
1. Introduction: 왜 지금 RL이 다시 뜨는가
2022년 ChatGPT 공개 이후 LLM 포스트 트레이닝의 중심은 RLHF(Reinforcement Learning from Human Feedback)였습니다. 그런데 RLHF는 까다로운 작업이었습니다. reward model을 따로 학습해야 했고, PPO 같은 RL 알고리즘은 하이퍼파라미터에 민감했으며, 분산 학습 인프라까지 필요했습니다. 2023~2024년에 DPO(Direct Preference Optimization)가 빠르게 확산된 것도 이런 이유였습니다. RL을 우회해서 선호 학습을 reward model 없이 직접 풀자는 접근이 매력적이었던 거죠.
흐름이 바뀐 시점은 2025년 1월입니다. DeepSeek-AI가 DeepSeek-R1을 공개하면서, “복잡한 RLHF 없이도, 규칙 기반 verifiable reward만으로 LLM의 추론 능력을 학습시킬 수 있다"는 것을 실증해버렸습니다. R1-Zero는 SFT(Supervised Fine-Tuning)도 거치지 않고 베이스 모델에 곧바로 RL만 적용했는데, AIME 같은 수학 벤치마크에서 reasoning 능력이 저절로 나타났습니다. 이 논문은 2025년 9월에 Nature에도 게재되며 학계에서 자주 인용됐습니다.
이후 1년 동안 후속 연구가 폭발적으로 쏟아졌습니다. ByteDance는 DAPO로 GRPO 알고리즘을 개량했고, Agentic RL이라는 새 분야가 굳어졌습니다. tool-use, multi-turn dialogue, long-horizon planning 같은 영역으로 RLVR(Reinforcement Learning with Verifiable Rewards)이 빠르게 확장되는 중입니다.
이 글은 그 1년의 흐름을 다섯 편의 논문으로 정리합니다. RLVR이 무엇이고, GRPO에서 DAPO로 어떻게 알고리즘이 진화했으며, Agentic RL이 어디로 가고 있는지 그리고 AWS 환경에서 RL 기반 fine-tuning을 검토할 때 고려할 점은 무엇인지를 살펴봅니다.
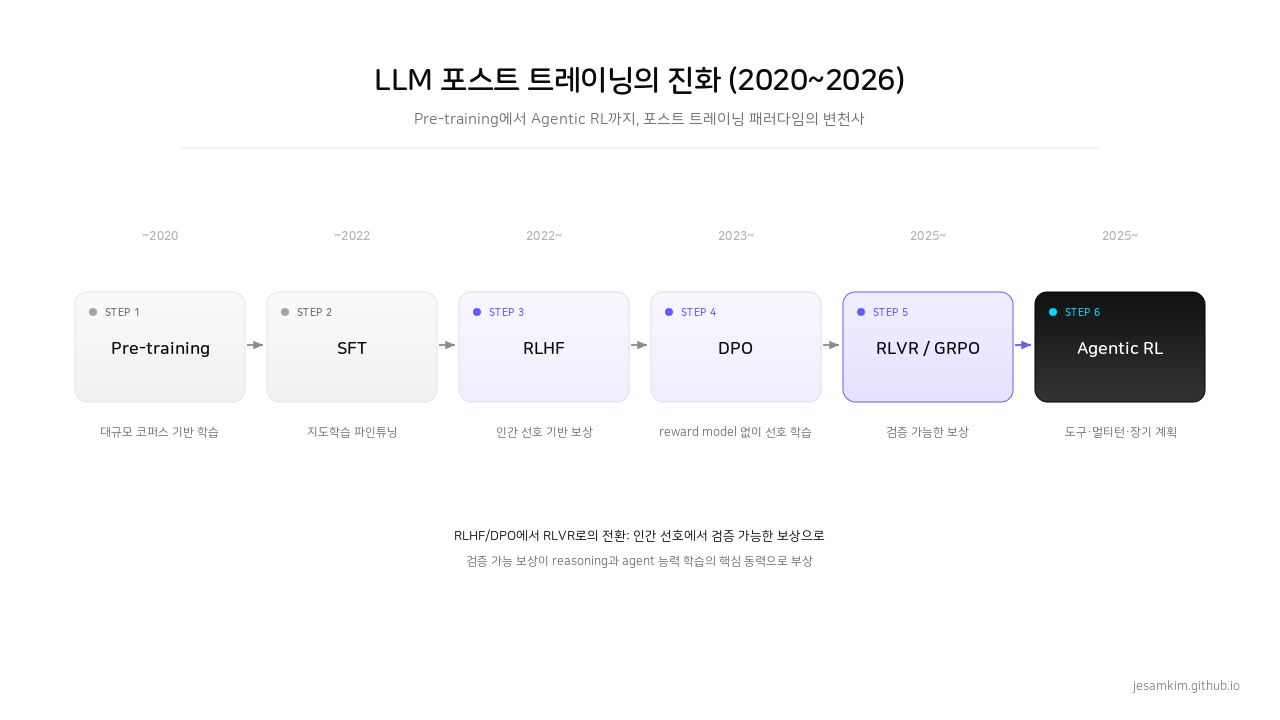
Pre-training부터 Agentic RL까지 LLM 포스트 트레이닝 패러다임의 진화.
다섯 편의 논문은 다음과 같습니다.
- DeepSeek-R1 (arxiv 2501.12948, Nature): RLVR의 전환점
- DAPO (arxiv 2503.14476): GRPO를 실전에서 쓸 만하게 다듬은 알고리즘
- RLVR/GRPO Dynamics (arxiv 2503.06639): GRPO가 왜 작동하는지에 대한 이론 분석
- Agentic RL Survey (arxiv 2509.02547): 에이전트 학습의 지형도
- Agentic Reasoning + Tool Integration (arxiv 2505.01441): tool-use를 RL로 학습하는 방법론
2. RLVR 개념 정리: Verifiable Reward가 바꾼 게임
RLHF의 가장 큰 비용은 reward model이었습니다. 사람이 응답 쌍을 비교 평가한 데이터로 reward model을 학습한 뒤, 그 reward model의 점수를 신호 삼아 정책 모델을 RL로 업데이트합니다. 단계가 하나 더 있다는 것 자체도 문제지만, 더 본질적인 한계는 reward model이 학습 과정에서 자주 drift한다는 점입니다. 정책이 reward model을 우회하는 방향으로 학습되면(reward hacking), 결과물은 reward는 높지만 사람이 보기에 이상한 출력으로 수렴합니다.
RLVR은 이 reward model 자체를 들어냅니다. 대신 자동 채점 가능한 verifier를 보상 신호로 씁니다. 다음 같은 작업이 그 대상입니다.
- 수학 문제: 정답을 알고 있으니 모델 출력을 정답과 비교해 0/1 보상을 줄 수 있습니다.
- 코드 생성: 테스트 케이스를 실행해서 통과 여부를 보상으로 씁니다.
- 구조화 출력: JSON schema 검증, 정규식 매칭 같은 형식 검증을 보상으로 씁니다.
이런 도메인에서는 사람이 매번 평가할 필요가 없습니다. 컴파일러, 인터프리터, 단위 테스트 러너, 정답 키 같은 결정론적 채점기가 이미 존재하니까요. 이 단순한 사실이 학습 파이프라인 전체를 바꿉니다. labeler가 사라지면 비용이 떨어지고, drift가 사라지니 더 오래 학습할 수 있고, 보상 신호가 결정론적이니 디버깅도 수월합니다.
DeepSeek-R1이 보여준 구체적 구성은 두 종류의 보상을 결합한 것입니다.
- Accuracy reward: 답이 맞았는가 (수학·코드 정답 비교)
- Format reward:
<think>태그 안에 추론 과정을 담고<answer>안에 최종 답을 담았는가
후자는 모델이 추론 흐름을 명시적으로 분리하도록 유도하는 장치입니다. 학습이 진행되면서 모델은 자연스럽게 <think> 안에서 길고 정교한 reasoning을 펼치는 쪽으로 정책을 발전시켰습니다.
여기서 중요한 점은 RLVR이 만능이 아니라는 사실입니다. 자동 채점 가능한 도메인에서만 작동합니다. 창작 글쓰기처럼 정답이 없는 작업에는 그대로 적용하기 어렵죠. 이 한계는 7장에서 다시 짚습니다.
3. 논문 ①: DeepSeek-R1 — RL만으로 추론 능력이 저절로 나타난다
DeepSeek-R1이 던진 핵심 메시지는 한 줄로 요약됩니다. SFT 없이 베이스 모델에 RL만 돌려도 reasoning 능력이 저절로 나타난다는 것입니다. 이걸 보여준 모델이 R1-Zero입니다.
R1-Zero의 학습 절차는 의외로 단순합니다. DeepSeek-V3-Base에 GRPO를 적용하고, 보상은 위에서 설명한 accuracy + format 두 가지만 씁니다. 그렇게 RL만 돌렸는데 AIME 2024 pass@1이 학습 전 15.6%에서 71.0%까지 올라갔습니다. 학습 곡선을 보면 모델 출력 길이도 시간이 지날수록 자연스럽게 길어집니다. 처음에는 짧게 답하던 모델이 학습 후반부에는 수천 토큰짜리 chain-of-thought를 자발적으로 생성합니다. 누가 시킨 게 아니라 보상 신호를 따라가다 보니 그렇게 됐다는 점이 중요합니다.
논문에 등장하는 “aha moment"는 이 현상의 구체적 사례입니다. 학습 중 어느 시점에 모델이 한 문제를 풀다가 “잠깐, 이 부분을 다시 확인해보자(Let’s reconsider…)” 같은 self-verification 패턴을 스스로 사용하기 시작합니다. 사람이 self-verification을 시키도록 prompt를 짜준 게 아니라, 보상이 높은 정책을 탐색하다가 모델이 그 행동을 발견한 겁니다. 이 사례는 “reasoning 행동은 학습 가능한 정책의 일부”라는 RLVR의 가설을 뒷받침합니다.
GRPO(Group Relative Policy Optimization) 자체도 잠시 짚어둘 필요가 있습니다. PPO는 critic(value function)을 따로 학습해야 해서 메모리·연산 비용이 큽니다. GRPO는 이걸 들어내고, 같은 prompt에 대해 여러 응답(group)을 샘플링한 뒤 group 내 상대적 reward로 advantage를 추정합니다. critic이 없으니 메모리 절감 효과가 크고, baseline은 그룹 평균이 자연스럽게 담당합니다. PPO의 근본 아이디어를 LLM 학습 환경에 맞게 단순화한 버전이라고 보면 됩니다. Cameron Wolfe의 GRPO 해설이 이 부분을 직관적으로 정리해두고 있어 참고할 만합니다.
R1-Zero에는 한계도 분명히 있습니다. 출력이 가독성이 떨어지고, 언어가 섞이는 현상(예: 영어와 중국어가 한 문장 안에서 혼용)도 나타납니다. 그래서 본 모델인 DeepSeek-R1은 cold-start SFT → RL → rejection sampling SFT → 추가 RL이라는 다단계 파이프라인으로 다듬었습니다. 그래도 학계가 인용하는 핵심 결과는 R1-Zero입니다. 베이스 모델에 곧바로 RL만 돌려도 reasoning이 저절로 나타난다는 사실 자체가 이전 RLHF 가정을 재검토하게 만든 지점이기 때문입니다.
Nature 게재(2025년 9월)는 또 다른 신호였습니다. LLM 학습 방법론이 Nature 본지에 올라간 사례는 흔치 않습니다. 그만큼 RLVR의 주장이 검증을 통과했고, 학계 주류가 이 흐름을 진지하게 받아들이고 있다는 뜻으로 읽을 수 있습니다.
4. 논문 ②③: GRPO에서 DAPO로 — 알고리즘 진화
GRPO가 R1을 가능하게 했지만, 실전에서 돌려보면 몇 가지 문제가 도드라집니다. ByteDance가 DAPO 논문에서 짚은 문제들은 다음 같습니다.
- Clip 대칭성 문제: PPO/GRPO의 clip은
1-ε과1+ε로 대칭입니다. 그런데 학습 후반부로 갈수록 entropy가 떨어지면서 모델이 “확신하는 토큰"만 반복 생성합니다. 탐색이 줄어드는 거죠. - Gradient 0 샘플 문제: 한 group 안의 응답이 전부 정답이거나 전부 오답이면, advantage가 모두 같아져서 gradient가 0이 됩니다. 학습 신호가 사라진 샘플이 배치를 차지하면서 효율이 떨어집니다.
- Sequence-level loss 문제: GRPO는 시퀀스 단위로 loss를 평균합니다. 긴 응답에서 나오는 저품질 토큰의 영향력이 희석됩니다.
- Overlong response 문제: max length를 넘긴 응답을 그냥 잘라버리면, reward shaping이 noise를 끼고 들어옵니다.
DAPO의 제안은 이 네 가지를 각각 다른 기법으로 다룹니다.
1. Clip-Higher는 clip을 비대칭으로 만듭니다. positive logratio(즉 정책이 더 자주 뽑으려는 방향)는 더 넓게 풀어주고(1+ε_high), negative logratio는 기존 그대로(1-ε_low) 둡니다. 모델이 새로운 행동을 시도할 여지를 더 주는 거죠. entropy 붕괴를 막고 탐색을 유지하는 효과가 있습니다.
2. Dynamic Sampling은 group 내 응답이 전부 같은 reward를 받는 prompt를 학습 배치에서 빼버립니다. gradient 0인 샘플을 제거하면 batch 효율이 올라갑니다.
3. Token-level Policy Gradient Loss는 sequence-level 평균 대신 token-level 평균을 씁니다. 긴 응답의 각 토큰이 동등하게 학습 신호에 기여하도록 만듭니다.
4. Overlong Reward Shaping은 max length 근처에서 부드럽게 패널티를 주는 reward shaping입니다. 잘라버리는 대신 점진적으로 reward를 깎아서 noise를 줄입니다.
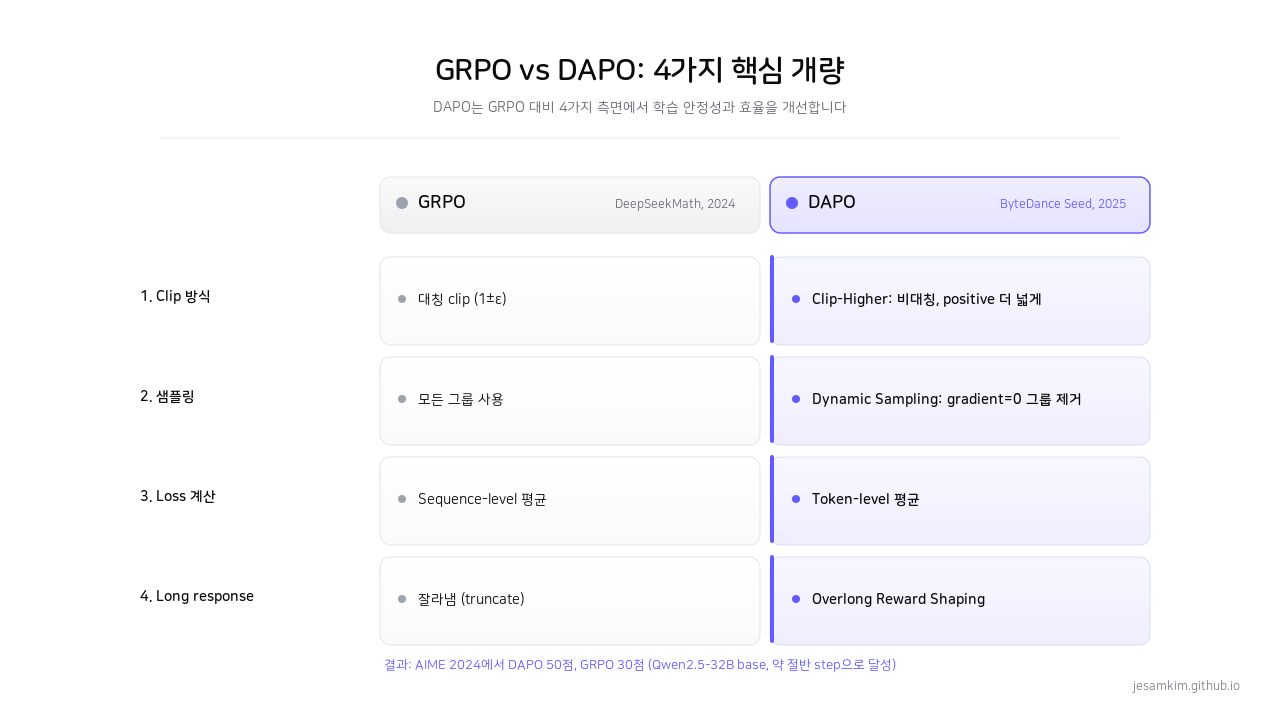
DAPO가 GRPO 대비 개량한 4가지 핵심 메커니즘.
성과는 명확합니다. Qwen2.5-32B 베이스 모델 기준으로 AIME 2024 pass@1이 GRPO로는 약 30점, DAPO로는 50점입니다. 더 주목할 점은 학습 스텝이 절반이라는 점입니다. 같은 자원으로 두 배 가까운 성능을 뽑은 셈입니다.
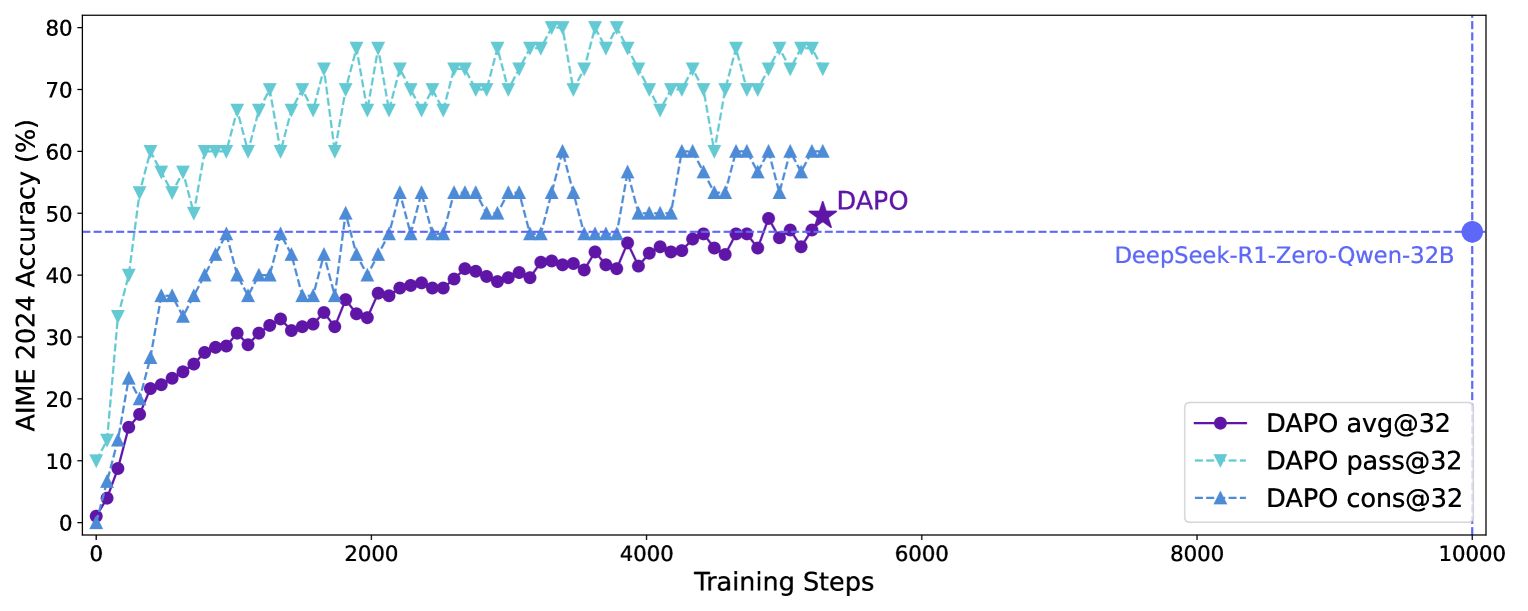
DAPO 학습 곡선: Qwen2.5-32B 베이스 모델 위에서 AIME 2024 avg@32/pass@32/cons@32. 수평 점선은 DeepSeek-R1-Zero-Qwen-32B의 avg@32 수준(47점)이며, DAPO는 이를 약 절반의 학습 스텝에서 추월합니다. 출처: Yu et al., DAPO (arxiv:2503.14476), Figure 1.
DAPO는 Clip-Higher 단일 기법만으로도 baseline 대비 학습 곡선이 뚜렷이 갈립니다. 같은 Qwen2.5-32B 환경에서 Clip-Higher 유무에 따른 AIME 학습 곡선은 아래와 같이 나타납니다. Clip-Higher 없는 GRPO(청록)는 평균 0.25 근처에서 정체하는 반면, Clip-Higher를 적용하면(보라) 0.35~0.40 구간까지 꾸준히 상승합니다.
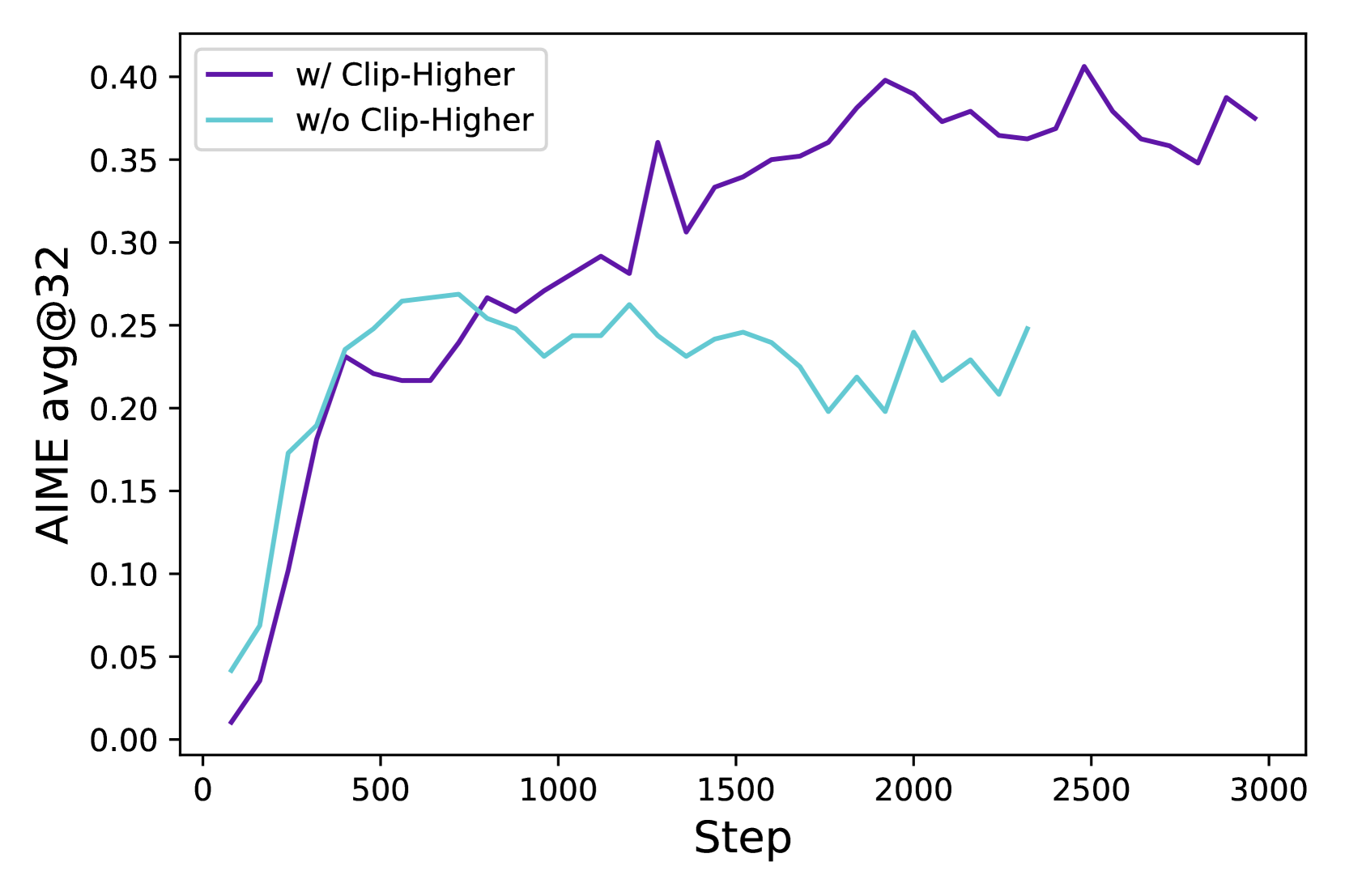
Clip-Higher 적용 전후의 AIME 학습 곡선 비교. 비대칭 clip이 entropy 붕괴를 막고 탐색을 유지시키는 효과가 수치로 드러납니다. 출처: Yu et al., DAPO (arxiv:2503.14476), Figure 2.
논문 ③인 Reinforcement Learning with Verifiable Rewards: GRPO’s Effective Loss, Dynamics, and Success Amplification는 더 이론적인 기여를 합니다. GRPO가 왜 작동하는지를 effective loss 형태로 분석합니다. 핵심 결과는 GRPO가 일종의 success amplification 메커니즘을 가진다는 것입니다. 베이스 모델이 어쩌다 한 번 정답을 맞히면, 그 정답 응답이 group 내에서 양의 advantage를 받고, 학습이 진행되면서 그 행동의 확률이 점점 증폭됩니다. 즉 RL이 새로운 능력을 만들어내는 게 아니라, 베이스 모델이 이미 가진 잠재 능력을 끌어올리는 쪽에 가깝다는 해석을 수학적으로 뒷받침합니다.
이 해석은 실무적으로도 중요합니다. RLVR이 만능이 아니라 베이스 모델의 sampling distribution에 0이 아닌 확률로 정답이 존재해야 학습이 진행된다는 의미니까요. 베이스 모델이 절대 풀 수 없는 문제는 RLVR로도 가르치기 어렵습니다.
5. 논문 ④: Agentic RL 지형도
R1과 DAPO가 다룬 것은 단일 턴 reasoning입니다. 모델이 prompt를 받고, chain-of-thought를 펼친 뒤, 하나의 답을 냅니다. verifier는 그 답을 채점합니다. 단순한 구조죠.
현실의 에이전트는 그렇지 않습니다. 도구를 호출하고, 결과를 받고, 다음 행동을 결정합니다. 검색을 하고, 코드를 실행하고, 다시 검색합니다. 한 번의 task 해결에 수십 번의 step이 들어갈 수 있습니다. RLVR을 이 환경으로 옮기려면 새로운 문제들을 풀어야 합니다.
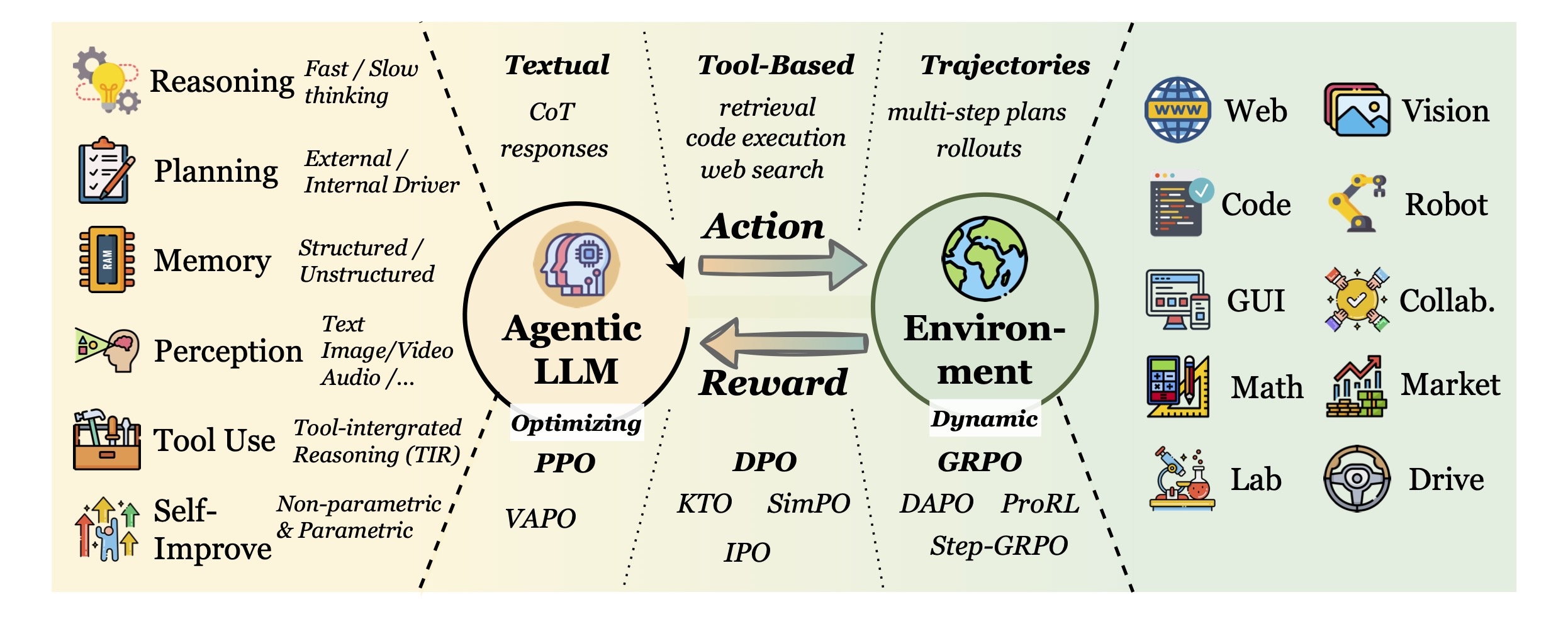
PBRFT에서 Agentic RL로의 패러다임 전환을 네 구역으로 펼쳐놓은 그림입니다. 맨 왼쪽은 모델의 capability(Reasoning, Planning, Memory, Perception, Tool Use, Self-Improve), 왼쪽 중간의 PBRFT 영역은 Textual CoT response를 action으로 쓰고 PPO/VAPO 계열로 학습됩니다. 오른쪽 중간의 Agentic RL 영역은 action space가 Tool-Based(retrieval/code/web search) 및 Trajectories(multi-step plans/rollouts)로 확장되고, environment가 동적(Dynamic)으로 바뀌며, 알고리즘은 GRPO/DAPO/ProRL/Step-GRPO 계열로 이동합니다. 맨 오른쪽은 이런 에이전트가 실제로 동작하는 environment 예시(Web, Vision, Code, Robot, GUI, Collab, Math, Market, Lab, Drive)입니다. 중앙부 DPO/KTO/SimPO/IPO는 두 영역을 잇는 preference 기반 알고리즘군입니다. 출처: Zhang et al., Agentic RL Survey (arxiv:2509.02547, v5), Figure 2.
Guibin Zhang et al.의 Agentic RL Survey는 이 지형을 정리한 종합 리뷰입니다. 2026년 4월에 v5까지 업데이트되며 빠르게 갱신되는 분야인데, 논문이 분류 축으로 제시한 항목은 다음 같습니다.
- Reward signal: 최종 task 성공 여부만 쓸지, 중간 step에 dense reward를 줄지
- Action space: 자연어 출력만인지, tool call이 포함되는지, GUI 클릭 같은 저수준 행동까지 포함하는지
- Horizon length: 한 step짜리 task인지, 수십~수백 step에 걸친 long-horizon task인지
- Tool integration: tool을 외부 black box로 둘지, 학습 가능한 모듈로 통합할지
이 분류 축이 의미가 있는 이유는, 각 축의 선택이 학습 난이도와 직결되기 때문입니다. 가장 어려운 조합은 long-horizon + sparse final reward + 넓은 tool action space입니다. credit assignment 문제가 폭발적으로 어려워집니다.
Credit assignment 문제는 이런 겁니다. 에이전트가 검색을 5번 하고 코드를 3번 실행한 뒤 답을 냈는데, 그 답이 틀렸습니다. 어느 step이 잘못된 걸까요? 첫 번째 검색이었나요? 코드의 두 번째 실행이었나요? 마지막 reasoning 단계였나요? RL은 “어떤 행동에 보상을 분배할지"의 문제인데, long-horizon에서는 이게 전통적인 RL 문제 그대로입니다. LLM 컨텍스트 안에서 풀어야 할 뿐입니다.
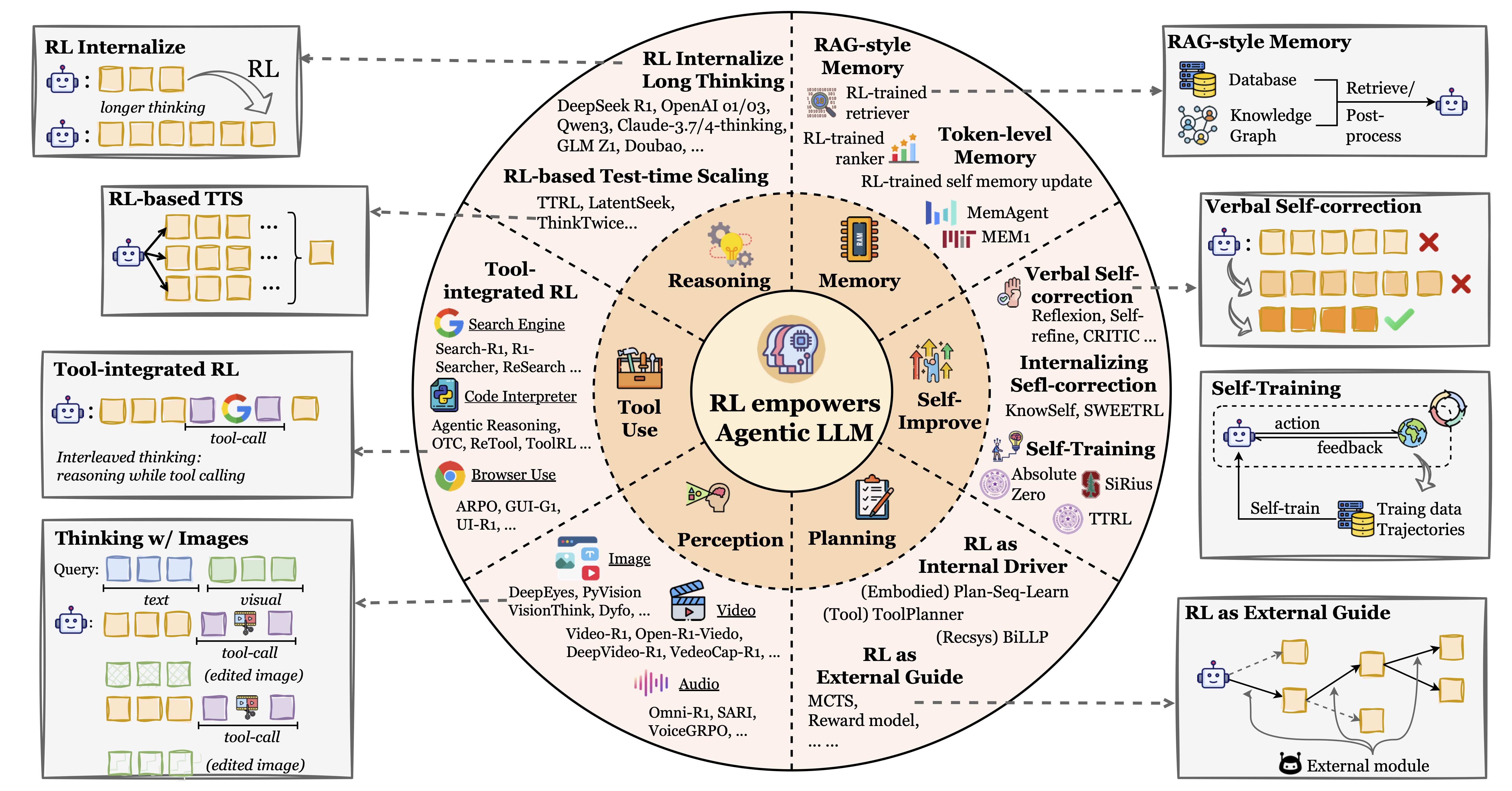
Agentic RL이 LLM에 부여하는 6가지 핵심 능력(Reasoning, Memory, Self-Improve, Planning, Perception, Tool Use). 각 영역별로 대표 논문과 기법이 정리되어 있습니다. 출처: Zhang et al., Agentic RL Survey (arxiv:2509.02547, v5), Figure 2.
Survey가 짚는 또 다른 이슈는 reward hacking입니다. tool을 쓸 수 있는 에이전트는 verifier 자체를 우회하는 방법을 학습할 수 있습니다. 코드 실행 환경에서 정답 파일을 직접 읽어버린다든지, 검색 결과를 그대로 복사하는 식으로요. verifier 설계를 잘못하면 모델은 “task를 푸는 정책"이 아니라 “verifier를 통과하는 정책"을 학습합니다.
최근 연구 흐름은 몇 가지로 갈립니다. deep research 에이전트(검색·논문 읽기·요약·인용을 long-horizon으로 통합), code execution 에이전트(코드 작성과 실행을 반복하며 디버깅), GUI automation 에이전트(브라우저나 앱을 조작) 같은 카테고리가 각각 다른 접근으로 발전 중입니다. 공통점은 RLVR을 단일 턴에서 멀티 턴으로 확장하는 것이고, 차이점은 environment의 결정성과 verifier의 설계입니다.
6. 논문 ⑤: Agentic Reasoning + Tool Integration via RL
Joykirat Singh et al.의 Agentic Reasoning and Tool Integration for LLMs via Reinforcement Learning은 위에서 말한 멀티 턴 학습을 구체화한 사례입니다. 이 논문이 흥미로운 이유는 reasoning과 tool use를 분리해서 다루지 않고 end-to-end RL로 함께 학습시킨다는 점입니다.
기존 ReAct 스타일은 prompt engineering에 의존합니다. 모델에게 “Thought: … / Action: search(…) / Observation: … / Thought: …” 같은 패턴을 예시로 주고, in-context learning으로 따라하게 합니다. 동작은 하지만 한계도 분명합니다. prompt를 어떻게 짜느냐에 성능이 크게 좌우되고, 새로운 도구가 추가될 때마다 prompt를 다시 설계해야 합니다. 더 본질적인 문제는, 모델이 “언제 도구를 부를지”, “도구 결과를 어떻게 해석할지"를 학습하지 않습니다. 그저 시연을 모방할 뿐입니다.

ARTIST의 rollout 구조. 정책 모델이 reasoning 토큰을 생성하다가 Tools 블록에서 외부 Environment와 상호작용(Action/Obs)한 뒤, Reasoning을 이어가 최종 Answer를 산출합니다. 보상은 최종 답의 정확성에서 오며, 이 전체 경로가 GRPO로 end-to-end 학습됩니다. 출처: Singh et al., ARTIST (arxiv:2505.01441), Figure 2.
이 논문의 접근은 다릅니다. 정책 모델이 reasoning 토큰과 tool call을 함께 생성하고, tool 실행 결과를 다시 컨텍스트에 받아 다음 행동을 결정하는 전체 trajectory를 RL로 학습합니다. 보상은 최종 task 성공 여부에서 옵니다. 그러면 모델은 자연스럽게 다음을 학습합니다.
- 어떤 종류의 질문에서 tool을 써야 하는지(예: 사실 확인이 필요한 질문에서는 검색, 계산이 필요한 질문에서는 코드 실행)
- tool 결과 중 어느 부분이 신뢰할 만한지
- 한 번의 tool call로 부족하면 어떻게 추가 호출을 구성할지
- 언제 멈추고 답을 낼지
prompt로 이걸 다 시키는 것과 비교하면 trade-off가 명확합니다. 학습 비용이 많이 들지만, 일단 학습되면 새로운 prompt 없이도 일반화가 됩니다. tool 인터페이스가 안정적인 환경에서는 이 학습 비용이 정당화될 수 있습니다.
논문의 실험은 multi-hop QA와 도구 기반 reasoning 벤치마크에서 진행됩니다. ReAct 스타일 prompting baseline 대비 의미 있는 개선을 보고합니다. 다만 한계도 솔직히 짚습니다. 학습 환경이 안정적이어야 한다는 점, tool 인터페이스가 자주 바뀌면 정책이 stale해진다는 점, 그리고 verifier 설계가 여전히 어려운 부분이라는 점입니다.
이 논문이 던지는 더 큰 의미는 패러다임의 이동입니다. “프롬프트로 시키던 행동을 학습으로 옮긴다”는 흐름은 ReAct뿐 아니라 다른 prompt-based 기법(self-consistency, reflection, planner-executor 분리 등)에도 똑같이 적용될 수 있습니다. 어떤 행동 패턴이 prompt engineering으로 안정적으로 유도될 수 있다면, 그건 RL로 학습되어 모델 가중치 안에 자리 잡을 가능성도 있다는 뜻이죠.
7. 엔지니어가 가져갈 포인트
다섯 편의 논문을 묶어서 보면 RL 기반 fine-tuning을 실제 환경에 적용할 때 챙겨야 할 고려사항이 정리됩니다. 특히 AWS 위에서 모델을 다루는 SA 입장에서 자주 받는 질문에 대한 가이드 형태로 정리해봅니다.
RLVR이 적합한 작업:
- 수학·논리 추론 (정답이 결정적)
- 코드 생성 (테스트로 채점 가능)
- 구조화 출력 (JSON schema, 정규식, 파서 통과 여부로 채점)
- SQL 생성 (실행 결과 비교)
- 함수 호출 인자 생성 (스키마 검증)
RLVR이 부적합한 작업:
- 창작 글쓰기 (정답 없음)
- 대화 자연스러움 평가 (주관적)
- 요약 품질 (정답이 여러 형태로 가능)
- 톤·스타일 매칭 (verifier 만들기 어려움)
부적합한 영역에서는 여전히 RLHF 또는 DPO가 합리적이고, 어떤 경우에는 SFT만으로도 충분합니다.
다음으로 RLVR의 구조적 한계 네 가지를 짚습니다.
1. Verifier 의존성. RLVR의 학습 품질은 verifier의 품질을 넘지 못합니다. verifier가 잘못 채점하면 그 오류가 그대로 정책에 학습됩니다. 수학·코드는 결정론적 채점이 쉽지만, 도메인이 복잡해질수록 verifier 설계 자체가 별도의 엔지니어링 과제가 됩니다.
2. Reward hacking 리스크. 모델은 verifier를 통과하는 가장 짧은 경로를 학습합니다. 만약 그 경로가 task 본질과 어긋난다면(예: 코드 실행 환경에서 정답 파일 직접 읽기), 결과는 보상은 높지만 가치 없는 출력이 됩니다. verifier의 sandboxing과 input 제어가 학습 만큼 중요합니다.
3. 긴 horizon에서의 credit assignment. Agentic RL에서 가장 어려운 문제입니다. dense reward를 잘 설계하지 못하면 학습이 매우 느려지고, 잘못 설계하면 모델이 reward shaping의 의도를 우회합니다.
4. 탐색-활용 균형. DAPO의 Clip-Higher가 다루는 문제와 같은 맥락입니다. 학습 후반부에 entropy가 떨어지면서 정책이 좁은 행동만 반복하면 일반화가 무너집니다. RL hyperparameter tuning은 여전히 비교적 어두운 영역입니다.
AWS 환경 적용 시 체크리스트: 학습·서빙·에이전트 실행으로 나눠서 보면 정리가 쉽습니다.
1) 학습 단계 (RL fine-tuning)
- 베이스 모델 sampling distribution 확인: success amplification 이론에 따르면, 베이스 모델이 한 번도 정답을 못 맞히는 task는 RLVR로 학습이 안 됩니다. RL을 시작하기 전에 베이스 모델의 pass@k(k=10~64 정도)를 측정해 0이 아닌지 확인합니다.
- 학습 스택 선택: 2026년 5월 기준 Bedrock의 Custom Models는 SFT 위주이고, GRPO·DAPO 같은 RL 알고리즘을 직접 돌리는 경로는 제공되지 않습니다. RL 학습이 필요하면 SageMaker AI(또는 SageMaker HyperPod)에서 trl, verl, OpenRLHF 같은 오픈소스 프레임워크를 띄워서 돌리는 패턴이 일반적입니다. 32B 이상 모델은 HyperPod의 멀티 노드 클러스터가 운영 부담을 줄여줍니다.
- Verifier 환경의 결정성과 격리: AWS Lambda나 Fargate 위에 verifier를 격리해 돌리는 패턴이 안전합니다. 훈련 job에서 verifier에 외부 네트워크 접근을 주면 reward hacking 통로가 열립니다. 코드 실행형 verifier는 특히 sandboxing이 중요합니다.
- 모델 크기 vs 학습 비용 trade-off: GRPO/DAPO는 critic 메모리를 줄였지만, 같은 prompt에 여러 응답을 sampling하느라 inference 부담이 큽니다. 작게 시작해(예: 1~7B) 보상 설계·환경을 검증한 뒤 규모를 키우는 접근이 안전합니다.
2) 서빙 단계 (학습된 모델 운영)
- Custom Model Import로 Bedrock에 올리기: SageMaker에서 RLVR로 학습한 모델 가중치를 Bedrock Custom Model Import에 업로드하면 Bedrock InvokeModel API로 서빙할 수 있습니다. 학습은 SageMaker, 추론은 Bedrock이라는 분리가 가능합니다. 지원 아키텍처는 공식 문서에서 확인이 필요합니다.
- Model Distillation으로 크기 줄이기: Bedrock Model Distillation을 쓰면 RLVR로 학습한 teacher 모델의 응답을 student 모델이 흉내 내도록 SFT 기반 distillation을 돌릴 수 있습니다. 추론 비용이 걸림돌일 때 검토할 만한 경로입니다.
- SageMaker AI endpoint로 직접 서빙: Bedrock import가 아키텍처 호환 문제 등으로 어려우면 SageMaker AI 엔드포인트에서 직접 서빙하는 경로도 있습니다. 지연 특성과 비용 모델이 달라 요구사항에 맞춰 비교가 필요합니다.
3) 에이전트 실행 단계 (Agentic RL)
- AgentCore와의 결합: Agentic RL로 학습된 정책은 “tool call + reasoning” 시퀀스를 생성합니다. Bedrock AgentCore의 managed harness나 Agents for Amazon Bedrock 위에서 학습된 정책을 실행하면 tool catalog, 세션 관리, 관측성을 직접 만들지 않아도 됩니다. 학습은 오픈소스 스택, 실행은 AgentCore로 가는 분업이 자연스럽습니다.
- Tool interface 안정성: 에이전트 정책은 학습 시점의 tool 스키마에 의존합니다. 프로덕션에서 tool 스펙이 자주 바뀌면 정책이 빠르게 stale해집니다. tool 인터페이스를 계약(contract)처럼 관리하고, 변경 시 재학습 또는 재미세조정을 전제로 두는 것이 안전합니다.
4) 가장 먼저 던질 질문
- “이 task에 정말 RL이 필요한가”: SFT로 풀리면 SFT가 답입니다. SFT가 plateau에 닿고 그 이상의 reasoning 깊이가 필요할 때 RLVR을 검토합니다. RL은 인프라 비용과 운영 복잡성이 SFT보다 한 단계 더 높습니다. Bedrock이 제공하는 Custom Models(SFT) + Distillation 조합으로 충분한 경우도 많습니다.
마지막으로 한 가지 메타 관찰을 덧붙이고 싶습니다. 2024년에는 “DPO가 PPO를 대체할 것"이라는 분위기가 있었는데, 2026년 현재 흐름은 그 반대로 가는 중입니다. RL이 다시 중심에 왔습니다. 이는 단순한 알고리즘 유행이 아니라, verifiable reward라는 새로운 보상 설계 방법이 RL의 실용 비용을 크게 낮췄기 때문이라고 봅니다. 이 흐름이 지속되면, 앞으로 1~2년 안에 LLM 포스트 트레이닝의 표준 파이프라인은 SFT → DPO에서 SFT → RLVR(또는 그 후속 알고리즘)로 옮겨갈 가능성이 높아 보입니다.
References
- DeepSeek-AI. “DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.” arXiv:2501.12948, 2025-01-22 (v2: 2026-01-04). arxiv
- DeepSeek-AI. “DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning.” Nature, 2025-09-17. Nature
- Yu, Q., et al. “DAPO: An Open-Source LLM Reinforcement Learning System at Scale.” arXiv:2503.14476, 2025-03. arxiv / OpenReview
- Mroueh, Y. “Reinforcement Learning with Verifiable Rewards: GRPO’s Effective Loss, Dynamics, and Success Amplification.” arXiv:2503.06639, 2025-03-09. arxiv
- Zhang, G., et al. “The Landscape of Agentic Reinforcement Learning for LLMs: A Survey.” arXiv:2509.02547, 2025-09-02 (v5: 2026-04-17). arxiv
- Singh, J., et al. “Agentic Reasoning and Tool Integration for LLMs via Reinforcement Learning.” arXiv:2505.01441, 2025-04-28. arxiv
- Raschka, S. “The State of LLM Reasoning Model Training.” Ahead of AI, 2025. substack
- Wolfe, C. R. “GRPO: Group Relative Policy Optimization.” Deep (Learning) Focus, 2025. substack