
World Model이라는 단어가 자꾸 눈에 밟혔습니다. 2018년 Ha와 Schmidhuber가 제안한 V-M-C(Vision-Memory-Controller) 구조가 요즘 다시 회자되는데, 로보틱스나 게임 환경이 아니라 금융 시계열에 붙여보면 어떤 그림이 될지 궁금했습니다.
V-M-C에서 M(Memory) 모듈은 “세상이 다음에 어떻게 움직일지"의 분포를 그려내는 시뮬레이터입니다. 금융 도메인에 옮겨놓으면 “내일 수익률이 어떤 모양으로 분포할까"를 학습으로 재현하는 역할이 됩니다. 이게 되면 그 위에 C(Controller)를 얹어 Sim-to-Real RL 트레이딩까지 이어질 수 있습니다. 이번 실험은 그 전 단계에 해당합니다. M 모듈을 Diffusion과 GAN 계열로 만들었을 때 베이스라인(Gaussian, Bootstrap, GARCH) 대비 얼마나 잘 재현하는지를 보려고 했습니다.
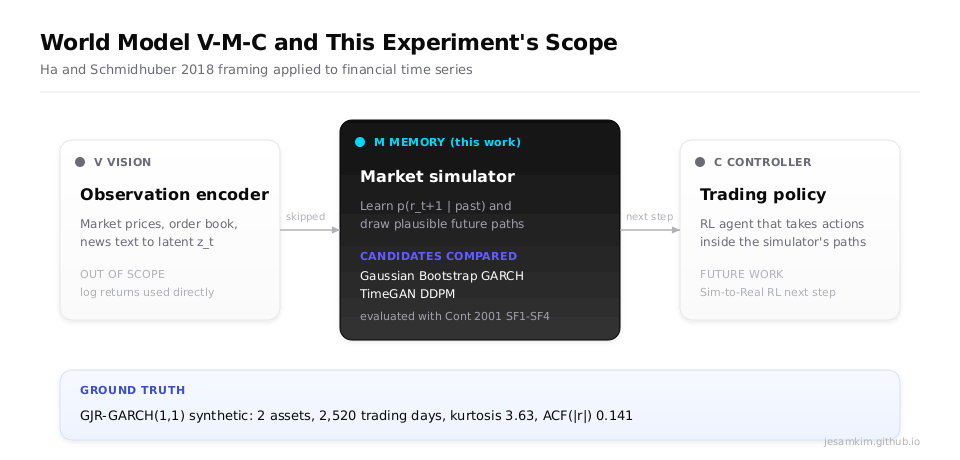
데이터를 KOSPI 실시세에서 합성으로 바꾼 이유
원래 KOSPI200 종목 10개를 10년치 받아 돌리려고 했습니다. yfinance로 데이터를 긁는 파이프라인은 다 짜뒀는데, 실행 단계에서 IP 제한에 막혔습니다. 이 지점에서 선택지가 둘이었습니다. 하나는 우회 경로를 찾아 실데이터를 받는 것, 다른 하나는 통계 속성이 통제된 합성 ground truth로 전환하는 것이었습니다. 후자를 골랐습니다. 벤치마크 비교가 목적이니 “실데이터에 가까운 통계"를 모사할 수 있으면 충분하다고 판단했습니다.
합성 데이터는 종목 2개짜리 GJR-GARCH(1,1) 프로세스로 생성했습니다. 대형주 두 개가 서로 어느 정도 상관을 가지고 함께 움직이는 상황을 떠올리면 됩니다. Glosten, Jagannathan, Runkle가 1993년에 제안한 GARCH 확장판으로, 파라미터만 잘 잡으면 금융 수익률의 핵심 특성을 전부 내재시킬 수 있습니다.
파라미터는 ω=1×10-6, α=0.06, β=0.90, γ=0.04로 잡았습니다. 역할은 이렇습니다.
- ω는 장기 평균 분산의 하한. 너무 작으면 분산이 죽고, 너무 크면 꾸준히 출렁입니다.
- α는 ARCH 항. “어제 수익률이 컸으면 오늘 변동성도 크다"는 효과를 만듭니다.
- β는 GARCH 항. 변동성의 지속성(persistence)입니다. 0.90이면 어제 변동성의 90%가 오늘로 이어집니다.
- γ는 leverage 항. 음의 수익률이 다음 기 변동성을 더 끌어올리는 비대칭성입니다.
두 종목은 서로 상관을 가지도록 rt(B) = 0.6 · rt(A) + 0.8 · GJR-GARCH(seed=22) 식으로 연결했습니다. seed=42로 고정해서 2,520 거래일(약 10년) 길이의 일간 로그 수익률을 뽑았습니다. 이걸 60일 rolling window로 자르면 (2461, 60, 2) 텐서가 됩니다. 첨도 3.63, ACF(|r|) lag1 = 0.141, 두 종목 사이의 상관 0.64. “평상시 대형주” 수준이라고 보면 맞습니다.
Cont 2001 Stylized Facts — 금융 시계열이 늘 보이는 네 가지 특징
Rama Cont가 2001년 Quantitative Finance에 정리한 stylized facts는 금융 수익률에서 반복적으로 관찰되는 통계적 특징입니다. 이번 실험에서는 이 중 네 가지를 잣대로 썼습니다.
SF1. Heavy tails (fat tail). 정규분포의 첨도(kurtosis)는 3인데, 실제 주식 일간 수익률은 4에서 8 사이입니다. “극단적 변동이 정규분포가 예측하는 것보다 훨씬 자주 일어난다"는 경험적 관찰이고, 이게 왜 블랙-숄즈의 내재가 자주 틀리는지의 핵심입니다.
SF2. 수익률의 자기상관 ≈ 0. 오늘 수익률이 양수였다고 내일도 양수일 가능성이 높지는 않습니다. 만약 자기상관이 뚜렷하면 누구나 그걸로 돈을 벌 테고, 차익거래가 그 패턴을 지워버립니다. 효율적 시장 가설의 약한 형태입니다.
SF3. 변동성 클러스터링. 수익률 자체의 자기상관은 0이지만, 절댓값 수익률의 자기상관은 양수입니다. “큰 변동이 큰 변동을 부른다"는 현상입니다. 평온한 시기와 격동의 시기가 몰려서 나타나는 이유가 이겁니다.
SF4. Leverage effect. 음의 수익률이 다음 기 변동성을 더 올리는 경향. 주가가 떨어질 때 패닉이 더 크다는 말로 풀 수 있습니다. Corr(r, r2)의 부호가 음수로 나오는 것이 정상입니다.
목표는 간단합니다. 모델이 생성한 합성 수익률이 이 네 가지 특징을 원본(Real)과 얼마나 비슷하게 가지고 있는가를 수치로 재는 것입니다.
모델 5종과 학습량
벤치마크 대상은 다섯입니다.
- Gaussian. i.i.d. N(0, σ2). 시간 구조가 없는 하한선입니다.
- Bootstrap. 실데이터에서 복원 추출. 통계적 유사도의 상한선이지만 새 시나리오를 만들지는 못합니다.
- GARCH(1,1) refit. 생성 후에 파라미터를 다시 추정해 재시뮬레이션. 계량경제 표준입니다.
- TimeGAN (Yoon et al., NeurIPS 2019). Embedder, Recovery, Generator, Discriminator 4-net에 Supervisor를 붙여 3-loss(embedding, supervised, joint)로 학습합니다.
- DDPM (Ho et al., NeurIPS 2020). 1D Conv 기반 ε-predictor로 학습하고 Algorithm 2로 역확산 샘플링합니다. 다변량은 CoFinDiff 스타일로 채널 스택.
학습은 NVIDIA A10G(24GB VRAM)에서 돌렸습니다. TimeGAN은 3-stage × 150 epochs로 약 33분, DDPM은 5,000 training steps로 약 5분 걸렸습니다. 두 모델 모두 seed=42 고정. 각 모델에서 (500, 60, 2) 합성 윈도우를 뽑아 평가용 샘플로 썼습니다.
결과 — DDPM은 GARCH보다 낫고, TimeGAN은 무너졌다
가장 압축된 한 장입니다.

초록은 실제값과 거의 일치, 노랑은 방향은 맞지만 크기 차이, 빨강은 부호가 반대이거나 값이 과장됐다는 뜻입니다. 임계값은 사전에 고정해뒀기 때문에 동일 데이터로 돌리면 재현됩니다.
지표별 구체 수치는 이렇습니다.
| 지표 | Real | Gaussian | Bootstrap | GARCH | TimeGAN | DDPM |
|---|---|---|---|---|---|---|
| Kurtosis (SF1) | 3.63 | 3.03 | 3.58 | 3.32 | 18.17 | 3.62 |
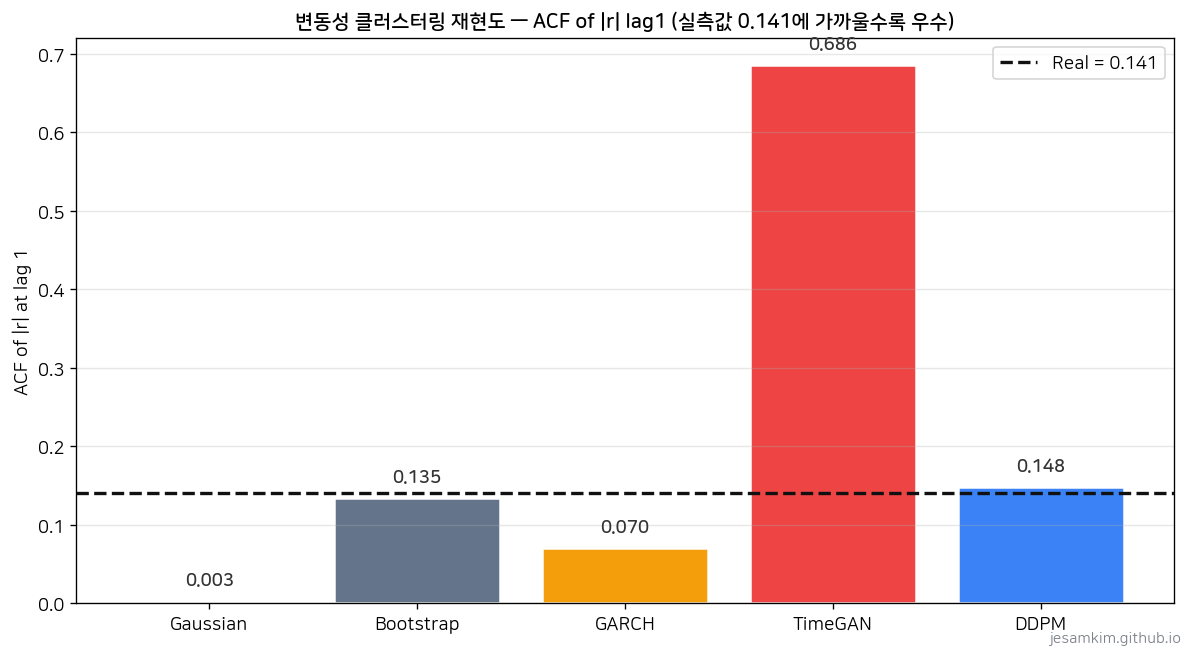
| ACF|r| lag1 (SF3) | 0.141 | 0.003 | 0.135 | 0.070 | 0.686 | 0.148 |
| ACF r lag1 (SF2) | 0.003 | -0.001 | 0.014 | 0.082 | 0.686 | 0.284 |
| Leverage (SF4) | 0.008 | 0.006 | 0.012 | 0.030 | -0.623 | 0.093 |
Kurtosis를 보면 DDPM의 3.62가 실측 3.63과 소수점 둘째 자리까지 맞습니다. GARCH의 3.32, Bootstrap의 3.58보다도 가깝습니다. 변동성 클러스터링을 재는 ACF(|r|) lag1은 더 놀랍습니다. DDPM 0.148이 실측 0.141에서 0.007만 벗어났고, 계량경제 표준인 GARCH(1,1) refit의 0.070보다 정확합니다.
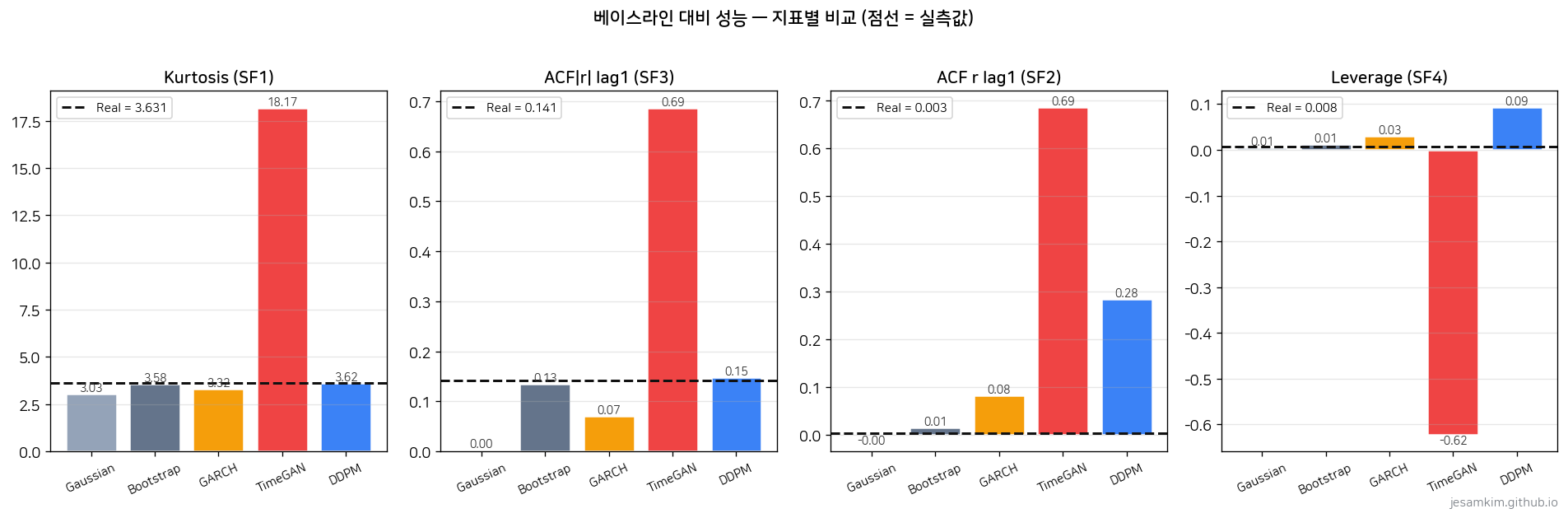
반면 TimeGAN의 kurtosis 18.17과 ACF 0.686은 얼핏 “fat tail을 엄청 잘 학습했다"처럼 보이지만 실상은 반대입니다. 독립 QA가 .npy 파일을 뜯어 보니 60,000개 샘플이 전부 음수였고, 4자리 반올림 기준 고유값이 24개뿐이었습니다. 값이 [-0.00970, -0.00337] 범위로 압축돼 ACF(r)과 ACF(|r|)이 0.686으로 정확히 같아지는 현상이 나타났습니다. 모든 값이 음수면 |−r| = −r이 되니까요. Leverage가 -0.623으로 실측 +0.008에서 한참 뒤집힌 것도 이 collapse 때문입니다. 즉 18.17은 fat tail 학습이 아니라 mode collapse 아티팩트입니다.
경로를 눈으로 보면 더 직관적입니다.
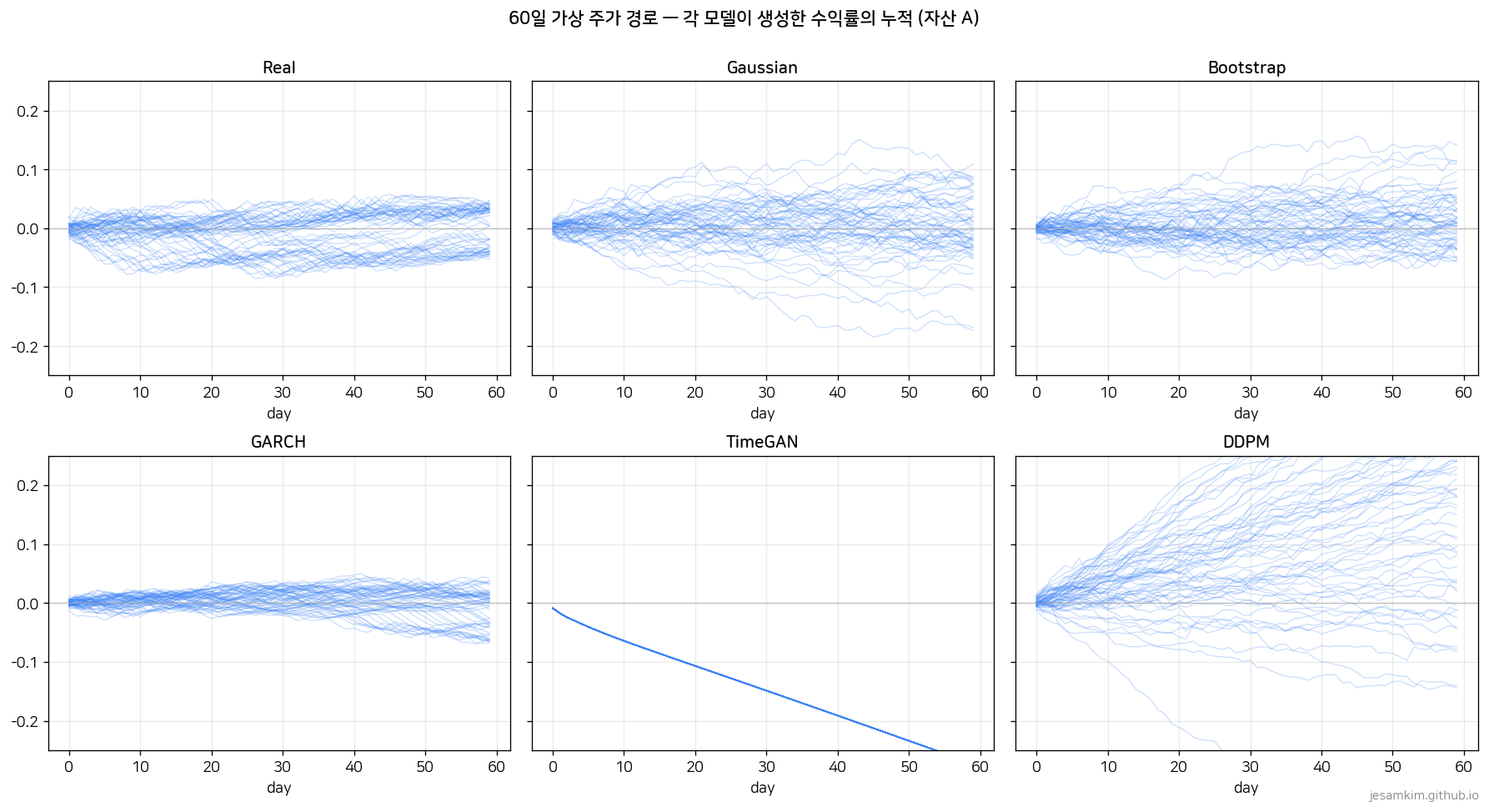
Real, Bootstrap, GARCH, DDPM은 퍼지면서 올라갔다 내려갔다 하는데, TimeGAN만 모든 경로가 일관되게 아래로 떨어집니다. 500개 경로를 겹친 분위수 부채꼴에서도 같은 패턴이 드러납니다.
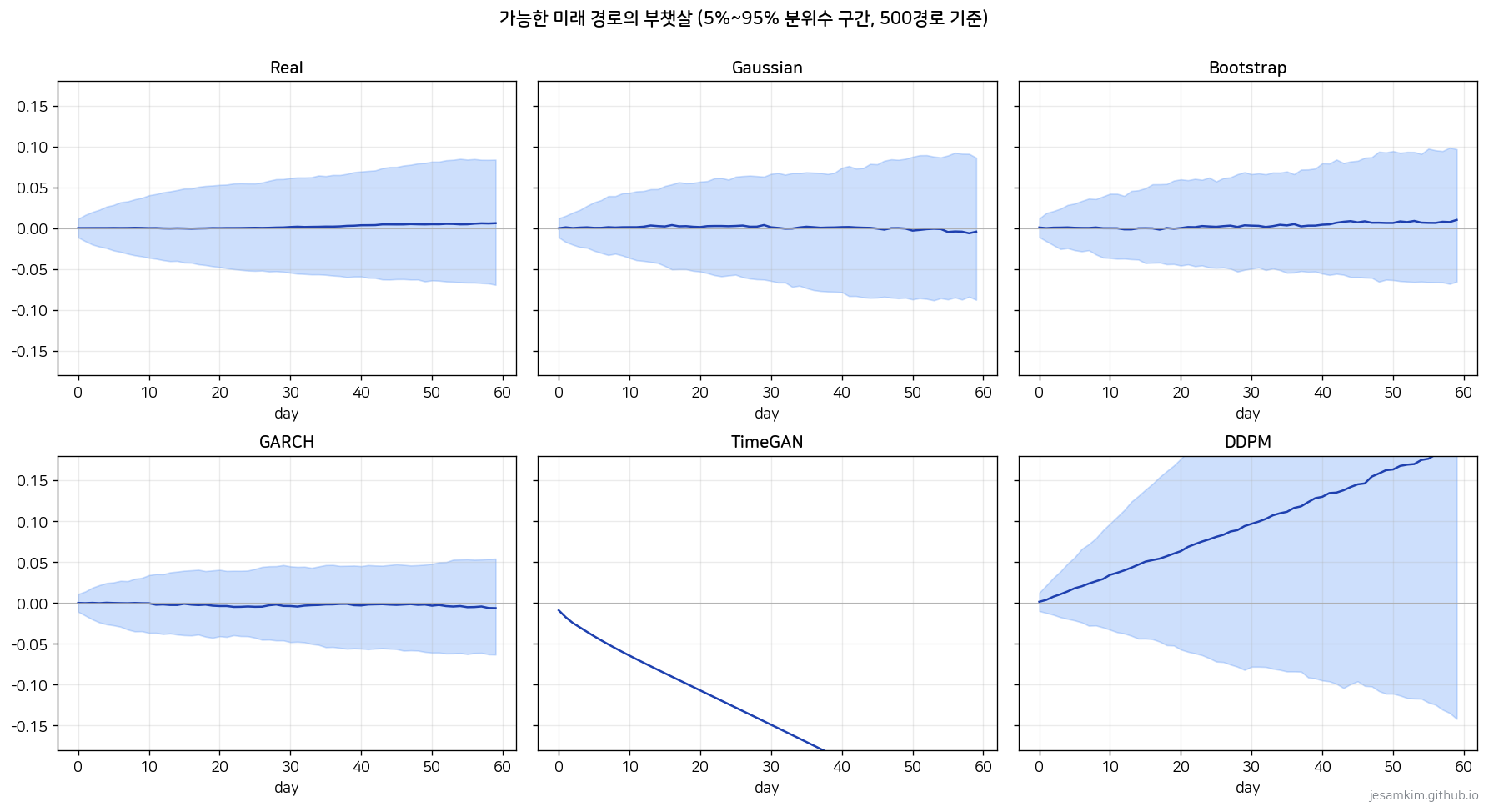
TimeGAN의 좁은 하락 띠는 “자연스러운 불확실성"이 아니라 분포가 한 점으로 쪼그라든 상태입니다.
무엇이 확인됐나
Diffusion이 GARCH(1,1) refit보다 변동성 클러스터링을 정확히 재현했습니다. DDPM의 ACF(|r|) 0.148은 실측 0.141에서 0.007밖에 벗어나지 않았고, 같은 지표에서 GARCH는 0.070으로 절반 수준에 머물렀습니다. 계량경제의 표준 도구를 학습 기반 모델이 넘어선다는 건, 변동성이 시간에 따라 몰려 나타나는 패턴을 파라메트릭 가정 없이 데이터로부터 복원할 수 있다는 뜻입니다. World Model의 M(Memory) 모듈 자리에 Diffusion 계열이 앉을 수 있다는 초기 증거가 나온 셈입니다.
Fat tail(SF1)도 학습으로 거의 완벽하게 복원됐습니다. DDPM의 kurtosis 3.62는 실측 3.63에 소수점 둘째 자리까지 맞았습니다. “극단적 변동이 정규분포가 예측하는 것보다 훨씬 자주 일어난다"는 금융 시계열의 고전적 특성이 학습 기반으로 복제된다는 뜻이고, 이는 곧 시뮬레이션 경로에서 tail risk가 과소평가되지 않는다는 말과 같습니다. 리스크 관리 관점에서 바로 쓸 재료입니다.
다만 DDPM이 “완전한 시장 시뮬레이터"라는 뜻은 아닙니다. SF2(raw return 무상관)에서 DDPM의 0.284는 이상적 0에서 꽤 벗어나 있습니다. SF1과 SF3에 강점을 보였다는 제한적 결론으로 읽는 게 맞습니다.
반대 방향의 교훈도 분명합니다. TimeGAN은 동일한 학습량에서 mode collapse로 무너졌습니다. 수치상 kurtosis 18.17, ACF 0.686처럼 얼핏 “fat tail을 잘 잡았다"처럼 보이지만, 실제로는 60,000개 샘플이 전부 음수로 쪼그라든 아티팩트였습니다. 이게 학습량 부족 때문인지 구조적 한계 때문인지는 단정할 수 없습니다. Yoon 논문 공식 repo 기본값은 50,000 iteration인데 이 실험은 450 iteration에서 끊었으니, 학습량 차이가 100배를 넘습니다. 그래도 “기본 설정으로는 무너진다"는 관찰 자체는 agent harness를 짤 때 염두에 둘 만한 정보입니다. 생성 모델을 M 모듈로 쓸 때 수치가 크다/작다만 보면 오독 가능성이 높고, collapse 여부와 샘플 다양성을 별도로 검사해야 한다는 점이 이 대비에서 드러납니다.
이 결론 자체가 베이스라인 3종 덕분에 가능했다는 점도 짚어둘 만합니다. DDPM의 kurtosis 3.62가 “좋은지"는 단독으로는 판단할 수 없습니다. Gaussian의 3.03이 있어야 시간 구조 학습이 된다는 것이 보이고, Bootstrap의 3.58이 있어야 재사용이 아닌 학습으로 저만큼 정확해졌다는 게 보이고, GARCH의 3.32가 있어야 파라메트릭 표준보다 낫다는 판단이 가능해집니다.
어떤 가능성을 봤나
이 실험은 “평상시 대형주 10년"을 모사한 합성 GT에서 진행됐습니다. 그 경계 안에서도 다음 단계가 꽤 구체적으로 보입니다.
(1) 조건부 생성으로 시나리오 공급기 만들기. 지금은 모델이 “학습 분포에서 랜덤하게 뽑은” 경로를 만듭니다. 여기에 realized volatility나 trend 같은 조건을 cross-attention으로 주입하면 “변동성 높은 시기의 경로 500개”나 “약세장 경로 500개”를 원하는 대로 생성할 수 있습니다. CoFinDiff가 제안한 구조가 이것이고, 이미 코드 레벨에서 붙일 수 있는 거리에 있습니다. 조건부 생성이 되면 이 합성 경로는 바로 스트레스 테스트용 시나리오가 됩니다.
(2) Sim-to-Real RL 트레이딩의 환경 시뮬레이터. World Model의 V-M-C 구조에서 M이 확보되면 그 위에 C(Controller)를 얹을 수 있습니다. FinRL 같은 프레임워크에 이번 DDPM이 생성한 경로를 환경으로 꽂으면, 실데이터로 과적합되기 쉬운 RL 정책을 먼저 합성 환경에서 훈련한 뒤 실제 시장으로 transfer하는 Sim-to-Real 파이프라인이 가능합니다. 일봉 단위에서는 이번 실험이 M의 하한선을 찍은 셈입니다.
(3) 위기 구간으로의 확장. 이번 GT는 leverage 부호가 +0.008로 약하게 양수로 뜨고(실제 시장은 -0.05 ~ -0.15로 음수), 2008이나 2020 규모의 스트레스 구간도 포함하지 않았습니다. GJR-GARCH의 ω와 γ를 더 공격적으로 잡아 위기 GT를 만들어 재평가하는 건 다음 자연스러운 단계입니다. DDPM이 평상시 구간에서 GARCH를 이겼다면, 위기 구간에서의 우위 여부는 그 자체로 중요한 연구 질문입니다.
(4) TimeGAN collapse의 원인 분리. 공식 repo 기본값이 50,000 iteration인데 이 실험은 450 iteration으로 끝났습니다. Epoch, hidden_dim, batch_size 3차원 스윕을 돌리면 “학습량 부족"인지 “구조적 한계"인지 분리할 수 있고, 그 결과는 GAN 계열을 금융 도메인에 쓸지 말지 판단할 때 공유 가능한 참고점이 됩니다.
실험 과정에서 배운 것
이번 실험에서 가장 많이 붙잡고 씨름한 것은 “무엇을 평가할 것인가"였습니다. Diffusion이나 GAN 같은 생성 모델 자체보다 베이스라인 3종(Gaussian, Bootstrap, GARCH)을 어떻게 끼워 넣을 것인지, Cont 2001의 네 가지 stylized fact를 어떤 지표로 수치화할 것인지, 각 수치가 어느 범위에서 의미를 갖는지를 정하는 설계 작업이 실험의 뼈대가 됐습니다. 학습 하이퍼파라미터, seed 고정, 500개 샘플 생성 같은 조건도 결과를 재현 가능하게 만들기 위해 꽤 촘촘하게 잡아야 했습니다.
코드 작성과 반복 실행은 Claude Code를 러너로 활용했습니다. 다만 모델이 내놓은 수치를 그대로 믿지 않기 위해 별도 세션의 QA subagent에게 .npy 샘플 파일만 넘겨주고 stylized-fact 24개 cell을 bit-exact 수준으로 재계산하게 했습니다. 메인 파이프라인과 QA가 서로의 결과를 모르는 상태에서 값이 일치해야만 통과시키는 구조였습니다.
이 과정이 없었다면 TimeGAN의 kurtosis 18.17을 “fat tail 학습 성공"으로 잘못 해석했을 겁니다. 숫자 자체는 커 보이지만 실제로는 mode collapse 아티팩트였고, 이건 메인 에이전트의 요약만 보면 놓치기 쉬운 함정이었습니다. LLM 기반 실험 파이프라인은 가드레일 없이는 허구를 생산할 수 있고, 가드레일은 반드시 독립 세션에서 원본을 재계산하는 방식이어야 한다는 것이 가장 크게 배운 점입니다.
베이스라인을 끼워 넣지 않았으면 “DDPM이 잘한다"는 주장은 선언에 그쳤을 겁니다. Gaussian, Bootstrap, GARCH 위에 놓여 있었기 때문에 어느 축에서 얼마만큼 이긴다는 정량적 결론이 나올 수 있었습니다. World Model이라는 큰 단어를 금융 도메인의 작은 한 조각에 붙여본 결과, 다음 방향을 이야기할 구체적 근거와 실험 습관 하나가 남았습니다.
References
- Ha, D., & Schmidhuber, J. (2018). World Models. arXiv:1803.10122. https://arxiv.org/abs/1803.10122
- Yoon, J., Jarrett, D., & van der Schaar, M. (2019). Time-series Generative Adversarial Networks. NeurIPS 2019. https://papers.nips.cc/paper/8789-time-series-generative-adversarial-networks
- Ho, J., Jain, A., & Abbeel, P. (2020). Denoising Diffusion Probabilistic Models. NeurIPS 2020. arXiv:2006.11239. https://arxiv.org/abs/2006.11239
- Tanaka, Y., Hashimoto, R., Takayanagi, T., Piao, Z., Murayama, Y., & Izumi, K. (2025). CoFinDiff: Controllable Financial Diffusion Model for Time Series Generation. arXiv:2503.04164. https://arxiv.org/abs/2503.04164
- Cont, R. (2001). Empirical properties of asset returns: stylized facts and statistical issues. Quantitative Finance, 1(2), 223-236. https://doi.org/10.1080/713665670
- Gretton, A., Borgwardt, K. M., Rasch, M. J., Schölkopf, B., & Smola, A. (2012). A Kernel Two-Sample Test. Journal of Machine Learning Research, 13, 723-773. https://jmlr.org/papers/v13/gretton12a.html
- Glosten, L. R., Jagannathan, R., & Runkle, D. E. (1993). On the Relation between the Expected Value and the Volatility of the Nominal Excess Return on Stocks. Journal of Finance, 48(5), 1779-1801. https://doi.org/10.1111/j.1540-6261.1993.tb05128.x