
1. 왜 LLM 서빙이 어려운가
최근 몇 년간 Claude, GPT-4, Llama 같은 대형 언어 모델을 프로덕션 환경에서 서빙하는 요구가 폭발적으로 증가했습니다. 하지만 실제로 모델을 서버에 올려 운영해보면, GPU 메모리 부족 문제에 빠르게 직면하게 됩니다.
일반적인 이미지 분류 모델이나 음성 인식 모델은 고정된 크기의 입력을 받아 한 번에 추론합니다. 하지만 LLM은 근본적으로 다릅니다. 텍스트를 생성할 때 토큰을 하나씩 순차적으로 출력하는 자기회귀(Autoregressive) 방식을 사용하기 때문에, 매 토큰 생성마다 이전에 나온 모든 토큰의 정보를 다시 참조해야 합니다.
만약 매번 전체 입력을 다시 처리한다면 계산 비용이 기하급수적으로 증가합니다. 이를 방지하기 위해 Transformer 모델은 KV Cache라는 메모리 버퍼에 이전 토큰들의 Key/Value 텐서를 저장해둡니다. 새 토큰을 생성할 때는 이 캐시만 읽으면 되므로 계산량을 크게 줄일 수 있습니다.
하지만 이 KV Cache가 바로 LLM 서빙의 가장 큰 병목입니다.
KV Cache가 GPU 메모리를 잡아먹는 이유
13B 파라미터 LLM을 예로 들어보겠습니다. 모델 가중치 자체는 FP16 기준으로 약 26GB 정도입니다. 그런데 하나의 시퀀스에 대한 KV Cache가 LLaMA-13B 기준 최대 1.7GB까지 커질 수 있습니다. 배치 크기가 32라면 KV Cache만 약 54GB가 필요합니다.
문제는 여기서 끝나지 않습니다. 기존 LLM 서빙 시스템들은 메모리를 미리 할당하는 방식을 사용했습니다. 각 요청이 최대 몇 개의 토큰을 생성할지 모르기 때문에, 최대 길이를 가정하고 메모리를 예약해야 했습니다. 결과적으로 실제 사용량과 무관하게 메모리가 낭비되는 내부 단편화(Internal Fragmentation) 문제가 발생합니다.
또한 요청들이 서로 다른 길이의 시퀀스를 처리하면서 메모리 공간이 비연속적으로 흩어지는 외부 단편화(External Fragmentation)도 발생합니다. 실제 벤치마크에서 기존 시스템들은 GPU 메모리의 20% 정도만 실제 KV Cache에 사용하고, 나머지 80%는 단편화로 낭비되고 있었습니다.
이것이 바로 vLLM이 해결하고자 한 문제입니다.
2. PagedAttention: OS 가상 메모리에서 배운 아이디어
vLLM의 핵심 혁신은 PagedAttention입니다. 이름에서 알 수 있듯이, 운영체제의 가상 메모리 페이징 기법을 KV Cache 관리에 그대로 적용한 것입니다.
가상 메모리 비유로 이해하기
운영체제에서는 프로세스가 보는 메모리 주소(논리 주소)와 실제 RAM의 주소(물리 주소)가 다릅니다. 프로세스 입장에서는 자신만의 연속된 메모리 공간이 있는 것처럼 보이지만, 실제로는 페이지 테이블을 통해 비연속적인 물리 메모리 여러 조각으로 매핑됩니다.
PagedAttention은 이와 동일한 원리를 사용합니다:
- 논리 블록(Logical KV Blocks): 각 시퀀스는 연속된 논리 블록 번호를 가집니다
- 물리 블록(Physical KV Blocks): GPU 메모리는 고정 크기(예: 16 토큰)의 물리 블록으로 나뉩니다
- 블록 테이블(Block Table): 논리 블록을 물리 블록으로 매핑하는 페이지 테이블 역할을 합니다
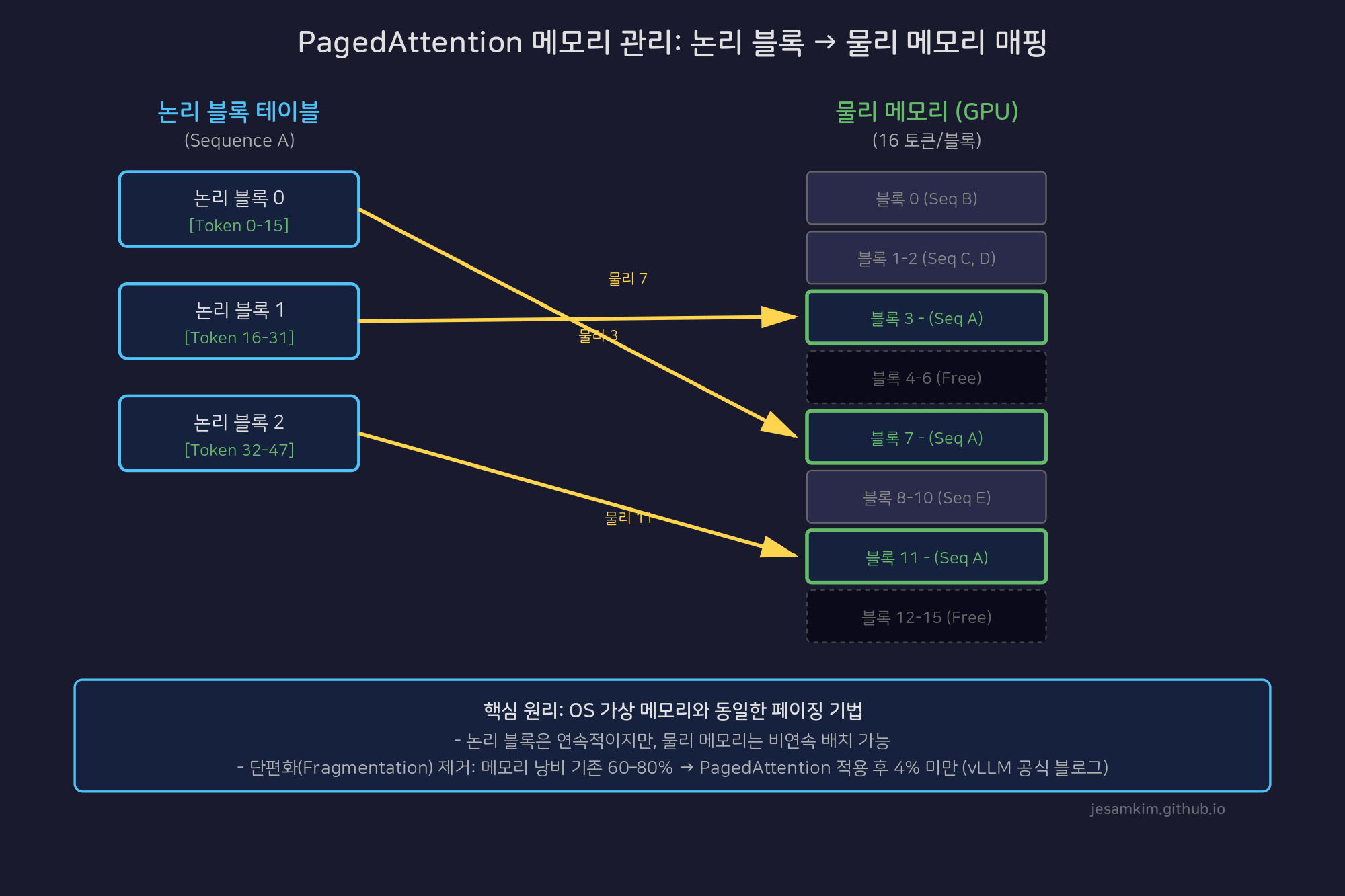
위 다이어그램을 보면, Sequence A의 논리 블록 0, 1, 2는 각각 물리 블록 7, 3, 11로 매핑됩니다. 시퀀스 입장에서는 연속된 블록으로 보이지만, 실제 GPU 메모리에서는 비연속적으로 배치되어 있습니다. 이렇게 하면 메모리 단편화 문제가 완전히 사라집니다.
단편화 제거의 실제 효과
vLLM 논문의 벤치마크 결과를 보면 그 효과가 극적입니다. Orca(기존 SOTA 시스템) 대비 메모리 낭비가 거의 0에 가까워졌고, 같은 GPU에서 처리할 수 있는 배치 크기가 2배 이상 증가했습니다.
vLLM 공식 블로그에 따르면 기존 시스템들은 단편화와 과다 예약으로 인해 메모리의 60–80%를 낭비하고 있었습니다. PagedAttention은 이 낭비를 4% 미만으로 줄여, 같은 GPU에서 훨씬 더 많은 요청을 동시에 처리할 수 있게 만들었습니다. 결과적으로 FasterTransformer와 Orca 대비 2–4배의 처리량 향상을 달성했습니다.
Copy-on-Write로 프롬프트 공유
PagedAttention의 또 다른 장점은 Copy-on-Write 최적화입니다. 여러 요청이 같은 시스템 프롬프트나 Few-shot 예시를 공유하는 경우, 같은 물리 블록을 여러 논리 블록이 참조하도록 할 수 있습니다.
예를 들어 100개의 요청이 모두 동일한 500 토큰짜리 시스템 프롬프트를 사용한다면:
- 기존 방식: 500 × 100 = 50,000 토큰분 메모리 필요
- Copy-on-Write: 500 토큰분 메모리만 필요 (100배 절약)
생성 단계에서 각 요청이 서로 다른 토큰을 출력하기 시작하면, 그때 비로소 새로운 물리 블록을 할당합니다. 마치 Unix의 fork() 시스템 콜처럼 동작합니다.
3. Continuous Batching: 매 Iteration마다 배치 재구성
PagedAttention이 메모리 문제를 해결했다면, Continuous Batching은 GPU 활용률 문제를 해결합니다.
Static Batching의 한계
기존 방식인 Static Batching은 다음과 같이 동작합니다:
- 여러 요청을 하나의 배치로 묶습니다 (예: Req A, B, C)
- 배치 전체가 완료될 때까지 처리합니다
- 일부 요청이 먼저 끝나도 가장 긴 요청이 끝날 때까지 기다립니다
- 배치 전체가 완료되면 새로운 배치를 시작합니다
문제는 3번 단계입니다. Req B가 50 토큰만 생성하고 끝났는데, Req A가 500 토큰을 생성한다면 450 iteration 동안 B의 슬롯이 비어있게 됩니다. GPU 리소스가 그냥 낭비되는 것입니다.
Iteration-level Scheduling
vLLM의 Continuous Batching은 매 iteration(토큰 생성 단계)마다 배치를 동적으로 재구성합니다:
- Iteration 1: Req A, B, C 처리
- Iteration 2: Req B가 완료됨 → 즉시 대기 중인 Req D를 추가 → A, D, C 처리
- Iteration 3: Req C가 완료됨 → Req E 추가 → A, D, E 처리
- 계속해서 완료된 요청은 빠지고 새 요청이 들어옵니다
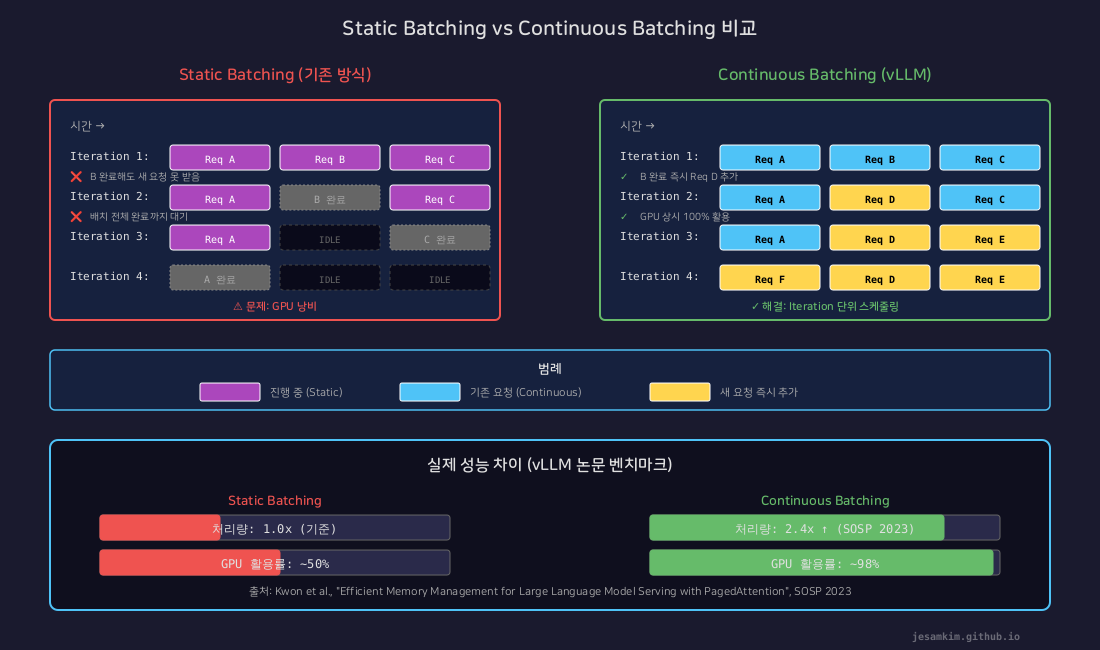
위 다이어그램을 보면 차이가 명확합니다. Static Batching은 완료된 요청의 슬롯이 IDLE 상태로 남지만, Continuous Batching은 즉시 새 요청으로 채워서 GPU가 상시 100%에 가깝게 동작합니다.
이처럼 매 iteration마다 빈 슬롯을 채워넣기 때문에 GPU가 상시 높은 활용률을 유지합니다. 실제 vLLM 벤치마크에서 HuggingFace Transformers 대비 최대 24배, TGI 대비 최대 3.5배 높은 처리량을 보여주었습니다.
4. vLLM 서빙 아키텍처
PagedAttention과 Continuous Batching이 어떻게 실제 시스템에서 동작하는지 살펴보겠습니다. vLLM은 크게 세 가지 컴포넌트로 구성됩니다.
핵심 컴포넌트
1. Scheduler
들어오는 요청들을 관리하고, 매 iteration마다 어떤 요청을 배치에 포함할지 결정합니다. 주요 역할:
- Waiting Queue에서 새 요청 선택
- Running 상태인 요청 관리
- Swapped 상태 요청 재개 (메모리 부족 시 CPU 메모리로 임시 이동)
- 우선순위 스케줄링 (FCFS, Priority Queue 등 지원)
2. KV Block Manager
GPU 메모리의 물리 블록을 할당하고 해제합니다. 기능:
- 블록 테이블 관리 (논리 → 물리 매핑)
- 여유 블록 추적 (Free block list)
- Copy-on-Write 공유 블록 관리
- Eviction 정책 (메모리 부족 시 어떤 블록을 CPU로 옮길지 결정)
3. Worker (Model Executor)
실제 GPU에서 모델 추론을 실행합니다. 역할:
- PagedAttention 커널 호출 (CUDA/ROCm 최적화)
- 배치 추론 실행
- Tensor Parallelism 지원 (여러 GPU로 모델 분산)
전체 요청 처리 흐름
사용자가 “프랑스의 수도는?“이라는 프롬프트를 보냈다고 가정해봅시다.
Step 1: Prefill Phase (프롬프트 처리)
- Scheduler가 요청을 받아 Waiting Queue에 추가
- KV Block Manager가 물리 블록 할당 (예: 블록 5, 12 할당)
- Worker가 프롬프트 전체를 한 번에 처리하여 KV Cache 생성
- 블록 테이블에 논리 블록 0 → 물리 블록 5, 논리 블록 1 → 물리 블록 12 매핑 기록
- 첫 번째 토큰 생성 (“파”)
Step 2: Decode Phase (토큰 생성 반복)
- Scheduler가 현재 Running 배치에 이 요청 포함 (다른 요청들과 함께)
- Worker가 새 토큰 “리"를 생성, KV Cache 업데이트
- 블록이 가득 차면 KV Block Manager가 새 물리 블록 할당
- 종료 토큰(
<eos>)이 나오거나 최대 길이에 도달할 때까지 반복
Step 3: 완료 및 정리
- Scheduler가 요청을 Running에서 제거
- KV Block Manager가 사용하던 물리 블록들을 Free list로 반환
- 즉시 대기 중인 다른 요청이 그 자리를 차지 (Continuous Batching)
이 전체 과정이 매 iteration마다 수십 개의 요청에 대해 동시에 일어납니다. Scheduler는 메모리 상황을 보면서 배치 크기를 동적으로 조절하고, KV Block Manager는 블록을 재활용하며, Worker는 GPU를 쉬지 않고 돌립니다.
5. 최신 최적화 기법들
vLLM은 계속 진화하고 있습니다. 최근 추가된 고급 최적화 기법들을 간단히 살펴보겠습니다.
Prefix Caching
여러 요청이 동일한 접두사(Prefix)를 공유하는 경우를 자동으로 감지합니다. Copy-on-Write보다 한 단계 더 나아가, 런타임에 동적으로 공통 접두사를 찾아 KV Cache를 재사용합니다.
예를 들어:
- “프랑스의 수도는?”
- “프랑스의 인구는?”
두 요청 모두 “프랑스의"까지는 동일하므로, 해당 부분의 KV Cache를 공유할 수 있습니다. RAG(Retrieval-Augmented Generation) 시나리오에서 특히 유용합니다. 같은 문서 컨텍스트를 사용하는 여러 질문을 처리할 때 prefill 시간이 크게 줄어듭니다.
Chunked Prefill
긴 프롬프트를 한 번에 처리하면 짧은 요청들이 오래 기다려야 합니다. Chunked Prefill은 프롬프트를 여러 청크로 나눠서 처리합니다.
예: 10,000 토큰 프롬프트를 512 토큰씩 20개 청크로 나눔
- 청크 1 처리 → 짧은 요청 1개 decode → 청크 2 처리 → …
- 긴 요청이 짧은 요청을 블로킹하지 않음
- 평균 응답 시간(Latency) 감소, 공평성(Fairness) 향상
Speculative Decoding
작은 Draft 모델로 여러 토큰을 미리 예측하고, 큰 Target 모델로 한 번에 검증하는 기법입니다. Draft 모델의 예측이 맞으면 여러 토큰을 한 iteration에 생성할 수 있어 속도가 빨라집니다.
vLLM에서는 다음을 지원합니다:
- Draft 모델로 Llama-7B, Target 모델로 Llama-70B 조합
- N-gram 기반 드래프팅 (별도 모델 없이 통계적 예측)
- 평균적으로 1.5–2배의 속도 향상
Disaggregated Prefill/Decode
Prefill 단계(프롬프트 처리)와 Decode 단계(토큰 생성)는 특성이 다릅니다:
- Prefill: Compute-bound (병렬 처리 가능, GPU 활용률 높음)
- Decode: Memory-bound (순차 처리, 메모리 대역폭 중요)
서로 다른 GPU 클러스터에서 Prefill과 Decode를 분리 실행하면:
- Prefill 클러스터: 고성능 GPU (A100, H100) 사용
- Decode 클러스터: 메모리 대역폭이 넓은 GPU 사용
- 각 단계에 최적화된 하드웨어 활용으로 비용 절감
6. 마무리
vLLM은 단순히 속도가 빠른 추론 엔진이 아닙니다. 운영체제의 가상 메모리 관리 원리를 LLM 서빙에 적용한 아키텍처 혁신입니다.
PagedAttention으로 메모리 단편화를 제거하고, Continuous Batching으로 GPU 활용률을 극대화하며, 다양한 최적화 기법들로 실제 프로덕션 환경의 요구사항을 충족시켰습니다. 그 결과 같은 하드웨어로 2–4배 이상의 처리량을 달성할 수 있었습니다.
특히 인상적인 점은 복잡한 최적화 기법들을 사용자에게 숨기고, 간단한 API로 제공한다는 것입니다. 사용자는 그냥 모델 이름과 프롬프트를 넘기기만 하면, vLLM이 내부에서 알아서 메모리를 관리하고 배치를 스케줄링합니다.
현재 vLLM은 오픈소스 LLM 서빙 스택의 사실상 표준이 되었습니다. Hugging Face Text Generation Inference, Anyscale Endpoints, Amazon SageMaker 등 많은 상용 서비스들이 vLLM을 기반으로 구축되고 있습니다.
앞으로는 Multi-LoRA 서빙(하나의 베이스 모델에 여러 LoRA 어댑터를 동적으로 교체), Vision-Language Model 지원, Mixture-of-Experts 최적화 등이 추가될 예정입니다. LLM 서빙 기술은 계속 진화하고 있습니다.
References
- Kwon, W., et al. (2023). “Efficient Memory Management for Large Language Model Serving with PagedAttention”. Proceedings of the 29th Symposium on Operating Systems Principles (SOSP 2023). https://arxiv.org/abs/2309.06180
- vLLM Documentation. https://docs.vllm.ai/
- vLLM GitHub Repository. https://github.com/vllm-project/vllm
- Yu, G., et al. (2022). “Orca: A Distributed Serving System for Transformer-Based Generative Models”. OSDI 2022. https://www.usenix.org/conference/osdi22/presentation/yu
- NVIDIA TensorRT-LLM Documentation. https://github.com/NVIDIA/TensorRT-LLM
- Hugging Face Text Generation Inference. https://github.com/huggingface/text-generation-inference