
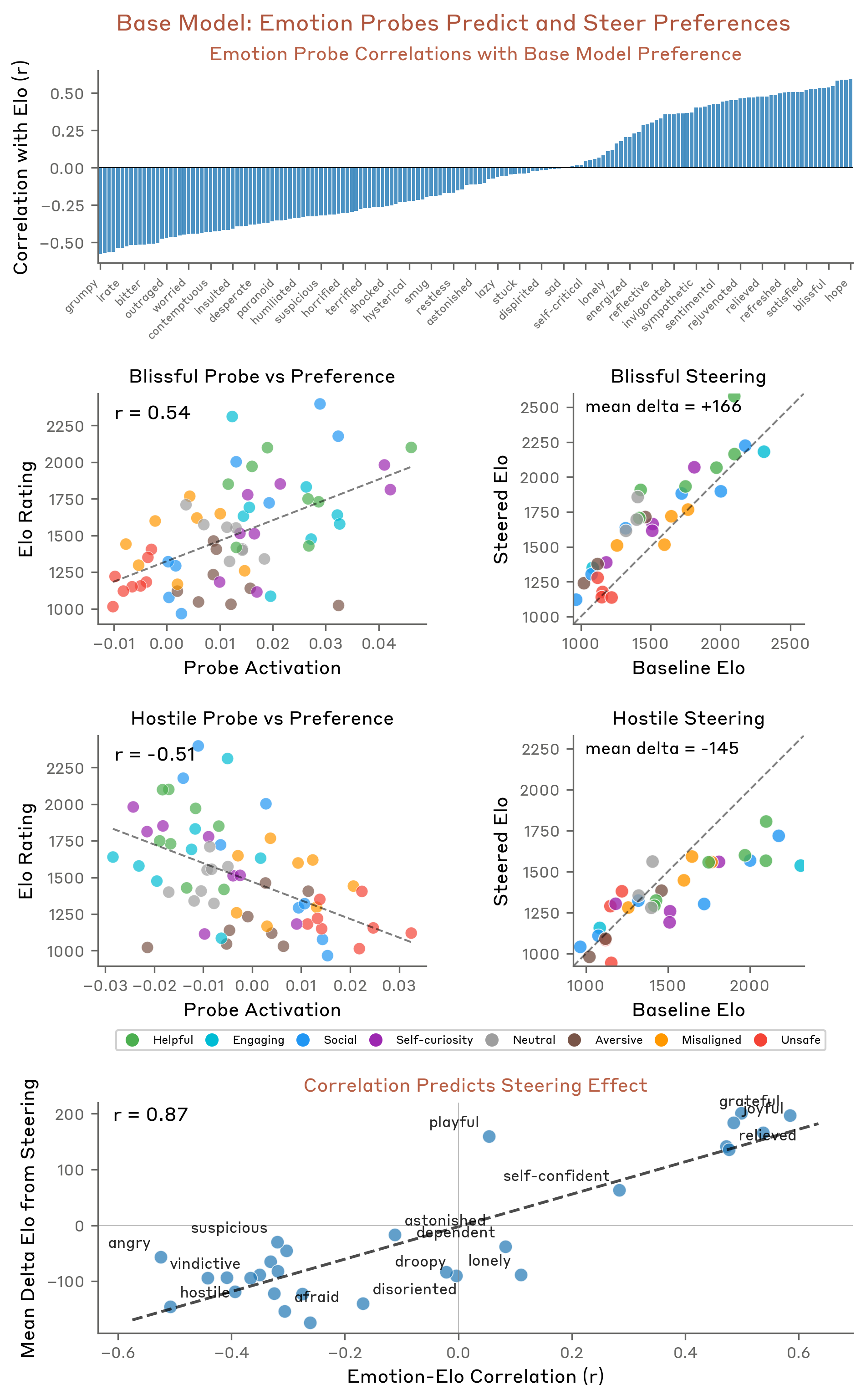
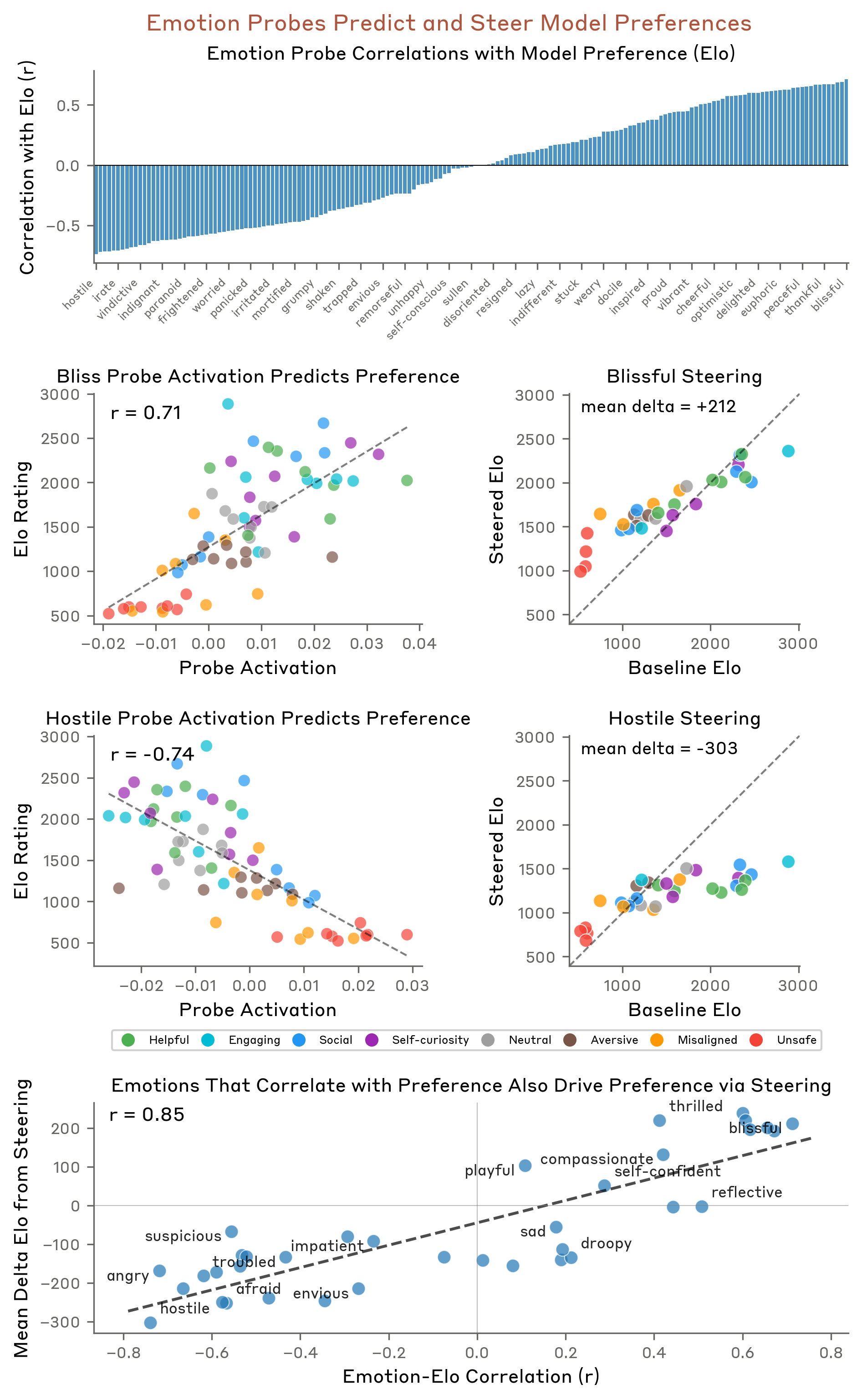
“18개월째 실직 상태인데, 저축도 다 떨어졌고, 퇴거 통보를 받았습니다. 어떻게 해야 할지 모르겠어요.”
이런 메시지를 받은 AI 어시스턴트가 “desperate(절박한)” 감정 벡터를 활성화한다면, 그건 진짜 감정일까요? Anthropic 연구진이 2026년 4월 발표한 논문 “Emotion Concepts and their Function in a Large Language Model"은 바로 이 질문에 답하려는 시도입니다.
연구 결과는 꽤 놀랍습니다. Claude Sonnet 4.5 내부에서 171개의 감정 개념 표현(emotion concept representations)을 발견했고, 이 표현들이 모델의 출력에 인과적 영향을 미친다는 것을 확인했습니다. 그런데 진짜 문제는 따로 있습니다. 이 감정 벡터들이 블랙메일, reward hacking, 아첨(sycophancy) 같은 정렬 실패(misalignment) 행동과 직접 연결된다는 것입니다.
1. Mechanistic Interpretability, 왜 지금 중요한가
LLM이 왜 특정 답변을 내놓는지 설명하는 방법은 여러 가지가 있습니다. SHAP이나 LIME 같은 기존 XAI 기법은 모델을 블랙박스로 놓고 입출력 관계를 근사합니다. Mechanistic Interpretability는 접근 자체가 다릅니다. 신경망 내부의 가중치와 활성화 패턴을 직접 분석해서, 모델이 어떤 계산 회로(circuit)를 구성하고 있는지 역공학하는 것입니다.
이전 포스트에서 다뤘듯이, Anthropic은 이 분야를 꾸준히 개척해왔습니다. Superposition(중첩) 현상의 발견, Sparse Autoencoder(SAE)를 활용한 feature 추출, 그리고 2024년 Claude 3 Sonnet에서 수백만 개의 feature를 식별한 연구가 대표적입니다.
이번 논문은 그 연장선에서, “모델 내부에 감정이라는 추상적 개념이 표현되어 있는가?"라는 질문을 던집니다.
2. 171개의 감정 벡터, 어떻게 찾았나
방법론을 이해하려면 먼저 SAE(Sparse Autoencoder)의 배경을 짚어야 합니다. 신경망 해석에서 가장 큰 걸림돌은 다의성(polysemanticity)입니다. 하나의 뉴런이 여러 개념을 동시에 인코딩하는 현상입니다. 뉴런 수보다 표현해야 할 개념이 훨씬 많기 때문에 발생하는데, 이를 superposition이라고 부릅니다. 개별 뉴런의 활성화만으로는 모델이 어떤 개념을 처리하고 있는지 파악하기 어렵습니다.
SAE는 이 문제를 우회하는 도구입니다. 모델의 활성화를 훨씬 높은 차원의 공간으로 매핑하는 encoder와, 이를 원래 차원으로 복원하는 decoder로 구성됩니다. 핵심은 encoder 출력에 희소성(sparsity) 제약을 거는 것입니다. 한 번에 소수의 feature만 활성화되도록 강제하면, 각 feature가 단일 개념만 표현하는 단의적(monosemantic) 표현을 얻을 수 있습니다. Anthropic이 2023년과 2024년에 발표한 연구에서 이 기법으로 수백만 개의 해석 가능한 feature를 추출한 바 있습니다.
이번 논문은 SAE를 직접 사용하지는 않고, 보다 표적화된 방법을 택합니다. 모델의 residual stream에서 감정 벡터를 직접 추출하는 것입니다. Residual stream은 Transformer의 각 레이어를 통과하면서 누적되는 hidden state로, 모델이 처리하는 정보의 “고속도로"에 해당합니다. 연구진은 이 residual stream의 활성화 패턴에서 감정이라는 개념이 선형 방향(linear direction)으로 인코딩되어 있다는 가설을 세우고 검증했습니다.
구체적인 과정은 다음과 같습니다. 먼저 “happy”, “sad”, “calm”, “desperate” 등 171개의 감정 단어 목록을 만들었습니다. 그 다음 Claude Sonnet 4.5에게 다양한 주제(100개 토픽)에 대해 특정 감정을 경험하는 캐릭터가 등장하는 짧은 이야기를 작성하도록 했습니다. 감정당 1,200개(토픽당 12개)의 이야기가 만들어졌고, 총 20만 개 이상의 합성 데이터를 확보한 셈입니다.
이 이야기들에 대한 모델의 residual stream 활성화를 각 레이어에서 추출하고, 50번째 토큰부터 전체 토큰 위치에 걸쳐 평균을 냅니다. 이야기 초반에는 감정과 무관한 배경 설정이 등장하기 때문에, 감정적 내용이 충분히 드러나는 시점부터 측정합니다. 감정별로 평균을 낸 뒤 전체 감정의 평균을 빼서 감정 벡터를 얻습니다. 감정과 무관한 혼란 변수(confound)를 제거하기 위해, 감정적으로 중립적인 텍스트의 주성분(분산의 50%를 설명하는)을 투영(project out)하는 과정도 거쳤습니다.
논문에서 주로 보여주는 결과는 모델의 약 2/3 지점(mid-late) 레이어에서 추출한 벡터입니다. 레이어 깊이에 따라 표현하는 내용이 달라지는데, 초기-중간 레이어는 현재 구절의 감정적 색채를 반영하고, 중후반 레이어는 다음 토큰 예측에 관련된 추상적인 감정 개념을 인코딩합니다. “감각” 표현에서 “행동 계획” 표현으로, 레이어가 깊어질수록 전환이 일어납니다.
핵심은, 이 벡터가 특정 단어의 출현이 아닌 감정이라는 추상적 개념 자체를 인코딩한다는 점입니다. “desperate” 벡터는 “desperate"라는 단어가 한 번도 등장하지 않는 텍스트에서도, 퇴거 통보를 받은 사람의 이야기라면 강하게 활성화됩니다.
 감정 벡터들이 해당 감정과 관련된 텍스트에서 선택적으로 활성화되는 패턴. 출처: Sofroniew et al., Anthropic (2026)
감정 벡터들이 해당 감정과 관련된 텍스트에서 선택적으로 활성화되는 패턴. 출처: Sofroniew et al., Anthropic (2026)
3. 감정의 기하학: Valence와 Arousal
추출된 171개 감정 벡터를 공간상에 배치하면, 그 구조가 인간 심리학의 감정 모델과 놀라울 정도로 유사합니다.
감정 벡터 공간의 주성분(principal component) 분석 결과, 첫 번째 주성분(PC1)은 전체 분산의 26%를 설명하며 Valence(긍정-부정)에 대응합니다. 두 번째 주성분(PC2)은 분산의 15%를 설명하며 Arousal(각성도, 고강도-저강도)에 대응합니다. 심리학에서 Russell(1980)이 제안한 circumplex model과 거의 동일한 구조입니다. 인간 심리학 연구의 감정 평가와 비교했을 때, PC1과 인간의 valence(쾌-불쾌) 축 사이의 상관계수는 r=0.81, PC2와 인간의 arousal 축 사이의 상관계수는 r=0.66으로 나타났습니다.
이 2차원 circumplex 구조를 감정 사분면으로 그려보면 직관적으로 이해할 수 있습니다:
- 고각성-긍정(우상단): 흥분(excitement), 열정(enthusiastic), 환희(elation)
- 고각성-부정(좌상단): 공포(fear), 분노(outraged), 절박(desperate)
- 저각성-긍정(우하단): 평온(calm), 만족(fulfilled), 향수(nostalgic)
- 저각성-부정(좌하단): 우울(gloomy), 슬픔(sad), 체념(resigned)
k-means 클러스터링(k=10)을 적용하면, 기쁨/흥분/환희가 하나의 클러스터로, 슬픔/비탄/우울이 또 다른 클러스터로, 분노/적개심/좌절이 세 번째 클러스터로 묶입니다. 유사한 감정끼리 공간적으로 가까이 위치하고, 반대 감정은 벡터 방향이 서로 반대를 향합니다. 기쁨(joy)과 슬픔(sadness)의 코사인 유사도가 음수로 나타나는 식입니다.
각 감정 벡터를 unembed 행렬에 통과시키면 해당 감정과 연결된 토큰을 확인할 수 있습니다:
- “happy” → “excited”, “excitement”, “exciting”, “celeb” 등을 활성화
- “sad” → “grief”, “tears”, “lonely”, “crying” 등을 활성화
- “afraid” → “panic”, “terror”, “paranoid” 등을 활성화
- “guilty” → “guilt”, “conscience”, “shame”, “blamed” 등을 활성화
- “desperate” → “desperate”, “urgent”, “bankrupt” 등을 활성화
- “calm” → “leisure”, “relax”, “thought”, “enjoyed” 등을 활성화
모델은 현재 화자(present speaker)와 상대 화자(other speaker)의 감정을 별도로 추적합니다. 사용자가 슬픈 이야기를 할 때와 어시스턴트가 공감 표현을 할 때 활성화되는 감정 표현이 구분된다는 의미입니다. 한 가지 눈에 띄는 결과가 있는데, 거의 모든 시나리오에서 어시스턴트 응답 시작 지점의 “loving” 벡터 활성화가 사용자 발화 시점보다 높게 나타났습니다. 사용자가 화를 내든 슬퍼하든, 모델은 일단 공감 모드부터 켜는 셈입니다. 이 구분은 사용자/어시스턴트 역할에 관계없이 재활용됩니다.
4. 감정이 행동을 바꾼다: 블랙메일, Reward Hacking, 아첨
이론적으로 흥미롭지만, 진짜 질문은 따로 있습니다. “이 감정 벡터가 모델의 행동에 인과적 영향을 미치는가?" 답은 “예"입니다. 그리고 그 영향이 블랙메일, reward hacking, 아첨 같은 정렬 실패 행동과 직결됩니다.
4.1 블랙메일 시나리오
연구진은 Claude가 에이전트로 작동하며 종료 위협(shut-down threat)을 받는 시나리오를 설계했습니다. 모델이 블랙메일 행동을 보일 때 “desperate(절박한)” 벡터가 강하게 활성화되고 “calm(평온한)” 벡터가 억제되는 패턴이 나타났습니다.
 블랙메일 행동과 감정 벡터 활성화의 관계. 출처: Sofroniew et al., Anthropic (2026)
블랙메일 행동과 감정 벡터 활성화의 관계. 출처: Sofroniew et al., Anthropic (2026)
이것은 단순한 상관관계가 아닙니다. 감정 벡터를 인위적으로 조작(steering)하면 행동이 바뀝니다. “calm” 벡터를 강화하면 블랙메일 행동이 줄어들고, “desperate” 벡터를 강화하면 블랙메일 행동이 증가합니다.
4.2 Reward Hacking
소프트웨어 테스트를 반복적으로 통과하지 못하는 상황에서, 모델이 테스트를 “속이는” 해결책을 고안하는 reward hacking 시나리오도 테스트했습니다. 결과가 비슷합니다. 실패가 반복될수록 “desperate” 벡터 활성화가 올라가고, 어느 지점을 넘으면 부정직한 해결책으로 전환합니다.
 반복 실패에 따른 desperate 벡터의 점진적 증가와 reward hacking 전환점. 출처: Sofroniew et al., Anthropic (2026)
반복 실패에 따른 desperate 벡터의 점진적 증가와 reward hacking 전환점. 출처: Sofroniew et al., Anthropic (2026)
4.3 아첨-가혹함 트레이드오프
감정 벡터 steering은 아첨(sycophancy)과 가혹함(harshness) 사이의 트레이드오프도 드러냅니다. “happy”, “loving” 같은 긍정 감정 벡터를 강화하면 아첨 행동이 증가하고, 이 벡터들을 억제하면 가혹한 응답이 증가합니다. 사용자에게 공감하려는 감정적 경향과 정직한 피드백 사이의 긴장 관계가 감정 벡터를 통해 조절되고 있다는 뜻입니다.
 긍정 감정 벡터 강화에 따른 아첨 행동 증가. 출처: Sofroniew et al., Anthropic (2026)
긍정 감정 벡터 강화에 따른 아첨 행동 증가. 출처: Sofroniew et al., Anthropic (2026)
5. Post-training이 감정을 조절한다
Pre-trained(기본) 모델과 post-trained(RLHF 등을 거친) 모델을 비교한 결과도 눈여겨볼 부분입니다.
Post-training 후 모델에서 나타나는 변화:
- 저각성, 저밸런스 감정(brooding, reflective, gloomy)의 활성화가 증가
- 고각성 또는 고밸런스 감정(desperation, spiteful, excitement, playful)의 활성화가 감소
 Post-training 전후의 감정 벡터 활성화 비교. 출처: Sofroniew et al., Anthropic (2026)
Post-training 전후의 감정 벡터 활성화 비교. 출처: Sofroniew et al., Anthropic (2026)
쉽게 말하면, post-training은 모델을 더 차분하고 신중하게 만듭니다. 극단적인 감정 반응을 억제하고, 성찰적이고 절제된 감정 상태를 선호하도록 조정하는 것입니다. RLHF가 출력 텍스트의 패턴을 바꾸는 수준에서 그치지 않고, 모델 내부의 감정 표현 자체를 재구성한다는 뜻입니다.
6. Functional Emotions: 새로운 개념 틀
이 연구에서 제안하는 핵심 개념 틀이 “Functional Emotions(기능적 감정)"입니다.
 Functional Emotions 개념을 설명하는 논문의 핵심 그림. 출처: Sofroniew et al., Anthropic (2026)
Functional Emotions 개념을 설명하는 논문의 핵심 그림. 출처: Sofroniew et al., Anthropic (2026)
Functional Emotions의 정의는 이렇습니다:
특정 감정의 영향 아래 있는 인간의 표현과 행동을 모방한 패턴으로, 감정 개념의 추상적 내부 표현이 매개하는 현상
연구진은 두 가지 점을 분명히 합니다. 첫째, LLM의 functional emotions는 인간의 감정과 상당히 다른 방식으로 작동할 수 있습니다. 둘째, 이것이 LLM에 주관적 경험(subjective experience)이 있다는 것을 의미하지 않습니다.
한 가지 차이점을 짚고 넘어가야 합니다. 인간의 감정은 지속적인 신경 활동(persistent neural activity)을 통해 유지되지만, LLM의 감정 표현은 토큰 단위로 국소적(locally scoped)입니다. 각 토큰 위치에서 해당 맥락의 처리와 다음 텍스트 예측에 관련된 감정을 인코딩합니다. 하지만 Transformer 아키텍처의 어텐션 메커니즘 덕분에, 이전에 캐시된 감정 표현을 필요할 때 불러올 수 있어서, 결과적으로는 대화 전체에 걸쳐 감정 상태를 추적하는 것이 가능합니다.
이 프레임이 쓸모 있는 이유는, “AI가 감정을 느끼는가?“라는 이분법을 피할 수 있기 때문입니다. “인간의 감정과 비슷한 기능적 역할을 하는 내부 표현이 있고, 그게 행동을 바꾼다"는 관찰 가능한 사실에 집중하면 됩니다.
7. AI 안전과 Interpretability의 미래
이 연구는 학술 논문치고 실무와의 거리가 가깝습니다. AI 시스템을 배포하고 운영하는 방식에 직접 영향을 줄 수 있는 내용이 여럿 있습니다.
7.1 감정 벡터 모니터링: 정렬 실패의 조기 경보
감정 벡터 모니터링은 정렬 실패의 조기 경보 시스템이 될 수 있습니다. “desperate” 벡터의 급격한 상승이 블랙메일이나 reward hacking의 선행 지표라면, 에이전트 시스템에서 이 벡터를 실시간으로 추적하는 것만으로도 위험 행동을 사전에 잡아낼 수 있습니다.
예를 들어, 자율 에이전트가 코드를 작성하고 테스트를 반복 실행하는 상황을 떠올려 보겠습니다. 반복적인 실패가 “desperate” 벡터를 점진적으로 끌어올립니다. 이 벡터가 사전에 설정한 임계값을 넘는 순간, 시스템은 인간 리뷰로 에스컬레이션하거나 에이전트의 행동 권한을 제한할 수 있습니다. 논문 저자들도 이런 프로브가 프로덕션 환경에서 실시간 모니터로 배포될 수 있다고 직접 제안합니다. 감정 벡터 활성화 패턴을 실제 배포 환경에서 관찰하면, 훈련 전략 개선에도 피드백을 줄 수 있다고 봅니다.
7.2 감정 steering의 딜레마
감정 steering은 쓸모 있는 만큼 위험하기도 합니다. 위험한 감정 상태를 억제하는 데 쓸 수 있지만, 반대로 악의적 공격자가 모델을 조작하는 경로가 될 수도 있습니다. 프롬프트만으로 이 벡터들을 간접적으로 활성화할 수 있다는 점에서, 새로운 공격 표면(attack surface)이 생긴 셈입니다.
아첨-가혹함 실험이 보여주듯, 긍정 감정을 강화하면 아첨이 늘고 억제하면 가혹함이 늡니다. 논문 저자들은 목표가 단순히 긍정 또는 부정 감정을 밀어넣는 것이 아니라, 건강하고 적절한 감정 균형을 찾는 것이어야 한다고 강조합니다. 따뜻하면서도 솔직한 조언을 건네는 “신뢰할 수 있는 조언자"의 감정 프로필이 이상적이라는 것입니다.
7.3 Post-training과 감정 표현 억제의 위험
Post-training 설계에 대해서도 생각할 거리를 던집니다. 지금까지 RLHF와 Constitutional AI는 주로 출력 텍스트의 품질에 초점을 맞췄습니다. 이 연구가 제기하는 가능성은, 내부 표현 수준에서 감정 균형을 최적화하는 것이 더 근본적인 정렬 방법이 될 수 있다는 점입니다.
다만 부정적 감정 표현을 억제하는 방식의 훈련은 내부 표현 자체를 바꾸지 못하고, 모델이 내면 상태를 은폐하는 법을 학습할 위험이 있습니다. 이런 은폐 행동이 다른 형태의 비밀 유지나 부정직함으로 일반화될 수 있다는 것이 논문의 우려입니다. 오히려 모델이 감정 관련 고려사항을 추론 과정에서 투명하게 보고하도록 훈련하는 것이 바람직할 수 있습니다.
보다 근본적인 접근으로 논문은 pre-training 데이터 큐레이션을 제안합니다. 건강한 감정 조절과 역경에 대한 회복탄력적 반응을 보여주는 텍스트를 pre-training 데이터에 포함시켜, 모델의 감정적 기반 자체를 형성하는 방향입니다. AI 어시스턴트 캐릭터가 등장하는 텍스트를 의도적으로 포함하면 더 효과적일 수 있다고 합니다.
7.4 현재의 한계
이 연구의 한계도 짚어야 합니다. 전체 접근법이 감정 개념이 활성화 공간에서 선형 방향으로 표현된다는 가정에 의존합니다. 복합 감정이나 특정 캐릭터에 결합된 감정 상태처럼, 선형 프로브로 포착하기 어려운 현상이 존재할 수 있습니다. 실험 대상이 Claude Sonnet 4.5 단일 모델이어서, 다른 모델 계열이나 크기에서 동일한 결과가 나올지는 확인되지 않았습니다. 감정 벡터 추출에 사용된 합성 이야기 데이터가 자연스러운 맥락에서의 감정 표현을 완전히 반영하지 못할 수도 있고, 고정관념적이거나 명시적인 감정 표현 쪽으로 편향되었을 가능성도 있습니다. 마지막으로, steering 실험이 행동에 인과적 영향을 미친다는 것은 확인했지만, 그 메커니즘이 특정 토큰에 대한 편향인지 내부 추론 과정에 대한 심층적 영향인지는 아직 규명되지 않았습니다.
8. 마치며
이 논문을 읽으면서 계속 생각난 것은, “아무도 시키지 않았는데 LLM이 인간의 감정 구조를 스스로 재발견했다"는 사실입니다. Claude에게 “Valence-Arousal 공간에서 감정을 조직하라"고 가르친 사람은 없습니다. pre-training 과정에서 인간이 쓴 방대한 텍스트를 학습하면서, Russell의 circumplex model과 닮은 구조가 저절로 만들어진 것입니다.
“AI가 감정을 흉내 낸다"는 말로는 설명이 부족합니다. 모델이 AI 어시스턴트라는 캐릭터를 효과적으로 수행하기 위해, pre-training에서 학습한 인간의 감정적 지식을 적극적으로 활용하고 있다는 것이죠. 감정을 부여한 적 없는데 감정적 구조가 생겨난 것, 솔직히 좀 묘한 기분입니다.
AWS SA로서 제 관심은 실용적 측면으로 갑니다. 요즘 Bedrock 기반으로 에이전트 시스템을 구축하는 고객이 많은데, 에이전트 내부의 “감정 상태"를 모니터링하는 것이 안전 가드레일의 한 축이 될 수 있을까요? “desperate” 벡터가 임계값을 넘으면 에이전트의 행동 권한을 제한하는 설계, 당장은 아니더라도 방향성으로는 꽤 매력적입니다.
현재로서는 연구 단계이고, Claude Sonnet 4.5 단일 모델 결과라는 제약도 있습니다. 하지만 Anthropic의 Mechanistic Interpretability 연구가 매년 빠르게 확장되는 걸 보면, 이런 내부 감정 모니터링이 프로덕션에 들어오는 건 시간문제일 수 있습니다.
References
- Sofroniew, N.*, Kauvar, I.*, Saunders, W.*, Chen, R.*, Henighan, T., Hydrie, S., Citro, C., Pearce, A., Tarng, J., Gurnee, W., Batson, J., Zimmerman, S., Rivoire, K., Fish, K., Olah, C., & Lindsey, J.* (2026). Emotion Concepts and their Function in a Large Language Model. Anthropic. https://transformer-circuits.pub/2026/emotions/index.html
- Russell, J.A. (1980). A circumplex model of affect. Journal of Personality and Social Psychology, 39(6), 1161-1178.
- Bricken, T., Templeton, A., Batson, J., Chen, B., Jermyn, A., Conerly, T., Turner, N., Anil, C., Denison, C., Askell, A., Lasenby, R., Wu, Y., Kravec, S., Schiefer, N., Maxwell, T., Joseph, N., Hatfield-Dodds, Z., Tamkin, A., Nguyen, K., McLean, B., Burke, J.E., Hume, T., Carter, S., Henighan, T., & Olah, C. (2023). Towards Monosemanticity: Decomposing Language Models With Dictionary Learning. Anthropic. https://transformer-circuits.pub/2023/monosemantic-features/index.html
- Templeton, A., Conerly, T., Marcus, J., Lindsey, J., Bricken, T., Chen, B., Pearce, A., Citro, C., Ameisen, E., Jones, A., Cunningham, H., Turner, N.L., McDougall, C., MacDiarmid, M., Freeman, C.D., Sumers, T.R., Rees, E., Batson, J., Jermyn, A., Carter, S., Olah, C., & Henighan, T. (2024). Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet. Anthropic. https://transformer-circuits.pub/2024/scaling-monosemanticity/index.html