
1. Inference Kingdom의 시대
NVIDIA CEO Jensen Huang은 GTC 2026 키노트에서 “2025년부터 2027년까지 GPU 수요만으로 1조 달러 규모의 매출이 예상된다"고 밝혔습니다. 이 수치는 단순한 전망이 아니라, AI 인프라 투자의 규모를 가늠할 수 있는 기준점입니다.
Huang은 이번 키노트에서 AI 기술 스택을 5개 계층의 케이크(Five-Layer AI Cake)로 설명했습니다. 칩, 시스템, 네트워크, 소프트웨어, 그리고 그 위에 놓이는 AI 모델까지. NVIDIA는 이 모든 계층을 자사 생태계로 통합하는 전략을 지난 수년간 꾸준히 실행해 왔고, GTC 2026에서 그 결실이 분명해졌습니다.
특히 주목할 점은 NVIDIA가 칩 제조사에서 AI Factory 설계자로의 전환을 공식화했다는 것입니다. Vera Rubin 플랫폼은 7개의 칩, 5개의 랙 스케일 시스템, 그리고 1개의 슈퍼컴퓨터를 하나의 통합 플랫폼으로 묶었습니다. GPU만 파는 회사가 아니라, 데이터센터 전체를 설계하는 회사가 된 셈입니다.
이 글에서는 GTC 2026의 표면적인 뉴스를 넘어, 아키텍처 수준의 기술적 분석을 시도합니다. Groq LPU 통합의 전략적 의미, AFD(Attention FFN Disaggregation)라는 새로운 추론 패러다임, 그리고 3세대에 걸친 로드맵이 엔터프라이즈 인프라 의사결정에 미치는 영향까지 다룹니다.
2. 3세대 로드맵: Blackwell에서 Vera Rubin, 그리고 Feynman으로
NVIDIA의 로드맵은 매년 새로운 아키텍처를 출시하는 빠른 주기를 유지하고 있습니다. 각 세대는 GPU만 바뀌는 것이 아니라 CPU, 네트워킹 스위치, DPU, 이더넷 스위치가 함께 업그레이드됩니다.
Blackwell Ultra (GB300) - 현재 세대
Blackwell Ultra는 현재 가용한 최신 세대입니다. DGX Station GB300은 72코어 Grace CPU와 Blackwell Ultra GPU를 NVLink-C2C로 연결한 데스크톱 슈퍼칩으로, 748GB의 일관된 메모리와 최대 20 PFLOPS FP4 성능을 제공합니다. 1조 파라미터 규모의 AI 모델을 단일 워크스테이션에서 다룰 수 있는 수준입니다.
Blackwell Ultra GPU는 160개의 SM(Streaming Multiprocessor), 5세대 Tensor Core, 그리고 NVFP4 정밀도를 지원합니다. Andrej Karpathy를 포함한 개발자들에게 이미 첫 시스템이 전달되었습니다.
Vera Rubin - 2026년 하반기
 NVIDIA Vera Rubin 플랫폼 구성 (Image: NVIDIA)
NVIDIA Vera Rubin 플랫폼 구성 (Image: NVIDIA)
Vera Rubin은 GTC 2026의 핵심 발표입니다. 7개의 칩이 하나의 플랫폼으로 통합됩니다:
- Rubin GPU: HBM4 탑재, 3.0+ TB/s 대역폭
- Vera CPU: ARM 기반, 기존 CPU 대비 2배 효율/50% 빠른 처리
- NVLink 6 Switch: 차세대 GPU간 인터커넥트
- ConnectX-9 SuperNIC: 네트워크 가속
- BlueField-4 DPU: 데이터 처리 유닛
- Spectrum-6 Ethernet Switch: 이더넷 스위칭
- Groq 3 LPU: 저지연 추론 가속기 (신규 추가)
시스템 구성으로는 NVL72(72 Rubin GPU + 36 Vera CPU), NVL144(Kyber 랙), NVL288(2개 Kyber 랙 구리 백플레인 연결)이 발표되었습니다.
NVIDIA의 공식 발표에 따르면, Vera Rubin NVL72는 Blackwell 대비 MoE 모델 학습 시 GPU 수를 1/4로 줄일 수 있으며, 추론 성능은 와트당 최대 10배, 토큰당 비용은 1/10 수준입니다.
Feynman - 2028년
Feynman은 2028년 예정된 차차세대 아키텍처입니다. Rosa CPU(Rosalind Franklin에서 명명), LP40 LPU, BlueField-5, CX10이 포함됩니다. 가장 중요한 변화는 NVLink 7과 Co-Packaged Optics(CPO)의 본격 도입입니다. NVL1152(8개 Kyber 랙) 구성에서 랙 간 연결에 CPO를 적용하여, 구리 연결의 물리적 한계를 넘어서는 것을 목표로 합니다.
SemiAnalysis의 분석에 따르면, Feynman GPU는 TSMC A16(1.6nm) 공정 기반으로 제조될 것으로 예상됩니다.
 Blackwell Ultra, Vera Rubin, Feynman, Groq 3 LPU/LPX 주요 사양 비교 (출처: NVIDIA 공식 발표 + SemiAnalysis 기술 분석)
Blackwell Ultra, Vera Rubin, Feynman, Groq 3 LPU/LPX 주요 사양 비교 (출처: NVIDIA 공식 발표 + SemiAnalysis 기술 분석)
3. Groq 인수와 LPU 아키텍처
200억 달러 규모의 IP 라이선싱
NVIDIA의 Groq 인수는 법적으로는 IP 라이선싱과 인력 채용의 형태를 취했습니다. SemiAnalysis의 분석에 따르면 규모는 약 200억 달러로, 완전한 기업 인수가 아닌 IP 라이선싱 구조를 선택한 이유는 반독점 심사 회피에 있습니다. NVIDIA의 시장 지배력을 고려하면 정식 인수는 규제 장벽이 높았을 것입니다.
실질적으로는 Groq의 핵심 IP와 인력을 모두 확보했고, 발표 후 4개월 이내에 LPX 시스템 개념 통합을 완료했습니다.
LPU 코어: Slice 기반 결정론적 실행
LPU(Language Processing Unit)의 핵심 혁신은 범용 코어 대신 단일 목적의 Slice 단위로 아키텍처를 재구성한 것입니다. 320바이트 벡터를 연산의 기본 단위로 사용하며, 네 종류의 실행 모듈이 파이프라인으로 동작합니다:
- MXM (Matrix Execution Module): 텐서 연산을 위한 밀집 행렬 곱셈 가감산
- MEM (Memory Block): 500MB 온칩 SRAM을 flat 메모리로 관리, 하드웨어 캐시 없이 컴파일러가 직접 배치
- VXM (Vector Execution Module): 포인트와이즈 산술 연산, 타입 변환, 활성화 함수
- SXM (Switch Execution Module): 순열, 회전, 분배, 전치 등 구조적 데이터 이동
이 슬라이스들이 수평으로 배열되어 데이터가 파이프라인처럼 흐르고, 명령어는 수직으로 분배됩니다. 하드웨어 실행이 예측 가능하기 때문에 컴파일러가 명령어 스케줄링을 극단적으로 최적화할 수 있습니다. 이를 결정론적 실행(Deterministic Execution)이라 하며, GPU의 동적 스케줄링과 근본적으로 다른 접근 방식입니다.
LP30 사양
 Groq 3 LPU 아키텍처 개요 (Image: NVIDIA Developer Blog)
Groq 3 LPU 아키텍처 개요 (Image: NVIDIA Developer Blog)
NVIDIA 공식 블로그 기준, LP30의 주요 사양은 다음과 같습니다:
- 온칩 SRAM: 500MB (LPU 1세대 230MB에서 2.2배 증가)
- SRAM 대역폭: 150 TB/s
- FP8 성능: 1.2 PFLOPS (LPU 1세대 750 TFLOPS INT8에서 대폭 향상)
- C2C 링크: 96개 x 112Gbps, 양방향 2.5 TB/s
SemiAnalysis의 분석에 따르면, LP30은 Samsung SF4X 공정으로 제조될 것으로 예상됩니다. 이는 전략적 선택입니다. TSMC N3 공정의 생산 제약을 우회하고, HBM 없이 동작하므로 HBM 공급 제약에서도 자유롭습니다. NVIDIA가 기존 TSMC/HBM 할당량을 소비하지 않고도 LPU 생산을 늘릴 수 있다는 의미입니다.
메모리 계층 비교: SRAM vs HBM4
LPU와 GPU의 메모리는 완전히 다른 특성을 가집니다.
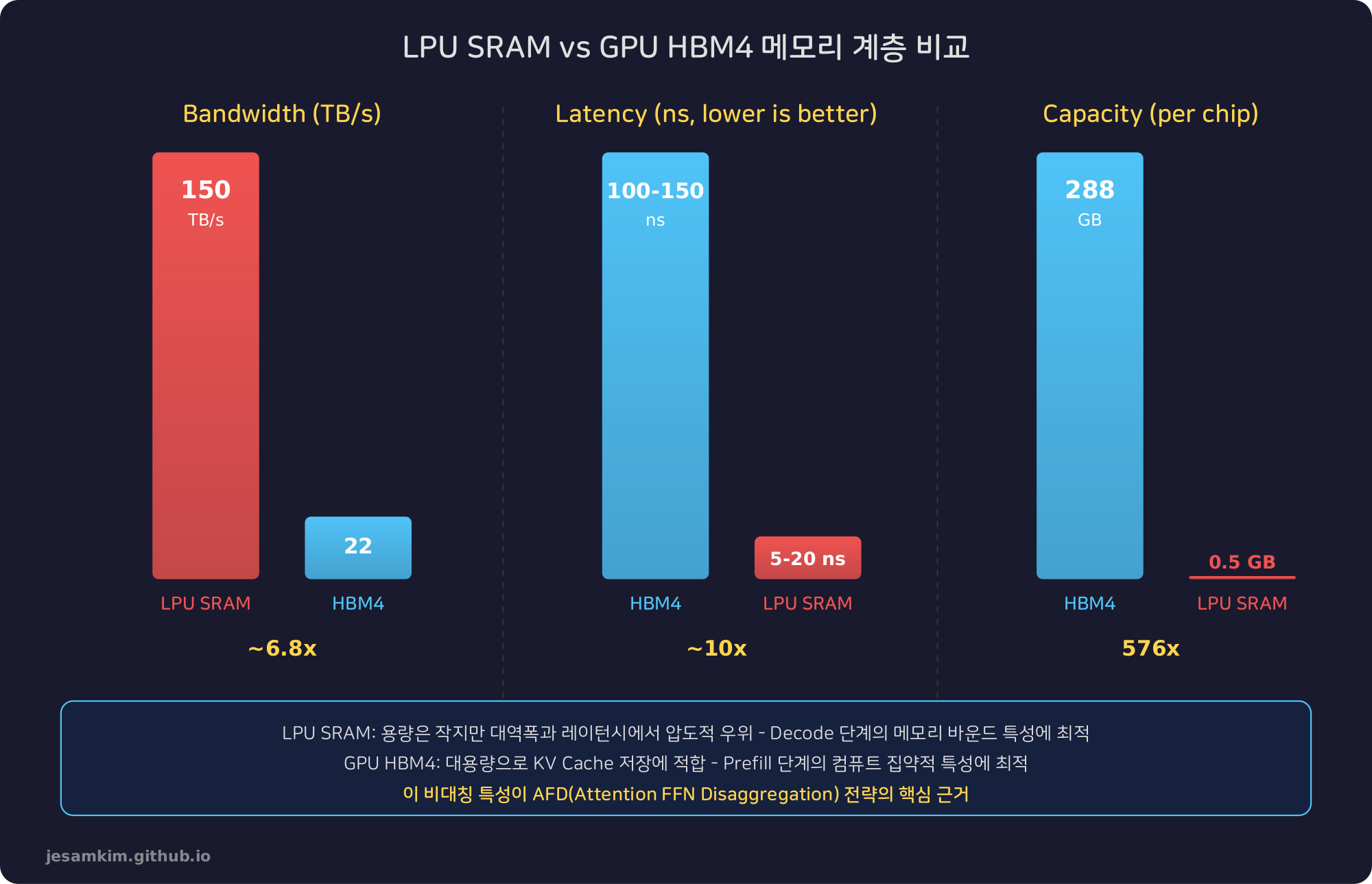 LPU SRAM과 GPU HBM4의 대역폭, 레이턴시, 용량 비교
LPU SRAM과 GPU HBM4의 대역폭, 레이턴시, 용량 비교
LPU SRAM은 용량(500MB)은 HBM4(288GB)에 비해 극히 작지만, 대역폭(150 TB/s)은 HBM4(22 TB/s)의 약 6.8배에 달하며, 레이턴시(5-20ns)는 HBM4(100-150ns) 대비 10배 이상 빠릅니다.
이 극단적인 비대칭 특성이 바로 AFD 전략의 기술적 근거가 됩니다.
4. AFD: Attention FFN Disaggregation - 추론 아키텍처의 전환
AFD는 GTC 2026에서 가장 주목할 만한 아키텍처 혁신입니다. LLM 추론의 Decode 단계를 Attention과 FFN으로 분리하여, 각각의 특성에 맞는 하드웨어에 배치하는 접근법입니다.
Prefill과 Decode의 근본적 차이
LLM 추론은 두 단계로 나뉩니다:
Prefill 단계는 입력 컨텍스트 전체를 병렬로 처리합니다. 여러 Query가 동시에 Key/Value를 생성하며, 대규모 행렬 연산으로 GPU의 병렬 연산 능력이 최대로 활용됩니다. 연산 집약적(Compute-Intensive)이며, GPU 활용률이 90% 이상에 달합니다.
Decode 단계는 토큰을 하나씩 순차적으로 생성합니다. 매 스텝에서 이전에 생성된 모든 토큰의 KV Cache를 메모리에서 읽어야 합니다. 메모리 바운드(Memory-Bound) 작업으로, 배치 크기를 늘려도 GPU 활용률은 10-20%에 머무릅니다. FLOPS는 남아돌지만 메모리 대역폭이 병목입니다.
 Prefill(연산 집약적)과 Decode(메모리 집약적)의 하드웨어 요구사항 차이
Prefill(연산 집약적)과 Decode(메모리 집약적)의 하드웨어 요구사항 차이
AFD의 핵심: Stateful과 Stateless의 분리
AFD는 Decode 단계 내부를 더 세밀하게 분리합니다:
Attention 연산 (Stateful): KV Cache를 동적으로 로딩하는 상태 유지(Stateful) 연산입니다. 대용량 HBM을 가진 GPU에 적합합니다. Vera Rubin NVL72의 GPU가 Prefill 전체와 Decode의 Attention 연산을 담당합니다.
FFN 연산 (Stateless): KV Cache 없이 토큰 입력만으로 계산되는 상태 비유지(Stateless) 연산입니다. 모델 가중치만 필요하며, LPU의 결정론적 실행과 고대역폭 SRAM에 최적화된 작업입니다. Groq 3 LPX의 LPU가 Decode의 FFN 연산을 전담합니다.
두 시스템은 Spectrum-X Ethernet을 통해 중간 Activations를 교환하며, NVIDIA Dynamo 프레임워크가 전체를 오케스트레이션합니다.
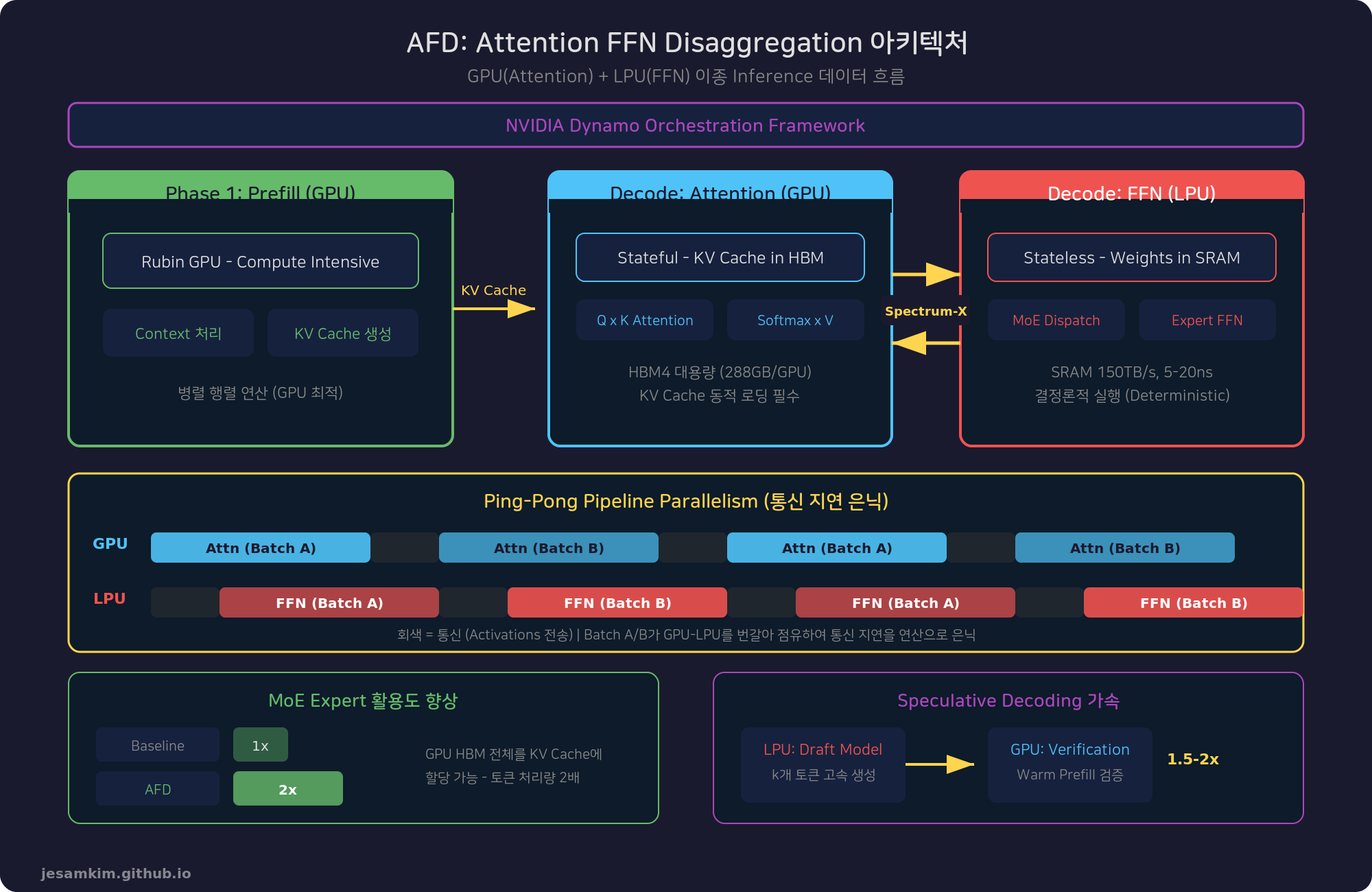 GPU(Attention) + LPU(FFN)의 데이터 흐름과 Ping-Pong Pipeline Parallelism
GPU(Attention) + LPU(FFN)의 데이터 흐름과 Ping-Pong Pipeline Parallelism
MoE 모델에서 Expert 활용도 2배 향상
AFD의 효과는 MoE(Mixture of Experts) 모델에서 특히 두드러집니다.
기존 구조에서는 GPU 하나가 Attention과 FFN 모두를 처리합니다. GPU 메모리를 KV Cache와 FFN 가중치가 나누어 사용하므로, 처리 가능한 토큰 수가 제한됩니다. 100개 토큰을 처리할 때 각 Expert는 평균 1개 토큰만 받아 활용도가 낮습니다.
AFD 구조에서는 GPU가 Attention만 담당하므로 HBM 전체를 KV Cache에 할당할 수 있습니다. 처리 가능 토큰이 200개로 늘어나고, 각 Expert의 활용도가 2배 향상됩니다. MoE 모델이 점점 더 Sparse해지는(Expert 풀이 커지는) 추세에서 이 효과는 더 커집니다.
Ping-Pong Pipeline Parallelism
AFD에서 GPU-LPU 간 토큰 라우팅은 All-to-All 집합 통신을 두 번 수행하므로 네트워크 지연이 발생할 수 있습니다. 이를 해결하기 위해 Ping-Pong Pipeline Parallelism을 적용합니다.
전체 배치를 마이크로 배치(Micro-batch)로 분할하고, 마이크로 배치 A가 LPU에서 FFN 연산을 수행하는 동안 마이크로 배치 B는 GPU에서 Attention 연산을 수행합니다. 두 마이크로 배치가 GPU와 LPU 사이를 번갈아 오가며, 통신 지연이 연산 시간에 의해 가려집니다(Hidden).
이 기법은 MegaScale-Infer와 Step-3 논문에서 처음 제안된 최신 학술 연구 결과인데, NVIDIA가 이를 실제 하드웨어 시스템과 소프트웨어 프레임워크(Dynamo)에 신속하게 통합했다는 점이 주목할 만합니다.
Speculative Decoding 가속
LPU는 AFD 외에도 Speculative Decoding의 Draft Model 실행을 가속합니다. 소형 Draft Model이 k개 토큰을 예측하면, 메인 모델이 한 번의 Warm Prefill로 검증하여 디코딩 스텝당 1.5-2배의 토큰 출력 증가를 달성합니다.
기존에는 Draft Model과 Verifier Model이 같은 GPU에서 돌았지만, AFD 구조에서는 LPU가 Draft 토큰을 고속 생성하고 GPU가 검증하는 이종 구성이 가능해집니다. LPX Compute Tray의 Fabric Expansion Logic FPGA가 DDR5 최대 256GB를 제공하여, Draft Model의 대용량 메모리 요구사항도 충족시킵니다.
NVIDIA Dynamo 프레임워크
 NVIDIA Dynamo - AI Factory를 위한 추론 운영 체제 (Image: NVIDIA)
NVIDIA Dynamo - AI Factory를 위한 추론 운영 체제 (Image: NVIDIA)
Dynamo는 이 모든 이종 추론 인프라를 하나의 일관된 서빙 경로로 통합하는 오케스트레이션 프레임워크입니다:
- 요청을 분류하고 레이턴시 목표에 따라 작업 라우팅
- Prefill을 GPU에 할당하여 대규모 컨텍스트 처리 및 KV Cache 빌드
- 중간 Activations를 LPU에 전달하여 FFN/MoE 실행
- KV-aware 라우팅, 저오버헤드 전송, 레이턴시 목표 기반 스케줄링으로 테넌트 간 지터를 줄이고 안정적인 테일 레이턴시 유지
NVIDIA 공식 블로그에 따르면, Vera Rubin NVL72와 LPX의 조합은 GB200 NVL72 대비 메가와트당 최대 35배 높은 TPS(Tokens Per Second)를 달성하며, 조 단위 파라미터 모델에 대해 최대 10배의 수익 기회를 제공합니다.
5. 시스템 아키텍처: 랙에서 AI Factory까지
LPX Rack: 256 LPU의 추론 전용 랙
 NVIDIA Groq 3 LPX 랙 시스템 (Image: NVIDIA Developer Blog)
NVIDIA Groq 3 LPX 랙 시스템 (Image: NVIDIA Developer Blog)
LPX 랙은 32개의 액체냉각 1U Compute Tray로 구성됩니다. 각 Tray에는 8개의 LPU 가속기, 호스트 프로세서, Fabric Expansion Logic이 탑재됩니다. 케이블리스 설계로 배포가 간소화되었습니다.
랙 전체 사양:
- 총 256 LPU
- 온칩 SRAM: 128GB (256 x 500MB)
- 집계 온칩 대역폭: 40 PB/s
- Scale-up C2C 대역폭: 640 TB/s
- FP8 처리량: 315 PFLOPS
4개 랙을 하나의 Scale-up 도메인으로 구성하면(1,024 LPU), 총 160,000 TB/s의 집계 메모리 대역폭을 확보합니다. 이는 Vera Rubin NVL72(1,580 TB/s)의 약 100배에 달하는 수치로, LPX가 추론 처리량에 얼마나 특화되었는지 보여줍니다.
Kyber 랙 업데이트: 블레이드 밀도 2배
GTC 2025 프로토타입에서 GTC 2026 업데이트로 Kyber 랙 아키텍처가 크게 변경되었습니다:
| 항목 | GTC 2025 | GTC 2026 |
|---|---|---|
| Compute Blade | 2 GPU + 2 Vera CPU | 4 GPU + 2 Vera CPU |
| Canister 수 | 4개 | 2개 |
| Compute Blade 수 | 72개 (4x18) | 36개 (2x18) |
| 총 GPU 수 | 144개 | 144개 (동일) |
| Switch Blade | 1U | 2U (6 NVLink 7 스위치) |
| NVLink 7 스위치 | - | 72개 (12x6) |
GPU 밀도가 블레이드당 2배로 증가하면서 Canister 수는 절반으로 줄었고, 총 GPU 수는 144개로 동일합니다. GPU는 80DP 커넥터를 통해 미드플레인에 연결되며(14.4Tbit/s uni-di), NVLink 7 스위치는 Flyover Cable로 미드플레인에 연결됩니다.
NVL288: 2개 Kyber 랙의 구리 결합
NVL288은 2개의 Kyber 랙(각 144 GPU)을 거대한 구리 백플레인으로 Back-to-Back 연결하여, 총 288개의 GPU를 단일 Scale-up 도메인으로 묶습니다. NVLink 7 스위치가 144포트의 448G PAM4를 지원해야 하므로, 신호 무결성 측면에서 극도의 기술적 도전이 따릅니다.
광학 전환을 최대한 미루고 구리 연결의 한계를 시험하는 NVIDIA의 전략적 선택입니다.
Vera ETL256: CPU 전용 랙
강화학습과 데이터 전처리 수요의 급증에 대응하기 위해, 256개의 Vera CPU를 단일 랙에 집적한 ETL256이 발표되었습니다.
OpenAI o1, o3와 같은 추론 중심 모델의 등장으로 RL 워크로드가 급증했고, RL 환경 시뮬레이션과 보상 모델 계산은 순차적 로직을 요구하여 GPU보다 CPU에 적합합니다. 멀티모달 데이터의 전처리 병목도 CPU 전용 랙의 필요성을 높였습니다.
과거에는 GPU 서버에 고성능 CPU를 함께 탑재했지만, 이제는 GPU 랙(NVL72)과 CPU 랙(ETL256)을 물리적으로 분리하여 각 워크로드에 맞게 독립적으로 확장할 수 있습니다.
CMX와 STX: 스토리지 계층 표준화
NVIDIA는 CMX(Converged Memory Extension)라는 새로운 중간 메모리 계층을 도입했습니다. HBM/SRAM과 네트워크 스토리지(SSD/HDD) 사이에 위치하며, 대규모 모델 학습 시 체크포인팅, 추론 시 KV Cache 오프로딩, 데이터셋 스테이징을 고속으로 처리합니다.
이를 구현하기 위한 STX(Storage Tray Extension) 랙은 NVLink 또는 초고속 Ethernet을 통해 Compute 랙과 직접 연결됩니다. BlueField-4 기반의 DOCA Memos 프레임워크는 추론 처리량을 최대 5배 향상시킨다고 합니다.
CPO 로드맵: 구리 우선, 광학은 점진적으로
NVIDIA의 CPO(Co-Packaged Optics) 도입 전략은 “구리를 쓸 수 있는 곳에는 구리를, 반드시 필요한 곳에만 광학을” 원칙을 따릅니다.
| 세대 | 시스템 | Scale-up 방식 |
|---|---|---|
| Rubin | NVL72 (Oberon) | 전체 구리 |
| Rubin Ultra | NVL144 (Kyber) | 전체 구리 |
| Rubin Ultra | NVL288 (2x Kyber) | 구리 (랙 간 구리 백플레인) |
| Rubin Ultra | NVL576 (8x Oberon) | 랙 내 구리 + 랙 간 CPO (소량) |
| Feynman | NVL144 (Kyber) | 전체 구리 |
| Feynman | NVL1152 (8x Kyber) | 랙 내 구리 + 랙 간 CPO |
SemiAnalysis에 따르면, 많은 분석가들이 Kyber 랙에 CPO Scale-up이 도입될 것으로 예상했지만 실제로는 그렇지 않습니다. CPO는 NVL576부터 랙 간 연결에만 사용되며, 랙 내부는 계속 구리를 사용합니다. 448Gbps PAM4 SerDes의 기술적 도전과 제조 신뢰성 문제가 핵심 이유입니다.
Feynman NVL1152에서는 Dragonfly 토폴로지와 OCS(Optical Circuit Switch)를 도입하여, 전기적 변환 없이 광 신호를 직접 라우팅하는 방식으로 1,152개 GPU 간의 효율적인 Scale-up 네트워크를 구성할 것으로 예상됩니다.
6. 소프트웨어와 에코시스템
NemoClaw/OpenClaw: 에이전틱 AI 소프트웨어 스택
Jensen Huang은 OpenClaw를 “인류 역사상 가장 인기 있는 오픈소스 프로젝트"라고 표현했습니다. 첫 주에 GitHub 스타 10만 개를 돌파하고 200만 방문자를 기록했으며, “모든 회사가 OpenClaw 전략을 가져야 한다"고 강조했습니다.
NemoClaw는 OpenClaw 어시스턴트를 안전하게 실행하기 위한 오픈소스 스택으로, 정책 시행, 네트워크 가드레일, 프라이버시 라우팅을 통합합니다. 단일 명령으로 NVIDIA OpenShell 런타임과 Nemotron 모델을 배포할 수 있습니다.
Physical AI
NVIDIA는 물리 세계의 AI를 위한 생태계를 확장하고 있습니다:
- Cosmos 3: 물리 AI 개발을 위한 월드 모델, GitHub과 Microsoft Foundry에서 제공
- Isaac GR00T: 범용 로봇 AI 프레임워크. GTC 현장에서 AGIBOT, Agile Robots, Hexagon Robotics 등 다수의 로봇이 시연
- Drive Hyperion L4: 로보택시 플랫폼. BYD, Hyundai, Nissan, Geely가 새 파트너로 합류하고, Uber와의 라이드헤일링 파트너십 발표
N1X AI PC
N1X는 MediaTek과 협력한 AI PC 플랫폼입니다. RTX PRO 6000 Blackwell은 4,000 TOPS의 로컬 AI 연산과 96GB GPU 메모리를 제공합니다. DGX Spark은 최대 4개 시스템을 클러스터링할 수 있게 업데이트되었습니다.
DLSS 5 Neural Rendering
DLSS 5는 3D 가이드 뉴럴 렌더링으로, 로컬 하드웨어에서 실시간 포토리얼 4K 성능을 구현합니다.
Space Computing
NVIDIA Space-1 Vera Rubin 시스템은 AI 데이터센터를 궤도에 올리는 것을 목표로 합니다. 가속 컴퓨팅을 “지구에서 우주까지” 확장하는 구상입니다.
7. 엔터프라이즈 시사점
추론 중심 투자로의 전환
GTC 2026의 메시지는 명확합니다. AI 인프라 투자의 중심이 학습에서 추론으로 이동하고 있습니다. Vera Rubin 플랫폼 전체가 추론 효율 극대화를 지향하며, LPU 통합과 AFD 아키텍처는 이 전환을 가속합니다.
AWS, Microsoft, Google Cloud, Oracle이 모두 Vera Rubin 시스템 지원을 발표했습니다. AWS는 올해부터 100만 개 이상의 NVIDIA GPU 배포를 시작하며, Microsoft는 액체냉각 Grace Blackwell GPU 수십만 개를 1년 이내에 글로벌 데이터센터에 배포했습니다.
GPU-LPU 이종 클러스터 설계 고려사항
AFD 구조를 도입하려는 조직은 다음을 고려해야 합니다:
- 워크로드 특성 분석: Decode 비중이 높은 대화형/실시간 서비스일수록 LPU의 효과가 큽니다. Prefill 비중이 높은 문서 요약 등은 GPU만으로 충분할 수 있습니다.
- 네트워크 대역폭: GPU-LPU 간 Activations 교환에 Spectrum-X Ethernet이 필수적입니다. 기존 네트워크 인프라와의 호환성을 확인해야 합니다.
- 모델 아키텍처: MoE 모델에서 AFD의 효과가 가장 큽니다. Dense 모델에서도 효과가 있지만, Expert 활용도 향상이라는 핵심 이점은 MoE에서 극대화됩니다.
Blackwell 구매 vs Vera Rubin 대기 의사결정
현재 AI 인프라를 구축하려는 조직이 직면하는 가장 현실적인 질문입니다:
| 고려 요소 | Blackwell Ultra (지금) | Vera Rubin (2026 H2) |
|---|---|---|
| 가용성 | 즉시 구매 가능 | 2026년 하반기 |
| 추론 효율 | 기준선 | 와트당 10배, 토큰당 비용 1/10 |
| 학습 효율 | 우수 | MoE 학습 시 GPU 1/4 |
| LPU 통합 | 불가 | 네이티브 지원 |
| 리스크 | 낮음 (검증된 제품) | 중간 (신규 플랫폼) |
즉각적인 수요가 있다면 Blackwell Ultra를 선택하되, 6개월 이상의 여유가 있다면 Vera Rubin의 추론 효율 향상이 TCO에 미치는 영향을 심도 있게 검토할 필요가 있습니다.
공급망 영향
GTC 2026의 발표는 여러 공급망 파트너에게 직접적인 영향을 미칩니다:
- AlphaWave: CPO 도입 지연과 구리 연결 유지 전략으로 DSP 및 Retimer 수요 지속 증가
- Amphenol / FIT: NVL288 등 대규모 구리 백플레인 시스템과 고밀도 커넥터(80DP 등) 수요 직접 수혜
- Marvell: AEC(Active Electrical Cable) 및 광학 인터커넥트 분야에서 다변화된 네트워크 토폴로지 지원
- Samsung: SF4X 공정을 통한 LPU 제조. TSMC 의존도를 낮추려는 NVIDIA 전략의 핵심 파트너
4대 기술 혁신 트렌드
GTC 2026에서 확인된 핵심 기술 트렌드를 정리하면:
AFD (Attention FFN Disaggregation): Stateful 연산과 Stateless 연산의 분리라는 새로운 추론 아키텍처가 표준으로 자리잡을 것입니다.
CPO의 단계적 도입: 구리의 한계를 극복하기 위해 랙 간 연결부터 시작하여 점진적으로 광학 인터커넥트 생태계가 확대됩니다.
초고밀도 분리형 아키텍처 (Disaggregation): GPU, CPU, LPU, 스토리지가 각각 독립적인 랙 단위로 구성되어 워크로드에 맞게 유연하게 확장되는 구조가 보편화됩니다.
HW-SW 공동 설계의 극대화: Ping-Pong Pipeline Parallelism처럼 최신 학술 연구가 하드웨어와 소프트웨어(Dynamo)에 빠르게 통합되는 속도가 NVIDIA의 핵심 경쟁력입니다.
NVIDIA의 GTC 2026 발표는 경쟁사들이 단일 칩 성능에 집중하는 사이, 시스템 및 데이터센터 레벨의 아키텍처 혁신으로 격차를 벌리고 있음을 보여줍니다. AI 인프라에 대한 투자를 계획하는 조직이라면, 단일 칩의 스펙 비교를 넘어서 이러한 시스템 수준의 아키텍처 진화를 이해하는 것이 중요합니다.
References
- NVIDIA Newsroom, “NVIDIA Vera Rubin Platform,” March 2026. https://nvidianews.nvidia.com/news/nvidia-vera-rubin-platform
- NVIDIA Developer Blog, “Inside NVIDIA Groq 3 LPX: The Low-Latency Inference Accelerator for the NVIDIA Vera Rubin Platform,” March 2026. https://developer.nvidia.com/blog/inside-nvidia-groq-3-lpx-the-low-latency-inference-accelerator-for-the-nvidia-vera-rubin-platform/
- NVIDIA Blog, “GTC 2026 News,” March 2026. https://blogs.nvidia.com/blog/gtc-2026-news/
- SemiAnalysis (Dylan Patel, Myron Xie, Daniel Nishball et al.), “GTC 2026 Recap: NVIDIA’s Inference Kingdom,” March 24, 2026.