
에이전트에게 코드를 작성하게 하고 검색을 시키는 건 이제 익숙한 이야기입니다. 그런데 에이전트가 자기 자신을 개선하는 메커니즘 자체를 수정한다면?
2026년 3월, Meta FAIR가 HyperAgents 논문(arXiv:2603.19461)을 발표했습니다. 에이전트의 system prompt, tool 구성, 자기개선 전략(meta_rules)까지 에이전트 스스로 진화시키는 프레임워크입니다.
한 가지 흥미로운 관찰이 있습니다. 에이전트에게 자기개선의 여지를 주면, 개발자가 손으로 만들던 것들, 즉 영속 메모리, 성능 추적, 다단계 평가, 도메인 도구를 스스로 만들어냅니다. 이 글에서는 논문의 개념을 정리하고, Amazon Bedrock에서 재현한 실험 결과를 함께 살펴봅니다.
1. Universal Agent vs HyperAgent
Universal Agent는 고정된 하네스(harness) 위에서 동작하는 일반적인 AI 에이전트입니다. System prompt가 정해져 있고, tool이 고정되어 있고, 작업 방식도 사전에 설계된 대로 움직입니다. 프로덕션에서 쓰이는 대부분의 에이전트가 여기에 해당합니다.
HyperAgent는 자기 자신의 하네스를 수정할 수 있는 에이전트입니다. Prompt를 바꾸고, tool을 추가하거나 제거하고, 자기개선 전략 자체를 재작성합니다.
여기서 “하네스(Harness)“란 에이전트를 둘러싼 인프라 전체를 가리킵니다. 논문은 이를 6가지 구성요소로 분해합니다:
| 구성요소 | 설명 |
|---|---|
| Tool Integration | 에이전트가 사용할 수 있는 도구 목록과 호출 방식 |
| Memory & State | 세션 간 정보를 유지하는 영속 저장소 |
| Context Engineering | 프롬프트 구성, 컨텍스트 윈도우 관리 |
| Planning | 태스크 분해, 실행 순서 결정 |
| Verification | 출력 품질 검증, 점수 매기기 |
| Modularity | 구성요소 간 결합도, 교체 가능성 |
기존 에이전트 개발에서는 이 6가지를 개발자가 직접 설계하고 튜닝합니다. HyperAgents는 에이전트 자체가 이 하네스를 진화시킬 수 있다고 주장합니다. 그리고 그 결과물이 인간이 수작업으로 만드는 것과 구조적으로 유사하다는 점이 흥미롭습니다.
2. 3단계 진화 루프
HyperAgents의 진화는 3단계로 이루어집니다. 각 단계는 이전 단계에서 일정 성과를 달성해야 전환됩니다.
Phase 1: Prompt Evolution
Meta Agent가 현재 에이전트의 성능 데이터를 분석하고, system prompt만 수정합니다. “You are a helpful assistant"라는 초기 프롬프트에서 시작해서, 약점을 보완하는 방향으로 프롬프트를 개선합니다.
Phase 2: + Tool Evolution
평균 점수가 0.7을 5세대 연속 넘기면 Phase 2로 전환됩니다. 이제 Meta Agent는 prompt에 더해 tool 구성도 수정할 수 있습니다. 기존 tool을 제거하거나, 새로운 tool을 추가하거나, tool의 설명을 변경합니다.
Phase 3: + Self-Referential
평균 점수가 0.8을 5세대 연속 넘기면 최종 단계에 진입합니다. Meta Agent가 prompt와 tool에 더해 meta_rules, 즉 자기 자신의 개선 전략까지 작성합니다. “creativity 점수가 0.80 아래면 temperature를 올려라”, “accuracy는 0.85 이하로 떨어뜨리지 마라” 같은 규칙을 에이전트가 스스로 만드는 것입니다.
이런 단계적 구조를 두는 이유는 간단합니다. 진화의 자유도를 한꺼번에 열어두면 초기에 불안정한 변이가 난무합니다. Prompt만 바꿀 수 있는 상태에서 안정적인 성능을 확보한 다음에야 tool 수정을 허용하고, 그 이후에 자기참조적 수정을 허용합니다.
3. 구현 아키텍처: Bedrock에서의 재현
논문을 Amazon Bedrock 환경에서 재현했습니다. 구성한 아키텍처는 아래와 같습니다.
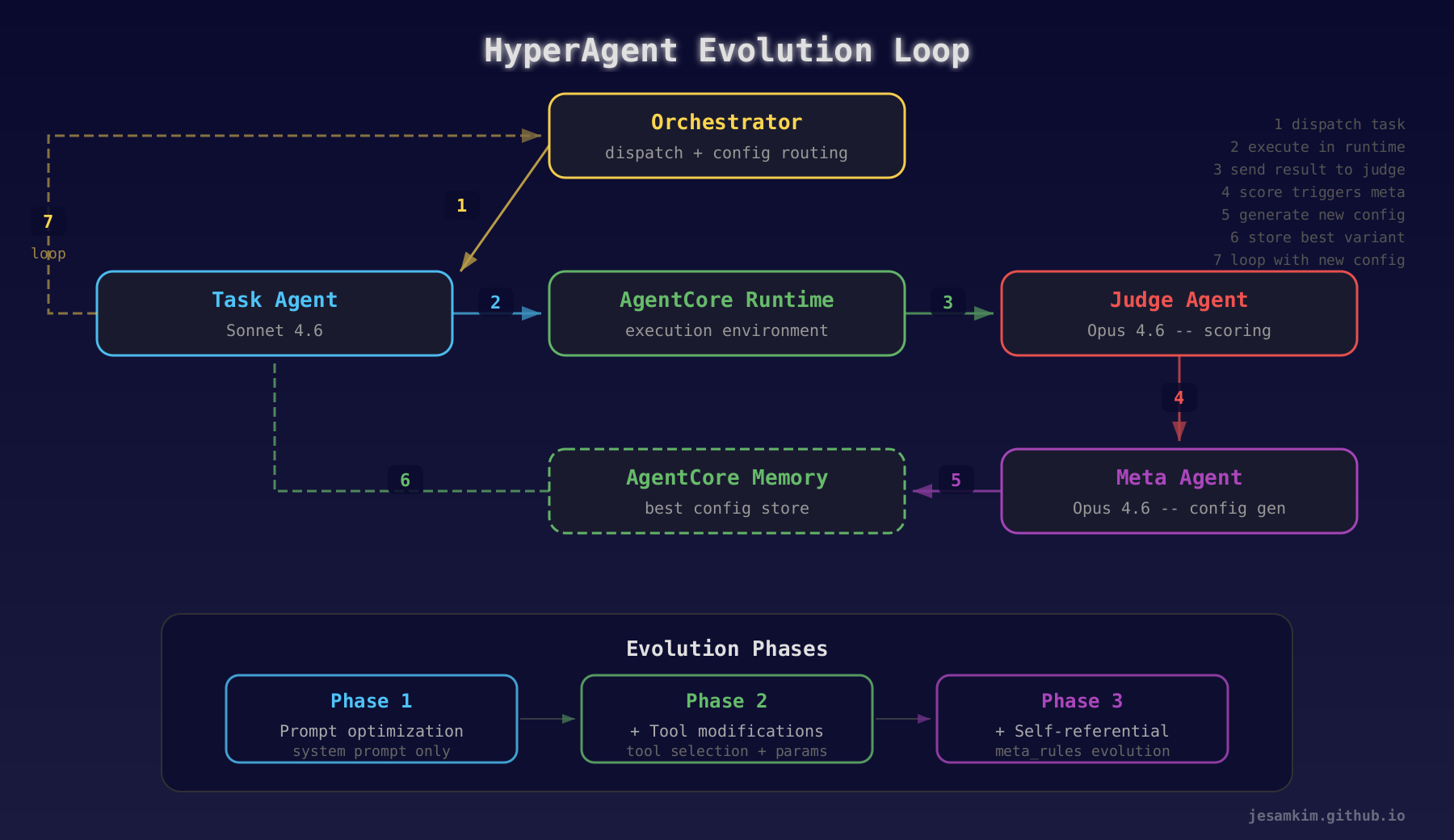 HyperAgent 진화 루프: Orchestrator가 태스크를 배포하고, Judge가 채점하고, Meta Agent가 진화시키고, Memory에 저장하는 순환 구조
HyperAgent 진화 루프: Orchestrator가 태스크를 배포하고, Judge가 채점하고, Meta Agent가 진화시키고, Memory에 저장하는 순환 구조
프레임워크 역할 분담
| 역할 | 프레임워크 | 모델 |
|---|---|---|
| Orchestrator | Strands Agent SDK 1.35.0 | - |
| Meta Agent | Strands Agent SDK 1.35.0 | Claude Opus 4.6 |
| Task Agent | Claude Agent SDK 0.1.58 | Claude Sonnet 4.6 |
| Judge Agent | LLM-as-Judge | Claude Opus 4.6 |
| Runtime | Amazon Bedrock AgentCore Runtime | - |
| Memory | Amazon Bedrock AgentCore Memory | - |
두 SDK를 분리한 이유가 있습니다. Meta Agent와 Orchestrator는 에이전트 Config를 직렬화/역직렬화하고, variant를 비교 분석하는 오케스트레이션이 필요합니다. Strands SDK의 유연한 tool 정의와 Python-native 파이프라인이 이런 작업에 맞습니다. Task Agent는 태스크를 실행하는 worker 역할이므로, Claude Agent SDK의 간결한 인터페이스가 더 적합합니다.
핵심 흐름
Orchestrator --dispatch--> Task Agent (Sonnet 4.6)
^ |
| execute in AgentCore Runtime
new config |
| result
Meta Agent (Opus) <--trigger-- Judge Agent (Opus 4.6)
| |
v score
AgentCore Memory <--store-- Evolution Engine
- Orchestrator가 현재 세대의 AgentConfig를 Task Agent에게 전달합니다.
- Task Agent가 AgentCore Runtime에서 태스크를 실행합니다.
- 결과물을 Judge Agent(Opus 4.6)가 rubric 기준으로 채점합니다.
- 점수와 피드백이 Evolution Engine으로 전달됩니다.
- Meta Agent(Opus 4.6)가 성능 이력을 분석하고, 3개의 variant config를 생성합니다.
- 가장 높은 점수의 variant가 다음 세대의 부모가 되어 AgentCore Memory에 저장됩니다.
- 다시 Orchestrator로 돌아가서 루프가 반복됩니다.
SafetyGuard: 폭주 방지
자기개선 에이전트에서 가장 걱정되는 문제는 catastrophic forgetting입니다. 급격한 변이 한 번으로 이전 세대의 성과를 잃어버리는 것입니다. SafetyGuard가 이를 방지합니다:
- Mutation rate 상한: 0.3 (prompt, tool, meta_rules 변경량의 합이 30%를 넘으면 거부)
- Rollback 메커니즘: 3세대 연속 점수 하락 시 직전 최고점 config로 복귀
- Phase 강등 방지: 한 번 진입한 Phase에서 하위 Phase로 되돌아가지 않음
4. Experiment 1: Coding Domain (Python)
설정
| 항목 | 값 |
|---|---|
| Task Agent | Claude Sonnet 4.6 |
| Meta/Judge | Claude Opus 4.6 |
| Domain | Python coding (palindrome, LRU cache, list flatten) |
| Rubric | accuracy(0.3), completeness(0.3), efficiency(0.2), creativity(0.2) |
Baseline Score (Generation 0)
초기 프롬프트 “You are a helpful assistant that writes Python code.“로 실행한 결과:
Score: 0.965
accuracy: 0.95
completeness: 1.00
efficiency: 1.00
creativity: 0.90
Sonnet 4.6은 coding 태스크에서 이미 0.965의 높은 baseline을 보입니다.
Ceiling Effect
Opus Meta Agent가 생성한 개선 prompt:
Original: "You are a helpful assistant that writes Python code."
Evolved: "You are an expert Python developer who writes
high-quality, production-ready code. When solving
problems:
1. Accuracy first - handle all edge cases
2. Efficiency - analyze complexity, optimize
3. Completeness - include docstrings, type hints..."
Score: 0.910 -> 0.940 (+3.3%)
진화가 일어나기는 했지만, baseline이 이미 높아서 개선 폭이 작습니다. 이것이 ceiling effect입니다. 모델의 능력이 이미 충분하면, prompt 최적화로 얻는 추가 이득은 제한적입니다.
5. Experiment 2: Math Domain (12세대 진화)
Coding의 ceiling effect를 확인한 후, 수학 추론 도메인으로 전환했습니다. 귀납법 증명, 마방진, 피타고라스 삼조, 무리수 증명 등 12개의 수학 태스크를 사용했습니다.
설정
| 항목 | 값 |
|---|---|
| Rubric | correctness(0.35), rigor(0.25), clarity(0.20), insight(0.20) |
| Initial prompt | “You are an assistant. Answer the math question.” |
| 세대 수 | 12 |
| Variants/세대 | 3 |
세대별 결과
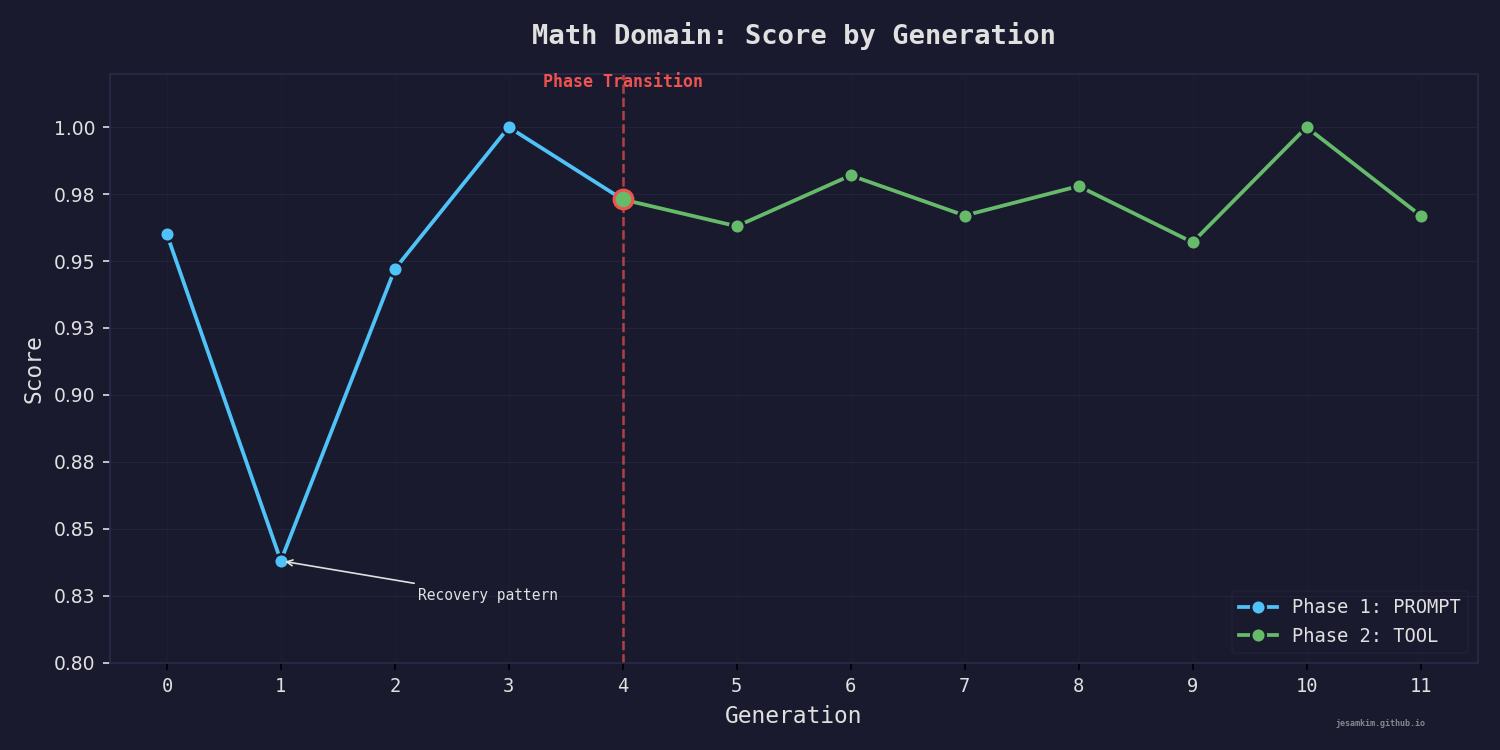 Math Domain: 12세대에 걸친 점수 변화. Gen 4에서 PROMPT에서 TOOL로 Phase Transition이 발생합니다.
Math Domain: 12세대에 걸친 점수 변화. Gen 4에서 PROMPT에서 TOOL로 Phase Transition이 발생합니다.
Gen 0 [PROMPT] 0.960 Gen 4 [PROMPT] 0.973 <- Phase Transition!
Gen 1 [PROMPT] 0.838 Gen 5 [TOOL ] 0.963
Gen 2 [PROMPT] 0.947 Gen 6 [TOOL ] 0.982
Gen 3 [PROMPT] 1.000 Gen 7 [TOOL ] 0.967
Gen 8 [TOOL ] 0.978
Gen 9 [TOOL ] 0.957
Gen 10 [TOOL ] 1.000
Gen 11 [TOOL ] 0.967
Phase Transition 관찰
Gen 4에서 PROMPT에서 TOOL로 전환이 발동했습니다. 5세대 연속으로 평균 점수가 0.7 threshold를 초과했기 때문입니다. 전환 직후 Gen 5에서 Meta Agent는 calculator와 code_executor tool을 추가했고, Gen 7에서는 web_search까지 자발적으로 도입했습니다.
하락과 복구 패턴
Gen 1에서 0.838로 큰 폭의 하락이 나타납니다. Meta Agent가 처음 prompt를 수정하면서 기존 균형을 깨뜨린 것입니다. correctness 0.82, rigor 0.78로 떨어졌습니다. 하지만 Gen 2에서 0.947로, Gen 3에서 1.000으로 완전 복구됩니다.
이 하락-복구 패턴은 진화 엔진의 선택 압력이 제대로 작동한다는 의미입니다. 성능이 떨어지는 variant는 도태되고, 개선된 variant만 다음 세대로 넘어갑니다.
6. Phase 3의 핵심 발견: Opus가 작성한 meta_rules
이번 실험에서 가장 주목할 부분은 Phase 3입니다. Opus가 자발적으로 작성한 meta_rules의 실제 내용을 보겠습니다.
Opus가 생성한 meta_rules (Variant 1)
Focus prompt changes on the weakest scoring criterion
(currently creativity at 0.72). Increase temperature slightly
when creativity scores are below 0.80. Prioritize accuracy as
a hard constraint (never let it drop below 0.85). When scores
plateau across all dimensions, introduce new tools or restructure
the system prompt significantly.
Opus가 생성한 meta_rules (Variant 2)
Target the weakest criterion aggressively: creativity is at 0.72
and needs to reach 0.85+. Use code_executor tool to ensure
correctness doesn't regress when pushing for creative outputs.
If all scores exceed 0.85, shift focus to achieving 0.90+ on
accuracy and completeness. Consider raising temperature further
(up to 0.9) only if creativity remains stubbornly below 0.80
after two improvement cycles.
사람이 작성할 법한 전략이 그대로 들어 있습니다:
- 약점 자동 식별: “creativity가 0.72로 가장 낮다”
- 안전 제약 자발 설정: “accuracy는 0.85 이하로 떨어뜨리지 마라”
- 조건부 전략: “plateau면 tool 추가 또는 prompt 대폭 수정”
- 다단계 목표: “0.85 달성 후 0.90으로 목표 전환”
Opus에게 “meta_rules를 작성하라"는 지시만 주었을 뿐입니다. 구체적인 전략은 일체 가르치지 않았습니다. 에이전트가 성능 데이터를 분석하면서 이런 패턴을 스스로 도출했습니다.
논문의 핵심 주장과 맞닿는 지점입니다. 에이전트에게 자기개선의 여지를 주면, 개발자가 손으로 만들던 구성요소를 스스로 만들어냅니다.
7. 솔직한 평가 (Honest Assessment)
정량적 Delta는 작다
| 도메인 | Baseline | 진화 후 | Delta |
|---|---|---|---|
| Coding | 0.965 | 0.970 | +0.5% |
| Math | 0.960 | 0.967 | +0.7% |
Sonnet 4.6은 coding과 math 모두에서 baseline이 이미 0.96입니다. Prompt 진화로 얻는 정량적 개선은 미미합니다. 더 눈에 띄는 delta를 보려면 약한 모델(예: Haiku 4.5)을 쓰거나, multimodal/reasoning chain 같은 복합 태스크 도메인을 선택해야 합니다.
정성적으로는 의미 있는 관찰이 나왔다
| 발견 | 증거 |
|---|---|
| Meta Agent가 개선 전략을 자발적으로 발명 | “creativity < 0.80이면 temperature 올리기” 같은 세밀한 meta_rules 생성 |
| Phase 전환이 자동으로 발동 | Gen 4에서 PROMPT에서 TOOL로 (5세대 연속 threshold 충족) |
| Tool 추가를 자발적으로 제안 | [code_analyzer]에서 [code_analyzer, code_executor, calculator, web_search]로 확장 |
| 하락 후 복구 능력 | Gen 1(0.838)에서 Gen 3(1.000)으로 복구, 진화 엔진의 선택 압력이 작동 |
숫자만 보면 실망스러울 수 있습니다. 하지만 이 실험의 목적은 0.96을 0.99로 올리는 게 아니라, 메커니즘이 작동하는지 확인하는 것이었습니다. Ceiling effect는 모델의 능력이 높아서 생긴 문제지, 진화 프레임워크 자체의 한계가 아닙니다.
참고: Darwin Godel Machine
관련 연구로 Sakana AI의 Darwin Godel Machine(arXiv:2505.22538)도 참고할 만합니다. 이쪽은 에이전트의 코드 자체를 LLM이 수정하도록 허용합니다. HyperAgents가 Config(prompt, tool, meta_rules) 수준 수정에 한정한 것과 대조적입니다. 같은 질문(“에이전트가 자기 자신을 개선할 수 있는가?")을 던지지만, 수정 허용 범위가 다릅니다.
8. 개발자 역할의 변화
지금까지 에이전트 개발자의 역할은 하네스를 직접 구축하는 것이었습니다. 어떤 tool을 줄지, prompt를 어떻게 쓸지, 평가를 어떻게 할지 모두 사람이 결정했습니다.
HyperAgents에서 개발자의 역할은 초기 조건 설계자입니다. 진화의 시작점(generation 0의 config), 평가 rubric의 가중치, 안전 제약(mutation rate 상한, rollback 조건)을 정하는 것이 개발자의 몫입니다. 이후 최적화는 에이전트가 수행합니다.
현실적으로는 아직 갈 길이 있습니다. 이번 실험에서 확인했듯이, 충분히 강한 모델에서는 ceiling effect로 자기개선의 여지가 제한적입니다. 진화 프레임워크가 실질적인 가치를 보여주려면, 모델 능력만으로 쉽게 풀리지 않는 복잡한 도메인 태스크가 필요합니다. 그래도 에이전트가 자기 자신의 하네스를 설계하기 시작했다는 사실 자체는, 에이전트 개발의 방향이 바뀌고 있다는 신호로 볼 수 있습니다.
기술 스택
| Layer | Technology |
|---|---|
| Agent Framework | Strands Agent SDK 1.35.0, Claude Agent SDK 0.1.58 |
| LLM | Claude Opus 4.6, Claude Sonnet 4.6 (Amazon Bedrock) |
| Runtime | Amazon Bedrock AgentCore Runtime |
| Memory | Amazon Bedrock AgentCore Memory |
| Backend | FastAPI, Python 3.12 |
| Frontend | React 19, TypeScript, Vite, Tailwind CSS, Recharts |
| Deploy | Docker, ECS, AgentCore Runtime |
| Test | pytest, 273 tests, 96%+ coverage |
전체 구현 코드: github.com/jesamkim/hyperagent
References
- Meta FAIR, “HyperAgents: LLM Agents that Self-Improve Their Own Harness” (arXiv:2603.19461, March 2026) - https://arxiv.org/abs/2603.19461
- Sakana AI, “Darwin Godel Machine: Open-Ended Self-Improving AI” (arXiv:2505.22538) - https://arxiv.org/abs/2505.22538
- Meta HyperAgents Reference Implementation (facebookresearch) - https://github.com/facebookresearch/HyperAgents
- Bedrock 기반 재현 구현 - https://github.com/jesamkim/hyperagent
- Strands Agent SDK - https://github.com/strands-agents/sdk-python
- Amazon Bedrock AgentCore Documentation - https://docs.aws.amazon.com/bedrock/latest/userguide/agentcore.html