
GPU 한 장으로 모델을 학습하다 보면 어김없이 만나는 에러가 있습니다. CUDA out of memory. 모델 파라미터 수만 보고 “이 정도면 들어가겠지” 싶었는데 실제로는 훨씬 더 많은 메모리를 요구합니다. Inference 때는 문제없이 돌아가던 모델이 Training에서는 메모리가 부족한 이유가 뭘까요?
이 글에서는 Neural Network 학습 루프의 각 단계를 따라가면서, GPU 메모리가 정확히 어디에 얼마나 쓰이는지를 수식과 함께 분석합니다.
1. Neural Network 학습 루프
한 iteration의 학습은 네 단계로 구성됩니다.
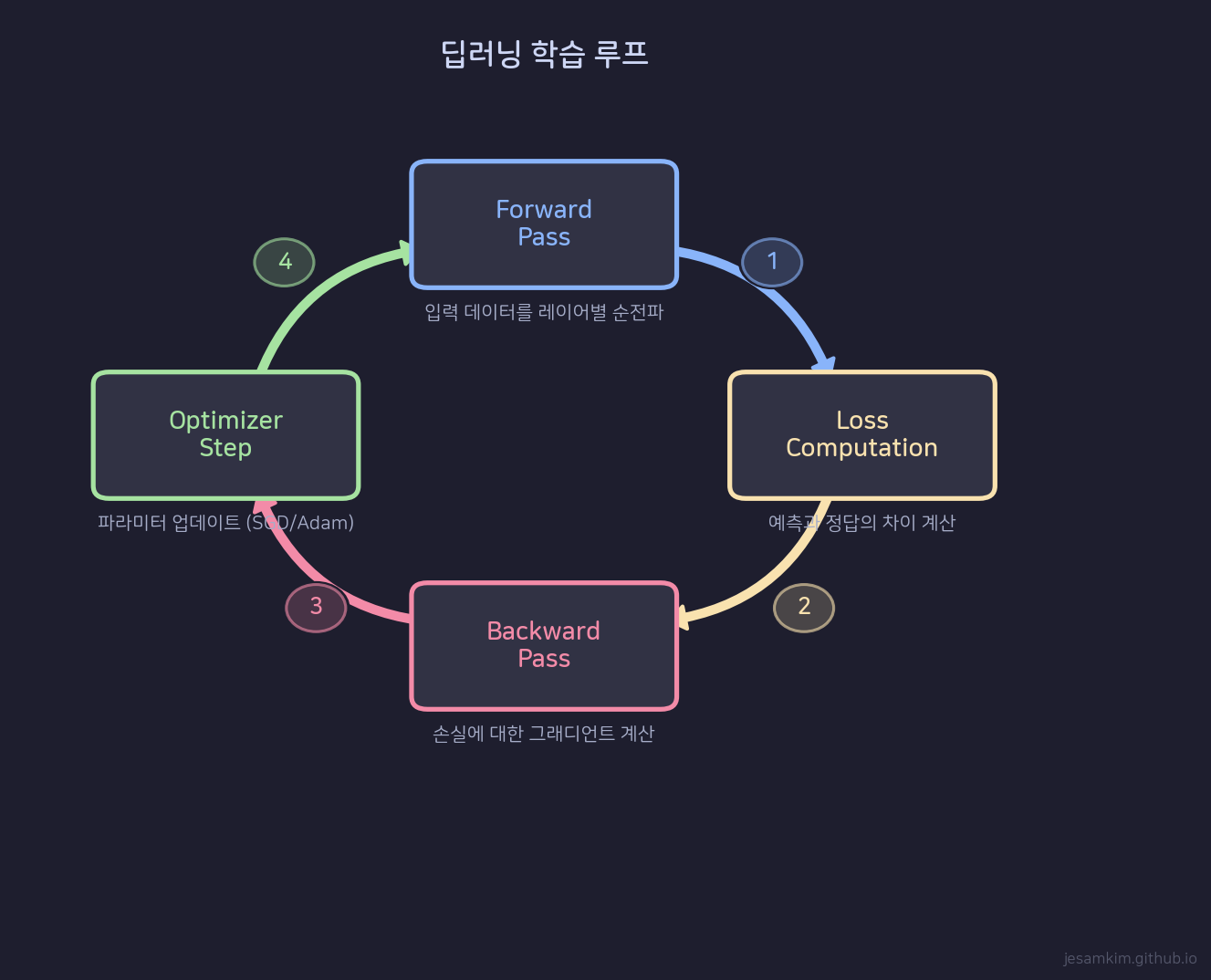 Neural Network 학습 루프: Forward - Loss - Backward - Optimizer의 순환 구조
Neural Network 학습 루프: Forward - Loss - Backward - Optimizer의 순환 구조
Forward Pass에서는 입력 데이터가 각 레이어를 통과하면서 activation을 생성합니다. 이 activation들은 나중에 Backward Pass에서 gradient를 계산하는 데 필요하므로 메모리에 보관해야 합니다.
Loss Computation은 모델 출력과 정답 레이블을 비교해서 scalar loss 값을 만듭니다. 메모리 측면에서는 거의 무시할 수 있는 수준입니다.
Backward Pass에서는 chain rule을 적용해 각 파라미터에 대한 gradient를 계산합니다. 이때 Forward에서 저장해둔 activation을 사용합니다. gradient는 파라미터와 같은 shape이므로, 파라미터 수만큼의 추가 메모리가 필요합니다.
Optimizer Step에서는 계산된 gradient를 사용해 파라미터를 업데이트합니다. 여기서 optimizer 종류에 따라 추가 상태(state)를 유지해야 하는데, 이것이 메모리 사용량에 큰 차이를 만듭니다.
2. Parameter Memory: Optimizer가 결정한다
모델의 파라미터 수를 m이라 두겠습니다. 각 optimizer가 유지하는 상태가 다르기 때문에, 동일한 모델이라도 optimizer 선택에 따라 parameter memory가 달라집니다.
SGD
가장 단순한 형태입니다. weights(w)와 gradients(g)만 있으면 됩니다.
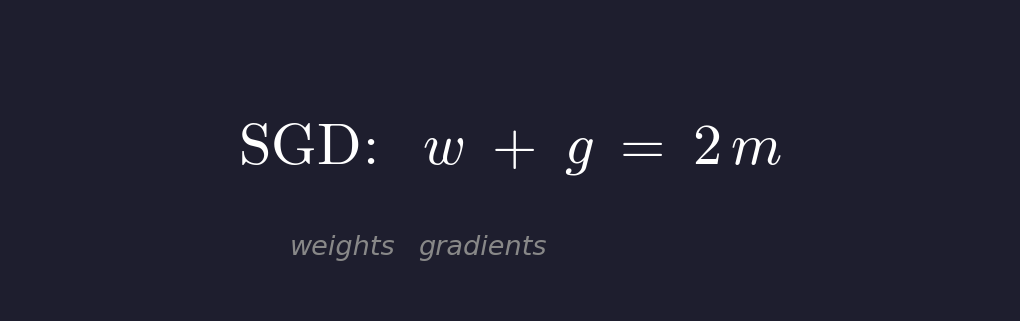
weights를 저장하는 데 m개의 element가 필요하고, gradient도 같은 shape이므로 m개가 필요합니다. 총 2m입니다.
SGD with Momentum
Momentum은 이전 gradient의 이동 평균(mt)을 추가로 유지합니다.
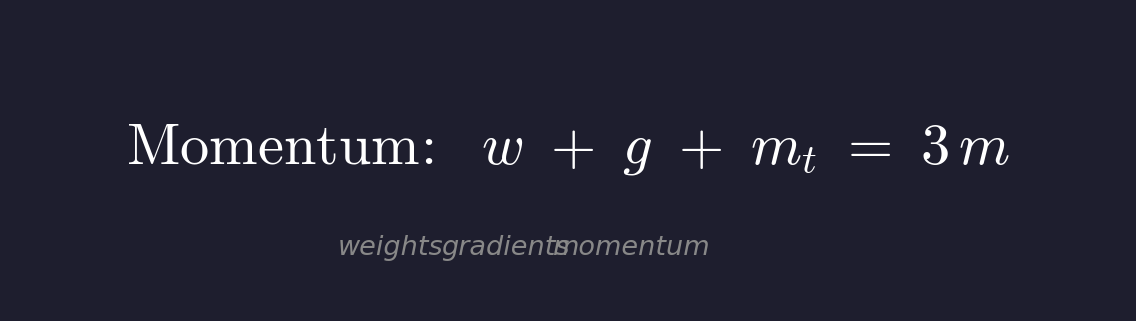
기존 2m에 momentum term mt가 추가되어 3m이 됩니다.
Adam
Adam은 first moment(mt, gradient의 이동 평균)와 second moment(vt, gradient 제곱의 이동 평균)을 모두 유지합니다.
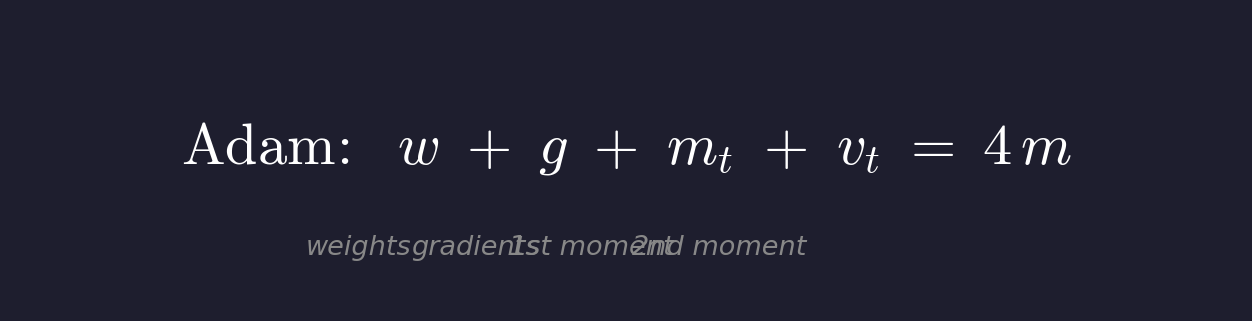
weights + gradients + first moment + second moment = 4m입니다. SGD 대비 2배의 parameter memory를 사용합니다.
AlexNet 예시
AlexNet의 파라미터 수는 약 61M(6100만 개)입니다. FP32(4 bytes/element) 기준으로 계산하면:
| Optimizer | 계산식 | 메모리 |
|---|---|---|
| SGD | 2 x 61M x 4B = 488MB | 488 MB |
| Momentum | 3 x 61M x 4B = 732MB | 732 MB |
| Adam | 4 x 61M x 4B = 976MB | 976 MB |
같은 모델인데 optimizer만 바꿔도 메모리 사용량이 488MB에서 976MB로 2배 차이가 납니다.
3. Activation Memory: Batch Size에 비례한다
Parameter memory는 모델 구조와 optimizer로 결정되고, batch size의 영향을 받지 않습니다. 반면 activation memory는 batch size에 정비례합니다.

여기서 alpha(α)는 모델의 각 레이어가 생성하는 activation 차원의 총합입니다. batch_size를 B라 하면, activation memory는 B x α가 됩니다.
Backward pass에서 gradient를 계산하려면 해당 레이어의 input activation이 필요합니다. chain rule에서 dL/dW = dL/dy x dy/dW인데, dy/dW를 구하려면 forward 때의 input을 알아야 하기 때문입니다. 그래서 forward pass 동안 생성된 모든 중간 activation을 메모리에 보관합니다.
batch size가 32에서 64로 늘어나면 activation memory도 정확히 2배가 됩니다. 대형 모델에서 OOM이 발생할 때 가장 먼저 줄이는 것이 batch size인 이유가 여기에 있습니다.
4. Training vs Inference: 메모리 차이의 두 가지 이유
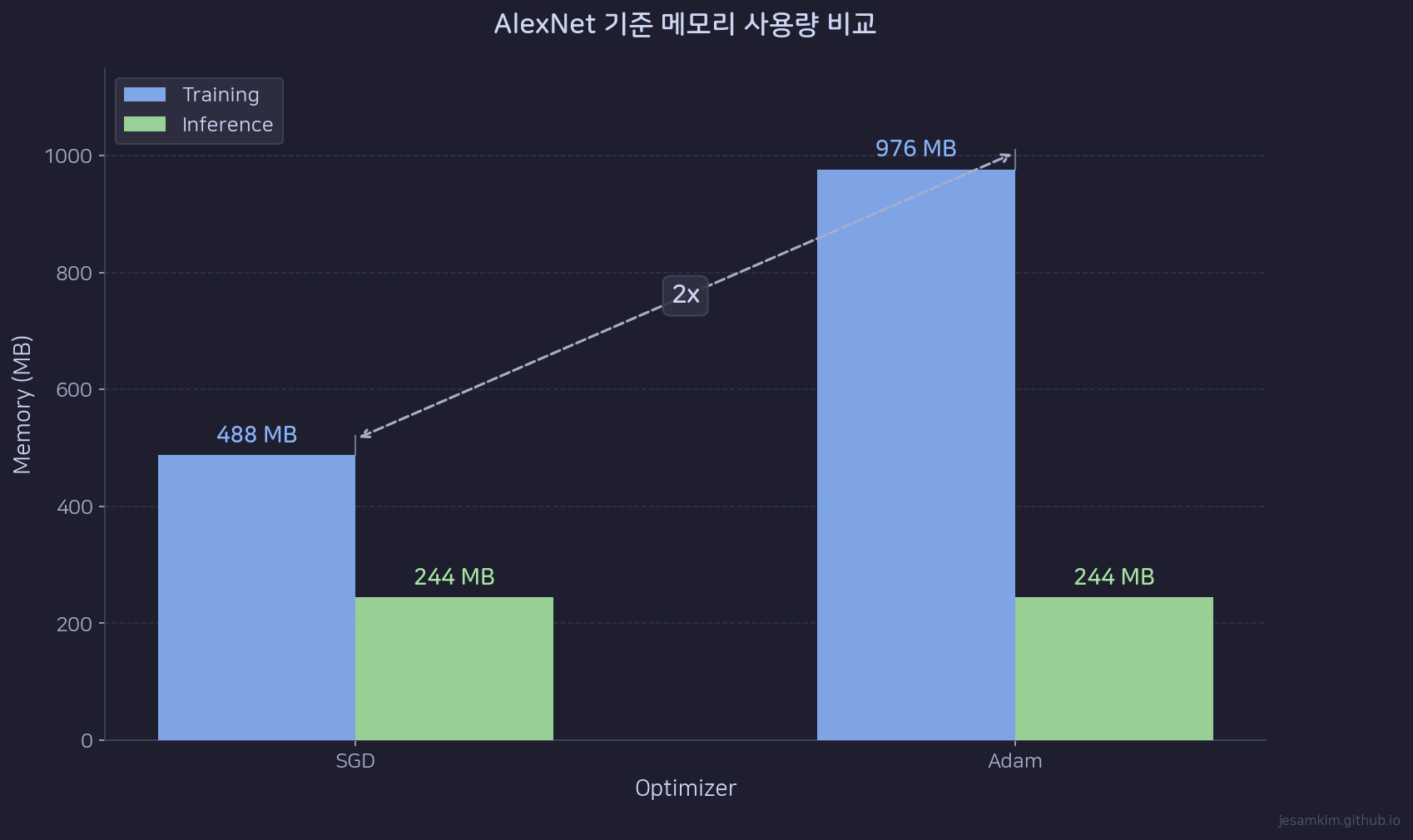 Training과 Inference의 메모리 구성 비교
Training과 Inference의 메모리 구성 비교
Inference에서는 모델의 weights만 메모리에 올리면 됩니다. 1m입니다. forward pass만 실행하면 되고, gradient를 계산할 필요가 없으며, 각 레이어의 activation은 다음 레이어 계산이 끝나면 바로 해제할 수 있습니다.
Training이 Inference보다 메모리를 많이 쓰는 이유는 두 가지입니다.
첫째, optimizer state가 추가됩니다. SGD는 gradient만 추가로 유지하면 되지만(+1m), Adam은 gradient + first moment + second moment까지 유지해야 합니다(+3m). Inference의 1m에 비해 Adam training은 4m으로, 4배의 parameter memory가 필요합니다.
둘째, 전체 activation을 유지해야 합니다. Inference에서는 레이어별로 activation을 생성하고 즉시 해제하면 됩니다. Training에서는 backward pass를 위해 모든 레이어의 activation을 끝까지 들고 있어야 합니다. batch size가 크고 모델이 깊을수록 이 차이가 극적으로 벌어집니다.
5. 메모리 사용량을 결정하는 세 가지 요인
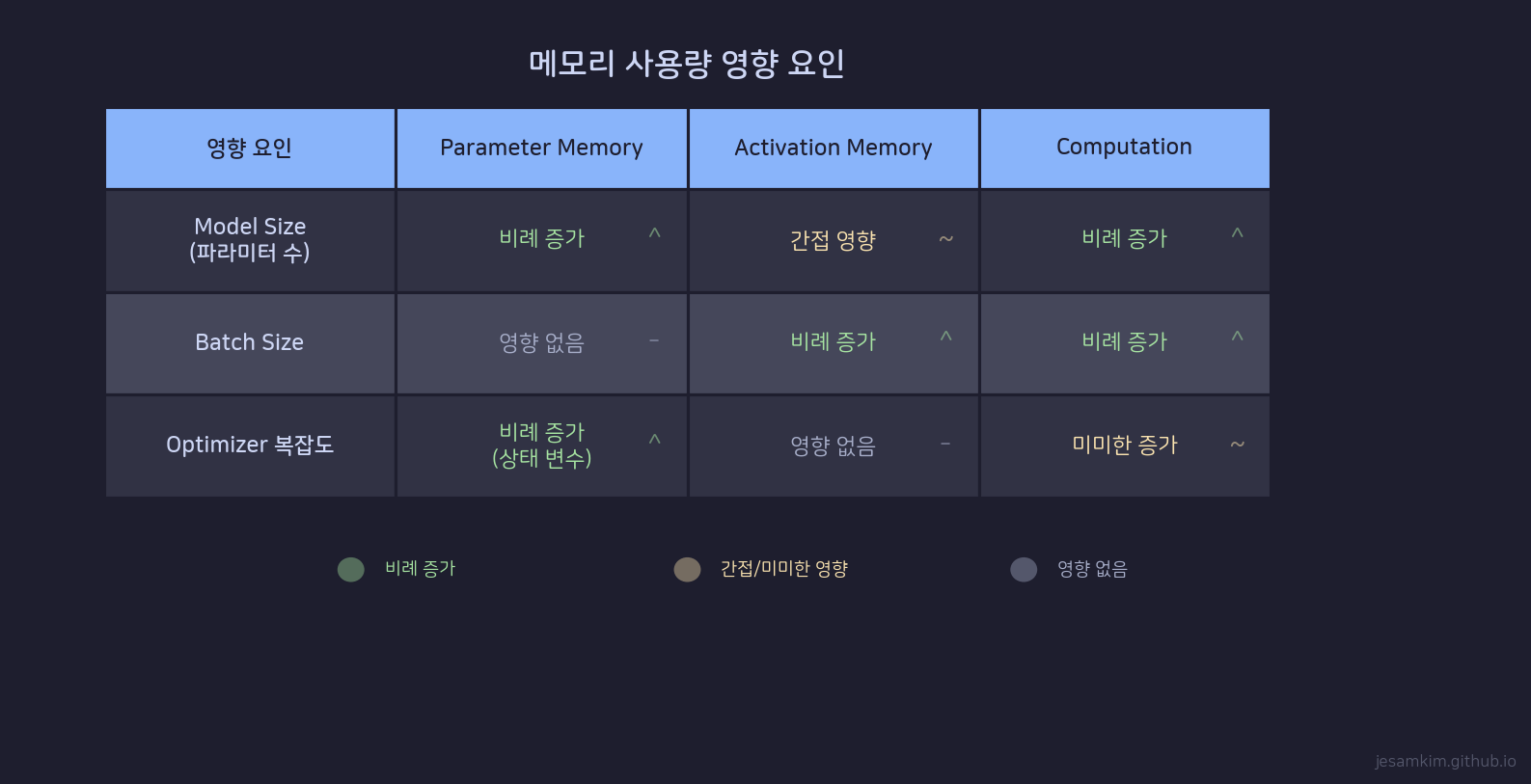 GPU 메모리 사용량에 영향을 미치는 세 가지 요인
GPU 메모리 사용량에 영향을 미치는 세 가지 요인
정리하면 이렇습니다.
Model Size는 parameter memory에 선형 비례합니다. 파라미터가 2배가 되면 weights, gradients, optimizer state 모두 2배가 됩니다.
Batch Size는 activation memory에 선형 비례합니다. parameter memory에는 영향을 주지 않습니다. OOM이 발생할 때 batch size를 줄이면 해결되는 경우가 많은 것은 activation memory만 줄어들기 때문입니다.
Optimizer 복잡도는 parameter memory의 배수를 결정합니다. SGD(2m)에서 Adam(4m)으로 바꾸면 parameter memory가 2배가 되지만, activation memory는 변하지 않습니다.
6. OOM 대응 전략
 OOM 발생 시 고려할 수 있는 네 가지 전략
OOM 발생 시 고려할 수 있는 네 가지 전략
Gradient Accumulation
batch size를 줄이되, 여러 mini-batch의 gradient를 누적해서 optimizer step을 한 번만 실행합니다. 실효 batch size는 유지하면서 activation memory를 줄이는 방법입니다. gradient를 합산만 하면 되므로 추가 메모리 비용이 거의 없습니다.
Activation Checkpointing
forward pass에서 모든 activation을 저장하는 대신, 일부만 저장(checkpoint)하고 나머지는 backward 때 다시 계산합니다. 메모리를 절약하는 대신 계산량이 늘어나는 트레이드오프입니다. 보통 전체 레이어의 제곱근(sqrt(L)) 개만 checkpoint하면 메모리를 O(L)에서 O(sqrt(L))로 줄일 수 있습니다.
Mixed Precision Training (FP16/BF16)
FP32(4 bytes) 대신 FP16이나 BF16(2 bytes)을 사용하면 weights와 activation의 메모리를 절반으로 줄일 수 있습니다. 단, optimizer state의 master weights는 FP32로 유지해야 수치 안정성이 보장됩니다. NVIDIA Ampere 이상 GPU에서 BF16이 지원되면서 실용성이 높아졌습니다.
Model Parallelism
한 GPU에 모델 전체를 올리는 대신, 여러 GPU에 모델을 분할합니다. Tensor Parallelism은 하나의 레이어를 여러 GPU에 나누고, Pipeline Parallelism은 레이어 그룹을 GPU별로 할당합니다. parameter memory와 activation memory를 모두 분산할 수 있지만, GPU 간 통신 오버헤드가 발생합니다.
정리
GPU 메모리는 Training 시에 크게 두 가지 축으로 소비됩니다. parameter memory(weights + gradients + optimizer states)는 모델 크기와 optimizer 종류에 의해 결정되고, activation memory는 batch size와 모델 깊이에 의해 결정됩니다. Inference에서는 weights만 들고 있으면 되므로(1m), Training(2m–4m + activations)과는 근본적으로 메모리 요구량이 다릅니다.
OOM을 만나면 먼저 batch size를 줄여서 activation memory를 낮추고, 그래도 부족하면 gradient accumulation, activation checkpointing, mixed precision, model parallelism을 단계적으로 적용하는 것이 일반적인 접근입니다.
다음 글에서는 이 메모리 문제를 여러 GPU로 해결하는 첫 번째 접근인 Data Parallelism을 분석합니다. activation memory는 GPU 수에 비례해서 줄어들지만, parameter memory는 쉽게 줄지 않는 이유를 살펴봅니다.
References
- Goodfellow, Bengio, Courville, “Deep Learning”, MIT Press, 2016, Chapter 8: Optimization for Training Deep Models
- Rajbhandari et al., “ZeRO: Memory Optimizations Toward Training Trillion Parameter Models” (arXiv:1910.02054) - https://arxiv.org/abs/1910.02054
- Micikevicius et al., “Mixed Precision Training” (arXiv:1710.03740) - https://arxiv.org/abs/1710.03740
- Chen et al., “Training Deep Nets with Sublinear Memory Cost” (arXiv:1604.06174) - https://arxiv.org/abs/1604.06174
- PyTorch Documentation, “CUDA Memory Management” - https://pytorch.org/docs/stable/notes/cuda.html