
1. 왜 VLM 파인튜닝인가
Vision Language Model(VLM)은 이미지를 보고 텍스트로 대답하는 멀티모달 AI입니다. GPT-4o, Claude Sonnet 4.6 Vision, Gemini Pro Vision 같은 범용 모델들이 일반적인 질문에는 잘 답하지만, 특정 도메인에서는 한계가 있습니다.
범용 VLM의 한계
건설 현장 안전 관리 시스템을 설계한다고 가정해봅시다. 범용 VLM에게 현장 사진을 보여주고 “안전모를 착용하지 않은 작업자가 있나요?“라고 물으면 일반적인 안전모는 감지하지만, 해당 건설사의 특정 안전 규정(색상별 직급 구분, 반사띠 부착 여부, 턱끈 체결 상태)까지는 판단하지 못합니다.
패션 리테일에서도 마찬가지입니다. “이 옷의 스타일은?“이라고 물으면 “캐주얼한 셔츠"라고 답하지만, 해당 브랜드의 상품 카테고리 체계(시즌, 라인, SKU 코드)에 맞춰 분류하지는 못합니다.
도메인 특화의 필요성
이럴 때 필요한 것이 파인튜닝입니다. 특정 도메인의 이미지-텍스트 쌍으로 모델을 추가 학습시키면, 해당 분야의 전문 지식을 습득할 수 있습니다.
파인튜닝의 장점:
- 도메인 용어 이해: 업계 전문 용어와 약어를 정확히 인식
- 시각적 패턴 학습: 업종별 특수한 객체, 결함, 상태를 구분
- 일관된 출력 형식: 프롬프트 없이도 정해진 포맷으로 응답
- 비용 절감: 긴 프롬프트 없이 짧은 입력으로 정확한 답변
Label Your Data의 2026 가이드에 따르면, 오픈소스 VLM을 5,000~50,000개 예시로 파인튜닝하면 GPT-4o 수준의 도메인 성능을 달성할 수 있다고 합니다.
2. 오픈소스 VLM 현황 (2025~2026)
2026년 3월 현재, 상용 수준의 오픈소스 VLM들이 다수 공개되어 있습니다.
Qwen2.5-VL (Alibaba Cloud)
Alibaba Cloud Qwen 팀이 2025년 2월에 공개한 모델입니다. 3가지 크기로 제공됩니다:
- 3B: 경량 엣지 디바이스용
- 7B: 파인튜닝 최적화 (단일 GPU 가능)
- 72B: MMBench-EN 88.6점 달성
기술적 특징:
- Vision Transformer에 window attention 적용 (긴 이미지 시퀀스 처리)
- SwiGLU 활성화 함수 + RMSNorm으로 학습 안정성 향상
- HuggingFace에서 공식 QLoRA 파인튜닝 레시피 제공
InternVL3.5 (Shanghai AI Lab)
OpenGVLab과 Shanghai AI Lab이 개발한 모델로, GUI 에이전트 태스크에 특화되어 있습니다.
- WindowsAgentArena 벤치마크에서 Qwen2.5-VL-72B 대비 +8.3% 높은 성능
- 241B-A28B MoE(Mixture of Experts) 아키텍처로 추론 효율 개선
모델 선택 기준
| 모델 | 최적 용도 | 파인튜닝 난이도 | 컴퓨트 요구사항 |
|---|---|---|---|
| Qwen2.5-VL-7B | 범용 도메인 특화 | 낮음 | 단일 A10G (24GB) |
| InternVL3.5 | GUI/에이전트 태스크 | 중간 | A100 (40GB) |
| Gemma 3 9B | Google 생태계 통합 | 낮음 | 단일 L4 (24GB) |
실전에서는 Qwen2.5-VL-7B를 추천합니다. HuggingFace TRL 라이브러리와 공식 통합되어 있고, 단일 소비자급 GPU에서도 QLoRA 파인튜닝이 가능합니다.
3. LoRA와 QLoRA의 핵심 원리
Full Fine-tuning의 문제
일반적인 파인튜닝은 모델의 모든 파라미터를 업데이트합니다. 7B 모델이라면 70억 개의 가중치를 전부 저장하고 최적화해야 하므로:
- GPU 메모리: 최소 100GB 이상 필요 (optimizer state 포함)
- 학습 시간: 수십 시간 ~ 수일
- 비용: $1,000 ~ $10,000 이상
LoRA: Low-Rank Adaptation
LoRA(Hu et al., 2021)는 Microsoft Research가 ICLR 2022에 발표한 기법입니다. 핵심 아이디어는 가중치 변화량이 저차원 구조를 가진다는 관찰입니다.
원본 가중치 행렬 W ∈ ℝd×k를 고정하고, 작은 행렬 두 개의 곱 ΔW = BA로 변화량만 학습합니다:
- B ∈ ℝd×r
- A ∈ ℝr×k
- r ≪ min(d, k) (예: r=8, d=4096)
학습 가능한 파라미터 수:
- Full fine-tuning: d × k (예: 4096 × 4096 = 16M)
- LoRA: d × r + r × k = r(d + k) (예: 8 × 8192 = 65K)
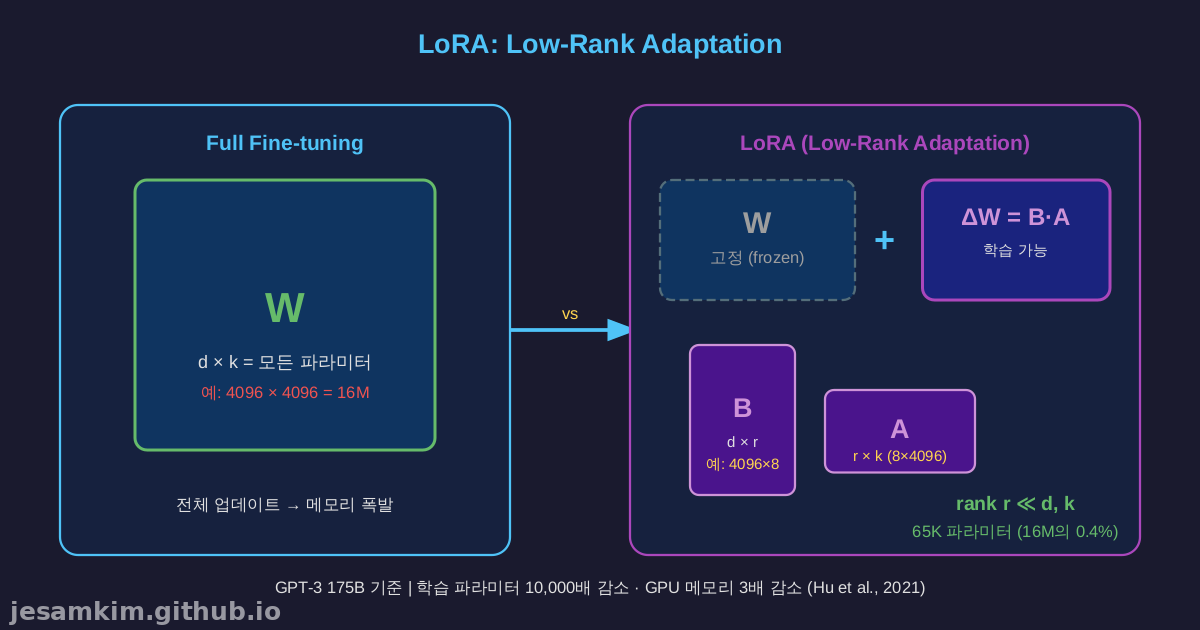
논문에서 보고한 성능:
- GPT-3 175B 대비 학습 가능 파라미터 10,000배 감소
- GPU 메모리 3배 감소
- RoBERTa, DeBERTa, GPT-2에서 full fine-tuning과 동등 이상 성능
- 추론 시 ΔW를 W에 병합하므로 추가 latency 없음
QLoRA: Quantized LoRA
QLoRA(Dettmers et al., 2023)는 LoRA에 양자화를 결합한 기법으로 NeurIPS 2023에 발표되었습니다.
핵심 혁신 3가지:
- 4-bit NormalFloat (NF4): 정규분포 가중치에 최적화된 4비트 데이터 타입
- Double Quantization: 양자화 상수 자체도 양자화 (추가 메모리 0.37비트/파라미터 절약)
- Paged Optimizers: CPU-GPU 메모리 간 자동 페이징으로 OOM 방지
실험 결과:
- 65B 모델을 단일 48GB GPU에서 파인튜닝 가능
- 16비트 LoRA 대비 성능 저하 1% 미만
언제 어떤 기법을 쓸까
| 방법 | GPU 메모리 | 학습 시간 | 성능 | 사용 시점 |
|---|---|---|---|---|
| Full FT | 200GB+ | 매우 느림 | 100% | 새 태스크, 대규모 데이터 |
| LoRA | 80GB | 중간 | 98~100% | 일반 파인튜닝 |
| QLoRA | 24GB | 느림 | 97~99% | 단일 GPU, 빠른 실험 |
실전 권장사항:
- 프로토타입 단계: QLoRA로 빠르게 검증 (rank=8~16)
- 프로덕션 배포: LoRA로 재학습 (rank=32~64), 성능 최적화
- 대규모 도메인 전환: Full fine-tuning 고려 (데이터 10만+ 개)
4. 실전 파인튜닝 파이프라인
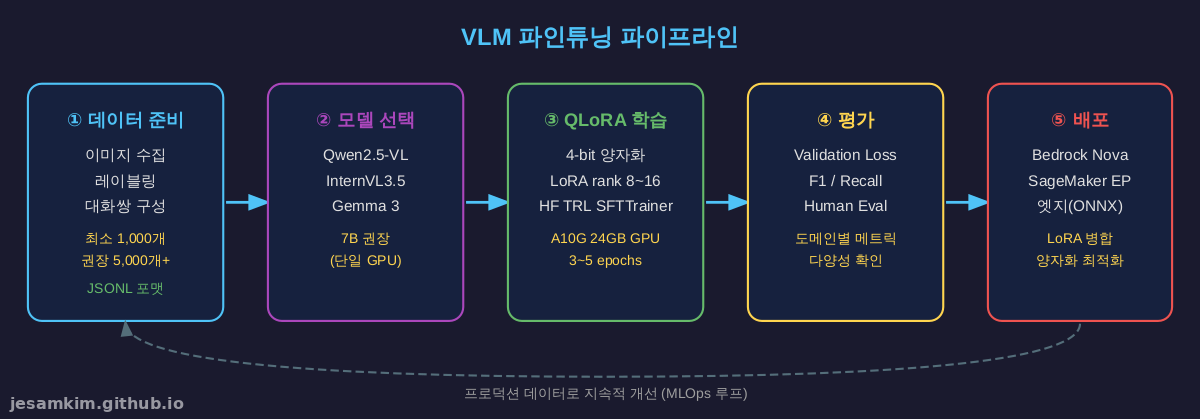
4.1 데이터 준비
VLM 파인튜닝은 이미지-대화 쌍 데이터가 필요합니다. 대화는 다중 턴(multi-turn)을 지원하며, 각 턴은 user 또는 assistant 역할을 가집니다.
예시 데이터 구조 (JSON):
{
"messages": [
{
"role": "user",
"content": [
{"type": "image", "url": "s3://bucket/safety/IMG_001.jpg"},
{"type": "text", "text": "이 현장의 안전 위반 사항을 나열해주세요."}
]
},
{
"role": "assistant",
"content": "1. 3번 작업자: 안전모 미착용\n2. 5번 구역: 추락방지망 미설치\n3. 지게차: 후방 경고등 고장"
}
]
}
데이터 품질 체크리스트:
- 이미지 해상도: 최소 512×512, 권장 1024×1024 (고해상도일수록 디테일 학습 향상)
- 다양성: 조명, 각도, 배경이 다양해야 일반화 성능 향상
- 레이블 일관성: 동일한 상황에 대해 다른 답변이 나오지 않도록 검수 필수
- 대화 자연스러움: “작업자가 안전모를 착용했습니까?” 같은 인공적 질문보다 “이 사진에서 주의할 점은?“이 효과적
필요한 데이터 양:
- 최소 1,000개: 기본 개념 학습 가능 (실험용)
- 5,000~10,000개: 프로덕션 수준 (일반 도메인)
- 50,000개 이상: 복잡한 시각적 추론, 다중 객체 관계 (고급)
4.2 HuggingFace TRL + QLoRA 학습
HuggingFace TRL 라이브러리의 SFTTrainer가 VLM을 지원합니다. 공식 쿡북에서 Qwen2-VL-7B 예제를 제공합니다.
핵심 코드 구조:
from transformers import Qwen2VLForConditionalGeneration, AutoProcessor
from trl import SFTConfig, SFTTrainer
from peft import LoraConfig
import torch
# 1. 모델과 프로세서 로드 (4비트 양자화)
model = Qwen2VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2-VL-7B-Instruct",
torch_dtype=torch.bfloat16,
load_in_4bit=True, # QLoRA
device_map="auto"
)
processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct")
# 2. LoRA 설정
lora_config = LoraConfig(
r=16, # rank (높을수록 표현력↑, 메모리↑)
lora_alpha=32, # scaling factor
target_modules=["q_proj", "v_proj", "k_proj", "o_proj"], # attention layers
lora_dropout=0.05,
bias="none"
)
# 3. 학습 설정
training_args = SFTConfig(
output_dir="./output",
per_device_train_batch_size=2,
gradient_accumulation_steps=8, # effective batch size = 16
num_train_epochs=3,
learning_rate=2e-4,
lr_scheduler_type="cosine",
warmup_ratio=0.1,
logging_steps=10,
save_strategy="epoch",
fp16=False,
bf16=True, # A100/H100에서 권장
max_seq_length=2048,
dataset_text_field="messages", # 대화 필드명
dataset_kwargs={"skip_prepare_dataset": True}
)
# 4. 트레이너 생성 및 학습
trainer = SFTTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
peft_config=lora_config,
tokenizer=processor.tokenizer,
)
trainer.train()
trainer.save_model("./final_model")
하이퍼파라미터 튜닝 가이드:
- rank (r): 8 (빠른 실험) → 16 (일반) → 32 (고성능)
- learning rate: 1e-4 ~ 5e-4 (LoRA는 full FT보다 10배 큰 LR 사용)
- batch size: GPU 메모리에 맞춰 조정 (gradient accumulation으로 effective batch 확보)
- epoch: 보통 3~5회 (과적합 주의)
4.3 학습 모니터링
학습 중 확인할 지표:
- Training Loss: 감소 추세 확인 (plateau 되면 조기 종료)
- Validation Loss: train loss와 격차 확인 (과적합 탐지)
- Sample 추론: 매 epoch마다 test 이미지로 실제 출력 확인
Weights & Biases 연동 예시:
import wandb
wandb.init(project="vlm-finetuning", name="qwen2-vl-safety")
training_args = SFTConfig(
...
report_to="wandb",
logging_steps=10
)
4.4 평가
정량적 평가:
- Exact Match (EM): 정답과 완전 일치 비율 (객관식, 분류)
- F1 Score: precision/recall 균형 (객체 검출, NER)
- BLEU/ROUGE: 텍스트 생성 품질 (설명, 캡션)
정성적 평가:
- Human Eval: 실제 사용자가 응답 품질 평가 (5점 척도)
- Domain Expert Review: 전문가가 기술적 정확성 검증
실전 팁: 정량 지표만으로는 불충분합니다. “안전모 미착용"을 “헬멧 없음"으로 표현해도 의미는 동일하지만 BLEU 점수는 낮게 나옵니다. 반드시 실제 사용 시나리오로 테스트하세요.
5. AWS에서의 VLM 파인튜닝
AWS는 두 가지 경로로 VLM 파인튜닝을 지원합니다.
5.1 Amazon Bedrock - Nova 모델 파인튜닝
2025년 3월 공개된 Amazon Nova 기술 보고서(arXiv 2506.12103)에 따르면, Nova는 멀티모달 파인튜닝을 지원합니다.
지원 모델:
- Nova Pro: 텍스트 + 이미지 입력으로 supervised fine-tuning (SFT)
- Nova Lite: 텍스트 + 이미지 SFT
- Nova 2 Lite: Bedrock과 SageMaker 모두 지원
- Nova Micro: 텍스트 전용 파인튜닝
파인튜닝 프로세스 (공식 문서):
- S3에 데이터 업로드 (JSONL 포맷)
{"messages": [{"role": "user", "content": [{"image": {"s3Uri": "s3://..."}, "text": "질문"}]}, {"role": "assistant", "content": "답변"}]}
- Bedrock 콘솔 또는 SDK로 파인튜닝 작업 생성
import boto3
bedrock = boto3.client('bedrock')
response = bedrock.create_model_customization_job(
jobName='safety-vlm-nova-pro',
customModelName='nova-pro-safety-v1',
roleArn='arn:aws:iam::...:role/BedrockCustomizationRole',
baseModelIdentifier='amazon.nova-pro-v1:0',
trainingDataConfig={'s3Uri': 's3://my-bucket/train/'},
validationDataConfig={'s3Uri': 's3://my-bucket/val/'},
hyperParameters={
'epochCount': '3',
'batchSize': '8',
'learningRate': '0.0001'
}
)
- 학습 완료 후 전용 엔드포인트로 추론
bedrock_runtime = boto3.client('bedrock-runtime')
response = bedrock_runtime.invoke_model(
modelId='arn:aws:bedrock:...:custom-model/nova-pro-safety-v1',
body=json.dumps({
"messages": [{"role": "user", "content": [{"image": {"s3": {...}}, "text": "안전 점검"}]}],
"inferenceConfig": {"maxTokens": 512}
})
)
비용 예시 (us-east-1 기준, 2026년 3월):
- 파인튜닝/추론 가격은 공식 Nova 가격 페이지 참조
5.2 SageMaker - 오픈소스 VLM 파인튜닝
SageMaker AI에서 Qwen2.5-VL 같은 오픈소스 모델을 파인튜닝할 수 있습니다.
추천 구성:
- 인스턴스: ml.g5.2xlarge (A10G 24GB) - 7B 모델 QLoRA 가능
- 컨테이너: HuggingFace DLC (Deep Learning Container) - TRL 포함
- 스팟 인스턴스: 비용 70% 절감 (학습 시간 여유 있을 때)
예시 학습 스크립트 (train.py):
# 위의 HuggingFace TRL 코드와 동일
# SageMaker는 /opt/ml/input/data/train 경로에 데이터 제공
SageMaker 학습 작업 실행:
from sagemaker.huggingface import HuggingFace
huggingface_estimator = HuggingFace(
entry_point='train.py',
instance_type='ml.g5.2xlarge',
instance_count=1,
transformers_version='4.36',
pytorch_version='2.1',
py_version='py310',
hyperparameters={
'epochs': 3,
'train_batch_size': 2,
'learning_rate': 2e-4
}
)
huggingface_estimator.fit({'train': 's3://my-bucket/train/'})
배포:
predictor = huggingface_estimator.deploy(
initial_instance_count=1,
instance_type='ml.g5.xlarge', # 추론은 더 작은 인스턴스 가능
endpoint_name='qwen2-vl-safety'
)
result = predictor.predict({
"inputs": {
"image": base64_encoded_image,
"text": "안전 점검 결과는?"
}
})
Bedrock vs SageMaker 선택 기준
| 기준 | Bedrock Nova | SageMaker 오픈소스 |
|---|---|---|
| 셋업 복잡도 | 낮음 (완전 관리형) | 중간 (컨테이너 설정 필요) |
| 모델 선택 | Nova Pro/Lite만 | 모든 오픈소스 VLM |
| 비용 | 토큰 기반 과금 | 인스턴스 시간 과금 |
| 커스터마이징 | 제한적 | 완전 자유 |
| 추천 시점 | 빠른 PoC, Nova 성능 충분 | 고급 튜닝, 특정 모델 필요 |
실전 조언: 먼저 Bedrock Nova로 프로토타입을 만들어 비즈니스 가치를 검증하고, 성능이 부족하거나 특수 요구사항이 있으면 SageMaker AI로 이전하는 전략이 효과적입니다.
6. 도메인별 응용 시나리오
6.1 건설 현장 안전 관리
설계 가능한 시스템:
- 현장 CCTV 또는 드론 영상을 실시간 분석
- 안전모, 안전화, 안전벨트 착용 여부 자동 감지
- 위험 구역 진입, 장비 오작동 탐지
- 일일 안전 리포트 자동 생성 (위반 사항 요약 + 스냅샷)
데이터 수집:
- 기존 현장 CCTV 녹화 영상에서 프레임 추출 (5초 간격)
- 안전 관리자가 위반 사항 레이블링 (라벨링 툴: CVAT, Label Studio)
- 예상 데이터량: 10,000~30,000 이미지 (3개월 현장 운영 시)
파인튜닝 전략:
- Base model: Qwen2.5-VL-7B (범용 객체 인식 성능 우수)
- 추가 학습: 해당 건설사의 안전 규정 코드북 (색상별 직급, 특수 장비)
- 출력 포맷: JSON {“violations”: [{“type”: “헬멧 미착용”, “location”: “3번 구역”, “worker_id”: “추정 불가”}]}
6.2 패션 상품 자동 분류
설계 가능한 시스템:
- 상품 이미지를 업로드하면 카테고리, 색상, 스타일, 시즌 자동 태깅
- 기존 카탈로그와 유사 상품 검색 (임베딩 기반)
- 모델 착용 사진에서 코디 아이템 자동 인식
데이터 수집:
- 기존 상품 DB에서 이미지 + 메타데이터 추출
- “이 상품을 설명해주세요” → “봄/여름 시즌의 오버핏 셔츠입니다. 색상은 라이트 베이지이며…” 형식
- 예상 데이터량: 50,000~100,000 상품 (대형 쇼핑몰 기준)
파인튜닝 전략:
- Base model: InternVL3.5 또는 Qwen2.5-VL-7B
- 추가 학습: 해당 브랜드의 스타일 가이드, SKU 체계
- Multi-task: 캡션 생성 + 속성 추출 동시 학습
6.3 제조 불량 검출
설계 가능한 시스템:
- 제품 검사 카메라 영상을 실시간 분석
- 표면 스크래치, 변색, 조립 불량 자동 분류
- 불량 유형별 통계 및 트렌드 분석
데이터 수집:
- 양품 vs 불량품 이미지 수집 (불량품은 소량이므로 data augmentation 필수)
- 불량 부위에 bounding box 또는 segmentation mask 추가
- 예상 데이터량: 5,000~10,000 이미지 (불량 유형 10가지 기준)
파인튜닝 전략:
- Base model: Qwen2.5-VL-3B (엣지 디바이스 배포 고려)
- 추가 학습: 각 불량 유형의 시각적 패턴 + 불량 코드 매핑
- Few-shot learning: 새로운 불량 유형 발생 시 소량 데이터로 빠르게 추가 학습
7. 주의사항과 베스트 프랙티스
데이터 품질이 전부
파인튜닝의 성공은 데이터 품질에 90% 달려있습니다.
흔한 실수:
- 레이블 불일치: 같은 이미지에 대해 A는 “안전”, B는 “위험"으로 레이블링
- 편향된 분포: 양품 90%, 불량품 10% → 모델이 항상 “양품"이라고 답함
- 저해상도 이미지: 256×256 이미지로 미세한 결함 검출 시도
해결책:
- 레이블링 가이드라인 문서화 + 크로스 체크
- 클래스 불균형 시 oversampling 또는 class weighting 적용
- 최소 512×512, 가능하면 1024×1024 이상 사용
과적합 방지
적은 데이터로 파인튜닝하면 과적합(overfitting)이 발생하기 쉽습니다.
증상:
- Training loss는 0에 가깝지만 validation loss는 높음
- 학습 데이터와 비슷한 이미지만 잘 맞추고 새로운 이미지는 틀림
대응:
- Data augmentation: 랜덤 크롭, 회전, 색상 조정으로 데이터 다양성 확보
- Early stopping: validation loss가 3 epoch 연속 증가하면 학습 중단
- Regularization: LoRA dropout 0.05~0.1 적용
- 더 많은 데이터: 최소 1,000개, 가능하면 5,000개 이상
평가 메트릭 선택
도메인에 따라 적절한 평가 지표가 다릅니다.
| 도메인 | 주요 메트릭 | 이유 |
|---|---|---|
| 안전 관리 | Recall | 위험 상황 놓치면 안 됨 (false negative 치명적) |
| 상품 분류 | Precision | 잘못된 태그가 고객 경험 해침 |
| 불량 검출 | F1 Score | 과검출/미검출 균형 필요 |
| 캡션 생성 | Human Eval | 자동 지표는 의미 파악 불가 |
실전 팁: 단일 메트릭에 의존하지 말고, 혼동 행렬(confusion matrix)을 확인해서 어떤 클래스를 자주 틀리는지 분석하세요.
추론 최적화
파인튜닝된 모델을 프로덕션에 배포할 때 고려사항:
Latency 요구사항:
- 실시간 (<100ms): 모델 양자화 (INT8, 심지어 INT4)
- 준실시간 (<1s): LoRA 어댑터 병합 후 배포
- 배치 처리 (수 초 이상 허용): 최적화 불필요
비용 최적화:
- Bedrock: 토큰 수 최소화 (이미지 해상도 조정, max_tokens 제한)
- SageMaker: Auto-scaling 설정 (트래픽 낮을 때 인스턴스 0으로)
- 엣지 배포: ONNX 변환 + TensorRT로 추론 가속
지속적 개선
파인튜닝은 일회성이 아니라 지속적 프로세스입니다.
설계 가능한 MLOps 파이프라인:
- 데이터 파이프라인: 프로덕션 추론 결과 중 confidence 낮은 샘플 자동 수집
- Human-in-the-loop: 전문가가 재검수 후 학습 데이터 추가
- 재학습 스케줄링: 새 데이터 1,000개 누적 시 자동 재학습
- A/B 테스팅: 새 모델과 기존 모델 성능 비교 후 배포
모니터링 지표:
- Prediction drift: 시간에 따른 출력 분포 변화 (데이터 분포 변화 탐지)
- User feedback: 사용자가 결과를 수정한 비율 (모델 품질 지표)
- Edge cases: 자주 틀리는 패턴 로깅 (다음 학습에 반영)
마치며
VLM 파인튜닝은 더 이상 대기업 연구소만의 영역이 아닙니다. QLoRA 덕분에 단일 GPU에서도 7B 모델을 학습할 수 있고, AWS Bedrock을 쓰면 인프라 관리 없이 바로 시작할 수 있습니다.
핵심은 데이터 품질과 명확한 평가 기준입니다. 1만 개의 저품질 데이터보다 1,000개의 고품질 데이터가 낫습니다. 그리고 벤치마크 점수보다 실제 사용 시나리오에서의 성능이 중요합니다.
지금 당장 시작해볼 수 있는 첫 단계:
- HuggingFace에서 Qwen2.5-VL-7B QLoRA 쿡북 따라하기
- 자신의 도메인 이미지 100개로 프로토타입 학습 (1~2시간 소요)
- 추론 결과 확인하고 데이터 보강 계획 수립
프로덕션 배포를 고려한다면 AWS Bedrock Nova로 PoC를 만들어 비즈니스 가치를 먼저 검증하는 것을 추천합니다. 성능이 충분하면 그대로 쓰고, 더 높은 성능이 필요하면 SageMaker AI에서 오픈소스 모델을 파인튜닝하는 것이 효율적인 경로입니다.
References
- LoRA: Low-Rank Adaptation of Large Language Models (Hu et al., 2021)
- QLoRA: Efficient Finetuning of Quantized LLMs (Dettmers et al., 2023)
- Qwen2.5-VL GitHub Repository
- InternVL3.5 GitHub Repository
- Amazon Nova Technical Report (arXiv 2506.12103)
- AWS Bedrock Nova Fine-tuning Documentation
- HuggingFace VLM Fine-tuning Cookbook