다시 기본으로
새 학기가 시작됐습니다. “AI 분산 학습 및 추론” 수업을 듣는데, 첫 주차는 딥러닝 기초를 다시 복습하는 시간이었습니다. 솔직히 말하면, Solutions Architect로 4년 동안 일하면서 AI/ML 서비스를 수도 없이 다뤘지만, 수식 앞에서는 다시 겸손해지더군요.
“딥러닝이 뭐냐"고 물으면 뭐라 답하시겠습니까? 저는 그동안 “데이터를 넣으면 학습해서 예측하는 것” 정도로만 이해하고 있었습니다. 하지만 이번 기회에 제대로 정리해보고 싶었습니다. 분산 학습을 배우기 전에, 일단 딥러닝 자체가 정확히 무엇을 하는 건지 알아야 했으니까요.
이 글은 Level 100을 위한 것입니다. 딥러닝을 처음 배우는 분들, 또는 저처럼 실무에서 쓰긴 했지만 정확히 어떻게 작동하는지는 몰랐던 분들을 위해 작성했습니다. 수식은 최소화하고, 직관적인 설명에 집중했습니다.
학습이란 결국 “가중치 찾기”
딥러닝 학습을 카페 비유로 설명해보겠습니다.
당신이 카페 사장이라고 상상해보세요. 손님이 커피를 주문하면, 원두의 양, 물의 온도, 추출 시간 등을 조절해서 커피를 만듭니다. 이 각각의 조절 요소가 바로 가중치(Weight)입니다.
처음에는 적당히 찍어서 만듭니다. 당연히 맛이 별로겠죠. 손님이 “너무 쓴데요"라고 하면, 원두 양을 줄입니다. “너무 싱거운데요"라고 하면, 추출 시간을 늘립니다. 이렇게 피드백을 받으며 조금씩 레시피를 개선해나갑니다.
딥러닝도 똑같습니다. 모델에 데이터(손님의 주문)를 넣으면, 가중치(레시피)를 통해 결과(커피)를 만듭니다. 결과가 정답과 다르면(손님이 불만을 표하면), 가중치를 조금씩 수정합니다. 이 과정을 수백, 수천, 수만 번 반복하면, 결국 좋은 가중치를 찾게 됩니다.
학습이란 결국 “좋은 가중치를 찾는 과정"입니다.
Forward, Loss, Backward, Update: 학습의 4단계
딥러닝 학습은 네 단계가 끊임없이 반복됩니다.
1단계: Forward Propagation (순전파)
입력을 모델에 넣어 출력을 얻는 과정입니다.
이미지 분류를 예로 들어보겠습니다. 고양이 사진을 모델에 넣으면, 모델은 여러 층(Layer)을 거쳐 “이건 개일 확률 20%, 고양이일 확률 10%, 새일 확률 40%, 말일 확률 15%, 자동차일 확률 15%“라고 답합니다.
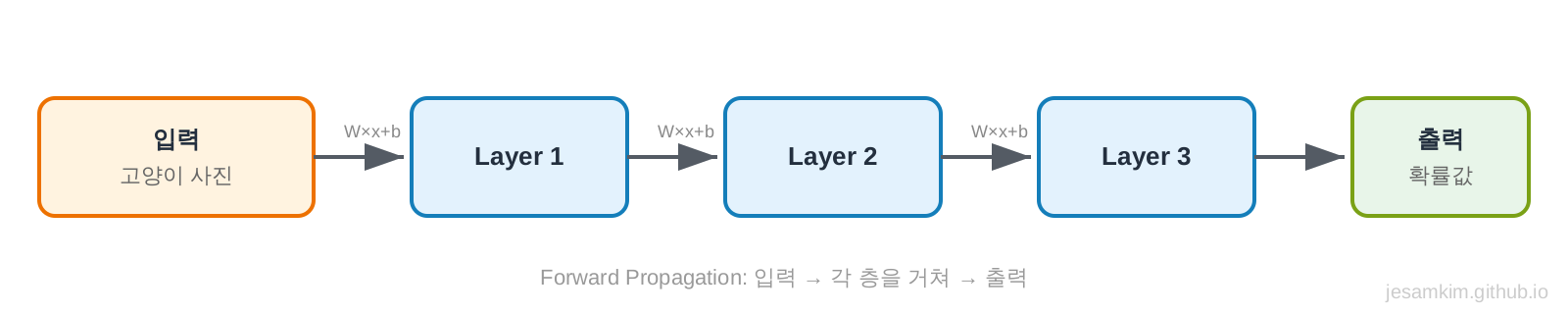
각 층에서는 다음과 같은 일이 일어납니다.
- 입력값에 가중치를 곱합니다
- 편향(Bias)을 더합니다
- 활성화 함수(Activation Function)를 통과시킵니다
- 다음 층으로 전달합니다
수식으로는 이렇게 표현됩니다만, 지금은 그냥 “가중치 곱하고, 편향 더하고, 활성화 함수 통과"라고만 이해하셔도 됩니다.
2단계: Loss 계산
모델의 출력과 정답을 비교해서 “얼마나 틀렸는지” 숫자로 표현합니다. 이 숫자가 Loss입니다.
위 예시에서 정답은 “고양이"인데, 모델은 “새일 확률 40%“라고 했습니다. 엉망이죠. 이럴 때 Loss는 큰 값이 나옵니다.
만약 학습이 잘 되어서 모델이 “고양이일 확률 99.6%“라고 답했다면, Loss는 아주 작은 값(거의 0)이 나옵니다.
Loss가 작을수록 모델이 정답에 가깝다는 뜻입니다. 따라서 학습의 목표는 “Loss를 최소화하는 것"입니다.
3단계: Backpropagation (역전파)
Loss를 줄이려면 가중치를 어떻게 조절해야 할까요? 이걸 계산하는 과정이 Backpropagation입니다.
출력층에서부터 거꾸로 올라가면서, 각 가중치가 Loss에 얼마나 기여했는지 계산합니다. 수학적으로는 “편미분"이라는 개념을 사용하지만, 직관적으로는 “이 가중치를 조금 늘리면 Loss가 얼마나 변할까?“를 계산하는 것입니다.
이 계산 결과를 Gradient(기울기)라고 부릅니다.
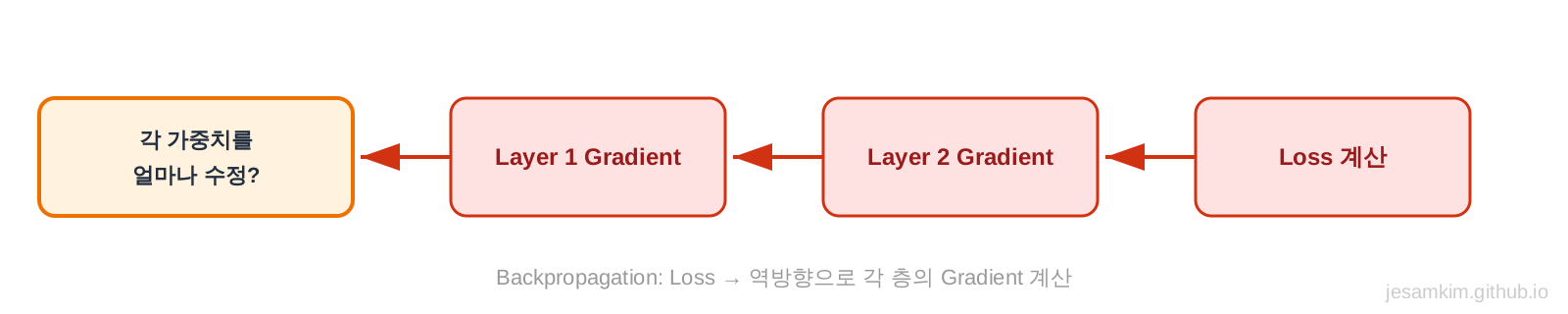
4단계: Update (가중치 업데이트)
Backpropagation으로 계산한 Gradient를 바탕으로, 가중치를 조금씩 수정합니다.
기본 규칙은 간단합니다.
새 가중치 = 기존 가중치 - 학습률 × Gradient
Gradient가 양수면 가중치를 줄이고, 음수면 가중치를 늘립니다. 이렇게 하면 Loss가 감소하는 방향으로 움직입니다.
이 네 단계를 수백, 수천 번 반복하면, 모델의 가중치가 점점 최적의 값에 가까워집니다. 이게 바로 학습입니다.
Gradient Descent: 산을 내려가는 방법
Gradient Descent(경사 하강법)를 산 하이킹에 비유해보겠습니다.
당신은 안개가 자욱한 산 정상에 있습니다. 목표는 가장 낮은 곳(산 아래)으로 내려가는 것입니다. 하지만 안개 때문에 앞이 보이지 않습니다. 어떻게 해야 할까요?
가장 간단한 방법은 현재 위치에서 가장 가파르게 내려가는 방향으로 한 걸음씩 이동하는 것입니다. 발밑의 경사(Gradient)를 느끼면서, 가장 가파른 방향으로 조금씩 걸어 내려갑니다.
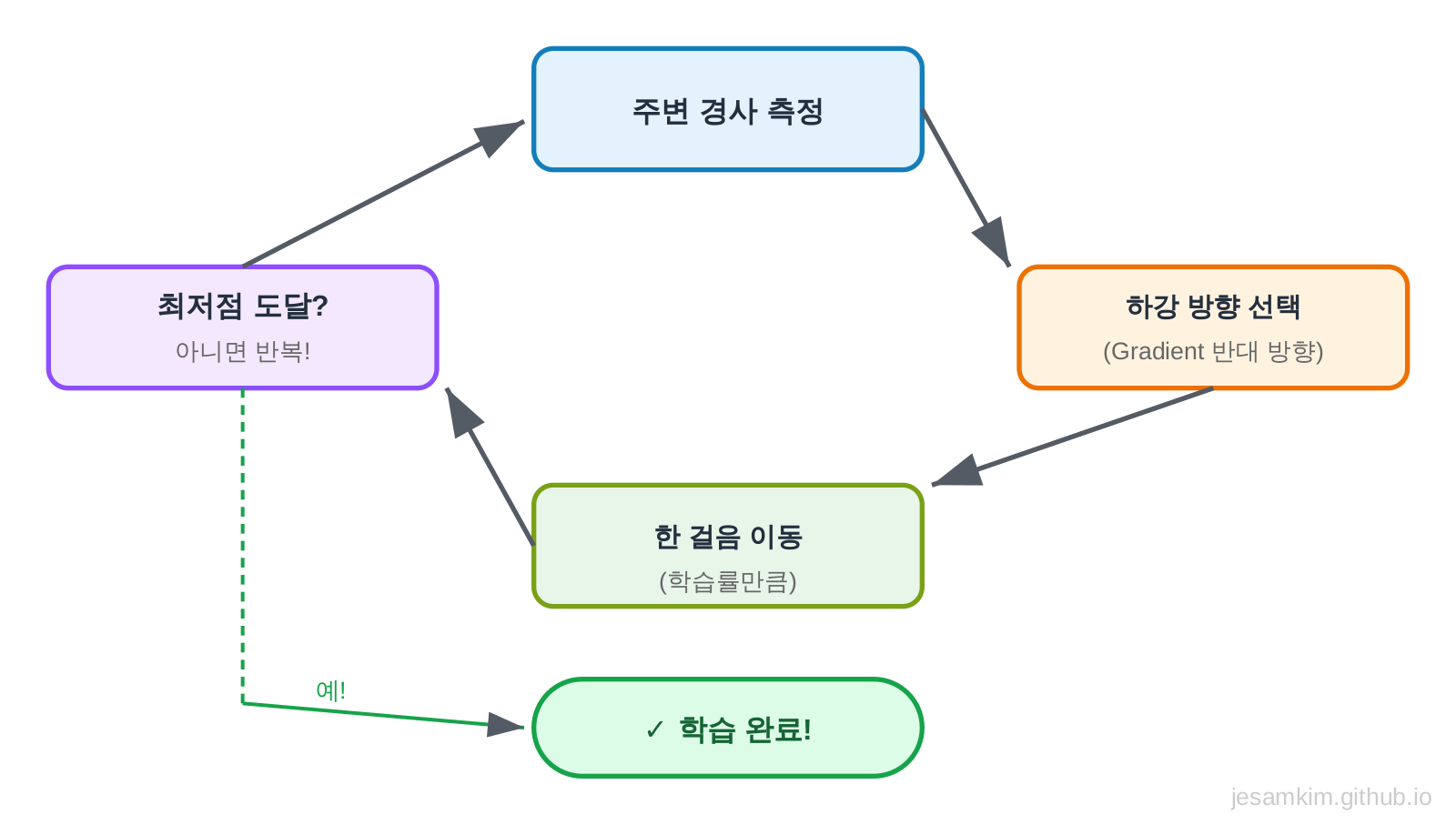
Gradient Descent도 똑같습니다.
- 현재 가중치에서 Loss의 기울기(Gradient)를 계산합니다
- 기울기가 가리키는 반대 방향으로 가중치를 조금 이동합니다
- 이 과정을 반복하면 Loss가 점점 줄어듭니다
여기서 “조금"이 얼마나 조금인지를 결정하는 게 학습률(Learning Rate)입니다. 학습률이 너무 크면 산을 내려가다가 계곡을 건너뛰어버릴 수 있고, 너무 작으면 내려가는 데 너무 오래 걸립니다.
Local Minimum 문제
산 하이킹 비유에서 한 가지 문제가 있습니다. 현재 위치에서 가장 가파른 방향으로만 내려가다 보면, 작은 움푹 팬 곳(Local Minimum)에 빠질 수 있습니다. 진짜 가장 낮은 곳(Global Minimum)은 저 너머에 있는데 말이죠.
딥러닝도 마찬가지입니다. 하지만 다행히, 실제로는 Local Minimum이 생각보다 큰 문제가 되지 않습니다. 딥러닝 모델은 파라미터가 워낙 많아서, 대부분의 Local Minimum이 실용적으로는 충분히 좋은 성능을 내기 때문입니다.
Mini-batch SGD: 효율적으로 학습하기
이론적으로는 전체 데이터를 한꺼번에 사용해서 Gradient를 계산하는 게 가장 정확합니다. 하지만 현실적으로는 불가능합니다.
예를 들어, 이미지 데이터가 5만 장 있다고 해보죠. 매번 5만 장 전체를 모델에 넣어 Loss를 계산하고 Gradient를 구하려면, GPU 메모리도 부족하고 시간도 너무 오래 걸립니다.
그래서 실무에서는 Mini-batch SGD를 사용합니다.
Mini-batch SGD의 원리
전체 데이터를 작은 묶음(Mini-batch)으로 나눕니다. 예를 들어 5만 장을 100장씩 500개의 Mini-batch로 나누는 거죠.
그러고 나서:
- 첫 번째 Mini-batch(100장)로 Gradient를 계산하고 가중치를 업데이트합니다
- 두 번째 Mini-batch(100장)로 Gradient를 계산하고 가중치를 업데이트합니다
- 이 과정을 500번 반복합니다
- 전체 데이터를 한 번 다 본 것을 1 Epoch이라고 합니다
- 데이터를 섞고(Shuffle) 다시 1번부터 반복합니다
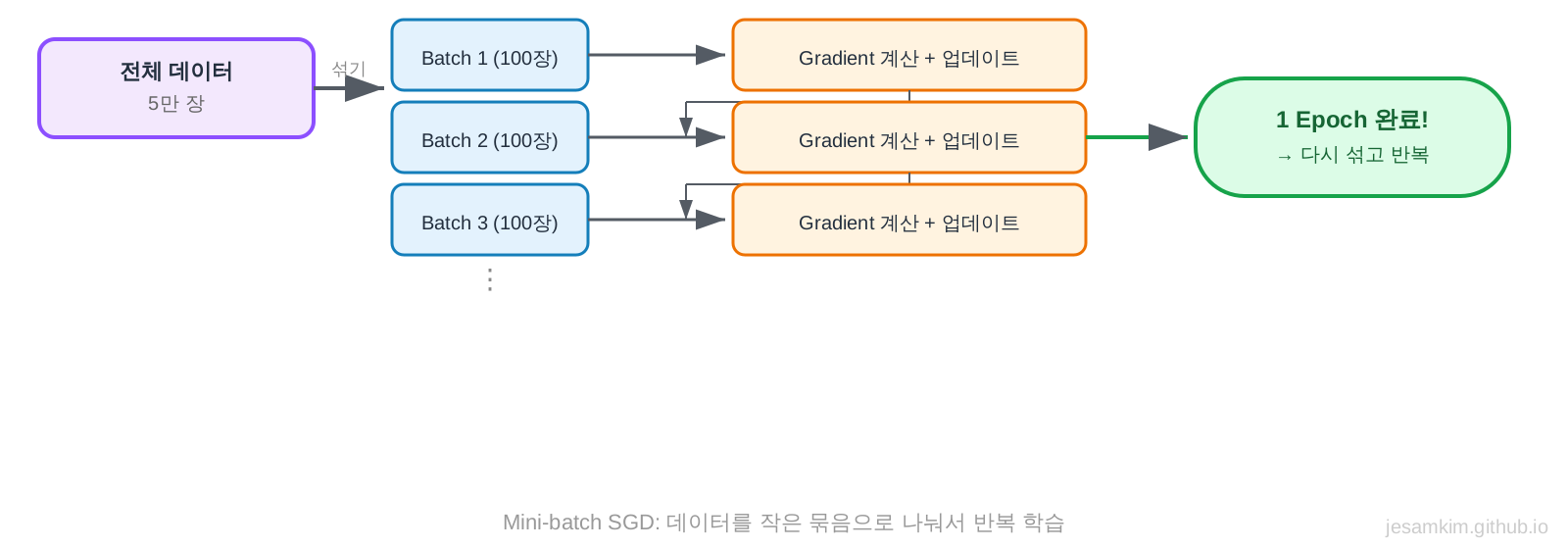
Mini-batch SGD의 장점
- 메모리 효율적: 전체 데이터를 한꺼번에 올릴 필요가 없습니다. 100장씩만 올리면 됩니다.
- 계산 효율적: 100장으로만 Gradient를 근사 계산해도 충분히 정확합니다.
- Local Minimum 탈출: Gradient에 노이즈가 섞이기 때문에, 작은 Local Minimum에서 빠져나오는 데 도움이 됩니다.
물론 단점도 있습니다. Gradient가 정확하지 않기 때문에, 학습 과정이 조금 불안정할 수 있습니다. 하지만 이 정도는 감수할 만한 수준이고, 실무에서는 거의 항상 Mini-batch SGD를 사용합니다.
Optimizer: 더 똑똑하게 학습하기
기본 Gradient Descent는 단순하지만, 문제가 있습니다. 학습이 너무 느리거나, 진동하거나, Local Minimum에 갇히는 경우가 많습니다.
그래서 더 똑똑한 방법들이 개발되었습니다. 이걸 Optimizer라고 부릅니다.
SGD with Momentum
자전거를 타고 언덕을 내려가는 모습을 상상해보세요. 처음에는 천천히 내려가지만, 시간이 지날수록 속도가 붙습니다. 그러다가 작은 언덕을 만나도, 관성 때문에 쉽게 넘어갑니다.
Momentum은 이 아이디어를 적용한 것입니다. 이전 Gradient의 방향성을 기억하고, 같은 방향으로 계속 움직이면 가속이 붙고, 방향이 갑자기 바뀌면 관성 때문에 급격한 변화가 완화됩니다.
장점: 학습이 빨라지고, Local Minimum을 빠져나오는 데 도움이 됩니다.
단점: 가속이 너무 붙으면, 좋은 지점도 지나쳐버릴 수 있습니다.
RMSProp
산길을 걷는데, 어떤 구간은 경사가 급하고 어떤 구간은 완만합니다. 경사가 급한 곳에서는 조심조심 작은 걸음으로 걷고, 완만한 곳에서는 큰 걸음으로 빠르게 걸어야 효율적이겠죠.
RMSProp은 이 아이디어를 적용합니다. Gradient가 큰 방향에서는 학습률을 줄이고, Gradient가 작은 방향에서는 학습률을 늘립니다.
핵심: 학습률을 동적으로 조절해서, 진동을 줄이고 안정적으로 수렴하게 만듭니다.
Adam: 실무의 정석
Adam은 Momentum과 RMSProp을 합친 Optimizer입니다. 실무에서 가장 널리 사용됩니다.
- Momentum처럼 이전 방향성을 기억합니다
- RMSProp처럼 학습률을 동적으로 조절합니다
- 초기 편향(Bias)을 보정하는 기능까지 추가합니다
대부분의 경우, Adam을 쓰면 무난하게 좋은 성능을 냅니다. 딥러닝 초보자라면 일단 Adam부터 써보시면 됩니다.
Optimizer별 메모리 차이
여기서 하나 알아둘 점이 있습니다. Optimizer마다 필요한 메모리가 다릅니다.
- SGD: 가중치만 저장 (메모리 1x)
- SGD + Momentum: 가중치 + Momentum 저장 (메모리 2x)
- RMSProp: 가중치 + 이동평균 저장 (메모리 2x)
- Adam: 가중치 + Momentum + 이동평균 저장 (메모리 3x)
작은 모델에서는 별 문제가 없지만, GPT-3 같은 거대 모델에서는 이 차이가 치명적입니다. 예를 들어 1750억 개의 파라미터가 있는 모델을 Adam으로 학습하면, 파라미터 메모리만 32bit 기준 약 2TB가 필요합니다(175B × 4 bytes × 3 = 2.1TB).
이게 바로 분산 학습이 필요한 이유 중 하나입니다. (다음 수업 주제이기도 합니다.)
Activation Function: 왜 필요한가
신경망의 각 층에는 활성화 함수(Activation Function)가 있습니다. 왜 필요할까요?
선형 변환의 한계
만약 활성화 함수가 없다면, 신경망은 단순히 행렬 곱셈의 연속입니다.
출력 = W3 × (W2 × (W1 × 입력))
행렬의 곱셈은 교환법칙이 성립하므로, 위 식은 결국 하나의 행렬로 합쳐집니다.
출력 = W' × 입력 (여기서 W' = W3 × W2 × W1)
즉, 100개의 층을 쌓아도 1개 층짜리 모델과 다를 게 없습니다. 층을 쌓는 의미가 없어집니다.
비선형 활성화 함수
이 문제를 해결하기 위해 각 층 사이에 비선형(Non-linear) 함수를 넣습니다. 대표적인 것이 ReLU(Rectified Linear Unit)입니다.
ReLU(x) = max(0, x)
0보다 크면 그대로 통과시키고, 0보다 작으면 0으로 만듭니다. 단순하지만 효과적입니다.
비선형 함수가 들어가면, 더 이상 행렬 곱셈으로 합칠 수 없습니다. 층을 쌓는 의미가 생기고, 복잡한 패턴을 학습할 수 있게 됩니다.
주요 활성화 함수들
- ReLU: 가장 많이 사용됩니다. 간단하고 효과적입니다.
- Leaky ReLU: ReLU의 변형. 음수 영역에서도 아주 작은 값을 통과시킵니다.
- GELU: 최근 Transformer 모델에서 많이 사용됩니다.
- Sigmoid: 0~1 사이 값으로 압축합니다. 예전에는 많이 썼지만 지금은 ReLU에 밀렸습니다.
- Tanh: -1~1 사이 값으로 압축합니다.
실무에서는 일단 ReLU부터 써보시면 됩니다.
Overfitting: 너무 잘 외우는 학생
카페 비유로 돌아가 보겠습니다.
당신은 100명의 손님에게 커피를 만들어줬고, 모두 만족했습니다. 이제 101번째 손님이 왔습니다. 이 손님도 만족시킬 수 있을까요?
만약 당신이 100명 손님의 얼굴과 취향을 하나하나 다 외워서 커피를 만들었다면, 101번째 손님은 만족시키지 못할 겁니다. 하지만 “일반적으로 사람들은 이런 커피를 좋아한다"는 원리를 이해했다면, 새로운 손님도 만족시킬 수 있습니다.
딥러닝도 마찬가지입니다.
Overfitting이란
Overfitting(과적합)은 모델이 훈련 데이터는 완벽하게 맞추지만, 새로운 데이터에서는 성능이 떨어지는 현상입니다.
시험에 나온 기출문제는 100점 맞는데, 새로운 문제는 틀리는 학생과 같습니다. 원리를 이해한 게 아니라, 답을 외운 거죠.
| 상태 | 훈련 성능 | 테스트 성능 | 문제 |
|---|---|---|---|
| Underfitting | 낮음 | 낮음 | 모델이 너무 단순 |
| Just right | 높음 | 적절 | 이상적 |
| Overfitting | 매우 높음 | 낮음 | 데이터를 외움 |
Overfitting 해결 방법
1. 데이터를 더 모으기
가장 근본적인 해결책입니다. 데이터가 많을수록 모델이 원리를 배우게 되고, 외우기 어려워집니다.
2. Data Augmentation(데이터 증강)
이미지를 좌우 반전하거나, 회전하거나, 확대/축소하는 등의 변형을 가해서 데이터를 인위적으로 늘립니다. 고양이 사진 1장을 10가지 방법으로 변형하면 10장이 됩니다.
3. Regularization(정규화)
모델이 너무 복잡해지지 않도록 제약을 겁니다. 가중치가 극단적으로 커지는 것을 방지하는 방법입니다.
4. Dropout
학습할 때 일부 뉴런을 무작위로 꺼버립니다. 특정 뉴런에 과도하게 의존하는 것을 방지합니다. 마치 축구팀에서 매 경기마다 일부 선수를 쉬게 하면, 팀 전체의 실력이 골고루 향상되는 것과 비슷합니다.
왜 이걸 알아야 하나
여기까지 딥러닝의 기본 원리를 정리했습니다. 이제 다시 원래 질문으로 돌아가보죠.
“딥러닝이 뭐냐?”
제 답은 이렇습니다.
딥러닝은 데이터를 통해 좋은 가중치를 찾는 과정입니다. Forward로 예측하고, Loss로 틀린 정도를 측정하고, Backpropagation으로 어떻게 고칠지 계산하고, Optimizer로 가중치를 업데이트합니다. 이 네 단계를 수천, 수만 번 반복하면 모델이 학습됩니다.
왜 이 기본을 알아야 할까요?
다음 주부터는 분산 학습을 배웁니다. 여러 GPU에 데이터를 나눠 학습하는 Data Parallelism, 모델을 나눠 학습하는 Model Parallelism 같은 고급 기법들이죠.
하지만 이 모든 기법의 기초는 결국 오늘 정리한 내용입니다. Forward, Loss, Backward, Update. Gradient Descent. Optimizer. Activation Function. Overfitting.
이 기본을 이해하지 못하면, 분산 학습은 그냥 “마법"처럼 보일 겁니다. 하지만 기본을 알면, 분산 학습이 왜 필요한지, 어떻게 작동하는지, 어떤 문제를 해결하는지 명확하게 이해할 수 있습니다.
기본이 탄탄하면, 그 위에 뭘 쌓든 흔들리지 않습니다. 이 글이 누군가에게 그런 기초가 되었으면 합니다.
References
- Bommasani et al., On the Opportunities and Risks of Foundation Models, arXiv:2108.07258, 2022
- Goodfellow et al., Deep Learning, MIT Press, 2016
- Kingma & Ba, Adam: A Method for Stochastic Optimization, ICLR 2015