
2026년 4월 16일, Anthropic이 Claude Opus 4.7을 공개했습니다. 같은 날 GitHub Copilot, Cursor, Claude Code가 일제히 지원을 시작했습니다. 가격은 Opus 4.6과 동일한 입력 $5 / MTok, 출력 $25 / MTok이고 모델 ID는 claude-opus-4-7입니다. 1M 컨텍스트와 128k max output은 유지됐습니다.
가격이 그대로면 보통은 숫자만 바뀐 업데이트로 흘려보내기 쉽습니다. 그런데 이번 릴리즈는 숫자보다 파라미터의 문법 자체가 바뀐 편입니다. thinking 인터페이스가 바뀌었고, 새 파라미터 두 개가 추가됐고, 비전 해상도가 3.3배가 됐습니다. 프로덕션에서 Opus 4.6을 쓰고 있었다면 코드 몇 군데는 반드시 손봐야 합니다.
TL;DR
Opus 4.7은 “숫자만 오른 Opus 4.6"이 아닙니다. 다음 세 가지가 실무에 직접 닿습니다.
- 새 effort level
xhigh+ task budgets(beta): Anthropic 공식 문서가 “코딩과 에이전트 태스크에는xhigh로 시작하라"고 권장합니다(Claude Code 같은 특정 도구에 한정된 권고가 아니라 Opus 4.7 모델 자체에 대한 권고입니다). task budgets는 max_tokens와 별개로 모델이 스스로 페이스를 조절할 수 있는 advisory 예산입니다. - Adaptive Thinking이 유일한 thinking 모드:
thinking: {"type": "enabled", "budget_tokens": N}은 4.7에서 400 에러를 냅니다. 이제{"type": "adaptive"}하나만 남았고, 깊이는 모델이 결정합니다. Opus 4.6과 달리 thinking은 기본 꺼짐입니다. - 비전 3.3배: 입력 이미지 해상도 한계가 1568px(1.15MP)에서 2576px(3.75MP)로 확장됐습니다. computer use, 스크린샷 이해, 문서 OCR에서 체감됩니다.
전부 작은 변화처럼 보이지만, thinking은 breaking이고 effort는 agent 성능 곡선 자체를 바꿉니다.

두 개의 새 원시값: xhigh effort와 task budgets
Opus 4.7의 새 capabilities 중 가장 실용적인 건 effort 파라미터입니다. 공식 문서는 effort를 “요청 하나에 모델이 얼마나 많은 계산을 쓸지 제어하는 버튼"으로 정의합니다. 값은 none, low, medium, high, xhigh 다섯입니다. 4.7에서 새로 생긴 건 xhigh. 참고로 Claude Code CLI는 여기에 한 단계 더 위의 max까지 노출합니다(--effort 옵션: low, medium, high, xhigh, max). 즉 API effort 파라미터는 5단계지만, Claude Code 하니스 위에서는 xhigh로 부족할 때 max까지 올릴 수 있습니다.
문서가 명시적으로 적고 있는 권장은 이렇습니다: “Start with xhigh for coding and agentic use cases”. high도 아니고 medium도 아닌 xhigh로 시작하라는 것입니다.
이유는 단순합니다. 낮은 effort에서 Opus 4.7은 “의심스러울 땐 빨리 끝내는” 쪽으로 기웁니다. API 수준에서 보면, 모델이 생성하는 tool use block 수가 줄고 내부 reasoning 길이도 짧아집니다. 이 변화가 Claude Code나 Cursor 같은 agent harness 위에서는 “서브 에이전트 호출이 줄고 탐색이 얕아지는” 현상으로 드러납니다. 모델이 직접 서브 에이전트를 띄우는 게 아니라, 하니스가 모델의 tool call을 받아서 서브 에이전트를 spawn하는 구조이기 때문입니다. 품질이 중요하면 effort를 올려야 모델 쪽 억제가 풀리고, 하니스도 더 적극적으로 분기합니다.
effort와 별개로 task budgets이 beta로 나왔습니다. 베타 헤더 task-budgets-2026-03-13을 붙이고 output_config.task_budget을 주면 됩니다.
import anthropic
client = anthropic.Anthropic()
response = client.beta.messages.create(
model="claude-opus-4-7",
max_tokens=128000,
output_config={
"effort": "high",
"task_budget": {"type": "tokens", "total": 128000},
},
messages=[
{"role": "user", "content": "이 모듈 리팩터링 계획을 짜줘"}
],
betas=["task-budgets-2026-03-13"],
)
max_tokens와 task_budget은 다릅니다. max_tokens는 hard cap으로, 넘으면 응답이 잘립니다. task_budget은 advisory 신호입니다. 모델이 이를 기준으로 스스로 페이스 조절을 합니다. 쓸데없이 과하게 파고드는 걸 막고, 복잡한 문제에서는 예산 안에서 계획을 수립하게 하는 용도입니다. 짧은 분류 태스크나 한 번에 끝나는 요청에서는 오히려 방해가 되니 안 쓰는 게 낫습니다.
실무 감각으로는 task budgets가 agent 시스템에서 빛납니다. 에이전트가 자유롭게 tool을 여러 번 부르는 환경에서 “이 작업에는 이만큼만 써라"라는 신호를 줄 수 있습니다. max_tokens만으로는 이 신호가 전달되지 않았습니다.
Adaptive Thinking이 유일해졌다
이게 Opus 4.7의 가장 큰 breaking change입니다.
Opus 4.6까지는 thinking을 켤 때 thinking: {"type": "enabled", "budget_tokens": 10000} 같은 식으로 token budget을 직접 지정했습니다. 4.7에서 이 구문은 400 에러를 반환합니다. 이제 thinking은 adaptive 하나만 존재합니다. 깊이는 모델이 문제 복잡도를 보고 자체 판단합니다.
또 하나 덫: Opus 4.7은 thinking이 기본 꺼짐입니다. 4.6은 켜져 있었습니다. 4.6에서 별다른 설정 없이 내부적으로 thinking의 혜택을 보고 있었다면, 4.7로 업그레이드하는 순간 그 혜택은 사라집니다. 명시적으로 켜야 합니다.
# Before (Opus 4.6)
message = client.messages.create(
model="claude-opus-4-6",
max_tokens=16000,
thinking={"type": "enabled", "budget_tokens": 10000},
messages=[...],
)
# After (Opus 4.7)
message = client.messages.create(
model="claude-opus-4-7",
max_tokens=16000,
thinking={"type": "adaptive"},
messages=[...],
)
Anthropic의 설계 근거는 간결합니다. 내부 평가에서 adaptive thinking이 extended thinking budget 방식을 안정적으로 앞섰다는 것. 직접 써보면 왜 그런지 짐작이 갑니다. 개발자가 budget을 추측할 필요가 없어지고, tool use 중간에 일어나는 interleaved thinking이 자연스럽게 작동합니다. 간단한 요청엔 거의 생각을 안 하고, 복잡한 코딩 태스크엔 스스로 길게 파고듭니다.
한 가지 숨은 함정: thinking content가 기본적으로 응답에서 생략됩니다. 스트리밍 UI를 붙였다면, 4.6에서는 thinking 블록이 실시간으로 흘러왔지만 4.7에서는 긴 pause 뒤에 바로 output이 나옵니다. UX 관점에서 이게 싫으면 display: "summarized"로 요약을 받아볼 수 있습니다.
Vision 3.3배: 왜 중요한가
Opus 4.7의 비전 입력 해상도 한계가 1568px(1.15MP)에서 2576px(3.75MP)로 늘었습니다. 픽셀 기준 3.3배.
숫자 자체보다 의미가 중요합니다. 1568px은 full HD 스크린샷(1920×1080)을 다운샘플해야 들어가는 크기였습니다. 2576px은 스크린샷, A4 문서, 대시보드 캡처를 거의 원본 그대로 먹일 수 있는 크기입니다. 결과적으로 computer use, UI 스크린샷 분석, diagram/document understanding에서 좌표가 훨씬 정확해집니다.
특히 computer use 에이전트에게는 작지 않은 변화입니다. 이전에는 브라우저 스크린샷을 모델에 넣은 뒤, 모델이 찍어준 좌표를 원본 해상도로 scale-factor 곱해서 되돌려주는 후처리가 필요했습니다. 2576px까지 원본이 들어가면 이 scale-factor math가 사실상 사라집니다. 모델이 가리키는 좌표가 실제 픽셀 좌표와 1:1로 매핑됩니다. 작은 아이콘 클릭, 정밀한 bounding box, 표 셀 하나를 집어내는 식의 low-level perception에서 차이가 납니다.
트레이드오프는 분명합니다. 고해상도 이미지는 토큰을 더 씁니다. 불필요하게 큰 이미지를 통째로 넣는 건 낭비입니다. “정밀함이 필요한 화면이냐, 썸네일만 봐도 되는 화면이냐"를 호출 전에 한 번 판단해서 downsample하는 코드는 여전히 필요합니다.
벤치마크: 공식 수치만
Anthropic의 공식 발표에 실린 파트너 testimonials에서 숫자만 뽑았습니다. 조작이나 추정은 없습니다.
- Cursor (CursorBench): 58% → 70% (Opus 4.6 → 4.7)
- Notion: 멀티스텝 워크플로우 +14%, tool error는 1/3로 감소
- Rakuten-SWE-Bench: production task resolution 3x
- Harvey (BigLaw Bench): 90.9% at high effort
- Hex: “low-effort 4.7가 medium-effort 4.6와 대등”
- CodeRabbit: recall +10%
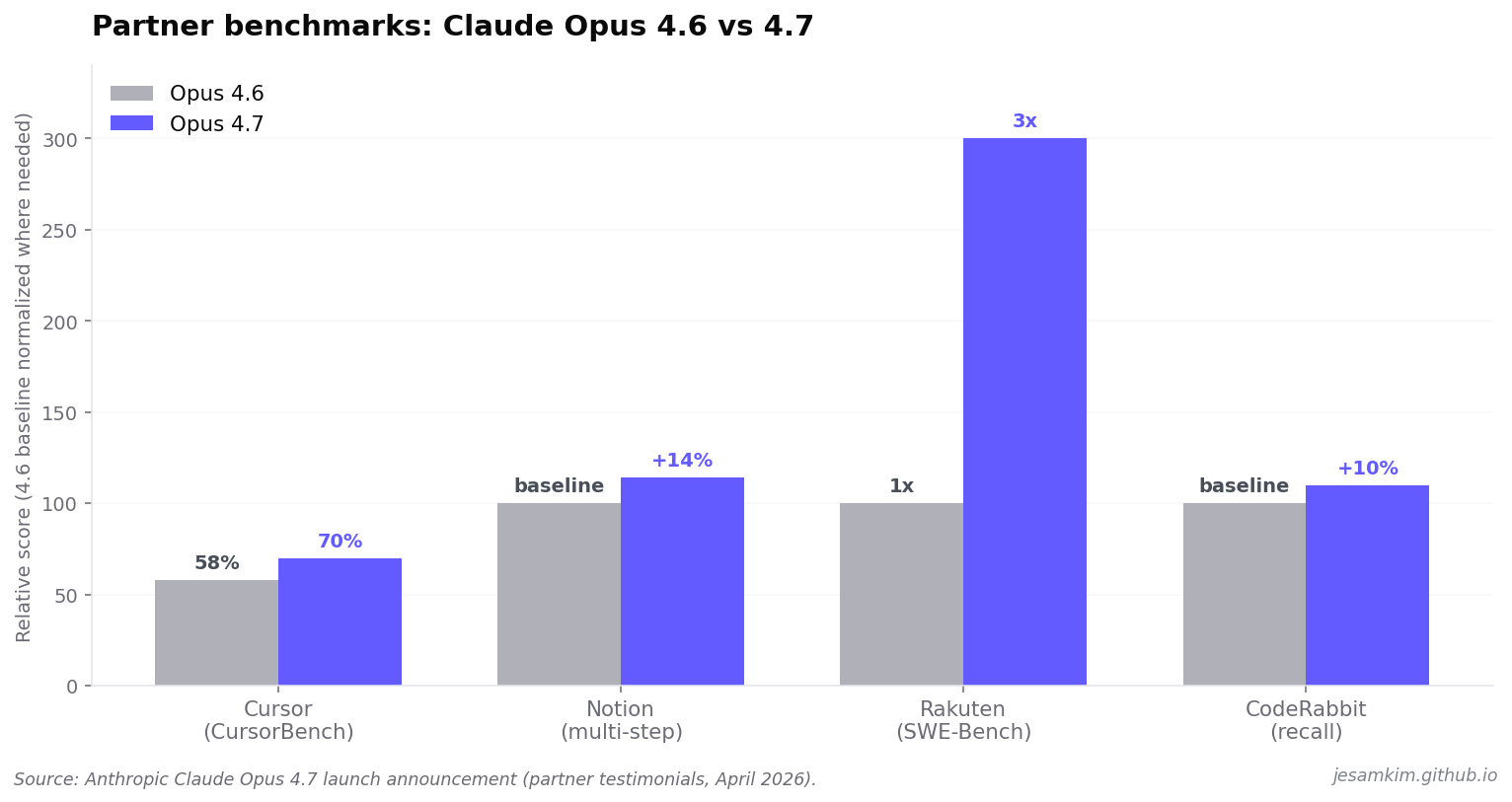
네 수치를 같이 놓고 보면 패턴이 있습니다. 평균적인 품질 상승보다 “같은 effort로 더 싸게, 높은 effort로 훨씬 깊게” 쪽에 가깝습니다. Hex의 증언(“low-effort 4.7 = medium-effort 4.6”)이 이 패턴을 요약합니다. 서브 에이전트를 Sonnet으로 돌리던 팀이 “이제 Opus 4.7 low-effort로 올려도 비용이 감당되네” 하는 판단을 할 수 있는 이유입니다.
Rakuten의 3x는 다른 숫자들과 결이 다른데, 이건 SWE-Bench 내부 변형에서 production task resolution rate가 3배로 올랐다는 보고입니다. 벤치 대상이 일반 SWE-Bench가 아니라 Rakuten 내부 과제이므로 직접 비교는 조심해야 합니다. 다만 “tool을 언제 쓸지"를 모델이 더 잘 판단한다는 점은 여러 파트너 testimony에서 공통으로 나타납니다.
프로덕션 마이그레이션 체크리스트
Opus 4.6 → 4.7 업그레이드에서 실제로 코드가 깨지는 지점들입니다. 공식 마이그레이션 가이드를 기준으로 실무 순서대로 정리했습니다.
- Extended thinking budget 제거.
thinking.budget_tokens를 쓰고 있다면 지웁니다.thinking: {"type": "adaptive"}로 바꿉니다. 기존{"type": "enabled", "budget_tokens": N}은 400 에러가 납니다. - Temperature, top_p, top_k 제거. 4.7에서는 지원하지 않습니다. 비결정성이 올라가니 프롬프트 수준에서 제어해야 합니다. 출력 포맷이 요동치면 JSON schema로 강제하거나 structured output을 쓰는 쪽이 낫습니다.
- 새 tokenizer 적용. 같은 한국어 텍스트가 4.6 대비 1~1.35배 더 많은 토큰으로 인코딩됩니다.
max_tokens를 그대로 두면 응답이 더 일찍 잘립니다. 컨텍스트 compaction 트리거와 비용 예측 로직도 재보정이 필요합니다. - Thinking content 기본 생략. 스트리밍 UI에서 “사용자가 보내고 나서 긴 정적” 현상이 생기면
display: "summarized"로 요약을 받아 중간 상태를 보여주는 식으로 피할 수 있습니다. - 더 literal한 지시 따르기. 특히 effort가 낮을 때 차이가 큽니다. 기존 프롬프트에서 “암묵적으로 알아서 해석하겠지” 하고 둔 부분이 있으면 재테스트해야 합니다. 반대로 말하면, 프롬프트를 명시적으로 쓰면 더 잘 따릅니다.
- 기본적으로 tool call을 덜 발생시킴. effort를 올리면 tool call 빈도가 다시 올라갑니다. Claude Code나 Cursor 같은 agent 하니스에서 서브 에이전트 호출이 확 줄었다면 이건 하니스 버그가 아니라 모델 동작 변경입니다. 필요하다면 effort를
xhigh로 올리는 것이 답입니다. Claude Code CLI를 쓰고 있다면xhigh로도 부족할 때--effort max까지 한 단계 더 올릴 수 있습니다(max는 Claude Code 전용, API에는 없음). - 실시간 사이버보안 안전장치. 4.7부터 사이버 공격 관련 요청은 실시간으로 차단됩니다. 합법적인 보안 연구 용도라면 Anthropic의 Cyber Verification Program에 신청해야 통과됩니다.
운영 패턴: Agent 하니스에서 모델을 어떻게 배치할까
여기서부터는 모델 스펙이 아니라 하니스 위에서 써본 운영 경험 쪽입니다. 필자가 쓰는 Claude Code를 기준으로 정리했습니다(Cursor, 자체 구현 에이전트에도 유사하게 적용됩니다).
프로덕션 agent 시스템을 돌려본 엔지니어는 알고 있을 겁니다. 모델 선택은 “가장 좋은 모델 하나"가 아니라 “어느 역할에 어떤 모델을 붙일 것인가"의 문제입니다. Claude Code 같은 하니스는 이 구조를 기본값으로 깔고 있습니다. 메인 에이전트가 하나, 서브 에이전트가 여럿입니다.
Opus 4.7이 나온 뒤 Claude Code에서 쓰는 모델 배치는 대체로 아래 범주로 정리됩니다.
품질 우선 — Claude Code / 연구·아키텍처 리뷰·장문 생성
- 메인 에이전트: Opus 4.7, effort
xhigh - 서브 에이전트: Opus 4.6 [1M] 또는 Opus 4.7 low-effort
- 근거: Hex의 파트너 testimony 기준 “low-effort 4.7 ≈ medium-effort 4.6"이므로 서브를 Opus 4.7 low-effort로 올리는 것도 옵션입니다. 비용이 부담되면 Opus 4.6 + 1M 컨텍스트 조합.
균형 — Claude Code / 일상 코딩·리팩터링·일반 agent 개발
- 메인 에이전트: Opus 4.7, effort
high - 서브 에이전트: Sonnet 4.6
- 근거: 메인이 plan과 judgment을 담당하고, 서브는 반복 작업을 싸게 처리. 비용과 품질의 스위트 스팟입니다. Claude Code 기본 권장에 가장 가까운 배치.
비용 우선 — 자체 구현 배치 파이프라인·대량 자동화
- 메인: Sonnet 4.6
- 서브: Haiku 4.5
- 근거: Opus급 판단력이 필요 없는 task — 스크리닝, 분류, 요약 생성 같은 반복 업무. 이 구간에서 Opus를 쓰면 과잉입니다.
가격만 떼어놓고 보면 Opus($15 / $75, Bedrock cached write/read 기준)와 Sonnet($3 / $15)의 격차는 5배입니다. 그래서 “서브까지 전부 Opus 4.6으로 올리세요"는 쉽게 추천할 수 없는 권고입니다. 다만 agent의 최종 산출물 품질이 중요할 때는, 메인 에이전트를 4.7 xhigh로 두는 것만으로도 Claude Code 전체 세션의 실수 누적이 체감될 만큼 줄어듭니다.
맺으며 한 가지. Opus 4.5~4.6 시절에는 “한 번에 모든 tool call을 해라"라거나 “plan을 먼저 출력해라” 같은 프롬프트 공학이 effort를 대신했습니다. 4.7은 이걸 스스로 합니다. “언제 tool을 쓸지, 언제 plan을 갱신할지"를 모델이 판단합니다. 엔지니어링의 중심도 조금씩 이동하는 중입니다. “LLM에게 무엇을 시킬지"에서 “LLM의 판단력을 어디까지 신뢰할지"로.
References
- Claude Opus 4.7 announcement — Anthropic, 2026-04-16
- What’s new in Claude 4.7 — Anthropic API docs
- Effort parameter — Anthropic API docs
- Task budgets (beta) — Anthropic API docs
- Adaptive thinking — Anthropic API docs
- Migration guide — Anthropic API docs
- Claude Opus 4.7 is generally available — GitHub Copilot changelog, 2026-04-16