
Enterprise 환경에서 LLM 기반 시스템을 프로덕션에 배포하려면, 단순히 API를 호출하는 것 이상의 설계가 필요합니다. PoC에서는 잘 동작하던 시스템이 실제 트래픽과 다양한 질의를 만나면 hallucination, 검색 품질 저하, 보안 취약점 같은 문제가 수면 위로 올라옵니다.
이 글에서는 Enterprise LLM 시스템을 설계할 때 반복적으로 등장하는 5가지 핵심 패턴을 정리합니다. 각 패턴은 독립적으로 적용할 수도 있고, 하나의 시스템 안에서 조합할 수도 있습니다.
1. Enterprise RAG: 검색 품질이 답변 품질을 결정합니다
RAG(Retrieval-Augmented Generation)는 LLM이 외부 지식을 참조해서 답변을 생성하는 기법입니다. 원리 자체는 단순하지만, 5만 건 이상의 내부 문서를 다루는 Enterprise 환경에서는 설계 난이도가 급격히 올라갑니다.
시맨틱 청킹
고정 길이(예: 500자)로 문서를 자르면 문맥이 끊기는 경우가 많습니다. 문단이나 섹션 경계를 존중하는 시맨틱 청킹이 검색 품질에 직접적인 영향을 줍니다. 청크 간 50토큰 정도의 overlap을 두면 경계 부분의 정보 손실을 줄일 수 있습니다.
각 청크에는 원본 문서명, 페이지 번호, 섹션 제목, 부서 정보 같은 메타데이터를 함께 저장합니다. 이 메타데이터가 나중에 접근 제어와 필터링의 기반이 됩니다.
하이브리드 검색: Dense + Sparse
Embedding 기반의 Dense 검색은 의미적 유사성을 잘 잡지만, 고유명사나 약어 같은 키워드 매칭에는 약합니다. BM25 기반의 Sparse 검색은 반대 성격을 가집니다. 두 방식을 결합하는 하이브리드 검색이 실무에서 가장 안정적인 결과를 보여줍니다.
2단계 검색: Retrieve-then-Rerank
검색 파이프라인의 핵심 구조입니다.
- 1단계 (Bi-Encoder): Cohere Embed v4로 쿼리와 문서를 각각 임베딩한 뒤 코사인 유사도로 Top-50을 뽑습니다. 문서 임베딩은 사전에 계산해두므로 속도가 빠릅니다.
- 2단계 (Cross-Encoder): Cohere Rerank v3가 쿼리-문서 쌍을 직접 비교해서 Top-5를 선별합니다. 정확도는 높지만, 매 쿼리마다 실시간 연산이 필요합니다.
이 2단계 구조는 recall과 precision의 균형을 맞추는 검증된 방법입니다. Bi-Encoder만으로는 정밀도가 부족하고, Cross-Encoder만으로는 수만 건을 전수 비교할 수 없습니다.
접근 제어
Enterprise RAG에서 빠뜨리기 쉬운 부분이 문서 수준 접근 제어입니다. 벡터 DB에 문서별 ACL(Access Control List)을 메타데이터로 저장하고, 쿼리 시점에 사용자의 부서/권한 정보를 기준으로 필터링합니다. 이걸 빠뜨리면, 인사팀 직원이 경영진 전용 문서를 검색 결과로 받는 상황이 생깁니다.
평가 메트릭
RAG 시스템의 품질을 어떤 숫자로 측정할 것인지 미리 정해야 합니다.
| 측정 대상 | 메트릭 | 설명 |
|---|---|---|
| 검색 품질 | nDCG@10 | 상위 10개 결과의 순위 품질 (1에 가까울수록 좋음) |
| 검색 범위 | Recall@10 | 관련 문서가 Top-10에 포함된 비율 |
| 답변 신뢰도 | Faithfulness | 답변이 검색된 문서에 근거하는 정도 |
| 운영 품질 | User Feedback | 사용자 만족도 (thumbs up/down) |
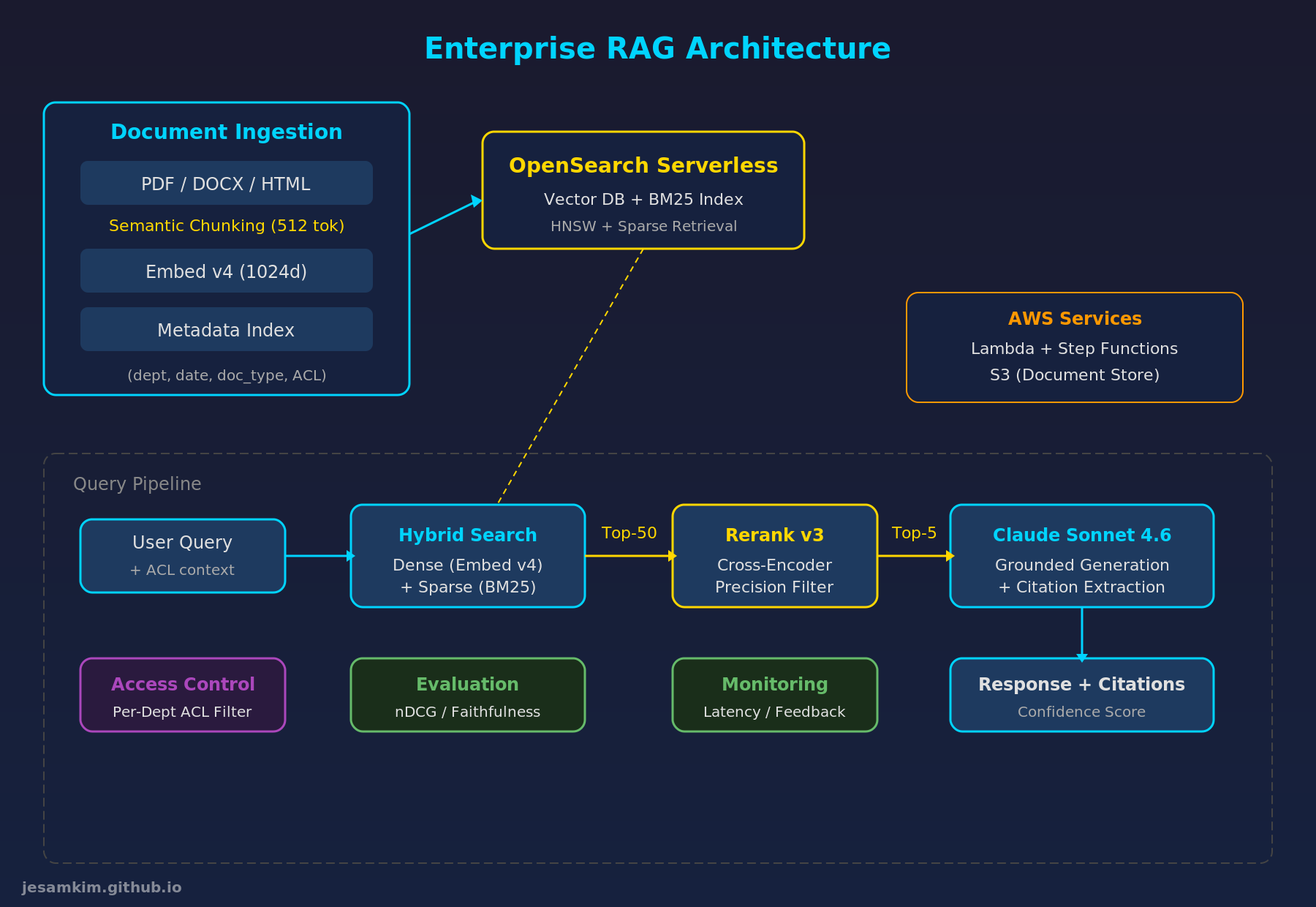 Enterprise RAG 아키텍처: 문서 수집부터 하이브리드 검색, Reranking, 답변 생성까지의 전체 흐름
Enterprise RAG 아키텍처: 문서 수집부터 하이브리드 검색, Reranking, 답변 생성까지의 전체 흐름
AWS 기반 구현
- 벡터 DB: Amazon OpenSearch Serverless (HNSW 인덱스 + BM25 동시 지원)
- 임베딩/리랭킹: Cohere Embed v4, Rerank v3 (Amazon Bedrock에서 호출 가능)
- LLM: Amazon Bedrock의 Claude Sonnet 4.6
- 오케스트레이션: AWS Lambda (쿼리 처리) + Step Functions (비동기 문서 수집)
- 문서 저장: Amazon S3 + 메타데이터 인덱스
2. Hallucination Detection Pipeline: 생성 전/중/후 3단계 방어
LLM은 자신이 틀렸다는 사실을 모릅니다. 그럴듯한 텍스트를 생성하는 것이 LLM의 본질이기 때문에, 사실이 아닌 내용도 매끄러운 문장으로 생성할 수 있습니다. 프로덕션 환경, 특히 금융이나 의료 같은 규제 산업에서는 hallucination이 곧 사고입니다.
Hallucination을 완전히 없앨 수는 없지만, 발생 확률을 줄이고 발생했을 때 탐지하는 파이프라인을 설계할 수 있습니다. 이 파이프라인은 세 단계로 나뉩니다.
생성 전 (Pre-Generation)
LLM에게 답변을 요청하기 전에, 검색된 문서의 품질부터 확인합니다.
- 쿼리 분류: 질의가 사실 확인형인지, 의견 요청형인지, 시간 의존적인지 구분합니다. 각 유형에 따라 검색 전략과 검증 수준이 달라집니다.
- 쿼리 재작성: 모호한 질의를 구체적으로 변환합니다. “최근 정책 변경 사항"보다 “2026년 1분기 인사 정책 변경"이 검색 품질을 높입니다.
- 검색 품질 확인: Top-5 문서의 관련성 점수가 기준 이하이면, 재검색하거나 쿼리를 재작성합니다. 품질 낮은 문서를 LLM에게 전달하면 hallucination 확률이 올라갑니다.
생성 중 (Generation)
LLM 호출 시점의 설정입니다.
- Grounded Generation: 시스템 프롬프트에 “제공된 출처의 정보만 사용하세요. 모든 주장에 출처를 표기하세요.“를 명시합니다.
- 낮은 Temperature: 사실 기반 응답에는 temperature 0.0~0.3을 사용합니다. 높은 temperature는 창의성을 높이지만 hallucination 확률도 함께 올립니다.
- 인라인 인용: 답변 생성 시 각 문장이 어떤 문서에서 비롯된 것인지 표시하도록 유도합니다.
생성 후 (Post-Generation)
가장 중요한 검증 단계입니다.
- NLI(Natural Language Inference) 검증: 별도의 분류 모델이 “답변의 각 문장이 검색된 문서에 의해 뒷받침되는가"를 판단합니다. entailment / contradiction / neutral 세 클래스로 분류합니다.
- 주장별 검증: 답변에서 개별 주장(claim)을 추출한 뒤, 각각을 출처 문서와 대조합니다. “매출이 20% 증가했다"는 주장이 있으면, 실제로 그 수치가 출처에 있는지 확인합니다.
- 신뢰도 스코어링: 검색 품질 + NLI 점수 + 주장 커버리지를 종합해서 0~1 사이의 신뢰도 점수를 산출합니다.
신뢰도 기반 라우팅
| 신뢰도 점수 | 동작 |
|---|---|
| 0.7 이상 | 답변 직접 전달 + 출처 인용 |
| 0.4 ~ 0.7 | 면책 조항 추가: “현재 확인 가능한 정보에 기반하면…” |
| 0.4 미만 | 답변 차단, 사람에게 에스컬레이션 |
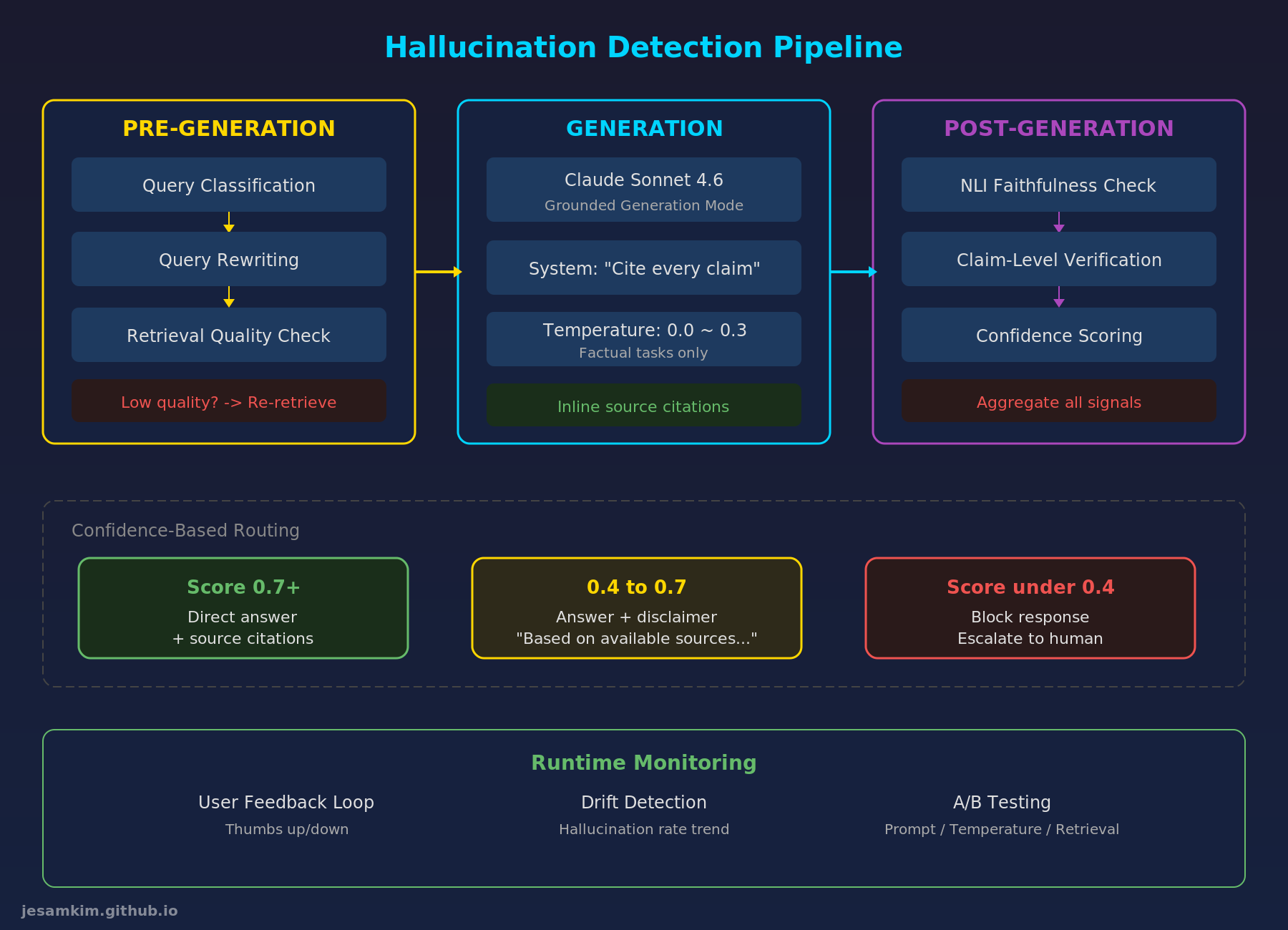 Hallucination Detection Pipeline: 생성 전/중/후 3단계와 신뢰도 기반 라우팅
Hallucination Detection Pipeline: 생성 전/중/후 3단계와 신뢰도 기반 라우팅
런타임 모니터링
프로덕션에서는 hallucination rate의 추세를 지속적으로 추적해야 합니다. 사용자 피드백(thumbs up/down), NLI 점수 분포의 변화, 에스컬레이션 비율을 대시보드로 모니터링합니다. hallucination rate가 상승 추세를 보이면 프롬프트, temperature, 검색 파라미터를 조정하는 A/B 테스트를 진행합니다.
AWS 기반 구현
- NLI 모델: Amazon SageMaker에 NLI 분류 모델 배포 (또는 Claude Sonnet 4.6을 judge 모델로 활용)
- 파이프라인 오케스트레이션: AWS Step Functions (조건 분기 + 병렬 실행)
- 모니터링: Amazon CloudWatch (커스텀 메트릭) + QuickSight (대시보드)
- 피드백 수집: API Gateway + DynamoDB (사용자 반응 저장)
3. Embedding 선택 및 최적화: 차원과 양자화의 트레이드오프
RAG 시스템의 검색 품질은 결국 embedding 모델에 의존합니다. 어떤 모델을 쓰고, 몇 차원으로 설정하고, 어떻게 양자화할 것인지에 따라 비용과 성능이 크게 달라집니다.
Bi-Encoder vs Cross-Encoder
두 가지 아키텍처의 차이를 명확히 이해해야 합니다.
| 항목 | Bi-Encoder (Embed v4) | Cross-Encoder (Rerank v3) |
|---|---|---|
| 입력 | 쿼리와 문서를 독립적으로 인코딩 | 쿼리+문서 쌍을 함께 인코딩 |
| 출력 | 벡터 (코사인 유사도로 비교) | 관련성 점수 (직접 비교) |
| 속도 | 빠름 (문서 벡터 사전 계산) | 느림 (매 쿼리마다 실시간 계산) |
| 정확도 | 상대적으로 낮음 (recall 우선) | 높음 (precision 우선) |
| 용도 | 1단계: 후보 검색 (Top-50) | 2단계: 재순위 (Top-5) |
프로덕션에서는 두 방식을 조합하는 것이 표준 패턴입니다. Bi-Encoder로 넓게 잡고, Cross-Encoder로 정밀하게 걸러냅니다.
차원별 트레이드오프
Embedding의 차원이 높을수록 더 많은 정보를 담을 수 있지만, 저장 공간과 연산 비용이 비례해서 늘어납니다. 실제 벤치마크 데이터를 보면 흥미로운 결과가 나옵니다.
| 모델 | 차원 | STS (유사도) | Retrieval (nDCG@10) |
|---|---|---|---|
| Cohere Embed v4 | 256 | 0.463 | 0.981 |
| Cohere Embed v4 | 512 | 0.411 | 0.987 |
| Cohere Embed v4 | 1024 | 0.449 | 0.981 |
| Cohere Embed v4 | 1536 | 0.485 | 0.987 |
검색(Retrieval) 목적이라면 512차원으로 이미 nDCG 0.987을 달성합니다. 1536차원과 동일한 수치입니다. 텍스트 유사도(STS) 측정에는 높은 차원이 유리하지만, RAG의 주요 용도인 검색에서는 512차원이면 충분합니다.
양자화 (Quantization)
임베딩 벡터의 정밀도를 낮추면 저장 공간을 절약할 수 있습니다.
| 타입 | 크기 (차원당) | 512d 벡터 크기 | 특징 |
|---|---|---|---|
| float32 | 4 bytes | 2,048 bytes | 최고 정밀도 |
| int8 | 1 byte | 512 bytes | 4배 절감, 검색 품질 거의 동일 |
| binary | 1 bit | 64 bytes | 32배 절감, 사전 필터링용 |
실무에서의 권장 조합: 512차원 + int8 양자화. 1536차원 float32 대비 약 6배의 저장 공간을 절감하면서 검색 품질은 거의 동일합니다. 100만 건 문서 기준으로 벡터 DB 월 비용이 약 $300에서 $50 수준으로 줄어듭니다.
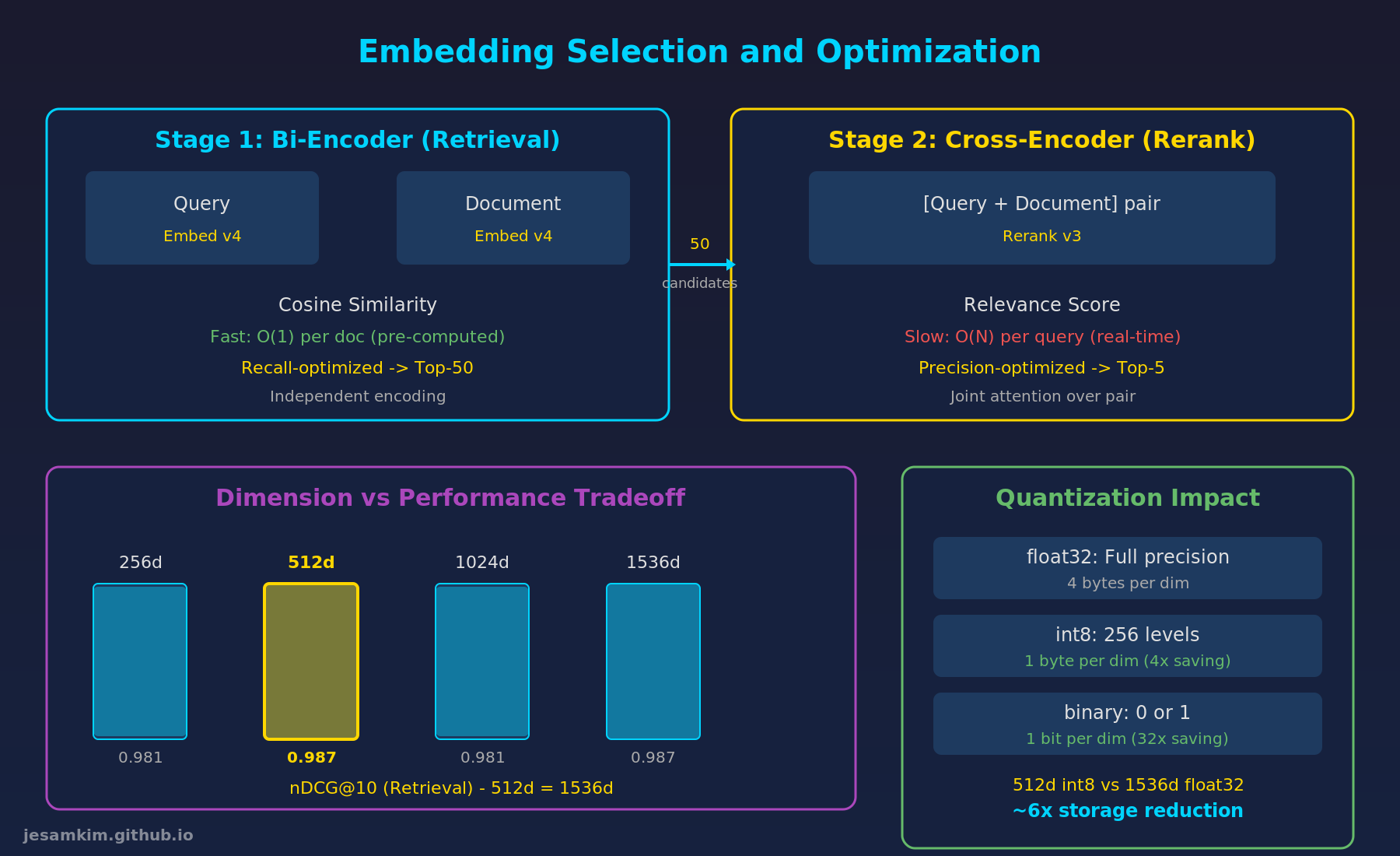 Embedding 최적화: Bi-Encoder와 Cross-Encoder의 2단계 구조, 차원별 성능 비교, 양자화 영향
Embedding 최적화: Bi-Encoder와 Cross-Encoder의 2단계 구조, 차원별 성능 비교, 양자화 영향
AWS 기반 구현
- 임베딩 생성: Cohere Embed v4 (Amazon Bedrock에서 호출, batch API로 96텍스트/요청 처리)
- 벡터 저장: Amazon OpenSearch Serverless (HNSW 인덱스, int8 양자화 지원)
- 리랭킹: Cohere Rerank v3 (Bedrock 또는 직접 API 호출)
- 비용 모니터링: AWS Cost Explorer로 임베딩 API 호출 비용과 벡터 DB 비용을 분리 추적
4. Tool Calling + Agent (MCP): LLM이 외부 시스템과 소통하는 방법
LLM이 텍스트 생성 이상의 일을 하려면, 외부 시스템을 호출할 수 있어야 합니다. CRM에서 고객 정보를 조회하거나, 데이터베이스에 쿼리를 실행하거나, 이메일을 보내는 작업이 여기에 해당합니다.
이런 도구 호출(Tool Calling)을 표준화한 것이 MCP(Model Context Protocol)입니다. Anthropic이 개발한 오픈 프로토콜로, LLM이 외부 도구를 발견하고, 인증하고, 호출하는 방식을 통일합니다. “AI를 위한 USB 포트"라고 비유할 수 있습니다. MCP를 지원하는 도구는 MCP를 지원하는 모든 LLM에서 사용할 수 있습니다.
도구 등록과 인증
MCP에서 도구는 다음과 같이 등록됩니다.
{
"name": "crm_lookup",
"description": "Look up customer information by name or ID",
"input_schema": {
"type": "object",
"properties": {
"query": {"type": "string"}
}
},
"authentication": "oauth2",
"permissions": ["read:contacts", "read:deals"]
}
여기서 핵심은 OAuth2를 통한 사용자 신원 전파입니다. 서비스 계정(service account)이 아닌, 실제 사용자의 토큰을 도구에 전달합니다. 이렇게 해야 각 도구가 “이 요청이 누구로부터 왔는지"를 알 수 있고, 사용자별 권한에 맞는 데이터만 반환합니다.
Human-in-the-Loop
모든 도구 호출을 자동으로 실행하면 위험합니다. 도구 호출을 두 가지로 나눕니다.
- 읽기 작업: 자동 실행 (CRM 조회, DB 쿼리, 문서 검색)
- 쓰기 작업: 사람 승인 필요 (이메일 발송, 데이터 수정, 레코드 삭제)
쓰기 작업은 “staged commit” 방식으로 처리합니다. LLM이 실행하려는 내용을 먼저 사용자에게 보여주고, 확인을 받은 후에 실제로 실행합니다. 금융 거래나 계약 관련 작업에서는 이 단계가 필수입니다.
Circuit Breaker
외부 도구가 불안정할 때를 대비한 방어 패턴입니다.
| 상황 | 동작 |
|---|---|
| 도구 호출 성공 | 결과를 LLM에 전달, 다음 단계 진행 |
| 단일 실패 | 1회 재시도 (30초 타임아웃) |
| 3회 연속 실패 | 도구 비활성화 + 알림 발송 |
| 쿨다운 후 | 도구 재활성화, 상태 모니터링 |
도구가 비활성화되면 LLM에게 “현재 CRM에 접근할 수 없습니다. 다른 방법을 시도하겠습니다.“라는 컨텍스트를 전달합니다. LLM이 대안 경로를 스스로 찾도록 유도하는 것이 Agent 설계의 포인트입니다.
감사 로그
규제 산업에서는 모든 도구 호출의 입출력을 기록해야 합니다. 감사 로그에는 다음 정보가 포함됩니다.
- 호출한 도구 이름
- 입력 파라미터
- 출력 결과 (또는 에러)
- 호출 시각 및 소요 시간
- 요청한 사용자 ID
- LLM이 도구를 호출한 이유 (planning context)
이 로그는 사후 감사에도 활용되지만, 디버깅과 시스템 개선에도 유용합니다. “왜 LLM이 이 도구를 호출했는가"를 추적할 수 있기 때문입니다.
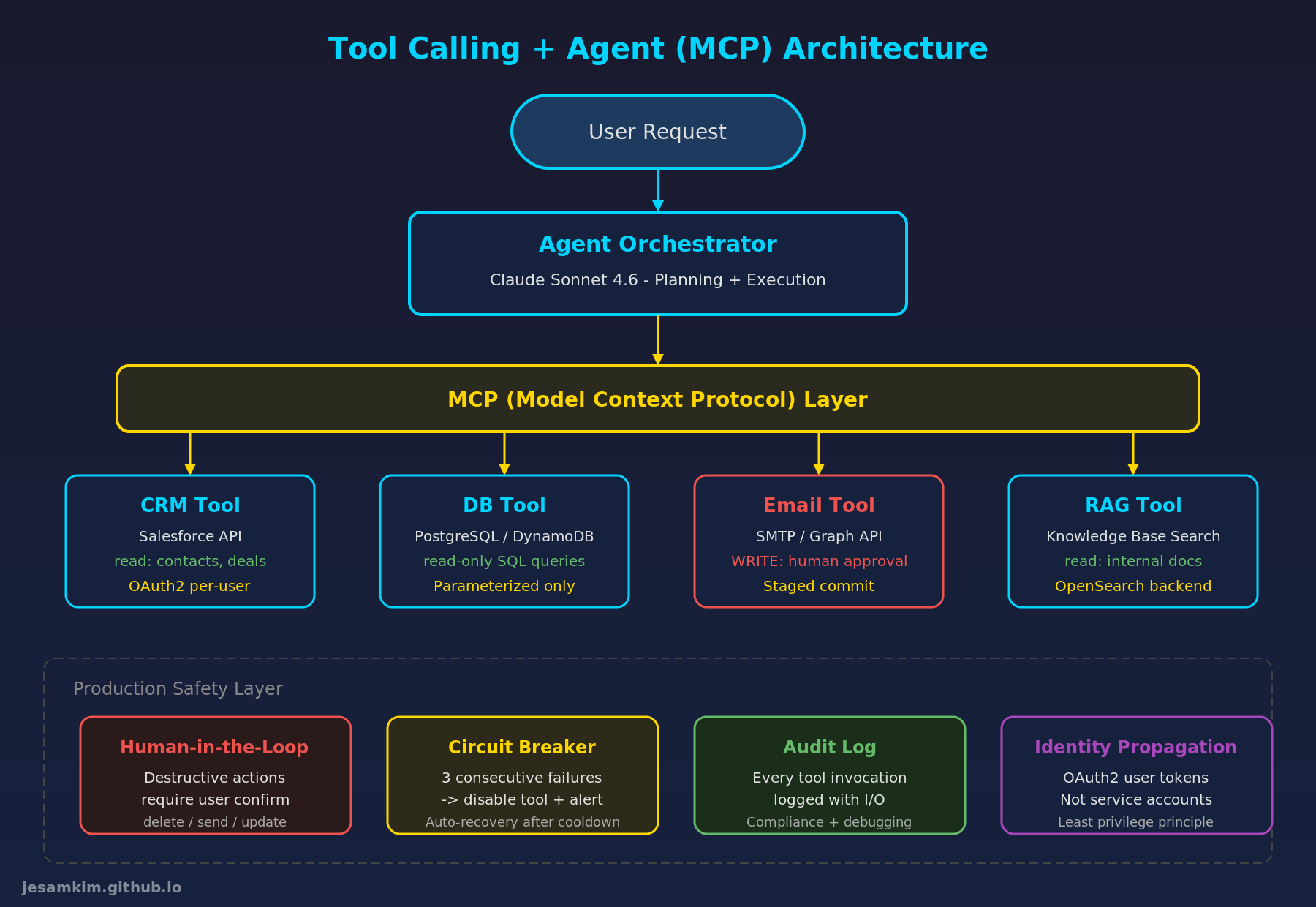 Tool Calling + Agent 아키텍처: MCP 프로토콜을 통한 도구 호출과 프로덕션 안전 장치
Tool Calling + Agent 아키텍처: MCP 프로토콜을 통한 도구 호출과 프로덕션 안전 장치
AWS 기반 구현
- Agent Orchestrator: Amazon Bedrock의 Claude Sonnet 4.6 (native tool use 지원)
- 도구 호스팅: AWS Lambda (각 도구를 독립 함수로 배포)
- 인증: Amazon Cognito (OAuth2 사용자 토큰 관리) + API Gateway (요청 라우팅)
- 감사 로그: Amazon CloudWatch Logs + S3 (장기 보관) + Athena (분석)
- Circuit Breaker: Step Functions의 상태 관리 또는 Lambda Powertools의 circuit breaker 패턴
5. 프로덕션 LLM 평가 체계: 배포 후가 진짜 시작입니다
LLM 시스템은 배포하고 나서부터 진짜 도전이 시작됩니다. 테스트 환경에서 잘 동작하던 시스템이 실제 사용자를 만나면 예상하지 못한 질의, 맥락 부족, edge case가 끊임없이 발생합니다. 이를 체계적으로 잡아내려면 단일 평가 방법이 아닌, 여러 계층을 조합한 평가 스택이 필요합니다.
5계층 평가 스택
| 계층 | 방법 | 메트릭 |
|---|---|---|
| 오프라인 | 테스트셋 평가 (500+ QA pairs) | nDCG, Faithfulness, BLEU |
| 배포 전 | LLM-as-Judge (Claude Sonnet 4.6이 응답 평가) | pass rate |
| 온라인 (명시적) | 사용자 피드백 (thumbs up/down) | satisfaction rate |
| 온라인 (암시적) | 복사, 후속 질문, 세션 이탈 추적 | engagement score |
| 주기적 | 전문가 리뷰 (주 100건 샘플링) | accuracy, safety |
각 계층은 서로 다른 시점과 관점에서 시스템을 평가합니다. 오프라인 평가로 기본 품질을 보장하고, LLM-as-Judge로 배포 전 게이트를 만들고, 온라인 신호로 실사용 품질을 추적하고, 전문가 리뷰로 자동화가 놓치는 뉘앙스를 잡습니다.
LLM-as-Judge 구현
프로덕션에서 가장 비용 대비 효과가 높은 방법입니다. Evaluator 모델이 생성된 응답을 세 가지 축으로 평가합니다.
Evaluator Prompt:
당신은 전문 평가자입니다. 다음 응답을 평가하세요:
1. Faithfulness (0-5): 출처 문서의 정보만 사용했는가?
2. Relevance (0-5): 사용자 질문에 적절히 답했는가?
3. Completeness (0-5): 모든 측면을 다루었는가?
점수와 근거를 제시하세요.
LLM-as-Judge는 전문가 리뷰 대비 100배 이상 빠르고 비용도 낮습니다. 매 배포 전에 테스트셋 전체를 자동 평가하고, pass rate(3점 이상 비율)가 기준 미달이면 배포를 차단하는 게이트로 활용할 수 있습니다.
다만 한계도 분명합니다. Evaluator 모델 자체의 편향이 존재하고, 미묘한 맥락이나 도메인 전문성이 필요한 판단에서는 정확도가 떨어집니다. 이 때문에 주기적 전문가 리뷰와 병행하는 것이 필수입니다.
암시적 신호 수집
사용자가 직접 피드백 버튼을 누르는 비율은 낮습니다. 대신 행동 데이터에서 품질 신호를 추출할 수 있습니다.
- 복사 행동: 답변 텍스트를 복사하면 유용했다는 신호
- 후속 질문: 같은 주제로 바로 재질문하면 답변이 불충분했다는 신호
- 세션 이탈: 답변 직후 이탈하면 불만족 가능성
이런 신호들을 종합하면 명시적 피드백만으로는 파악할 수 없는 품질 추세를 잡을 수 있습니다.
 프로덕션 LLM 평가 스택: 오프라인부터 전문가 리뷰까지 5계층 구조
프로덕션 LLM 평가 스택: 오프라인부터 전문가 리뷰까지 5계층 구조
AWS 기반 구현
- LLM-as-Judge: Amazon Bedrock의 Claude Sonnet 4.6 (평가 프롬프트로 호출)
- 피드백 수집: API Gateway + DynamoDB (thumbs up/down 저장)
- 암시적 신호: CloudWatch Custom Metrics (복사/후속질문/이탈 이벤트)
- 대시보드: Amazon QuickSight (계층별 메트릭 시각화)
- 테스트셋 관리: S3 (골든 데이터셋) + Lambda (주기적 자동 평가 실행)
- 전문가 리뷰: DynamoDB에서 주간 100건 랜덤 샘플링 + 리뷰 인터페이스
5가지 패턴의 조합
이 5가지 패턴은 독립적으로 적용할 수도 있지만, 실제 Enterprise LLM 시스템에서는 대부분 함께 사용됩니다.
한 금융회사의 내부 지식 검색 시스템을 예로 들면:
- 사용자 질의가 들어오면 Enterprise RAG로 관련 문서를 검색합니다.
- 검색 결과를 Embedding 최적화(512d int8)로 효율적으로 관리하면서도 품질을 유지합니다.
- LLM이 답변을 생성하면 Hallucination Detection Pipeline이 신뢰도를 검증합니다.
- 추가 정보가 필요하면 Tool Calling으로 내부 DB나 CRM을 조회합니다.
- 전체 시스템의 품질을 프로덕션 평가 체계가 5계층으로 지속 모니터링합니다.
각 패턴을 단독으로 구현하면 효과가 제한적입니다. 검색 품질이 좋아도 hallucination 검증이 없으면 잘못된 답변이 사용자에게 전달될 수 있고, 도구 호출이 가능해도 감사 로그가 없으면 규제 요건을 충족하지 못합니다. 모든 것이 잘 동작하더라도, 평가 체계 없이는 시스템이 시간이 지나면서 품질이 떨어지는 것을 알아차리지 못합니다.
프로덕션 LLM 시스템의 품질은 결국 이런 패턴들이 얼마나 촘촘하게 맞물려 있느냐에 달려 있습니다.
References
- Lewis, P., et al. “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.” NeurIPS 2020. https://arxiv.org/abs/2005.11401
- Anthropic. “Model Context Protocol (MCP) Specification.” 2024. https://modelcontextprotocol.io/
- Amazon Web Services. “Amazon OpenSearch Serverless.” https://docs.aws.amazon.com/opensearch-service/latest/developerguide/serverless.html
- Amazon Web Services. “Amazon Bedrock User Guide.” https://docs.aws.amazon.com/bedrock/latest/userguide/
- Cohere. “Embed v4 API Reference.” https://docs.cohere.com/reference/embed
- Cohere. “Rerank v3 API Reference.” https://docs.cohere.com/reference/rerank
- Nystrom, M. “Circuit Breaker Pattern.” Microsoft Azure Architecture Center. https://learn.microsoft.com/en-us/azure/architecture/patterns/circuit-breaker