
1. 왜 비디오 RAG인가: 텍스트 RAG를 넘어서
텍스트 RAG(Retrieval-Augmented Generation)는 이미 성숙한 기술입니다. 문서를 청크로 나누고, 임베딩하고, 벡터 데이터베이스에 저장한 뒤, 쿼리와 유사한 청크를 검색해 LLM의 응답을 보강하는 패턴이 확립되어 있습니다.
하지만 기업 데이터의 상당 부분은 텍스트가 아닌 비디오입니다. CCTV 녹화, 회의 녹화, 교육 콘텐츠, 마케팅 영상 등 비디오 형태로 축적된 정보는 방대합니다. Statista 조사에 따르면 2025년 기준 전 세계 인터넷 사용자의 94.6%가 매월 온라인 비디오를 시청하고 있습니다.
이러한 배경에서 VideoRAG 논문(Jeong et al., 2025, ACL Findings)이 비디오 RAG 프레임워크를 제안했습니다. 기존 접근법은 비디오를 텍스트로 변환할 때 멀티모달 정보가 손실되거나, 쿼리 기반 검색 없이 사전에 정의된 비디오만 사용하는 한계가 있었습니다.
비디오 RAG는 이러한 문제를 해결하고, 텍스트처럼 검색 가능한 비디오 지식 베이스를 구축하는 것을 목표로 합니다.
2. 실전 유즈케이스: 비디오 RAG가 풀 수 있는 문제들
비디오 RAG가 실제로 어떤 문제를 해결할 수 있을까요?
산업 현장 안전 관리 (건설/제조)
건설 현장이나 제조 공장에서는 CCTV 아카이브가 방대하게 쌓입니다. 과거 사고 사례를 검색하거나 안전 교육 자료를 추출하는 데 비디오 RAG를 활용할 수 있습니다.
예를 들어 “지난달 크레인 근접 작업 위반 영상 찾아줘"라는 쿼리에 대해, 과거 몇 달치 CCTV 아카이브에서 관련 장면을 검색하고 타임스탬프를 제공할 수 있습니다.
주의: 실시간 안전 감지(안전모 미착용 감지 등)는 스트리밍 추론을 사용하며, RAG와는 별개의 아키텍처입니다. 비디오 RAG는 사후 검색에 적합합니다.
미디어/방송 아카이브
방송사는 수만 시간의 방송 아카이브를 보유하고 있습니다. 특정 장면, 인물, 발언을 검색할 때 비디오 RAG가 유용합니다.
텍스트 자막 검색만으로는 부족한 경우가 많습니다. “붉은 드레스를 입은 진행자가 스튜디오에서 인터뷰하는 장면"처럼 비주얼 요소와 텍스트를 함께 검색하는 멀티모달 검색의 시너지가 필요합니다.
교육/이러닝
온라인 강의 플랫폼은 수천 개의 강의 영상을 보유하고 있습니다. 학습자가 특정 개념을 검색하면, 해당 개념을 설명하는 강의 구간을 정확히 찾아주는 것이 가능합니다.
“미분의 기하학적 의미"를 검색하면, 관련 강의 영상과 타임스탬프를 반환해 학습자 맞춤 콘텐츠 큐레이션을 제공할 수 있습니다.
3. 비디오를 벡터로 만드는 두 가지 접근법
비디오 RAG를 구축하려면, 비디오를 벡터로 변환해야 합니다. 두 가지 접근법이 있습니다.
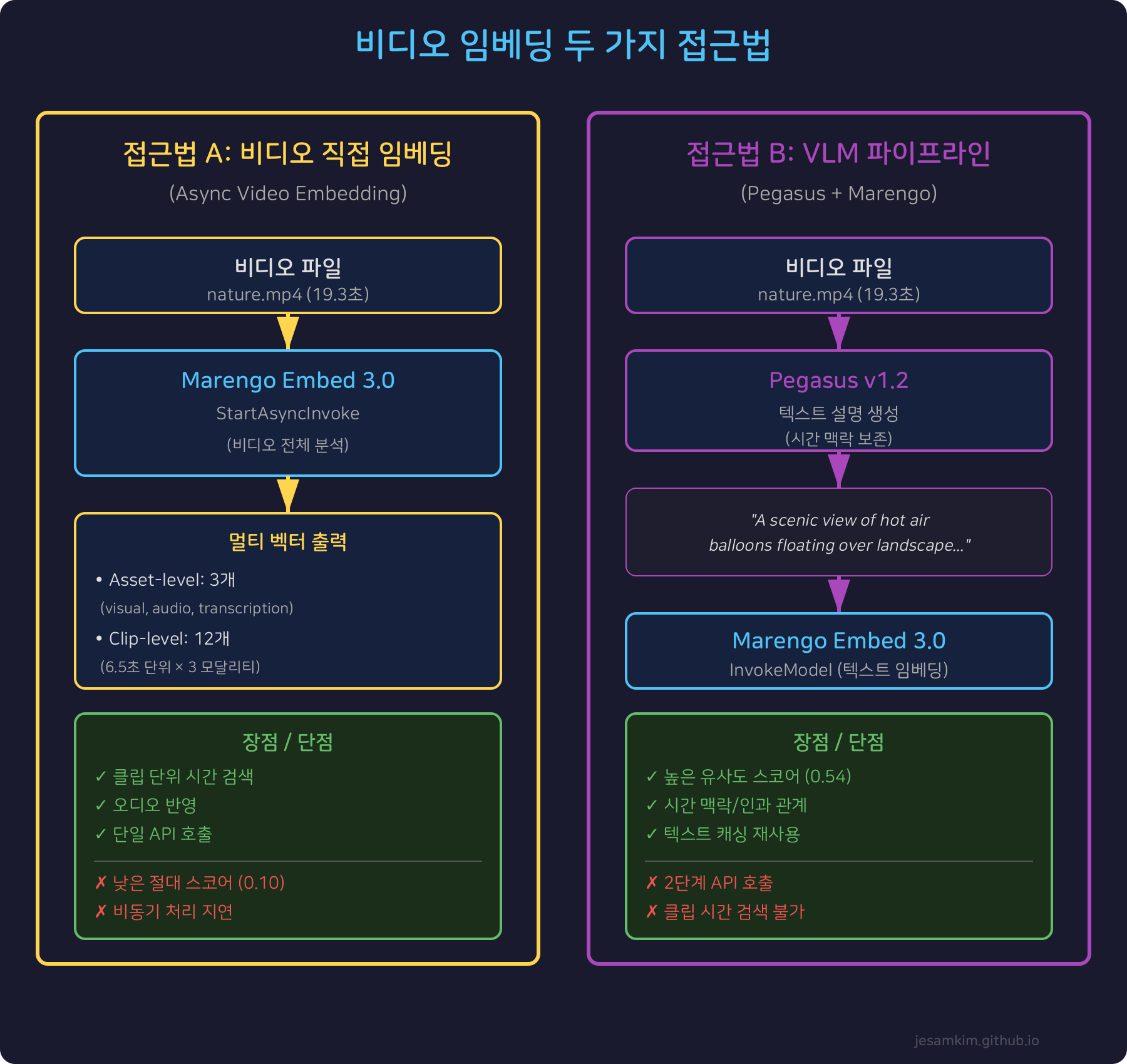
접근법 A: 비디오 직접 임베딩 (Async Video Embedding)
Marengo Embed 3.0의 StartAsyncInvoke API를 사용해 비디오를 직접 임베딩하는 방식입니다.
동작 방식:
- 비디오 파일을 S3에 업로드하고, StartAsyncInvoke API를 호출합니다
- Marengo가 비디오 전체를 분석해 멀티모달 벡터를 생성합니다
- Asset-level: 비디오 전체에 대한 visual, audio, transcription 벡터 (3개)
- Clip-level: 약 6.5초 단위 세그먼트별 벡터 (영상당 9–18개)
- 최대 4시간/6GB 비디오 지원
장점:
- 클립 단위 시간 검색이 가능합니다. “사람이 제스처를 하는 구간"을 타임스탬프로 정확히 검색할 수 있습니다
- 오디오와 대화를 반영합니다 (audio modality 벡터)
- 단일 API 호출로 완료되어 구현이 단순합니다
단점:
- 절대 유사도 스코어가 낮습니다 (0.07–0.15 수준)
- 비동기 API이므로 완료까지 수십 초 소요됩니다
- 텍스트 설명을 재사용할 수 없습니다
접근법 B: VLM(Video Language Model) 기반 파이프라인
비디오 전체를 Pegasus v1.2에 입력해 텍스트 설명을 생성한 뒤, 그 텍스트를 Marengo Embed 3.0으로 임베딩하는 방식입니다.
동작 방식:
- Pegasus v1.2가 비디오를 분석해 자연어 설명을 생성합니다
- 생성된 텍스트를 Marengo Embed 3.0의 InvokeModel(동기 API)로 임베딩합니다
- 단일 512차원 벡터를 얻습니다
장점:
- 높은 유사도 스코어 (0.46–0.64 수준, 비디오 직접 임베딩 대비 5배)
- 시간적 맥락과 인과 관계를 자연어로 표현합니다
- 텍스트 설명을 캐싱해 재사용할 수 있습니다
단점:
- 2단계 API 호출이 필요합니다 (Pegasus → Marengo)
- 클립 단위 시간 검색이 불가능합니다
- 추가 추론 비용이 발생합니다
실험을 통해 두 접근법의 성능 차이를 비교해 보겠습니다.
4. Twelve Labs 모델: Pegasus v1.2와 Marengo Embed 3.0
Twelve Labs 소개
Twelve Labs는 비디오 이해 전문 AI 스타트업입니다. AWS SageMaker HyperPod에서 모델을 학습하며, 2025년 7월부터 Amazon Bedrock에서 정식으로 사용할 수 있습니다.
Pegasus v1.2 (비디오 언어 모델)
Pegasus v1.2는 Twelve Labs의 최신 비디오 언어 모델입니다.
아키텍처: video encoder + video-language alignment + language decoder로 구성되어 있으며, Pegasus-1 Technical Report에 따르면 약 80B 파라미터를 가진 것으로 알려져 있습니다 (Pegasus-1 기준, v1.2의 정확한 파라미터 수는 별도 공개되지 않았습니다).
성능:
- 최대 1시간 비디오 지원
- 15분까지 일정한 TTFT(Time To First Token) 레이턴시
- VideoMME-Long 벤치마크에서 GPT-4o, Gemini 1.5 Pro 대비 SOTA 성능 달성
특징:
- 타임스탬프 기반 시간 이해가 탁월합니다. 예를 들어 미식축구 경기에서 “3쿼터 7분 20초에 무슨 일이 일어났나요?“라는 질문에 정확히 답변합니다
- 한국어 응답을 자연스럽게 생성합니다
Bedrock 설정:
- Inference Profile:
us.twelvelabs.pegasus-1-2-v1:0 - 리전: US West (Oregon), Europe (Ireland), US East (N. Virginia), Asia Pacific (Seoul) 등 7개 리전 (cross-region inference)
- 파라미터 문서
Marengo Embed 3.0 (멀티모달 임베딩)
Marengo Embed 3.0은 512차원 벡터를 출력하는 멀티모달 임베딩 모델입니다.
입력 모달리티:
- InvokeModel (동기 API): 텍스트, 이미지를 즉시 임베딩합니다
- StartAsyncInvoke (비동기 API): 비디오, 오디오, 이미지, 텍스트를 모두 임베딩할 수 있습니다. 최대 4시간/6GB 비디오까지 처리 가능합니다
비디오 임베딩 출력:
- Asset-level: 비디오 전체에 대한 visual, audio, transcription 모달리티별 벡터 (3개)
- Clip-level: 약 6.5초 단위 세그먼트별로 3개 모달리티 벡터 생성
- 예: 19.3초 비디오 → asset 3개 + clip 12개 = 총 15개 벡터
Bedrock 설정:
- Inference Profile:
us.twelvelabs.marengo-embed-3-0-v1:0 - 리전: US East (N. Virginia), Europe (Ireland), Asia Pacific (Seoul)
- 파라미터 문서
5. 실전 실험: Bedrock에서 직접 비교해 보니
실험 코드는 GitHub 레포지토리에서 확인할 수 있습니다.
실험 환경
3개의 샘플 비디오를 준비했습니다. 모두 Pexels에서 CC0 라이선스로 제공되는 영상입니다.
- nature.mp4: 카파도키아 열기구 (19.3초)
- city.mp4: 강변 대화 (37.9초)
- cooking.mp4: 실험실 피펫 작업 (14.0초)
재미있는 점은 cooking.mp4는 파일명과 실제 내용이 일치하지 않는다는 것입니다. 실제로는 실험실에서 피펫을 사용하는 장면이지만, 파일명은 cooking입니다. Pegasus가 이것을 정확히 파악하는지 확인할 수 있습니다.
실험 1: Pegasus 비디오 QA
먼저 Pegasus v1.2가 비디오를 얼마나 잘 이해하는지 테스트했습니다.
3개 비디오 × 4개 프롬프트 = 총 12건의 질의를 수행했고, 모두 성공했습니다(100% 성공률).
주요 발견:
- 한국어 응답이 자연스럽습니다. 다만 일부 hallucination이 존재합니다(예: “페가수스 공원” 같은 존재하지 않는 장소 언급)
- 타임스탬프 추출이 정확합니다. [MM:SS-MM:SS] 형식으로 구간별 설명을 제공합니다
- cooking.mp4의 실제 내용(실험실 피펫 작업)을 정확히 파악했습니다. 파일명에 속지 않고 비디오 내용을 정확히 분석했습니다
실험 2: 임베딩 비교
두 가지 방식으로 비디오 임베딩을 생성하고, 쿼리와의 유사도를 비교했습니다.
Async Video Embed:
- 비디오를 S3에 업로드
- StartAsyncInvoke API로 Marengo Embed 3.0 호출
- Asset-level visual 벡터를 사용 (비디오 전체의 시각적 특징)
Pegasus+Marengo:
- Pegasus v1.2로 비디오 전체를 텍스트 설명으로 변환
- 텍스트를 Marengo Embed 3.0으로 임베딩 (동기 API)
결과 데이터
3개의 쿼리에 대해 각 비디오와의 cosine similarity를 측정했습니다.
| 쿼리 | 방식 | nature | city | cooking |
|---|---|---|---|---|
| “hot air balloons in cappadocia” | Async Video Embed | 0.135 | 0.005 | -0.070 |
| Pegasus+Marengo | 0.456 | 0.176 | 0.117 | |
| “people having conversation outdoors” | Async Video Embed | -0.022 | 0.067 | -0.075 |
| Pegasus+Marengo | 0.290 | 0.636 | 0.158 | |
| “science experiment in lab” | Async Video Embed | -0.083 | -0.066 | 0.099 |
| Pegasus+Marengo | 0.222 | 0.254 | 0.534 |
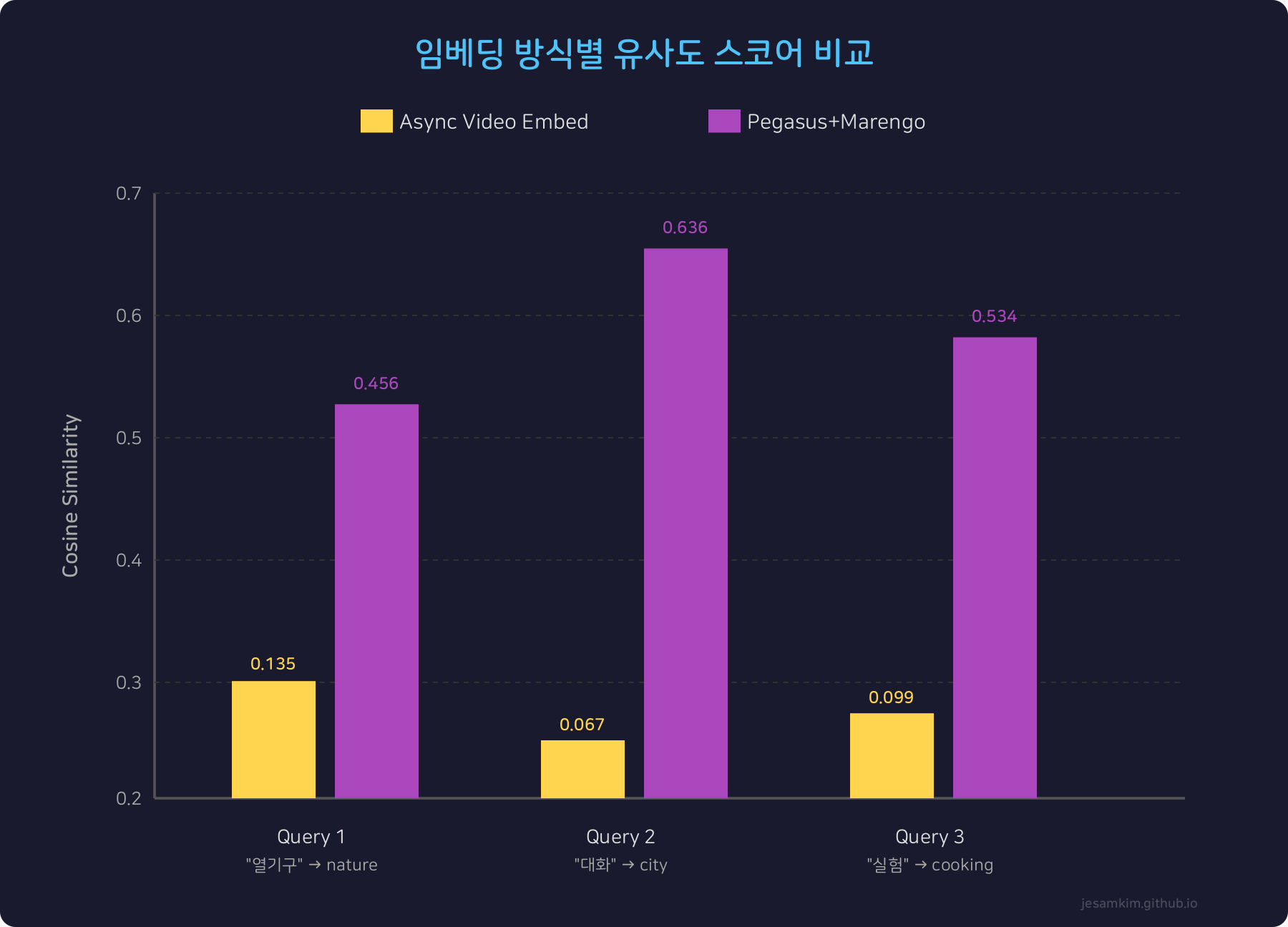
핵심 발견:
두 방식 모두 정확한 1위 매칭을 했습니다(3/3). 즉, “열기구” 쿼리는 nature 비디오를, “대화” 쿼리는 city 비디오를, “실험” 쿼리는 cooking 비디오를 각각 최고 점수로 검색했습니다.
하지만 절대 스코어가 극적으로 다릅니다. Async Video Embed의 평균 스코어는 0.100인 반면, Pegasus+Marengo는 0.542로 약 5배 높습니다.
Pegasus+Marengo는 모든 쿼리에서 양수 스코어를 보이지만, Async Video Embed는 음수 스코어가 많습니다. 이는 비디오 시각적 벡터가 텍스트 쿼리와 직접 비교될 때 의미적 정렬이 약하다는 것을 의미합니다.
클립 단위 시간 검색
Async Video Embed의 강점은 클립 단위 검색입니다. city.mp4의 클립별 유사도를 보면:
| 쿼리 | 타임스탬프 | 유사도 |
|---|---|---|
| “people gesturing and talking” | 13.0-19.2초 | 0.107 |
| 6.5-13.0초 | 0.083 | |
| 0-6.5초 | 0.063 |
실제로 13.0-19.2초 구간에서 사람들이 손으로 제스처를 하며 대화하는 장면이 가장 두드러집니다. 클립 단위 벡터가 시간적 세그먼트를 정확히 찾아냅니다.
비디오 간 유사도 개선
3개 비디오의 asset-level visual 벡터끼리 cosine similarity를 계산하면:

| nature | city | cooking | |
|---|---|---|---|
| nature | 1.00 | 0.63 | 0.60 |
| city | 0.63 | 1.00 | 0.62 |
| cooking | 0.60 | 0.62 | 1.00 |
비디오 직접 임베딩은 0.60–0.63 범위로, 프레임 평균 방식(0.74–0.79)보다 의미적 구분이 개선되었습니다. 하지만 여전히 절대 스코어가 낮아, 텍스트 쿼리와의 직접 매칭에는 한계가 있습니다.
종합 비교
| 방식 | 평균 스코어 | 장점 | 단점 |
|---|---|---|---|
| Async Video Embed | 0.100 | 클립 단위 시간 검색, 단일 API | 낮은 절대 스코어 |
| Pegasus+Marengo | 0.542 | 높은 유사도, 텍스트 재사용 | 2단계 API, 시간 검색 불가 |
6. 비디오 RAG 파이프라인 아키텍처: 하이브리드 접근법
실험 결과를 바탕으로, 두 방식을 모두 활용하는 하이브리드 아키텍처를 권장합니다.
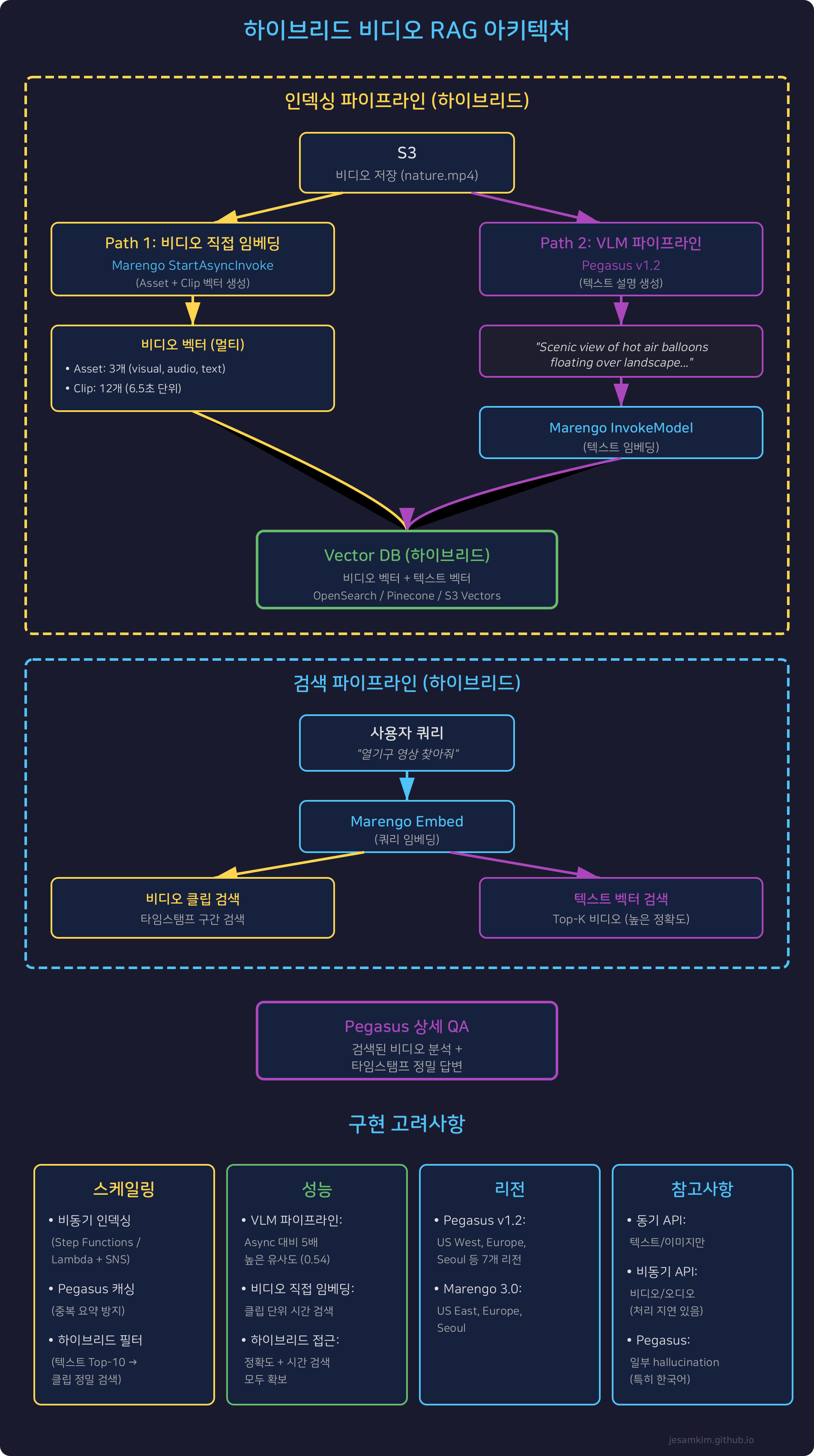
Phase 1: 인덱싱
- 비디오 저장: S3에 비디오를 업로드합니다
- 비동기 비디오 임베딩: StartAsyncInvoke로 Marengo가 asset + clip 벡터를 생성합니다
- 텍스트 설명 생성: Pegasus v1.2로 비디오 전체를 텍스트로 요약합니다
- 텍스트 임베딩: Marengo의 동기 API로 텍스트를 임베딩합니다
- 저장: 두 종류의 벡터(비디오 + 텍스트)와 메타데이터를 Vector DB에 저장합니다
Phase 2: 검색
- 쿼리 임베딩: 사용자 쿼리를 Marengo로 임베딩합니다
- 하이브리드 검색:
- 텍스트 임베딩으로 Top-K 비디오 검색 (높은 정확도)
- 비디오 임베딩으로 클립 단위 시간 검색 (타임스탬프)
- 메타데이터 반환: 검색된 비디오의 메타데이터와 관련 구간을 가져옵니다
Phase 3: 생성
- 상세 QA: 검색된 비디오를 Pegasus v1.2에 다시 입력하고, 사용자 쿼리에 대한 상세 답변을 생성합니다
- 타임스탬프 제공: 답변과 함께 클립 단위 검색 결과에서 얻은 정확한 타임스탬프를 제공합니다
AWS 서비스 구성
- S3: 비디오 저장
- Amazon Bedrock: Pegasus v1.2 + Marengo Embed 3.0 (동기 + 비동기 API)
- Vector DB: Amazon OpenSearch Service, Pinecone, 또는 S3 Vectors
AWS 케이스 스터디에서는 TwelveLabs와 S3 Vectors 통합이 소개되어 있습니다. S3 Vectors를 사용하면 별도의 Vector DB 없이 S3에서 직접 벡터 검색이 가능합니다.
스케일링 고려사항
- 비동기 인덱싱: 수천 개의 비디오를 인덱싱할 때는 비동기 워크플로우(Step Functions 등)를 사용합니다. StartAsyncInvoke 완료 시 SNS 알림을 받아 다음 단계를 트리거합니다
- 캐시 전략: Pegasus 텍스트 설명을 S3 또는 DynamoDB에 캐싱해 재사용합니다
- 하이브리드 필터링: 먼저 텍스트 임베딩으로 Top-10을 찾고, 그 중에서 비디오 임베딩으로 클립 구간을 정밀 검색합니다
7. 한계와 전망
한계점
텍스트-비디오 의미 정렬: 비디오 직접 임베딩의 절대 스코어가 낮아, 텍스트 쿼리와 직접 매칭 시 정확도가 떨어집니다. 텍스트 임베딩을 함께 사용하는 하이브리드 접근이 필요합니다.
Hallucination: Pegasus가 한국어 요약 시 일부 환각을 생성합니다. 예를 들어 “페가수스 공원” 같은 존재하지 않는 장소를 언급하는 경우가 있습니다.
비동기 처리 지연: StartAsyncInvoke는 비디오 길이에 따라 수십 초에서 수 분이 소요되므로, 실시간 인덱싱이 필요한 경우에는 부적합합니다.
전망
비디오 RAG는 아직 초기 단계이지만, 텍스트 RAG가 걸어온 길을 빠르게 따라올 것입니다.
VAST Data + TwelveLabs 파트너십: VAST Data와 TwelveLabs가 파트너십을 체결해 on-premise 환경에서도 비디오 인텔리전스를 구축할 수 있게 되었습니다.
비디오 검색의 민주화: 몇 년 내에 비디오가 텍스트만큼 검색 가능해질 것입니다. “지난주 회의에서 누가 예산 삭감을 언급했지?“라는 질문에, 회의 녹화 아카이브에서 정확한 장면과 타임스탬프를 찾아주는 시대가 옵니다.
멀티모달 이해의 진화: 텍스트 + 비주얼 + 오디오를 통합 이해하는 모델이 계속 발전하면, “말투가 불안해 보이는 발표자"처럼 감정과 맥락까지 검색할 수 있게 될 것입니다.
결론
비디오 RAG를 구축할 때, 비디오 직접 임베딩(Async Video Embed)은 클립 단위 시간 검색에 강점이 있지만 절대 유사도 스코어가 낮습니다. 반면 VLM 기반 파이프라인(Pegasus + Marengo)은 5배 높은 유사도 스코어를 달성하며, 텍스트 쿼리와의 의미적 매칭이 우수합니다.
실전에서는 두 방식을 모두 활용하는 하이브리드 접근을 권장합니다. 텍스트 임베딩으로 관련 비디오를 찾고, 비디오 임베딩으로 정확한 타임스탬프를 제공하는 것입니다.
Amazon Bedrock에서 Twelve Labs 모델을 사용하면, 복잡한 인프라 구축 없이도 프로덕션 수준의 비디오 RAG를 빠르게 구축할 수 있습니다.
실험 코드는 GitHub 레포지토리에 공개되어 있습니다.
References
- Twelve Labs Pegasus 1.2 블로그: https://www.twelvelabs.io/blog/introducing-pegasus-1-2
- Pegasus-1 Technical Report: https://arxiv.org/abs/2404.14687 (Jung et al., 2024)
- AWS Blog - TwelveLabs on Bedrock: https://aws.amazon.com/blogs/aws/twelvelabs-video-understanding-models-are-now-available-in-amazon-bedrock/
- VideoRAG: https://arxiv.org/abs/2501.05874 (Jeong et al., 2025, ACL Findings)
- TwelveLabs on Bedrock: https://aws.amazon.com/bedrock/twelvelabs/
- Bedrock Pegasus Documentation: https://docs.aws.amazon.com/bedrock/latest/userguide/model-parameters-pegasus.html
- Bedrock Marengo Documentation: https://docs.aws.amazon.com/bedrock/latest/userguide/model-parameters-marengo-3.html
- Twelve Labs Pegasus-1 블로그: https://www.twelvelabs.io/blog/introducing-pegasus-1
- VAST Data + TwelveLabs Partnership: https://www.vastdata.com/press-releases/vast-data-and-twelvelabs-partner-to-expand-video-intelligence
- 실험 코드 GitHub 레포: https://github.com/jesamkim/bedrock-twelvelabs
- Statista - Online Video Viewers Worldwide: https://www.statista.com/statistics/1489445/online-video-viewers-worldwide-quarterly/