
음성 AI를 처음 만났을 때
새 학기가 시작되고 음성 인터페이스 수업 첫 강의를 들었습니다. ChatGPT Voice를 쓰면서 “이거 신기하네” 정도로만 생각했는데, 막상 원리를 배우려니 생각보다 깊은 세계더군요.
첫 수업에서 교수님이 이런 질문을 던졌습니다. “텍스트에서 음성 파형을 바로 만들면 되지, 왜 굳이 여러 단계를 거칠까?" 생각해보면, 같은 “안녕하세요"도 누가 말하느냐에 따라 톤이 다르고, 감정에 따라 속도와 억양이 달라집니다. 텍스트에는 이런 정보가 없죠. 그래서 TTS는 텍스트 → 음성 특징(Mel-spectrogram) → 최종 파형이라는 중간 단계를 거칩니다.
그 순간 깨달았습니다. 음성 AI를 이해하려면 먼저 사람이 어떻게 말을 하는지부터 알아야 한다는 것을요.
사람은 어떻게 소리를 만들어낼까
기계가 음성을 만들려면, 먼저 사람이 어떻게 말하는지 이해해야 합니다. 생각해보면 당연합니다. 사람이 하는 방식을 모르면, 기계에게 어떻게 가르쳐주겠습니까?
인간의 음성 생성은 두 가지 핵심 기관으로 이루어집니다.
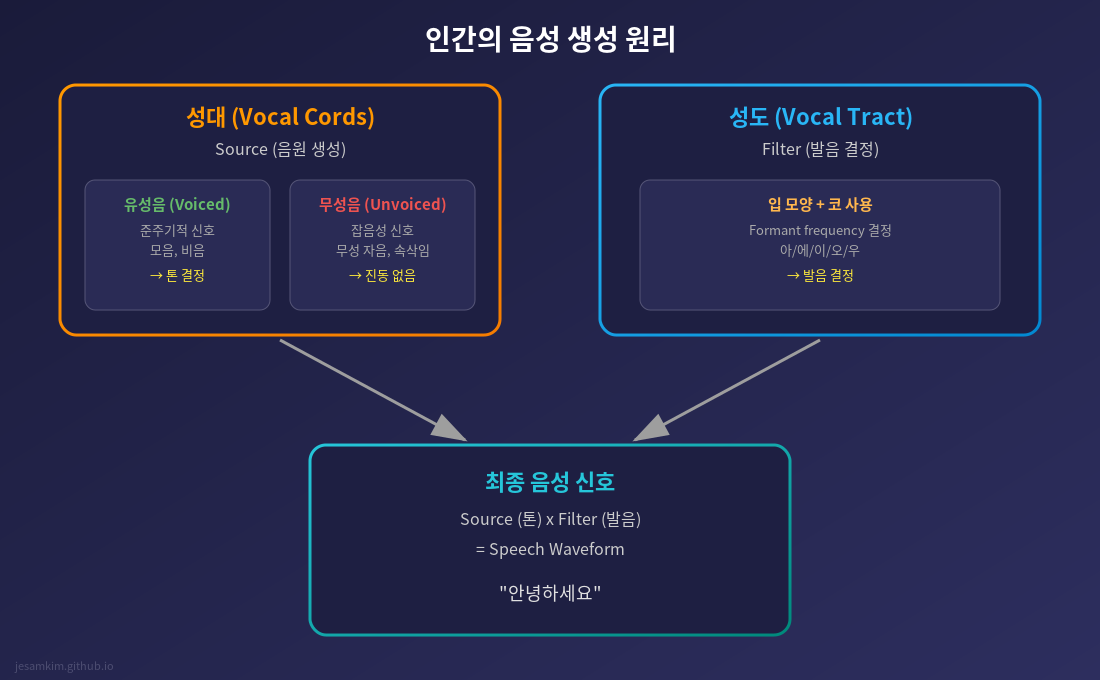
성대: 톤을 결정하는 곳
성대(Vocal Cords)는 목 안쪽 후두부에 있는 얇은 근육 조직입니다. 폐에서 올라온 공기가 이 성대를 통과하면서 진동하면, 우리가 “목소리"라고 부르는 음원(Source)이 만들어집니다.
성대가 빠르게 진동하면 높은 톤, 천천히 진동하면 낮은 톤이 됩니다. “아↗아↘“처럼 톤을 올리고 내릴 수 있는 이유가 바로 성대의 진동 속도를 조절할 수 있기 때문입니다. 이 진동 주기를 F0 (Fundamental Frequency)라고 부릅니다.
흥미로운 건 성대가 항상 진동하는 건 아니라는 점입니다. “아” 같은 모음을 발음할 때는 성대가 주기적으로 진동하는데, 이걸 유성음(Voiced Sound)이라고 합니다. 반면 “ㅎ” 같은 소리를 낼 때는 성대가 열려 있어 진동하지 않습니다. 이건 무성음(Unvoiced Sound)이죠.
직접 확인해볼 수 있습니다. 목에 손을 대고 “아"라고 발음하면 진동이 느껴지지만, “ㅎ"라고 하면 진동이 없습니다.
성도: 발음을 결정하는 곳
성대에서 만들어진 음원은 그 자체로는 그냥 윙윙거리는 소리에 불과합니다. 이 소리가 성도(Vocal Tract)를 통과하면서 비로소 “말"이 됩니다.
성도는 후두부에서 입술까지 이어지는 관(pipe) 모양의 공간입니다. 여기에는 혀, 입술, 이, 코 등이 포함됩니다. 입 모양을 바꾸고, 혀의 위치를 조절하고, 코를 사용하거나 사용하지 않으면서, 성도의 형태가 변합니다.
성도의 형태가 바뀌면 특정 주파수 대역이 공명합니다. 이 공명 주파수를 Formant라고 부르는데, 바로 이게 발음을 결정합니다. “아”, “에”, “이”, “오”, “우"가 다르게 들리는 이유는 각각의 Formant 패턴이 다르기 때문입니다.
정리하면 이렇습니다. 성대는 톤을 만들고, 성도는 발음을 만듭니다. 음성 신호는 결국 이 두 가지의 조합입니다.
그렇다면 기계는 이 원리를 어떻게 재현할까요?
TTS는 왜 2단계로 나뉠까
Text-to-Speech(TTS) 시스템의 목표는 간단합니다. 텍스트를 입력하면 음성이 나오는 것이죠. 하지만 구현은 간단하지 않습니다.
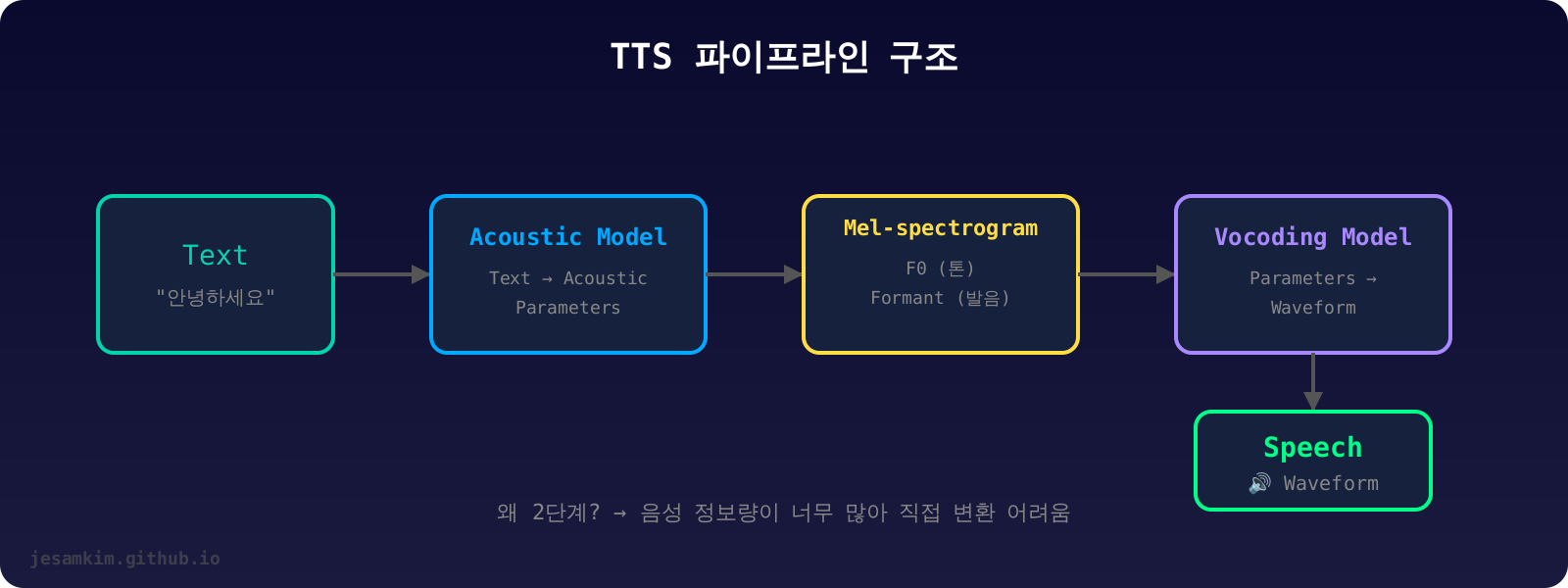
TTS 시스템은 크게 두 단계로 나뉩니다.
1단계: Acoustic Model (음향 모델)
Acoustic Model은 텍스트를 받아서 Acoustic Parameters라는 중간 표현을 만들어냅니다. 이 파라미터는 음성의 음향적 특징을 담고 있습니다. 톤, 음량, 음색, 발화 속도, 심지어 감정까지도요.
왜 텍스트에서 음성을 바로 만들지 않고 이런 중간 단계를 거칠까요? 음성 신호가 가진 정보량이 너무 많기 때문입니다.
예를 들어보겠습니다. 48kHz로 샘플링된 10초짜리 음성 파일은 약 480,000개의 샘플로 이루어져 있습니다. 각 샘플이 16bit라면, 총 7,680,000 bit의 데이터입니다. 텍스트 “안녕하세요” 다섯 글자로부터 이 엄청난 양의 데이터를 직접 생성하는 건 현실적으로 어렵습니다.
그래서 중간에 압축된 표현을 사용합니다. 현재 가장 널리 쓰이는 게 Mel-spectrogram입니다.
2단계: Vocoding Model (보코딩 모델)
Vocoding Model은 Acoustic Parameters를 받아서 실제 음성 파형(Waveform)을 복원합니다. 압축된 표현으로부터 사람이 들을 수 있는 소리를 다시 만들어내는 거죠.
이 두 단계를 거치는 이유를 다시 한번 정리하면: 정보량 때문입니다. 텍스트에서 수십만 개의 샘플로 이루어진 파형을 직접 만드는 건 너무 어렵습니다. 하지만 텍스트 → 중간 표현 → 파형으로 나누면 각 단계의 복잡도가 관리 가능한 수준이 됩니다.
그렇다면 이 “중간 표현"은 정확히 무엇일까요?
기계가 음성을 “이해"하는 방법
음성 신호를 시간 축에서 보면 그냥 복잡한 파형입니다. 어디가 “아"이고 어디가 “에"인지 구분하기 어렵습니다. 하지만 주파수 영역에서 보면 이야기가 달라집니다.
Spectrogram: 시간과 주파수를 동시에 보기
Spectrogram(스펙트로그램)은 음성 신호를 2D 이미지로 변환한 것입니다. X축은 시간, Y축은 주파수, 색깔은 에너지를 나타냅니다.
만드는 방법은 이렇습니다. 음성 신호를 작은 구간(보통 20ms)으로 잘라서, 각 구간마다 Fourier Transform을 적용합니다. 그러면 각 시간 구간에서 어떤 주파수 성분이 강한지 알 수 있습니다. 이걸 시간 순서대로 쭉 이어 붙이면 Spectrogram이 됩니다.
Spectrogram을 보면 사람 눈으로도 패턴을 파악할 수 있습니다. 수직으로 반복되는 갈비뼈 같은 패턴은 F0(톤)의 변화를 보여주고, 수평으로 진한 줄무늬는 Formant(발음)를 나타냅니다. 시간에 따라 톤이 어떻게 변하는지, 어떤 발음으로 바뀌는지 한눈에 들어옵니다.
수업 중에 들었던 말이 기억에 남습니다. “사람이 눈으로 봤을 때 파악할 수 있다면, 기계가 본다면 훨씬 쉽게 파악할 수 있다."
Mel-spectrogram: 인간의 귀를 닮은 표현
하지만 일반 Spectrogram에는 문제가 있습니다. 주파수 축이 선형(linear)으로 되어 있다는 점입니다.
음성의 중요한 정보는 대부분 저주파 대역에 집중되어 있습니다. F0도, Formant도 대부분 스펙트로그램 하단부(저주파)에 위치합니다. 그런데 전체 주파수 범위를 균일하게 보면, 정작 중요한 저주파 영역의 해상도가 떨어집니다.
이 문제를 해결한 게 Mel-spectrogram입니다.
Mel-spectrogram은 Mel-filterbank라는 필터를 적용한 것입니다. 이 필터는 인간의 청각 특성을 반영합니다. 사람의 귀는 저주파에 민감하게 반응하고, 고주파에는 상대적으로 둔감합니다.
Mel-filterbank는 저주파 대역에는 좁은 간격의 필터를(높은 해상도), 고주파 대역에는 넓은 간격의 필터를(낮은 해상도) 배치합니다. 결과적으로 중요한 정보가 많은 저주파 영역을 자세히 볼 수 있게 됩니다.
Mel-filterbank를 적용하면 피치의 흐름과 Formant의 변화가 훨씬 명확하게 보입니다. 사람이 이해하기 쉬우면 기계도 이해하기 쉽다는 원칙이 여기서도 적용됩니다.
현재 음성 합성 분야에서 Mel-spectrogram은 거의 표준으로 자리 잡았습니다. 다양한 TTS 모델들이 Acoustic Parameters로 Mel-spectrogram을 사용합니다.
하지만 문제가 하나 있습니다. Mel-spectrogram만으로는 음성을 복원할 수 없다는 점입니다.
어떻게 다시 소리를 만들어낼까
Mel-spectrogram은 magnitude 정보만 담고 있고, phase 정보는 손실됩니다. Inverse Fourier Transform으로 직접 복원할 수 없습니다. 과거에는 이 때문에 Mel-spectrogram을 주로 음성 인식(ASR) 같은 분류 작업에만 썼습니다.
하지만 딥러닝의 등장으로 상황이 바뀌었습니다.
Parametric Vocoder의 시대
예전에는 Parametric Vocoder라는 방식을 사용했습니다. 대표적인 게 LPC(Linear Predictive Coding) Vocoder입니다.
이 방식은 앞서 설명한 사람의 음성 생성 원리를 그대로 모방합니다. Source(성대)와 Filter(성도)를 분리해서, Source는 pitch period로, Filter는 Linear Prediction Coefficients로 표현합니다. 그러고 나서 수학적으로 정의된 공식에 따라 음성을 합성합니다.
수학적으로는 명확하지만, 문제는 음질입니다. 합성된 음성이 기계적으로 들립니다. 사람이 직접 설계한 특징(feature engineering)을 사용하기 때문에, 실제 음성의 미묘한 뉘앙스를 담아내지 못합니다.
Neural Vocoder의 등장
2016년 DeepMind가 발표한 WaveNet이 게임 체인저였습니다.
WaveNet은 CNN 기반의 딥러닝 모델로, Mel-spectrogram을 입력받아 음성 파형을 직접 생성합니다. 사람이 설계한 규칙 없이, 모델이 데이터로부터 학습합니다.
결과는 놀라웠습니다. 합성된 음성이 실제 사람 목소리와 구분하기 어려울 정도로 자연스러웠습니다. 하지만 치명적인 문제가 있었습니다. 너무 느렸습니다. 1초짜리 오디오를 생성하는 데 약 5분이 걸렸습니다.
WaveNet은 Autoregressive 모델입니다. 이전 샘플을 보고 다음 샘플을 예측하는 방식이죠. 48kHz 샘플링이면 1초에 48,000개의 샘플을 순차적으로 생성해야 합니다. 병렬화할 수 없으니 느릴 수밖에 없습니다.
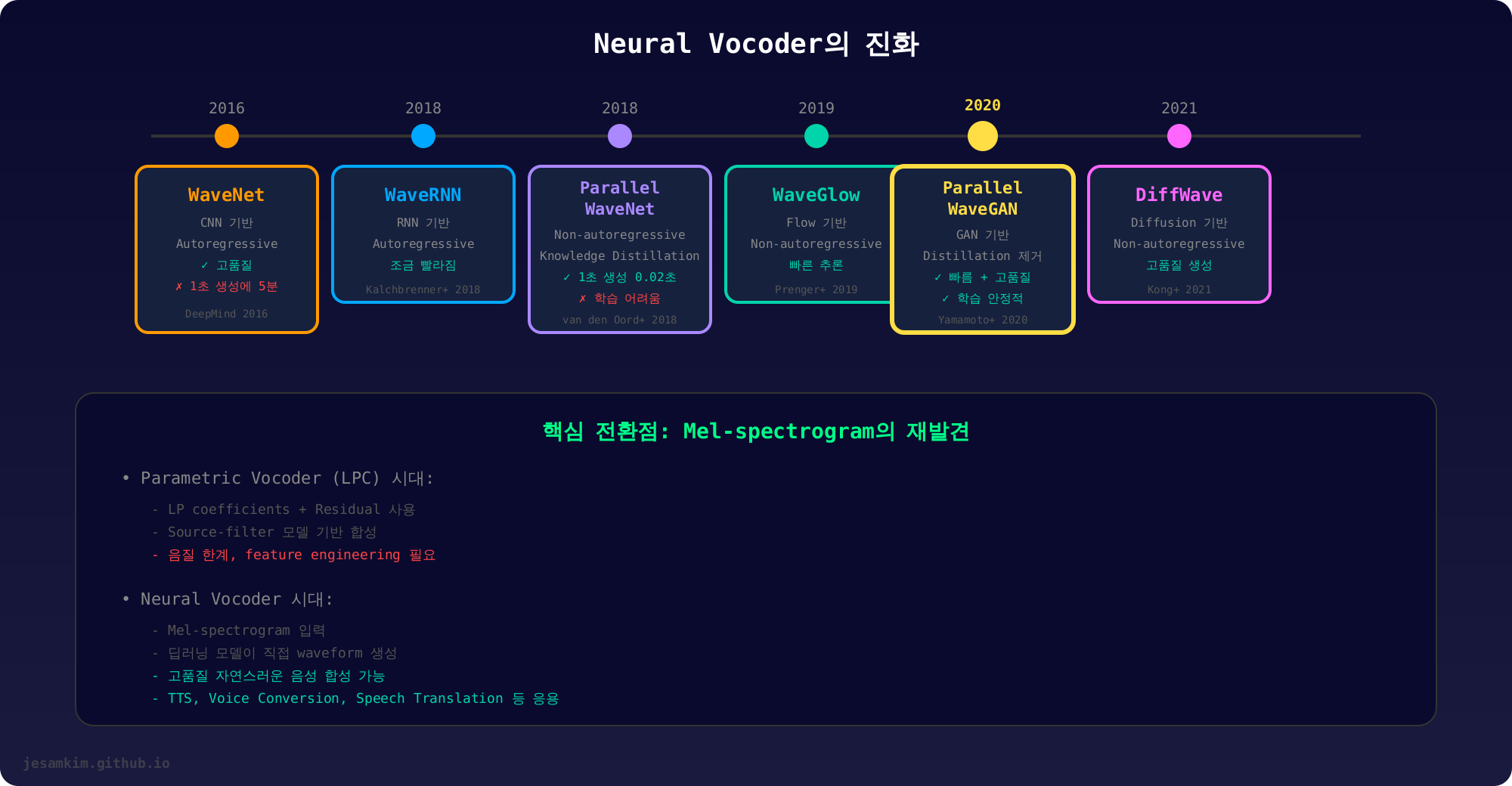
속도와 품질, 두 마리 토끼를 잡다
이후 여러 연구가 이어졌습니다. 목표는 하나였습니다. WaveNet의 음질을 유지하면서 속도를 올리는 것이죠.
2018년 Parallel WaveNet이 나왔습니다. Teacher-Student Distillation이라는 기법을 사용해서, Autoregressive WaveNet(Teacher)의 지식을 Non-autoregressive 모델(Student)에게 전달합니다. Student 모델은 이전 샘플을 기다릴 필요가 없으니 병렬로 생성할 수 있습니다.
결과는 놀라웠습니다. 1초 오디오를 0.02초 만에 생성했습니다. WaveNet 대비 250배 빠른 속도입니다. 하지만 단점이 있었습니다. Teacher-Student 학습이 불안정하고 어려웠습니다.
2020년 Parallel WaveGAN이 이 문제를 해결했습니다. Distillation 대신 GAN(Generative Adversarial Network)을 사용했습니다. Generator가 음성을 생성하면, Discriminator가 실제 음성인지 합성 음성인지 판별합니다. 이 과정을 반복하면서 Generator의 품질이 향상됩니다.
Parallel WaveGAN은 학습도 안정적이고, 추론 속도도 빠르고, 음질도 좋습니다. 현재 많은 TTS 시스템에서 실제로 사용되고 있습니다.
이 외에도 Flow 기반의 WaveGlow(2019), Diffusion 기반의 DiffWave(2021) 등 다양한 접근법이 계속 나오고 있습니다.
음성 AI를 배우며 느낀 점
수업을 들으면서 가장 인상 깊었던 건, 기술의 발전이 결국 “사람을 이해하는 것”에서 시작한다는 점이었습니다.
사람이 어떻게 말하는지(성대와 성도), 사람의 귀가 어떻게 소리를 듣는지(Mel-scale), 사람이 어떻게 시각적으로 패턴을 인식하는지(Spectrogram). 이 모든 이해가 쌓여서 지금의 음성 AI가 만들어졌습니다.
처음엔 “그냥 텍스트를 음성으로 바꾸면 되는 거 아닌가?“라고 생각했습니다. 하지만 알고 보니 그 뒤에는 신호 처리, 인간 청각 시스템, 딥러닝 모델 설계 등 수많은 레이어가 쌓여 있었습니다.
ChatGPT Voice를 쓸 때 이제는 다르게 들립니다. “아, 지금 Acoustic Model이 Mel-spectrogram을 만들고 있겠구나”, “이 자연스러운 톤 변화는 Neural Vocoder가 F0를 잘 재현한 거구나” 하는 생각이 듭니다.
기술을 쓰는 것과 이해하는 것은 다릅니다. 이해하면 더 잘 쓸 수 있고, 문제가 생겼을 때 원인을 파악할 수 있고, 새로운 응용을 생각해낼 수 있습니다.
다음 주부터는 LLM과 음성을 결합하는 방법, 멀티모달 처리, 그리고 대규모 음성 합성 모델을 배운다고 합니다. 기초가 탄탄하니, 그 위에 무엇을 쌓든 이해할 수 있을 것 같습니다.
References
- Van Den Oord et al., WaveNet: A generative model for raw audio, arXiv:1609.03499, 2016
- Kalchbrenner et al., Efficient neural audio synthesis, arXiv:1802.08435, 2018
- Van den Oord et al., Parallel WaveNet: Fast high-fidelity speech synthesis, Proc. ICML, 2018
- Prenger et al., WaveGlow: A flow-based generative network for speech synthesis, Proc. ICASSP, 2019
- Yamamoto et al., Parallel WaveGAN: A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram, Proc. ICASSP, 2020
- Kong et al., DiffWave: A versatile diffusion model for audio synthesis, Proc. ICLR, 2021