2017년 Google이 발표한 “Attention Is All You Need"와 2018년의 “BERT: Pre-training of Deep Bidirectional Transformers"는 자연어 처리(NLP)의 흐름을 완전히 바꿔놓은 논문입니다. 오늘날 Claude, GPT 계열, Gemini 같은 대규모 언어 모델(LLM)은 모두 이 두 논문의 아이디어 위에 세워져 있습니다.
이 글에서는 수식을 최소화하고, 두 논문의 핵심 아이디어를 직관적으로 풀어봅니다.
1. RNN/LSTM은 왜 한계에 부딪혔나
Transformer가 등장하기 전, 자연어 처리의 주류는 RNN(Recurrent Neural Network)과 그 변형인 LSTM(Long Short-Term Memory)이었습니다.
순차 처리의 병목
RNN 계열 모델은 문장을 왼쪽에서 오른쪽으로, 한 토큰씩 순서대로 처리합니다. “오늘 날씨가 정말 좋다"라는 문장이 있으면, “오늘"을 처리한 뒤 “날씨가"를 처리하고, 그 다음 “정말"을 처리하는 식입니다.
이 방식에는 문제가 있습니다.
첫째, 병렬 처리가 불가능합니다. 각 단계가 이전 단계의 결과에 의존하기 때문에, GPU가 아무리 많아도 순차적으로밖에 계산할 수 없습니다. 문장이 길어질수록 학습 시간이 비례해서 증가합니다.
둘째, 긴 문장에서 정보가 사라집니다. 문장의 앞부분 정보는 뒤쪽 토큰을 처리할 때까지 여러 단계를 거치면서 점점 희석됩니다. LSTM이 이 문제를 개선하긴 했지만, 수백 토큰 이상의 긴 문맥에서는 여전히 한계가 뚜렷했습니다.
번역의 어려움
기계 번역을 예로 들어봅니다. “The agreement on the European Economic Area was signed in August 1992"라는 문장을 한국어로 번역한다고 합시다. RNN 기반 모델은 이 영어 문장 전체를 하나의 고정 길이 벡터로 압축한 뒤, 그 벡터에서 한국어 문장을 생성합니다.
문제는 하나의 벡터에 문장 전체의 의미를 담는 것이 사실상 불가능하다는 점입니다. 문장이 길어질수록 번역 품질이 급격히 떨어졌고, 이것이 Attention 메커니즘이 등장한 배경입니다.
2. Attention Is All You Need (2017)
Vaswani et al.이 발표한 이 논문의 제목 자체가 핵심 주장입니다. RNN도, CNN도 필요 없다. Attention만으로 충분하다.
Self-Attention: 모든 토큰이 서로를 바라본다
Self-Attention의 핵심 아이디어는 직관적입니다. 문장 내 모든 토큰이 다른 모든 토큰과의 관련성을 동시에 계산합니다.
“고양이가 매트 위에 앉았다"라는 문장에서 “앉았다"를 처리할 때, RNN은 이전 단계들의 누적된 hidden state에 의존합니다. 반면 Self-Attention은 “앉았다"가 “고양이가”, “매트”, “위에” 등 문장 내 모든 단어를 직접 참조합니다.
이를 위해 각 토큰은 세 가지 벡터로 변환됩니다.
- Query(Q): “나는 어떤 정보가 필요한가?” (질문)
- Key(K): “나는 어떤 정보를 갖고 있는가?” (키워드)
- Value(V): “내가 제공할 실제 정보” (값)
 Self-Attention: 각 토큰의 Query가 모든 토큰의 Key와 비교되어 Attention Score를 생성하고, 이 점수로 Value를 가중합산합니다.
Self-Attention: 각 토큰의 Query가 모든 토큰의 Key와 비교되어 Attention Score를 생성하고, 이 점수로 Value를 가중합산합니다.
동작 과정은 이렇습니다.
- “앉았다"의 Query 벡터가 문장 내 모든 토큰의 Key 벡터와 내적(dot product)을 계산합니다.
- 내적 결과를 Key 벡터 차원의 제곱근으로 나눠 스케일링합니다.
- Softmax를 적용해 0과 1 사이의 가중치(Attention Score)로 변환합니다.
- 이 가중치로 각 토큰의 Value 벡터를 가중합산합니다.
결과적으로 “앉았다"는 “고양이가"에 높은 가중치를, “매트"에 중간 가중치를 부여하고, 이 정보들을 종합한 새로운 표현을 얻습니다. 핵심은 이 모든 계산이 행렬 곱셈으로 이루어지기 때문에 GPU에서 병렬로 처리할 수 있다는 점입니다.
Multi-Head Attention: 여러 관점으로 보기
하나의 Attention만으로는 단어 간 관계를 한 가지 측면에서만 포착합니다. 실제로 단어 사이에는 여러 종류의 관계가 존재합니다. “고양이가 매트 위에 앉았다"에서 “앉았다"와 “고양이가"는 주어-서술어 관계이고, “앉았다"와 “위에"는 위치 관계입니다.
Multi-Head Attention은 이 문제를 해결합니다. 동일한 입력에 대해 서로 다른 Q, K, V 변환 행렬을 사용하는 Attention을 여러 개(보통 8개 또는 16개) 병렬로 수행합니다. 각 “Head"는 서로 다른 종류의 관계를 학습합니다. 어떤 Head는 문법적 관계를, 다른 Head는 의미적 유사성을, 또 다른 Head는 위치적 근접성을 포착할 수 있습니다.
Positional Encoding: 순서 정보 부여
Self-Attention에는 고유한 약점이 있습니다. 모든 토큰을 동시에 처리하기 때문에, 토큰의 순서 정보가 없습니다. “고양이가 개를 쫓았다"와 “개가 고양이를 쫓았다"를 구분할 수 없다는 뜻입니다.
이 문제를 해결하기 위해 Transformer는 Positional Encoding을 사용합니다. 각 위치에 고유한 벡터를 만들어 입력 임베딩에 더합니다. 원 논문에서는 서로 다른 주파수의 사인/코사인 함수를 사용했습니다. 위치 1에는 특정 패턴의 벡터가, 위치 2에는 다른 패턴의 벡터가 부여되어, 모델이 토큰의 순서를 알 수 있게 됩니다.
Encoder-Decoder 구조
Transformer의 전체 구조는 Encoder와 Decoder 두 부분으로 구성됩니다.
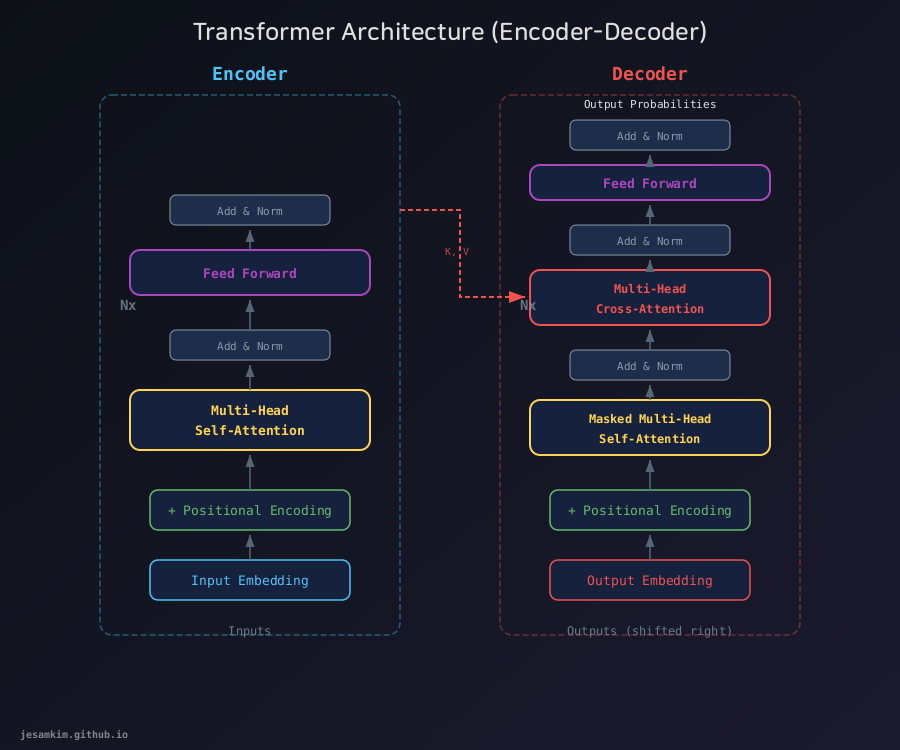 Transformer의 Encoder-Decoder 구조. Encoder의 출력이 Decoder의 Cross-Attention에 Key, Value로 전달됩니다.
Transformer의 Encoder-Decoder 구조. Encoder의 출력이 Decoder의 Cross-Attention에 Key, Value로 전달됩니다.
Encoder는 입력 문장을 처리합니다. Self-Attention 레이어와 Feed Forward 레이어가 쌓여 있고, 각 레이어에는 Residual Connection과 Layer Normalization(Add & Norm)이 적용됩니다. 원 논문에서는 이런 블록을 6개 쌓았습니다.
Decoder는 출력 문장을 생성합니다. Encoder와 비슷하지만 두 가지가 다릅니다.
- Masked Self-Attention: 미래 토큰을 볼 수 없도록 마스킹합니다. 번역 시 아직 생성하지 않은 단어를 참조할 수 없어야 하기 때문입니다.
- Cross-Attention: Decoder의 Query가 Encoder의 Key, Value를 참조합니다. 이 연결을 통해 Decoder는 입력 문장의 어떤 부분에 주목해야 하는지 학습합니다.
성능과 속도의 동시 달성
이 구조가 가져온 변화는 극적이었습니다. WMT 2014 영어-독일어 번역에서 기존 최고 성능을 BLEU 점수 2점 이상 앞질렀고, 학습 시간은 기존 모델 대비 크게 단축되었습니다. RNN의 순차 처리 병목이 사라졌기 때문입니다.
3. 왜 BERT가 필요했나
Transformer가 등장한 이후, 연구자들은 자연스러운 질문을 던졌습니다. 꼭 Encoder와 Decoder를 모두 써야 할까?
단방향의 한계
Transformer 이후 가장 먼저 주목받은 모델은 OpenAI의 GPT(2018)입니다. GPT는 Transformer의 Decoder만 사용합니다. 왼쪽에서 오른쪽으로 다음 토큰을 예측하는 방식으로 학습합니다.
이 접근법은 텍스트 생성에는 적합하지만, 문장을 이해하는 작업에는 한계가 있었습니다. 다의어 해석이 대표적인 예입니다. 문맥의 앞부분만 봐서는 단어의 정확한 의미를 판단할 수 없는 경우가 많고, 뒤에 나오는 정보까지 봐야 비로소 의미가 확정됩니다. GPT처럼 왼쪽→오른쪽으로만 읽는 모델은 이런 판단이 구조적으로 어렵습니다.
양방향 문맥의 필요성
Google의 연구팀은 이 문제에 집중했습니다. 문장 분류, 질의응답, 개체명 인식 같은 자연어 이해(NLU) 작업에서는 양방향 문맥이 필수적입니다.
그래서 탄생한 것이 BERT(Bidirectional Encoder Representations from Transformers)입니다. 이름을 하나씩 풀어보면 BERT의 본질이 보입니다.
- Bidirectional: 왼쪽→오른쪽만 보는 GPT와 달리, 양쪽 문맥을 동시에 봅니다
- Encoder: Transformer의 Encoder 구조만 사용합니다 (Decoder는 쓰지 않음)
- Representations: 텍스트의 의미를 담은 벡터 표현을 학습합니다. 라벨 없는 텍스트에서 스스로 학습하는 자기지도학습(Self-supervised Learning) 방식입니다
- Transformers: 앞에서 설명한 Transformer 아키텍처가 기반입니다
양방향이 왜 중요한지 “bank"라는 단어로 생각해봅니다. “We went to the river bank"에서 bank는 강둑입니다. “I need to go to bank to make a deposit"에서 bank는 은행입니다. 왼쪽 문맥(“river”)만 보면 강둑이라고 추측할 수 있지만, 오른쪽 문맥(“make a deposit”)을 같이 봐야 은행이라고 확신할 수 있습니다. GPT처럼 왼쪽→오른쪽만 읽는 모델은 이런 판단이 어렵습니다. BERT가 양방향을 선택한 이유가 여기에 있습니다.
자기지도학습이란 사람이 라벨을 붙이지 않아도, 데이터 자체에서 학습 신호를 만들어내는 방식입니다. BERT의 경우 문장 일부를 가리고 맞추는 것(MLM)이 바로 그 학습 신호입니다. 이 패러다임은 NLP를 넘어 음성(wav2vec), 이미지(MAE) 등 다른 분야에서도 동일하게 적용되고 있습니다.
4. BERT (2018) 핵심
Devlin et al.이 발표한 BERT의 핵심 기여는 두 가지입니다. 양방향 사전학습 방법과 Pre-train + Fine-tuning 패러다임입니다.
Masked Language Model (MLM)
양방향 Attention을 학습시키려면 한 가지 문제를 풀어야 합니다. 예측 대상 토큰이 자기 자신을 직접 볼 수 있다면, 모델은 답을 그냥 복사하면 되니까 아무것도 배우지 못합니다.
BERT는 이 문제를 해결했습니다. 입력 토큰의 15%를 무작위로 선택해 마스킹한 뒤, 모델이 양방향 문맥을 활용해 원래 토큰을 예측하도록 합니다. 이것이 Masked Language Model(MLM)입니다.
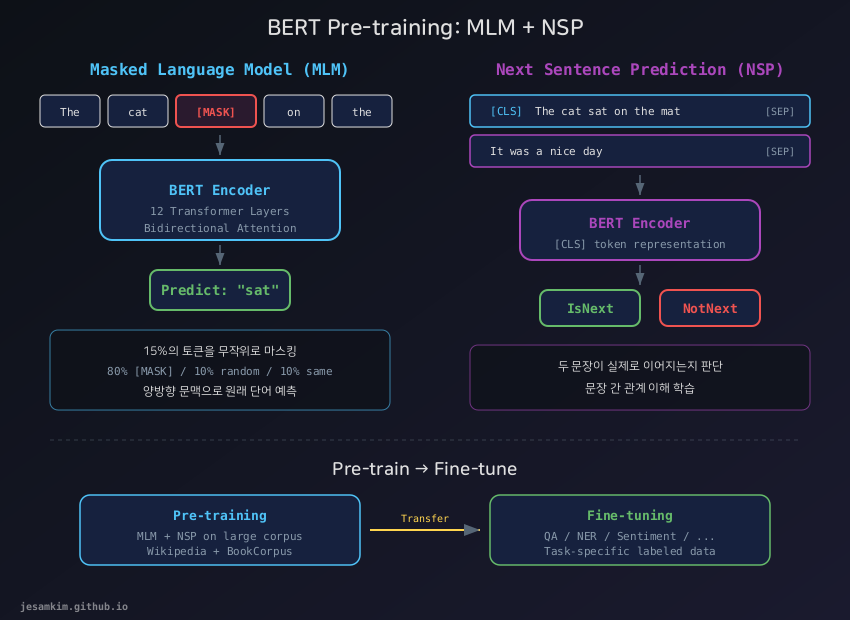 BERT의 두 가지 사전학습 과제: MLM(좌)과 NSP(우). MLM은 마스킹된 토큰을 양방향 문맥으로 예측하고, NSP는 두 문장의 연결 관계를 판단합니다.
BERT의 두 가지 사전학습 과제: MLM(좌)과 NSP(우). MLM은 마스킹된 토큰을 양방향 문맥으로 예측하고, NSP는 두 문장의 연결 관계를 판단합니다.
마스킹 방식에도 세부 전략이 있습니다.
- 선택된 15% 토큰 중 80%는 [MASK] 토큰으로 교체
- 10%는 랜덤한 다른 토큰으로 교체
- 10%는 원래 토큰 그대로 유지
왜 이렇게 복잡한 방식을 택했을까요? Fine-tuning 단계에서는 [MASK] 토큰이 존재하지 않습니다. 100% [MASK]로만 학습하면, 모델이 [MASK] 토큰에만 최적화되어 실제 사용 시 성능이 떨어집니다. 랜덤 교체와 원본 유지를 섞어서 모델이 어떤 위치의 토큰이든 올바른 표현을 학습하도록 유도한 것입니다.
Next Sentence Prediction (NSP)
MLM은 토큰 수준의 이해를 학습하지만, 문장 간 관계는 포착하지 못합니다. 질의응답이나 자연어 추론처럼 두 문장의 관계를 판단해야 하는 작업이 있습니다.
BERT는 Next Sentence Prediction(NSP)이라는 보조 과제를 추가했습니다. 두 문장 A, B를 주고, B가 실제로 A 다음에 오는 문장인지(IsNext) 아닌지(NotNext) 이진 분류합니다. 학습 데이터에서 50%는 실제 연속 문장 쌍을, 50%는 무작위로 조합한 쌍을 사용합니다.
입력 형식은 다음과 같습니다.
[CLS] 문장A 토큰들 [SEP] 문장B 토큰들 [SEP]
[CLS] 토큰의 최종 hidden state가 NSP 분류에 사용되고, 각 토큰의 hidden state가 MLM 예측에 사용됩니다. 두 과제의 loss를 합산하여 동시에 학습합니다.
Pre-train + Fine-tuning 패러다임
BERT 이전의 NLP는 각 작업마다 모델 구조를 처음부터 설계하고, 작업별 데이터로 처음부터 학습하는 방식이었습니다. BERT는 이 관행을 뒤집었습니다.
사전학습(Pre-training) 단계에서는 위키피디아와 BookCorpus 등 대규모 비라벨 텍스트로 MLM과 NSP를 학습합니다. 이 과정에서 모델은 언어의 일반적인 구조와 의미를 학습합니다.
미세조정(Fine-tuning) 단계에서는 사전학습된 모델에 작업별 출력 레이어를 하나 추가하고, 소량의 라벨 데이터로 전체 모델을 다시 학습합니다. 감성 분석이면 긍정/부정 분류기를, 질의응답이면 답변 위치 예측기를 붙이는 식입니다.
이 방식이 강력한 이유는 전이 학습(Transfer Learning)에 있습니다. 사전학습에서 축적한 언어 지식이 여러 하위 작업에 그대로 전이됩니다. 작업별 라벨 데이터가 적더라도 높은 성능을 달성할 수 있습니다.
BERT의 모델 크기
원 논문에서 발표된 두 가지 모델의 사양입니다.
| 모델 | Transformer 레이어 | Hidden Size | Attention Heads | 파라미터 수 |
|---|---|---|---|---|
| BERT-Base | 12 | 768 | 12 | 110M |
| BERT-Large | 24 | 1024 | 16 | 340M |
BERT-Base는 원래 Transformer Encoder와 동일한 크기로 설계되었습니다. 발표 당시 BERT는 GLUE, SQuAD, MultiNLI 등 11개 NLP 벤치마크에서 동시에 최고 성능을 기록했습니다.
5. 이 두 논문이 만든 현재의 LLM 지형
Transformer와 BERT는 이후 모든 언어 모델의 설계 기반이 되었습니다. 흥미로운 점은, Transformer의 어떤 부분을 사용하느냐에 따라 세 가지 계보가 갈라졌다는 것입니다.
Encoder-only: BERT 계열
Transformer의 Encoder만 사용합니다. 양방향 문맥을 활용하기 때문에 텍스트 이해 작업에 적합합니다.
- 대표 모델: BERT, RoBERTa, ALBERT, DeBERTa
- 적합한 작업: 감성 분석, 개체명 인식, 문장 유사도, 검색 랭킹
- 특징: 입력 문장의 표현(Embedding)을 잘 만들어내는 데 초점
후속 모델인 RoBERTa, DeBERTa 등이 BERT의 학습 방법을 개선하여 성능을 끌어올렸습니다.
Decoder-only: GPT 계열
Transformer의 Decoder만 사용합니다. 왼쪽에서 오른쪽으로 다음 토큰을 예측하는 방식으로, 텍스트 생성에 적합합니다.
- 대표 모델: GPT-2, GPT-3, GPT-4/5, Claude, Llama
- 적합한 작업: 대화, 글쓰기, 코드 생성, 추론
- 특징: 모델을 키우고 데이터를 늘리면 성능이 계속 향상되는 Scaling Law
GPT-3(2020)가 보여준 In-context Learning은 결정적인 전환점이었습니다. Fine-tuning 없이, 프롬프트에 예시 몇 개만 넣으면 새로운 작업을 수행할 수 있다는 발견은 GPT 계열, Claude 같은 범용 AI의 길을 열었습니다.
Encoder-Decoder: T5 계열
Transformer의 원래 구조를 그대로 사용합니다. 입력을 이해하고 출력을 생성하는 Sequence-to-Sequence 작업에 적합합니다.
- 대표 모델: T5, BART, mT5, Flan-T5
- 적합한 작업: 번역, 요약, 질의응답
- 특징: 모든 NLP 작업을 “텍스트 입력 → 텍스트 출력” 형식으로 통일
T5(2019)는 “Text-to-Text Transfer Transformer"라는 이름처럼, 분류 작업도 “positive”, “negative” 같은 텍스트를 출력하는 방식으로 처리합니다.
현재의 LLM은 어디에 위치하는가
2026년 현재, 가장 강력한 LLM들은 대부분 Decoder-only 구조를 채택하고 있습니다. GPT 계열, Claude, Gemini, Llama 등이 대표적입니다.
그 이유는 Scaling Law와 관련이 있습니다. Decoder-only 구조는 “다음 토큰 예측"이라는 단순한 목표로 학습하면서도, 모델 크기와 데이터를 키우면 추론, 코딩, 수학 등 복잡한 능력이 자연스럽게 발현(emergent)됩니다. BERT 스타일의 MLM보다 학습 효율이 높고, 생성 작업에서 유연하기 때문입니다.
그렇다고 BERT 계열이 사라진 것은 아닙니다. 검색 엔진의 문서 랭킹, 문장 임베딩, 텍스트 분류 등에서는 여전히 Encoder-only 모델이 효율적입니다. 실무에서는 목적에 따라 두 계열을 조합해서 사용하는 경우가 많습니다.
6. BERT 이후의 발전
BERT가 공개된 뒤, 수많은 후속 연구가 쏟아졌습니다. 크게 두 갈래입니다.
성능 개선 방향으로는 RoBERTa가 대표적입니다. NSP를 제거하고 10배 많은 데이터로 더 오래 학습했더니 성능이 올라갔습니다. ELECTRA는 마스킹 대신 “교체된 토큰을 찾아내는” 방식으로, 모든 토큰 위치에서 학습 신호를 얻어 효율을 높였습니다.
경량화 방향으로는 ALBERT가 레이어 간 파라미터를 공유해서 모델 크기를 줄였고, DistilBERT는 지식 증류(Knowledge Distillation) 기법으로 BERT의 97% 성능을 60% 크기로 달성했습니다.
이 모델들에서 사용된 기법은 지금도 Transformer 기반 모델 전반에서 활용되고 있습니다.
7. 핵심 정리
| 구분 | Transformer (2017) | BERT (2018) |
|---|---|---|
| 구조 | Encoder + Decoder | Encoder only |
| 핵심 기법 | Self-Attention, Multi-Head | MLM, NSP |
| 학습 방향 | 단방향 (Decoder) | 양방향 |
| 주요 기여 | RNN 없이 병렬 처리 | Pre-train + Fine-tune |
| 후속 영향 | 모든 LLM의 기반 구조 | NLU 벤치마크 석권 |
Transformer는 Self-Attention이라는 메커니즘으로 순차 처리의 한계를 넘었고, BERT는 이 구조를 양방향 사전학습에 활용해 NLP의 작업 방식 자체를 바꿨습니다. 두 논문이 제시한 아이디어는 약 8년이 지난 지금도 현대 AI의 핵심 기반으로 작동하고 있습니다.
References
- Vaswani, A., Shazeer, N., Parmar, N., et al. (2017). “Attention Is All You Need.” Advances in Neural Information Processing Systems 30 (NeurIPS 2017). https://arxiv.org/abs/1706.03762
- Devlin, J., Chang, M., Lee, K., Toutanova, K. (2018). “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.” Proceedings of NAACL-HLT 2019. https://arxiv.org/abs/1810.04805
- Radford, A., Narasimhan, K., Salimans, T., Sutskever, I. (2018). “Improving Language Understanding by Generative Pre-Training.” OpenAI. https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
- Liu, Y., Ott, M., Goyal, N., et al. (2019). “RoBERTa: A Robustly Optimized BERT Pretraining Approach.” https://arxiv.org/abs/1907.11692
- Raffel, C., Shazeer, N., Roberts, A., et al. (2019). “Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.” https://arxiv.org/abs/1910.10683
- Brown, T., Mann, B., Ryder, N., et al. (2020). “Language Models are Few-Shot Learners.” NeurIPS 2020. https://arxiv.org/abs/2005.14165