
1. 여러 모델을 운영하는 비용
프로덕션 환경에서 LLM을 운영하는 팀이라면, 한 가지 모델로 모든 작업을 처리하기 어렵다는 점을 잘 알고 있을 것입니다. 빠른 채팅 응답에는 경량 Instruct 모델을, 복잡한 수학 문제에는 추론 특화 모델을, 이미지 분석에는 멀티모달 모델을, 코드 생성에는 코딩 특화 모델을 각각 배포해야 합니다. 모델마다 별도의 엔드포인트, 라우팅 로직, GPU 할당이 필요하고, 운영 복잡도는 모델 수에 비례해 증가합니다.
2026년 3월 16일, Mistral AI가 공개한 Mistral Small 4는 이 문제에 정면으로 답합니다. 기존에 별도로 존재하던 Instruct(Small 3.2), 추론(Magistral), 비전(Pixtral), 코딩(Devstral) 네 가지 모델 계열을 하나의 MoE 모델로 통합했습니다. 119B 파라미터 규모이지만, 토큰당 실제 연산에 참여하는 파라미터는 6.5B에 불과합니다. Apache 2.0 라이선스로 상업적 사용과 파인튜닝에 제한이 없습니다.
이 글에서는 Small 4의 MoE 아키텍처, 통합 기능, configurable reasoning, 벤치마크 성능, 그리고 실제 배포 방법까지 순서대로 살펴보겠습니다.
2. MoE 아키텍처: 119B 파라미터, 6.5B 연산
Mixture-of-Experts의 핵심 아이디어
Dense 모델은 모든 토큰에 대해 전체 파라미터를 연산합니다. 반면 Mixture-of-Experts(MoE) 모델은 각 토큰마다 일부 Expert만 선택적으로 활성화합니다. 이 방식의 장점은 명확합니다. 전체 파라미터에 저장된 지식은 119B 규모이지만, 실제 연산 비용은 6.5B 수준에 머문다는 것입니다.
Small 4의 구조
Mistral Small 4의 MoE 레이어는 다음과 같이 구성됩니다.
- 총 파라미터: 119B (임베딩 + 출력 레이어 포함 시 약 8B 추가)
- Expert 수: 128개
- 토큰당 활성 Expert: 4개
- 토큰당 활성 파라미터: 약 6.5B
- 컨텍스트 윈도우: 256K 토큰 (262,144)
각 토큰이 입력되면, Router 네트워크가 128개 Expert 중 가장 적합한 4개를 선택합니다. 선택된 Expert의 출력은 가중합(weighted sum)으로 집계되어 최종 결과를 만듭니다. 나머지 124개 Expert는 해당 토큰에 대해 연산을 수행하지 않으므로, GPU 사이클을 소모하지 않습니다.
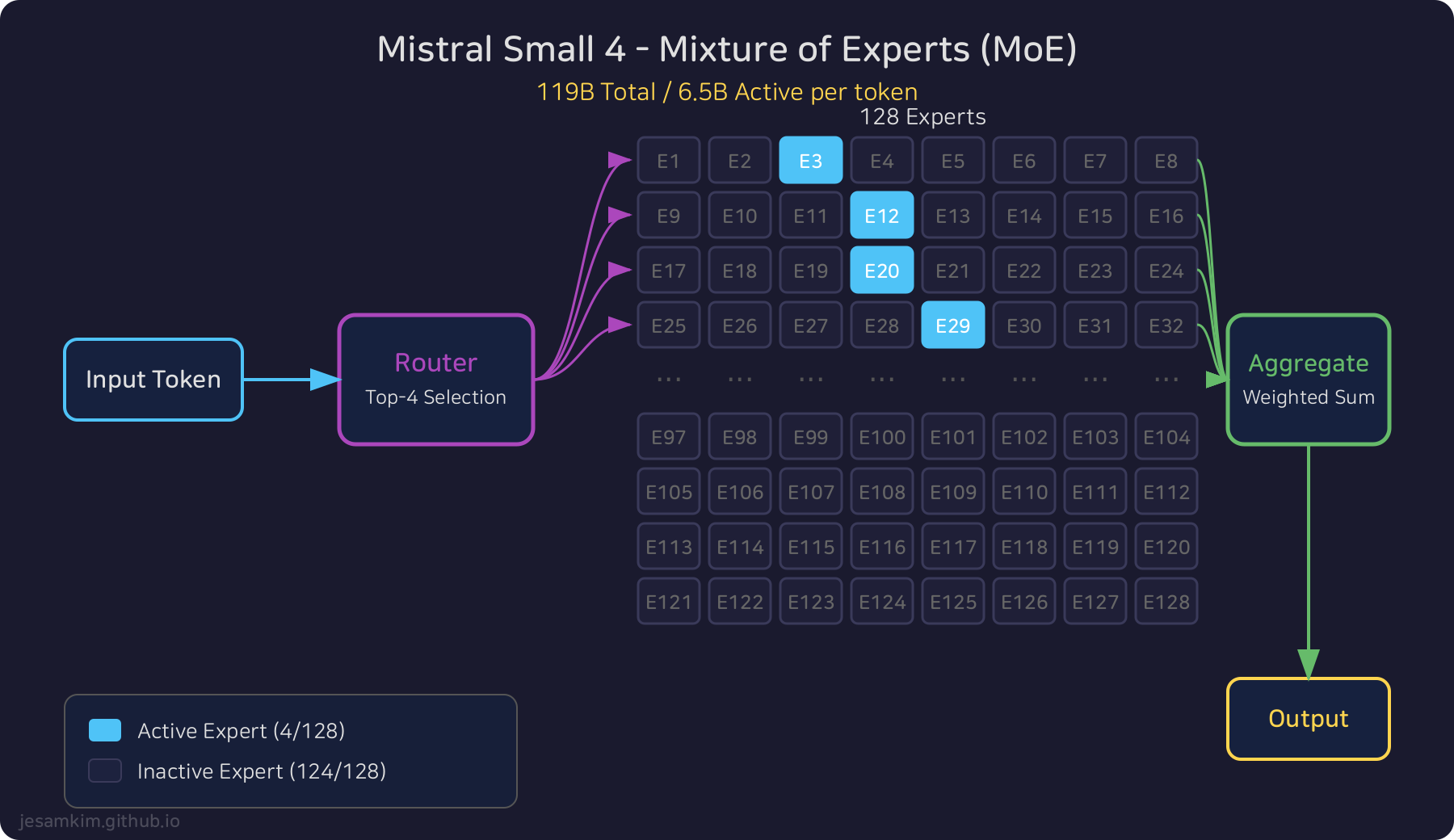 Mistral Small 4의 Sparse MoE 라우팅 구조. 128개 Expert 중 4개만 활성화되어 연산에 참여합니다.
Mistral Small 4의 Sparse MoE 라우팅 구조. 128개 Expert 중 4개만 활성화되어 연산에 참여합니다.
같은 119B 파라미터를 Dense 모델로 구성했다면, 토큰당 연산량은 약 18배 이상 증가합니다. MoE는 지식 용량과 추론 비용을 분리하는 아키텍처 패턴이며, Small 4는 이를 128 Expert / 4 Active라는 높은 희소성 비율로 구현했습니다.
3. 통합된 기능: 네 가지 모델이 하나로
Mistral Small 4 이전에는, 용도에 따라 서로 다른 모델을 선택해야 했습니다.
| 기존 모델 | 역할 | Small 4에서 |
|---|---|---|
| Mistral Small 3.2 | 일반 Instruct / 채팅 | 통합 |
| Magistral | 수학, 논리 추론 | 통합 |
| Pixtral | 이미지 이해, 멀티모달 | 통합 |
| Devstral | 에이전트 코딩, 함수 호출 | 통합 |
Small 4는 이 네 가지 기능을 단일 모델에서 제공합니다.
멀티모달: 텍스트와 이미지를 입력으로 받아 텍스트를 출력합니다. 별도의 비전 모델 없이 이미지 분석이 가능합니다.
다국어: 영어, 프랑스어, 스페인어, 독일어, 이탈리아어, 포르투갈어, 네덜란드어, 중국어, 일본어, 한국어, 아랍어를 지원합니다.
에이전트 기능: 네이티브 함수 호출(function calling)과 구조화된 JSON 출력을 지원합니다. 외부 도구와 연동하는 에이전트 워크플로우를 별도 모델 없이 구성할 수 있습니다.
운영 관점에서 가장 큰 변화는, 라우팅 계층이 사라진다는 점입니다. 요청 유형에 따라 서로 다른 모델 엔드포인트로 트래픽을 분기하는 로직이 불필요해집니다. 단일 엔드포인트가 채팅, 추론, 비전, 코딩 요청을 모두 처리합니다.
4. Configurable Reasoning: 요청 단위로 추론 깊이 조절
Small 4의 가장 실용적인 기능 중 하나는 reasoning_effort 파라미터입니다. 같은 모델, 같은 엔드포인트에서 요청마다 추론 깊이를 조절할 수 있습니다.
reasoning_effort="none": 빠른 응답 모드. 기존 Small 3.2와 유사한 속도로 동작합니다. 단순 질의응답이나 채팅에 적합합니다.reasoning_effort="high": 심층 추론 모드. 기존 Magistral처럼 단계적 사고 과정을 거칩니다. 수학, 논리, 복잡한 코드 생성에 적합합니다.
Mistral은 reasoning_effort="high" 사용 시 temperature 0.7을 권장하며, "none" 모드에서는 0.0에서 0.7 사이를 권장합니다.
코드 예시
from mistralai import Mistral
client = Mistral(api_key="YOUR_API_KEY")
# 빠른 채팅 응답 (reasoning_effort=none)
fast_response = client.chat.complete(
model="mistral-small-latest",
messages=[{"role": "user", "content": "Python에서 리스트 정렬 방법을 알려주세요."}],
reasoning_effort="none",
temperature=0.3,
)
# 심층 추론 (reasoning_effort=high)
deep_response = client.chat.complete(
model="mistral-small-latest",
messages=[{"role": "user", "content": "다음 미분방정식의 일반해를 구하세요: y'' + 4y = 0"}],
reasoning_effort="high",
temperature=0.7,
)
이 구조의 실질적 이점은 배포 단순화입니다. 빠른 응답이 필요한 채팅봇과 깊은 추론이 필요한 분석 파이프라인이 같은 GPU 클러스터, 같은 모델 인스턴스를 공유할 수 있습니다. 모델을 두 벌 배포하거나, 요청 유형에 따라 라우팅을 분기할 필요가 없습니다.
5. 벤치마크: 출력 효율성이 핵심
LLM 벤치마크에서 점수만 비교하는 것은 절반만 보는 셈입니다. 같은 점수를 달성하더라도, 출력 토큰 수가 적을수록 레이턴시가 낮고, 비용이 줄고, 사용자 경험이 좋아집니다. Small 4의 벤치마크는 이 출력 효율성에서 두드러집니다.
AA LCR (Artificial Analysis Length-Controlled Response)
Artificial Analysis의 LCR 벤치마크에서 Small 4는 0.72점을 기록하면서, 출력 길이를 1,600자로 유지했습니다. 동일한 점수대의 Qwen 모델은 5,800에서 6,100자를 출력했습니다. 같은 품질의 답변을 3.6배에서 3.8배 짧은 텍스트로 전달한 것입니다.
LiveCodeBench
코드 생성 벤치마크인 LiveCodeBench에서 Small 4는 GPT-OSS 120B를 능가하면서, 출력 토큰 수는 20% 적었습니다. 코드 품질을 유지하면서 불필요한 주석이나 반복을 줄인 결과입니다.
속도 개선
이전 세대인 Mistral Small 3 대비, Small 4는 레이턴시 최적화 모드에서 40% 레이턴시 감소를, 처리량 최적화 모드에서 3배 처리량 향상을 달성했습니다.
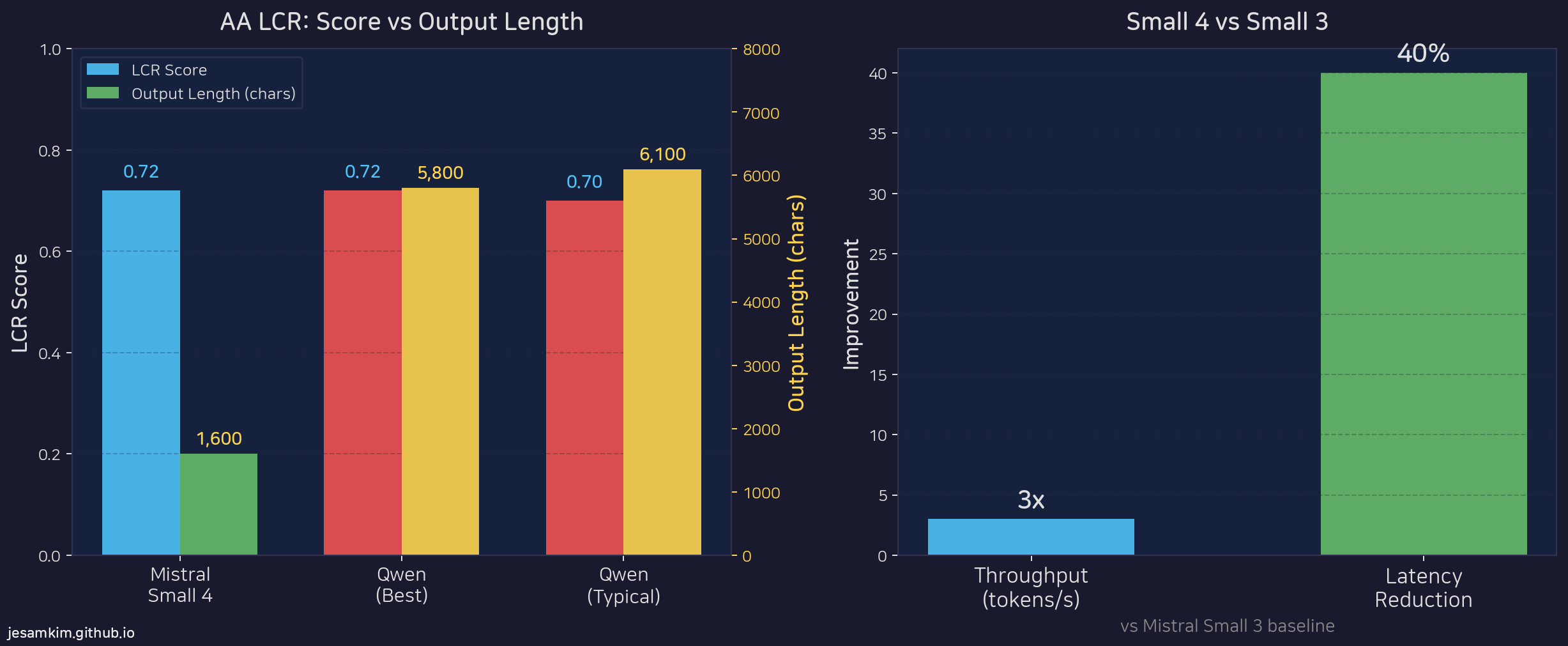 AA LCR 점수 대비 출력 길이 비교(좌), Small 3 대비 성능 개선(우). 출처: Mistral AI, Artificial Analysis
AA LCR 점수 대비 출력 길이 비교(좌), Small 3 대비 성능 개선(우). 출처: Mistral AI, Artificial Analysis
공식 벤치마크 결과
아래는 Mistral이 공개한 내부 벤치마크와 추론 모델 비교 결과입니다.
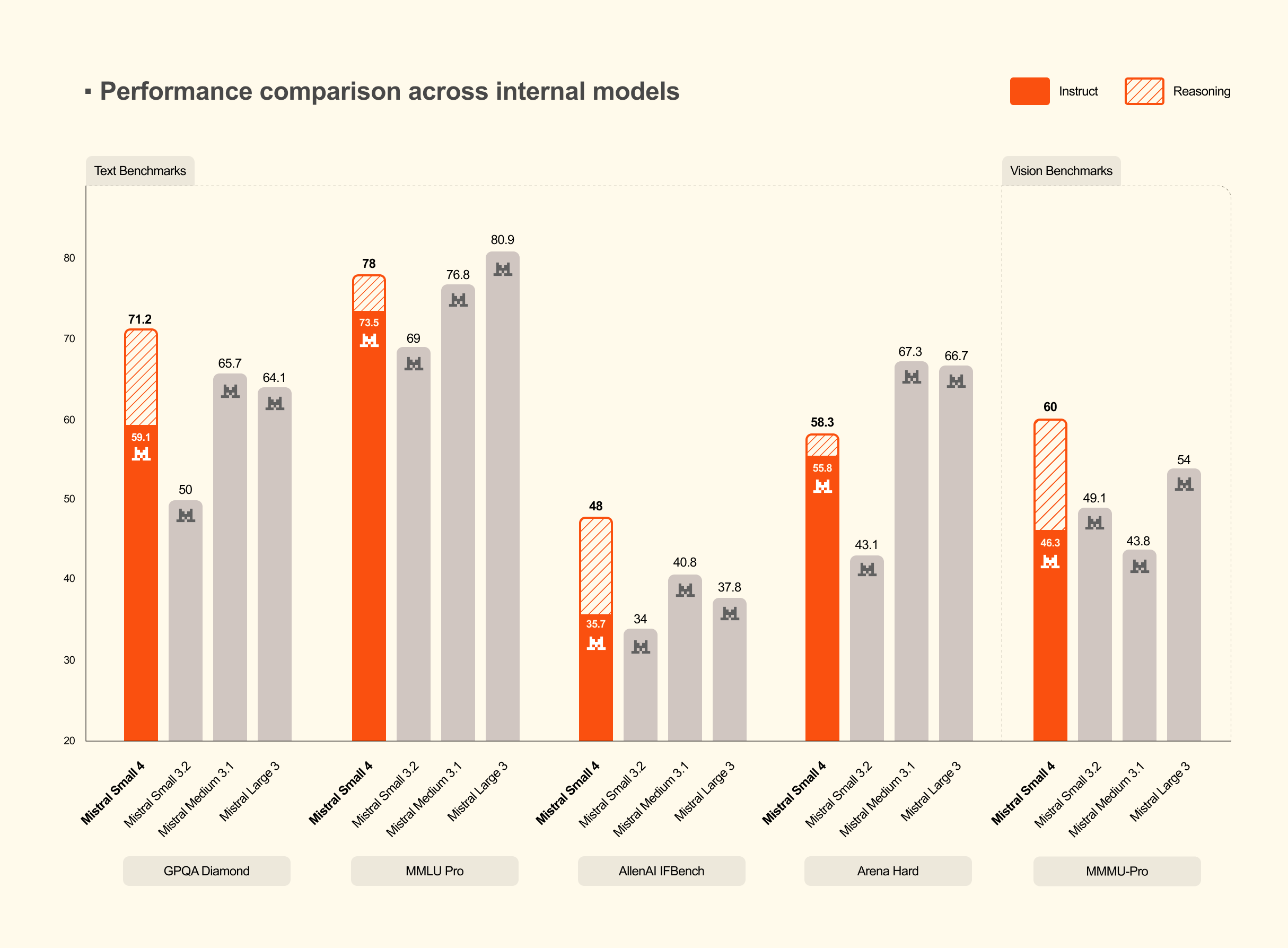 Mistral 내부 벤치마크 비교. 출처: Mistral AI HuggingFace
Mistral 내부 벤치마크 비교. 출처: Mistral AI HuggingFace
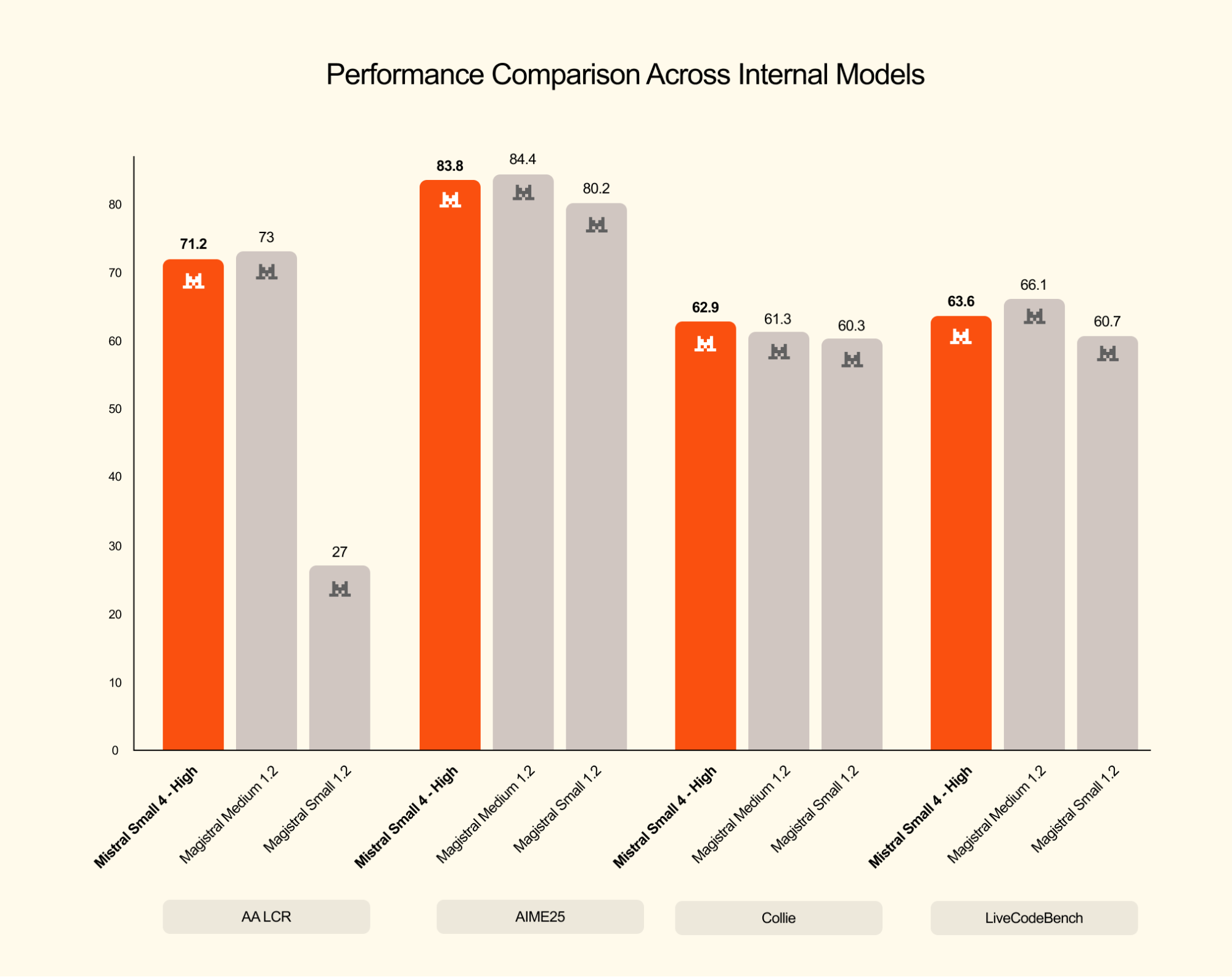 추론 모델 벤치마크 비교. 출처: Mistral AI HuggingFace
추론 모델 벤치마크 비교. 출처: Mistral AI HuggingFace
짧은 출력은 단순히 “말을 줄였다"는 의미가 아닙니다. 토큰 기반 과금 모델에서 출력 토큰이 줄면 비용이 직접 감소하고, 스트리밍 응답의 완료 시간이 단축되며, 후처리 파이프라인의 부하가 줄어듭니다.
6. 배포: API부터 셀프호스팅까지
Mistral API
가장 빠른 시작 방법은 Mistral의 관리형 API입니다.
| 항목 | 가격 (1M 토큰당) |
|---|---|
| Input | $0.15 |
| Output | $0.60 |
참고로 주요 경쟁 모델의 가격대는 다음과 같습니다. Claude Sonnet 4.6은 Input $3 / Output $15, GPT-5.2는 Input $1.75 / Output $14이며, DeepSeek V3.2는 Input $0.28 / Output $0.42입니다. Small 4는 오픈소스 모델 중에서도 가격 경쟁력이 높은 편에 속합니다.
셀프호스팅
Apache 2.0 라이선스이므로, 온프레미스나 클라우드 GPU에 직접 배포할 수 있습니다.
최소 하드웨어 요구사항:
- 4x NVIDIA H100 (80GB)
- 2x NVIDIA H200 (141GB)
- 1x DGX B200
권장 구성:
- 4x NVIDIA H200
- 2x DGX B200
추론 프레임워크:
- vLLM (권장): Mistral이 제공하는 커스텀 Docker 이미지
mistralllm/vllm-ms4:latest사용 가능 - llama.cpp, SGLang, Transformers, LM Studio도 지원
최적화 옵션:
- NVFP4: 4-bit 양자화 체크포인트로, 더 작은 GPU 구성에서도 구동 가능
- EAGLE: Speculative Decoding 헤드를 통한 추가 속도 향상
# vLLM으로 셀프호스팅 (Docker)
docker run --gpus all -p 8000:8000 \
mistralllm/vllm-ms4:latest \
--model mistralai/Mistral-Small-4-119B-2603 \
--tensor-parallel-size 4
NVIDIA와의 파트너십을 통해 NIM(NVIDIA Inference Microservices)에서 Day-0 지원을 받으며, NeMo를 통한 파인튜닝과 Nemotron Coalition 연동도 가능합니다.
정리
Mistral Small 4는 “하나의 모델로 여러 역할을 수행한다"는 단순한 메시지를 MoE 아키텍처와 configurable reasoning으로 현실화했습니다. 128개 Expert 중 4개만 활성화하는 희소성 구조 덕분에, 119B 규모의 지식을 6.5B 수준의 연산 비용으로 활용할 수 있습니다.
프로덕션 환경에서의 핵심 가치는 세 가지입니다. 첫째, 채팅/추론/비전/코딩 모델을 개별 관리하던 운영 부담이 줄어듭니다. 둘째, reasoning_effort 파라미터로 동일 엔드포인트에서 빠른 응답과 심층 추론을 모두 제공할 수 있습니다. 셋째, Apache 2.0 라이선스와 다양한 양자화 옵션으로 셀프호스팅의 진입 장벽이 낮습니다.
토큰당 $0.15/$0.60의 API 가격이나, H100 4장으로 시작할 수 있는 셀프호스팅 구성은, 중소 규모 팀에서도 충분히 검토해볼 수 있는 선택지입니다.
References
- Mistral AI. “Introducing Mistral Small 4.” https://mistral.ai/news/mistral-small-4 (2026.03.16)
- Mistral AI. “Mistral-Small-4-119B-2603 Model Card.” https://huggingface.co/mistralai/Mistral-Small-4-119B-2603
- Mistral AI. “Mistral-Small-4-119B-2603-NVFP4.” https://huggingface.co/mistralai/Mistral-Small-4-119B-2603-NVFP4
- NVIDIA. “NIM for Mistral Small 4.” https://build.nvidia.com/mistralai/mistral-small-4-119b-2603