
컨텍스트 윈도우만 늘려서는 풀리지 않는 문제
2025년부터 2026년 사이 LLM 컨텍스트 윈도우는 200K에서 1M 토큰까지 늘어났습니다. 그런데 production에서 에이전트를 운영해본 팀들은 비슷한 결론에 도달하고 있습니다. “세션 길이가 길어지면 컨텍스트만 키워서는 풀리지 않는 문제가 생긴다”는 것이죠. 멀티턴 대화가 수십 턴을 넘어가면 latency가 급격히 늘어나고, 토큰 비용은 누적되며, 모델이 앞쪽 정보를 슬그머니 잊어버리는 lost-in-the-middle 현상이 따라옵니다.
그래서 2026년 들어 에이전트 메모리 아키텍처가 본격적으로 production 관심사로 올라왔습니다. ACL 2026 Findings에 채택된 From Storage to Experience 서베이는 이 흐름을 명시적으로 정리했고, ECAI 2025의 Mem0는 production 최적화 수치를 처음으로 공개했으며, AWS는 Bedrock AgentCore Memory를 GA로 풀었습니다. 이 글은 학계의 분류 체계, 두 편의 대표 논문, 그리고 매니지드 서비스가 메모리를 어떻게 다루는지를 한 번에 묶어 정리합니다.
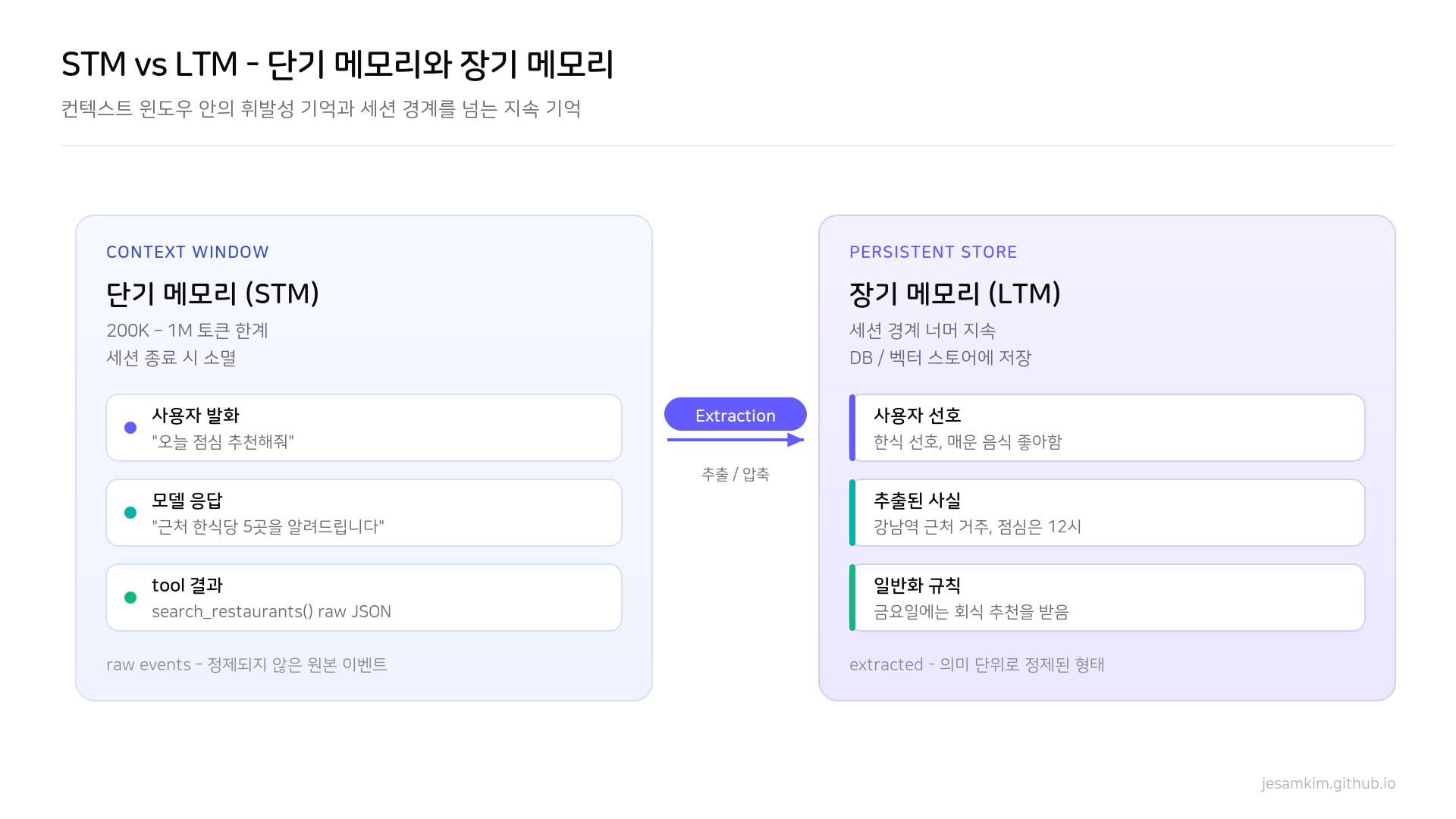
단기 메모리는 세션 내 raw event를, 장기 메모리는 추출/압축된 영속 정보를 담습니다. 두 계층 사이를 Extraction이 잇습니다.
단기 메모리와 장기 메모리, 무엇이 다른가
LLM 에이전트의 메모리는 보통 두 계층으로 나뉩니다. 단기 메모리(STM)는 현재 세션의 raw 이벤트입니다. 사용자 발화, 모델 응답, tool 호출 결과처럼 그 시점에 일어난 일을 그대로 담습니다. 컨텍스트 윈도우에 직접 들어가는 정보이고, 세션이 끝나거나 윈도우 한계에 부딪히면 사라집니다.
장기 메모리(LTM)는 세션 경계를 넘어 지속되는 정보입니다. 여러 세션에서 반복적으로 등장한 사용자 선호, 과거 대화에서 추출한 사실, 누적된 경험에서 뽑아낸 일반화된 규칙 같은 것이 여기 들어갑니다. raw 이벤트를 그대로 보관하지 않고, 추출 과정을 거쳐 압축된 형태로 저장하는 것이 특징입니다.
이 분리가 왜 필요한지는 단순합니다. STM을 그대로 누적하면 컨텍스트가 폭발하고, LTM 없이 STM만 쓰면 세션이 바뀌는 순간 모든 맥락이 사라집니다. 두 계층을 어떻게 정의하고, STM에서 LTM으로 정보를 어떻게 옮기느냐가 메모리 설계의 본질이라고 볼 수 있습니다.
학계의 분류 — Storage, Reflection, Experience
Hongzhan Lin 외의 서베이는 LLM 에이전트 메모리 메커니즘이 진화해온 흐름을 세 단계로 정리합니다. Storage, Reflection, 그리고 Experience입니다.
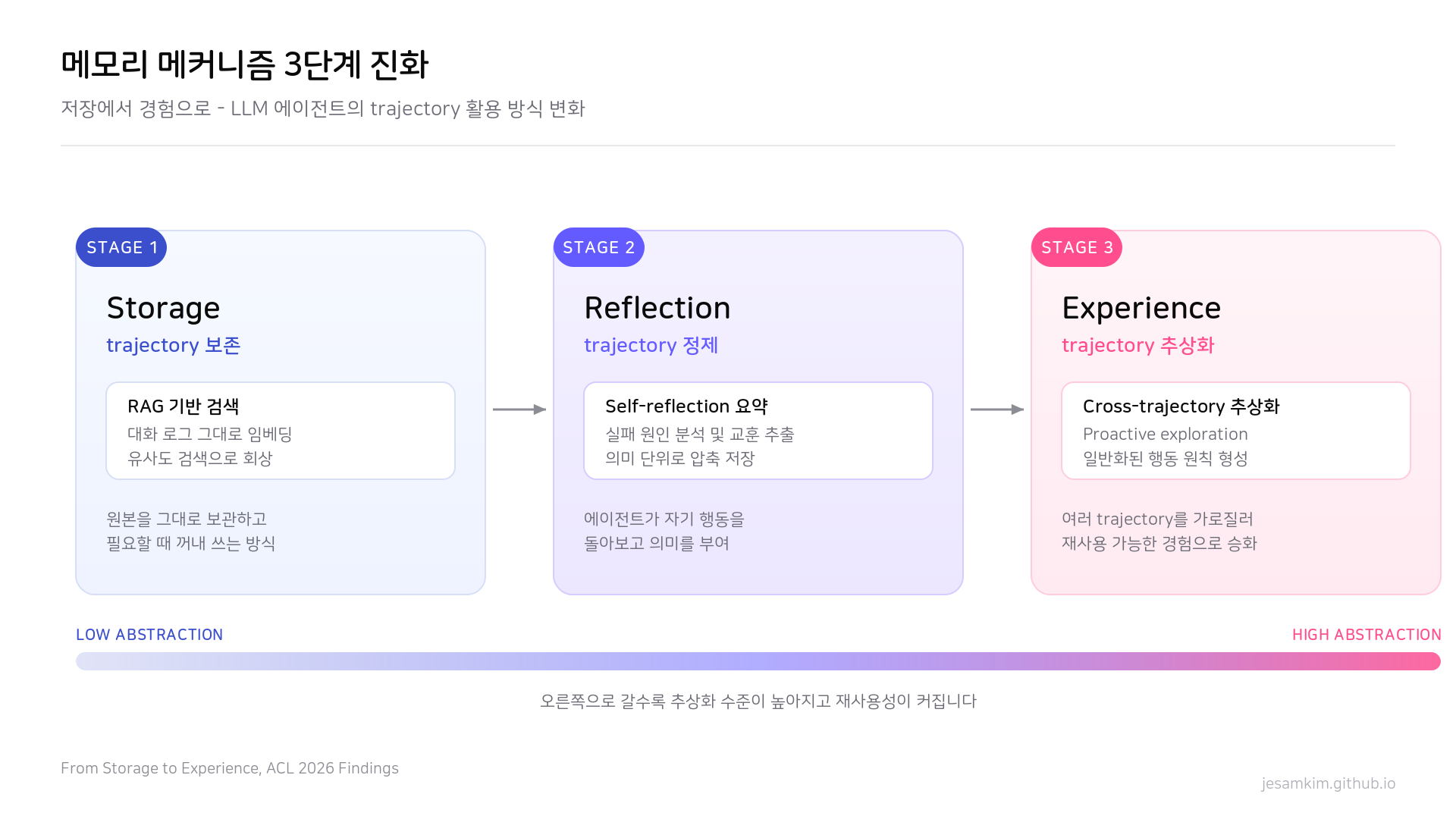
메모리 메커니즘의 세 단계 진화. 출처: From Storage to Experience, ACL 2026 Findings.
Storage 단계는 trajectory를 그대로 보존하는 가장 단순한 방식입니다. 대화 기록, tool 호출 로그, 관찰값을 그대로 저장하고 필요할 때 retrieval로 끌어다 씁니다. RAG 기반 메모리가 대표적입니다. 구현이 간단하고 정보 손실이 없다는 장점이 있지만, 양이 늘어날수록 신호 대 잡음비가 떨어집니다.
Reflection 단계는 trajectory를 정제(refinement)하는 쪽으로 한 단계 올라간 형태입니다. 저장된 raw 데이터에 self-reflection을 걸어 요약하고, 중요한 부분과 그렇지 않은 부분을 가르고, 잘못된 추론을 수정합니다. 저장량을 늘리기보다 저장 형태를 다듬는 데 무게를 둔 발상입니다.
Experience 단계는 trajectory를 추상화(abstraction)해서 일반화된 경험으로 바꾸는 단계입니다. 서베이는 이 단계의 핵심 메커니즘으로 두 가지를 지목합니다. 하나는 proactive exploration으로, 에이전트가 수동적으로 기록만 남기는 게 아니라 부족한 부분을 메우려고 능동적으로 행동을 시도하는 패턴입니다. 다른 하나는 cross-trajectory abstraction인데, 여러 세션에 걸친 trajectory들을 가로질러 공통 패턴을 뽑아내는 방식입니다.
서베이는 이 진화를 끌고 가는 driver를 세 가지로 정리합니다. 첫째, long-range consistency를 유지해야 하는 요구입니다. 단순 RAG로는 수십 세션에 걸친 일관성이 깨집니다. 둘째, dynamic environment의 도전입니다. 환경이 시시각각 바뀌면 과거 trajectory의 가치가 빠르게 떨어집니다. 셋째, continual learning 목표입니다. 에이전트가 운영 중에 계속 나아져야 한다면, 메모리는 단순 저장소가 아니라 학습 신호의 원천이 되어야 합니다.
이 세 단계 분류는 추상적으로 보일 수 있지만, 실제 시스템을 어디에 위치시킬지 판단하는 기준으로는 꽤 유용합니다. Mem0는 Reflection 단계에 해당하는 정제 메커니즘을 production에 옮긴 사례이고, 뒤에서 다룰 AgeMem은 Experience 단계의 cross-trajectory 학습을 RL로 명시화한 사례입니다.
Mem0 — 메모리 중심 아키텍처와 LOCOMO 벤치마크
Mem0는 ECAI 2025에 채택된 논문으로, “production-ready AI agent를 위한 확장 가능한 장기 메모리"를 표방합니다. 핵심 발상은 단순합니다. 대화에서 중요한 정보를 동적으로 추출(extract)하고, 기존 메모리와 겹치는지를 보고 consolidate한 뒤, 필요할 때 retrieve한다는 흐름입니다. 흔한 RAG와 다른 점은 메모리 자체가 아키텍처의 중심이라는 것입니다. 컨텍스트는 모델이 그때그때 받는 입력일 뿐이고, 영속적인 지식의 본거지는 메모리 모듈이 담당합니다.
논문은 이 접근을 검증하기 위해 LOCOMO(LoCoMo) 벤치마크를 사용했습니다. LOCOMO는 메모리가 필요한 멀티턴 대화 task를 모은 데이터셋으로, full-context 입력, 여러 RAG 변형, OpenAI Memory, Zep, 그리고 오픈소스 메모리 시스템 등 10개 접근법을 head-to-head로 비교할 수 있게 설계됐습니다.
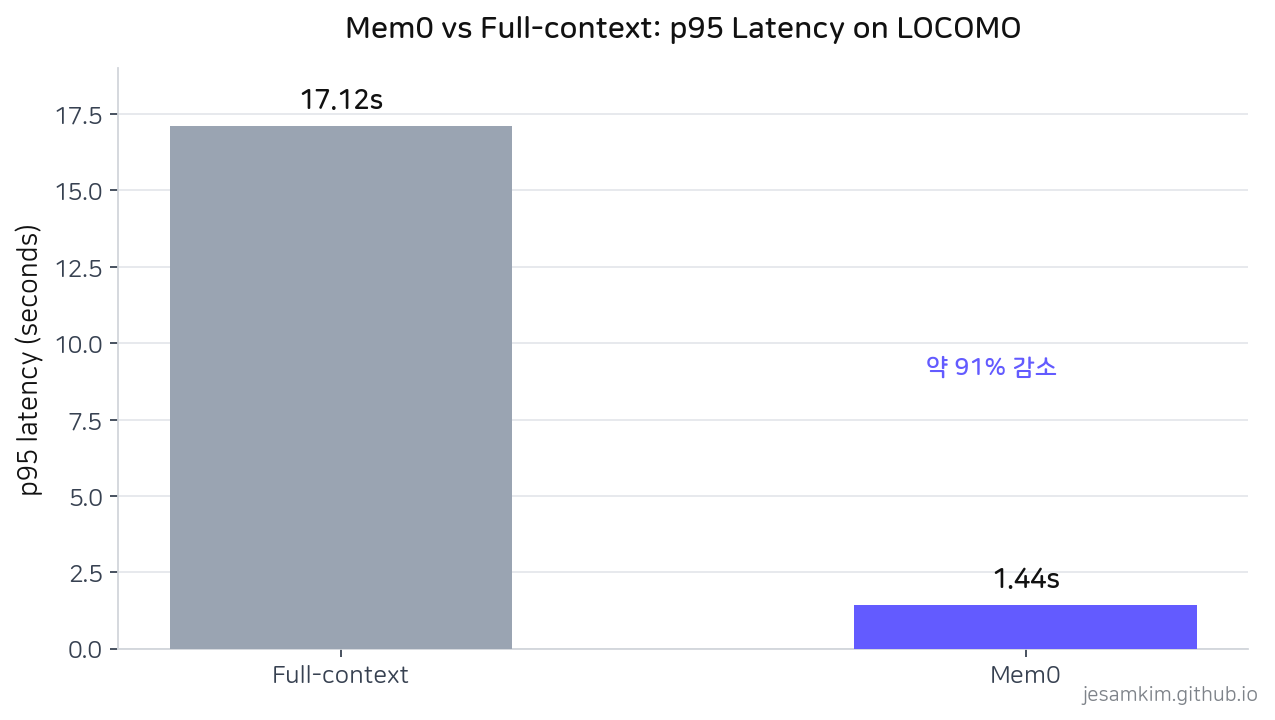
LOCOMO 벤치마크에서 측정된 p95 latency. 출처: Mem0, ECAI 2025.
여기서 가장 자주 인용되는 수치 두 가지가 나옵니다. p95 latency가 1.44초로, full-context 방식의 17.12초 대비 약 91% 낮습니다. 토큰 비용도 full-context 대비 약 90% 낮은 수준으로 측정됐습니다. production 관점에서 보면 의미가 큽니다. 컨텍스트 윈도우를 1M까지 늘려서 모든 과거 대화를 매번 다시 입력하는 방식은 latency와 비용에서 한계가 분명한데, 메모리 계층을 거치면 정보를 잃지 않으면서도 두 지표가 한 자릿수로 떨어집니다. 이 수치는 preuve.ai의 2026 AI 메모리 시스템 통계 정리에서도 확인할 수 있습니다.
한 가지 짚어둘 점이 있습니다. mem0.ai 공식 리서치 페이지에는 LoCoMo 92.5점, LongMemEval 94.4점, BEAM 64.1/48.6, 7000 토큰 미만 같은 수치가 올라와 있는데, 이건 ECAI 논문 발표 이후 갱신된 token-efficient 알고리즘 결과로 논문 본문 수치와는 다릅니다. 인용할 때는 “Mem0 자체 리서치 페이지 기준"으로 명시하는 편이 정확합니다.
Mem0의 의의는 메모리를 별도 모듈로 분리하는 패턴을 production 수준에서 검증한 데 있습니다. extract/consolidate/retrieve 세 단계는 뒤에서 살펴볼 AWS AgentCore Memory의 처리 단계와도 곧장 매핑됩니다. 학계 아이디어와 클라우드 매니지드 서비스 사이의 거리가 빠르게 좁혀지고 있다는 신호로 읽을 수 있습니다.
AgeMem — 메모리 연산을 tool-based action으로 노출
Yi Yu 외의 AgeMem은 다른 길을 갑니다. 메모리 시스템을 외부 모듈로 두는 대신, LTM과 STM 관리를 에이전트의 정책에 직접 통합하는 접근입니다. 통합 프레임워크라는 이름 그대로 단기와 장기를 한 모델 안에서 함께 다룹니다.
핵심 설계는 두 가지입니다. 첫째, 메모리 연산을 tool-based action으로 노출합니다. store, retrieve, update, summarize, discard 같은 메모리 조작을 LLM이 호출 가능한 tool로 만들어두면, 모델이 task를 풀어가면서 어떤 시점에 무엇을 기억하고 어떤 정보를 잊을지를 자율적으로 결정할 수 있습니다. 이건 메모리 정책을 hard-coded heuristic이 아니라 학습된 행동으로 만든다는 뜻입니다.
둘째, 이 정책을 3단계 progressive RL + step-wise GRPO로 학습시킵니다. GRPO(Group Relative Policy Optimization)는 보상을 그룹 내 상대값으로 정규화하는 방식으로, 메모리 task처럼 sparse하고 discontinuous한 reward에 강합니다. 메모리 연산은 즉각적인 보상을 주지 않는 경우가 많고(“이 정보를 지금 저장해두면 5턴 뒤에 도움이 된다”), 보상이 띄엄띄엄 주어지는 환경에서 PPO는 학습이 잘 풀리지 않습니다. step-wise GRPO는 이런 신호 부족 문제에 대응하도록 설계됐습니다.
논문은 5개 long-horizon 벤치마크에서 강한 memory-augmented baseline 대비 일관된 우위를 보였다고 보고합니다(consistently outperforms). task 성능, LTM 품질, context 효율 세 측면에서 모두 개선됐다는 결과입니다. 코드는 github.com/y1y5/AgeMem에 공개돼 있습니다.
AgeMem이 흥미로운 건 메모리 관리가 더 이상 별도 컴포넌트가 아니라 학습 가능한 정책의 일부가 됐다는 점입니다. 서베이의 Experience 단계가 묘사한 proactive exploration, cross-trajectory abstraction이 RL 목표 함수에 직접 들어간 형태로 볼 수 있습니다. 다만 production 관점에서는 학습 비용과 정책 안정성이라는 새로운 과제를 가져옵니다. tool 호출 결정을 잘못 내리면 메모리가 의도와 다른 방향으로 망가질 수 있으니, RL 학습 환경 설계가 시스템 자체만큼이나 중요해집니다.
AWS Bedrock AgentCore Memory — 매니지드 서비스의 위치
학계 흐름을 옆에 두고 매니지드 서비스 쪽도 보겠습니다. AWS Bedrock AgentCore는 GA 상태이고, 그 안의 Memory 컴포넌트는 STM과 LTM을 명시적으로 분리한 구조를 제공합니다.
STM은 raw conversation event입니다. 세션별로 저장되며, 개발자는 CreateEvent API로 각 turn을 전송합니다. 사용자 발화, 모델 응답, tool 결과 같은 이벤트가 그대로 들어갑니다.
LTM은 strategy를 통해 raw event에서 자동으로 추출/통합되는 영속 정보입니다. 단순한 한 단계 변환이 아니라 세 단계 처리를 거칩니다.
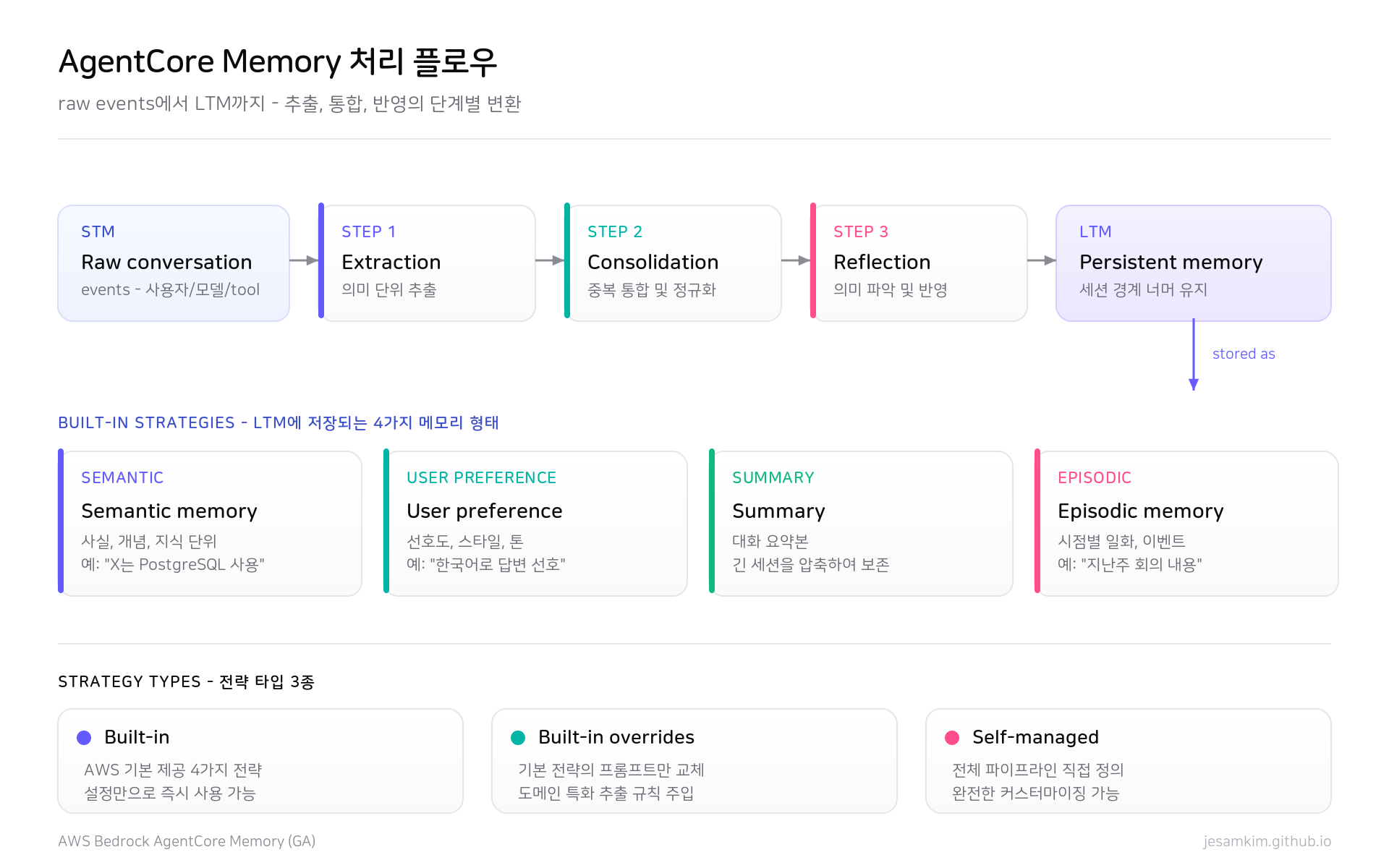
AgentCore Memory의 STM에서 LTM으로 이어지는 처리 단계와 built-in 전략. 출처: AWS Bedrock AgentCore Memory (GA).
처리 단계는 Extraction, Consolidation, Reflection 세 가지입니다. Extraction은 STM에서 유용한 insight를 식별해 LTM record로 변환합니다. Consolidation은 새로 들어온 record가 기존 record와 어떻게 관계 맺는지를 판단해 갱신/병합 여부를 결정합니다. Reflection은 여러 에피소드에 걸쳐 insight를 생성해 단일 세션을 넘어선 패턴을 잡습니다. 이 세 단계 순서는 Mem0의 extract → consolidate → retrieve 흐름과 거의 그대로 겹칩니다.
built-in 전략은 네 종류가 제공됩니다. Semantic memory는 의미 기반 사실을 저장합니다. User preference memory는 사용자 선호와 설정을 누적합니다. Summary는 대화 요약을 보관합니다. Episodic memory는 특정 사건과 그 맥락을 시간 순으로 정리합니다.
전략은 운영 모드 측면에서 세 가지 타입으로 나뉩니다. Built-in은 추출 프롬프트와 모델, 저장 형식이 모두 자동으로 처리되는 모드입니다. 설정 부담이 가장 적지만 LTM 스토리지 비용이 상대적으로 높습니다. Built-in overrides는 추출 프롬프트를 직접 커스텀하면서 호출 모델은 사용자 계정의 Bedrock 모델을 쓰는 방식입니다. 출력 스키마가 더 명확해지고 스토리지 비용도 낮아집니다. Self-managed는 추출/통합 파이프라인 전체를 사용자가 소유하는 모드로, 인프라까지 직접 운영해야 하지만 전 과정을 통제할 수 있습니다. 단일 memory resource 안에 built-in과 custom 전략을 동시에 구성하는 것도 가능합니다.
2026-05에는 LTM record metadata 지원이 추가됐습니다. record에 태그를 붙여 필터링하거나 효율적으로 retrieve할 수 있게 됐는데, 그동안 메타데이터가 없어 우회 방법으로 처리하던 영역이 정식 기능으로 들어왔습니다.
AgentCore Memory의 위치를 정리하면 이렇습니다. 학계의 Reflection 단계 메커니즘을 매니지드 형태로 제공하면서, 운영 자율성을 세 단계 슬라이더(built-in/overrides/self-managed)로 조절할 수 있게 한 구조입니다. AgeMem 같은 RL 기반 정책 학습은 들어 있지 않고, Experience 단계의 cross-trajectory abstraction을 자동화하지도 않습니다. 그건 사용자가 self-managed 모드에서 직접 구현하거나, 아예 별도 학습 파이프라인을 두어야 하는 영역입니다.
정리 — 메모리 설계에서 챙겨야 할 것들
세 갈래를 따라오면서 몇 가지 일관된 원칙이 보입니다.
STM과 LTM을 처음부터 분리하는 것이 첫 번째입니다. 컨텍스트 윈도우만 늘리는 방식은 latency와 비용에서 빠르게 한계에 부딪힙니다. Mem0의 1.44초 대 17.12초 차이가 이를 직접적으로 보여줍니다. STM은 raw event 그대로, LTM은 추출된 형태로 두 계층을 명확히 구분하는 게 출발점입니다.
extract → consolidate → retrieve 흐름을 명시화하는 것이 두 번째입니다. Mem0와 AgentCore가 거의 같은 단계 구성을 채택하고 있는 건 우연이 아닙니다. raw event를 LTM에 그대로 쌓으면 신호가 잡음에 묻히고, retrieve 단계만 다듬어서는 부족합니다. extract와 consolidate가 메모리 품질의 대부분을 결정합니다.
메모리 정책을 어디까지 학습 가능하게 만들 것인가가 세 번째 결정 포인트입니다. AgeMem처럼 메모리 연산을 tool action으로 노출하고 RL로 학습시키면 자율성이 높아지지만, 학습 비용과 안정성 부담이 따라옵니다. 매니지드 서비스의 built-in 전략처럼 hard-coded 정책을 받아쓰면 운영은 단순해지지만 도메인 적합도는 떨어질 수 있습니다. 자율성 슬라이더의 어디에 자리 잡을지가 시스템마다 달라야 합니다.
마지막으로 서베이가 제시한 driver 세 가지(long-range consistency, dynamic environment, continual learning)를 명시적 요구사항으로 두는 것입니다. 메모리가 production에서 풀어야 할 문제는 이 세 축에서 나옵니다. 어느 축이 가장 중요한지에 따라 Storage 단계 RAG로 충분할지, Reflection 단계 정제가 필요할지, Experience 단계 RL까지 가야 할지가 갈립니다.
컨텍스트 윈도우는 계속 늘어나겠지만, 에이전트의 기억은 윈도우 안이 아니라 윈도우 바깥의 메모리 계층이 만들어냅니다. 2026년의 production 에이전트가 작년과 가장 다른 점은, 메모리 설계를 더는 사후 최적화로 미루지 않는다는 데 있습니다.
References
- Hongzhan Lin et al., From Storage to Experience: A Survey on the Evolution of LLM Agent Memory Mechanisms, ACL 2026 Findings
- Mem0 team, Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory, ECAI 2025
- Yi Yu et al., Learning Unified Long-Term and Short-Term Memory Management for Large Language Model Agents, arXiv cs.CL, 2026
- AWS, AgentCore Memory Strategies, Bedrock AgentCore Developer Guide
- AWS, Built-in Memory Strategies, Bedrock AgentCore Developer Guide
- AWS, Amazon Bedrock AgentCore now supports metadata for long-term memory records, AWS What’s New, 2026-05