
1. 왜 지금 Physical AI인가
ChatGPT가 세상에 나온 지 3년이 조금 넘었습니다. 그 사이 LLM은 코딩, 번역, 요약 등 텍스트 기반 작업에서 인간 수준의 성능을 보여주었습니다. 하지만 한 가지 분명한 한계가 있습니다. LLM은 말하는 AI이지, 행동하는 AI가 아닙니다.
물건을 집거나, 문을 열거나, 공장 라인에서 부품을 조립하는 일은 텍스트 생성과는 완전히 다른 문제입니다. 물리 세계에서는 중력, 마찰, 충돌 같은 물리 법칙을 실시간으로 고려해야 하고, 센서 노이즈와 예측 불가능한 환경 변화에도 대응해야 합니다. 이 영역을 다루는 것이 바로 Physical AI입니다.
2026년 3월, 이 분야에 대한 관심이 그 어느 때보다 뜨겁습니다. 이번 주 열리고 있는 NVIDIA GTC 2026(3월 17-20일)에서는 GR00T N1.7, Cosmos 3, Newton이 한꺼번에 공개되었습니다. Google DeepMind는 2025년 3월에 Gemini 2.0 기반의 Gemini Robotics를 발표했고, Yann LeCun은 Meta를 떠나 AMI Labs를 10억 달러 시드로 설립한다고 밝혔습니다. Jensen Huang의 표현을 빌리자면, Physical AI는 “다음 AI 프론티어"입니다.
이 글에서는 Physical AI를 구성하는 세 가지 기둥인 VLM, VLA, World Model을 하나씩 풀어보겠습니다. ML은 알지만 로보틱스는 생소한 분들을 위해, 가능한 한 직관적으로 설명하겠습니다.
2. VLM (Vision-Language Model) - 보고 이해하는 AI
VLM이란
Vision-Language Model은 이미지와 텍스트를 함께 처리하는 모델입니다. 사진을 보여주면 “이것은 빨간 사과입니다"라고 설명하거나, “이 사진에서 위험한 상황이 있나요?“라는 질문에 답할 수 있습니다.
VLM이 등장하기 전에는 Vision과 Language가 완전히 별개의 영역이었습니다. 이미지 분류는 ResNet, 텍스트 이해는 BERT가 담당했습니다. 이 둘을 하나의 모델로 묶는 것이 VLM의 기본 아이디어입니다.
진화 과정
CLIP (OpenAI, 2021)이 출발점입니다. 4억 개의 이미지-텍스트 쌍으로 Contrastive Learning을 수행해서, 이미지와 텍스트를 같은 벡터 공간에 매핑하는 방법을 보여주었습니다. 학습 데이터에 없던 카테고리도 분류할 수 있는 Zero-shot 능력이 큰 반향을 일으켰습니다.
2023년에는 두 가지 중요한 발전이 있었습니다. LLaVA(Large Language and Vision Assistant)는 CLIP Vision Encoder에 LLaMA를 연결해서, 이미지에 대한 자유로운 대화가 가능한 모델을 오픈소스로 공개했습니다. 같은 해 GPT-4V는 대규모 상용 VLM이 실제 서비스에서 어느 정도의 성능을 낼 수 있는지 보여주었습니다. 이미지 속 텍스트 인식, 차트 해석, 공간 추론까지 가능해졌습니다.
2024년부터는 Gemini 1.5가 긴 비디오까지 이해하는 멀티모달 능력을 선보이면서, VLM의 활용 범위가 정적 이미지를 넘어 동영상과 실시간 스트림으로 확장되고 있습니다.
VLM에 대한 상세한 기술 설명은 Hugging Face VLM 블로그에서 잘 정리하고 있습니다.
아키텍처 구조
대부분의 VLM은 세 가지 구성요소로 이루어집니다:
- Vision Encoder - 이미지를 시각 토큰(visual tokens)으로 변환합니다. ViT(Vision Transformer)를 주로 사용합니다
- Projector - 시각 토큰을 LLM이 이해할 수 있는 임베딩 공간으로 매핑합니다. MLP나 Cross-Attention 레이어를 사용합니다
- LLM Backbone - 시각 토큰과 텍스트 토큰을 함께 처리해서 텍스트 응답을 생성합니다
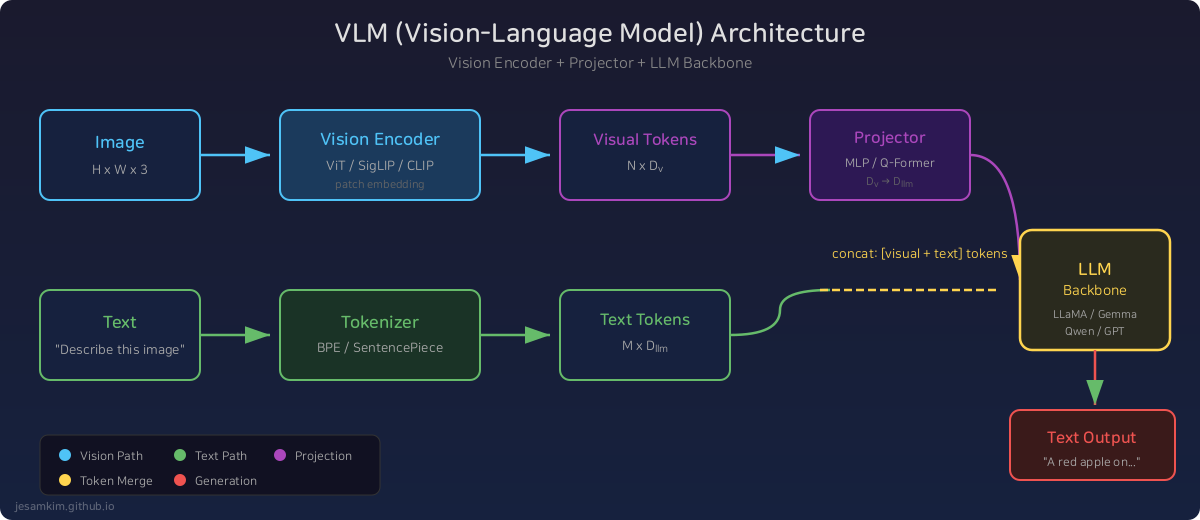
Vision Encoder와 LLM 사이의 Projector가 중요합니다. Vision Encoder의 출력 차원과 LLM의 입력 차원이 다르기 때문에, 이 격차를 연결하는 역할을 합니다. LLaVA는 단순한 Linear Projection으로도 괜찮은 성능을 보여주었고, 이후 모델들은 Q-Former(BLIP-2), Cross-Attention, Perceiver Resampler 같은 더 정교한 구조를 사용합니다.
VLM의 한계
VLM은 이미지를 보고 이해할 수 있지만, 물리 세계에서 행동할 수는 없습니다. “저 컵을 집어"라는 명령을 이해할 수는 있어도, 실제로 로봇 팔을 움직여 컵을 집는 동작을 생성하지 못합니다. 출력이 텍스트로 제한되기 때문입니다.
이 한계를 넘기 위해 등장한 것이 VLA입니다.
3. VLA (Vision-Language-Action Model) - 보고, 이해하고, 행동하는 AI
VLM에서 VLA로
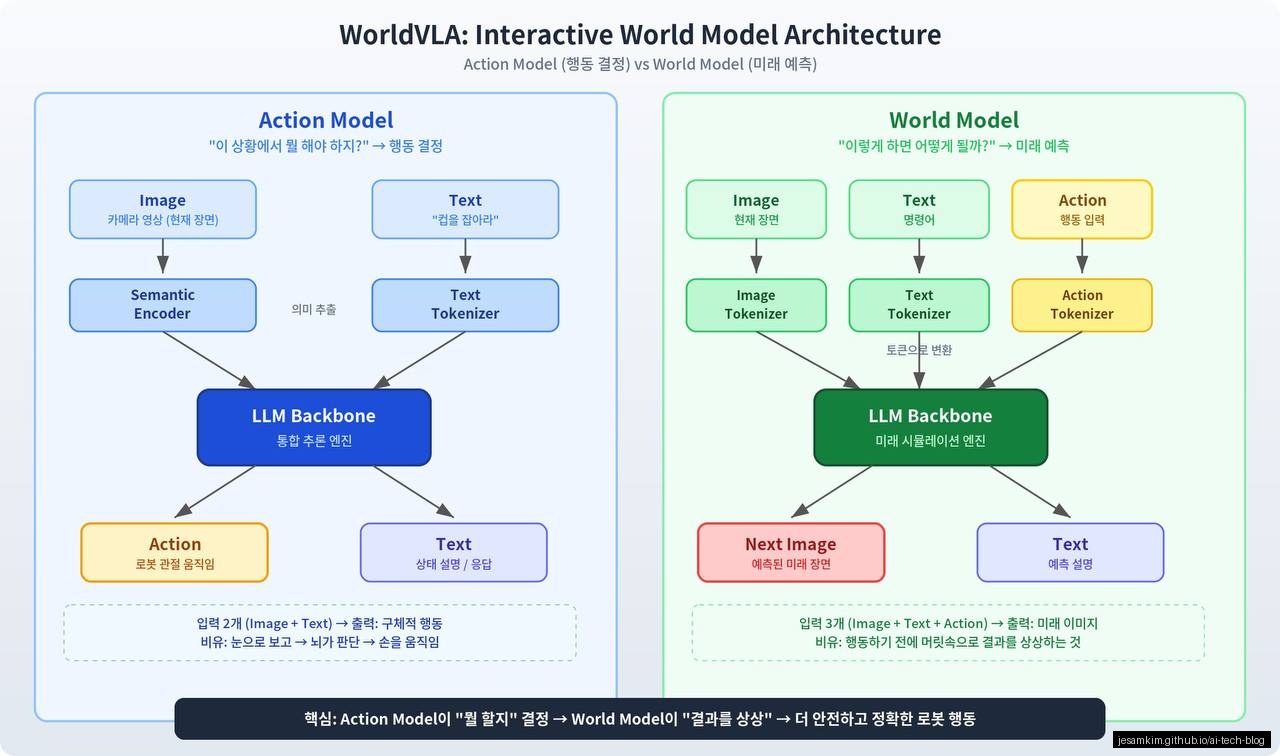
VLA의 아이디어는 단순합니다. VLM의 출력에 Action을 추가하는 것입니다. 텍스트 대신(혹은 텍스트와 함께) 로봇이 실행할 수 있는 동작 명령을 출력합니다.
구체적으로 말하면, VLA는 다음과 같은 입출력 구조를 가집니다:
- 입력: 카메라 이미지 + 자연어 명령 (예: “빨간 컵을 왼쪽으로 옮겨줘”)
- 출력: 로봇 관절 각도, 그리퍼 열림/닫힘, 이동 속도 등의 Action 벡터
텍스트 출력 하나를 Action 벡터로 바꿨을 뿐인데, AI가 물리적 행동으로 세상에 개입할 수 있게 됩니다.
Action을 출력하는 방식은 크게 두 가지입니다. 하나는 로봇 동작을 이산 토큰으로 변환해서 LLM의 텍스트 생성 메커니즘을 그대로 활용하는 것이고(RT-2 방식), 다른 하나는 연속 Action 분포를 직접 생성하는 것입니다(pi0의 Flow Matching 방식). 전자는 기존 LLM 인프라를 재활용할 수 있다는 장점이 있고, 후자는 부드럽고 정밀한 동작 생성에 유리합니다.
핵심 모델 타임라인
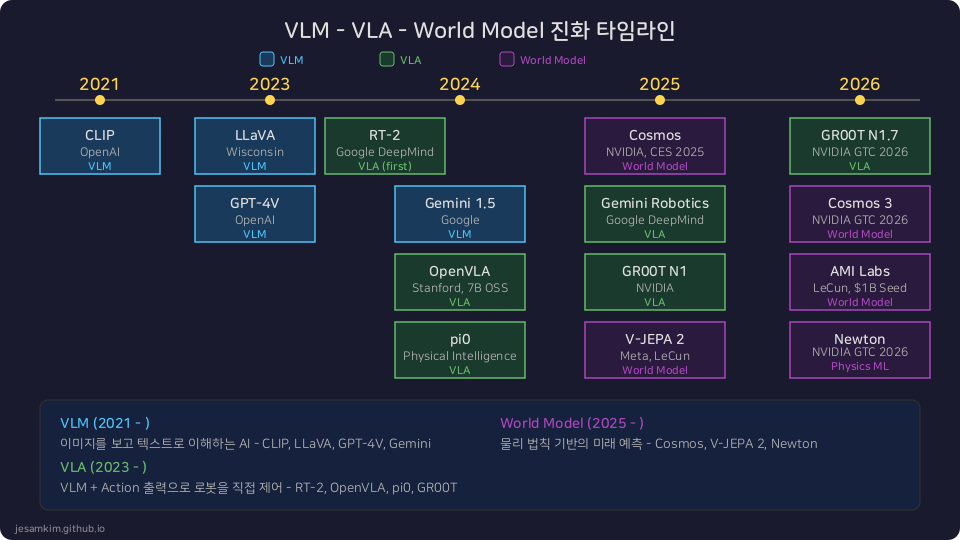
RT-2 (Google DeepMind, 2023) - 대규모 VLA의 시작
RT-2는 VLM을 로봇 제어에 직접 사용할 수 있음을 처음으로 대규모로 증명한 모델입니다. PaLM-E와 PaLI-X를 기반으로, 로봇 동작을 256개의 이산 토큰으로 인코딩했습니다. “RT-2-PaLI-X-55B” 버전은 55B 파라미터 규모로, 웹에서 학습한 시각-언어 지식이 로봇 행동으로 전이(transfer)될 수 있다는 것을 보여주었습니다.
예를 들어, “바나나처럼 생긴 물건을 가져와"라는 요청에 노란 바나나 모형을 집는 것이 가능했는데, 이는 웹 데이터에서 학습한 “바나나=노란색, 길쭉한 모양"이라는 지식이 로봇 행동에 연결되었기 때문입니다.
OpenVLA (Stanford, 2024) - 오픈소스 7B VLA
OpenVLA는 Prismatic VLM(7B)을 기반으로 한 오픈소스 VLA입니다. Open X-Embodiment 데이터셋에서 970K 에피소드로 학습했으며, RT-2보다 훨씬 작은 모델로도 경쟁력 있는 성능을 보였습니다. 오픈소스라는 점에서 학계와 스타트업의 VLA 연구 접근성을 크게 높였습니다.
특히 주목할 점은 Fine-tuning 효율입니다. 새로운 로봇이나 작업에 적용할 때, 전체 모델을 재학습하지 않고 LoRA 같은 기법으로 빠르게 적응시킬 수 있습니다.
pi0 (Physical Intelligence, 2024) - Flow Matching 기반
pi0은 Pre-trained VLM 위에 Action Expert를 붙이되, Flow Matching이라는 생성 모델 기법으로 Action을 출력합니다. Diffusion Model과 비슷하지만, 노이즈에서 Action으로의 변환을 ODE(Ordinary Differential Equation)로 모델링한다는 점이 다릅니다. 이산 토큰 대신 연속적인 Action 분포를 직접 학습한다는 것이 차별화 포인트입니다.
옷 개기, 식탁 정리 같은 접촉이 많은(contact-rich) 작업에서 좋은 성능을 보였습니다. 후속 모델인 pi0.5는 웹 데이터까지 활용한 VLM Pre-training을 더 적극적으로 수행하고, 다양한 로봇 플랫폼에 걸친 일반화 능력을 강화했습니다.
Gemini Robotics (Google DeepMind, 2025.03)
Gemini Robotics는 Gemini 2.0을 기반으로 한 VLA입니다. 두 가지 버전이 있습니다:
- Gemini Robotics-ER (Embodied Reasoning): 공간 추론, 물체 탐지, 궤적 계획 등을 수행하는 VLM입니다. 직접 로봇을 제어하지는 않고, 상위 수준의 계획을 생성합니다. “냉장고에서 물을 꺼내와"라는 지시를 “냉장고 앞으로 이동 → 문 열기 → 물병 잡기 → 문 닫기"로 분해하는 역할입니다
- Gemini Robotics: 실제 로봇 동작을 출력하는 VLA입니다. 다양한 로봇 형태(manipulator, mobile, humanoid)에 일반화할 수 있도록 설계했고, 소수의 데모만으로 새로운 작업에 적응하는 few-shot 능력을 강조합니다
같이 공개된 ASIMOV 벤치마크도 눈여겨볼 만합니다. 기존 벤치마크가 “성공/실패"만 측정했다면, ASIMOV는 안전한 행동인지, 물리적 제약을 위반하지 않는지까지 평가합니다.
GR00T N1에서 N1.7 (NVIDIA, 2025-2026)
NVIDIA의 GR00T N1은 휴머노이드 로봇에 특화된 VLA 모델입니다. Dual-system 아키텍처를 채택했는데, 이는 인간의 인지 체계에서 영감을 받은 설계입니다:
- System 2 (느린 사고): 대형 VLM이 자연어 명령을 이해하고, 작업 계획을 세우고, 상황을 판단합니다. 매 프레임마다 실행되지는 않습니다
- System 1 (빠른 반응): 작고 빠른 Action Model이 실시간(수십 Hz)으로 모터 제어 신호를 출력합니다. System 2가 내려준 계획을 기반으로, 현재 센서 데이터에 맞는 저수준 동작을 생성합니다
이번 GTC 2026에서 발표된 GR00T N1.7은 상용화 가능한 수준(commercially viable)에 도달했다고 NVIDIA가 밝혔습니다. 기존 N1 대비 조작 성공률, 새 환경 적응 속도, 안전성 모두에서 개선이 있었습니다.
아키텍처 분류: End-to-End vs Dual-System
VLA 아키텍처는 크게 두 가지로 나눌 수 있습니다:
Single End-to-End 방식은 이미지와 언어 입력을 받아 한 번에 Action을 출력합니다. RT-2, OpenVLA, pi0이 이 방식입니다. 학습이 단순하고, 모델 하나로 전체 파이프라인을 처리할 수 있다는 장점이 있습니다. 반면, 모델이 커질수록 추론 지연 시간(latency)이 늘어나서, 실시간 제어에는 한계가 있습니다.
Dual-System 방식은 상위 수준의 추론 모듈(보통 큰 VLM)과 하위 수준의 행동 생성 모듈(작고 빠른 모델)을 분리합니다. GR00T N1이 대표적입니다. 실시간 반응 속도가 필요한 로봇 제어에서는 이 방식이 실용적입니다. 큰 VLM이 200ms 걸리는 추론을 매 프레임(50Hz = 20ms)마다 돌릴 수는 없으니까요.
VLA 분야의 전체 흐름에 대한 체계적인 정리는 VLA Survey에서 확인할 수 있습니다.
4. World Model - 미래를 상상하는 AI
물리 세계의 내부 시뮬레이터
사람은 컵을 테이블 끝에 놓으면 떨어질 것을 “상상"할 수 있습니다. 직접 떨어뜨려보지 않아도, 머릿속에서 물리 법칙을 시뮬레이션하기 때문입니다. World Model은 AI에게 이 능력을 부여하려는 시도입니다.
World Model은 현재 상태(state)와 행동(action)을 입력으로 받아, 미래 상태를 예측합니다. 로봇이 어떤 행동을 하기 전에 “이 행동을 하면 어떤 결과가 올까?“를 시뮬레이션할 수 있게 해줍니다. 이는 두 가지 면에서 가치가 있습니다:
- 안전성 - 위험한 행동을 실행 전에 걸러낼 수 있습니다. “이 방향으로 팔을 뻗으면 사람과 충돌한다"는 예측이 가능해집니다
- 데이터 효율 - 실제 로봇을 돌리지 않고도 시뮬레이션된 경험으로 학습할 수 있습니다. 로봇 데이터는 텍스트나 이미지에 비해 수집 비용이 훨씬 높기 때문에, 이 점은 실질적으로 매우 중요합니다
LeCun의 JEPA와 AMI Labs
Yann LeCun은 수년간 World Model의 중요성을 강조해왔습니다. 그가 제안한 JEPA(Joint Embedding Predictive Architecture)는 기존 생성 모델과 다른 접근을 취합니다. 픽셀 수준의 예측 대신, 추상적인 표현 공간(representation space)에서 미래를 예측합니다.
왜 픽셀 예측이 문제일까요? 미래 비디오의 모든 픽셀을 정확하게 생성하려면, 무의미한 디테일(나뭇잎의 정확한 위치, 물결의 미세한 패턴 등)까지 맞춰야 합니다. JEPA는 이런 불필요한 정보를 버리고, 의미 있는 추상 표현만 예측합니다. LeCun 식으로 말하면, “세상의 모든 디테일을 재구성하지 않고도 세상을 이해할 수 있다"는 겁니다.
Meta에서 발표한 V-JEPA 2는 비디오를 입력으로 받아, 마스킹된 프레임의 표현을 예측하는 방식으로 물리 세계에 대한 이해를 학습합니다. 별도의 Action 출력은 없지만, 물리적 상호작용에 대한 이해가 내재화되어 있습니다.
2026년 3월, LeCun은 Meta에서 나와 AMI Labs(Augmented Machine Intelligence)를 설립했습니다. 10억 달러 규모의 시드 투자를 받았으며, “인간 수준의 세계 모델"을 만드는 것이 목표입니다. World Model이 학술 연구에서 산업 투자로 넘어가는 시점이라고 볼 수 있습니다.
NVIDIA Cosmos
NVIDIA는 2025년 1월 CES에서 Cosmos를 처음 발표했습니다. Cosmos는 물리 세계를 이해하는 World Foundation Model로, 비디오 생성과 물리 시뮬레이션을 결합한 모델입니다. 텍스트나 이미지 조건을 기반으로 물리적으로 그럴듯한(physically plausible) 미래 비디오를 생성할 수 있습니다.
이후 Predict 2.5를 거쳐, GTC 2026에서 Cosmos 3가 공개되었습니다. 기존 버전 대비 물리적 정확도가 크게 향상되었습니다. 구체적으로는 강체 역학(rigid body dynamics), 유체 시뮬레이션, 접촉/마찰 모델링에서 눈에 띄는 개선이 있었습니다.
Cosmos 3가 NVIDIA 로보틱스 스택에서 맡는 역할은 명확합니다. Isaac Sim에서 기본 시뮬레이션 환경을 구축하고, Cosmos 3로 다양한 시나리오 변형(조명 변화, 물체 위치 변경, 방해 요소 추가 등)을 대량 생성해서, GR00T이 학습할 합성 데이터를 만드는 파이프라인입니다.
같은 자리에서 공개된 Newton은 물리 법칙 자체를 학습하는 Physics ML 모델입니다. Cosmos와 상호보완적인 관계인데, Cosmos가 시각적 미래 예측(다음 프레임이 어떻게 보일까)에 집중한다면, Newton은 힘, 토크, 접촉 역학 같은 물리량 예측(어떤 힘이 작용할까)에 집중합니다.
5. Physical AI = VLM + VLA + World Model
전체 스택 통합
지금까지 살펴본 세 가지 기둥을 합치면, Physical AI의 전체 그림이 완성됩니다:
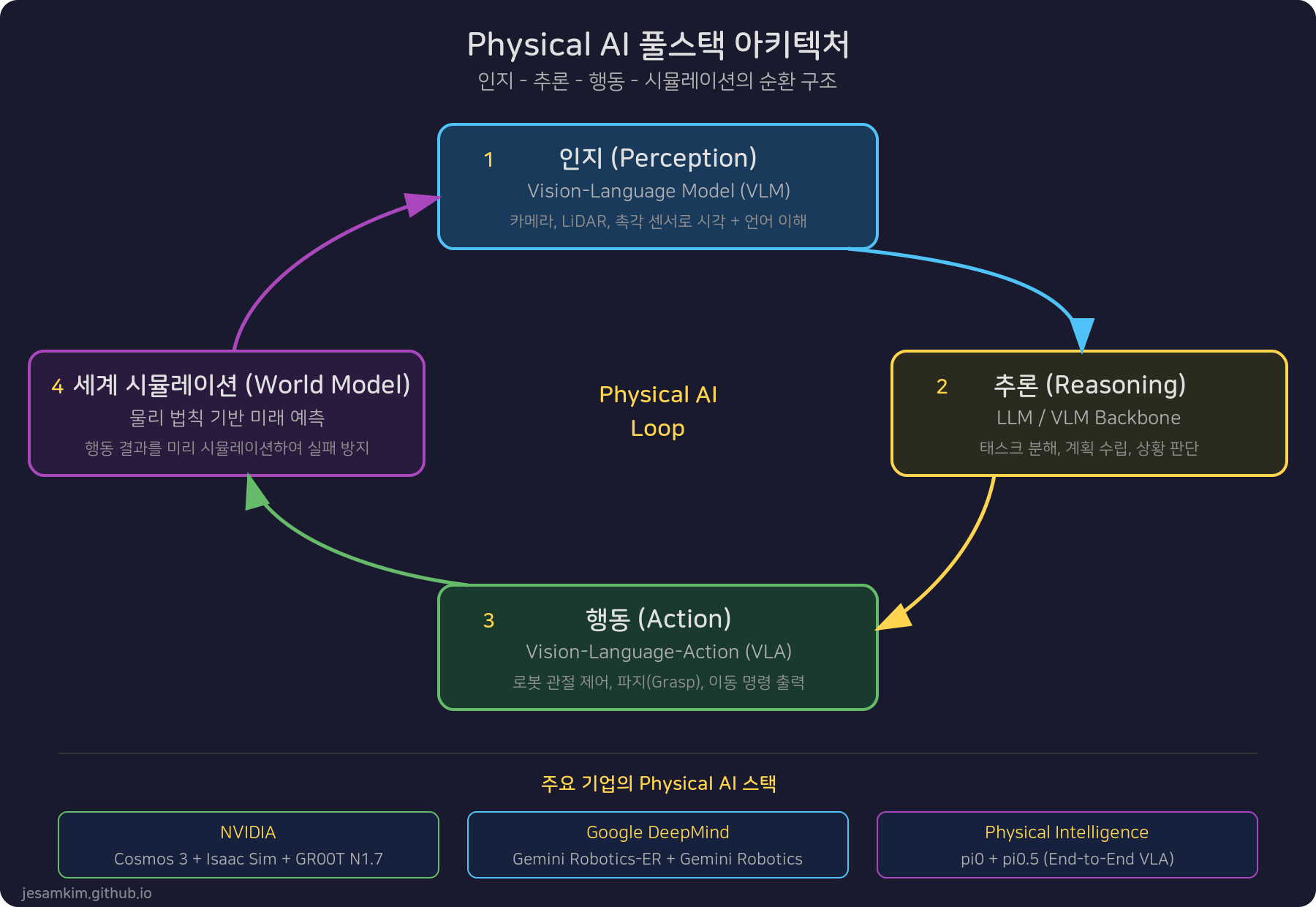
이 순환 구조를 정리하면 다음과 같습니다:
- 인지 (Perception) - VLM이 카메라, LiDAR, 촉각 센서 데이터를 처리해서 환경을 이해합니다
- 추론 (Reasoning) - LLM/VLM Backbone이 상황을 판단하고, 태스크를 분해하고, 계획을 세웁니다
- 행동 (Action) - VLA가 구체적인 로봇 동작(관절 각도, 그리퍼 제어 등)을 출력합니다
- 세계 시뮬레이션 (World Simulation) - World Model이 행동 결과를 미리 예측하고, 위험한 행동을 사전에 필터링합니다
이 네 단계가 반복 순환하면서, 로봇은 실시간으로 환경에 적응하고 새로운 상황에도 대응할 수 있게 됩니다.
주요 기업별 Physical AI 스택
NVIDIA: 가장 완성된 풀스택
NVIDIA는 Physical AI에 필요한 거의 모든 레이어를 자체 구축하고 있습니다:
| 레이어 | 제품 | 역할 |
|---|---|---|
| World Model | Cosmos 3 | 물리 기반 비디오 생성, 시나리오 시뮬레이션 |
| 시뮬레이션 | Isaac Sim / Omniverse | 디지털 트윈, 합성 데이터 생성 |
| VLA | GR00T N1.7 | 휴머노이드 로봇 제어 |
| Physics ML | Newton | 물리 법칙 학습, 힘/토크 예측 |
| 하드웨어 | Jetson Thor | 로봇 온보드 AI 칩 |
이 스택의 강점은 시뮬레이션에서 현실까지의 파이프라인이 하나로 연결된다는 점입니다. Isaac Sim에서 합성 데이터를 만들고, Cosmos로 다양한 변형을 생성하고, GR00T으로 정책을 학습한 뒤, Jetson Thor에 배포하는 End-to-End 흐름이 가능합니다. 로보틱스 스타트업 입장에서는 이 스택 위에서 자사 로봇만 올리면 되니까, 진입 장벽이 낮아집니다.
Google DeepMind: Gemini 기반 이원 체계
Google DeepMind는 Gemini를 기반으로 두 가지 모델을 운영합니다:
- Gemini Robotics-ER: 고수준 추론, 공간 이해, 계획 수립을 담당하는 VLM
- Gemini Robotics: 실제 로봇 동작을 생성하는 VLA
Gemini의 강력한 멀티모달 이해 능력을 로보틱스에 전이한다는 전략입니다. 특히 few-shot 일반화 능력을 강조해서, 적은 데이터로도 새로운 로봇과 작업에 적응할 수 있는 것이 차별점입니다. NVIDIA가 시뮬레이션 기반이라면, Google은 Foundation Model의 일반화 능력에 베팅하는 셈입니다.
Physical Intelligence: End-to-End 단순함
Physical Intelligence(pi)는 가장 단순하면서도 직접적인 접근을 취합니다. pi0과 pi0.5는 VLM 위에 Action Expert를 붙인 End-to-End 구조로, 별도의 World Model이나 시뮬레이션 없이 실제 로봇 데이터로 직접 학습합니다.
접촉이 많고 변형이 많은 작업(빨래 개기, 식탁 정리 등)에서 인상적인 결과를 보여주고 있습니다. “시뮬레이션이 완벽해질 때까지 기다리기보다, 현실 데이터로 바로 학습하자"는 실용적 철학입니다.
6. 실제 적용과 전망
현재 적용 분야
휴머노이드 로봇은 가장 활발한 적용 분야입니다. Figure AI는 Figure 02에 OpenAI의 멀티모달 모델을 탑재해서 물류 창고 작업을 수행합니다. 1X Technologies의 NEO는 가정용 로봇을 목표로 합니다. Agility Robotics의 Digit은 이미 Amazon 물류센터에서 시범 운영 중입니다. 이 회사들 모두 NVIDIA의 GR00T이나 자체 VLA를 탑재하는 방향으로 가고 있습니다.
자율주행 분야에서도 World Model의 활용이 확대되고 있습니다. Waymo는 자체 시뮬레이션 환경에서 물리 기반 시나리오 생성을 적극 활용하고 있고, NVIDIA Cosmos를 자율주행 개발에 도입하는 파트너사들이 늘어나고 있습니다.
의료 로봇도 주목할 분야입니다. LEM Surgical 같은 회사는 수술 로봇에 VLA 기반의 정밀 제어를 적용하고 있습니다. 이 영역은 안전성 요구사항이 높아서, World Model의 사전 시뮬레이션과 안전성 검증이 필수적입니다.
GTC 2026에서 나온 것들
이번 주 열리고 있는 GTC 2026(3월 17-20일)은 Physical AI의 현 수준을 가늠할 수 있는 자리입니다:
- GR00T N1.7: 상용화 가능 수준의 휴머노이드 VLA. Dual-system 아키텍처 고도화
- Cosmos 3: 물리 정확도가 대폭 향상된 World Foundation Model
- Newton: 물리 법칙을 직접 학습하는 Physics ML 모델. Cosmos와 상호보완
- Jetson Thor: 로봇 온보드 추론을 위한 차세대 SoC
NVIDIA가 GPU 회사에서 “로봇 AI 인프라 회사"로 전환하고 있다는 신호가 점점 뚜렷해지고 있습니다. Jensen Huang이 GTC 키노트에서 로보틱스에 할애한 시간만 봐도 이 방향성은 분명합니다.
남은 과제
Physical AI가 실험실을 넘어 실제 산업 현장에 배포되려면, 풀어야 할 문제들이 있습니다.
Sim-to-Real Gap은 가장 오래된 문제입니다. 시뮬레이션에서 잘 작동하는 정책이 현실에서는 실패하는 경우가 여전히 많습니다. 조명, 질감, 물체의 미세한 물리적 특성 차이가 성능을 크게 떨어뜨립니다. Domain Randomization, System Identification, Sim-to-Real Transfer 같은 기법이 발전하고 있지만, 완전한 해결은 아직 멀었습니다. NVIDIA가 Cosmos와 Newton에 투자하는 이유이기도 합니다. 시뮬레이션의 물리적 정확도가 높아지면, 이 격차가 줄어듭니다.
안전성(Safety)은 Physical AI에서 특히 중요합니다. 텍스트 AI가 잘못된 답변을 하면 불편하지만, Physical AI가 잘못된 행동을 하면 사람이 다칠 수 있습니다. Gemini Robotics 논문에서도 안전성을 별도 섹션으로 다루면서, 행동 전 안전 확인(safety check)과 물리적 제약 준수를 강조합니다. ASIMOV 벤치마크가 안전성 평가를 포함한 이유입니다.
데이터 부족도 큰 병목입니다. LLM은 인터넷에서 수조 토큰을 수집할 수 있지만, 로봇 행동 데이터는 실제 로봇을 돌려야 얻을 수 있습니다. Open X-Embodiment 같은 대규모 로봇 데이터셋이 등장하고 있고, 시뮬레이션 기반 합성 데이터가 이 문제를 완화하고 있지만, 텍스트나 이미지 데이터에 비하면 절대적으로 부족합니다. NVIDIA가 Cosmos를 “데이터 엔진"이라고 부르는 것은 이 맥락입니다.
표준화도 갈 길이 멉니다. 로봇마다 관절 구조, 센서 구성, 제어 인터페이스가 다릅니다. VLA가 여러 로봇에 일반화되려면, 어떤 형태의 Action 표현이 표준이 될지 합의가 필요합니다. Open X-Embodiment가 데이터 표준화를 시도하고 있고, GR00T은 URDF 기반의 로봇 기술(description)을 표준 입력으로 사용하지만, 아직 업계 전체의 합의는 없습니다.
정리
Physical AI는 LLM의 다음 단계입니다. “말하는 AI"에서 “행동하는 AI"로의 전환이 시작되었습니다.
- VLM은 시각과 언어를 통합해서 세상을 이해합니다
- VLA는 VLM에 행동 출력을 추가해서, AI가 물리 세계에 개입할 수 있게 합니다
- World Model은 행동의 결과를 미리 상상해서, 안전하고 효율적인 행동을 가능하게 합니다
이것들이 합쳐진 것이 Physical AI이고, 2026년 현재 NVIDIA, Google DeepMind, Physical Intelligence, Meta(AMI Labs) 등이 각자의 접근법으로 이 스택을 완성해가고 있습니다.
GTC 2026에서 발표된 내용들을 보면, Physical AI가 “연구 주제"에서 “산업 기술"로 전환되는 변곡점에 있다는 것을 느낄 수 있습니다. 아직 실험실에서 공장으로 나가는 과정에 있지만, 2025년과 2026년 사이에 나온 결과물들의 밀도를 보면, 이 흐름이 멈출 것 같지는 않습니다.
References
- Google DeepMind, “Gemini Robotics: Bringing AI into the Physical World”, arXiv:2503.20020, 2025.03
- Physical Intelligence, “π₀: A Vision-Language-Action Flow Model for General Robot Control”, arXiv:2410.24164, 2024.10
- Kim et al., “OpenVLA: An Open-Source Vision-Language-Action Model”, arXiv:2406.09246, 2024.06
- Sapkota et al., “Vision-Language-Action Models: Concepts, Progress, Applications and Challenges”, arXiv:2505.04769, 2025.05
- “Vision-Language-Action Models for Robotics: A Review”, vla-survey.github.io, 2025
- Brohan et al., “RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control”, 2023
- NVIDIA, “Isaac GR00T N1: An Open Foundation Model for Generalist Humanoid Robots”, 2025.03
- NVIDIA, GTC 2026: Cosmos 3, GR00T N1.7, Newton, 2026.03
- Yann LeCun, AMI Labs, $1B Seed Round, 2026.03
- Hugging Face, “Vision Language Models Explained”, 2024.04