📌 이 글에서 다루는 Nova Forge SFT 실험의 전체 코드와 데이터셋은 GitHub 레포에서 확인할 수 있습니다.
1. 왜 Fine-tuning인가: RAG vs Fine-tuning 판단 기준
대규모 언어 모델을 특정 도메인이나 태스크에 맞추려 할 때, 두 가지 주요 접근법이 있습니다. Retrieval-Augmented Generation(RAG)과 Fine-tuning입니다.
RAG가 적합한 경우
- 최신 정보나 사실 지식이 필요한 경우 (예: 제품 카탈로그, 법률 문서)
- 지식이 자주 변경되는 경우
- 출처 추적이 중요한 경우 (환각 방지)
- 프롬프트만으로 해결 가능한 경우
Fine-tuning이 적합한 경우
- 일관된 스타일이나 포맷을 학습해야 하는 경우 (예: 브랜드 톤, 응답 구조)
- 복잡한 추론 패턴을 학습해야 하는 경우
- 새로운 행동 양식을 학습해야 하는 경우 (예: 코드 생성 스타일)
- 레이턴시가 중요한 경우 (RAG의 검색 오버헤드 제거)
간단히 말하면, 무엇을 아는가(knowledge)의 문제라면 RAG를, 어떻게 행동하는가(behavior)의 문제라면 Fine-tuning을 선택하는 것이 일반적입니다.
2. Fine-tuning의 함정: Catastrophic Forgetting
하지만 Fine-tuning에는 치명적인 함정이 있습니다. 바로 Catastrophic Forgetting(치명적 망각)입니다.
문제의 본질
전통적인 Full Fine-tuning은 모델의 모든 파라미터를 업데이트합니다. 특정 도메인 데이터로 훈련하면 해당 태스크 성능은 향상되지만, 원래 학습했던 다른 능력들이 급격히 저하되는 현상이 발생합니다.
예를 들어:
- 의료 도메인으로 파인튜닝 → 일반 상식 질문에 대한 답변 능력 저하
- 한국어 데이터로 파인튜닝 → 영어 능력 저하
- 코드 생성으로 파인튜닝 → 자연어 이해 능력 저하
이는 신경망의 가중치가 새로운 정보로 덮어써지기 때문입니다. 수십억 개의 파라미터가 모두 변경되면서, 사전 학습 단계에서 얻은 범용 지식이 손실됩니다.
Catastrophic Forgetting의 측정
이 현상은 벤치마크 점수 하락으로 확인할 수 있습니다:
- MMLU(Massive Multitask Language Understanding): 범용 지식
- HellaSwag: 상식 추론
- GSM8K: 수학 능력
- HumanEval: 코드 생성
도메인 데이터로 Full Fine-tuning 후 이 벤치마크들의 점수가 떨어지면, Catastrophic Forgetting이 발생한 것입니다.
실제 사례: Forgetting의 영향
실제 파인튜닝 실험에서 다음과 같은 패턴이 관찰되었습니다:
Full Fine-tuning의 전형적 패턴
- 도메인 특화 파인튜닝 후:
- 목표 태스크 성능: 크게 향상 (20-35%p)
- 범용 벤치마크(MMLU, HellaSwag): 심각한 하락 (10-20%p)
- 다른 도메인 능력(코드, 수학): 급격한 저하
LoRA/QLoRA의 전형적 패턴
- 도메인 특화 파인튜닝 후:
- 목표 태스크 성능: 상당한 향상 (Full FT 대비 80-90% 수준)
- 범용 벤치마크: 미미한 하락 (1-3%p)
- 다른 도메인 능력: 대부분 유지
이 차이는 LoRA가 원본 가중치를 동결하여 기존 지식을 보존하기 때문입니다.
Data Mixing의 효과
Data Mixing은 도메인 데이터와 범용 데이터를 혼합하여 훈련하는 기법입니다. Catastrophic Forgetting을 완화하는 가장 효과적인 방법 중 하나입니다.
Data Mixing 비율별 경향 (Full Fine-tuning 기준):
| Data Mix 비율 (도메인:범용) | 도메인 성능 | 범용 능력 유지 | 종합 평가 |
|---|---|---|---|
| 100:0 (도메인만) | 매우 높음 | 심각한 하락 | ❌ 실용성 낮음 |
| 80:20 | 높음 | 중간 수준 하락 | ⚠️ 주의 필요 |
| 50:50 | 중간~높음 | 경미한 하락 | ✅ 권장 |
| 20:80 | 중간 수준 | 대부분 유지 | ⚠️ 도메인 성능 부족 |
| 0:100 (범용만) | 낮음 | 유지 | ❌ 목표 미달 |
핵심 교훈:
- 50:50 비율이 대부분의 경우 최적
- 도메인 성능 향상과 범용 능력 보존의 균형
- Full Fine-tuning에서도 Data Mixing으로 Forgetting을 크게 완화 가능
LoRA + Data Mixing 조합의 시너지:
LoRA 자체가 가중치를 동결하므로 Forgetting을 근본적으로 방지하지만, Data Mixing을 추가하면 더욱 강력합니다:
- LoRA만 사용: 범용 능력 소폭 하락
- LoRA + Data Mixing: 범용 능력 거의 완전 보존 + 도메인 성능도 더 향상
Data Mixing이 LoRA의 학습을 보조하여 도메인 적응과 지식 보존을 동시에 최적화합니다.
3. PEFT의 등장: 원본 가중치를 지키는 전략
Parameter-Efficient Fine-Tuning(PEFT)는 이 문제를 해결하기 위해 등장했습니다. 핵심 아이디어는 간단합니다:
원본 모델의 가중치는 동결(freeze)하고, 작은 수의 추가 파라미터만 훈련한다.
이 접근법은 두 가지 이점을 제공합니다:
- Catastrophic Forgetting 방지: 원본 가중치가 보존되므로 기존 능력 유지
- 메모리/연산 효율성: 훈련할 파라미터 수가 1% 미만으로 감소
PEFT 진화 타임라인
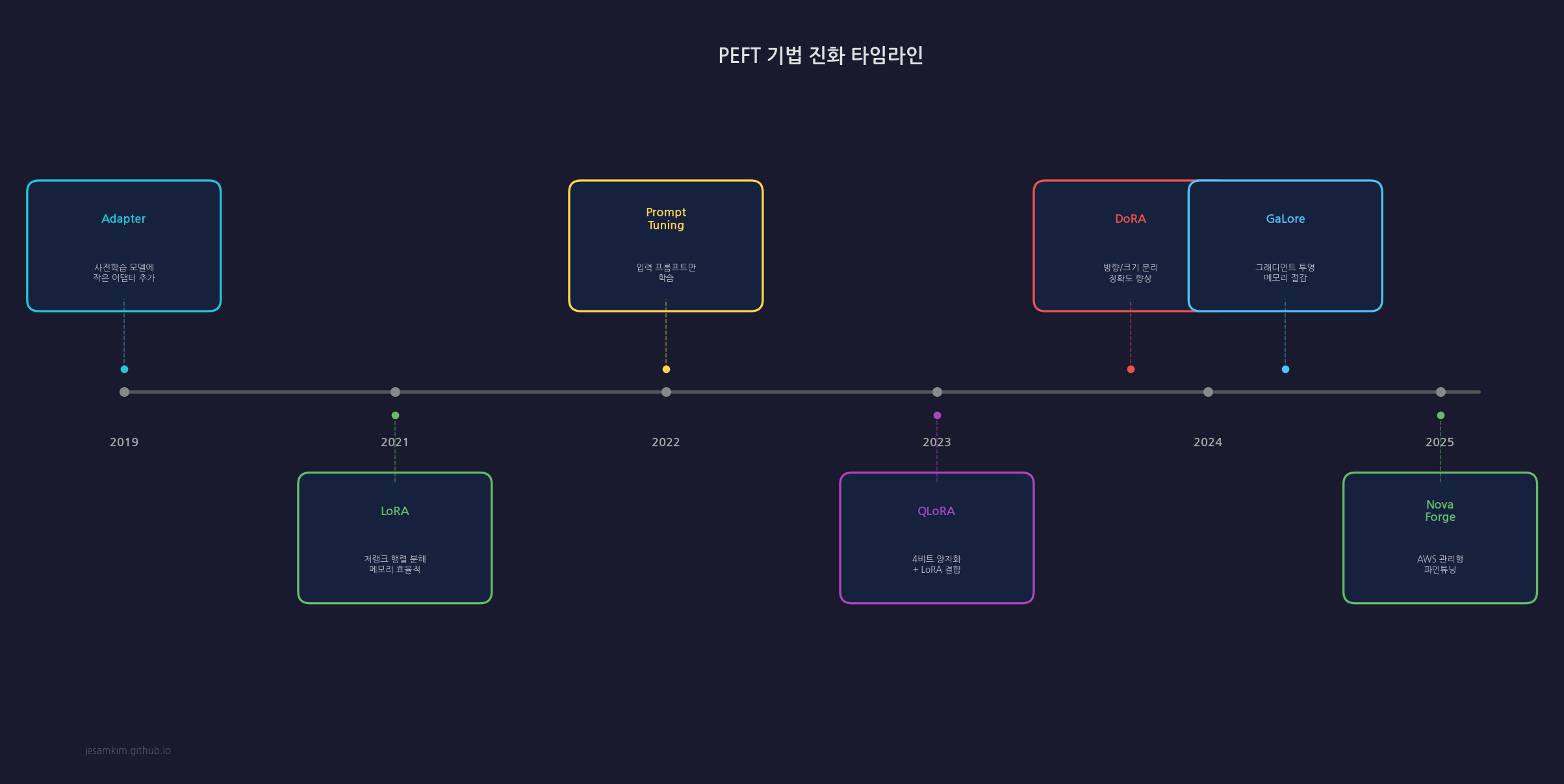
PEFT 기법들은 지난 몇 년간 빠르게 진화했습니다:
- 2019: Adapter Layers — 각 Transformer 레이어에 작은 병목 네트워크 삽입
- 2021: LoRA — Low-rank 행렬 분해로 어댑터 단순화
- 2023: QLoRA — 양자화 + LoRA로 메모리 사용량 극적 감소
- 2024: DoRA — 가중치를 magnitude와 direction으로 분해
- 2024: LoRA+ — 학습률 스케일링으로 성능 개선
- 2024: GaLore — 그래디언트 저차원 투영으로 메모리 효율 극대화
4. PEFT 기법 비교: 구조와 성능
LoRA: 저차원 어댑터의 시작
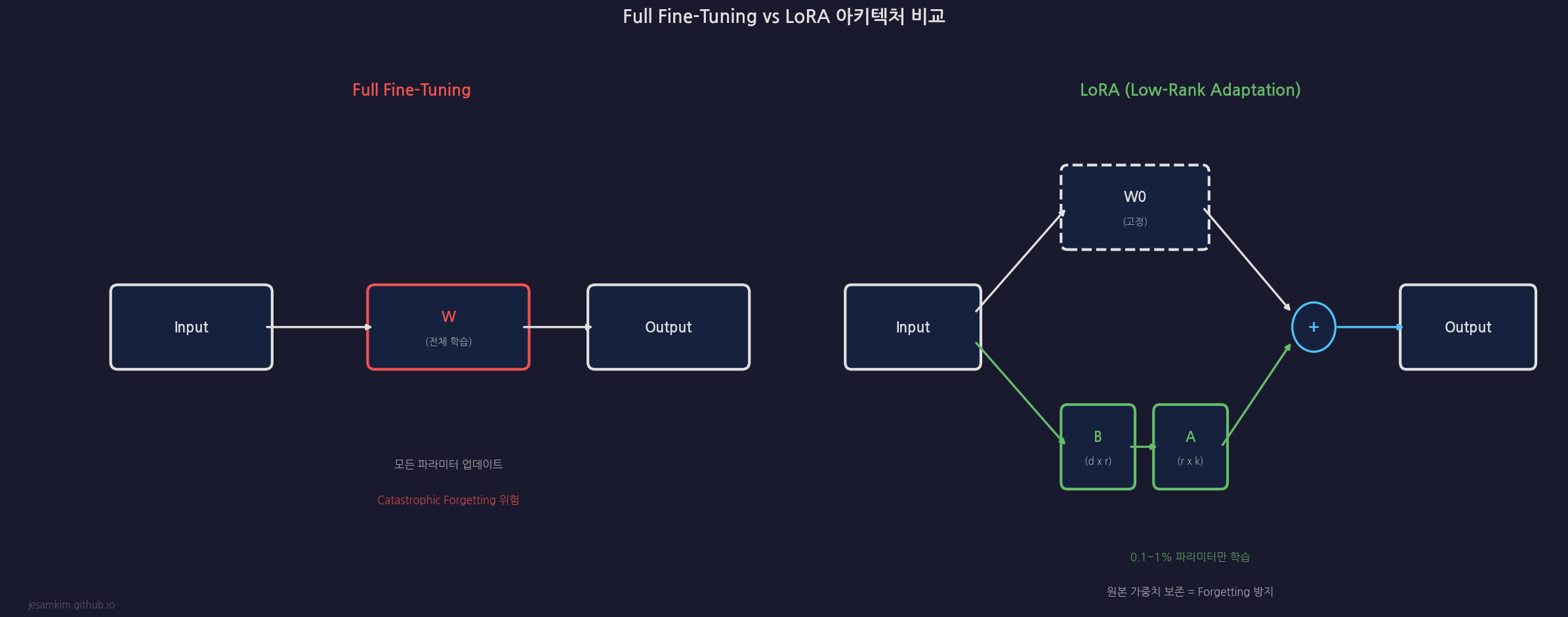
LoRA(Low-Rank Adaptation)는 2021년 Microsoft가 발표한 기법으로, PEFT 분야의 표준이 되었습니다. 핵심 아이디어는 가중치 업데이트가 낮은 고유 차원(intrinsic dimension)을 가진다는 관찰에서 출발합니다.
수학적 정의:
사전 학습된 가중치 행렬 W0 ∈ ℝd×k가 있을 때, 파인튜닝 후의 가중치는:
W = W0 + ΔW = W0 + BA
여기서:
- W0 ∈ ℝd×k는 동결된 원본 가중치
- B ∈ ℝd×r, A ∈ ℝr×k는 훈련 가능한 저차원 행렬
- r ≪ min(d, k)는 rank (일반적으로 4~64)
- 순전파: h = W0x + BAx
파라미터 감소량:
원본 Full Fine-tuning: d × k개 파라미터 LoRA: d × r + r × k = r × (d + k)개 파라미터
예를 들어, d=4096, k=4096인 레이어에서:
- Full: 16,777,216개 (16M)
- LoRA (r=16): 131,072개 (131K) → 99.2% 감소
- LoRA (r=64): 524,288개 (524K) → 96.9% 감소
핵심 하이퍼파라미터:
rank (r)
- 어댑터의 표현력을 결정
- 낮은 rank (4-8): 간단한 태스크, 작은 데이터셋 (overfitting 방지)
- 중간 rank (16-32): 대부분의 경우 적합
- 높은 rank (64-128): 복잡한 추론, 대량 데이터
alpha (α)
- LoRA 업데이트의 스케일링 팩터
- 실제 적용: ΔW × (α / r)
- 일반적으로 α = 2r 또는 α = 4r
- 높은 alpha: 더 공격적인 학습 (도메인 적응 강화)
- 낮은 alpha: 보수적 학습 (원본 능력 보존)
target_modules
- Transformer의 어느 레이어에 LoRA를 적용할지
- 기본: Query, Value 프로젝션 (q_proj, v_proj)
- 확장: Key, Output, FFN 포함 (k_proj, o_proj, gate_proj, up_proj, down_proj)
- 더 많은 모듈 = 더 높은 표현력, 하지만 메모리/계산 증가
초기화 전략:
LoRA는 A와 B를 비대칭적으로 초기화합니다:
- A 행렬: 랜덤 Gaussian 초기화 (평균 0, 표준편차 1/r)
- B 행렬: 0으로 초기화
이 방식은 훈련 시작 시 ΔW = BA = 0이 되어, 원본 모델의 출력을 그대로 유지하면서 학습이 시작됩니다. 이는 안정적인 수렴에 기여합니다.
장점:
- 원본 가중치 동결 → Catastrophic Forgetting 근본적 방지
- 추론 시 W0 + BA를 하나의 행렬로 병합 가능 (지연시간 오버헤드 없음)
- 여러 LoRA 어댑터를 교체하여 다중 태스크 지원
- HuggingFace PEFT 라이브러리로 간편한 구현
한계:
- 낮은 rank에서는 Full Fine-tuning 대비 성능 갭 존재
- 매우 복잡한 도메인 변화에서는 높은 rank 필요 (메모리 이점 감소)
QLoRA: 양자화로 메모리 장벽 돌파
QLoRA(Quantized LoRA)는 2023년 워싱턴 대학교에서 발표한 혁신적인 기법으로, LoRA에 4-bit 양자화를 결합하여 메모리 사용량을 극적으로 감소시킵니다.
핵심 구성 요소:
4-bit NormalFloat(NF4) 양자화
- 기존 모델 가중치를 4-bit로 압축
- NF4는 정규분포에 최적화된 데이터 타입
- FP16 대비 메모리 사용량 75% 감소 (16-bit → 4-bit)
Double Quantization
- 양자화 상수(quantization constants) 자체를 다시 양자화
- 평균 0.37 bit/parameter 추가 절약
- 65B 모델에서 약 3GB 추가 메모리 절감
Paged Optimizers
- NVIDIA Unified Memory를 활용한 CPU-GPU 메모리 관리
- GPU 메모리 부족 시 자동으로 CPU로 페이징
- OOM(Out of Memory) 에러 방지
LoRA 어댑터는 FP16/BF16 유지
- 학습 안정성과 정확도 보존
- 4-bit base + 16-bit adapter의 하이브리드 정밀도
메모리 계산 예시:
65B 파라미터 모델 파인튜닝:
| 방법 | Base 모델 | Optimizer | Gradient | LoRA | 총합 |
|---|---|---|---|---|---|
| Full FP16 | 130GB | 260GB | 130GB | 0GB | 520GB |
| LoRA FP16 | 130GB | 2GB | 2GB | 1GB | 135GB |
| QLoRA 4-bit | 33GB | 2GB | 2GB | 1GB | 38GB |
QLoRA는 단일 48GB GPU(A6000, RTX 6000 Ada)에서 65B 모델 파인튜닝을 가능하게 합니다.
성능 벤치마크:
QLoRA는 양자화로 인한 성능 저하가 매우 적습니다:
- Guanaco 65B 모델:
- Vicuna 벤치마크에서 ChatGPT 성능의 99.3% 달성 (QLoRA 논문)
- 단일 48GB GPU에서 24시간 훈련 가능
- Full 16-bit Fine-tuning 대비 1-3%p 이내의 성능 차이
구현 코드 예시 (HuggingFace PEFT):
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
from peft import LoraConfig, get_peft_model
# 4-bit 양자화 설정
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
)
# 모델 로드
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-70b-hf",
quantization_config=bnb_config,
device_map="auto"
)
# LoRA 설정
lora_config = LoraConfig(
r=16,
lora_alpha=64,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
)
model = get_peft_model(model, lora_config)
언제 QLoRA를 사용해야 하는가:
- ✅ GPU 메모리가 제한적인 경우 (RTX 4090, A10G, A100 40GB 등)
- ✅ 대형 모델(70B+)을 소형 GPU에서 파인튜닝해야 하는 경우
- ✅ 비용 절감이 중요한 경우 (작은 인스턴스 사용 가능)
- ⚠️ 추론 시 양자화 오버헤드가 있음 (LoRA 대비 약 20% 느림)
- ⚠️ 최고 성능이 필요한 프로덕션 환경에서는 Full LoRA 고려
DoRA: 가중치 분해로 표현력 향상
DoRA(Weight-Decomposed Low-Rank Adaptation)는 2024년 NVIDIA와 UC Berkeley 연구진이 발표한 기법으로, LoRA의 구조적 한계를 해결합니다.
LoRA의 한계:
LoRA는 가중치 업데이트를 저차원 공간에 제한하기 때문에, Full Fine-tuning이 탐색하는 가중치 공간의 일부만 접근할 수 있습니다. 특히 가중치의 magnitude(크기)와 direction(방향)을 독립적으로 조정하기 어렵습니다.
DoRA의 핵심 아이디어:
DoRA는 가중치를 명시적으로 magnitude와 direction으로 분해합니다:
W = m · (V / ||V||c)
여기서:
- m: magnitude (학습 가능한 스칼라 벡터)
- V: directional component (학습 가능한 행렬)
- ||V||c: column-wise norm
DoRA는 directional component에만 LoRA를 적용합니다:
W’ = m · ((V + BA) / ||V + BA||c)
수학적 분석:
Full Fine-tuning의 가중치 업데이트는 다음과 같이 분해됩니다:
ΔW = Δ||W|| · (W / ||W||) + ||W|| · Δ(W / ||W||)
- 첫 번째 항: magnitude 변화
- 두 번째 항: direction 변화
LoRA는 두 번째 항만 효과적으로 모델링하지만, DoRA는 두 항 모두를 독립적으로 학습합니다.
학습 역학 비교:
연구진은 gradient 업데이트 패턴을 분석한 결과, DoRA가 Full Fine-tuning과 더 유사한 학습 역학을 보인다는 것을 발견했습니다:
| 메트릭 | LoRA | DoRA | Full FT |
|---|---|---|---|
| Magnitude 변화율 | 낮음 | 높음 | 높음 |
| Direction 변화율 | 높음 | 높음 | 높음 |
| Gradient 상관관계 | 0.73 | 0.91 | 1.00 |
벤치마크 성능:
다양한 태스크에서 DoRA는 LoRA를 일관되게 능가합니다:
Commonsense Reasoning (8개 태스크):
- DoRA가 LoRA 대비 평균 1-2%p 향상
- Full Fine-tuning에 근접한 성능
Visual Instruction Tuning (LLaVA 1.5):
- DoRA가 LoRA 대비 1.5-2%p 향상
- 멀티모달 태스크에서도 효과적
일반적 경향:
- 동일한 rank에서 DoRA가 LoRA보다 우수
- 특히 복잡한 추론과 비전-언어 태스크에서 효과적
추가 메모리 비용:
DoRA는 magnitude 벡터를 추가로 학습하므로, LoRA보다 약간 더 많은 메모리를 사용합니다:
- LoRA: r × (d + k)
- DoRA: r × (d + k) + d (magnitude)
- 4096 차원 레이어에서 r=16일 때: 약 3% 추가
언제 DoRA를 사용해야 하는가:
- ✅ 최고 성능이 중요한 경우
- ✅ 충분한 훈련 데이터(5K+ 샘플)가 있는 경우
- ✅ 복잡한 도메인 적응이 필요한 경우
- ⚠️ 메모리가 극도로 제한적이면 LoRA 선택
- ⚠️ 훈련 시간이 LoRA 대비 약 10-15% 증가
LoRA+: 학습률 최적화
LoRA+는 2024년 발표된 기법으로, LoRA의 학습률 설정을 최적화하여 성능을 향상시킵니다. 놀랍도록 간단하지만 효과적인 개선입니다.
핵심 아이디어:
LoRA는 A와 B 두 개의 행렬을 학습하는데, 초기화 방식이 비대칭적입니다:
- A: 랜덤 초기화 (평균 0, 작은 분산)
- B: 0으로 초기화
이로 인해 학습 초기에 A와 B가 다른 gradient 규모를 가지게 되며, 동일한 학습률을 사용하면 비효율적인 학습이 발생합니다.
LoRA+의 해결책:
A 행렬과 B 행렬에 서로 다른 학습률 적용
- ηB = η (base learning rate)
- ηA = η / λ (λ는 학습률 비율, 보통 16~64)
일반적으로:
- B 행렬: 높은 학습률 (예: 2e-4)
- A 행렬: 낮은 학습률 (예: 3.125e-6, λ=64일 때)
이론적 근거:
연구진은 LoRA의 수렴 속도를 분석한 결과, A와 B에 대한 최적 학습률 비율이 존재한다는 것을 증명했습니다:
λopt ≈ r / η
여기서:
- r: LoRA rank
- η: base learning rate
예를 들어, r=16이고 η=1e-4일 때, λopt ≈ 16 / 1e-4 = 160,000… 이는 너무 크므로, 실용적으로는 λ = 16 ~ 64 정도가 적합합니다.
실험 결과:
다양한 태스크에서 LoRA+는 표준 LoRA를 일관되게 능가합니다:
- 평균 개선폭: 2-3%p
- 복잡한 추론 태스크(수학, 코드)에서 특히 효과적
- 대화 품질 벤치마크에서도 향상
수렴 속도:
LoRA+는 동일한 성능에 도달하는 데 필요한 훈련 스텝을 평균 30-40% 감소시킵니다:
- LoRA: 1000 스텝에서 수렴
- LoRA+: 600-700 스텝에서 수렴
이는 훈련 시간과 비용을 직접적으로 절감합니다.
하이퍼파라미터 가이드:
| λ 값 | 적합한 경우 | 특징 |
|---|---|---|
| 1 | 표준 LoRA | Baseline |
| 16 | 대부분의 경우 | 안전한 선택 |
| 32 | 복잡한 태스크 | 균형 잡힘 |
| 64 | 매우 복잡한 태스크 | Nova Forge 기본값 |
| 128+ | 실험적 | 불안정할 수 있음 |
Amazon Nova Forge 설정:
peft:
peft_scheme: "lora"
lora_tuning:
alpha: 64
lora_plus_lr_ratio: 64.0 # LoRA+ 활성화
구현 복잡도:
LoRA+는 기존 LoRA 코드에 단 몇 줄만 추가하면 구현 가능합니다:
# LoRA+: A와 B에 서로 다른 학습률 할당
optimizer = torch.optim.AdamW([
{'params': [p for n, p in model.named_parameters() if 'lora_A' in n],
'lr': base_lr / lambda_ratio},
{'params': [p for n, p in model.named_parameters() if 'lora_B' in n],
'lr': base_lr},
])
언제 LoRA+를 사용해야 하는가:
- ✅ 항상 사용 권장 — 추가 비용 없이 성능 향상
- ✅ 훈련 시간 단축이 중요한 경우
- ✅ 복잡한 추론 태스크 (수학, 코드, 논리)
- ⚠️ 매우 간단한 태스크에서는 이득이 적을 수 있음
GaLore: 그래디언트 차원 축소
GaLore(Gradient Low-Rank Projection)는 2024년 MIT와 Caltech 연구진이 발표한 혁신적인 기법으로, LoRA와는 완전히 다른 철학을 가지고 있습니다.
LoRA와의 근본적 차이:
- LoRA: 가중치의 일부만 학습 (원본 동결)
- GaLore: 모든 가중치를 학습하되, 그래디언트를 저차원으로 투영
이는 GaLore가 메모리 효율적인 Full Fine-tuning으로 작동한다는 것을 의미합니다.
핵심 아이디어:
신경망 학습 중 그래디언트 행렬이 낮은 고유 차원(low intrinsic rank)을 가진다는 관찰에서 출발합니다. GaLore는 이를 활용하여 그래디언트를 저차원 부공간에 투영합니다.
수학적 정의:
일반적인 그래디언트 업데이트:
Wt+1 = Wt - η · ∇L(Wt)
GaLore의 그래디언트 투영:
Glow-rank = PT · ∇L(W) · Q
여기서:
- P ∈ ℝd×r, Q ∈ ℝk×r: 투영 행렬 (SVD로 계산)
- r ≪ min(d, k): 저차원 rank
- Glow-rank ∈ ℝr×r: 압축된 그래디언트
알고리즘 흐름:
- Forward pass: 일반적인 순전파
- Backward pass: 풀 그래디언트 ∇L 계산
- SVD 투영: Glow-rank = PT · ∇L · Q
- 저차원 업데이트: optimizer는 Glow-rank만 저장
- 재투영: ΔW = P · ΔGlow-rank · QT
- 가중치 업데이트: W ← W - ΔW
메모리 절감 메커니즘:
GaLore는 optimizer state(momentum, variance)를 저차원 공간에만 유지합니다:
| 항목 | Full FT | GaLore (r=128) |
|---|---|---|
| 모델 가중치 (W) | d×k | d×k (동일) |
| Optimizer 1st moment | d×k | r×r |
| Optimizer 2nd moment | d×k | r×r |
| Gradient | d×k | r×r |
예를 들어, d=4096, k=4096, r=128인 경우:
- Full FT optimizer state: 16M × 2 = 32M 파라미터
- GaLore optimizer state: 16K × 2 = 32K 파라미터
- 메모리 감소: 99%
전체 모델(7B)에서:
- Full FT: ~120GB (모델 14GB + optimizer 84GB + gradient 22GB)
- GaLore: ~42GB (65% 감소)
투영 행렬 업데이트:
P와 Q는 고정되지 않고 주기적으로 업데이트됩니다:
# 매 T 스텝마다 SVD 재계산
if step % T == 0:
U, S, V = torch.svd_lowrank(grad, q=r)
P = U[:, :r]
Q = V[:, :r]
일반적으로 T = 200~500 스텝이 적합합니다.
실험 결과:
LLaMA 사전 학습 및 RoBERTa 파인튜닝 실험에서:
- 성능: Full Fine-tuning 대비 1%p 이내의 차이
- 메모리 효율: 60-65% 절감
- 범용성: 사전 학습과 파인튜닝 모두 적용 가능
GaLore는 LoRA보다 Full Fine-tuning에 더 가까운 성능을 달성합니다.
장점:
- Full Fine-tuning에 가까운 성능 (LoRA보다 우수)
- optimizer state 메모리 대폭 감소
- 모든 파라미터가 업데이트되므로 표현력 최대화
단점:
- SVD 계산 오버헤드 (훈련 시간 10-15% 증가)
- 모든 가중치가 변경되므로 Catastrophic Forgetting 위험 존재
- LoRA처럼 원본 가중치를 동결하지 않음
- Data Mixing이나 regularization 필요
- 추론 시 전체 모델을 배포해야 함 (LoRA처럼 어댑터 교체 불가)
언제 GaLore를 사용해야 하는가:
- ✅ 사전 학습(Pre-training)이나 Continued Pre-training
- ✅ 매우 큰 모델을 제한된 메모리에서 Full FT 해야 하는 경우
- ✅ 최고 성능이 필요하고 Forgetting 위험을 감수할 수 있는 경우
- ⚠️ 일반적인 파인튜닝에서는 LoRA+ 또는 DoRA가 더 안전
- ⚠️ 추론 시 여러 어댑터를 교체해야 한다면 LoRA 계열 선택
성능 비교 (대략적 추정치)
| 기법 | 훈련 파라미터 | 메모리 사용량 | Full FT 대비 성능 | Forgetting 방어 |
|---|---|---|---|---|
| Full Fine-tuning | 100% | 100% | 100% | ⚠️ 매우 취약 |
| Adapter | ~2% | ~70% | 95-98% | ✅ 양호 |
| LoRA (r=16) | ~0.5% | ~50% | 97-99% | ✅ 우수 |
| QLoRA (4-bit) | ~0.5% | ~25% | 96-98% | ✅ 우수 |
| DoRA | ~0.6% | ~55% | 98-99.5% | ✅ 우수 |
| LoRA+ | ~0.5% | ~50% | 98-99.5% | ✅ 우수 |
| GaLore | 100% (메모리 효율) | ~35% | 99-100% | ⚠️ 보통 |
주: 메모리 사용량과 성능 수치는 일반적인 경향을 나타내는 대략적 추정치이며, 실제 값은 모델 크기와 태스크에 따라 달라질 수 있습니다.
Forgetting 방어 메커니즘:
- LoRA 계열: 원본 가중치 동결 → 근본적으로 방지
- GaLore: 모든 파라미터 업데이트 → 일부 forgetting 발생 가능 (단, 적은 편)
5. Amazon Nova Forge: 최신 커스터마이징 파이프라인
Amazon Nova Forge는 AWS가 제공하는 Nova 모델 전용 파인튜닝 플랫폼입니다. 다음 커스터마이징 방법을 지원합니다:
지원 방법론
1. Supervised Fine-Tuning (SFT)
가장 일반적인 파인튜닝 방법으로, input-output 페어 데이터로 모델을 학습시킵니다.
데이터 형식:
{"messages": [
{"role": "user", "content": "질문 또는 명령"},
{"role": "assistant", "content": "원하는 답변"}
]}
⚠️ 실제 Nova 모델 주의사항: Nova 모델의 SFT 데이터는 Converse API 형식을 사용합니다.
content필드가 문자열이 아닌 배열 형태이며,system필드는 messages 외부 최상위에 위치합니다:{ "system": [{"text": "시스템 프롬프트"}], "messages": [ {"role": "user", "content": [{"text": "질문 또는 명령"}]}, {"role": "assistant", "content": [{"text": "원하는 답변"}]} ] }이는 Claude, Titan 등 다른 Bedrock 모델의 JSONL 형식과 다르므로 주의가 필요합니다.
적합한 경우:
- 특정 도메인 지식 학습 (의료, 법률, 금융)
- 특정 응답 스타일/포맷 학습
- 태스크별 행동 패턴 학습
- 1K~10K 샘플로 효과적
지원 기법:
- LoRA (rank: 8~64)
- LoRA+ (lora_plus_lr_ratio: 16~64)
- Full-rank (대량 데이터, 높은 GPU 메모리)
2. Direct Preference Optimization (DPO)
DPO는 인간 선호도를 직접 학습하는 alignment 기법입니다. RLHF(Reinforcement Learning from Human Feedback)의 복잡한 보상 모델 훈련 없이도 유사한 효과를 얻을 수 있습니다.
핵심 아이디어:
두 개의 응답 중 어느 것이 더 나은지를 학습합니다:
- Chosen response: 선호되는 답변
- Rejected response: 선호되지 않는 답변
데이터 형식:
{
"prompt": "사용자 질문",
"chosen": "좋은 답변 예시",
"rejected": "나쁜 답변 예시"
}
손실 함수:
DPO는 다음 목적 함수를 최적화합니다:
LDPO = -log(σ(β · (log πθ(yw|x) / πref(yw|x) - log πθ(yl|x) / πref(yl|x))))
여기서:
- πθ: 학습 중인 모델
- πref: 참조 모델 (원본 또는 SFT 모델)
- yw: chosen response
- yl: rejected response
- β: temperature 파라미터 (일반적으로 0.1~0.5)
작동 원리:
- 모델이 chosen response에 더 높은 확률을 부여하도록 학습
- Rejected response의 확률은 낮추도록 학습
- 참조 모델로부터 과도하게 벗어나지 않도록 KL divergence 제약
적합한 경우:
- 응답 품질 개선 (유해성 감소, 유용성 향상)
- 특정 스타일 선호도 학습
- 안전성(Safety) alignment
- 3K~10K 선호도 페어 권장
실전 팁:
- SFT 후 DPO 적용이 일반적 (2단계 파인튜닝)
- Chosen/rejected 응답 차이가 명확해야 효과적
- 너무 긴 응답보다는 200-500 토큰 길이가 적합
3. Reinforcement Fine-Tuning (RFT)
RFT는 보상 함수(reward function)를 기반으로 모델을 강화학습시킵니다. DPO보다 유연하지만 더 복잡합니다.
핵심 아이디어:
모델이 생성한 답변을 보상 함수로 평가하고, 높은 보상을 받는 방향으로 학습합니다.
보상 함수 예시:
- 규칙 기반: 특정 패턴 포함/제외
- 외부 도구: 코드 실행 성공률, 단위 테스트 통과율
- Verifier 모델: 별도 학습된 검증 모델 (수학 문제 검증 등)
- 사용자 피드백: 실시간 인간 평가
훈련 루프:
- 모델이 여러 응답 생성 (sampling)
- 각 응답에 보상 점수 부여
- 높은 보상 응답의 확률 증가
- 낮은 보상 응답의 확률 감소
수학적 정의:
RFT는 다음 목적 함수를 최대화합니다:
J(θ) = 𝔼xD, yπθ[R(x, y)] - β · KL(πθ || πref)
여기서:
- R(x, y): 보상 함수
- β: KL 페널티 가중치
적합한 경우:
- 검증 가능한 태스크 (코드 생성, 수학 문제)
- 복잡한 추론이 필요한 경우
- 다단계 의사결정 (대화, 계획 수립)
- 명확한 평가 지표가 있는 경우
실전 예시:
수학 문제 해결:
- 보상: 최종 답이 정답과 일치하면 +1, 아니면 0
- RFT로 모델이 정답률을 높이는 추론 전략 학습
코드 생성:
- 보상: 단위 테스트 통과율 (0~1)
- 컴파일 에러: -0.5 페널티
- 실행 성공 + 모든 테스트 통과: +1
Amazon Nova Forge의 RFT 예시:
reinforcement_config:
reward_model: "verifier-model-name"
beta: 0.1 # KL 페널티
num_samples: 4 # 응답 샘플링 개수
temperature: 0.7
4. Continued Pre-training
대량의 도메인 데이터로 모델의 지식 베이스를 확장하는 방법입니다.
데이터 규모:
- 일반적으로 100B+ 토큰
- SFT(1K~10K 샘플)와는 규모가 완전히 다름
데이터 형식:
- 비구조화 텍스트 (문서, 책, 논문, 웹 페이지)
- JSONL 또는 텍스트 파일
적합한 경우:
- 특정 도메인 지식 대량 주입 (의료 문헌, 법률 판례)
- 새로운 언어 학습
- 특정 시대/스타일의 텍스트 적응
주의사항:
- Catastrophic Forgetting 위험이 가장 큼
- Data Mixing 필수
- 매우 높은 컴퓨팅 비용
Nova Forge의 Catastrophic Forgetting 방어 전략
Nova Forge는 Data Mixing 기능으로 이 문제를 해결합니다:
data_mixing:
dataset_catalog: sft_1p5_text_chat
sources:
customer_data:
percent: 50
nova_data:
reasoning-instruction-following: 45
planning: 10
code: 10
instruction-following: 13
math: 2
chat: 0.5
작동 원리:
- 고객 데이터 50% + Nova 원본 데이터 50% 혼합
- Nova 데이터가 범용 능력 유지 (reasoning, code, math 등)
- LoRA와 결합하면 이중 보호: 가중치 동결 + 데이터 다양성
6. Nova Forge 실전 설정 가이드
전체 설정 파일 구조
Nova Forge는 YAML 형식의 설정 파일로 모든 파인튜닝 파라미터를 정의합니다. 다음은 완전한 설정 예시입니다:
⚠️ Bedrock API 사용 시 참고: Bedrock
CreateModelCustomizationJobAPI를 통해 fine-tuning을 실행할 경우, YAML 설정이 아닌hyperParametersmap (epochCount, batchSize, learningRate 등)으로 파라미터를 전달합니다. 아래 YAML 설정은 Nova Forge의 내부 구조를 이해하기 위한 레퍼런스입니다. 또한 fine-tuning 지원 리전은 현재 us-east-1만 해당됩니다 (us-west-2는 fine-tuning 모델이 노출되지 않음).
# ====================
# Run Configuration
# ====================
run:
# 작업 이름 (실험 추적용)
name: medical-qa-lora-plus
# 베이스 모델 선택
# - amazon.nova-2-lite-v1:0:256k (경량, 256K 컨텍스트)
# - amazon.nova-2-micro-v1:0:128k (초경량, 128K 컨텍스트)
# - amazon.nova-2-pro-v1:0:300k (고성능, 300K 컨텍스트)
model_type: amazon.nova-2-lite-v1:0:256k
# 훈련 데이터 경로 (JSONL 형식)
data_s3_path: s3://my-bucket/medical-qa/train.jsonl
# 검증 데이터 경로 (선택 사항)
validation_data_s3_path: s3://my-bucket/medical-qa/val.jsonl
# GPU 인스턴스 수 (distributed training)
# Nova Lite: 4~8 replicas 권장
# Nova Pro: 8~16 replicas 권장
replicas: 4
# 출력 경로 (체크포인트, 로그, 최종 모델)
output_s3_path: s3://my-bucket/outputs/medical-qa/
# 랜덤 시드 (재현성)
seed: 42
# ====================
# Training Configuration
# ====================
training_config:
# 최대 훈련 스텝
# 경험 법칙: 데이터셋 크기 / global_batch_size * 3 epoch
max_steps: 500
# 체크포인트 저장 주기
save_steps: 50
# 검증 평가 주기
eval_steps: 50
# 최대 시퀀스 길이 (토큰)
# Nova Lite 256K: 최대 32768 권장 (메모리 제약)
# 더 긴 시퀀스는 메모리 사용량 급증
max_length: 8192
# 전역 배치 크기 (모든 replica 합산)
# replica당 배치 크기 = global_batch_size / replicas
# 예: 32 / 4 = replica당 8
global_batch_size: 32
# ⚠️ 주의: Nova Micro는 batch_size 최대 1만 허용합니다.
# 모델별 허용 범위가 다르므로 dry-run으로 사전 검증하세요.
# Gradient accumulation steps
# 메모리가 부족하면 이 값을 늘려 유효 배치 크기 증가
gradient_accumulation_steps: 1
# 추론 체인 학습 활성화
# Nova의 <think> 토큰 기반 추론 학습
reasoning_enabled: true
# Gradient clipping (폭주 방지)
max_grad_norm: 1.0
# 로깅 주기
logging_steps: 10
# ====================
# Learning Rate Scheduler
# ====================
lr_scheduler:
# Warmup 스텝 (보통 max_steps의 10-15%)
# 학습 초반 안정성 확보
warmup_steps: 50
# 최소 학습률 (cosine decay 끝점)
min_lr: 1e-6
# 스케줄러 타입 (기본: cosine)
# 옵션: cosine, linear, constant
type: cosine
# ====================
# Optimizer Configuration
# ====================
optim_config:
# 학습률 (LoRA에서는 1e-4 ~ 1e-5 권장)
lr: 2e-5
# Weight decay (정규화)
# LoRA에서는 0.0 또는 매우 작은 값 (0.01) 권장
weight_decay: 0.01
# AdamW beta parameters
beta1: 0.9
beta2: 0.999
# Epsilon (수치 안정성)
epsilon: 1e-8
# ====================
# PEFT Configuration
# ====================
peft:
# PEFT 방식: "lora" 또는 "full" (Full Fine-tuning)
peft_scheme: "lora"
lora_tuning:
# LoRA rank (4~64)
# 작은 데이터: 8~16
# 중간 데이터: 16~32
# 대량 복잡 데이터: 32~64
rank: 32
# LoRA alpha (보통 rank의 2~4배)
alpha: 128
# LoRA+ 학습률 비율
# 16~64 권장, 0이면 비활성화
lora_plus_lr_ratio: 64.0
# LoRA dropout (overfitting 방지)
# 작은 데이터: 0.05~0.1
# 큰 데이터: 0.0~0.05
dropout: 0.05
# 적용할 모듈 (선택 사항)
# 기본: 모든 attention + FFN
# target_modules: ["q_proj", "v_proj", "k_proj", "o_proj"]
# ====================
# Data Mixing (Catastrophic Forgetting 방지)
# ====================
data_mixing:
# Nova의 사전 학습 데이터 카탈로그
dataset_catalog: sft_1p5_text_chat
sources:
# 고객 데이터 (실제 파인튜닝 데이터)
customer_data:
percent: 50
# Nova 원본 데이터 믹싱 (총 50%)
nova_data:
# 추론 능력 유지 (가장 중요)
reasoning-instruction-following: 20
# 계획 수립 능력
planning: 5
# 코드 생성 능력
code: 10
# 일반 지시 수행
instruction-following: 10
# 수학 능력
math: 3
# 대화 능력
chat: 2
# 총합이 customer_data와 합쳐 100%가 되도록
# ====================
# Evaluation Configuration (선택 사항)
# ====================
evaluation:
# 평가 전략: "steps" 또는 "epoch"
strategy: steps
# 평가에 사용할 배치 크기
batch_size: 8
# 평가 메트릭
metrics:
- perplexity
- accuracy
# Early stopping (선택 사항)
early_stopping:
patience: 3 # 3번 연속 개선 없으면 중단
metric: perplexity
mode: min # perplexity는 낮을수록 좋음
# ====================
# Monitoring & Logging
# ====================
monitoring:
# CloudWatch 로그 그룹
cloudwatch_log_group: /aws/sagemaker/nova-forge
# TensorBoard 활성화
tensorboard: true
# Weights & Biases 연동 (선택 사항)
# wandb:
# project: nova-forge-medical
# entity: my-team
핵심 파라미터 상세 설명
1. max_steps 계산
적절한 max_steps는 데이터 크기와 epoch 수로 계산합니다:
max_steps = (데이터셋 크기 / global_batch_size) × epoch 수
예시:
- 데이터셋: 5,000 샘플
- global_batch_size: 32
- 목표 epoch: 3
- max_steps = (5000 / 32) × 3 ≈ 469 → 500 설정
2. global_batch_size vs gradient_accumulation_steps
메모리 부족 시:
# 방법 1: 작은 배치
global_batch_size: 16
gradient_accumulation_steps: 1
# 방법 2: Gradient accumulation (권장)
global_batch_size: 32 # 유효 배치 크기
gradient_accumulation_steps: 2 # 실제 배치는 16
방법 2가 더 안정적인 학습을 제공합니다.
3. Learning rate 스케줄링
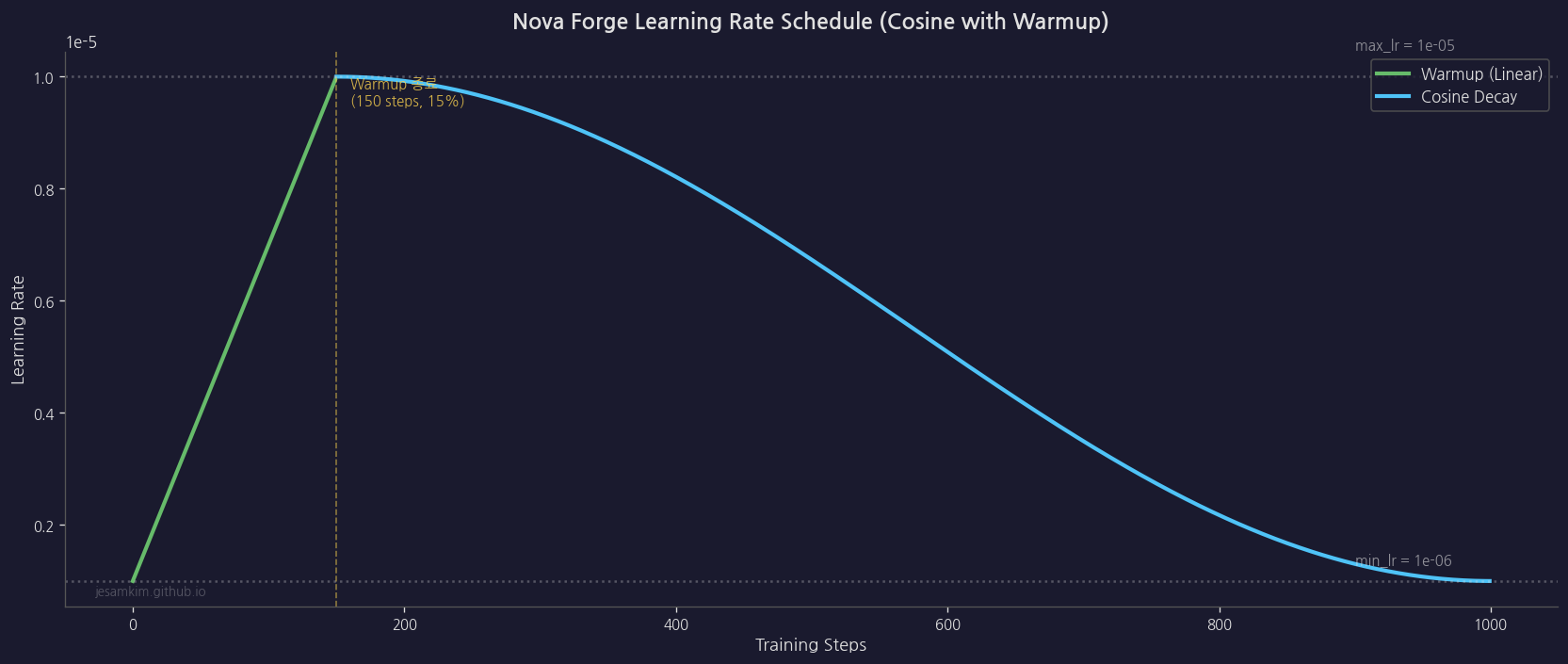
- Warmup: 0 → peak_lr (안정적 시작)
- Cosine decay: peak_lr → min_lr (부드러운 수렴)
- Warmup 비율: 보통 max_steps의 10-15%
4. Data Mixing 비율 전략
| 도메인 특화 정도 | customer_data | nova_data | 비고 |
|---|---|---|---|
| 매우 특수함 | ~70% | ~30% | Forgetting 위험 증가 |
| 일반적 | ~50% | ~50% | 권장 |
| 범용 능력 중시 | ~30% | ~70% | 도메인 성능 감소 |
주: 비율은 대략적 가이드라인이며, 실제 최적값은 도메인과 데이터 특성에 따라 조정이 필요합니다.
기본 LoRA 설정 (간소화 버전)
빠른 시작을 위한 최소 설정:
run:
name: my-domain-lora-sft
model_type: amazon.nova-2-lite-v1:0:256k
data_s3_path: s3://my-bucket/train.jsonl
replicas: 4
output_s3_path: s3://my-bucket/outputs/
training_config:
max_steps: 100
save_steps: 10
max_length: 8192
global_batch_size: 32
reasoning_enabled: true
lr_scheduler:
warmup_steps: 15
min_lr: 1e-6
optim_config:
lr: 1e-5
weight_decay: 0.0
peft:
peft_scheme: "lora"
lora_tuning:
rank: 16
alpha: 64
lora_plus_lr_ratio: 64.0
dropout: 0.05
data_mixing:
dataset_catalog: sft_1p5_text_chat
sources:
customer_data:
percent: 50
nova_data:
reasoning-instruction-following: 45
code: 5
Rank/Alpha 튜닝 전략
| 시나리오 | Rank | Alpha | 이유 |
|---|---|---|---|
| 작은 도메인 변화 | 8 | 32 | Overfitting 방지 |
| 중간 복잡도 태스크 | 16 | 64 | 균형 잡힌 선택 |
| 복잡한 추론 패턴 | 32 | 128 | 높은 표현력 필요 |
| 매우 특수한 도메인 | 64 | 192 | 최대 용량 |
경험 법칙:
- Alpha는 보통 Rank의 2~4배
- 데이터가 적을수록 낮은 Rank (overfitting 방지)
- 데이터가 많고 복잡할수록 높은 Rank
Forgetting 방지 체크리스트
✅ LoRA/LoRA+ 사용 (Full-rank보다 우선)
✅ Data Mixing 활성화 (50% Nova 데이터 혼합)
✅ Reasoning 데이터 포함 (범용 벤치마크 유지)
✅ 중간 체크포인트 검증 (MMLU, HellaSwag 등)
✅ Learning rate 보수적 설정 (1e-5 이하)
✅ 적절한 Warmup (max_steps의 15%)
데이터 준비 팁
JSONL 형식 예시:
{"messages": [
{"role": "user", "content": "법률 문서 요약해줘: [문서 내용]"},
{"role": "assistant", "content": "주요 내용은 다음과 같습니다.."}
]}
품질 > 수량:
- 1,000개 고품질 샘플 > 10,000개 저품질 샘플
- 다양한 패턴 포함 (edge case 커버)
- 일관된 포맷 유지
7. 의사결정 가이드: 언제 어떤 기법을 쓸 것인가
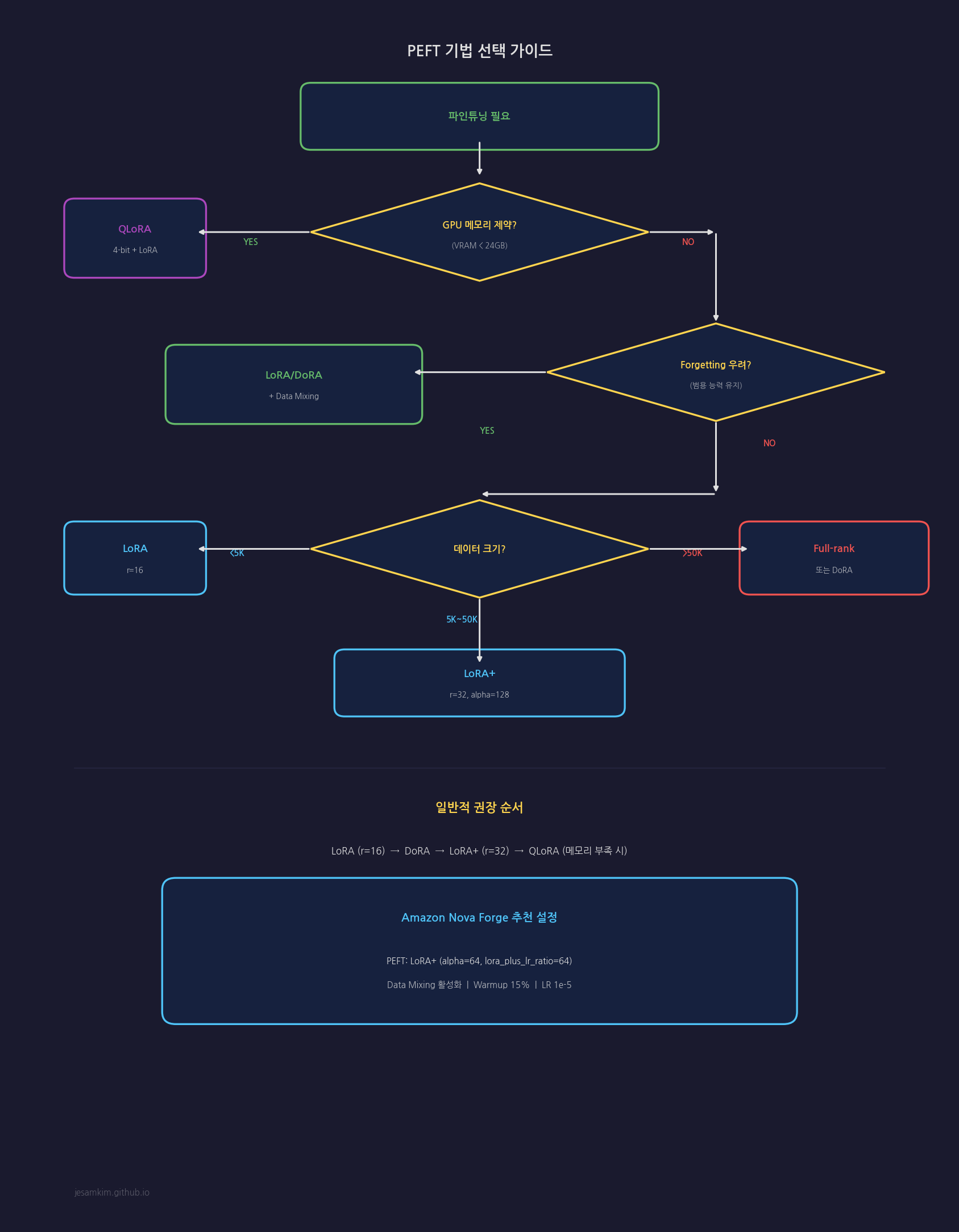
시나리오별 추천
시나리오 1: 메모리가 충분한 경우 (A100 80GB 이상)
데이터 크기 < 5K → LoRA (r=16, α=64)
데이터 크기 5K~50K → LoRA+ (r=32, α=128)
데이터 크기 > 50K → DoRA 또는 Full-rank SFT
시나리오 2: 메모리가 제한적인 경우 (RTX 4090, A10G 등)
모든 경우 → QLoRA (4-bit, r=16)
극단적 제약 → GaLore
시나리오 3: Catastrophic Forgetting이 중요한 경우
1순위: LoRA + Data Mixing
2순위: DoRA + Data Mixing
3순위: Adapter Layers
시나리오 4: 최고 성능이 필요한 경우
충분한 데이터(>10K) → Full-rank SFT + Data Mixing
제한된 데이터 → DoRA 또는 LoRA+
AWS 환경에서의 추천
| AWS 서비스 | 추천 기법 | 이유 |
|---|---|---|
| Amazon Nova Forge | LoRA+ with Data Mixing | 기본 지원, 최적화됨 |
| SageMaker Training | QLoRA (PEFT library) | 비용 효율성 |
| SageMaker JumpStart | LoRA | 빠른 시작 |
| Bedrock Continued Pre-training | Full-parameter | 대량 도메인 지식 주입 |
결론
파인튜닝은 강력하지만 Catastrophic Forgetting이라는 치명적 함정을 내포하고 있습니다. PEFT 기법들은 원본 가중치를 보존하면서도 도메인 적응을 가능하게 하는 우아한 해결책입니다.
핵심 교훈:
- RAG vs Fine-tuning: 지식은 RAG, 행동은 Fine-tuning
- LoRA 계열이 기본 선택: 효율성과 Forgetting 방어의 균형
- Data Mixing은 필수: 특히 Full Fine-tuning 시
- 메모리 제약 시 QLoRA: 성능 손실 최소
- Amazon Nova Forge 활용: LoRA+와 Data Mixing으로 프로덕션급 파인튜닝 가능
파인튜닝을 시작하기 전에, 벤치마크 baseline을 측정하고, 중간 체크포인트마다 범용 성능을 모니터링하세요. Forgetting은 예방이 치료보다 쉽습니다.
💻 이 글에서 소개한 Nova Forge SFT 실험(한국어 감성 분류, 73% → 99%)의 전체 코드와 데이터셋은 GitHub에서 확인할 수 있습니다.
References
- Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., & Chen, W. (2021). LoRA: Low-Rank Adaptation of Large Language Models. arXiv:2106.09685. https://arxiv.org/abs/2106.09685
- Dettmers, T., Pagnoni, A., Holtzman, A., & Zettlemoyer, L. (2023). QLoRA: Efficient Finetuning of Quantized LLMs. arXiv:2305.14314. https://arxiv.org/abs/2305.14314
- Liu, S.-Y., Wang, C.-Y., Yin, H., Molchanov, P., Wang, Y.-C. F., Cheng, K.-T., & Chen, M.-H. (2024). DoRA: Weight-Decomposed Low-Rank Adaptation. arXiv:2402.09353. https://arxiv.org/abs/2402.09353
- Hayou, S., Ghosh, N., & Yu, B. (2024). LoRA+: Efficient Low Rank Adaptation of Large Models. arXiv:2402.12354. https://arxiv.org/abs/2402.12354
- Zhao, J., Zhang, Z., Chen, B., Wang, Z., Anandkumar, A., & Tian, Y. (2024). GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection. arXiv:2403.03507. https://arxiv.org/abs/2403.03507
- Rafailov, R., Sharma, A., Mitchell, E., Ermon, S., Manning, C. D., & Finn, C. (2023). Direct Preference Optimization: Your Language Model is Secretly a Reward Model. arXiv:2305.18290. https://arxiv.org/abs/2305.18290
- AWS Documentation. Amazon Nova Forge Supervised Fine-Tuning. https://docs.aws.amazon.com/nova/latest/nova2-userguide/nova-forge-sft.html
- AWS Documentation. Customizing Nova models with Amazon SageMaker AI. https://docs.aws.amazon.com/sagemaker/latest/dg/nova-model.html
- AWS Blog. Announcing Amazon Nova customization in Amazon SageMaker AI. https://aws.amazon.com/blogs/aws/announcing-amazon-nova-customization-in-amazon-sagemaker-ai/
- AWS Machine Learning Blog. Reinforcement fine-tuning for Amazon Nova: Teaching AI through feedback. https://aws.amazon.com/blogs/machine-learning/reinforcement-fine-tuning-for-amazon-nova-teaching-ai-through-feedback/