
이전 글에서 Data Parallelism(DP)의 한계를 짚었습니다. activation memory는 GPU 수에 비례해 줄어들지만, parameter memory는 그대로입니다. 모델이 GPU 한 장에 들어가지 않으면 DP만으로는 학습할 수 없습니다.
Pipeline Parallelism(PP)은 이 문제에 대한 직접적 답입니다. 모델을 레이어 단위로 잘라서 여러 GPU에 배치합니다. GPU 0에 레이어 1–6, GPU 1에 레이어 7–12 식으로 분할하면, 각 GPU는 전체 모델이 아닌 일부분만 들고 있으면 됩니다.
문제는 효율입니다. 파이프라인 구조에서는 한 GPU가 연산하는 동안 다른 GPU들이 놀게 되는 pipeline bubble이 생깁니다. PP의 진화 역사는 곧 이 bubble을 줄여온 역사입니다.
1. Naive Pipeline: 1/N Utilization
가장 단순한 파이프라인을 생각합시다. N개의 GPU에 모델을 N등분하고, 하나의 mini-batch를 순서대로 처리합니다.
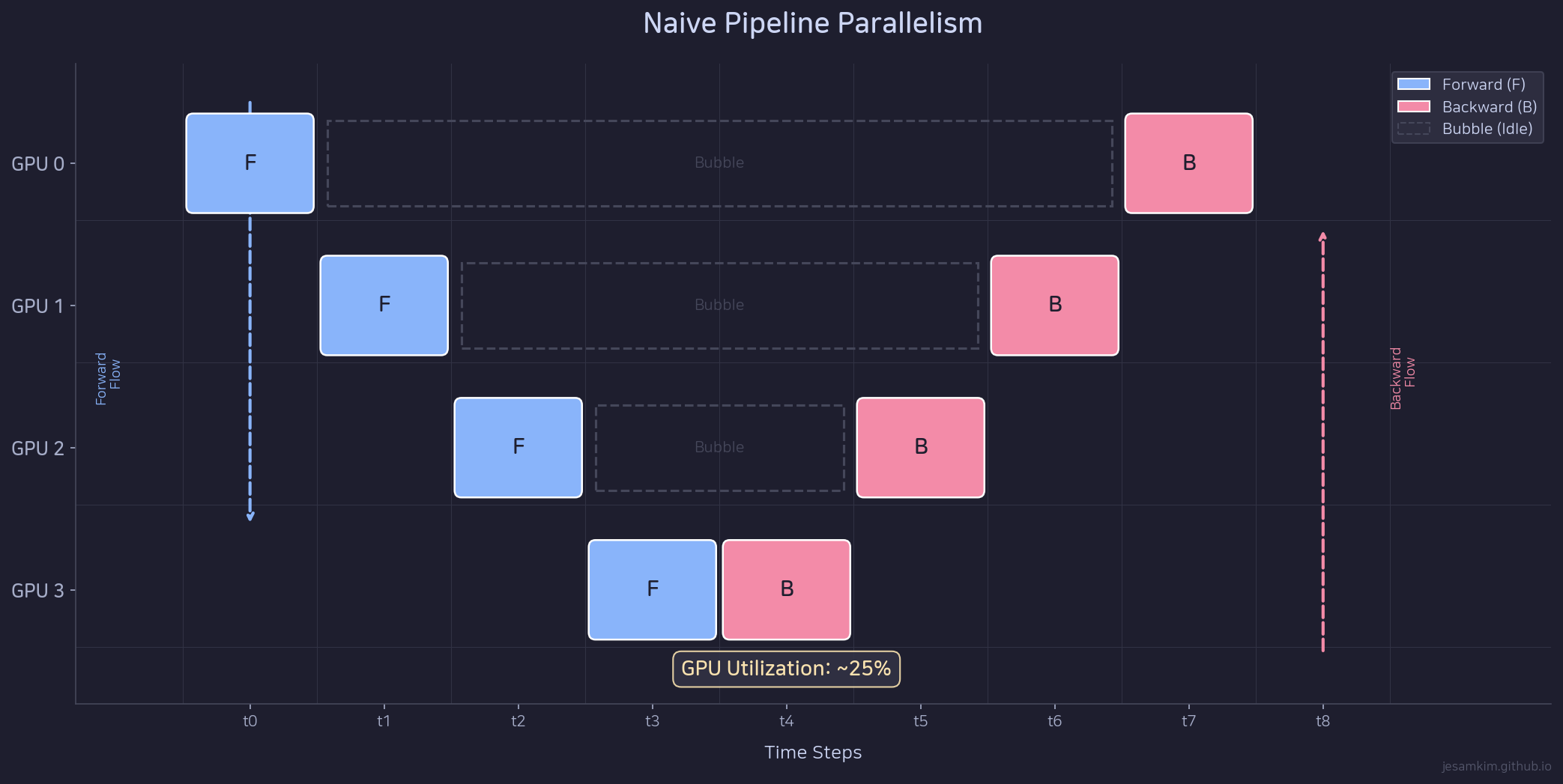 Naive Pipeline: N=4 GPU에서 하나의 mini-batch를 처리하는 스케줄. 회색은 idle 상태.
Naive Pipeline: N=4 GPU에서 하나의 mini-batch를 처리하는 스케줄. 회색은 idle 상태.
Forward는 GPU 0에서 시작해 GPU 3까지 순서대로 전파됩니다. Backward는 GPU 3에서 시작해 GPU 0까지 역순으로 진행됩니다. 이 과정에서 한 GPU가 연산하는 동안 나머지 N-1개의 GPU는 아무것도 하지 않습니다.
GPU utilization은 1/N입니다. GPU가 4개면 25%, 8개면 12.5%입니다. 비싼 GPU를 여러 장 쓰면서 대부분의 시간을 idle로 보내는 셈입니다. 실용적이지 않습니다.
2. GPipe: Micro-batch로 파이프라인 채우기
GPipe(Huang et al., 2019)는 mini-batch를 더 작은 micro-batch로 쪼개는 아이디어를 도입했습니다. mini-batch를 K개의 micro-batch로 나누면, 파이프라인에 여러 micro-batch를 동시에 흘려보낼 수 있습니다.
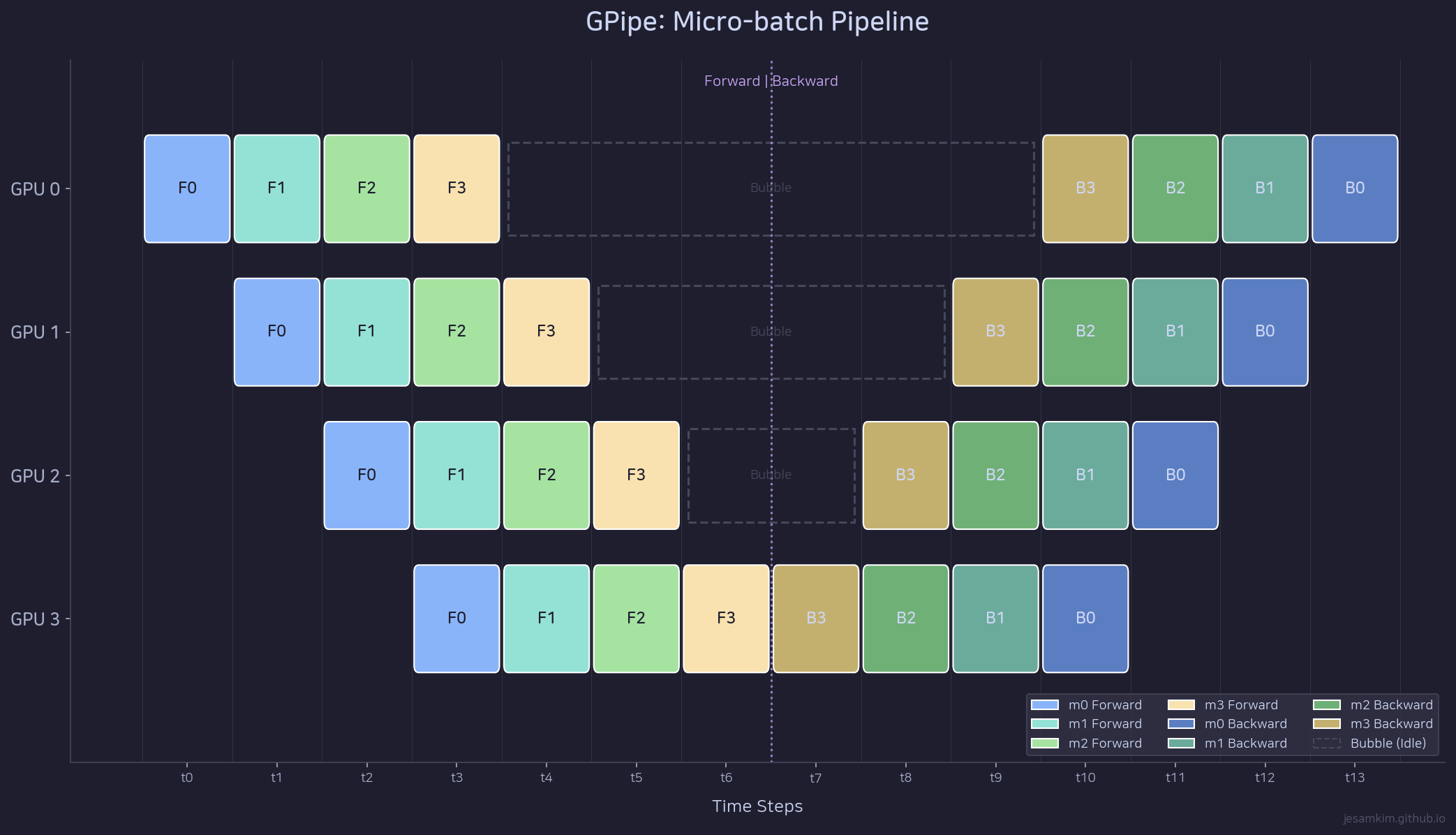 GPipe 스케줄: N=4 GPU, K=4 micro-batches. 먼저 모든 forward를 실행하고, 이후 모든 backward를 역순으로 실행한다.
GPipe 스케줄: N=4 GPU, K=4 micro-batches. 먼저 모든 forward를 실행하고, 이후 모든 backward를 역순으로 실행한다.
GPipe의 스케줄은 두 단계입니다. 먼저 K개 micro-batch의 forward를 모두 실행합니다(all-forward). 마지막 micro-batch의 forward가 끝나면, backward를 역순으로 실행합니다(all-backward). 이 방식에서 forward와 backward 사이에 아직 bubble이 존재하지만, micro-batch 수 K를 늘리면 bubble 비율이 줄어듭니다.

bubble 비율은 (N-1)/(K+N-1)입니다. N=4, K=4이면 bubble은 3/7 = 42.9%입니다. K=12로 늘리면 3/15 = 20%로 줄어듭니다. K를 충분히 크게 하면 bubble을 무시할 수 있을 정도로 줄일 수 있습니다.
하지만 이 접근에는 비용이 있습니다. all-forward를 먼저 실행하므로, K개 micro-batch의 activation을 모두 메모리에 보관해야 합니다. micro-batch 수를 늘릴수록 bubble은 줄어들지만, peak activation memory가 K에 비례해서 증가합니다. bubble과 메모리 사이의 트레이드오프입니다.
3. 1F1B: Forward/Backward 교차 실행
1F1B(One Forward One Backward) 스케줄은 GPipe의 메모리 문제를 해결합니다.
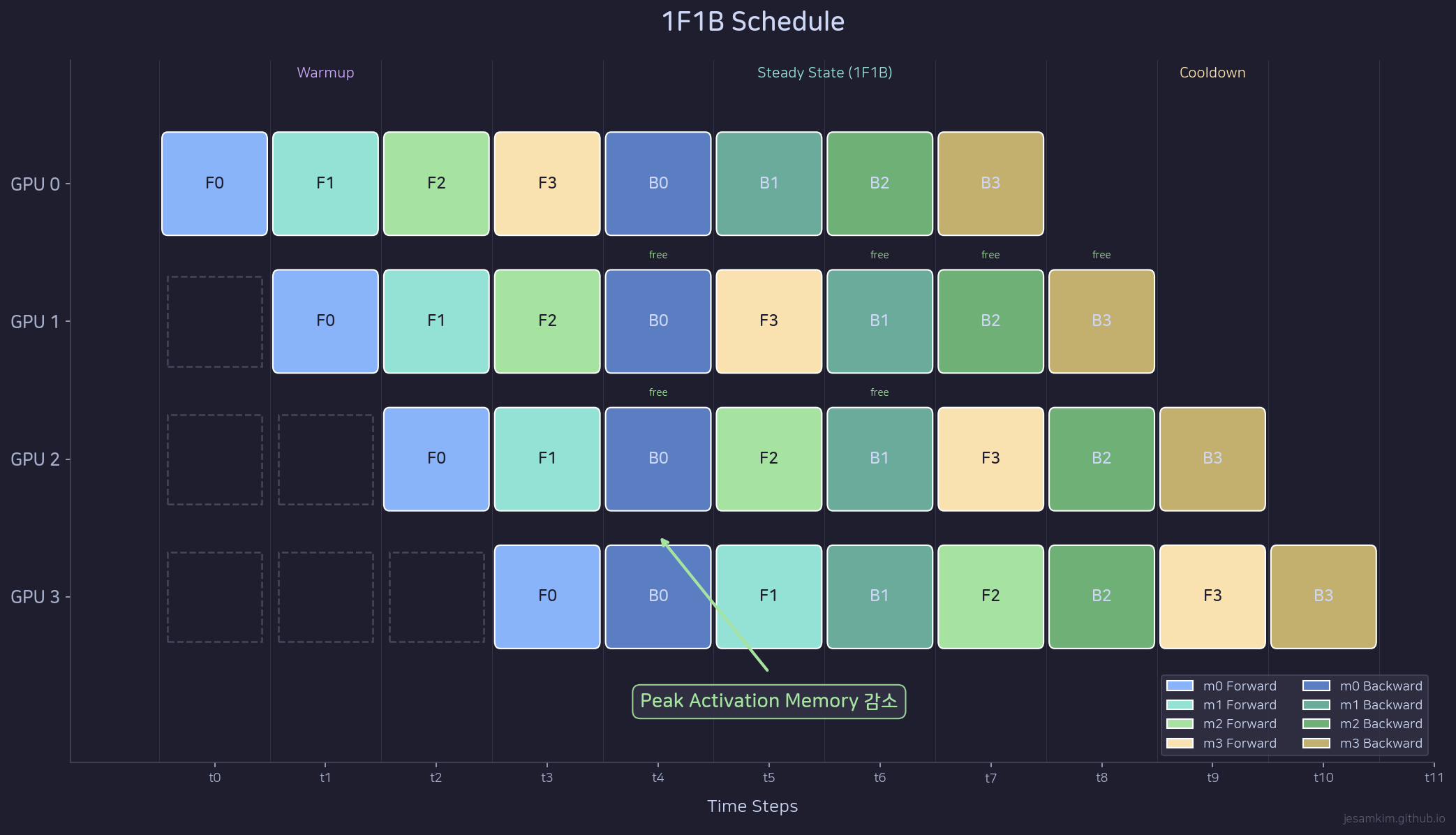 1F1B 스케줄: warmup 이후 forward와 backward를 하나씩 교차 실행한다.
1F1B 스케줄: warmup 이후 forward와 backward를 하나씩 교차 실행한다.
1F1B는 세 구간으로 나뉩니다.
Warmup: 파이프라인을 채우기 위해 forward만 실행합니다. GPU 0은 여러 micro-batch의 forward를 연속 실행하고, 뒤쪽 GPU들은 앞에서 보내준 activation이 도착하는 대로 forward를 실행합니다.
Steady State: forward 1개를 실행한 직후 backward 1개를 실행하는 패턴을 반복합니다. forward가 끝나면 곧바로 해당 micro-batch의 backward를 처리하므로, GPipe처럼 모든 forward가 끝날 때까지 기다릴 필요가 없습니다.
Cooldown: 파이프라인에 남은 backward를 마저 처리합니다.
1F1B의 핵심 이점은 peak activation memory 절감입니다. GPipe는 K개 micro-batch의 activation을 동시에 들고 있어야 하지만, 1F1B는 forward 직후 backward를 실행해서 activation을 즉시 해제합니다. peak activation이 K가 아닌 N(pipeline stage 수)에 비례하게 됩니다. K » N인 일반적 상황에서 메모리 절약이 상당합니다.
bubble 비율 자체는 GPipe와 동일한 (N-1)/(K+N-1)입니다. 1F1B의 기여는 bubble 감소가 아니라 메모리 효율 개선에 있습니다.
4. ZBH: Backprop을 둘로 쪼개다
Zero Bubble(Qi et al., 2023)은 bubble을 근본적으로 제거하려는 시도입니다. 이를 위해 backward pass를 두 개의 독립적인 연산으로 분리합니다.
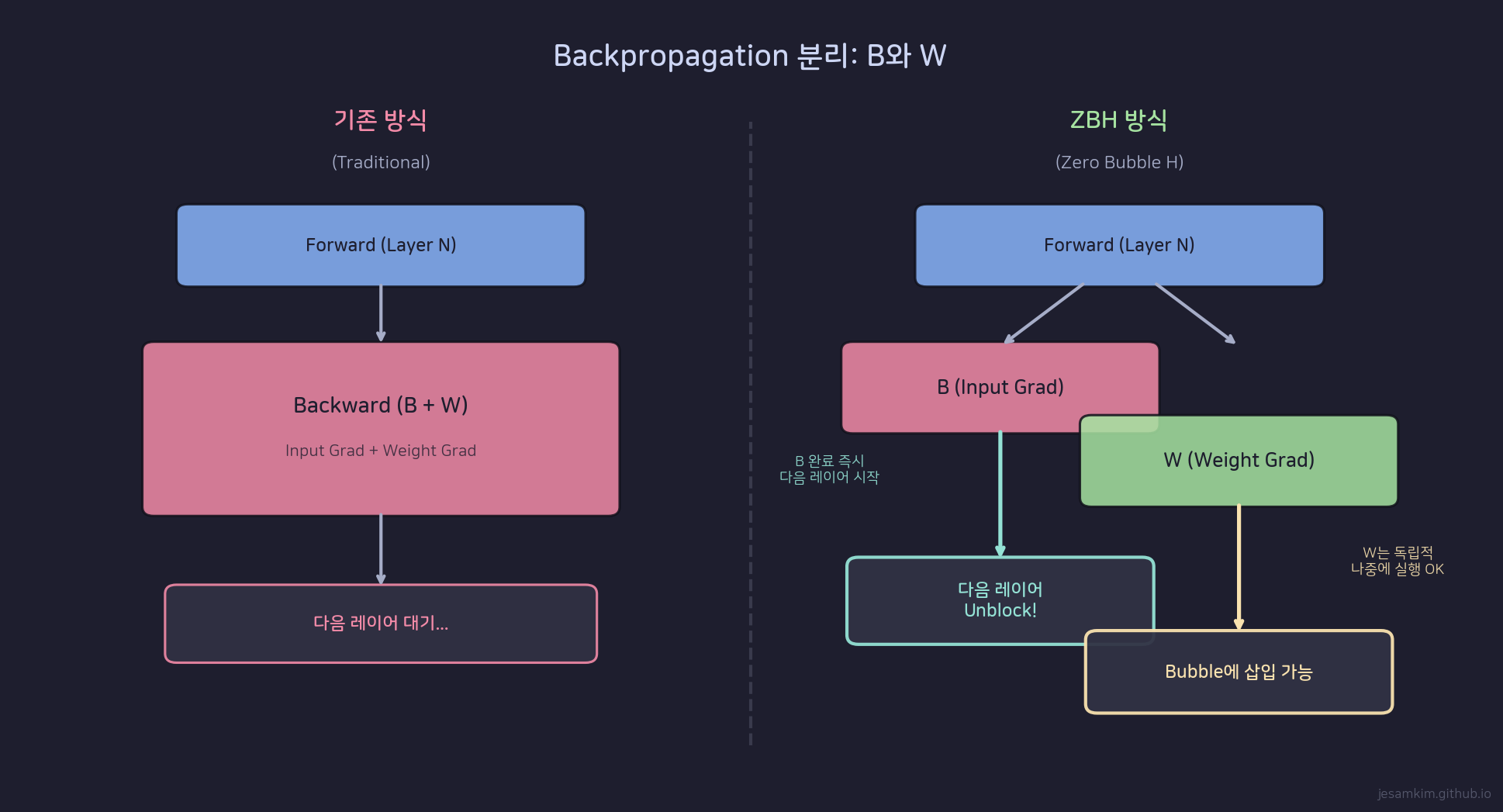 ZBH의 핵심 아이디어: Backward를 B(input gradient)와 W(weight gradient)로 분리
ZBH의 핵심 아이디어: Backward를 B(input gradient)와 W(weight gradient)로 분리
일반적인 backward pass는 두 가지를 한꺼번에 계산합니다. (1) input에 대한 gradient(이전 레이어로 전달해야 함)와 (2) weight에 대한 gradient(optimizer에서 사용). ZBH는 이 둘을 명시적으로 분리합니다.
B (input gradient): dL/dx를 계산합니다. 이 값은 파이프라인의 이전 stage로 전달되어야 하므로, 가능한 빨리 실행해야 합니다. 다음 stage의 backward를 시작하려면 이 값이 필요하기 때문입니다.
W (weight gradient): dL/dW를 계산합니다. 이 값은 해당 stage 내부에서만 쓰이고, 외부로 전달할 필요가 없습니다. 따라서 즉시 실행할 필요가 없고, bubble 슬롯에 넣어서 실행할 수 있습니다.
실행 순서는 F - B - W가 됩니다. F(forward)가 끝나면 B(input gradient)를 먼저 계산해서 이전 stage에 전달하고, W(weight gradient)는 나중에 빈 시간에 실행합니다.
5. ZBH1 vs ZBH2: 메모리와 처리량의 트레이드오프
B와 W를 분리한 뒤, W를 스케줄에 어떻게 배치하느냐에 따라 두 가지 변형이 나옵니다.
 ZBH1(상단)과 ZBH2(하단) 스케줄 비교. ZBH1은 메모리 효율적이고, ZBH2는 bubble을 완전히 제거한다.
ZBH1(상단)과 ZBH2(하단) 스케줄 비교. ZBH1은 메모리 효율적이고, ZBH2는 bubble을 완전히 제거한다.
ZBH1 (Memory-Efficient)
W를 가능한 빨리 실행합니다. B가 끝나면 바로 W를 실행해서, 해당 micro-batch의 activation을 빠르게 해제합니다. peak activation memory가 1F1B와 비슷한 수준입니다.
bubble이 완전히 제거되지는 않지만, 1F1B 대비 상당히 줄어듭니다. B와 W의 분리 덕분에 스케줄 최적화의 여지가 넓어지기 때문입니다.
ZBH2 (High Throughput)
W를 최대한 뒤로 미룹니다. bubble 슬롯에 W를 채워 넣어서 GPU utilization을 거의 100%까지 끌어올립니다. 이론적으로 zero bubble에 근접합니다.
대신 W가 지연되므로, 해당 micro-batch의 activation을 더 오래 유지해야 합니다. peak activation memory가 ZBH1보다 높아집니다. 메모리가 충분한 상황에서 처리량을 극대화할 때 유리합니다.
6. 전체 비교
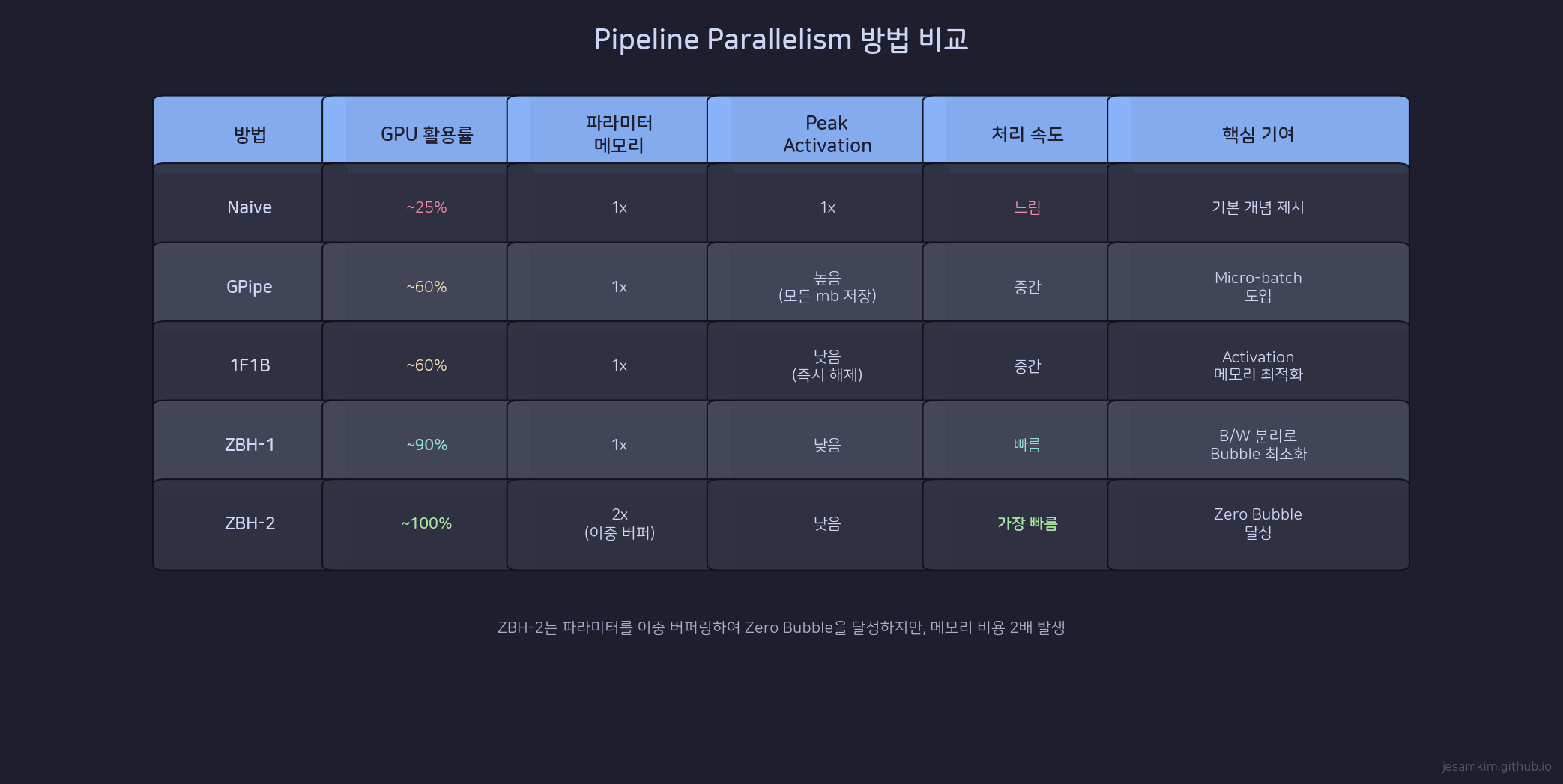 Pipeline Parallelism 기법 비교표
Pipeline Parallelism 기법 비교표
| 기법 | GPU Utilization | Param Memory | Peak Activation | 핵심 기여 |
|---|---|---|---|---|
| Naive | 1/N | per-GPU | low | baseline |
| GPipe | K/(K+N-1) | per-GPU | K x act | micro-batch 도입 |
| 1F1B | K/(K+N-1) | per-GPU | N x act | F/B 교차로 메모리 절감 |
| ZBH1 | ≈100% | per-GPU | N x act | B/W 분리, 메모리 효율 |
| ZBH2 | ≈100% | per-GPU | >N x act | bubble 완전 제거 |
Naive에서 ZBH2까지, 진화의 방향은 일관됩니다. bubble을 줄이면서 메모리 오버헤드를 관리하는 것입니다. GPipe는 micro-batch로 bubble을 줄였지만 메모리가 늘었습니다. 1F1B는 F/B 교차로 메모리를 되찾았습니다. ZBH는 backward를 B/W로 분리해서 남은 bubble마저 제거했습니다.
각 단계에서 기존 기법의 한계를 정확히 식별하고, 그것만 해결하는 최소한의 변경을 가했다는 점이 인상적입니다. micro-batch라는 아이디어 하나, F/B 교차라는 스케줄 변경 하나, B/W 분리라는 분해 하나. 복잡한 메커니즘이 아니라 명확한 관찰에서 나온 설계입니다.
실전 선택 가이드
어떤 PP 기법을 선택할지는 상황에 따라 다릅니다.
모델이 GPU 한 장에 들어가면 PP가 필요 없습니다. DP나 ZeRO를 쓰는 것이 단순하고 효율적입니다.
모델이 GPU 한 장에 들어가지 않으면서 GPU 메모리 여유가 있다면, ZBH2가 처리량 측면에서 최선입니다. 메모리가 빠듯하다면 ZBH1이나 1F1B가 안전합니다.
실제로는 PP를 단독으로 쓰기보다, DP와 조합하는 경우가 대부분입니다. Megatron-LM처럼 PP + DP + Tensor Parallelism을 동시에 사용하는 3D 병렬화가 대규모 모델 학습의 표준이 되었습니다.
References
- Huang et al., “GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism” (arXiv:1811.06965) - https://arxiv.org/abs/1811.06965
- Narayanan et al., “PipeDream: Generalized Pipeline Parallelism for DNN Training” (SOSP 2019) - https://doi.org/10.1145/3341301.3359646
- Narayanan et al., “Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM” (arXiv:2104.04473) - https://arxiv.org/abs/2104.04473
- Qi et al., “Zero Bubble Pipeline Parallelism” (arXiv:2401.10241) - https://arxiv.org/abs/2401.10241
- Fan et al., “DAPPLE: A Pipelined Data Parallel Approach for Training DNN” (PPoPP 2021) - https://doi.org/10.1145/3437801.3441593
- Rajbhandari et al., “ZeRO: Memory Optimizations Toward Training Trillion Parameter Models” (arXiv:1910.02054) - https://arxiv.org/abs/1910.02054