
이전 글에서 Pipeline Parallelism(PP)이 모델을 레이어 단위로 잘라 여러 GPU에 배치하는 방식을 분석했습니다. PP 덕분에 GPU 한 장에 들어가지 않는 모델도 학습할 수 있게 되었고, bubble을 줄이는 방향으로 GPipe, 1F1B, ZBH가 진화해왔습니다.
그런데 PP의 분할 단위는 레이어입니다. 레이어 하나가 GPU 메모리를 초과하면 어떻게 할까요? 또, 하나의 병렬화 기법만으로는 수천 개 GPU를 효율적으로 활용하기 어렵습니다. 모델 용량은 키우면서 연산량은 유지하고 싶다면요?
이 글에서는 이 세 가지 질문에 대한 답을 다룹니다. Tensor Parallelism, Hybrid Parallelism, 그리고 MoE + Expert Parallelism입니다.
1. Tensor Parallelism: 레이어 내부를 쪼갠다
Pipeline Parallelism이 레이어 사이를 분할한다면, Tensor Parallelism(TP)은 레이어 내부의 행렬 연산을 분할합니다. 하나의 Linear layer에서 z = Wx를 계산할 때, weight matrix W 자체를 여러 GPU에 나눠 갖는 방식입니다.
W를 나누는 방향에 따라 두 가지 선택지가 있습니다.
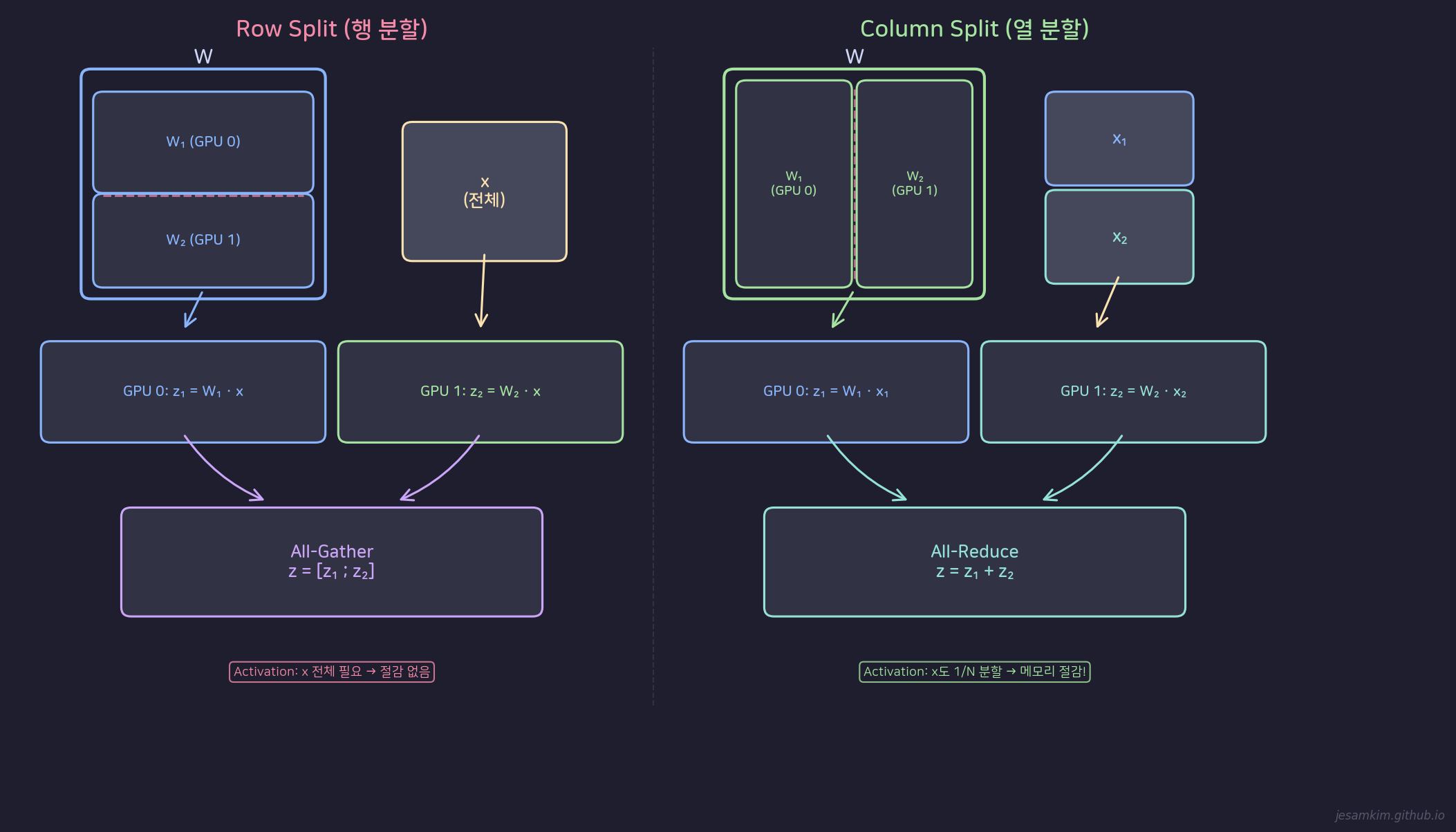 Row Split과 Column Split: W를 나누는 방향에 따라 통신 패턴과 메모리 절감 효과가 달라진다
Row Split과 Column Split: W를 나누는 방향에 따라 통신 패턴과 메모리 절감 효과가 달라진다
Option 1: Row Split (행 분할)
W를 행 방향으로 분할합니다. GPU 0은 W의 위쪽 행 W1, GPU 1은 아래쪽 행 W2를 담당합니다.
두 GPU 모두 동일한 입력 x 전체를 받습니다. 각 GPU는 자기가 맡은 행으로 연산합니다.
- GPU 0: z1 = W1 · x (출력의 위쪽 부분)
- GPU 1: z2 = W2 · x (출력의 아래쪽 부분)
Forward에서 전체 출력을 얻으려면 두 결과를 이어 붙여야 합니다: z = [z1 ; z2]. 이 연산이 All-Gather(concatenation)입니다.
Backward에서는 gradient를 합산하는 All-Reduce가 필요합니다.
Row Split의 한계는 activation memory입니다. 각 GPU가 x 전체를 필요로 하므로, activation memory 절감이 없습니다.
Option 2: Column Split (열 분할)
W를 열 방향으로 분할합니다. GPU 0은 W의 왼쪽 열 W1, GPU 1은 오른쪽 열 W2를 담당합니다.
입력 x도 대응하여 분할합니다. GPU 0은 x1(x의 앞부분), GPU 1은 x2(x의 뒷부분)를 받습니다.
- GPU 0: z1 = W1 · x1 (부분합)
- GPU 1: z2 = W2 · x2 (부분합)
Forward에서 전체 출력을 얻으려면 부분합을 더해야 합니다: z = z1 + z2. 이 연산이 All-Reduce(summation)입니다.
Backward에서는 각 GPU가 자신의 xi 슬라이스만 필요하므로, 추가 통신이 불필요합니다.
Column Split의 핵심 이점은 여기에 있습니다. 입력도 분할되므로 activation memory도 1/N으로 줄어듭니다.
메모리 비교
N개 GPU, 파라미터 행렬 크기 dout x din, activation 크기를 alpha · B라 하면:
| 방식 | Parameter Memory | Activation Memory |
|---|---|---|
| Centralized | 2 · dout · din | alpha · B |
| Row Split | 2 · dout · din / N | alpha · B (절감 없음) |
| Column Split | 2 · dout · din / N | alpha · B / N |
Parameter memory는 두 방식 모두 1/N으로 줄어듭니다. 차이는 activation memory입니다. Column Split만이 activation까지 절감합니다.
Option 3: Row-Column 교대 방식 (Megatron-LM)
실제 Transformer 모델에서는 Linear layer가 두 개씩 연속으로 나옵니다. MLP 블록의 경우 첫 번째 layer(확장)와 두 번째 layer(축소)가 쌍을 이룹니다.
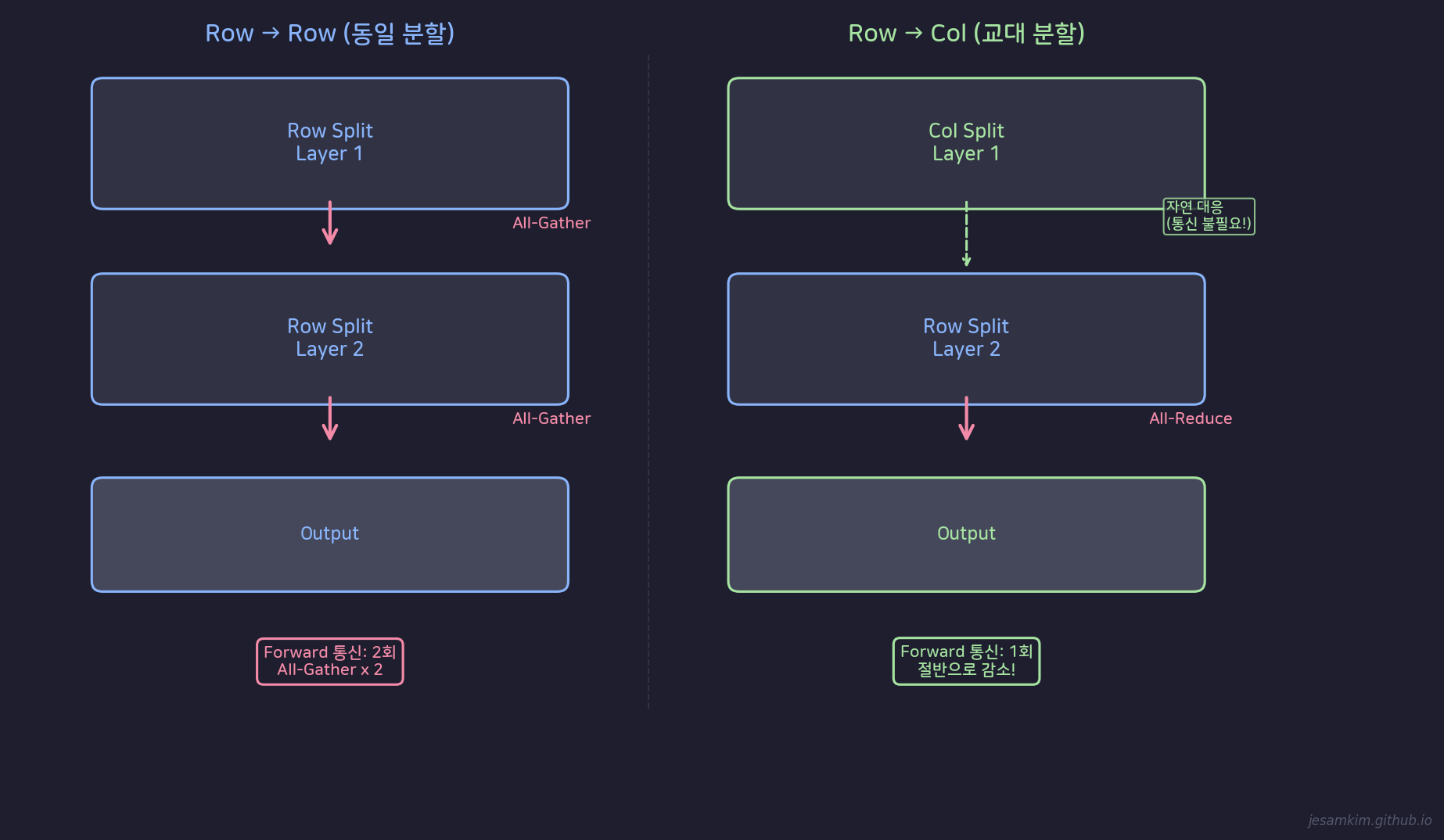 Row-Col 교대 방식: 2-layer당 통신 횟수를 절반으로 줄인다
Row-Col 교대 방식: 2-layer당 통신 횟수를 절반으로 줄인다
Row Split의 출력 형태는 Column Split의 입력 형태와 자연스럽게 대응됩니다. 첫 번째 layer를 Column Split, 두 번째 layer를 Row Split으로 배치하면, 중간에 All-Gather 없이 바로 연결할 수 있습니다.
통신 횟수를 비교하면:
| 조합 | 2-layer당 Forward 통신 |
|---|---|
| Row → Row | All-Gather x 2 = 2회 |
| Col → Col | All-Reduce x 2 = 2회 |
| Col → Row (교대) | All-Reduce x 1 = 1회 |
Megatron-LM(Shoeybi et al., 2019)이 채택한 이 교대 방식은 통신량을 절반으로 줄입니다. Attention 블록에서도 동일한 원리가 적용됩니다. Multi-head attention의 head를 GPU별로 나누면(Column Split 유사), 이후 output projection을 Row Split으로 처리해서 통신을 최소화합니다.
DeepSeek-V3의 선택
흥미로운 것은 DeepSeek-V3(2024)의 설계입니다. DeepSeek-V3는 학습에서 Tensor Parallelism을 사용하지 않습니다. 논문에서 “no costly tensor parallelism"이라고 명시했습니다.
이유는 Training의 복잡성입니다. Training에서는 Forward뿐 아니라 Backward까지 통신이 필요하므로, TP의 통신 오버헤드가 커집니다. DeepSeek-V3는 대신 Pipeline Parallelism + Expert Parallelism 조합으로 이 문제를 회피했습니다.
반면 Inference에서는 TP를 적극 활용합니다. Inference는 Forward만 실행하므로 통신 패턴이 단순하고, latency를 줄이는 데 TP가 효과적입니다.
2. Hybrid Parallelism: 기법들을 조합한다
하나의 병렬화 기법만으로 수천 개 GPU를 효율적으로 활용하기는 어렵습니다. Data Parallelism은 parameter memory를 줄이지 못하고, Pipeline Parallelism은 bubble이 존재하며, Tensor Parallelism은 고속 인터커넥트를 요구합니다.
실제 대규모 모델 학습에서는 여러 기법을 조합합니다.
2D: Data + Pipeline
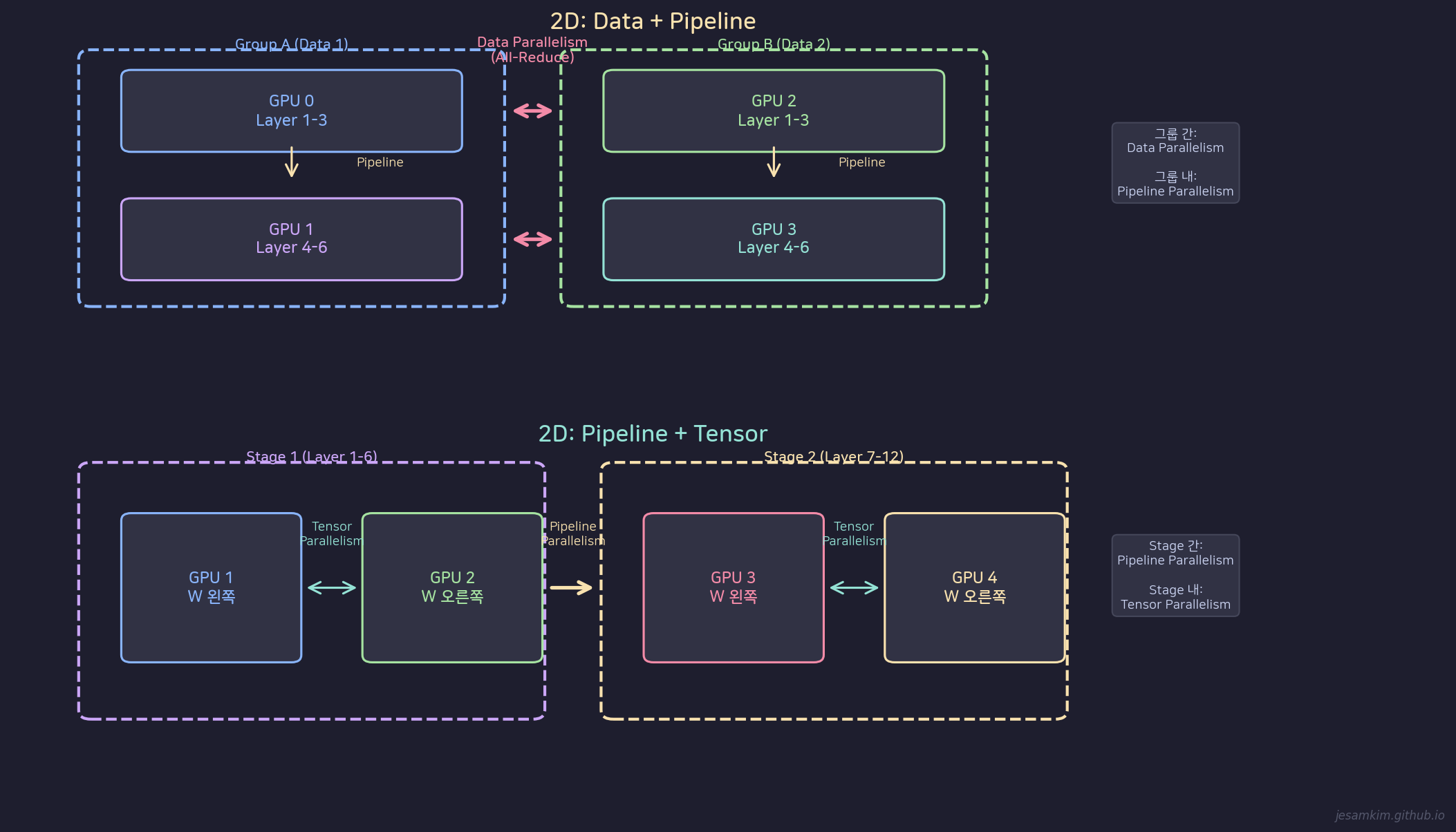 2D Hybrid Parallelism: Data+Pipeline(좌)과 Pipeline+Tensor(우) 조합
2D Hybrid Parallelism: Data+Pipeline(좌)과 Pipeline+Tensor(우) 조합
4개 GPU를 두 그룹으로 나눕니다. [GPU 0, GPU 1]이 그룹 A, [GPU 2, GPU 3]이 그룹 B입니다.
그룹 간에는 Data Parallelism을 적용합니다. 그룹 A와 B는 서로 다른 데이터를 처리하고, gradient를 All-Reduce로 동기화합니다.
그룹 내에서는 Pipeline Parallelism을 적용합니다. GPU 0은 앞쪽 레이어, GPU 1은 뒤쪽 레이어를 담당합니다.
이 조합으로 DP의 activation memory 절감과 PP의 parameter memory 분산을 동시에 얻습니다.
2D: Pipeline + Tensor
4개 GPU를 두 stage로 나눕니다. [GPU 1, GPU 2]가 Stage 1, [GPU 3, GPU 4]가 Stage 2입니다.
Stage 간에는 Pipeline Parallelism을 적용합니다. Stage 1은 앞쪽 레이어, Stage 2는 뒤쪽 레이어를 처리합니다.
Stage 내에서는 Tensor Parallelism을 적용합니다. 같은 stage의 두 GPU가 하나의 레이어 내부 행렬을 나눠 계산합니다.
이 조합은 레이어 하나가 GPU 한 장에 들어가지 않을 때 필요합니다.
3D: Pipeline + Tensor + Data
세 기법을 모두 조합하면 3D Parallelism이 됩니다. 필요한 총 GPU 수는:
Ntotal = Npp x Ntp x Ndp
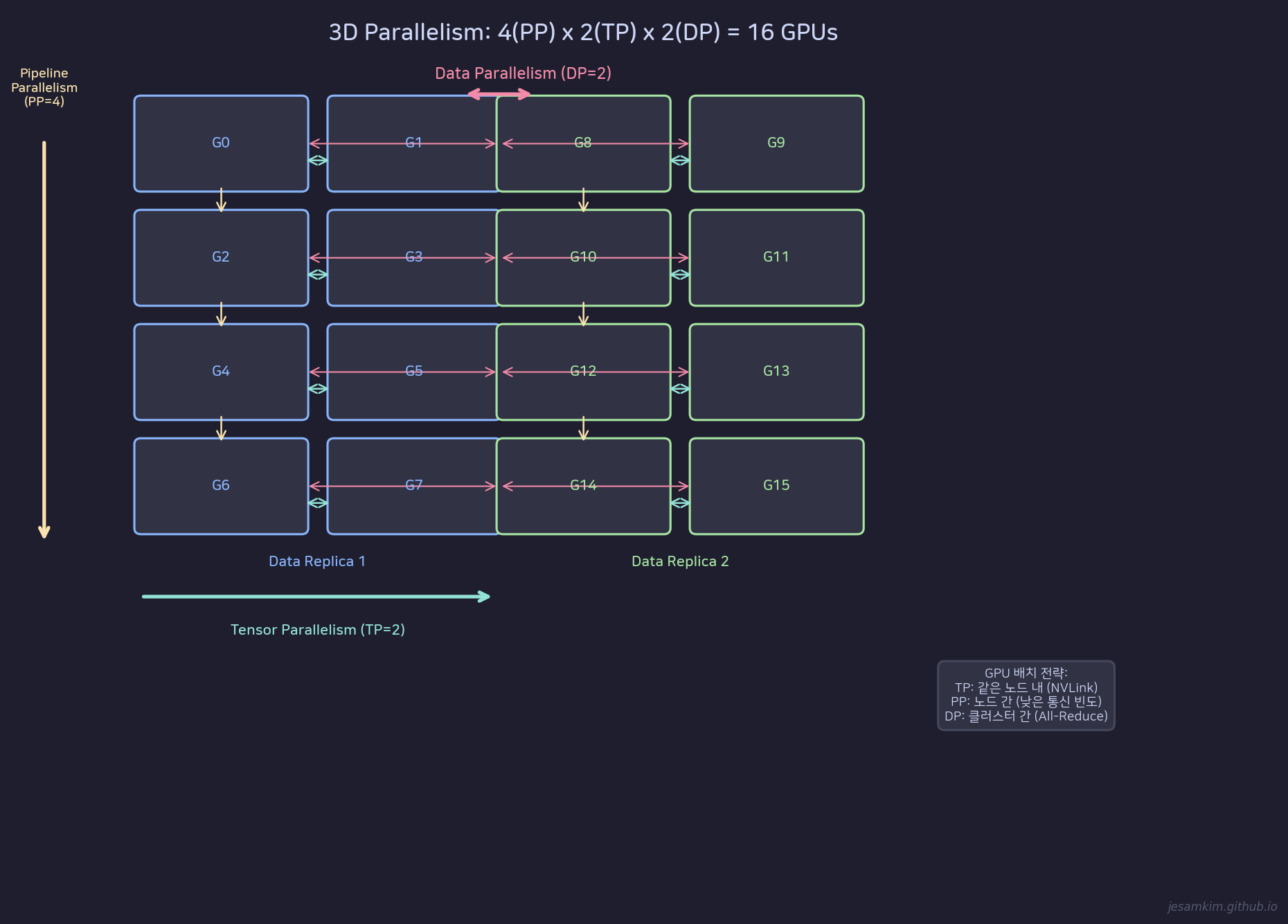 3D Parallelism: Pipeline(4) x Tensor(4) x Data(2) = 32 GPUs
3D Parallelism: Pipeline(4) x Tensor(4) x Data(2) = 32 GPUs
32 GPU 예시에서 4(pipeline) x 4(tensor) x 2(data) = 32를 구성할 수 있습니다.
GPU 배치 전략이 중요합니다:
- Tensor Parallelism은 같은 노드 내에 배치합니다. All-Reduce/All-Gather 통신이 빈번하므로 NVLink 같은 고속 인터커넥트가 필수입니다.
- Pipeline Parallelism은 노드 간에 배치합니다. 인접 stage 사이의 Point-to-Point 통신만 발생하므로 상대적으로 낮은 대역폭으로도 동작합니다.
- Data Parallelism은 가장 바깥 차원에 배치합니다. gradient 동기화를 위한 All-Reduce가 iteration마다 한 번 발생합니다.
Megatron-LM(Narayanan et al., 2021)이 이 3D 구조의 대표적 구현체입니다. 당시 530B 파라미터 모델을 3072개 GPU로 학습하는 데 이 전략을 사용했습니다.
3. Mixture of Experts (MoE): 필요한 전문가만 부른다
지금까지의 병렬화 기법들은 Dense 모델을 전제로 합니다. Dense 모델은 매 입력마다 전체 파라미터를 활성화합니다. 모델이 커질수록 연산량도 비례해서 증가합니다.
MoE(Mixture of Experts)는 접근 자체가 다릅니다. 모델 용량(파라미터 수)은 키우되, 각 입력에 대해 일부 Expert만 선택적으로 활성화합니다.
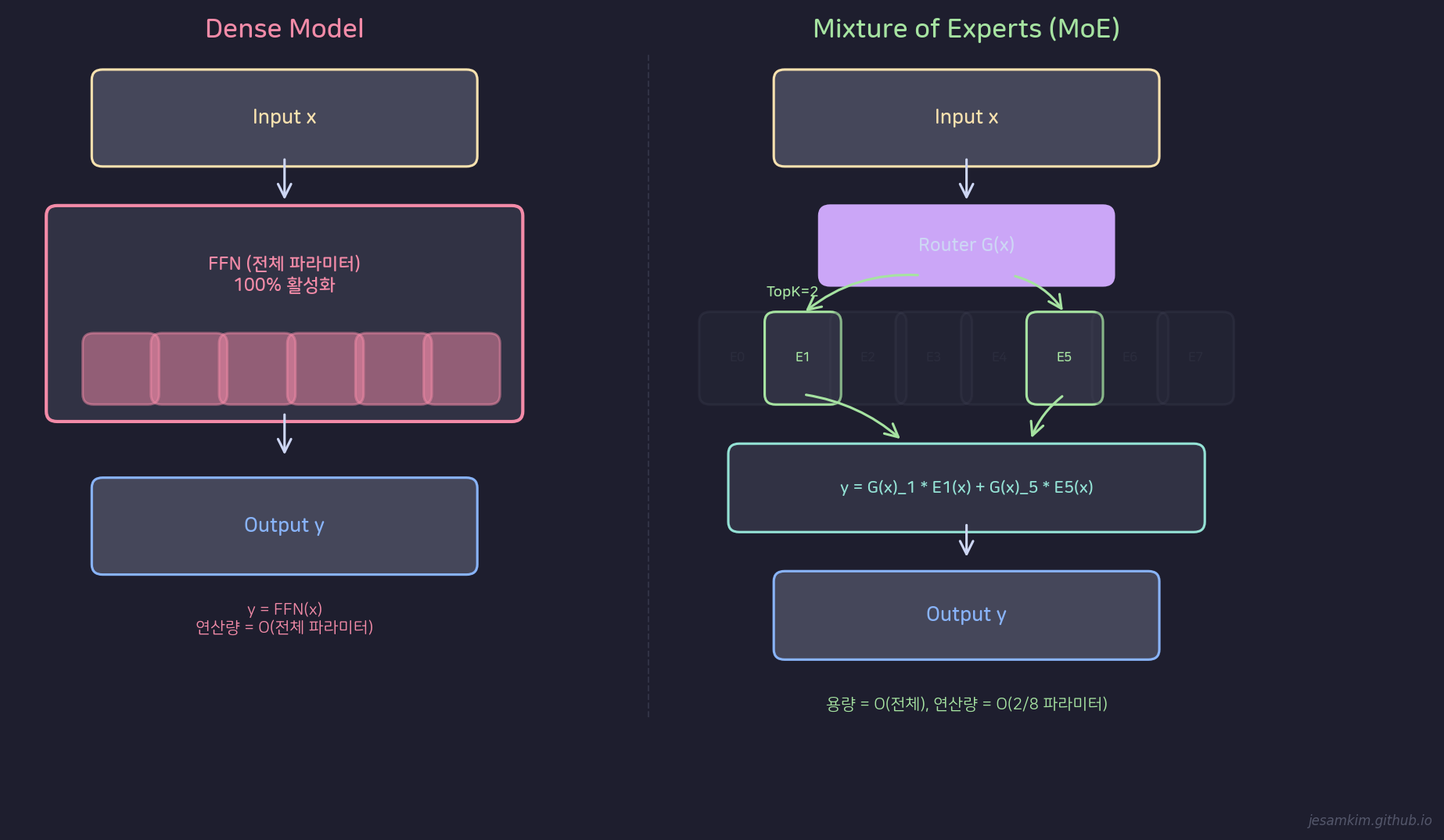 Dense 모델은 전체 파라미터를 활성화하고, MoE는 Router가 선택한 일부 Expert만 활성화한다
Dense 모델은 전체 파라미터를 활성화하고, MoE는 Router가 선택한 일부 Expert만 활성화한다
구조
MoE 레이어는 두 요소로 구성됩니다.
Router(Gating Network)는 입력 x를 받아 각 Expert로 보낼 확률을 계산합니다. 보통 단순한 Linear layer + Softmax입니다.
Expert는 독립적인 FFN(Feed-Forward Network)입니다. 8개, 16개, 또는 수백 개까지 배치할 수 있습니다.
출력은 다음과 같이 계산됩니다:
y = sum of G(x)i · Ei(x), for i in TopK
여기서 G(x)i는 Router가 Expert i에 부여한 가중치, Ei(x)는 Expert i의 출력입니다. TopK는 보통 k=1 또는 k=2로, 전체 Expert 중 상위 k개만 선택합니다.
8개 Expert에서 TopK=2라면, 입력 하나당 전체 파라미터의 2/8 = 25%만 활성화됩니다. 모델 용량은 8배이지만 연산량은 Dense 대비 크게 늘지 않습니다.
Load-Balancing Loss
MoE의 실용적 문제는 Expert collapse입니다. Router가 특정 Expert만 반복 선택하면, 나머지 Expert는 gradient를 받지 못해 학습되지 않습니다. 결국 소수의 Expert만 유의미하게 남고 MoE의 이점이 사라집니다.
이를 방지하기 위해 Cross-entropy loss에 load-balancing loss를 추가합니다. 이 보조 손실은 토큰들이 Expert에 균등하게 분배되도록 유도합니다. 주로 영향을 미치는 부분은 Router의 파라미터입니다. Router가 특정 Expert에 편향된 확률을 출력하면 패널티가 커지는 구조입니다.
Switch Transformer(Fedus et al., 2022)에서 도입된 이 방식은 이후 대부분의 MoE 모델에서 표준으로 자리잡았습니다.
4. Expert Parallelism: MoE를 여러 GPU에 분산한다
MoE 모델에서 Expert 수가 많아지면, 모든 Expert를 한 GPU에 올릴 수 없습니다. Expert Parallelism(EP)은 Expert를 GPU별로 분산 배치합니다. 4개 Expert가 있으면 GPU 0에 Expert 0, GPU 1에 Expert 1 식으로 나눕니다.
핵심 통신: Dispatch와 Combine
EP에서는 두 번의 All-to-All 통신이 발생합니다.
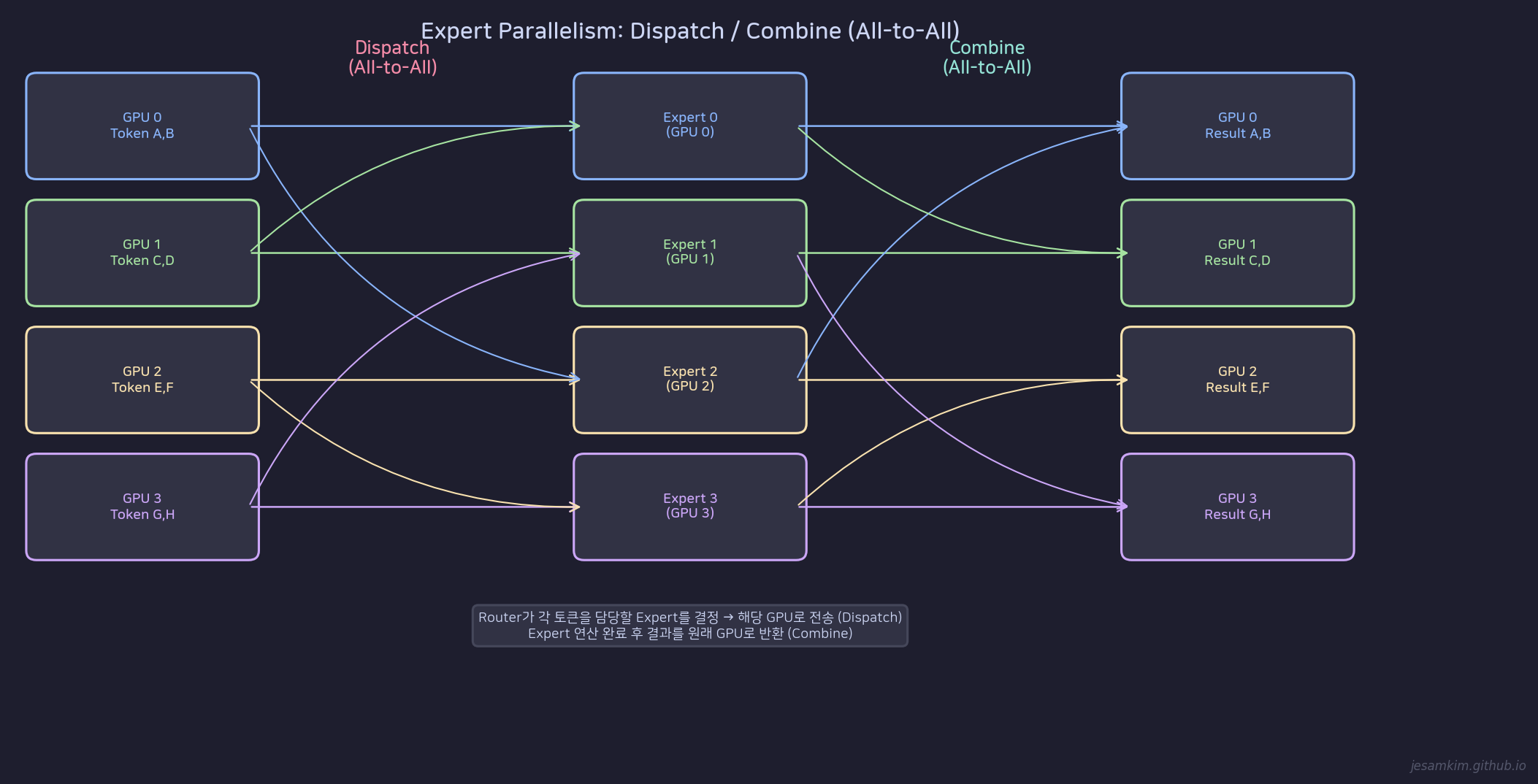 Expert Parallelism의 Dispatch/Combine: All-to-All 통신으로 토큰을 Expert가 있는 GPU로 보내고 결과를 돌려받는다
Expert Parallelism의 Dispatch/Combine: All-to-All 통신으로 토큰을 Expert가 있는 GPU로 보내고 결과를 돌려받는다
Dispatch: Router가 각 토큰의 담당 Expert를 결정하면, 토큰을 해당 Expert가 있는 GPU로 전송합니다. GPU 0의 토큰이 Expert 2를 선택했다면, 그 토큰은 GPU 2로 이동합니다. 모든 GPU가 동시에 서로에게 토큰을 보내므로 All-to-All 통신입니다.
Combine: Expert 연산이 끝나면, 결과를 원래 토큰이 있던 GPU로 반환합니다. 역시 All-to-All 통신입니다.
Transformer 블록 내 배치
GShard(Lepikhin et al., 2020) 방식에서 Transformer 블록의 구성은 다음과 같습니다:
- Attention, Layer Norm 등은 모든 GPU에 동일하게 복제(replicated)합니다. 이 부분은 파라미터가 상대적으로 작습니다.
- FFN 레이어만 Expert로 교체하여 GPU별로 분산(sharded)합니다.
Expert 레이어 직전에 Dispatch(All-to-All), 직후에 Combine(All-to-All)이 발생합니다. Transformer 블록 하나당 2회의 All-to-All 통신이 추가되는 셈입니다.
실용적으로는 각 GPU가 전체 토큰이 아닌 일부 토큰만 담당하는 방식을 씁니다. 이 경우 Data Parallelism이 암묵적으로 포함됩니다. 각 GPU는 자기 토큰의 Forward/Backward를 처리하면서, Expert 연산이 필요할 때만 All-to-All로 토큰을 교환합니다.
DeepSeek-V3의 통합
DeepSeek-V3는 세 가지 병렬화를 조합합니다:
- 16-way Pipeline Parallelism: 모델을 16개 stage로 분할
- 64-way Expert Parallelism: 256개 Expert를 64개 GPU에 분산
- ZeRO-1 Data Parallelism: optimizer state만 분산
여기에 DualPipe라는 자체 스케줄링을 도입했습니다. DualPipe는 All-to-All 통신과 연산을 overlap시켜 통신 시간을 숨깁니다. Part 3에서 다룬 ZBH의 Backward 분리(B/W split) 아이디어도 활용합니다. Backward를 input gradient 계산(B)과 weight gradient 계산(W)으로 분리해서 스케줄링 유연성을 확보한 것입니다.
결과적으로 DeepSeek-V3는 671B 파라미터 MoE 모델을 2048개 H800 GPU로 학습했으며, GPU당 MFU(Model FLOPs Utilization)는 약 61%를 달성했습니다.
5. 4대 병렬화 종합 비교
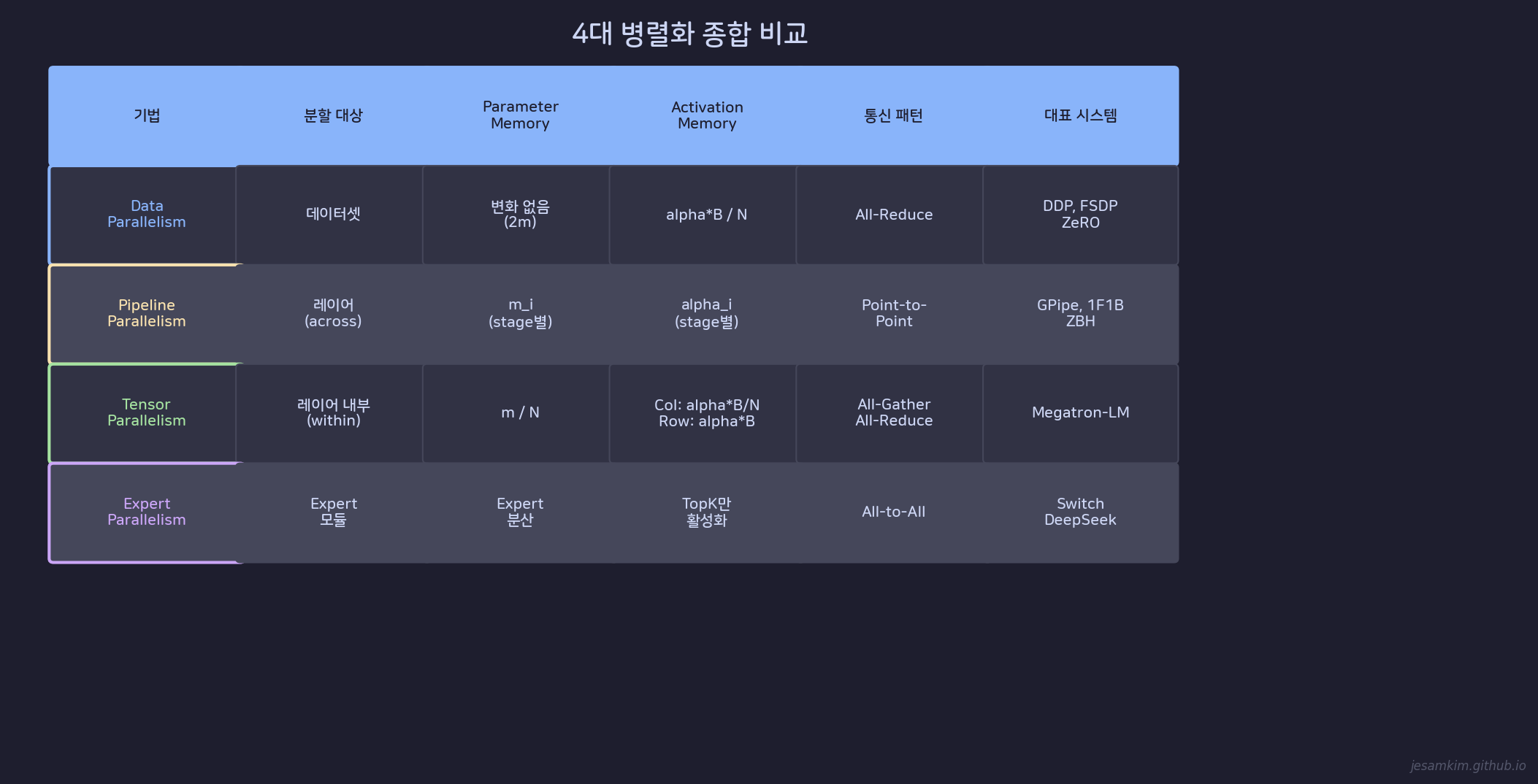 Data, Pipeline, Tensor, Expert Parallelism의 종합 비교
Data, Pipeline, Tensor, Expert Parallelism의 종합 비교
| 기법 | 분할 대상 | Param Mem | Act Mem | 통신 패턴 | 대표 시스템 |
|---|---|---|---|---|---|
| Data | 데이터셋 | 변화 없음 (2m) | alpha · B/N | All-Reduce | DDP, FSDP |
| Pipeline | 레이어 (across) | mi (stage별) | alphai (stage별) | Point-to-Point | GPipe, 1F1B |
| Tensor | 레이어 내부 (within) | m/N | Col: alpha · B/N | All-Gather / All-Reduce | Megatron-LM |
| Expert | Expert 모듈 | Expert 분산 | TopK만 활성화 | All-to-All | Switch, DeepSeek |
의사결정 가이드
어떤 기법을 선택할지는 병목이 어디에 있느냐에 따라 달라집니다.
Activation memory가 병목이면(batch size가 크거나, sequence가 긴 경우) Data Parallelism이 직접적입니다. 데이터를 나누면 GPU당 activation이 1/N으로 줄어듭니다.
Parameter memory가 병목이면(모델이 GPU 한 장에 안 들어가는 경우) Pipeline Parallelism으로 레이어를 분산합니다. 레이어 하나도 안 들어가면 Tensor Parallelism을 추가합니다.
레이어 내부 연산도 분할이 필요하면 Tensor Parallelism을 씁니다. 특히 Inference에서 latency를 줄이는 데 효과적입니다. 단, 고속 인터커넥트가 전제입니다.
모델 용량은 키우되 연산량을 유지하고 싶으면 MoE + Expert Parallelism을 고려합니다. 파라미터 수 대비 실제 연산량의 비율을 조절할 수 있습니다.
실제로는 이 기법들을 단독으로 쓰는 경우가 드뭅니다. Megatron-LM의 3D Parallelism, DeepSeek-V3의 PP+EP+DP 조합처럼, 문제의 성격에 맞게 여러 기법을 계층적으로 조합하는 것이 현재의 표준입니다.
References
- Shoeybi et al., “Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism” (arXiv:1909.08053) - https://arxiv.org/abs/1909.08053
- Narayanan et al., “Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM” (arXiv:2104.04473) - https://arxiv.org/abs/2104.04473
- Lepikhin et al., “GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding” (arXiv:2006.16668) - https://arxiv.org/abs/2006.16668
- Fedus et al., “Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity” (arXiv:2101.03961) - https://arxiv.org/abs/2101.03961
- DeepSeek-AI, “DeepSeek-V3 Technical Report” (arXiv:2412.19437) - https://arxiv.org/abs/2412.19437
- Shazeer et al., “Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer” (arXiv:1701.06538) - https://arxiv.org/abs/1701.06538
- Rajbhandari et al., “ZeRO: Memory Optimizations Toward Training Trillion Parameter Models” (arXiv:1910.02054) - https://arxiv.org/abs/1910.02054