
두 갈래의 흐름이 한 점에서 만나는 그림
최근 음성 AI 흐름을 따라가다 보니, 지난 몇 년의 발전이 서로 다른 두 갈래로 갈라졌다가 다시 한 점에서 합쳐진다는 인상을 받았습니다. 한쪽은 음성을 이해하기입니다. 라벨 하나 없이 원시 파형만 잔뜩 넣어두고, 그 안에 숨어 있는 구조를 모델이 스스로 찾아내게 만드는 표현 학습(self-supervised learning)이죠. 다른 한쪽은 음성을 만들기입니다. 텍스트를 받아 사람 같은 목소리를 합성하는 TTS(text-to-speech)의 진화입니다.
흥미로운 점은 이 둘이 끝에서 만난다는 것입니다. 표현 학습이 만들어낸 “음성을 이산 토큰으로 자르는 기술"과, 합성 쪽이 키워온 “임의 화자의 목소리를 모사하는 능력"이 결합해, 학습 때 본 적 없는 사람의 5–10초짜리 음성만으로 그 목소리로 아무 문장이나 읽어주는 zero-shot voice cloning이 가능해졌습니다.
여러 자료를 종합해서 흐름을 정리해본다는 마음으로, 두 갈래가 각각 어떻게 발전했고 왜 그렇게 설계됐는지를, 그리고 마지막에 어디서 합류하는지를 풀어보려 합니다. 수식도 몇 개 등장하지만 “이 항이 왜 여기 있는가"라는 질문을 중심에 둡니다.
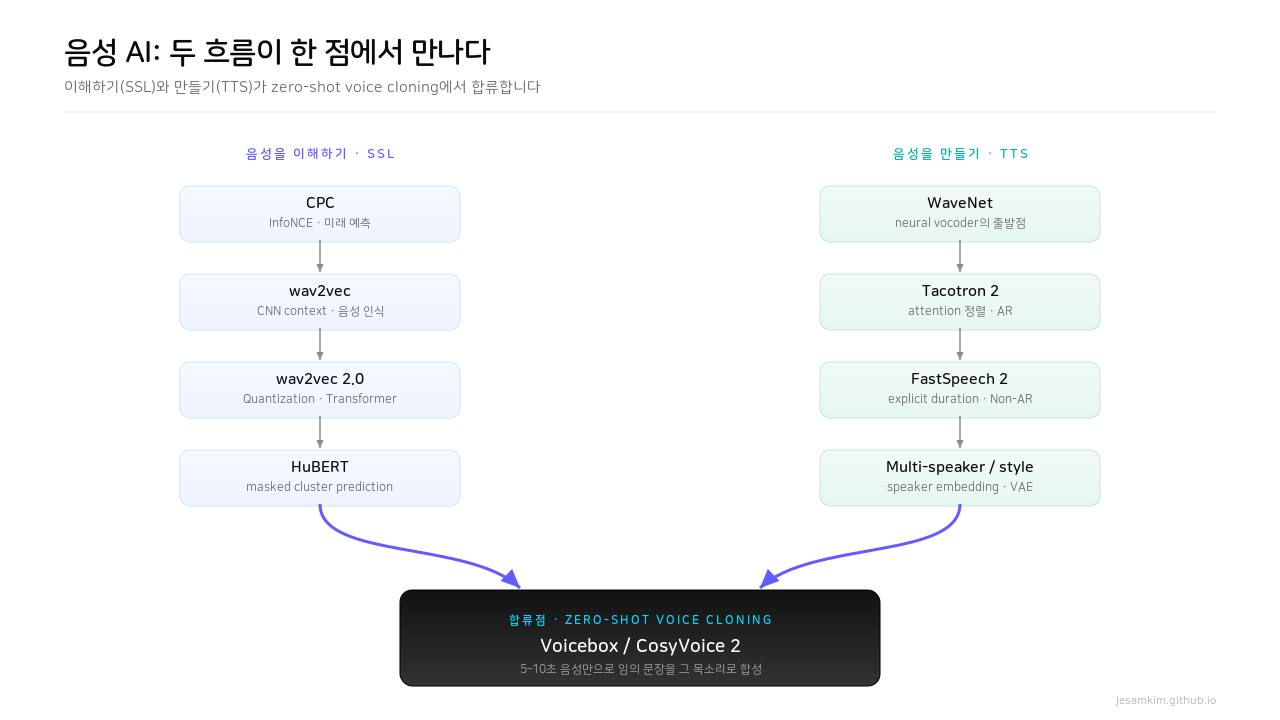 Figure 1. 음성을 이해하는 SSL 흐름과 음성을 만드는 TTS 흐름이 zero-shot voice cloning에서 한 점으로 합쳐집니다.
Figure 1. 음성을 이해하는 SSL 흐름과 음성을 만드는 TTS 흐름이 zero-shot voice cloning에서 한 점으로 합쳐집니다.
Part 1. 음성을 이해하기 — Self-Supervised Speech Representation
왜 음성은 유독 어려운가
텍스트에서는 BERT가, 이미지에서는 여러 대조 학습 모델이 일찌감치 자리를 잡았는데, 음성에서 “이게 표준이다” 싶은 단일 모델이 늦게 나온 데에는 이유가 있습니다. 음성 신호가 가진 네 가지 성질 때문입니다.
- 가변 길이: 발화마다 길이가 다릅니다.
- 경계 없는 긴 시퀀스: 텍스트처럼 단어나 음소 사이에 명시적 구분선이 없습니다. 소리는 그냥 이어집니다.
- 연속 신호: 텍스트 토큰은 이산적이지만 목소리는 연속적인 파형입니다.
- 제각각인 downstream task: 음성 인식, 합성, 화자 인식, 감정 인식까지 쓰임새가 폭넓습니다.
특히 세 번째가 결정적입니다. 언어 모델의 토큰은 정수 인덱스로 떨어지는데, 목소리는 항상 연속적인 파형이라 같은 틀에 바로 넣을 수가 없습니다. 그래서 “연속적인 음성을 어떻게 잘 잘라서 이산적으로 만들 것인가"가 이 분야의 오랜 난제였고, 뒤에서 볼 quantization이 바로 그 답입니다.
SSL 접근은 크게 둘로 나뉩니다. positive와 negative 쌍을 구별하며 배우는 contrastive 계열(CPC, wav2vec, wav2vec 2.0), 그리고 가려진 구간을 맞히며 배우는 predictive 계열(HuBERT, WavLM)입니다. 2019–2020년에는 contrastive가 주도했고, 이후 무게중심이 predictive로 옮겨갔습니다. 왜 그렇게 됐는지를 순서대로 따라가 봅니다.
CPC (2018) — contrastive의 출발점
Contrastive 학습의 직관은 의외로 쉽습니다. 오지선다 문제를 푸는 것과 같습니다. 기준이 되는 표현(anchor)이 있고, 정답에 해당하는 positive 샘플 하나와 오답에 해당하는 negative 샘플 여럿이 섞여 있을 때, 정답을 골라낼 확률은 높이고 오답을 고를 확률은 낮추도록 학습합니다. 레이블 없이도 데이터 안의 구조만으로 “무엇이 비슷하고 무엇이 다른가"를 배우는 셈이죠. 음성에서는 “이어진 프레임은 비슷하고, 무관한 구간은 다르다"는 시간적 구조를 활용합니다.
Contrastive Predictive Coding(CPC)은 이 아이디어를 음성·이미지·텍스트·강화학습에 두루 적용한 첫 사례입니다. 핵심은 생성 모델을 쓰지 않았다는 점입니다. 입력 x로부터 무언가를 직접 복원하려 들면 x의 풍부한 저수준 세부사항까지 다 재구성해야 해서 낭비가 큽니다. 대신 CPC는 현재 컨텍스트와 미래 표현 사이의 상호정보량(mutual information)을 최대한 보존하는 방향으로만 학습합니다.
 Figure 2. CPC는 파형을 압축하고(g_enc), 문맥을 요약한 뒤(g_ar), 미래 표현을 contrastive하게 맞히는 세 단계로 동작합니다.
Figure 2. CPC는 파형을 압축하고(g_enc), 문맥을 요약한 뒤(g_ar), 미래 표현을 contrastive하게 맞히는 세 단계로 동작합니다.
구조는 세 단계입니다.
- Compression: 인코더 genc(보통 strided 1D CNN)가 각 프레임 xt를 잠재 벡터 zt로 압축합니다. 16kHz 원시 파형을 받아 100Hz 해상도의 latent로 바꾸는데, receptive field가 약 30ms입니다. 흥미롭게도 이 단계는 mel-filterbank 같은 룰 기반 변환과 역할이 비슷합니다. 다만 FFT는 항상 같은 방식으로 뽑는 반면, CNN 인코더는 학습 가능하다는 점이 다릅니다.
- Autoregressive modeling: 30ms는 너무 짧습니다. “안녕하세요"의 한 음소도 채 안 들어가죠. 그래서 GRU 기반 gar이 과거 latent를 순차적으로 요약해 더 넓은 문맥을 담은 컨텍스트 벡터 ct를 만듭니다.
- Noise-Contrastive Estimation: ct로부터 미래의 zt+k를 예측합니다.
세 번째 단계의 손실이 그 유명한 InfoNCE입니다.
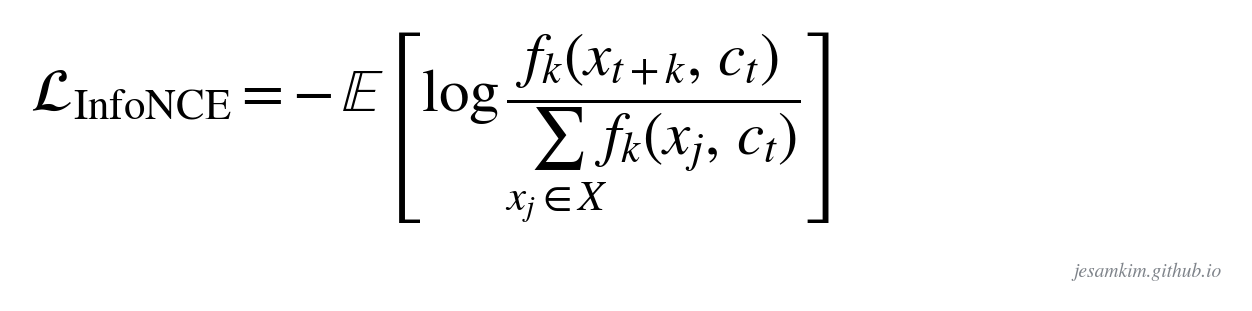
수식이 길어 보이지만 구조는 cross-entropy 그대로입니다. 분자는 정답(positive) 샘플의 점수, 분모는 전체 후보(정답 + 오답)의 점수 합입니다. 정답이 뽑힐 확률을 최대화하는 것이죠. 점수 함수는 fk(x, ct) = exp(zT Wk ct) 형태인데, 여기서 zT(Wk ct)는 내적입니다. self-attention과 같은 원리로, 내적 값이 크면 두 벡터의 상관관계가 높고 그만큼 확률이 커집니다. Wk는 “k 스텝 뒤를 추정하는 방향"을 학습하는 행렬이라, 예측 거리마다 다른 Wk를 씁니다.
수학적으로 InfoNCE를 최소화하는 것은 상호정보량을 최대화하는 것과 같다는 게 증명되어 있습니다(이름의 “Info"가 여기서 옵니다). 증명 자체보다는, “내적으로 유사도를 재고 positive는 올리고 negative는 내린다"는 물리적 의미를 잡는 게 더 중요하다고 봅니다. 뒤에 나오는 모델들은 손실이 계속 바뀌지만 이 표현 학습의 철학은 그대로 이어지거든요.
실험에서 CPC는 레이블 없이 사전학습만으로 LibriSpeech 화자 분류 정확도 97.4%를 찍어, 지도학습 상한(98.5%)에 거의 닿았습니다. 음소 분류는 64.6%로 상한과 10%포인트 정도 차이가 났고요. 화자 정보가 음소 정보보다 표현에 더 쉽게 인코딩된다는 뜻입니다. 예측 거리는 12 스텝(120ms)이 최적이었는데, 멀리 내다볼수록 모델이 국소적 잡음 대신 음소 같은 고수준 구조에 집중하게 된다는 점이 눈에 띄었습니다.
wav2vec (2019) — GRU를 CNN으로
wav2vec은 한 줄로 요약하면 “음성 인식을 위한 CPC"입니다. Facebook AI가 CPC 틀을 음성 인식에 직접 적용하면서 두 가지를 바꿨습니다.
첫째, 컨텍스트를 만드는 g를 GRU에서 Causal CNN으로 교체했습니다. 이유는 병렬화입니다. RNN은 과거 state를 순차적으로 기억하느라 한 시점씩만 처리할 수 있어 대규모 데이터 학습에 병목이 됩니다. CNN으로 바꾸면 고정 receptive field(약 210ms)를 병렬로 계산할 수 있죠. 당시는 RNN에서 CNN으로 넘어가던 시기였고, Transformer는 아직 음성 SSL에 들어오지 않았습니다.
둘째, 손실을 InfoNCE의 softmax 대신 binary cross-entropy로 바꿨습니다. 각 후보를 0이냐 1이냐로 독립 판정하는 방식인데, Word2Vec의 negative sampling과 같은 철학입니다. CPC가 “전체 후보를 동시에 비교하는 경쟁"이라면 wav2vec은 “개별 후보를 따로 판정하는 이진 퀴즈"인 셈입니다. 이 모델은 WSJ 테스트셋에서 WER 2.43%를 기록하며, 기존 character 기반 최고 모델 대비 100배 적은 전사 데이터로 같은 성능을 냈습니다.
wav2vec 2.0 (2020) — 세 조각의 통합
wav2vec 2.0은 그동안 따로 놀던 퍼즐 조각을 하나로 합쳤습니다. CPC의 contrastive loss, vq-wav2vec의 vector quantization, BERT의 masking과 Transformer 컨텍스트를 종단간(end-to-end)으로 묶은 것이죠. 결과만 보면, 1시간 레이블로 WER 1.8/3.3을 냈고 10분 레이블만으로도 기존 최고 성능에 도달했습니다.
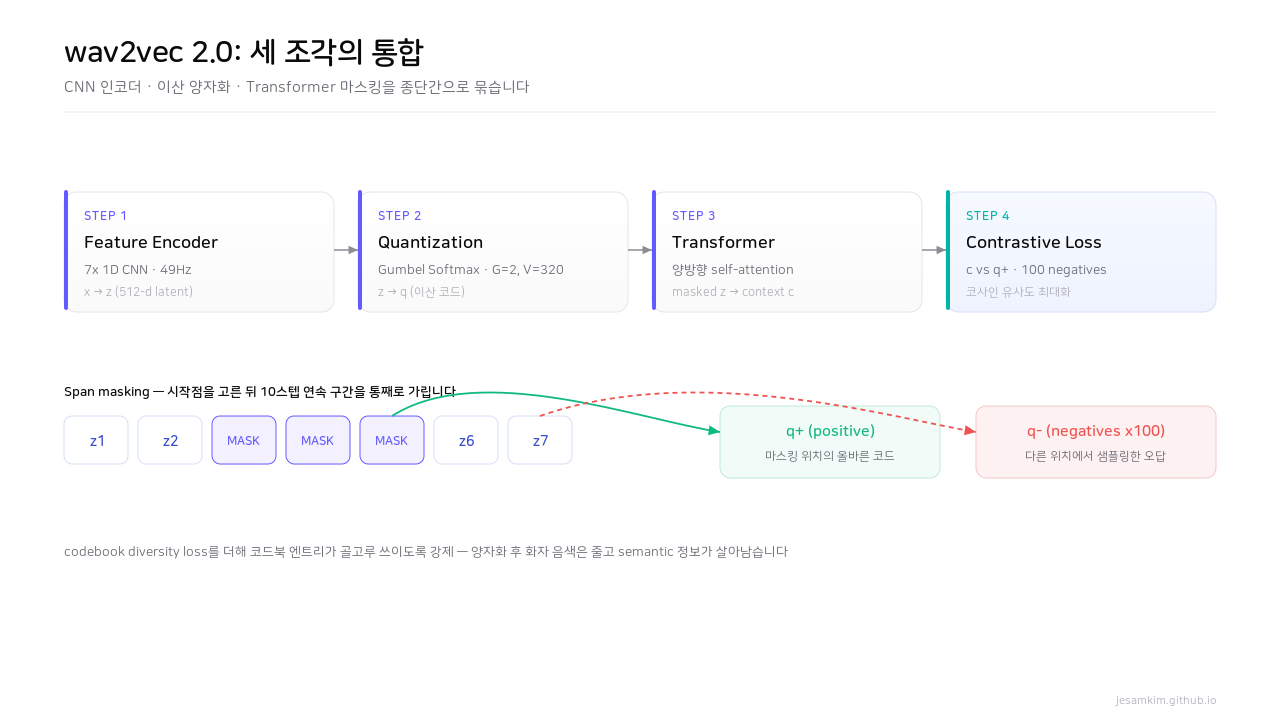 Figure 3. span masking으로 가린 위치의 context 벡터가 올바른 quantized 코드(q+)를 100개의 negative(q-) 사이에서 골라내도록 학습합니다.
Figure 3. span masking으로 가린 위치의 context 벡터가 올바른 quantized 코드(q+)를 100개의 negative(q-) 사이에서 골라내도록 학습합니다.
파이프라인은 네 단계입니다.
Step 1 — Feature Encoder. 7개 1D convolution 블록이 원시 파형을 512차원 latent로 바꿉니다. 추출률은 49Hz입니다. CPC/wav2vec의 100Hz에서 절반으로 낮춘 건데, 1초 음성을 50개 프레임으로만 표현해도 충분하다는 판단입니다. 뒤에 강력한 Transformer가 붙으니 저해상도 latent로도 되고, 시퀀스가 짧아지면 self-attention의 O(n2) 비용이 4분의 1로 줄어듭니다. 음소 길이(약 50ms)에도 더 잘 맞고요.
Step 2 — Quantization. 여기가 음성을 BERT처럼 다루게 만든 핵심 장치입니다. 연속 latent z를 이산 코드 q로 바꿉니다. 16비트 PCM이 진폭을 65,536개 경우의 수로 양자화하듯, wav2vec 2.0은 product quantization으로 음성을 이산화합니다. 코드북을 G=2개 그룹으로 나누고 각 그룹에 V=320개 엔트리를 두면 320 × 320 = 102,400개의 고유한 이산 단위를 표현할 수 있습니다. 늘 연속적이던 음성이 유한 개의 이산 표현으로 바뀌는 순간입니다.
문제는 이산화가 미분 불가능하다는 점입니다. 코드를 고르는 순간 gradient 흐름이 끊겨 모델을 업데이트할 수 없습니다. 그래서 Gumbel Softmax를 씁니다.
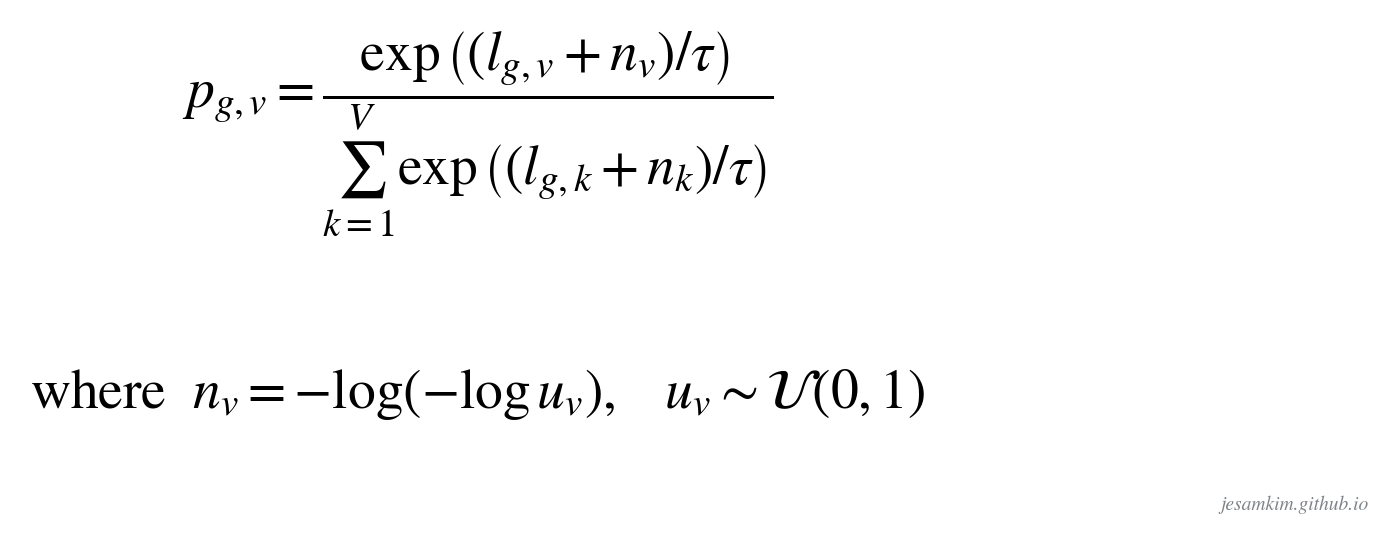
logit에 Gumbel noise nv를 더하고 temperature τ로 나눠 softmax를 취합니다. 학습 시에는 soft한 확률 분포로 미분 가능하게 흘려보내고, 추론 시에는 확률이 가장 높은 곳에 1을 주는 진짜 이산 선택을 합니다. “확률적으로 여기에 비트를 주는 게 제일 좋겠다"를 배운 다음, 실제로는 가장 그럴듯한 자리를 결정론적으로 고르는 구조입니다. 이 트릭은 neural audio codec 분야 전반의 표준이기도 합니다.
Step 3 — Transformer Context. CPC의 GRU나 wav2vec의 Causal CNN은 과거만 보지만, Transformer는 양방향 self-attention으로 전체 시퀀스 문맥을 봅니다. BERT 스타일 masked prediction과 자연스럽게 맞물리죠. 위치 정보는 sinusoidal 대신 학습 가능한 1D convolution으로 줍니다.
Step 4 — Contrastive Loss with Masking. 마스킹 방식이 BERT와 다릅니다. BERT는 토큰 15%를 랜덤하게 가리지만, 음성에서 한 프레임만 가리면 인접 프레임이 거의 같은 음소라 너무 쉽게 풀립니다. 그래서 시작점을 p=0.065 확률로 고른 뒤 10스텝 연속 구간을 통째로 가립니다(span masking). 실제로는 전체의 약 50%가 마스킹됩니다. 모델은 마스킹된 위치의 context 벡터 ct와 올바른 quantized 벡터 qt의 코사인 유사도를, 100개 negative 사이에서 가장 높게 만들도록 학습합니다.
여기에 codebook diversity loss를 더합니다. 모든 데이터가 단일 코드북 엔트리로 쏠리면 “실패한 양자화"가 되기 때문에, 코드북 사용 분포의 엔트로피를 최대화해 엔트리들이 골고루 쓰이게 강제합니다. 양자화의 부수 효과도 알아둘 만합니다. 양자화를 거치면 화자 음색 정보는 상당히 날아가고 텍스트 관련 semantic 정보가 잘 살아남습니다. wav2vec 2.0이 음성 인식에 특히 강한 이유죠.
세 모델을 한 표로 정리하면 변화의 축이 분명해집니다.
| 속성 | CPC (2018) | wav2vec (2019) | wav2vec 2.0 (2020) |
|---|---|---|---|
| 핵심 혁신 | InfoNCE loss | 음성 인식 적용 | 종단간 통합 |
| 학습 목표 | 미래 예측 | 미래 예측 | masked span 예측 |
| 표현 | 연속 | 연속 | 연속 입력 / 이산 출력 |
| 컨텍스트 모델 | GRU | CNN | Transformer |
| Frame rate | 100Hz | 100Hz | 49Hz |
손실은 softmax NCE에서 binary NCE를 거쳐 masked contrastive로, 컨텍스트는 GRU에서 CNN을 거쳐 Transformer로, 표현은 연속에서 연속+이산으로 옮겨왔습니다. CPC가 “미래 예측"이라는 자기회귀적 사고를 가져왔다면, wav2vec 2.0은 BERT식 “masked prediction"으로 전환했습니다. 이 전환이 다음 주인공인 HuBERT의 발판이 됩니다.
HuBERT — contrastive에서 predictive로
HuBERT(Hidden-Unit BERT)는 제가 개인적으로 가장 흥미롭게 본 모델입니다. 설계 전체가 “음성 표현 학습이 어려운 세 가지 이유"와 1대 1로 대응되도록 짜여 있거든요.
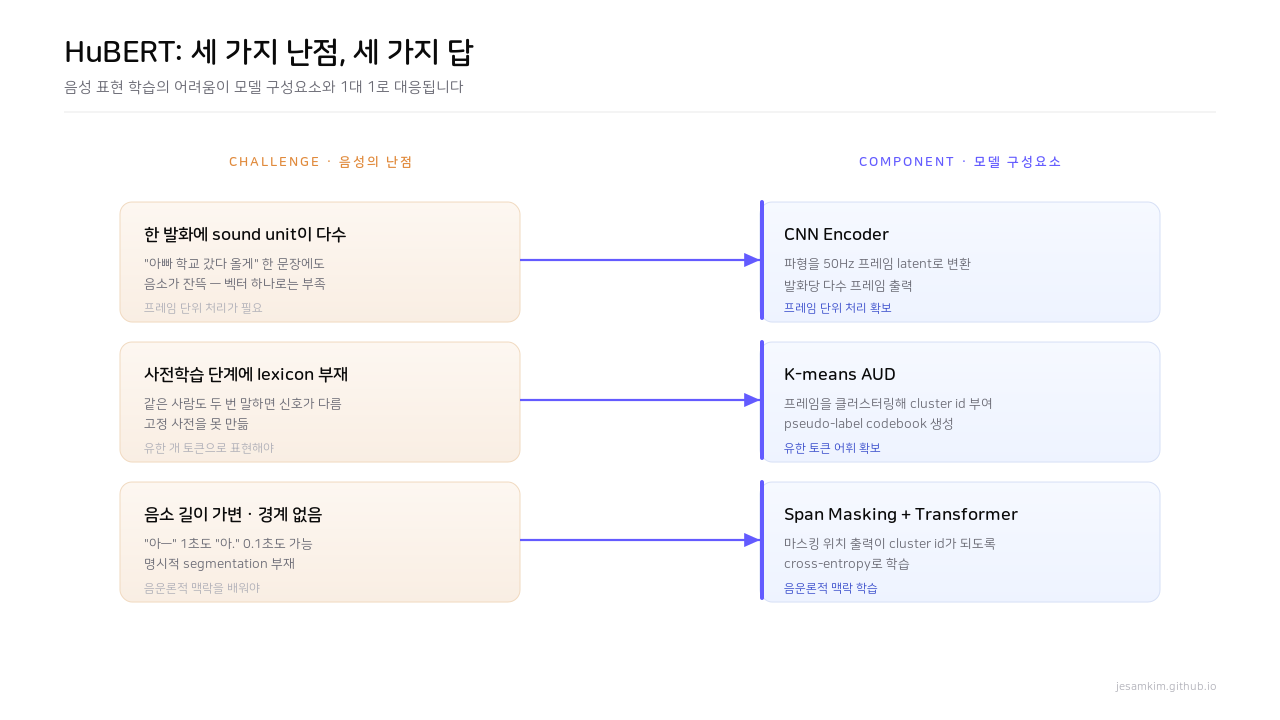 Figure 4. HuBERT의 세 구성요소는 음성 표현 학습이 어려운 세 가지 이유와 1대 1로 대응됩니다.
Figure 4. HuBERT의 세 구성요소는 음성 표현 학습이 어려운 세 가지 이유와 1대 1로 대응됩니다.
세 가지 난점과 그 답은 이렇습니다.
- 한 발화에 여러 sound unit이 있다 → 프레임 단위로 처리해야 한다 → CNN encoder(50Hz). “아빠 학교 갔다 올게” 한 문장에도 음소가 잔뜩 들어 있으니, 한 발화에서 벡터 하나만 뽑는 옛날 방식(autoencoder, 화자 임베딩)으로는 안 됩니다.
- 사전학습 단계에 lexicon이 없다 → 음성을 유한 개 토큰으로 표현해야 한다 → K-means clustering. 텍스트는 BPE로 몇 만 토큰이면 거의 모든 조합을 표현하지만, 음성은 사람마다, 심지어 같은 사람이 두 번 말해도 신호가 다릅니다. 고정 사전을 못 만들죠. 그래서 제각기 다른 “안녕하세요"를 그룹핑해 그룹 ID를 부여하는 양자화 문제로 귀결됩니다.
- 음소 길이가 가변이고 명시적 경계가 없다 → 음운론적 맥락을 배워야 한다 → span masking + Transformer. “아—“를 1초 길게 낼 수도, “아.“를 0.1초로 짧게 낼 수도 있으니까요.
전체 흐름은 이렇습니다. CNN이 파형을 50Hz 프레임 latent로 바꾸고, 일부 프레임을 [MSK]로 가립니다. 별도 경로로 K-means가 모든 프레임에 cluster id를 pseudo-label로 부여하고, Transformer는 마스킹된 위치의 출력이 그 cluster id가 되도록 cross-entropy로 학습합니다.
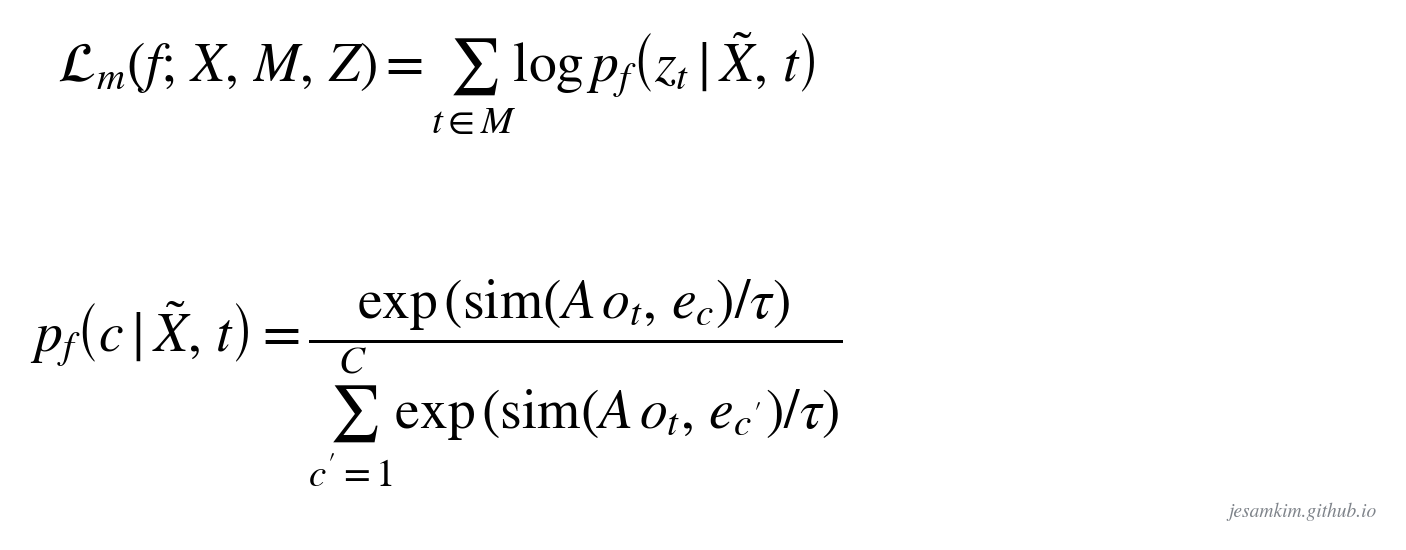
손실은 마스킹 구간 M에서만 계산하는 cross-entropy입니다. 확률은 Transformer 출력 ot를 projection한 것과 codeword embedding ec의 scaled cosine similarity로 정의합니다. wav2vec 2.0의 InfoNCE와 결정적으로 다른 점은, 분모가 negative 샘플의 합이 아니라 “전체 코드북 사전"의 합이라는 것입니다. negative sampling 자체가 사라지고 “어휘에 대한 다중 분류"로 단순해진 셈이죠. codeword embedding ec가 학습 가능한 파라미터라, 모델이 cluster의 의미까지 함께 배우도록 cosine similarity를 씁니다.
HuBERT에는 두 가지 영리한 장치가 더 있습니다.
Cluster ensemble. K-means 코드북을 50개로 할지 100개로 할지 500개로 할지, 정답을 모릅니다. 그래서 여러 크기를 동시에 씁니다. 작은 코드북은 모음/자음 같은 큰 범주를 깔끔하게, 큰 코드북은 톤·피치·세부 발음까지 잡습니다. 게다가 여러 K-means를 앙상블하면 단일 모델의 오분류(noise)는 평균에서 사라지고, 공통적으로 중요한 정보만 남습니다.
Iterative refinement. 1차에서는 MFCC(39차)에 K-means를 걸어 pseudo-label을 만듭니다. 그런데 1차 학습이 끝난 HuBERT의 6번째 Transformer layer hidden state(768차)는 phonetic 정보를 일부 담고 있습니다. 그래서 2차에서는 이 hidden state에 다시 K-means를 걸어 더 나은 target을 만듭니다. PNMI(phone-normalized mutual information) 지표로 보면, MFCC 코드북 대비 1차 hidden state로 갈 때 품질이 2배 이상 뛰었습니다. 0번째 layer는 음향 정보에 치우치고 12번째는 너무 추상화되는데, 6–7번째가 “raw와 phonetic 사이의 sweet spot"이라는 게 실험적으로 확인됐습니다. 이 자기부트스트래핑이 “pretext task의 디테일보다 teacher(cluster)의 품질이 더 중요하다"는 논문 주장의 근거입니다.
왜 predictive가 이겼나
contrastive와 predictive의 차이를 한 문장으로 줄이면, HuBERT는 wav2vec 2.0의 아키텍처를 거의 그대로 쓰되 contrastive loss를 “외부 K-means cluster id에 대한 cross-entropy"로 바꾼 모델입니다. negative sampling을 없애고 BERT식 masked prediction을 음성에 정착시킨 것이죠. 여기서 target을 모델 바깥(K-means)에서 계산한다는 점이 predictive의 정의입니다. gradient가 target으로 흘러들어가지 않으니까요.
실무에서 이 모델들이 중요한 건 오픈소스 토크나이저로서의 가치 때문입니다. HuBERT나 WavLM은 무거워서 새로 SSL 사전학습을 하기는 부담스럽지만, 이미 잘 만들어진 모델을 가져와 task에 맞게 양자화/튜닝해서 쓰는 건 매우 활발합니다. 12개 Transformer layer가 layer마다 다른 정보(발음·화자·운율·감정)를 담고 있어서, downstream task에 따라 어느 layer를 꺼내 쓸지가 관건이 됩니다. 이 “음성을 의미 있는 이산 토큰으로 바꾸는 능력"이 바로 Part 3에서 합류 지점의 한 축이 됩니다.
Part 2. 음성을 만들기 — Neural TTS의 진화
왜 두 단계로 나눴나
딥러닝 기반 TTS는 보통 두 모델로 나뉩니다. Acoustic Model이 텍스트에서 mel-spectrogram 같은 음향 파라미터를 만들고, Vocoding Model이 그 음향 파라미터를 실제 파형으로 바꿉니다.
굳이 나눈 이유는 mel-spectrogram이라는 중간 표현이 편리하기 때문입니다. 음성을 주파수 축으로 바꾸고 mel-filterbank를 씌우면 formant와 F0(기본 주파수) 구조가 또렷이 드러나고, 사람 청각 특성에 맞게 압축돼 모델이 다루기 쉬워집니다. 다만 mel-spectrogram은 magnitude 정보만 담고 phase가 없어서, 역변환만으로는 음성을 복원할 수 없습니다. 과거에는 이래서 분석(음성 인식 등)에만 쓰였는데, neural vocoder가 등장하면서 mel에서 직접 고품질 파형을 만들어내게 됐습니다.
Neural Vocoder — WaveNet에서 GAN까지
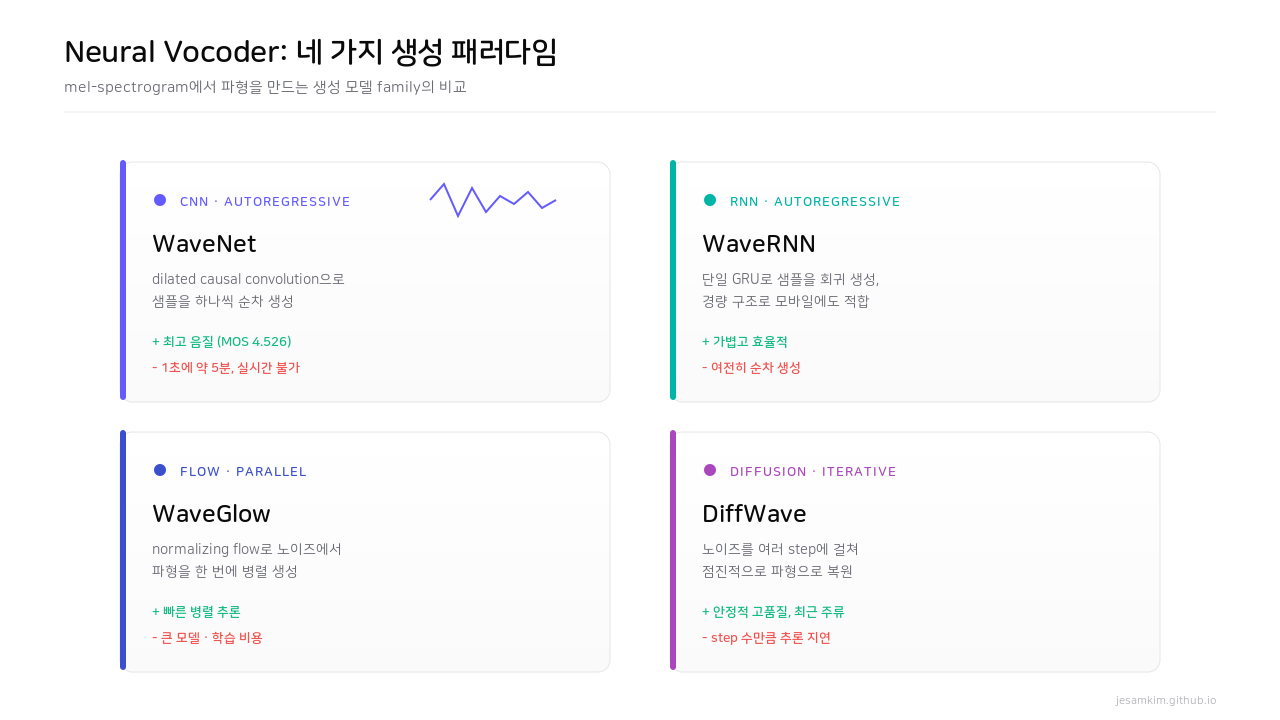 Figure 5. 보코더는 어떤 생성 모델 family를 쓰느냐로 갈립니다. autoregressive 계열은 품질이 높지만 느리고, flow/diffusion 계열은 병렬·반복 생성으로 속도를 확보합니다.
Figure 5. 보코더는 어떤 생성 모델 family를 쓰느냐로 갈립니다. autoregressive 계열은 품질이 높지만 느리고, flow/diffusion 계열은 병렬·반복 생성으로 속도를 확보합니다.
보코더는 어떤 생성 모델 family를 쓰느냐로 갈립니다. RNN 기반 WaveRNN, normalizing flow 기반 WaveGlow, diffusion 기반 DiffWave가 있지만, 출발점이자 가장 중요한 건 CNN 기반 WaveNet(2016)입니다.
WaveNet은 이전 샘플들에 조건부로 다음 샘플을 예측하는 autoregressive 모델입니다. 연속 파형 값을 직접 회귀하는 대신, mu-law companding으로 256개 레벨로 양자화해 회귀를 분류 문제로 바꿨습니다. 핵심 장치는 dilated causal convolution입니다. dilation을 1, 2, 4, 8로 지수적으로 키우면 적은 레이어로도 긴 receptive field를 확보하면서 인과성(미래를 안 봄)을 지킬 수 있습니다. 여기에 tanh × sigmoid의 gated activation으로 정보 흐름을 제어하고, residual·skip connection으로 깊은 학습을 안정화하며, mel-spectrogram을 조건으로 주입하면 TTS 보코더가 됩니다.
Tacotron 2 실험에서 WaveNet 보코더는 MOS 4.526으로 ground truth(4.582)에 바짝 붙었습니다. receptive field가 클수록 음질이 좋아진다는 것도 표로 확인됐고요(255ms일 때 4.526, 2.5ms일 때 3.819). 문제는 속도입니다. 16kHz면 1초에 16,000개 샘플을 하나씩 순차 생성해야 해서, 1초 오디오에 약 5분이 걸립니다. 실시간은 불가능하죠.
그래서 Parallel WaveNet이 나왔습니다. probability density distillation으로, 미리 학습한 autoregressive teacher의 분포를 non-autoregressive student가 따라 배우게 합니다. student는 랜덤 노이즈만 받아 병렬로 생성하니 1초 오디오를 0.02초에 만듭니다. 다만 teacher-student 분포 매칭 학습이 까다롭다는 게 발목을 잡았습니다.
이 학습 난이도를 깔끔하게 푼 게 Parallel WaveGAN입니다. 세 가지를 바꿨습니다. 첫째, distillation을 제거하고, 둘째, adversarial training(LSGAN 형태)을 도입했으며, 셋째, multi-resolution STFT loss를 더했습니다. 마지막이 특히 똑똑합니다. STFT는 FFT/window/shift 조합에 따라 시간 해상도와 주파수 해상도가 트레이드오프되는데, 한 가지 해상도만 쓰면 어느 한쪽을 놓칩니다. 그래서 여러 해상도의 STFT loss를 평균 냅니다. 각 해상도에서는 큰 에너지 성분(formant)에 민감한 spectral convergence loss와 작은 에너지 성분(unvoiced)까지 챙기는 log magnitude loss를 함께 써서 스펙트럼 전 영역을 균형 있게 학습합니다.
결과적으로 Parallel WaveGAN은 1.44M 파라미터로 teacher WaveNet과 동급 MOS(4.16)를 내면서 학습 시간은 절반 이하로 줄였습니다. 1초 생성 기준 WaveNet의 5분 vs 0.02초, 약 15,000배 차이입니다. 이후 HiFi-GAN, BigVGAN 같은 후속 GAN 보코더가 production TTS의 표준으로 자리 잡았습니다.
Acoustic Model — Tacotron 2와 FastSpeech 2
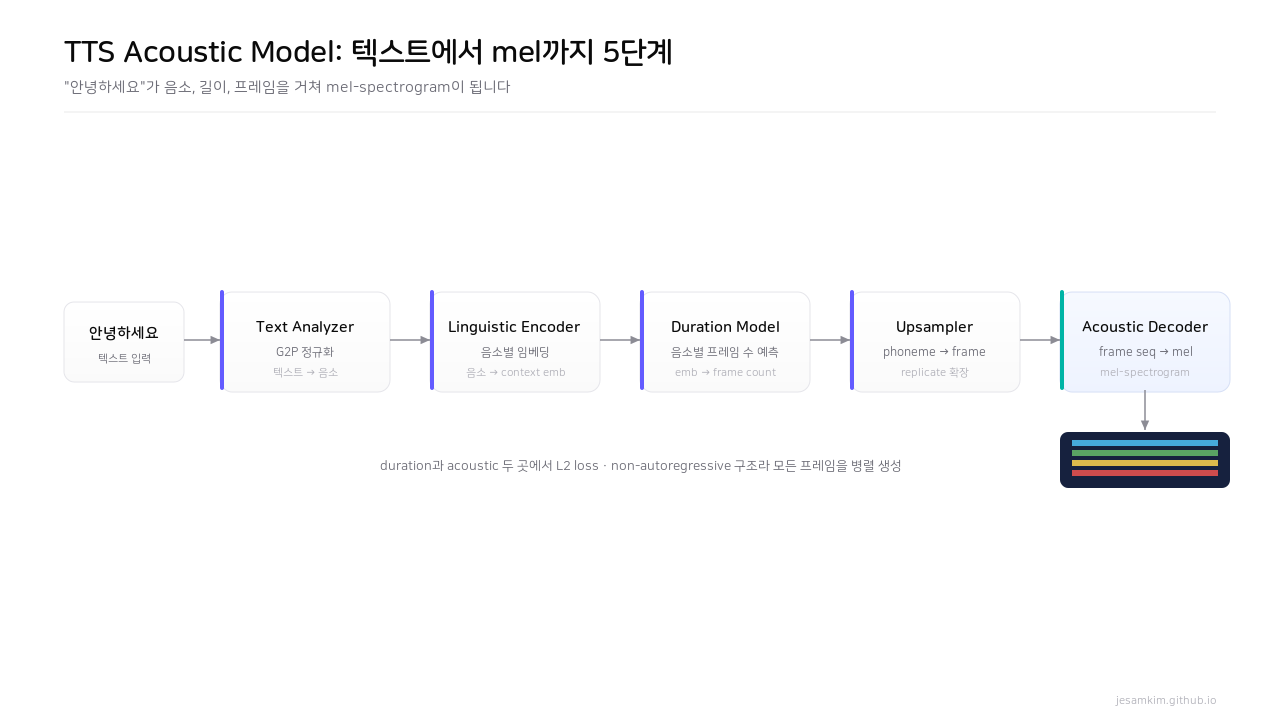 Figure 6. Acoustic Model은 텍스트를 음소로 바꾸고, 음소별 길이를 예측해 프레임으로 확장한 뒤 mel-spectrogram을 만드는 다섯 단계를 거칩니다.
Figure 6. Acoustic Model은 텍스트를 음소로 바꾸고, 음소별 길이를 예측해 프레임으로 확장한 뒤 mel-spectrogram을 만드는 다섯 단계를 거칩니다.
Acoustic Model의 표준 구조는 다섯 단계입니다. Text Analyzer가 텍스트를 음소열로 바꾸고(숫자·약어·기호를 발음으로 정규화하는 작은 frontend 시스템입니다. 신규 언어 진입 시 G2P 모듈 확보가 첫 관문이죠), Linguistic Encoder가 음소별 context embedding을 만들고, Duration Model이 각 음소가 몇 프레임을 차지할지 예측하고, Upsampler가 phoneme-level을 frame-level로 확장하고, Acoustic Decoder가 mel-spectrogram을 만듭니다. duration과 acoustic 두 곳에서 L2 loss를 씁니다. 이 구조는 non-autoregressive라 모든 프레임을 병렬 생성할 수 있어 빠릅니다.
이 표준에서 갈라진 두 모델이 대조적입니다.
Tacotron 2는 autoregressive 방식의 정점입니다. 명시적 duration model 대신 Location Sensitive Attention으로 텍스트와 mel 사이를 정렬합니다. 텍스트와 음성은 본질적으로 순서가 같으니(앞 단어를 뒤에 읽지 않으니) monotonic alignment를 유도하는 거죠. autoregressive decoder가 이전 프레임을 다음 입력으로 써서 품질은 ground truth급(MOS 4.526)이지만, 두 가지 약점이 있습니다. RNN+autoregressive라 학습·추론이 모두 순차적이고, attention 기반 정렬이 hallucination에 취약합니다. “일, 이, 삼, 사, 오, 육, 칠, 팔"을 “일, 일, 일, 일, 이, 삼…“으로 반복하거나, 순서가 뒤집히거나, stop token을 잘못 잡아 일찍 끝나버리는 식입니다. 기술적으로는 뛰어났지만 안정성 때문에 현업 적용이 까다로웠습니다.
FastSpeech 2는 다시 non-autoregressive로 돌아갑니다. 비싸더라도 forced alignment로 얻은 phoneme segmentation을 직접 써서 explicit duration model로 hallucination을 차단합니다. FastSpeech 1이 autoregressive teacher의 attention map을 distillation해서 duration을 얻었던 것과 달리, FastSpeech 2는 teacher를 제거하고 ground-truth duration으로 직접 학습합니다. teacher-student는 student가 teacher를 넘을 수 없는 upper bound 문제가 있었거든요. 대신 Variance Adaptor로 duration·pitch·energy를 conditional input으로 더해 controllability를 확보합니다. 실무에서는 duration과 pitch predictor를 많이 쓰고, energy는 볼륨이라 그냥 후처리로 조정하는 편이라 잘 안 씁니다.
재미있는 건 실제 산업에서 둘을 섞는다는 점입니다. FastSpeech 2 encoder + Variance Adaptor로 빠른 phoneme 처리와 controllability를 잡고, Tacotron 2 decoder의 autoregressive 품질을 가져오는 하이브리드를 씁니다. Tacotron 2의 attention hallucination은 FastSpeech 2의 explicit duration model로 timing을 못 박아 해결하고, 디코더 품질은 그대로 유지하는 식이죠.
화자와 스타일을 입히기
목소리 하나를 잘 만드는 데서 나아가, “누구의 목소리인가"와 “어떤 방식으로 말하는가"를 제어하는 단계로 넘어갑니다.
Multi-speaker. 모듈마다 역할을 나눕니다. Linguistic Encoder는 화자와 무관한 콘텐츠(speaker-independent)를 담고, Acoustic Decoder(음색)와 Duration Model(운율)은 speaker embedding을 주입받아 화자별로 조건화됩니다(speaker-dependent). embedding을 만드는 영리한 방법은 사전학습된 speaker recognition 모델을 쓰는 것입니다. 화자 분류를 학습하면 hidden representation이 자연스럽게 화자 특성을 인코딩하는데(t-SNE로 보면 화자별·성별로 클러스터가 갈립니다), 새 화자의 짧은 음성만 넣어 embedding을 뽑으면 TTS 전체를 다시 학습하지 않고도 화자를 추가할 수 있습니다. 일종의 zero-shot 화자죠. 데이터가 충분하면 single-speaker 품질이 더 좋지만, 화자가 많은 실제 서비스에서는 모델 하나에 embedding만 바꿔 끼우는 multi-speaker가 메모리·녹음 비용 면에서 크게 유리합니다.
Multi-style. 감정·운율 스타일을 제어하려면 VAE 기반 Style Encoder를 씁니다. 참조 음성을 받아 평균 벡터 μ와 분산 벡터 σ2를 내고, reparameterization trick으로 latent z를 샘플링해 디코더에 주입합니다. 흥미로운 건 감정 레이블 없이 학습해도 latent space에 Sad/Happy/Neutral 클러스터가 자연스럽게 형성된다는 점입니다. 게다가 VAE의 연속 latent space 덕분에 클러스터 사이를 보간할 수 있습니다. 예를 들어 어르신 안부를 묻는 응대 에이전트라면, 너무 슬픈 톤도 너무 무덤덤한 톤도 곤란한데, 슬픔과 중립 클러스터 중간에서 z를 샘플링하면 “많이 힘드셨겠어요” 정도의 정중한 걱정 톤을 만들 수 있습니다. 감정의 강도를 미세 조정하는 거죠. 여기서 등장한 “사전학습 모델로 화자를 zero-shot으로 붙인다"는 발상이, 다음 파트의 본격적인 zero-shot voice cloning으로 이어집니다.
Part 3. 두 흐름이 만나는 곳 — Large-Scale Zero-Shot TTS
녹음이라는 제약
기존 TTS의 acoustic model은 본질적으로 “타깃 화자의 음성 특성을 직접 학습"합니다. 그래서 출력 품질이 그 화자의 학습 데이터 양과 질에 강하게 묶입니다. 새 화자로 일반화가 어렵다는 뜻이죠. 이게 현장에서 얼마나 큰 제약인지는 녹음 조건을 비교하면 분명해집니다.
| 항목 | Conventional TTS | Voice cloning |
|---|---|---|
| 녹음량 | 30–60분 이상 | 수 초 |
| 발화 유형 | 스크립트 낭독 | 자유 발화 |
| 화자 | 전문 성우 | 비전문가 |
| 녹음 환경 | 깨끗한 스튜디오 | 아무 데나 |
전문 성우 1시간 녹음에 보통 일주일, 천만에서 이천만 원이 듭니다. 게다가 TTS로 만들어보기 전에는 쓸 만한지 알 수 없어서, 밝은 톤은 되는데 걱정하는 톤이 안 되면 또 녹음을 받아야 합니다. 일반인은 또박또박 읽기도 어렵고, 성대 수술 전에 목소리를 남기고 싶은 사람도 있고요. 그래서 “녹음을 한 문장에서 열 문장으로 줄이고, 전문 성우가 아니어도, 조용한 방에서 녹음한 것으로도 멀쩡하게 읽어주는 TTS"가 목표가 됩니다. 기존 지도학습으로는 이런 조건에서 알아들을 수 없는 소리가 나왔습니다.
기존 통념은 “녹음 품질이 곧 합성 품질"이었습니다. Large-scale TTS는 이 가정을 뒤집습니다. 대규모 데이터 + 대규모 모델이라는 새 축이 생기면, 같은 voice cloning 조건(짧은 녹음, 자유 발화, 비전문 화자)에서도 매우 자연스러운 합성이 가능해집니다. 개별 녹음 품질 제약이 더 이상 결과를 좌우하지 않게 된 거죠.
Voicebox와 Flow Matching
Voicebox(2023, Meta FAIR)의 생성 엔진은 flow matching입니다. diffusion을 대체하는 생성 방식인데, 직관은 거속시(거리=속력×시간)로 충분합니다.
1초 동안 x0에서 x1까지 등속도로 이동한다고 합시다. 속도는 모든 구간에서 같으니 ut = x1 - x0(시간이 1이므로 거리 그 자체)이고, 임의 시점 t의 위치는 xt = (1-t)x0 + t·x1이라는 선형 보간입니다. 실제 데이터는 등속이 아니겠지만, neural network v(xt; θ)(보통 Transformer)가 임의 시점 t의 속도를 등속 운동처럼 추정하도록 학습시킵니다.
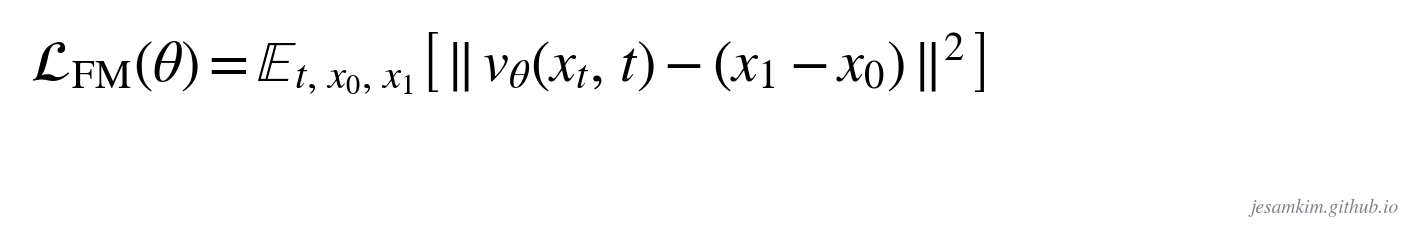
손실은 정답 속도와 추정 속도의 L2 거리입니다. diffusion이 노이즈에서 데이터로 곡선을 그리며 가는 반면, flow matching은 거의 직선 경로(optimal transport)로 “직선거리로 꽂아버립니다”. 두 기법은 수학적으로 동치이고 전제만 조금 다른데, 차이는 생성 시 sampling 횟수(NFE)입니다. diffusion은 수백에서 수천 step이 필요하지만 flow matching은 훨씬 적은 step으로 복원합니다. 추론은 학습된 속도 추정기로 노이즈 x0에서 출발해 Euler step으로 trajectory를 적분하면 됩니다. 한 가지 헷갈리기 쉬운 점은, flow matching은 loss(목적함수)이고 Transformer는 architecture라는 구분입니다. mel 자체의 에러가 아니라 mel의 변화량(vector field)을 추정하도록 손실을 설계한 게 flow matching입니다.
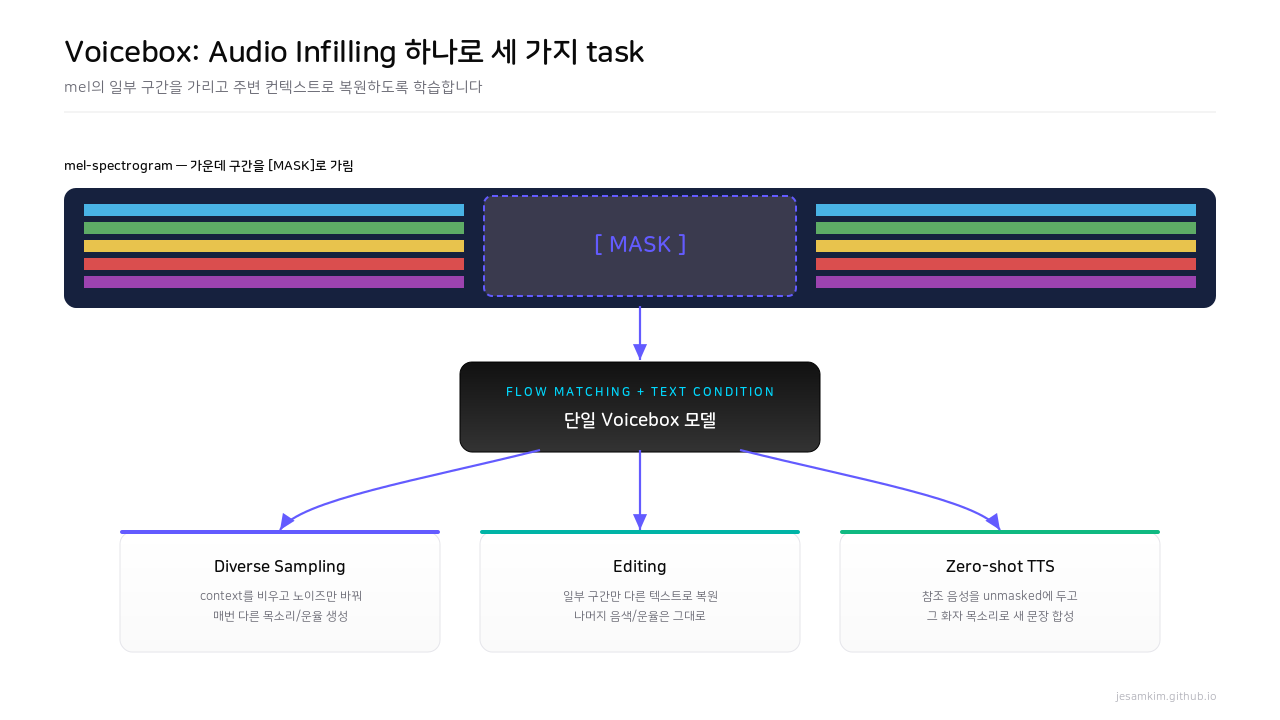 Figure 7. 가린 구간을 주변으로 복원하는 단일 audio infilling 학습으로, 같은 모델이 세 가지 task를 in-context로 수행합니다.
Figure 7. 가린 구간을 주변으로 복원하는 단일 audio infilling 학습으로, 같은 모델이 세 가지 task를 in-context로 수행합니다.
Voicebox의 핵심 학습 task는 audio infilling입니다. BERT가 텍스트 토큰을 가리고 주변으로 복원하듯, Voicebox는 음향 파라미터의 일부 프레임을 [MASK]로 가리고 주변 프레임으로 복원합니다. 마스킹된 구간을 그냥 채우면 아무 말이나 나올 수 있으니, 텍스트 정보를 condition으로 함께 줍니다. 50K 시간 규모 다국어 데이터로 학습한 결과, 단일 모델이 in-context learning만으로 여러 task를 동시에 수행합니다.
- Diverse sampling: audio context를 비워두면 같은 텍스트에서 출발 노이즈만 바꿔 매번 다른 목소리·운율을 만듭니다. one-to-many 모호성을 latent space에서 자연스럽게 해소하죠.
- Editing: 원본 음성에서 일부 구간만 마스킹하고 다른 텍스트를 condition으로 주면, 그 구간만 새 텍스트로 복원됩니다. 나머지 음색·운율은 그대로입니다.
- Zero-shot TTS: 참조 음성을 unmasked 영역에 두고 합성할 텍스트를 condition으로 주면, 그 화자 목소리로 새 문장을 읽습니다. 별도 speaker encoder 없이 화자 클로닝이 됩니다.
왜 zero-shot이 되는지가 핵심입니다. 6만 시간, 수십만 명의 목소리를 섞어 임의 마스킹을 걸어 복원하도록 학습하면, 모델은 “이 사람의 특성"이 아니라 “주변 정보로 빈 곳을 복원하는 법"을 배웁니다. 그래서 처음 보는 화자의 mel이 와도, 일부를 잘라 복원하는 법을 이미 알고 있으니 그 목소리가 누구든 채울 수 있습니다. 추론 때는 5–10초짜리 speech prompt를 unmasked 영역에 넣고 합성 구간은 [MASK]로 두면 됩니다. 텍스트가 “무엇을 말할지”, prompt가 “어떤 목소리로 말할지"를 결정하니 둘을 독립적으로 제어할 수 있죠.
이 분리 덕분에 cross-lingual voice cloning도 됩니다. Aligner가 텍스트와 음향 특징을 정렬하므로 prompt의 음색 정보와 마스킹 영역의 발음 정보가 분리됩니다. 영어 화자 prompt로 한국어 문장을 그 화자 목소리로 합성할 수 있다는 뜻입니다. 다만 이 능력은 소규모 모델에서는 잘 안 나오고 대규모 학습에서 비로소 안정적으로 관찰됩니다. 성능 수치를 보면 Voicebox(330M)는 zero-shot TTS에서 WER 1.9%로 ground truth(2.2%)를 능가하고, 화자 유사도에서도 VALL-E를 뚜렷이 앞섰습니다. 한국어 4화자 실험에서는 화자당 데이터를 1시간에서 4–8초로 줄였는데도 화자 유사도·명료도·자연스러움이 모두 개선됐습니다. 녹음 비용을 모델 크기와 GPU 컴퓨트 비용으로 치환한 셈입니다.
여기서 Part 1과 Part 2가 만나는 게 보입니다. SSL이 키워온 “주변으로 복원하는 self-supervised 사고”(HuBERT의 masked prediction)와, TTS가 다듬어온 acoustic model 구조가 flow matching 위에서 결합한 것이죠.
CosyVoice 2 — LLM이 음성에 들어오면
또 하나의 합류점은 LLM입니다. CosyVoice 2(2024, Alibaba)는 “LLM의 능력을 음성까지 확장할 수 있을까"라는 질문에서 출발합니다.
문제는 mel-spectrogram이 연속값(floating point)이라는 점입니다. LLM의 디코더는 next token prediction, 즉 “vocab 5만 개 중 몇 번 인덱스인가"를 맞히는데, 실수값인 mel은 인덱스로 표현할 수 없습니다. 그래서 음성을 이산 토큰으로 바꿔야 합니다. 여기서 Part 1의 양자화가 돌아옵니다. HuBERT가 K-means로, wav2vec 2.0이 Gumbel Softmax로 했던 그 작업이 LLM 음성 모델의 전제 조건이 됩니다.
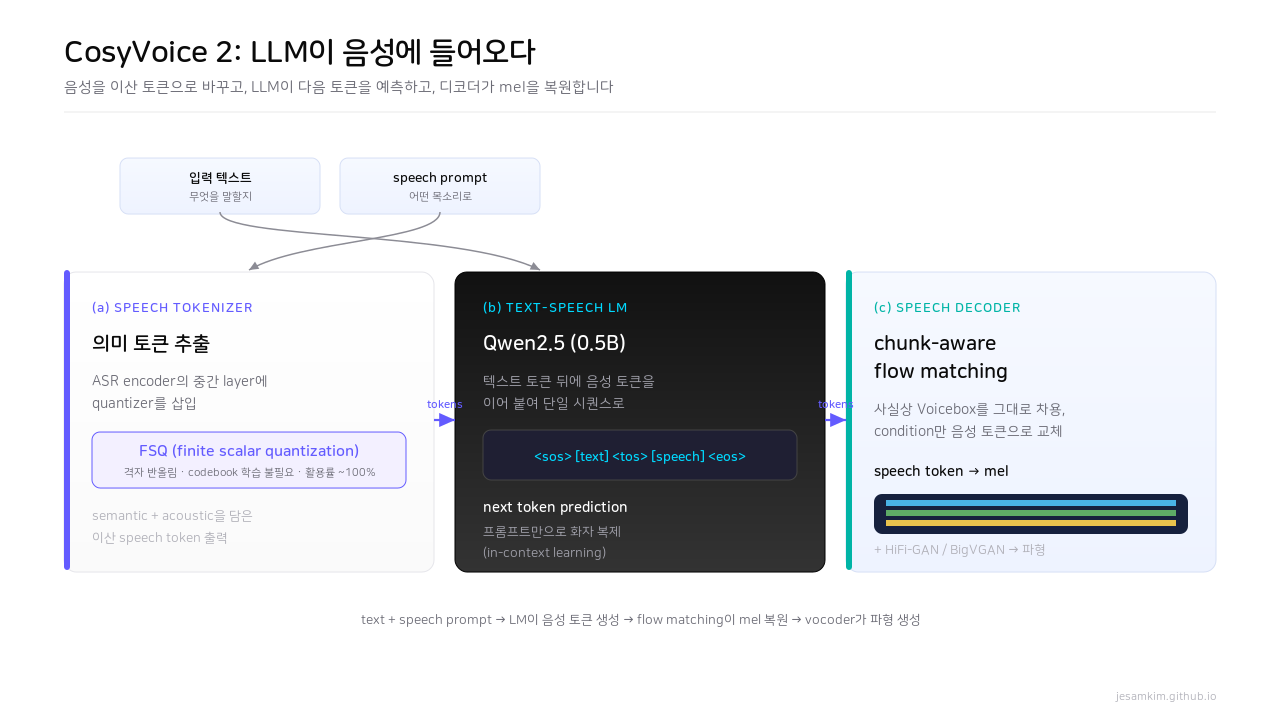 Figure 8. 음성을 FSQ로 이산 토큰화하고, Qwen2.5 LM이 다음 토큰을 예측하며, flow matching 디코더가 mel을 복원합니다.
Figure 8. 음성을 FSQ로 이산 토큰화하고, Qwen2.5 LM이 다음 토큰을 예측하며, flow matching 디코더가 mel을 복원합니다.
CosyVoice 2는 세 블록입니다.
(a) Speech Tokenizer. ASR task의 부산물로 semantic token을 얻는 게 핵심 아이디어입니다. ASR 인코더에서 음성에 가까운 아래쪽 layer는 acoustic 정보를, 텍스트에 가까운 위쪽 layer는 semantic 정보를 담는데, 중간 layer에 quantizer를 끼워 넣으면 둘을 모두 담은 이산 speech token이 나옵니다. 양자화에는 FSQ(finite scalar quantization)를 씁니다. VQ가 학습된 codebook 벡터로 양자화한다면, FSQ는 격자(grid)를 미리 정해두고 가장 가까운 격자점으로 반올림합니다. codebook을 학습할 필요가 없고 활용률이 거의 100%에 가까워, LLM 토크나이저에 더 잘 맞습니다.
(b) Text-Speech Language Model. Qwen2.5(0.5B)를 backbone으로 씁니다. 학습 때는 텍스트 토큰 뒤에 음성 토큰을 이어 붙여 단일 시퀀스(<sos> [text] <tos> [speech] <eos>)로 만들고 next token prediction을 합니다. 모델 입장에서는 텍스트든 음성이든 “0–5만 사이 인덱스 하나"가 순차적으로 들어오는 것뿐이라, 늘 하던 next token prediction을 그대로 합니다. 우리가 인덱스의 일부를 음성 토큰으로 바꿔치기한 것뿐인데, 그게 TTS가 됩니다. 추론 때는 prompt 텍스트·음성과 입력 텍스트를 함께 넣어, 같은 화자 특성으로 새 문장의 음성 토큰을 자기회귀적으로 생성합니다. 별도 화자 학습 없이 프롬프트만으로 화자를 복제하는 in-context learning이죠.
(c) Speech Decoder. 구조는 Voicebox를 거의 그대로 가져왔습니다. 유일한 차이는 입력 condition입니다. Voicebox는 텍스트(context feature)를 시간축에 나열한 것을 condition으로 받았는데, CosyVoice 2는 음성 토큰을 받습니다. 그리고 그 음성 토큰은 LLM이 찾아줍니다. 학습 때는 굳이 LLM을 태우지 않고, 사전학습 tokenizer로 뽑은 speech token을 condition으로 주고 mel을 마스킹해 복원하도록 학습합니다(token-to-speech). 추론 때만 입력 텍스트의 음성 토큰을 LLM이 추정해 채웁니다. 복원된 mel에 HiFi-GAN이나 BigVGAN을 붙이면 파형이 나옵니다.
Continuous vs Discrete, 그리고 AR의 대가
여기서 두 방식의 본질적 차이가 드러납니다. Voicebox는 연속 표현(mel)을 flow matching으로 병렬(non-AR) 생성하고, CosyVoice 2는 이산 토큰을 next token prediction으로 순차(AR) 생성합니다. AR을 택하면 모델 내부에서 alignment를 배워 별도 duration model이 필요 없고, 맥락을 스스로 파악해 더 live한 운율(다이나믹)을 만듭니다. 스포츠 중계처럼 박진감 있는 표현이 살아나죠.
대신 두 가지 대가를 치릅니다.
느린 속도. LLM이 음성 토큰을 한 프레임씩 순차 생성한 뒤, 디코더가 다시 mel로 디코딩하는 직렬 처리라 발화가 길수록 지연이 커집니다. 해법은 streaming입니다. 전체를 다 만들고 재생하는 대신, 텍스트 N개당 음성 토큰 M개를 번갈아 만들어 청크 단위로 생성-디코딩-재생을 인터리빙합니다. “안녕"을 재생하는 동안 뒤에서 “하세요"를 만드는 식이죠. 이전 청크 재생과 다음 청크 생성이 병렬로 돌아, 체감 지연은 첫 청크 생성 시간만큼만 발생합니다. 텍스트가 음성보다 짧으니 텍스트가 끝나는 지점에 Turn of Speech 토큰을 넣어 이후로는 음성 토큰만 생성하게 신호를 줍니다. 지연이 중요하면 streaming, 오프라인 고품질이면 non-streaming을 고르면 됩니다.
Hallucination. AR은 이전 단계 오류가 누적되는 구조라, 발화 끝을 못 잡아 노래처럼 늘어지거나(데이터에 음악이 섞여 있던 흔적), 군더더기 소리가 끼는 환각이 생깁니다. 해법은 두 갈래입니다. 데이터 측면에서 data refinement로 깨끗한 데이터를 골라 다시 fine-tuning하고, 학습 측면에서 reinforcement learning으로 “텍스트를 얼마나 정확하게 읽었는가"를 reward로 두고 정렬합니다. ChatGPT를 만든 RLHF와 같은 발상이죠. 수치로 보면 CosyVoice 2는 LibriSpeech test-clean에서 WER 2.47%로 사람(2.66%)보다 낮고 화자 유사도도 높았으며, streaming 버전도 품질 손실이 거의 없었습니다.
세 흐름의 합류점
흥미로운 솔직함은, 품질만 놓고 보면 Voicebox(flow matching)가 CosyVoice 2보다 낫다는 점입니다. mel을 직접 복원하니까요. 그럼에도 LLM 기반을 연구하는 이유는 “앞으로 LLM은 계속 발전할 것"이라는 믿음입니다. backbone LLM이 좋아질수록 거기 fine-tuning한 음성 모델도 함께 좋아지니, 음성도 LLM에 맞춰 같이 가자는 전략입니다.
| 측면 | Audio Infilling (Voicebox) | LLM 기반 (CosyVoice 2) |
|---|---|---|
| 음성 표현 | 연속 (mel-spectrogram) | 이산 (speech token, FSQ) |
| 생성 방식 | flow matching (Non-AR, 병렬) | next token prediction (AR, 순차) |
| 화자 복제 | masked infilling + speech prompt | in-context learning |
| 강점 | 안정적, 고품질 | LLM 능력 활용, 풍부한 운율 |
정리하면 zero-shot voice cloning은 세 흐름의 합류점입니다. 표현 학습(SSL)이 만든 “음성을 의미 있는 이산 토큰으로 자르는 토크나이저”, LLM의 next token prediction, 그리고 flow matching 디코더. Part 1의 양자화와 masked prediction이 Part 3의 speech tokenizer와 audio infilling으로, Part 2의 acoustic model 구조가 flow matching 디코더로 흘러들어와 한 점에서 만납니다. zero-shot TTS는 flow matching이 나왔고, large-scale로 갔고, self-supervised learning을 TTS에 적용한, 세 박자가 맞아떨어진 결과인 셈입니다.
마무리
흐름을 따라가며 가장 크게 남은 건, 손실 함수와 학습 task의 설계가 “데이터의 어떤 구조를 활용할 것인가"라는 질문으로 수렴한다는 점이었습니다. CPC의 미래 예측, HuBERT의 masked cluster 예측, Voicebox의 audio infilling은 표면적으로 달라 보여도 모두 “주변 맥락으로 빈 곳을 채우게 만든다"는 self-supervised 정신을 공유합니다. 양자화라는 한 가지 장치가 wav2vec 2.0에서 시작해 HuBERT를 거쳐 CosyVoice 2의 speech tokenizer까지 형태를 바꿔가며 계속 등장하는 것도 기억에 남았고요.
다음에 더 파보고 싶은 건 두 가지입니다. 하나는 cross-lingual voice cloning이 대규모 학습에서만 안정적으로 나타나는 현상의 메커니즘입니다. 음색과 언어가 어느 규모에서 어떻게 분리되기 시작하는지가 궁금합니다. 다른 하나는 prompt 기반 감정·스타일 제어입니다. Voicebox 방식은 감정을 스스로 만들지 못하고 예시 프롬프트가 있어야 하는데, NaturalSpeech 계열처럼 mel을 여러 컴포넌트로 분해해 자연어로 제어하는 방향이 어디까지 성숙했는지 직접 코드로 따라가 보고 싶습니다. 음성을 이해하는 흐름과 만드는 흐름이 이미 한 번 합쳐졌으니, 다음 합류점이 어디일지도 천천히 지켜볼 생각입니다.
References
- Aaron van den Oord, Yazhe Li, Oriol Vinyals. “Representation Learning with Contrastive Predictive Coding.” arXiv:1807.03748. https://arxiv.org/abs/1807.03748
- Steffen Schneider, Alexei Baevski, Ronan Collobert, Michael Auli. “wav2vec: Unsupervised Pre-training for Speech Recognition.” arXiv:1904.05862. https://arxiv.org/abs/1904.05862
- Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli. “wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations.” arXiv:2006.11477. https://arxiv.org/abs/2006.11477
- Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed. “HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units.” arXiv:2106.07447. https://arxiv.org/abs/2106.07447
- Aaron van den Oord et al. “WaveNet: A Generative Model for Raw Audio.” arXiv:1609.03499. https://arxiv.org/abs/1609.03499
- Aaron van den Oord et al. “Parallel WaveNet: Fast High-Fidelity Speech Synthesis.” arXiv:1711.10433. https://arxiv.org/abs/1711.10433
- Ryuichi Yamamoto, Eunwoo Song, Jae-Min Kim. “Parallel WaveGAN: A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram.” arXiv:1910.11480. https://arxiv.org/abs/1910.11480
- Jungil Kong, Jaehyeon Kim, Jaekyoung Bae. “HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis.” arXiv:2010.05646. https://arxiv.org/abs/2010.05646
- Sang-gil Lee, Wei Ping, Boris Ginsburg, Bryan Catanzaro, Sungroh Yoon. “BigVGAN: A Universal Neural Vocoder with Large-Scale Training.” arXiv:2206.04658. https://arxiv.org/abs/2206.04658
- Jonathan Shen et al. “Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions.” arXiv:1712.05884. https://arxiv.org/abs/1712.05884
- Yi Ren et al. “FastSpeech 2: Fast and High-Quality End-to-End Text to Speech.” arXiv:2006.04558. https://arxiv.org/abs/2006.04558
- Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, Matt Le. “Flow Matching for Generative Modeling.” arXiv:2210.02747. https://arxiv.org/abs/2210.02747
- Matthew Le et al. “Voicebox: Text-Guided Multilingual Universal Speech Generation at Scale.” arXiv:2306.15687. https://arxiv.org/abs/2306.15687
- Zhihao Du et al. “CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models.” arXiv:2412.10117. https://arxiv.org/abs/2412.10117
- Fabian Mentzer, David Minnen, Eirikur Agustsson, Michael Tschannen. “Finite Scalar Quantization: VQ-VAE Made Simple.” arXiv:2309.15505. https://arxiv.org/abs/2309.15505