
“지난달 서울 지역 매출 상위 10개 제품 보여줘.”
이 한 문장을 SQL로 바꾸는 일, 예전에는 데이터 분석가에게 요청하고 하루를 기다려야 했습니다. 지금은 LLM이 몇 초 만에 해냅니다. Text2SQL(또는 NL2SQL)은 자연어 질문을 실행 가능한 SQL 쿼리로 변환하는 기술입니다. 규칙 기반 파서 시절부터 존재하던 오래된 문제지만, LLM 등장 이후 정확도가 급격히 올라가면서 실제 프로덕션에 투입되기 시작했습니다.
기업 입장에서 Text2SQL은 데이터 민주화의 핵심입니다. SQL을 모르는 마케터, 기획자, 경영진도 자연어로 데이터에 접근할 수 있게 되면, 데이터 팀의 병목이 사라집니다. 2025–2026년 사이에 쏟아진 연구 결과를 바탕으로, 현재 가장 효과적인 접근법들을 정리합니다.
1. Text2SQL 파이프라인 기본 구조
Text2SQL 시스템은 크게 네 단계로 구성됩니다.
NL Input → Schema Linking → SQL Generation → Validation/Execution
각 단계를 살펴봅니다.
1단계: 자연어 입력 전처리. 사용자 질문에서 핵심 의도를 파악합니다. “지난달"이 2026년 3월을 의미하는지, “매출"이 revenue 컬럼인지 sales_amount 컬럼인지 판단해야 합니다.
2단계: Schema Linking. 전체 데이터베이스 스키마에서 질문과 관련된 테이블과 컬럼을 찾아냅니다. 이 단계가 Text2SQL의 성패를 가르는 핵심입니다. 엔터프라이즈 DB는 수백 개의 테이블과 수천 개의 컬럼을 가질 수 있는데, LLM의 context window에 이 전부를 넣을 수는 없습니다.
여기서 Schema RAG 패턴이 필요합니다. Few-shot 예제처럼 스키마 메타데이터도 벡터 스토어에 미리 저장해두고, 질문이 들어올 때 관련 테이블/컬럼 정보만 꺼내 쓰는 방식입니다.
벡터 스토어에 저장할 스키마 메타데이터 예시:
[테이블: orders]
- 설명: 고객 주문 이력 테이블
- order_id (INT, PK): 주문 고유 번호
- revenue (DECIMAL): 매출액, 원화, 환불 제외한 실결제 금액
- status (VARCHAR): 주문 상태 — "paid", "cancelled", "pending"
- region (VARCHAR): 배송 지역 — "서울", "부산", "대구" 등
[비즈니스 용어 사전]
- "매출" → orders.revenue
- "고객" → customers.customer_id
- "최근" → 기본값 30일 (명시 없을 시)
이 메타데이터를 임베딩해두면, “서울 매출"이라는 질문이 들어왔을 때 orders 테이블과 region, revenue 컬럼이 자동으로 선택됩니다. 컬럼명이 직관적이지 않거나(amt, cd 같은 축약형), 비즈니스 용어와 DB 컬럼명이 다를 때 특히 효과가 큽니다. MCI-SQL 논문이 강조하는 “Metadata-Complete Context"의 핵심도 바로 이 부분입니다.
3단계: SQL 생성. 선택된 스키마 정보와 질문을 LLM에 넣어 SQL을 생성합니다.
4단계: 검증과 실행. 생성된 SQL의 문법 오류를 검사하고, 실행 결과가 합리적인지 확인합니다.
Python 의사코드로 보면 이렇습니다.
def text_to_sql(question: str, db_schema: dict) -> str:
# 1. Schema Linking - 관련 테이블/컬럼 필터링
relevant_schema = filter_schema(question, db_schema)
# 2. 프롬프트 구성
prompt = build_prompt(
question=question,
schema=relevant_schema,
few_shots=select_similar_examples(question)
)
# 3. LLM으로 SQL 생성
sql = llm.generate(prompt)
# 4. 검증 루프
for attempt in range(max_retries):
is_valid, error = validate_and_execute(sql, db_connection)
if is_valid:
return sql
sql = llm.generate(refine_prompt(prompt, sql, error))
return sql
Schema Linking의 중요성은 아무리 강조해도 지나치지 않습니다. MCI-SQL 논문에 따르면, 컬럼 필터링 단계에서 메타데이터(컬럼 설명, 샘플 값, 외래키 관계)를 완전하게 제공했을 때 BIRD 벤치마크에서 실행 정확도가 크게 향상됩니다.
2. 핵심 기법 5가지
현재 Text2SQL 분야에서 주로 사용되는 기법을 다섯 가지로 분류할 수 있습니다.
기법 1: Prompt Engineering + Schema Injection
가장 단순하면서도 프로덕션에서 가장 널리 쓰이는 방법입니다. LLM에게 DB 스키마 정보를 프롬프트에 직접 주입하고, SQL을 생성하도록 지시합니다.
핵심은 스키마 정보를 얼마나 잘 구성하느냐입니다. 단순히 CREATE TABLE DDL을 넣는 것보다, 컬럼별 설명과 샘플 값을 함께 제공하면 정확도가 올라갑니다.
schema_prompt = """
Table: orders (주문 테이블)
- order_id (INT, PK): 주문 고유 번호
- product_name (VARCHAR): 제품명, 예: '갤럭시 S26', 'MacBook Pro'
- region (VARCHAR): 지역, 예: '서울', '부산', '대구'
- revenue (DECIMAL): 매출액 (원화)
- order_date (DATE): 주문일
"""
장점: 구현이 간단하고, 모델 교체가 쉽습니다. Claude나 GPT 계열 모델만 있으면 바로 시작할 수 있습니다.
단점: 스키마가 큰 DB에서는 context window 제한에 걸립니다. 복잡한 다중 테이블 JOIN이 필요한 쿼리에서 정확도가 떨어집니다.
기법 2: Few-shot / Demonstration Selection (DAIL-SQL 방식)
프롬프트에 유사한 질문-SQL 쌍을 예시로 넣어주는 방법입니다. 단순 few-shot과 다른 점은, 예시를 고정하지 않고 입력 질문과 유사한 예시를 동적으로 선택한다는 것입니다.
DAIL-SQL은 질문의 유사도와 SQL 구조의 유사도를 함께 고려해 예시를 선택합니다. “지역별 매출 합계를 구해줘"라는 질문이 들어오면, 과거에 GROUP BY region 패턴을 사용한 예시가 자동으로 선택됩니다.
장점: 모델이 SQL 패턴을 in-context에서 학습하므로, fine-tuning 없이도 정확도가 크게 향상됩니다.
단점: 좋은 예시 풀(demonstration pool)을 미리 구축해야 합니다. 예시 선택 알고리즘의 품질이 전체 성능을 좌우합니다.
기법 3: Chain-of-Thought Decomposition
복잡한 질문을 한 번에 SQL로 변환하지 않고, 중간 추론 단계를 거칩니다. “지난달 서울 매출 상위 10개 제품인데, 전월 대비 성장률도 보여줘"라는 질문은 사실 두 개의 하위 쿼리를 JOIN해야 합니다.
Struct-SQL은 여기서 한 걸음 더 나아가, 비정형 CoT 대신 SQL 실행 계획(Query Execution Plan)을 구조화된 추론 표현으로 사용합니다. 자유 형식의 “먼저 이 테이블에서… 그 다음…“이라는 추론 대신, 구조화된 실행 계획을 중간 표현으로 삼습니다.
장점: 다중 테이블 JOIN, 서브쿼리, 집계 함수가 포함된 복잡한 쿼리에서 정확도가 높습니다.
단점: 추론 단계가 추가되므로 latency가 증가합니다. 단순한 쿼리에는 오히려 과잉입니다.
기법 4: Self-Correction / Iterative Refinement
생성된 SQL을 실행하고, 에러가 발생하면 그 피드백을 LLM에 다시 넣어 수정하는 방식입니다. 사람이 SQL을 작성할 때도 첫 시도에서 완벽한 쿼리를 쓰는 경우는 드뭅니다.
MCI-SQL은 Intermediate Correction이라는 전략을 사용합니다. 최종 SQL이 아니라, SQL 생성 중간 단계(schema linking 결과, 부분 SQL)에서 검증과 수정을 수행합니다. 최종 결과물만 검증하는 것보다 중간 단계에서 잘못된 방향을 잡아내는 것이 훨씬 효율적입니다.
장점: 실행 에러를 자동으로 복구하므로, 실제 프로덕션 환경에서 안정성이 높습니다.
단점: DB 실행이 필요하므로 latency와 비용이 추가됩니다. 무한 루프 방지를 위한 제한이 필요합니다.
기법 5: Fine-tuning + Reinforcement Learning
범용 LLM 대신 Text2SQL 전용 모델을 학습시키는 접근법입니다. 가장 높은 정확도를 달성할 수 있지만, 학습 데이터와 인프라가 필요합니다.
두 가지 주목할 연구가 있습니다.
OmniSQL은 대규모 합성 데이터를 자동 생성하여 7B, 14B, 32B 크기의 전용 모델을 학습시켰습니다. 합성 데이터의 품질과 다양성을 체계적으로 관리한 것이 특징입니다.
Arctic-Text2SQL-R1은 강화학습(RL) 기반 후속 학습(post-training)을 적용했습니다. SQL 실행 결과의 정확성을 보상 신호로 사용하는 단순한 reward 설계로도 강한 추론 능력을 이끌어냈습니다.
장점: 벤치마크 최고 성능. 작은 모델(7B–14B)로도 Claude, GPT 수준의 Text2SQL 정확도 달성이 가능합니다.
단점: 학습 파이프라인 구축, GPU 비용, 데이터셋 관리가 필요합니다. 스키마 변경 시 재학습 또는 적응이 필요할 수 있습니다.
3. 주요 벤치마크와 최고 성능 모델 현황
Text2SQL 분야에는 세 가지 주요 벤치마크가 있습니다.
Spider는 2018년에 등장한 크로스-도메인 벤치마크입니다. 200개 이상의 DB, 약 10,000개의 질문-SQL 쌍으로 구성되어 있습니다. 현재 상위 모델들의 실행 정확도(Execution Accuracy)가 90%를 넘겨서, 더 이상 모델 간 변별력이 크지 않습니다.
BIRD는 Spider의 한계를 보완하기 위해 등장했습니다. 실제 업무에 가까운 대규모 DB와 외부 지식(Knowledge Evidence)을 포함합니다. 값이 모호하거나 도메인 지식이 필요한 질문이 많아, Spider보다 난이도가 높습니다.
Spider 2.0은 엔터프라이즈 수준의 난이도를 제시합니다. 632개의 실전 워크플로우 문제로 구성되어 있으며, BigQuery, Snowflake 같은 클라우드 데이터 웨어하우스 환경에서의 SQL 생성을 포함합니다.
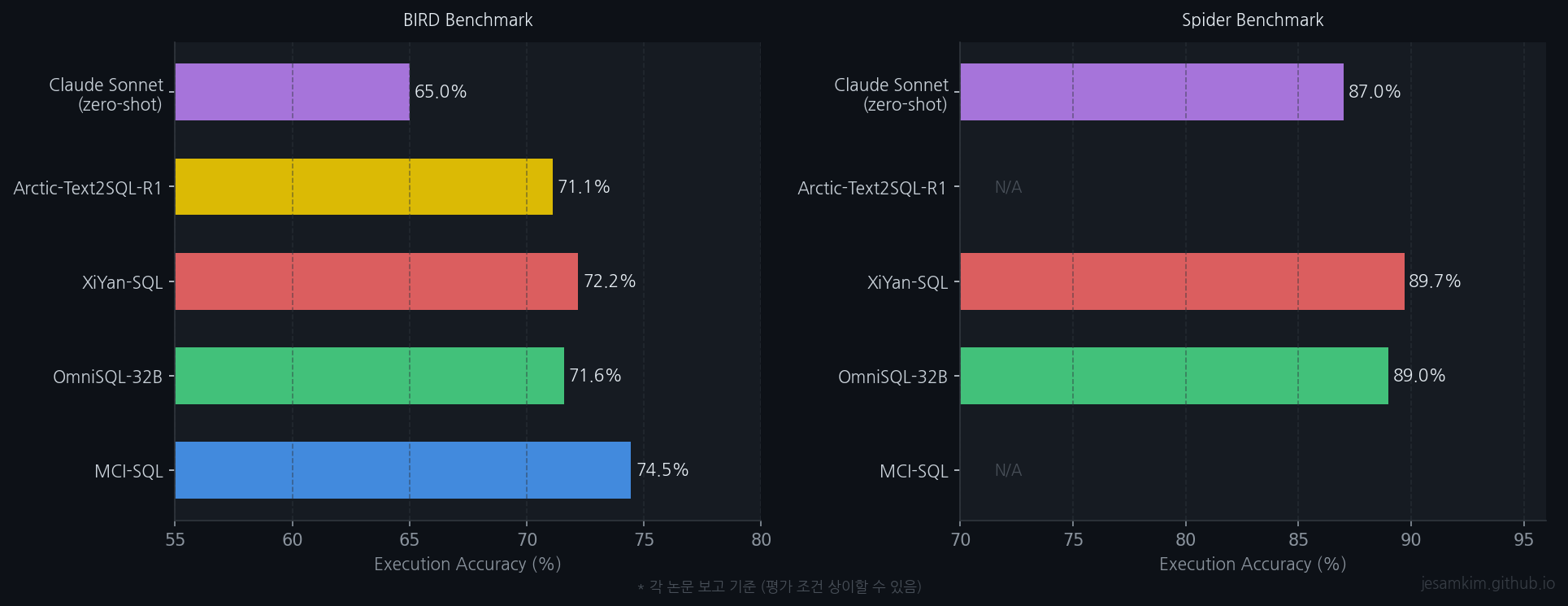 BIRD/Spider 벤치마크 성능 비교. 각 논문 보고 기준.
BIRD/Spider 벤치마크 성능 비교. 각 논문 보고 기준.
현재 최고 성능 모델 비교
| 모델 | BIRD (dev EX) | Spider (dev EX) | 접근 방식 |
|---|---|---|---|
| MCI-SQL | 74.45% | - | Metadata-Complete + Intermediate Correction |
| OmniSQL-32B | 71.6% | 89.0% | 합성 데이터 fine-tuning |
| XiYan-SQL | 72.2% | 89.7% | Multi-generator + candidate selection |
| Arctic-Text2SQL-R1 | 71.1% | - | RL post-training |
| Claude 3.5 Sonnet (zero-shot) | ~65% | ~87% | 범용 LLM |
EX = Execution Accuracy. 각 논문 보고 기준이며, 평가 조건(few-shot 수, 사용 도구 등)이 상이할 수 있습니다.
여기서 짚어야 할 점이 있습니다. Spider에서 90%에 가까운 정확도를 보이는 모델도, 실제 업무 환경에서는 성능이 크게 떨어집니다. Spider 2.0에서는 최고 성능 모델도 30% 미만의 정확도를 기록합니다. 벤치마크와 현실의 간극이 여전히 크다는 뜻입니다.
원인은 분명합니다. 벤치마크 DB는 스키마가 작고 깔끔합니다. 실제 DB는 수백 개의 테이블, 일관성 없는 네이밍, 문서화되지 않은 비즈니스 로직, 그리고 동의어 문제(“매출"이 revenue인지 amount인지 sales인지)가 난무합니다.
4. 실전 적용 패턴
비용, 보안, 정확도 트릴레마
엔터프라이즈에서 Text2SQL을 도입할 때, 세 가지를 동시에 만족시키기 어렵습니다.
정확도를 최대화하려면 가장 큰 모델(GPT-5.4, Claude Opus 4.6 등)을 사용해야 합니다. 하지만 토큰당 비용이 높고, 외부 API 호출은 보안 정책에 걸릴 수 있습니다.
보안을 지키려면 사내 인프라에서 모델을 돌려야 합니다. 7B–14B 급 모델을 자체 호스팅하면 보안 문제는 해결되지만, 범용 LLM 대비 정확도가 떨어질 수 있습니다.
비용을 절감하려면 작은 모델을 써야 합니다. Struct-SQL이 제안한 Knowledge Distillation 접근이 여기서 빛납니다. 큰 모델(teacher)이 생성한 구조화된 CoT 추론 과정을 작은 모델(student)에게 학습시키면, 8B급 모델로도 상당한 정확도를 확보할 수 있습니다.
Schema가 복잡할 때: 메타데이터를 완전하게
MCI-SQL의 핵심 교훈은 Metadata-Complete Context입니다. 컬럼 이름만 던져주지 말고, 다음 정보를 함께 제공해야 합니다.
- 컬럼 설명: “region 컬럼은 매장 소재 광역시/도를 저장합니다”
- 샘플 값: “예: ‘서울특별시’, ‘부산광역시’, ‘경기도’”
- 외래키 관계: “orders.product_id → products.id”
- 값 분포: “NULL 비율 2.3%, 고유값 17개”
이 정보가 있고 없고의 차이는 컬럼 필터링 정확도에서 극명하게 나타납니다.
AWS에서 구현하기: Strands Agents + AgentCore 패턴
단순히 “Claude에게 SQL 물어보기"를 넘어, 앞서 소개한 기법들을 에이전트 구조로 조합하면 훨씬 강력한 Text2SQL 시스템을 만들 수 있습니다.
기본 구조: Strands Agents + Tool Use
AWS의 오픈소스 에이전트 프레임워크인 Strands Agents를 사용하면, Text2SQL의 각 단계를 도구(tool)로 분리하고 에이전트가 상황에 따라 순서를 결정하는 구조를 만들 수 있습니다.
from strands import Agent, tool
import boto3
@tool
def search_schema(question: str) -> str:
# Schema RAG - 질문과 관련된 테이블/컬럼 메타데이터 검색
# Bedrock Knowledge Base에 테이블 설명, 컬럼 설명, 샘플값, 비즈니스 용어 사전 저장
# "매출" -> orders.revenue, "고객" -> customers.customer_id 같은 매핑 자동 처리
return vector_search_schema(question, top_k=5)
@tool
def search_similar_queries(question: str) -> list:
# Few-shot Selection - 유사 질문-SQL 예제 검색
return vector_search_examples(question, top_k=3)
@tool
def execute_sql(query: str) -> dict:
# SQL 실행 + 에러 반환 - Validation & Execution 단계
try:
result = run_athena_query(query) # 또는 Aurora, Redshift
return {"success": True, "data": result}
except Exception as e:
return {"success": False, "error": str(e)} # Self-Correction 루프 트리거
agent = Agent(
model="global.anthropic.claude-sonnet-4-6",
tools=[get_schema, execute_sql, search_similar_queries],
system_prompt="You are a Text2SQL expert. Use tools to gather schema context, find similar examples, generate SQL, and self-correct on errors."
)
response = agent("지난 분기 서울 지역 매출 상위 10개 제품을 보여줘")
에이전트는 스스로 판단해서 search_similar_queries로 유사 예제를 가져오고(Few-shot), get_schema로 관련 테이블을 확인하고(Schema Linking), SQL을 생성한 뒤 execute_sql로 실행합니다. 에러가 나면 에러 메시지를 컨텍스트로 받아 SQL을 수정합니다(Self-Correction). 앞서 설명한 기법 3가지가 에이전트 루프 안에서 자동으로 작동하는 구조입니다.
프로덕션 배포: AgentCore Runtime
개발한 에이전트를 프로덕션에 올릴 때는 Amazon Bedrock AgentCore의 Runtime을 사용합니다. AgentCore Runtime은 에이전트 코드를 세션 단위 MicroVM에서 실행하는 서버리스 환경으로, LLM이 응답을 기다리는 동안은 CPU 비용이 발생하지 않습니다.
[사용자 질문]
|
AgentCore Runtime (에이전트 실행 환경)
|-- Strands Agent Loop
| |-- Tool: search_schema -> Bedrock Knowledge Base (Schema RAG)
| | | 테이블 설명, 컬럼 메타데이터, 비즈니스 용어 사전
| |-- Tool: search_similar_queries -> Bedrock Knowledge Base (Few-shot)
| | | 유사 질문-SQL 예제
| |-- Claude Sonnet 4.6 -> SQL 생성 + Self-Correction
| +-- Tool: execute_sql -> Athena / Aurora / Redshift
+-- AgentCore Memory -> 멀티턴 대화 컨텍스트 유지
|
[결과 + 자연어 요약]
AgentCore Gateway를 함께 쓰면 기존 사내 DB 연결이나 REST API를 MCP(Model Context Protocol) 기반 도구로 등록해서 에이전트에게 노출할 수 있습니다. 새로운 데이터 소스를 추가해도 에이전트 코드를 바꾸지 않아도 됩니다.
보안 설계 원칙: 스키마 메타데이터만 LLM 컨텍스트에 들어가고, 실제 데이터는 LLM을 거치지 않습니다. SQL 생성(LLM)과 SQL 실행(DB)의 경계를 명확히 분리하는 것이 엔터프라이즈 환경에서의 핵심입니다.
작은 모델을 쓸 때: Knowledge Distillation
Struct-SQL이 보여준 패턴을 따릅니다.
- Teacher 모델(Claude Opus 4.6, GPT-5.4)로 학습 데이터의 Structured CoT를 생성
- 쿼리 실행 계획 형태로 추론 과정을 구조화
- Student 모델(8B급)을 이 데이터로 fine-tuning
Struct-SQL 논문에 따르면, 구조화된 CoT로 증류한 모델이 비정형 CoT 증류 대비 8.1%p의 정확도 향상을 달성했습니다. 단순히 “생각의 과정"을 보여주는 것보다, 그 과정을 SQL 실행 계획처럼 형식화하는 것이 작은 모델의 학습에 훨씬 효과적이라는 의미입니다.
5. 마치며
Text2SQL은 더 이상 연구 단계의 기술이 아닙니다. BIRD 벤치마크에서 74%를 넘는 실행 정확도, 엔터프라이즈 DB 환경에서도 작동하는 파이프라인, 그리고 7B 급 모델로도 실용적인 성능을 내는 Knowledge Distillation 기법까지, 프로덕션 투입의 조건이 갖춰지고 있습니다.
물론 풀어야 할 과제가 남아 있습니다.
멀티턴 대화가 대표적입니다. “아까 그 쿼리에서 기간을 3개월로 바꿔줘"처럼 이전 맥락을 참조하는 질문은 단일 턴 Text2SQL과는 다른 문제입니다. BIRD-Interact는 이런 동적 인터랙션을 평가하는 벤치마크인데, GPT-5도 c-Interact 모드에서 8.67%의 완료율밖에 달성하지 못했습니다. 갈 길이 멉니다.
모호한 질의 처리도 과제입니다. “최근 매출이 좋은 제품"에서 “최근"이 1주일인지 1개월인지, “좋은"의 기준이 절대 금액인지 성장률인지, 시스템이 능동적으로 되물어야 합니다.
SQL 방언(dialect) 일반화 문제도 있습니다. PostgreSQL, MySQL, BigQuery, Redshift는 문법이 다릅니다. 하나의 모델이 모든 방언을 지원하려면 dialect-aware한 학습이 필요합니다.
Text2SQL의 다음 단계는 “SQL 생성기"에서 “데이터 대화 에이전트"로의 전환입니다. 질문을 이해하고, 부족한 정보를 되묻고, 쿼리를 실행하고, 결과를 해석해서 설명하는 전체 흐름을 하나의 에이전트가 처리하는 방향으로 나아가고 있습니다.
References
- Gao, D. et al. (2023). “Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation (DAIL-SQL).” arXiv:2308.15363
- Thaker, K. & Bresler, Y. (2025). “Knowledge Distillation with Structured Chain-of-Thought for Text-to-SQL (Struct-SQL).” arXiv:2512.17053
- Wang, Q. et al. (2026). “MCI-SQL: Text-to-SQL with Metadata-Complete Context and Intermediate Correction.” arXiv:2603.13390
- Li, H. et al. (2025). “OmniSQL: Synthesizing High-quality Text-to-SQL Data at Scale.” arXiv:2503.02240
- Yao, Z. et al. (2025). “Arctic-Text2SQL-R1: Simple Rewards, Strong Reasoning in Text-to-SQL.” arXiv:2505.20315
- Liu, Y. et al. (2025). “XiYan-SQL: A Novel Multi-Generator Framework For Text-to-SQL.” arXiv:2507.04701
- Lei, F. et al. (2024). “Spider 2.0: Evaluating Language Models on Real-World Enterprise Text-to-SQL Workflows.” arXiv:2411.07763
- Huo, N. et al. (2025). “BIRD-INTERACT: Re-imagining Text-to-SQL Evaluation via Dynamic Interactions.” arXiv:2510.05318