
같은 백본 위에서 텍스트와 음성이 만나기까지
지난 글에서는 사람이 어떻게 소리를 내는지부터 시작해, 텍스트가 Mel-spectrogram을 거쳐 파형으로 바뀌는 2단계 TTS 파이프라인까지 정리했습니다. Acoustic Model이 중간 표현을 만들고, Neural Vocoder가 그걸 다시 들리는 소리로 복원하는 흐름이었죠.
그런데 그 글을 마무리하면서 한 가지 질문이 머릿속을 떠나지 않았습니다. “파이프라인의 각 단계 안에 들어 있는 모델 자체는 어떻게 발전해 왔을까?" 텍스트를 받는 쪽도, 음성을 다루는 쪽도, 결국은 데이터를 입력 받아 표현을 만들어내는 신경망입니다. 이 표현 학습이 어떤 과정을 거쳐 지금 모습이 됐는지를 들여다보지 않으면, 파이프라인 그림은 절반만 이해한 셈입니다.
그래서 이번 글에서는 세 갈래로 나눠 정리해 보려 합니다. 먼저 텍스트와 음성이 공통으로 올라타게 된 백본인 Transformer와 Self-Attention, 그 위에서 텍스트가 걸어온 길인 BERT → GPT → InstructGPT, 그리고 음성이 따라간 길인 wav2vec 2.0 → HuBERT → WavLM입니다. 두 모달리티가 어디서 갈라졌고 어디서 다시 만나는지, 흐름을 따라가 봅시다.
1. 공통 백본 — Self-Attention과 Transformer
왜 RNN/LSTM에서 갈아탔을까
Transformer 이전에는 sequence를 다루는 모델은 RNN, 그중에서도 LSTM이 사실상 표준이었습니다. 그런데 LSTM 기반 인코더-디코더 구조에는 두 가지 고질적인 약점이 있었습니다.
첫째, vanishing gradient입니다. RNN 계열은 backpropagation through time이라는 방식으로 학습하는데, gradient가 시간축을 따라 반복해서 곱해지다 보면 앞쪽 토큰이 뒤쪽 토큰에 미치는 영향이 거의 0으로 줄어듭니다. LSTM의 cell state와 gating이 이 문제를 어느 정도 완화하긴 하지만, 문장이 50–100 토큰을 넘어가면 성능이 눈에 띄게 떨어집니다.
둘째는 순차 처리의 비효율입니다. 현재 토큰의 hidden state ht를 계산하려면 직전 단계 ht-1이 먼저 나와야 합니다. 이 의존성 때문에 입력 토큰을 병렬로 처리할 수가 없고, GPU 코어 대부분이 사실상 놀게 됩니다.
2017년 Vaswani 외 7명이 NeurIPS에서 내놓은 “Attention Is All You Need”는 이 두 문제를 self-attention이라는 한 가지 연산으로 풀어버렸습니다. 모든 위치가 다른 모든 위치를 직접 참조하니, 위치 1과 위치 100 사이의 경로 길이가 O(1)입니다. LSTM에서는 O(n)이었으니, 장거리 의존성 학습이 훨씬 쉬워집니다. 게다가 모든 위치의 attention을 행렬 곱 한 번으로 동시에 계산하니 GPU 활용률도 자연스럽게 올라갑니다.
Q, K, V를 도서관 비유로 이해하기
Self-attention을 처음 봤을 때 가장 헷갈렸던 부분이 Q, K, V 세 가지 벡터입니다. 입력 token embedding 하나에 학습 가능한 가중치 행렬을 각각 곱해 세 벡터를 뽑아내는데, 도서관 비유로 보면 역할이 분명합니다. Query는 검색어(“뭘 찾고 있나?”), Key는 책 색인(“나는 이런 정보를 갖고 있어”), Value는 실제 본문(“내가 전달할 내용”)입니다. 검색어로 색인을 훑어 관련 있는 책의 본문을 모아오는 과정과 같습니다. 수식으로는 이렇게 됩니다.
Attention(Q, K, V) = softmax(QKT / √dk) · V
모든 Query와 Key 쌍의 dot product가 두 토큰의 관련도가 되고, softmax로 확률 분포로 만든 뒤 이 가중치로 Value를 합산합니다. 결과적으로 각 토큰은 자기와 관련 있는 다른 토큰의 정보를 골라서 가져옵니다.
 그림 1. 입력 token embedding 하나에서 Q, K, V 세 벡터가 분기되어 다른 위치들과 score를 계산하고, 그 가중치로 V를 모아 새 표현을 만든다.
그림 1. 입력 token embedding 하나에서 Q, K, V 세 벡터가 분기되어 다른 위치들과 score를 계산하고, 그 가중치로 V를 모아 새 표현을 만든다.
왜 √dk로 나눌까요? Dot product는 벡터 차원이 커질수록 값 자체가 커집니다. dk가 64일 때 분산이 64까지 올라가는데, 이 큰 값이 softmax에 들어가면 출력이 거의 one-hot처럼 되어버립니다. 한 토큰에만 attention이 몰리고 gradient가 사라져 학습이 진행되지 않죠. √64 = 8로 나눠주면 분산이 1로 돌아와서 softmax가 여러 토큰에 고르게 attention을 줍니다.
논문은 또 attention을 하나만 쓰지 않고 Multi-Head 구조로 8개를 병렬로 돌립니다. 512차원 입력을 64차원씩 나눠 head별로 독립 계산하는데, 한 head는 구문 관계를, 다른 head는 의미 유사도를 보는 식입니다. 계산량은 큰 차이 없이 여러 관점을 동시에 잡는 게 이득입니다. 그리고 recurrence를 없애면서 잃어버린 순서 정보는 positional encoding(sinusoidal)으로 보완합니다. 모델이 절대 위치가 아니라 상대 위치를 쉽게 학습할 수 있도록 sin/cos를 조합한 형태입니다.
이 구조 하나가 NLP만이 아니라 vision, audio, multimodal 영역까지 전부 바꿔놓았습니다. 제가 업무에서 다루는 Amazon Bedrock이나 SageMaker AI 위의 LLM 기반 서비스도 결국은 이 Transformer 위에 서 있습니다.
2. Language SSL의 진화 — BERT, GPT, 그리고 InstructGPT
같은 Transformer 위에서도 텍스트 분야는 두 갈래로 갈라졌습니다. 한쪽은 BERT, 다른 쪽은 GPT입니다.
BERT (2018) — 양방향 문맥을 보는 인코더
Devlin 외가 NAACL 2019에 내놓은 BERT(Bidirectional Encoder Representations from Transformers)는 이름 그대로 양방향 인코더입니다. 사전학습 목적은 Masked Language Modeling (MLM)으로, 입력 토큰의 약 15%를 가리고 그 자리에 무엇이 와야 하는지를 맞히는 task입니다.
핵심은 문장을 양쪽 방향에서 동시에 본다는 점입니다. “The man went to the [MASK] to buy milk.“에서 [MASK]를 채우려면 앞쪽 문맥만큼이나 뒤쪽 문맥도 봐야 하는데, RNN 기반 단방향 모델로는 어려웠던 일입니다. BERT는 한동안 자연어 이해(NLU) 분야의 표준이었습니다. 분류, 개체명 인식, 질의응답 같은 task에서 fine-tuning 한 번이면 강한 성능이 나왔습니다. (원 논문에는 Next Sentence Prediction이라는 두 번째 목적도 있었지만, RoBERTa 같은 후속 연구에서 별 효과가 없다는 게 알려지며 빠지는 추세입니다.)
GPT 계열 — 디코더-only로 가는 다른 길
같은 Transformer를 쓰면서도 GPT 계열은 다른 길을 갔습니다. Decoder-only 구조에 autoregressive language modeling(다음 토큰 예측) 목적을 붙이고, 모델 크기와 데이터를 계속 키웠습니다. GPT-1(2018)은 시작점이었고, GPT-2(2019)는 zero-shot을 보여줬습니다. 결정적이었던 건 GPT-3(2020)입니다. 175B 파라미터까지 키우면서, fine-tuning 없이 prompt에 예시 몇 개만 주면 새로운 task를 풀어내는 in-context learning이 본격적으로 등장했습니다.
그런데 GPT-3를 실제로 써본 사람들이 곧 깨달은 게 있습니다. 모델이 사용자 지시를 자주 무시하거나 사실이 아닌 내용을 그럴듯하게 만들어낸다는 점입니다. 원인은 학습 방식 자체에 있었습니다. 사전학습은 “인터넷 문서에서 다음 단어 맞추기"를 목표로 삼는데, 이건 “이 문장 번역해줘” 같은 사용자 요청과는 다른 문제입니다. 다음 단어를 잘 맞춘다고 해서 원하는 답이 나오는 건 아니죠. Ouyang 외(2022)는 이걸 misaligned objective라고 부릅니다.
InstructGPT (2022) — 정렬이 스케일을 뒤집다
InstructGPT는 이 미스매치를 사람의 피드백으로 좁히는 3단계 파이프라인을 제안합니다.
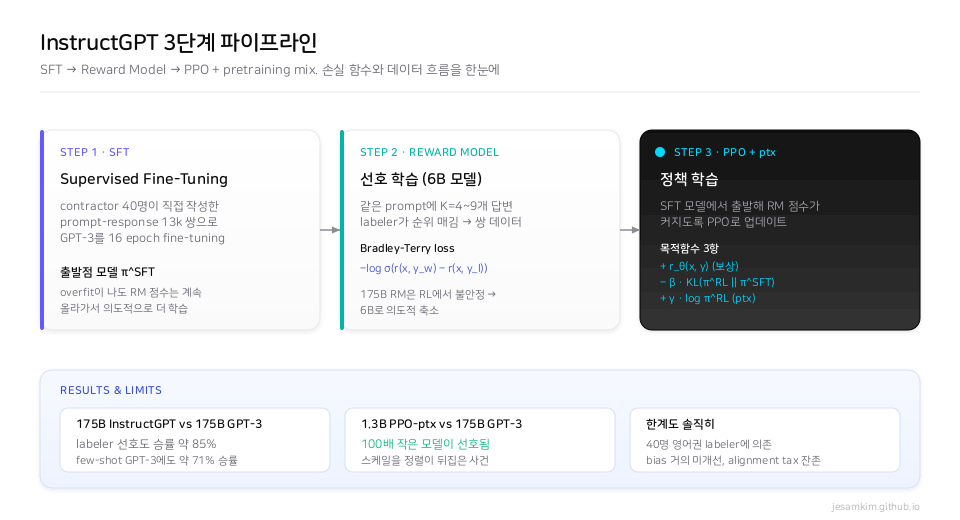 그림 2. InstructGPT 3단계 파이프라인. SFT로 출발점을 만들고, 사람 선호로 RM을 학습한 뒤, PPO로 정책을 업데이트한다. 핵심은 KL 페널티와 ptx 항.
그림 2. InstructGPT 3단계 파이프라인. SFT로 출발점을 만들고, 사람 선호로 RM을 학습한 뒤, PPO로 정책을 업데이트한다. 핵심은 KL 페널티와 ptx 항.
Step 1, SFT. 스크리닝을 통과한 contractor 40명이 prompt에 대한 좋은 답변을 직접 작성합니다. 이 13k 쌍으로 GPT-3를 16 epoch fine-tuning해서 SFT 모델을 얻습니다. 흥미로운 건 validation loss가 1 epoch 만에 overfit이 나는데도, RM 점수와 사람 선호도는 계속 올라가서 일부러 더 학습시킨다는 점입니다.
Step 2, Reward Model. 같은 prompt에 K개(보통 4–9개) 답변을 만들어 labeler가 순위를 매깁니다. 한 번 매기면 K개 중 2개를 뽑는 조합 수만큼의 “A가 B보다 낫다” 쌍 데이터가 나옵니다. 이 쌍들로 Bradley-Terry 손실을 최소화합니다. 좋은 답변 yw의 점수가 나쁜 답변 yl의 점수보다 커지도록, −log σ(r(x, yw) − r(x, yl))을 줄여나가는 형태입니다. RM은 175B가 아니라 6B 크기로 썼는데, 175B RM은 RL 단계에서 학습이 불안정해서 작은 게 낫다고 합니다.
Step 3, PPO + ptx. SFT에서 출발해 RM 점수가 커지도록 PPO로 업데이트합니다. 목적함수는 세 항으로 이루어집니다. RM 점수, SFT에서 너무 멀어지지 않게 잡는 KL 페널티, 그리고 pretraining 데이터의 log-likelihood(ptx)입니다. KL이 없으면 모델이 RM 점수만 노리고 이상한 답을 만드는 reward hacking이 생깁니다. ptx 항은 RLHF 후 SQuAD나 DROP 같은 NLP 벤치마크 성능이 떨어지는 alignment tax를 줄이려고 넣었습니다.
결과는 어땠을까요? 175B InstructGPT는 175B GPT-3 대비 약 85% 승률, few-shot GPT-3에도 약 71% 승률을 보였습니다. 그런데 한 가지 수치가 따로 눈에 띕니다. 1.3B PPO-ptx 모델이 175B GPT-3보다 사람 선호도에서 더 좋게 평가받았습니다. 100배 작은 모델이 100배 큰 모델을 이긴 사건이죠. GPT-3까지는 모델을 키우면 성능이 올라간다는 scaling이 전부였는데, 사람 피드백으로 정렬하는 방식이 100배 차이를 뒤집을 만큼 강력하다는 걸 이 논문이 보여줬습니다. TruthfulQA truthfulness가 약 2배, RealToxicityPrompts toxicity는 25% 감소.
한계도 분명합니다. 40명 영어권 labeler의 선호를 그대로 “인간 선호"로 일반화하긴 어렵고, Winogender나 CrowS-Pairs 같은 bias 벤치마크에서는 거의 개선이 없었다고 저자들이 그대로 적었습니다. alignment tax도 ptx로 줄긴 해도 0이 되진 않습니다. 그래도 이 논문이 중요한 건, 지금 쓰는 ChatGPT와 Claude 같은 chat 모델의 학습 방식이 결국 이 3단계 흐름을 따르기 때문입니다. SFT → 선호 데이터 → DPO 또는 PPO.
3. Speech SSL의 진화 — wav2vec 2.0, HuBERT, WavLM
이제 음성 쪽으로 넘어갑니다. 음성 표현 학습은 텍스트와는 다른 본질적 어려움이 있는데, 정리하면 네 가지입니다.
- Variable-length sequence: 같은 말을 빠르게도 천천히도 할 수 있어서 길이가 일정하지 않습니다.
- No segment boundaries: 텍스트의 단어처럼 자연스럽게 잘리는 단위가 없습니다. 파형은 연속된 한 덩어리입니다.
- Continuous: 이산 토큰으로 된 사전이 없습니다. 파형은 16-bit 정수 시퀀스이고, 같은 발음도 매번 조금씩 다른 값으로 찍힙니다.
- Tasks가 다양: ASR, speaker identification, emotion, separation, diarization 등. 한 모델로 모두 잘하기가 쉽지 않습니다.
wav2vec 2.0 (2020) — Contrastive 계열
Baevski 외의 wav2vec 2.0은 음성 표현을 self-supervised로 학습하는 대표적인 contrastive 계열 모델입니다. 원시 파형을 CNN encoder에 넣어 latent feature zt를 만들고, 이 latent에 quantization을 적용해 discrete한 qt를 얻습니다. z 일부를 mask 처리한 채 Transformer에 통과시켜 context 표현 ct를 뽑고, mask된 위치에 대해 “정답 qt가 같은 발화 안의 무작위 qt’들 사이에서 누구와 가장 가까운가"를 contrastive loss로 학습합니다. 핵심은 quantization으로 음성을 discrete하게 만들었다는 점이죠. 연속 신호를 토큰처럼 다룰 수 있게 되면서, 텍스트 self-supervised 도구를 음성에 옮겨올 길이 열렸습니다.
HuBERT (2021) — Predictive 계열
Hsu 외의 HuBERT(Hidden-Unit BERT)는 같은 문제를 다른 방식으로 풉니다. Negative sampling이 없는 대신, 오프라인으로 K-means clustering을 돌려 각 프레임에 pseudo-label을 미리 붙여 둡니다. 그러고 나서 BERT처럼 일부 구간을 mask 처리하고, mask된 위치의 cluster ID를 cross-entropy로 분류합니다.
음성의 네 가지 어려움이 모델 구성요소에 어떻게 매핑되는지를 보면 깔끔합니다.
- Variable-length / continuous → CNN encoder가 가변 길이 파형을 고정 간격 frame feature로 바꿉니다.
- No segment boundaries / no discrete vocab → 오프라인 K-means가 인공 토큰 사전을 만듭니다.
- Tasks가 다양 → Transformer + span masking으로 downstream에 일반화되는 표현을 학습합니다.
cross-entropy를 쓰니 학습이 안정적이고 negative sampling 설계 부담이 사라집니다. 1차 iteration K-means는 raw MFCC로 만들고, 다음 iteration부터는 모델 중간 layer hidden state로 다시 클러스터링하는 식으로 점진 개선합니다.
WavLM (2021) — Full-stack speech model
한 가지 의문이 남습니다. wav2vec 2.0이나 HuBERT 둘 다 ASR에서는 잘 했는데, 화자 식별이나 화자 분리, diarization 같은 다른 task에서는 효과가 크지 않았습니다. 왜 그랬을까요? 두 가지로 보입니다. 첫째, 사전학습 목적이 결국 “마스크 구간의 내용 맞히기"이다 보니 화자 정보를 굳이 보존할 필요가 없습니다. 둘째, 학습 데이터가 거의 전부 audiobook(Libri-Light 60k 시간)이라 한 명이 깨끗하게 읽는 음성뿐입니다. 카페에서 옆 테이블 대화가 섞이거나 두 사람 목소리가 겹치는 상황을 모델이 본 적이 없으니, 그런 입력을 처리할 줄 모르는 게 당연합니다.
Chen 외의 WavLM은 이 두 지점을 정면으로 공략했습니다. HuBERT를 베이스로 두고 세 가지를 바꿨습니다.
(1) Denoising masked speech modeling + utterance mixing. 입력을 만들 때 같은 batch 안의 다른 발화나 DNS challenge 잡음을 일부러 섞어 넣습니다. 그런데 정답 pseudo-label은 여전히 원본(메인 화자) 기준입니다. 모델은 어수선한 입력에서 메인 화자가 무슨 말을 했는지 골라내야 하니, 화자 분리와 잡음 제거 능력이 부수적으로 같이 학습됩니다. 손실 함수는 HuBERT와 동일하고, 입력이 깨끗한 x가 아니라 노이즈/오버랩된 x̂이라는 점만 다릅니다.
(2) Gated relative position bias. wav2vec 2.0이나 HuBERT가 쓰는 conv 기반 위치 임베딩은 고정값이어서, 같은 50ms 간격이라도 침묵 사이냐 발화 사이냐에 따라 의미가 다른 걸 반영할 수 없었습니다. WavLM은 query 벡터로 gate를 만들어 위치 bias 자체가 내용에 따라 적응되도록 했습니다. 직관적으로는 “지금 보고 있는 프레임이 음성이면 멀리까지 참조하고, 침묵이면 좀 무시해” 같은 동작이 가능해집니다.
(3) 94k 시간 데이터. Libri-Light 60k에 GigaSpeech 10k(팟캐스트, YouTube)와 VoxPopuli 24k(유럽의회 녹음)를 더했습니다. 도서 낭독만 보던 모델이 이제 대화체와 회의 음성도 보게 되면서, 음성 SSL의 오랜 약점이었던 audiobook 편향을 양과 다양성 양쪽으로 줄였습니다.
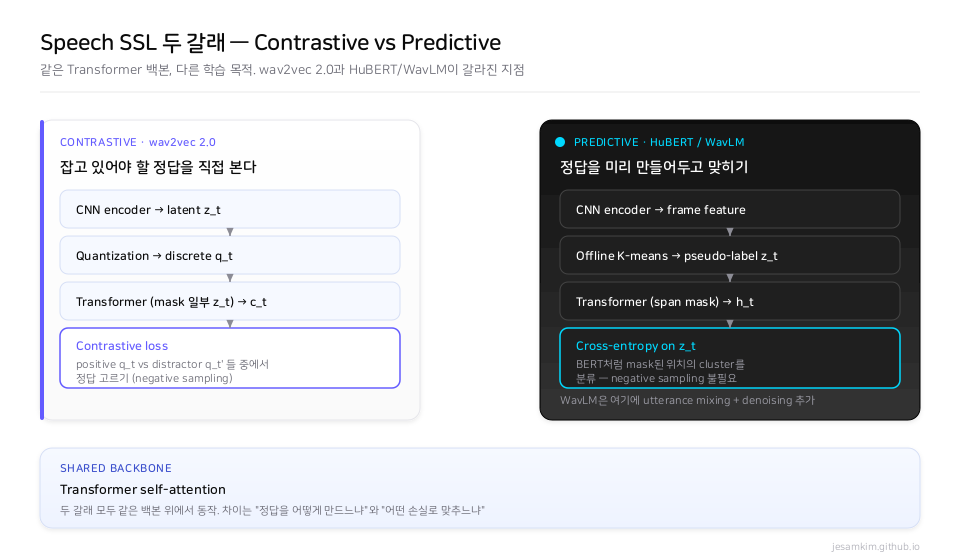 그림 3. 같은 Transformer 백본 위에서, wav2vec 2.0은 contrastive loss와 negative sampling으로, HuBERT/WavLM은 오프라인 pseudo-label과 cross-entropy로 표현을 학습한다. WavLM은 거기에 utterance mixing과 gated rel-pos를 더했다.
그림 3. 같은 Transformer 백본 위에서, wav2vec 2.0은 contrastive loss와 negative sampling으로, HuBERT/WavLM은 오프라인 pseudo-label과 cross-entropy로 표현을 학습한다. WavLM은 거기에 utterance mixing과 gated rel-pos를 더했다.
결과는 SUPERB 벤치마크 10개 task에서 그대로 드러납니다. WavLM Large는 모든 task에서 HuBERT Large 대비 우위였고, overall 점수가 약 2.6 올라갔습니다. 더 흥미로운 건 WavLM Base+ (94M)이 HuBERT Large (316M)보다 좋다는 점입니다. 모델을 키우지 않고 학습 방식만 바꿔도 이 정도 차이가 난다는 뜻이죠. Speaker Diarization(CALLHOME, DER 기준)에서는 EEND-EDA 대비 약 12.6% 개선, Speech Separation(LibriCSS, WER 기준)에서는 Conformer 대비 약 27.7% 개선이 나왔습니다. ablation도 흥미롭습니다. denoising/mixing task만 빼도 speaker diarization 점수가 크게 나빠지는데(4.55 → 6.03, 낮을수록 좋음), utterance mixing이 화자 관련 능력의 거의 전부를 책임진다는 뜻입니다.
WavLM의 의미는 단순히 SOTA를 갈아치웠다는 것 이상입니다. 음성 SSL이 그동안 “ASR 잘하는 모델 만들기"에 갇혀 있던 걸, “full-stack speech model“로 끌고 나간 첫 시도라는 점이죠. wav2vec → wav2vec 2.0 → HuBERT까지의 흐름이 학습 목적을 다듬는 방향이었다면, WavLM은 학습 데이터를 만드는 방식 자체를 바꿔서 모델이 보지 못한 task까지 같이 학습되게 만들었습니다.
두 흐름이 만나는 곳
세 갈래를 따라오면서 한 가지가 점점 분명해집니다. 텍스트와 음성, 두 모달리티가 결국 같은 Transformer 백본 위에서 token으로 표현된다는 점이죠. BERT가 텍스트 토큰을 양방향 mask prediction으로 학습했다면, HuBERT는 음성 frame을 K-means cluster로 토큰화한 뒤 같은 mask prediction을 적용합니다. 이름만 다를 뿐 구조는 닮아 있습니다.
이 닮음이 의미하는 건 명확합니다. 텍스트와 음성을 같은 모델 안에서 다룰 수 있는 길이 열린다는 것이죠. 그래서 요즘 나오는 LLM 기반 음성 합성, 음성-텍스트 멀티모달 모델, 그리고 음성으로 직접 대화하는 에이전트 같은 흐름이 자연스럽게 따라옵니다. 어떤 모델이 이 다음을 정의할지는 아직 단정하기 어렵지만, 분기점은 분명히 표현 학습 단계에서 결정됩니다.
지난 글 마지막에 적었던 문장이 떠오릅니다. “기술을 쓰는 것과 이해하는 것은 다릅니다.” 이번 글을 정리하면서 그 말을 한 번 더 확인했습니다. ChatGPT에 마이크로 말을 거는 동작 하나가, 그 뒤에는 self-attention과 quantization과 K-means와 PPO가 겹겹이 쌓여 있는 결과였습니다. 다음 글에서는 그 위에 어떤 음성 합성 모델이 올라가는지를 따라가 보려 합니다.
References
- Vaswani et al., Attention Is All You Need, NeurIPS 2017
- Devlin et al., BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, NAACL 2019
- Brown et al., Language Models are Few-Shot Learners (GPT-3), NeurIPS 2020
- Ouyang et al., Training language models to follow instructions with human feedback (InstructGPT), NeurIPS 2022
- Baevski et al., wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations, NeurIPS 2020
- Hsu et al., HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units, IEEE/ACM TASLP 2021
- Chen et al., WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing, IEEE JSTSP 2022