
이전 글에서 GPU 메모리가 parameter memory와 activation memory로 나뉘고, 특히 activation memory가 batch size에 비례한다는 것을 분석했습니다. 큰 모델을 큰 batch size로 학습하려면 GPU 한 장으로는 메모리가 부족합니다.
Data Parallelism(DP)은 이 문제에 대한 가장 직관적인 접근입니다. 데이터를 쪼개서 여러 GPU에 나눠주고, 각 GPU가 자기 몫의 데이터로 gradient를 계산한 뒤, 결과를 모아서 파라미터를 업데이트합니다. 이 글에서는 DP의 구체적인 동작 원리를 Parameter Server 아키텍처 기준으로 분석합니다.
1. Parameter Server 아키텍처
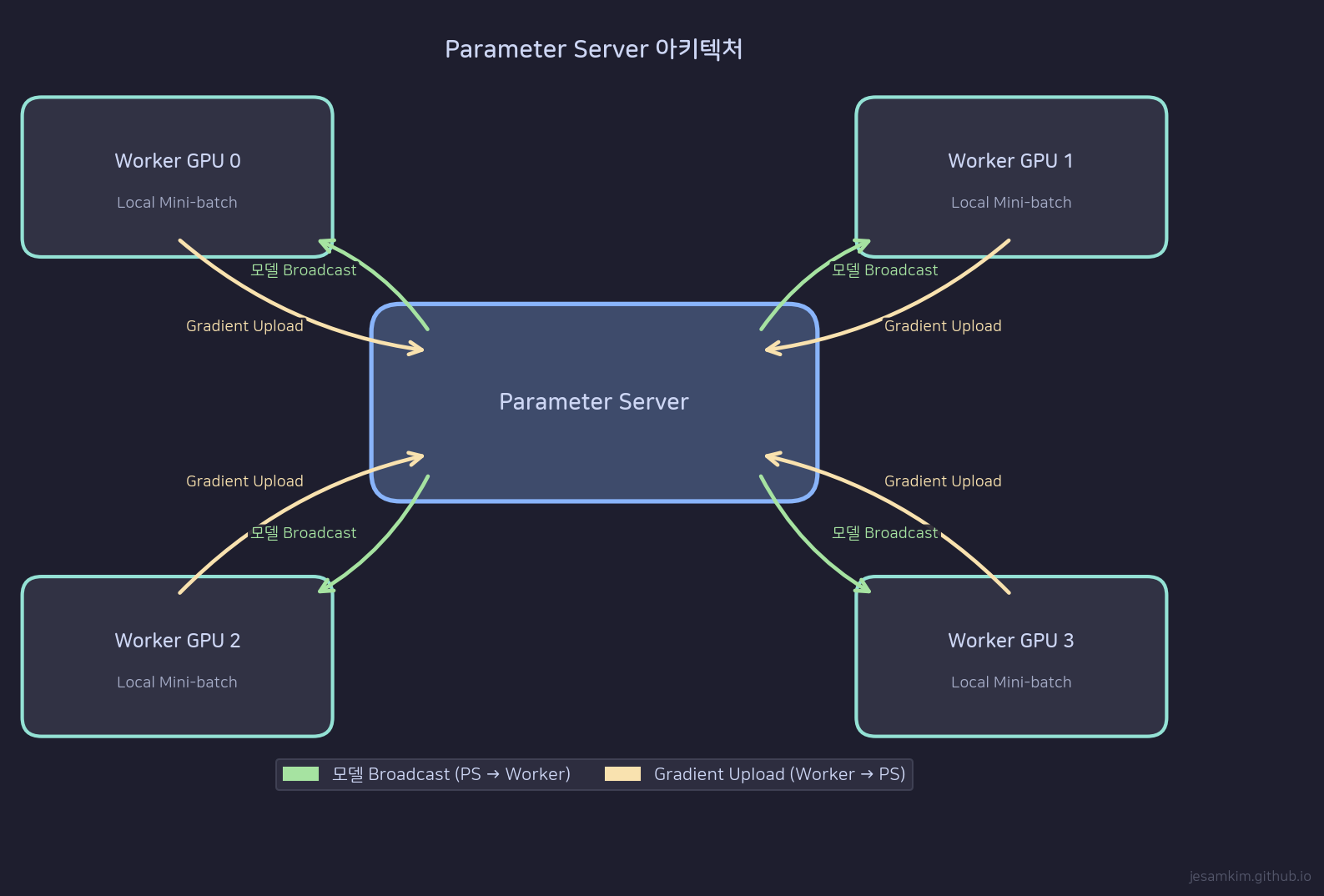 Parameter Server(PS) 아키텍처: PS가 파라미터를 관리하고, Worker GPU들이 gradient를 계산한다
Parameter Server(PS) 아키텍처: PS가 파라미터를 관리하고, Worker GPU들이 gradient를 계산한다
DP의 고전적 구현은 Parameter Server(PS) 방식입니다. 구성은 단순합니다.
Parameter Server는 모델의 전체 파라미터와 optimizer state를 보유합니다. 파라미터 배포, gradient 수집, optimizer step 실행을 담당합니다.
Worker GPU는 각각 모델의 복사본을 가지고 있으며, 자기에게 할당된 mini-batch로 forward/backward를 실행합니다. 계산이 끝나면 gradient를 PS에 보냅니다.
전체 데이터셋 D를 N개의 GPU에 균등 분할합니다. global batch size가 B라면 각 Worker는 B/N 크기의 mini-batch를 처리합니다.
2. 학습 4단계
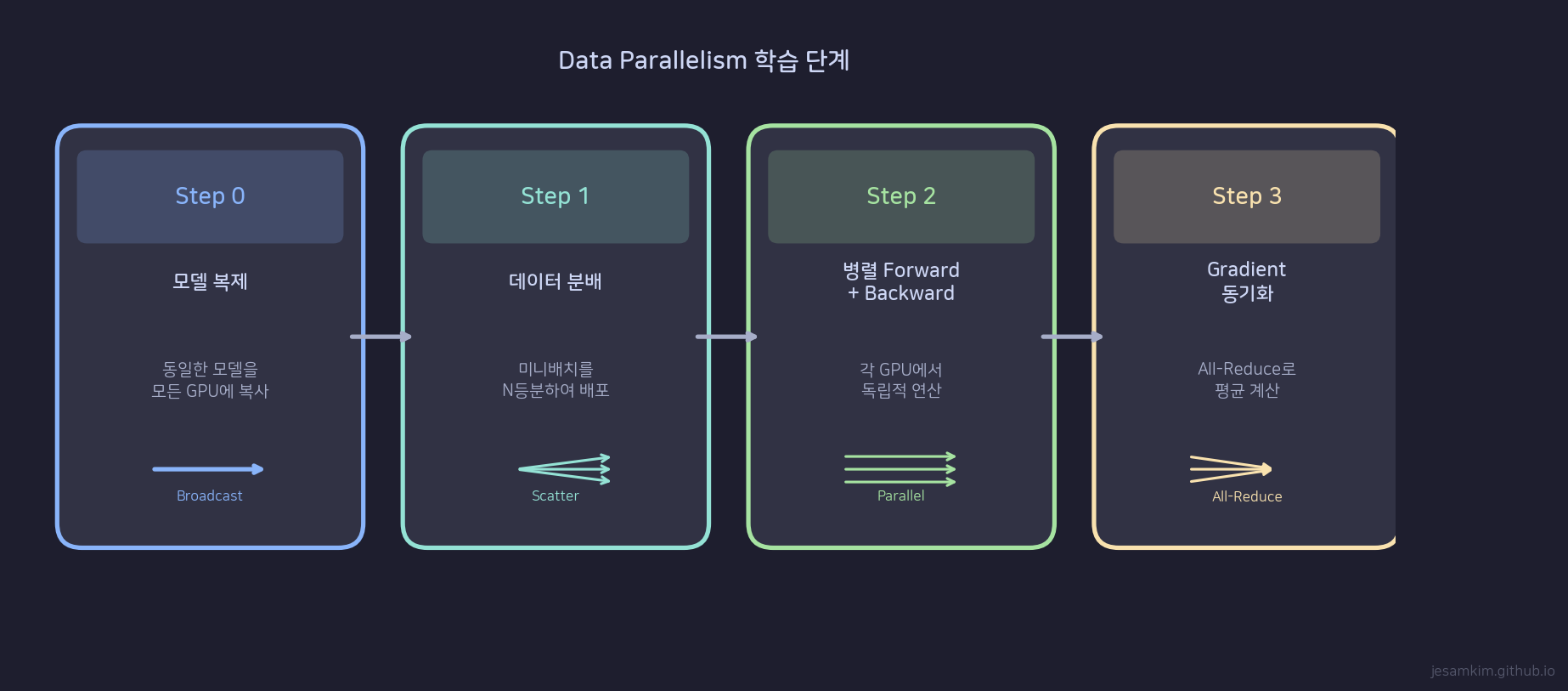 Data Parallelism 학습의 4단계: Broadcast - Local Compute - Aggregate - Update
Data Parallelism 학습의 4단계: Broadcast - Local Compute - Aggregate - Update
Step 0: Parameter Broadcast
PS가 현재 파라미터 wt를 모든 Worker에 전송합니다. 모든 Worker가 동일한 파라미터로 시작하는 것이 동기식(synchronous) DP의 전제입니다.
Step 1: Local Forward + Backward
각 Worker k가 자기 mini-batch Dk로 forward pass와 backward pass를 실행합니다. Worker k는 local gradient gk = (1/|Dk|) x sum of gradients over Dk를 계산합니다. 이 단계는 각 Worker가 독립적으로 수행하므로 병렬화됩니다.
Step 2: Gradient Aggregation
모든 Worker가 자기의 local gradient gk를 PS에 전송합니다. PS는 이를 평균합니다: g = (1/N) x (g1 + g2 + … + gN). 이 통신 단계가 DP의 병목입니다.
Step 3: Optimizer Update
PS가 aggregated gradient g를 사용해 optimizer step을 실행합니다. wt+1 = wt - lr x g. 업데이트된 파라미터는 다음 iteration의 Step 0에서 다시 broadcast됩니다.
3. Centralized Training과의 수학적 동치성
DP가 단일 GPU 학습과 정확히 같은 결과를 내는지는 수학적으로 증명할 수 있습니다.
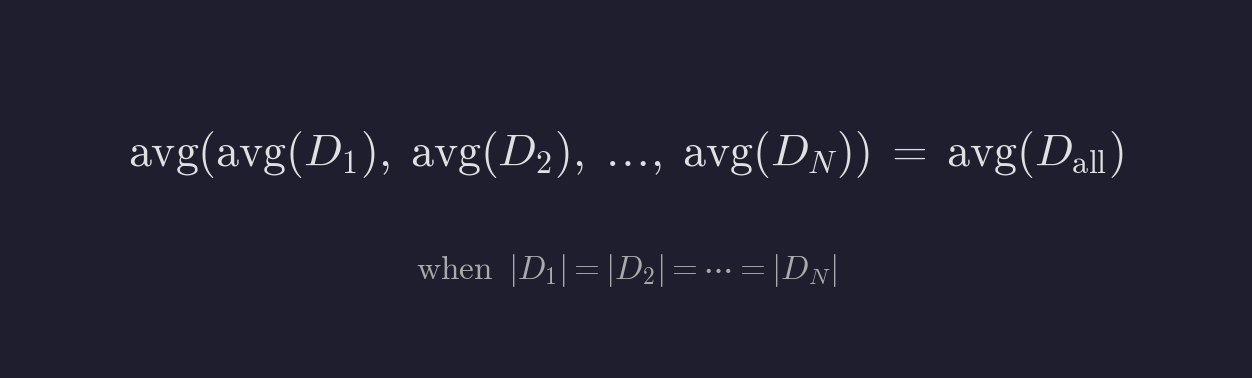
전체 데이터셋 D를 N개의 균등한 부분 D1, D2, …, DN으로 나눈다고 합시다. 각 부분의 크기가 동일할 때(|D1| = |D2| = … = |DN|), 부분 평균의 평균은 전체 평균과 같습니다.
구체적으로 보겠습니다. 전체 데이터셋에 대한 gradient의 평균은:
gcentralized = (1/B) x sum of all sample gradients
DP에서 각 Worker k의 local gradient는:
gk = (1/(B/N)) x sum of sample gradients in Dk = (N/B) x sum of sample gradients in Dk
이것들의 평균을 구하면:
gDP = (1/N) x sum(gk) = (1/N) x sum((N/B) x local sums) = (1/B) x sum of all sample gradients = gcentralized
분할 크기가 동일하다는 조건 하에서, DP의 aggregated gradient는 centralized training의 gradient와 수학적으로 동일합니다. 랜덤 시드까지 맞추면 bit-exact한 결과를 얻을 수 있습니다(floating point 연산 순서 차이는 무시할 경우).
4. 메모리 분석
DP에서 메모리가 어떻게 변하는지 분석합니다. 이전 글의 두 축(parameter memory, activation memory)으로 나눠서 봅니다.
Activation Memory: N분의 1로 감소

global batch size B를 N개의 Worker가 나눠 갖으므로, 각 Worker의 local batch size는 B/N입니다. activation memory는 batch size에 비례하므로, Worker 당 activation memory는 α x B/N이 됩니다. GPU 수를 늘리면 activation memory가 선형으로 줄어듭니다. 이것이 DP의 가장 큰 이점입니다.
Parameter Memory: PS 방식에서는 2m 고정

PS 방식에서 각 Worker는 weights(w)와 gradients(g)만 보유합니다. optimizer state는 PS에 있기 때문입니다. 따라서 Worker 당 parameter memory는 optimizer 종류에 무관하게 w + g = 2m입니다.
이 점이 중요합니다. Adam의 parameter memory가 4m이었던 것은 optimizer state(mt, vt)를 포함한 수치입니다. PS 방식에서는 이 state가 PS 측에 있으므로, Worker 입장에서는 SGD든 Adam이든 2m으로 동일합니다.
단, PS 자체는 전체 optimizer state를 유지해야 하므로 PS의 메모리 부담은 커집니다.
5. ResNet-18 ImageNet 예시
실제 수치로 계산해 봅시다. ResNet-18(파라미터 약 11.7M)을 ImageNet(224x224 입력)으로 학습하는 경우입니다.
Centralized (N=1, B=512)
- Parameter memory: 4 x 11.7M x 4B = 187.2 MB (Adam 기준, 4m)
- Activation memory: 약 20.85 GB (B=512, 224x224 입력 기준)
- 총 메모리: 약 21.03 GB
activation memory가 parameter memory를 압도합니다. 이 경우 메모리 병목은 parameter가 아니라 activation입니다.
Data Parallelism (N=10, B=512)
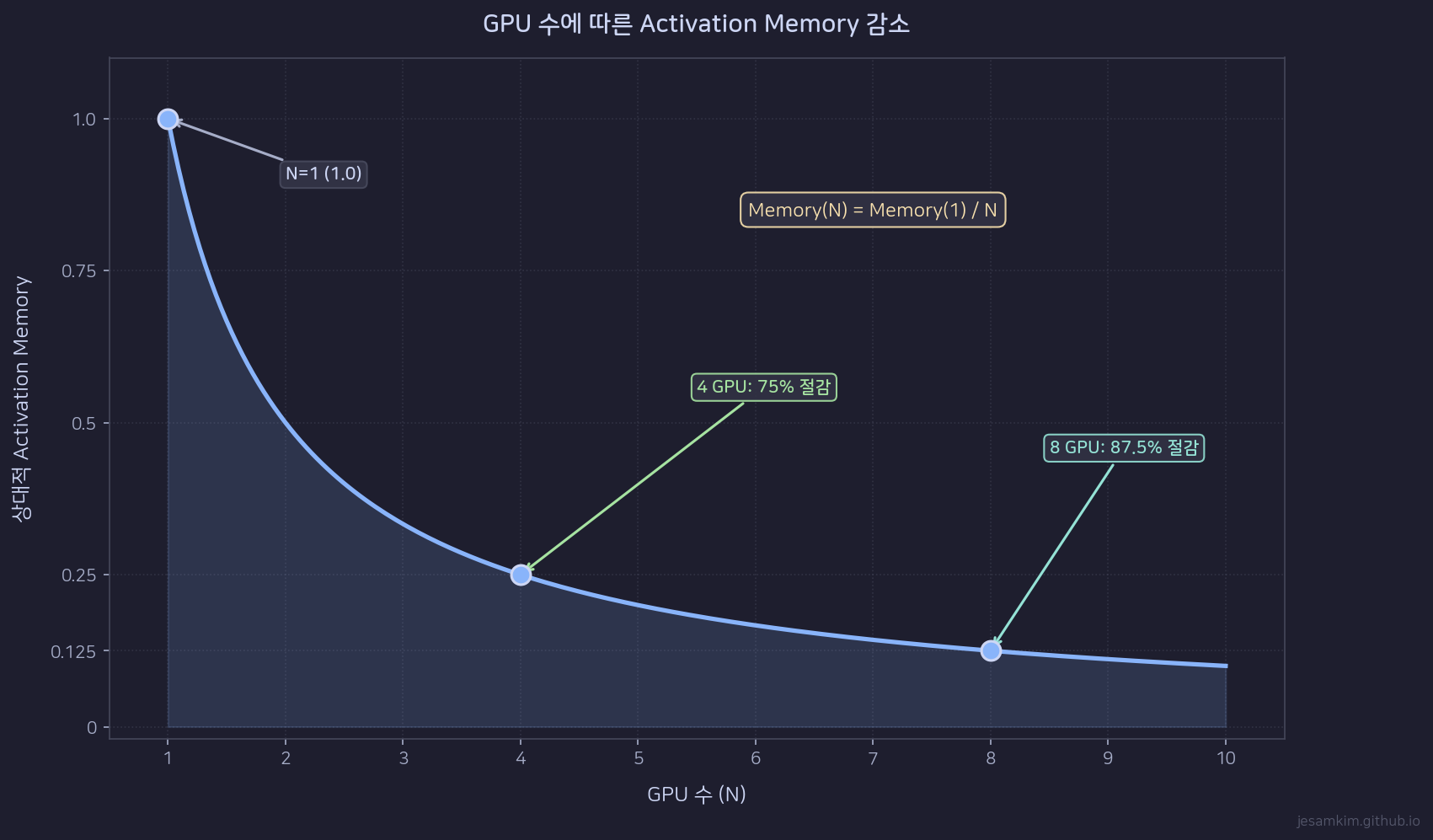 ResNet-18 ImageNet 학습: Centralized vs Data Parallelism (N=10) 메모리 비교
ResNet-18 ImageNet 학습: Centralized vs Data Parallelism (N=10) 메모리 비교
- Parameter memory per Worker: 2 x 11.7M x 4B = 93.6 MB (PS 방식, 2m)
- Activation memory per Worker: 20.85 GB / 10 = 2.09 GB
- Worker 당 총 메모리: 약 2.19 GB
21.03 GB에서 2.19 GB로, Worker 당 메모리가 약 10분의 1로 줄었습니다. activation memory가 지배적인 상황에서는 DP의 메모리 절감 효과가 GPU 수에 거의 비례합니다.
6. DP의 근본적 한계: Parameter Memory
activation memory는 N분의 1로 깔끔하게 줄어듭니다. 문제는 parameter memory입니다.
PS 방식에서 Worker당 parameter memory는 2m으로 고정됩니다. GPU를 10대로 늘리든 100대로 늘리든 2m입니다. GPU 수를 늘리면 activation은 줄어들지만, parameter memory는 전혀 줄어들지 않습니다.
모델이 충분히 크면(GPT-3 175B 파라미터 같은 경우), parameter memory 자체가 GPU 한 장에 들어가지 않습니다. FP32 기준 175B x 4 bytes = 700 GB이고, Adam 기준으로 4m = 2.8 TB입니다. 이 상황에서는 DP만으로는 근본적 해결이 불가능합니다. 모델 자체를 여러 GPU에 분할해야 하는데, 이것이 Model Parallelism과 Pipeline Parallelism의 영역입니다.
7. DP vs Federated Learning
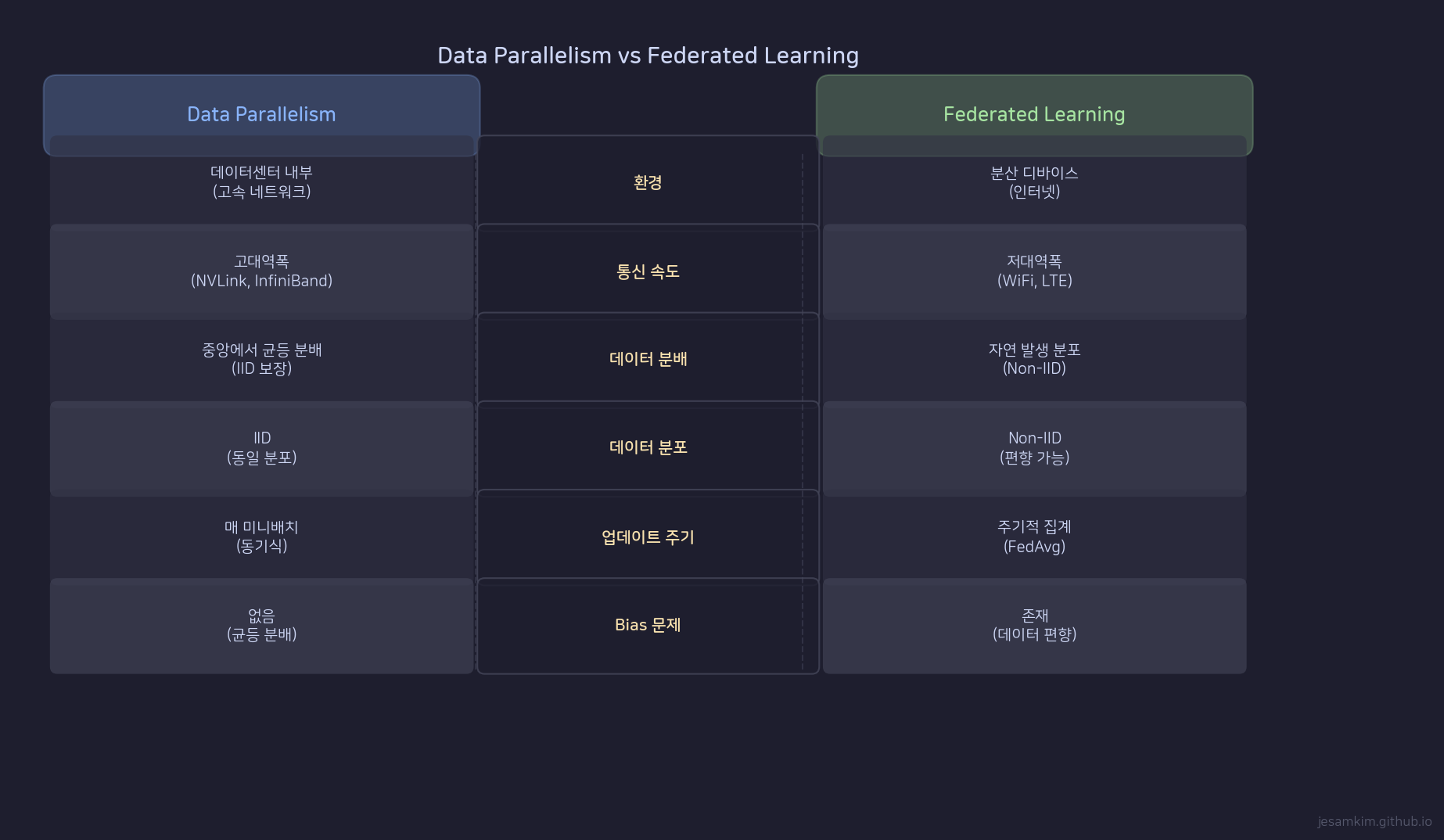 Data Parallelism과 Federated Learning의 구조 비교
Data Parallelism과 Federated Learning의 구조 비교
Data Parallelism과 Federated Learning(FL)은 “데이터를 분할해서 학습한다"는 점에서 표면적으로 비슷해 보입니다. 하지만 동작 환경과 결과가 다릅니다.
데이터 분포가 가장 큰 차이입니다. DP에서는 전체 데이터셋을 균등하게(IID) 분할합니다. 각 Worker의 mini-batch가 전체 분포를 대표하므로, 앞서 증명한 수학적 동치성이 성립합니다. FL에서는 각 device가 자기만의 데이터를 가지고 있고, 이 데이터가 전체 분포와 다를 수 있습니다(non-IID). 예를 들어, 스마트폰 키보드 예측 모델에서 한국어만 쓰는 사용자와 영어만 쓰는 사용자의 데이터 분포는 매우 다릅니다.
통신 환경도 다릅니다. DP는 데이터센터 내부의 고속 네트워크(NVLink, InfiniBand)를 사용합니다. FL은 인터넷을 통해 edge device들과 통신하므로 대역폭이 제한적이고 지연이 큽니다.
업데이트 방식에서, DP는 보통 동기식(synchronous)입니다. 모든 Worker의 gradient가 도착할 때까지 기다립니다. FL은 비동기식(asynchronous)이 가능하고, FedAvg처럼 여러 local epoch을 돌린 후 모델 가중치를 교환하는 방식을 씁니다.
bias 문제에서 차이가 명확합니다. DP는 IID 분할 덕분에 bias가 없습니다. FL은 non-IID 데이터로 인한 client drift 문제가 있어서, FedProx나 SCAFFOLD 같은 보정 알고리즘이 필요합니다.
결론적으로, DP와 FL은 목적이 다릅니다. DP는 학습 속도를 높이기 위한 것이고, FL은 데이터를 중앙에 모으지 않고도 모델을 학습하기 위한 것입니다.
정리
Data Parallelism은 데이터를 N개 GPU에 나눠서 학습 속도를 높이고, activation memory를 1/N로 줄이는 효과적인 방법입니다. PS 방식에서 각 Worker의 parameter memory는 optimizer와 무관하게 2m으로 고정되고, Centralized Training과 수학적으로 동치인 gradient를 생산합니다.
하지만 DP는 parameter memory의 근본적 해결책이 아닙니다. 모델이 GPU 한 장에 들어가지 않을 정도로 커지면, DP만으로는 학습이 불가능합니다. 다음 글에서는 모델 자체를 GPU에 분할하는 Pipeline Parallelism의 진화 과정을 분석합니다. Naive Pipeline에서 시작해서 GPipe, 1F1B, 그리고 Zero Bubble까지, bubble을 어떻게 줄여왔는지 추적합니다.
References
- Li et al., “Scaling Distributed Machine Learning with the Parameter Server” (OSDI 2014) - https://www.usenix.org/conference/osdi14/technical-sessions/presentation/li_mu
- Dean et al., “Large Scale Distributed Deep Networks” (NIPS 2012) - https://proceedings.neurips.cc/paper/2012/hash/6aca97005c68f1206823815f66102863-Abstract.html
- McMahan et al., “Communication-Efficient Learning of Deep Networks from Decentralized Data” (arXiv:1602.05629) - https://arxiv.org/abs/1602.05629
- Karimireddy et al., “SCAFFOLD: Stochastic Controlled Averaging for Federated Learning” (arXiv:1910.06378) - https://arxiv.org/abs/1910.06378
- He et al., “Deep Residual Learning for Image Recognition” (arXiv:1512.03385) - https://arxiv.org/abs/1512.03385
- PyTorch Distributed Overview - https://pytorch.org/tutorials/beginner/dist_overview.html