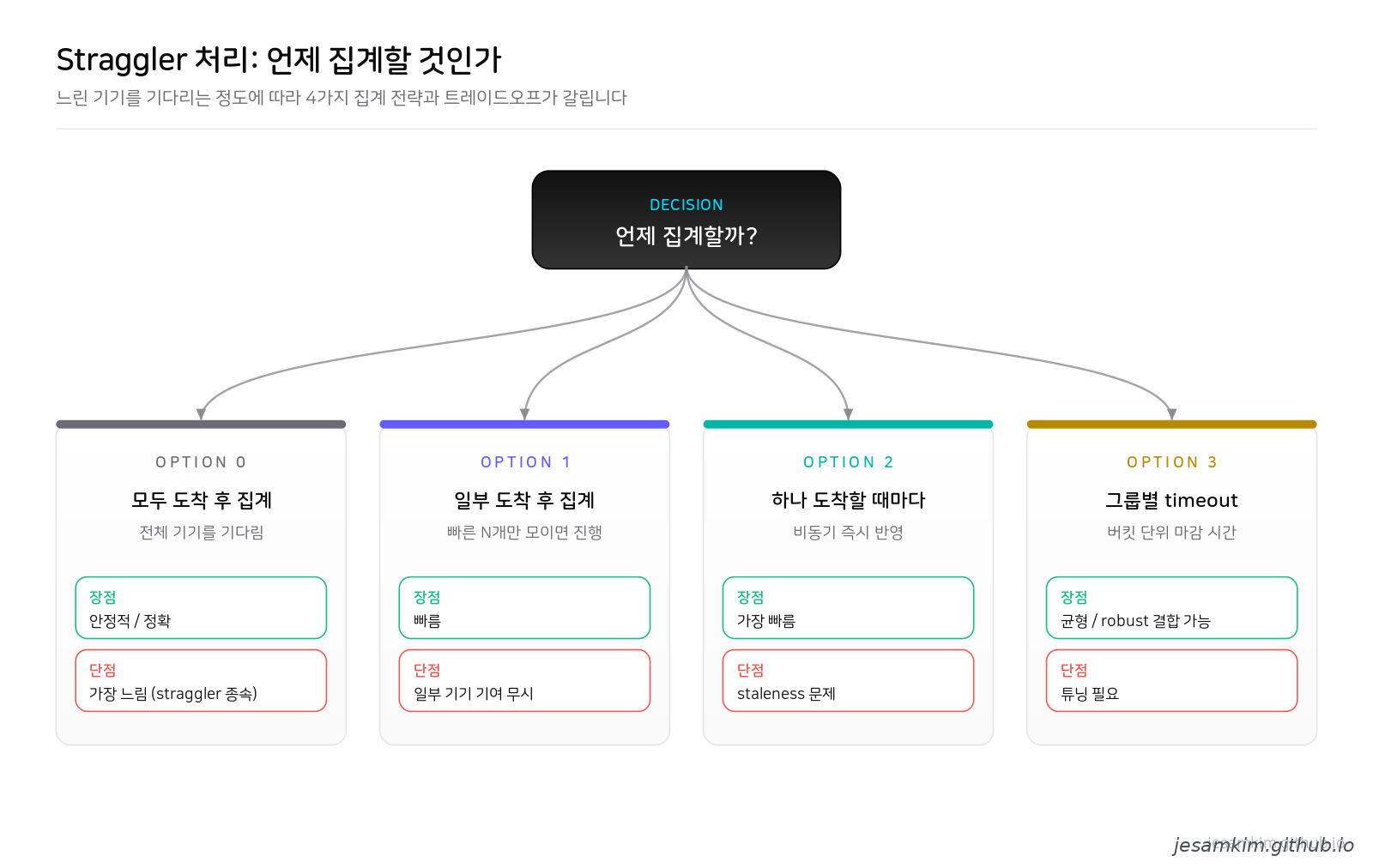 그림 3. 느린 기기(straggler)를 얼마나 기다릴지에 따라 4가지 집계 전략이 갈립니다. 속도와 안정성, robust 결합 가능성 사이의 트레이드오프를 보여줍니다.
그림 3. 느린 기기(straggler)를 얼마나 기다릴지에 따라 4가지 집계 전략이 갈립니다. 속도와 안정성, robust 결합 가능성 사이의 트레이드오프를 보여줍니다.
여기서 옵션 3을 기억해 두세요. 다음 절에서 이게 왜 특별한지 드러납니다.
G. Adversary 문제: 악의적인 기기가 거짓을 보낼 때
한 줄 직관
참여자 중 누군가 일부러 이상한 모델을 보내면, 단순 평균은 그 하나에 통째로 휘둘려서 망가집니다.
비유
다섯 명이 각자 “오늘 적정 기온"을 추측해서 평균을 냅니다. 네 명이 20도 근처를 말하는데 한 명이 “1000도"라고 우기면, 단순 평균은 단숨에 216도로 튀어 오릅니다. 한 명의 극단값이 전체를 오염시킨 겁니다.
연합학습에서 이런 참여자를 adversary(적대적 노드)라고 부릅니다. 꼭 해커만은 아닙니다.
- 의도적 공격: gradient에 -100을 곱해서 모델이 정반대로 학습하게 만드는 식.
- 의도 없는 불량 데이터: 라벨이 잘못 붙었거나 품질이 나쁜 데이터.
- 무임승차(free-rider): 전기/연산을 아끼려고 학습은 안 하고 랜덤 모델이나 받은 모델을 그대로 돌려보내는 사람.
소수만 있어도, 특히 라운드마다 반복적으로 공격이 누적되면 모델이 곤두박질칩니다. 단순 평균(Mean)은 통계학 용어로 “breakdown point가 0%“입니다. 단 하나의 극단값에도 무너진다는 뜻이죠. 그래서 평균 대신 튼튼한(robust) 집계 방법이 필요합니다. 네 가지를 보겠습니다.
방법 1: Multi-Krum: 거리 기반으로 골라내기
발상은 단순합니다. “다수가 비슷한 방향이면 그게 정직한 방향”이라고 가정하는 겁니다. 정직한 gradient들은 서로 가까이 뭉쳐 있고, 악의적인 건 멀찍이 떨어져 있겠죠.
그래서 각 gradient에 대해 “가까운 이웃들까지의 거리 합"으로 점수를 매기고, 점수가 작은(=잘 뭉쳐 있는) 것들만 골라 평균냅니다. 멀리 떨어진 outlier는 제외합니다.
비유하면, 다트판에 화살이 여러 개 꽂혔는데 대부분 가운데 모여 있고 하나만 구석에 박혀 있으면, 그 구석 화살은 “조준이 틀린 것"으로 보고 빼고 계산하는 겁니다.
이 방법엔 조건이 하나 있습니다. 악의적 노드가 최대 몇 개인지(f라고 표기)를 미리 알아야 합니다. 그리고 악의적 노드끼리 짜고 뭉칠 수 있으니, 안전 여유를 두고 조금 더 보수적으로 골라냅니다.
방법 2: Trimmed Mean: 좌표별로 극단값 자르기
Trimmed Mean(절사 평균)은 관점이 다릅니다. Multi-Krum이 “벡터 통째로"를 보고 골라낸다면, 이건 각 숫자(좌표) 단위로 자릅니다.
스포츠 심사를 떠올려 보세요. 심사위원 점수에서 최고점과 최저점을 빼고 나머지로 평균을 냅니다. 한두 명이 극단적으로 점수를 매겨도 결과가 안 흔들리죠. Trimmed Mean도 똑같습니다. 모델의 각 파라미터마다 모든 기기의 값을 모아 정렬하고, 위아래 f개씩 잘라낸 뒤 나머지를 평균냅니다.
여기서 중요한 디테일. 극단값을 0으로 바꾸는 게 아니라 아예 빼고 계산합니다. 0으로 두면 그 0이 평균에 반영되니까요. 또 Multi-Krum과 달리 벡터가 통째로 날아가는 게 아니라, 여러 벡터에서 조금씩 정보가 빠집니다.
방법 3: Geometric Median: 거리 합이 최소인 중앙점
Geometric Median(기하 중앙값)은 “모든 점까지의 거리 합이 가장 작은 한 점”을 찾습니다. 1차원에서는 우리가 아는 그 중앙값(median)과 같습니다.
중앙값의 강력함을 시험 등수로 비유해 보겠습니다. 반에서 1등이 100점을 맞았는데, 갑자기 그 점수가 1000점, 10000점으로 부풀려져도 중간 등수 학생의 점수는 꿈쩍도 안 합니다. 극단값이 아무리 날뛰어도 중앙은 흔들리지 않는 거죠. 이게 robust statistics(강건 통계)의 고전적 성질입니다.
여기서 미묘하지만 결정적인 포인트가 있습니다. 거리의 합을 최소화하면 robust한 중앙값이 나오지만, 거리의 제곱 합을 최소화하면 그냥 단순 평균이 나옵니다. 제곱을 붙이느냐 마느냐가 “공격에 강한가 약한가"를 가릅니다. 그래서 제곱 없는 거리 합을 써야 합니다.
Geometric Median의 가장 큰 장점은 악의적 노드 수(f)를 미리 몰라도 된다는 점입니다. Multi-Krum이나 Trimmed Mean은 f를 알아야 하는데, 실전에서 그걸 정확히 아는 건 어렵거든요.
방법 4: Public Data 활용, 데이터로 직접 검증 (Sageflow)
앞의 세 방법은 모두 gradient의 통계(거리, 순위)만 봅니다. 데이터는 안 봅니다. 네 번째 방법은 한 발 더 나아가, 서버가 가진 소량의 공개 데이터(public data)로 각 모델을 직접 시험해 봅니다. 이 방법을 정리한 대표 연구가 Sageflow(2021년 발표)입니다.
두 가지 검사를 씁니다.
Entropy(엔트로피) 필터링: 각 기기 모델에 공개 데이터를 넣고 출력의 “불확실성"을 잽니다. 모델 파라미터를 랜덤하게 망쳐놓은 공격 모델은 아무거나 헷갈려 하므로 불확실성(entropy)이 비정상적으로 높습니다. 이게 기준치를 넘으면 그 모델은 버립니다. 즉 “확신을 못 하는 모델”을 걸러냅니다.
Loss 기반 가중 평균: 필터를 통과한 모델이라고 다 믿을 순 없습니다. 라벨을 일부러 뒤섞은 데이터로 “열심히” 학습한 공격 모델은 자기 답에 확신이 있어서(entropy가 낮아서) 필터를 통과해 버리거든요. 그래서 살아남은 모델들에 대해 공개 데이터로 실제 정답을 얼마나 맞히는지(loss)를 재고, 틀리는 모델일수록 영향력을 줄입니다.
핵심은 두 검사의 역할이 다르다는 점입니다. Entropy는 “확신하는가"를 보고, Loss는 “정답을 맞히는가"를 봅니다. 잘못된 방향으로 확신하는 모델은 entropy로 못 잡지만 loss로 잡힙니다. 그래서 둘을 같이 써야 어떤 공격이든 막을 수 있습니다. 단점은 모든 모델에 공개 데이터를 통과시켜야 해서 계산 비용이 늘어난다는 겁니다.
Adversary 방어 방법 비교
| 방법 | 보는 관점 | f를 알아야? | 핵심 직관 |
|---|---|---|---|
| Multi-Krum | 벡터 전체 (거리) | 필요 | 뭉친 것만 골라 평균 |
| Trimmed Mean | 좌표 단위 (순위) | 필요 | 위아래 극단값 제거 |
| Geometric Median | 벡터 전체 (거리 합) | 불필요 | 거리 합 최소인 중앙점 |
| Public Data (Sageflow) | 실제 데이터 검증 | 불필요 | 확신도(entropy) + 정답률(loss) |
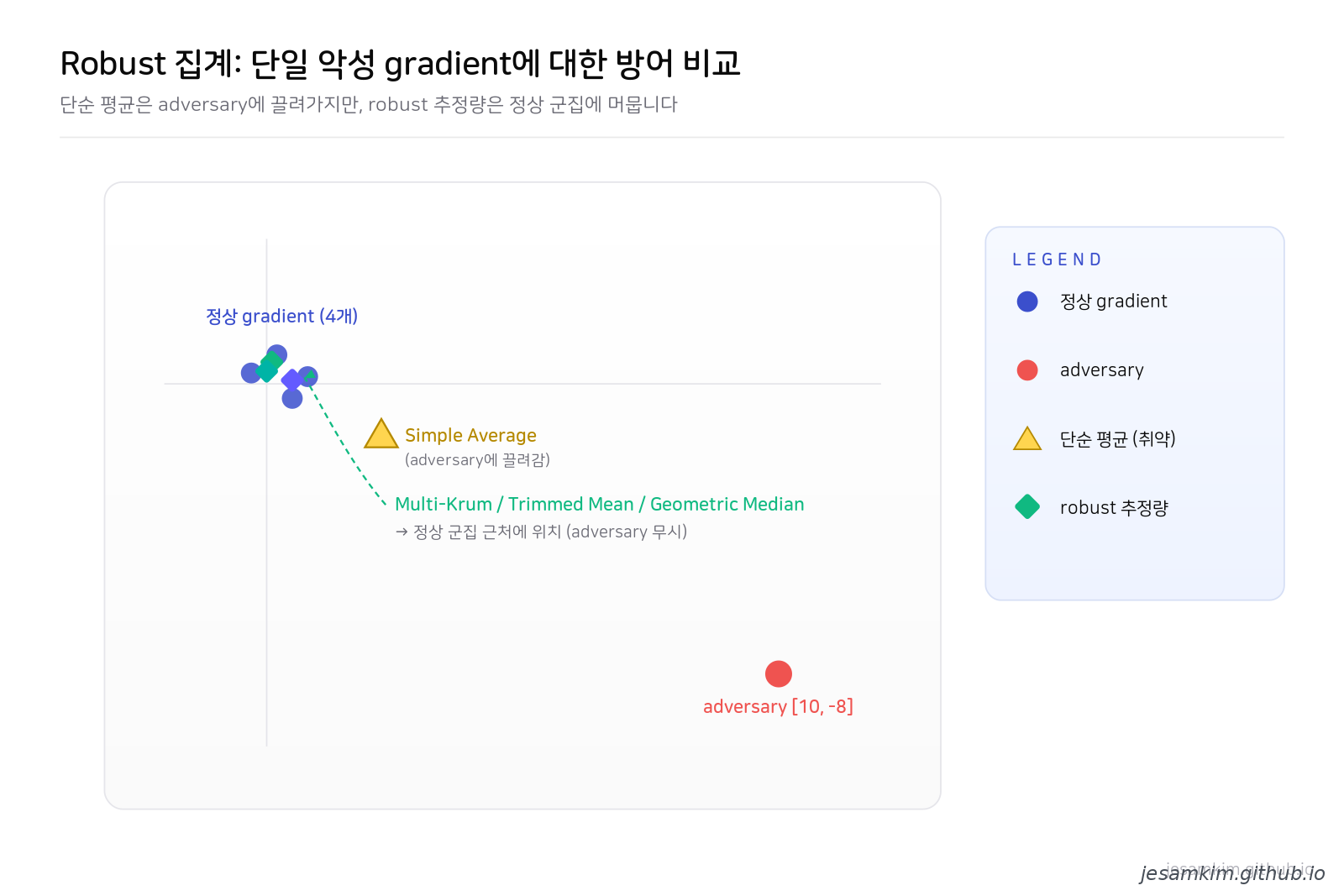 그림 4. 단 하나의 악성 gradient만으로도 단순 평균은 크게 끌려갑니다. 반면 Multi-Krum, Trimmed Mean, Geometric Median 같은 robust 추정량은 정상 군집 근처에 머뭅니다.
그림 4. 단 하나의 악성 gradient만으로도 단순 평균은 크게 끌려갑니다. 반면 Multi-Krum, Trimmed Mean, Geometric Median 같은 robust 추정량은 정상 군집 근처에 머뭅니다.
Straggler와 Adversary를 동시에: Sageflow 통합
여기서 앞 절의 떡밥을 회수합니다. 비동기(옵션 2)는 가장 빠르지만 치명적 약점이 있습니다. 한 번에 한 대씩만 처리하니까, 여러 모델을 비교해야 동작하는 robust 방법(Multi-Krum, Trimmed Mean, Geometric Median)을 쓸 수가 없습니다. 비교 대상이 없으니 악의적 모델을 골라낼 방법이 없는 거죠.
반면 옵션 3(staleness-aware grouping)은 timeout 동안 모인 여러 모델을 그룹으로 묶습니다. 그룹 안에 여러 대가 있으니, 그 안에서 robust 집계를 자유롭게 적용할 수 있습니다. 이래서 옵션 3이 특별합니다. 느린 기기 문제와 악의적 기기 문제를 동시에 풀 수 있는 유일한 토대가 되거든요.
Sageflow가 바로 이 조합입니다. staleness 그룹화로 straggler를 다루고, 각 그룹 안에서 entropy 필터링과 loss 가중 평균으로 adversary를 막습니다. 느린 노드와 악의적 노드가 동시에 존재하는 험한 환경에서 가장 균형 잡힌 성능을 보입니다.
| Straggler 처리 | Robust 집계 결합 가능? |
|---|---|
| 옵션 0 (모두 대기) | 가능 (단, 느림) |
| 옵션 1 (일부 대기) | 가능 (단, 데이터 손실) |
| 옵션 2 (비동기) | 불가능 (한 번에 한 대씩) |
| 옵션 3 (그룹화) | 모두 가능 |
H. 분산 추론: 학습이 끝났다면 서비스는 어떻게?
지금까지는 전부 “어떻게 잘 학습할까”의 이야기였습니다. 이제 관점을 바꿉니다. 모델을 다 만들었다면, 실제 사용자에게 어떻게 빠르고 싸게 서비스할까요? 이게 분산 추론(Distributed Inference)입니다.
학습과 추론은 성격이 다르다
- 학습은 한 번 잘 해두면 되는 일회성/주기적 작업입니다.
- 추론은 요청이 들어올 때마다 즉시 응답해야 하는 실시간 작업입니다. 그래서 지연시간(latency), 처리량(throughput), 서빙 비용이 핵심 지표가 됩니다.
재미있는 점은, 추론을 위한 특별한 기술이 따로 있는 게 아니라는 겁니다. 학습에서 쓰던 병렬화 기법(데이터/텐서/전문가 병렬화)을 그대로 가져와 추론에 씁니다. 다만 어디에 뭘 적용할지가 달라집니다.
LLM 추론의 두 단계: Prefilling과 Decoding
거대 언어 모델(LLM)의 추론은 성격이 완전히 다른 두 단계로 나뉩니다. 챗봇에 “MoE가 뭐야?“라고 물었다고 합시다.
1단계 Prefilling(프리필링): 질문을 한 번에 먹이는 단계. 입력 프롬프트의 모든 토큰(“What”, “is”, “MoE”, “?")을 동시에 모델에 통과시킵니다. 모든 토큰을 한꺼번에 처리할 수 있으니 병렬화에 매우 유리하고, 연산이 많습니다(compute-bound). 딱 한 번만 합니다.
2단계 Decoding(디코딩): 답을 한 글자씩 짜내는 단계. LLM은 본질적으로 “다음 단어 맞히기” 모델입니다. 답이 통째로 나오는 게 아니라, “MoE” 다음에 “is”, 그다음 “a”… 이렇게 한 토큰씩 순서대로 생성합니다. 앞 토큰이 나와야 다음 토큰을 만들 수 있어서 병렬화가 어렵고(sequential), 매번 거대한 모델 가중치를 메모리에서 읽어야 해서 메모리가 병목(memory-bound)입니다. 답변 길이만큼 수십 번에서 수천 번 반복합니다.
비유하면 prefilling은 시험 문제를 한눈에 다 읽는 것이고, decoding은 답안을 한 글자씩 손으로 써 내려가는 것입니다. 읽는 건 빠르지만 쓰는 데 시간이 걸리죠. 사용자가 체감하는 “타자기처럼 답이 나오는 속도"는 거의 전적으로 decoding에 달려 있습니다.
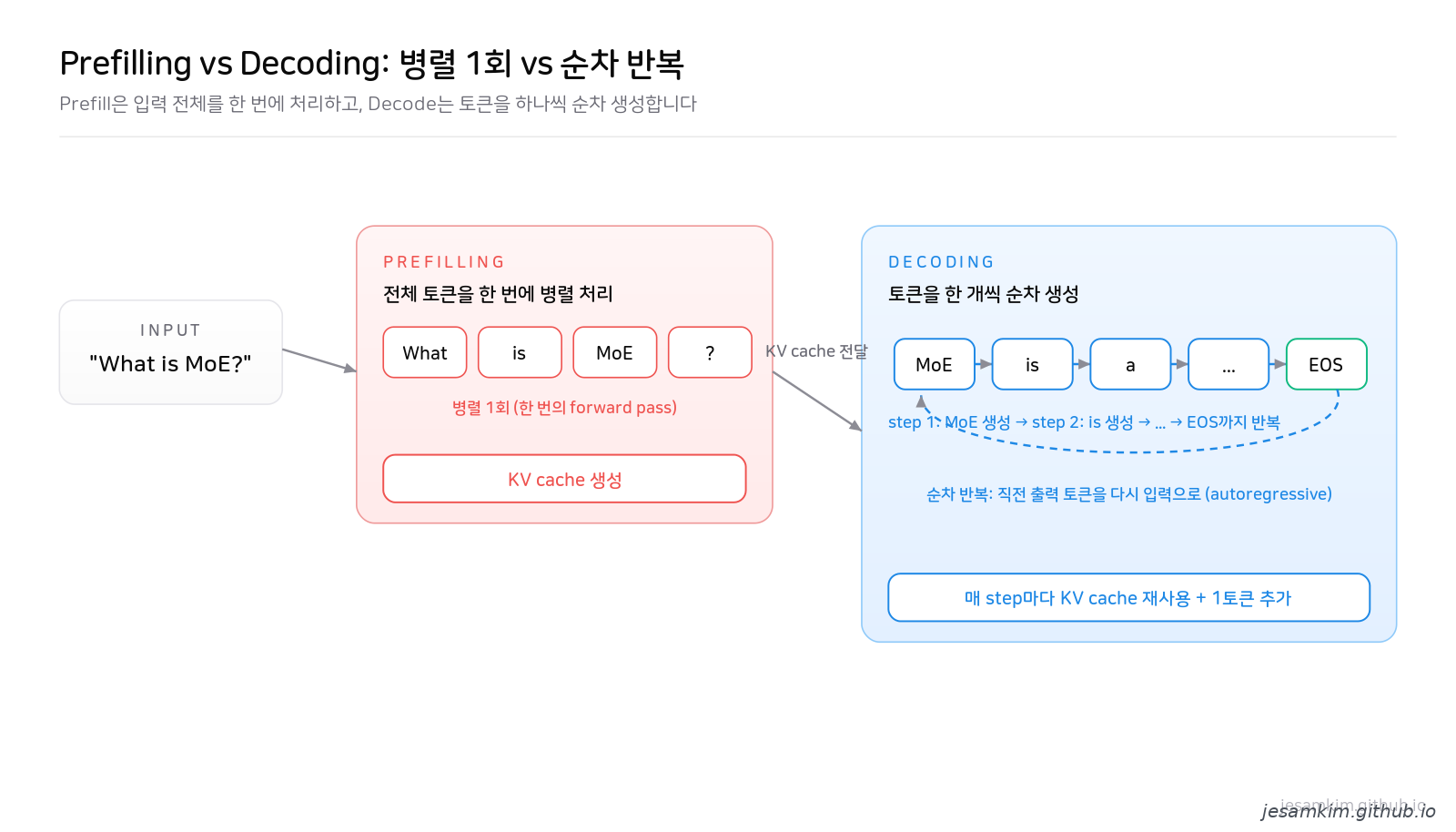 그림 5. Prefilling은 입력 전체를 한 번의 forward pass로 병렬 처리해 KV cache를 만들고, Decoding은 토큰을 하나씩 순차적으로(autoregressive) EOS까지 생성합니다.
그림 5. Prefilling은 입력 전체를 한 번의 forward pass로 병렬 처리해 KV cache를 만들고, Decoding은 토큰을 하나씩 순차적으로(autoregressive) EOS까지 생성합니다.
DeepSeek-V3: 두 단계에 다른 병렬화를 적용
실제 사례로 DeepSeek-V3를 보겠습니다(공개된 기술 보고서 기준). 이 모델은 prefilling과 decoding에 서로 다른 규모의 병렬화를 씁니다.
- Prefilling: 최소 배포 단위가 32개 GPU입니다. 데이터 병렬화 8배(DP8)로 동시 접속한 여러 사용자를 8개 그룹에 나눠 담고, 각 그룹 안에서 attention 부분은 텐서 병렬화 4배(TP4)로 쪼갭니다. MoE(전문가 혼합) 부분은 전문가 병렬화 32배(EP32)로 256명의 전문가를 32개 GPU에 8명씩 배치합니다.
- Decoding: 최소 배포 단위가 무려 320개 GPU입니다. 데이터 병렬화를 80배(DP80)로, 전문가 병렬화를 320배(EP320)로 키웁니다.
왜 decoding에 GPU를 10배나 더 쏟아부을까요? Prefilling은 한 질문 안에서 토큰들을 동시에 처리할 수 있어 적은 GPU로 충분합니다. 하지만 decoding은 토큰을 하나씩 순서대로 만들어야 해서 한 사용자 안에서는 병렬화가 안 됩니다. 그래서 “사용자를 여러 GPU에 흩어놓는” 방식으로 우회합니다. 320명이 동시에 쓰면, 320개 GPU가 한 명씩 맡아 즉시 응답하는 식이죠. GPU 32개로 320명을 받으면 한 GPU가 10명을 줄 세워 처리하니 대기 시간이 길어집니다.
여기서 흥미로운 비대칭이 하나 더 있습니다. 학습에는 텐서 병렬화를 안 쓰고 추론에만 씁니다. 텐서 병렬화는 순방향 계산(forward)은 단순하지만 역방향 계산(backward)까지 따지면 매우 복잡해집니다. 학습은 backward가 필수라 비용이 크지만, 추론은 forward만 하니까 텐서 병렬화의 장점만 깔끔히 누릴 수 있는 겁니다. 반대로 파이프라인 병렬화는 추론에서 통신 부담이 커서 잘 안 씁니다.
또 한 가지. 같은 데이터 병렬화라도 학습과 추론에서 의미가 다릅니다. 학습의 DP는 여러 GPU가 gradient를 모아 동기화해야 하지만, 추론의 DP는 각 GPU가 서로 다른 사용자 요청을 완전히 독립적으로 처리합니다. 협력도, 동기화도, backward도 없이 forward만 따로따로 돌리면 끝입니다. 그래서 통신 부담이 거의 사라집니다.
Prefilling vs Decoding 정리
| 항목 | Prefilling | Decoding |
|---|---|---|
| 입력 길이 | 프롬프트 전체 | 한 토큰씩 |
| 계산 방식 | 고도 병렬 (compute-bound) | 순차적 (memory-bound) |
| 비유 | 문제를 한눈에 읽기 | 답을 한 글자씩 쓰기 |
| DeepSeek-V3 GPU 수 | 32 (DP8 + EP32) | 320 (DP80 + EP320) |
On-Device vs Cloud: 작은 건 폰에서, 어려운 건 클라우드로
서버에 모델을 두는 방식(cloud)만 있는 건 아닙니다. 모델을 아예 사용자 기기에 직접 넣는 방식(on-device)도 있습니다. 둘은 정반대의 장단점을 가집니다.
- On-device(폰에서 직접): 데이터를 안 보내니 프라이버시가 좋고, 통신이 필요 없어 오프라인에서도 됩니다. 대신 기기 자원(메모리, 배터리)이 한계라 큰 모델은 못 올리고, 보통 공개된 작은 모델을 쓰니 성능이 낮습니다.
- Cloud(서버에서): 강력한 서버 자원으로 거대 모델을 굴릴 수 있습니다. 대신 데이터를 보내야 하니 프라이버시와 통신 지연 문제가 있습니다.
각각 약점이 분명하니, 자연스러운 결론은 둘을 협력시키는 하이브리드입니다. 쉬운 질문은 폰의 작은 모델이 바로 처리하고, 어려운 질문만 클라우드의 거대 모델로 넘기는 거죠. 대부분은 로컬에서 빠르고 안전하게 풀고, 특별한 경우(폰이 답을 못 내거나 배터리가 위급할 때)만 선택적으로 클라우드를 부릅니다.
여기서 진짜 어려운 문제는 “언제 클라우드로 넘길지"를 어떻게 판단하느냐입니다. 폰 모델의 답을 일일이 검토해서 틀렸을 때 넘기는 건 비현실적입니다. 검토할 시간이면 처음부터 클라우드로 보내는 게 나으니까요. 게다가 폰 모델이 그럴듯하게 지어낸 답(hallucination)은 알아채기도 어렵습니다.
그래서 최근 연구의 핵심 아이디어는 폰 모델이 스스로 “이건 제가 모르겠어요, 도움이 필요해요"라고 말하도록 학습시키는 겁니다. 풀 수 있는 문제는 바로 답하고, 못 푸는 문제는 도움 요청 신호를 내보내도록요. 강화학습 기반 라우팅(어느 질문을 어디로 보낼지 지연/비용/품질을 보고 결정), 협력적 추론 학습 같은 방법들이 이 방향에서 연구되고 있습니다. 이 구도는 후보가 둘(폰/클라우드)인 단순 라우팅에서, 여러 LLM 에이전트 중 적임자를 고르는 멀티 에이전트 라우팅으로도 확장되고 있습니다.
I. 마무리: 두 축으로 기억하기
긴 여정이었습니다. 흩어진 데이터로 모델을 학습하는 법(연합학습)부터, 그 모델을 서비스하는 법(분산 추론)까지 달려왔습니다. 복잡해 보이지만 사실 모든 내용은 두 개의 축으로 깔끔하게 정리됩니다.
첫 번째 축: 효율성 vs 강건성. 빠르고 싸게 하려는 욕심(비동기, 일부만 기다리기, gradient 압축)과, 정확하고 안전하게 하려는 욕심(Geometric Median, DP, Secure Aggregation)은 끊임없이 충돌합니다. 빠른 학습은 어떤 형태로든 비용을 치릅니다. 데이터를 버리거나, 신선도가 떨어지거나, 보호가 약해지거나. 정답은 하나가 아니라 상황에 따라 균형점을 고르는 겁니다.
두 번째 축: 학습 vs 추론. “어떻게 잘 배울까"와 “배운 걸 어떻게 잘 써먹을까"는 다른 문제입니다. 학습에서 좋았던 기법이 추론에서도 좋다는 보장은 없습니다. DeepSeek-V3가 학습엔 텐서 병렬화를 빼고 추론엔 넣은 게 그 증거죠.
초보자가 이 글에서 딱 세 가지만 가져간다면 이걸 권합니다.
연합학습은 “데이터 대신 모델을 주고받는” 발상입니다. 하지만 데이터가 사람마다 편향되는 non-IID 문제(Client Drift)와, gradient만으로도 원본이 새는 프라이버시 문제 때문에, 그냥 평균만 내서는 부족합니다.
현실의 분산 학습은 “느린 기기(straggler)“와 “악의적 기기(adversary)“라는 두 적과 싸웁니다. 그리고 이 둘을 동시에 막는 열쇠는 신선도 기반 그룹화(옵션 3)였습니다. 여러 모델을 그룹으로 묶어야 비로소 튼튼한 집계를 적용할 수 있으니까요.
추론에는 특별한 신기술이 없습니다. 학습에서 쓰던 병렬화를 워크로드(prefill인지 decode인지)에 맞게 재조합하는 게 핵심이고, 폰과 클라우드를 협력시키는 하이브리드가 앞으로의 방향입니다.
스마트폰 키보드가 제 입력을 안 보내고도 똑똑해지는 비밀이, 사실은 이렇게 많은 고민의 결과였던 셈입니다.
References
- McMahan et al., “Communication-Efficient Learning of Deep Networks from Decentralized Data” (FedAvg), AISTATS 2017. https://arxiv.org/abs/1602.05629
- Li et al., “Federated Optimization in Heterogeneous Networks” (FedProx), MLSys 2020. https://arxiv.org/abs/1812.06127
- Karimireddy et al., “SCAFFOLD: Stochastic Controlled Averaging for Federated Learning”, ICML 2020. https://arxiv.org/abs/1910.06378
- Li et al., “Ditto: Fair and Robust Federated Learning Through Personalization”, ICML 2021. https://arxiv.org/abs/2012.04221
- Collins et al., “Exploiting Shared Representations for Personalized Federated Learning” (FedRep), ICML 2021. https://arxiv.org/abs/2102.07078
- Zhu et al., “Deep Leakage from Gradients”, NeurIPS 2019. https://arxiv.org/abs/1906.08935
- Wei et al., “Federated Learning with Differential Privacy: Algorithms and Performance Analysis”, IEEE TIFS 2020. https://doi.org/10.1109/TIFS.2020.2988575
- Bonawitz et al., “Practical Secure Aggregation for Privacy-Preserving Machine Learning”, ACM CCS 2017. https://doi.org/10.1145/3133956.3133982
- Blanchard et al., “Machine Learning with Adversaries: Byzantine Tolerant Gradient Descent” (Krum), NeurIPS 2017. https://papers.nips.cc/paper/2017/hash/f4b9ec30ad9f68f89b29639786cb62ef-Abstract.html
- Pillutla et al., “Robust Aggregation for Federated Learning” (RFA / Geometric Median), IEEE Transactions on Signal Processing 2022. https://arxiv.org/abs/1912.13445
- Park et al., “Sageflow: Robust Federated Learning against Both Stragglers and Adversaries”, NeurIPS 2021. https://proceedings.neurips.cc/paper/2021/hash/076a8133735eb5d7552dc195b125a454-Abstract.html
- Chai et al., “TiFL: A Tier-based Federated Learning System”, HPDC 2020. https://arxiv.org/abs/2001.09249
- DeepSeek-AI, “DeepSeek-V3 Technical Report”, 2024. https://arxiv.org/abs/2412.19437
- “Improving Gboard language models via private federated analytics”, Google Research, 2024. https://research.google/blog/improving-gboard-language-models-via-private-federated-analytics/