비전 언어 모델(VLM)은 이미지와 텍스트를 동시에 이해하는 AI 모델입니다. 하지만 제조 현장에서 실제 가치를 만들려면 이미지를 해석하는 것만으로는 부족합니다. 물리 법칙을 예측하고 로봇을 직접 제어해야 합니다. 이 글에서는 VLM이 World Model과 VLA(Vision-Language-Action)로 확장되며 제조 산업을 바꾸는 과정과, AWS 기반 구현 방법을 다룹니다.
1. VLM의 진화: 텍스트를 넘어 시각 세계로
비전 언어 모델(VLM)은 이미지와 텍스트를 함께 처리하는 멀티모달 AI입니다. GPT-4o, Gemini 2.5 Pro, Claude Sonnet 4.6 Vision 같은 최신 VLM은 이미지 분류를 넘어 장면을 이해하고 질문에 답합니다. 추론도 수행합니다.
VLM의 작동 원리
VLM은 두 가지 핵심 구성 요소로 만들어집니다.
- Vision Encoder: Vision Transformer(ViT) 같은 모델이 이미지를 토큰 시퀀스로 변환합니다.
- Language Model: 텍스트와 이미지 토큰을 함께 처리해 멀티모달 추론을 수행합니다.
예를 들어, Claude Sonnet 4.6 Vision에 반도체 웨이퍼 맵 이미지를 입력하면 “중심부에 링 형태 결함이 보입니다. 화학적 오염 가능성이 있습니다"라고 자연어로 설명합니다.
기존 CNN 비전 vs VLM
전통적인 CNN 기반 비전 시스템은 특정 작업(예: 불량 분류)을 위해 수천 장의 라벨링된 이미지로 학습해야 했습니다. 하지만 VLM은 인터넷 규모의 이미지-텍스트 데이터로 사전 학습되어, Few-shot 학습만으로도 새로운 작업에 적응할 수 있습니다.
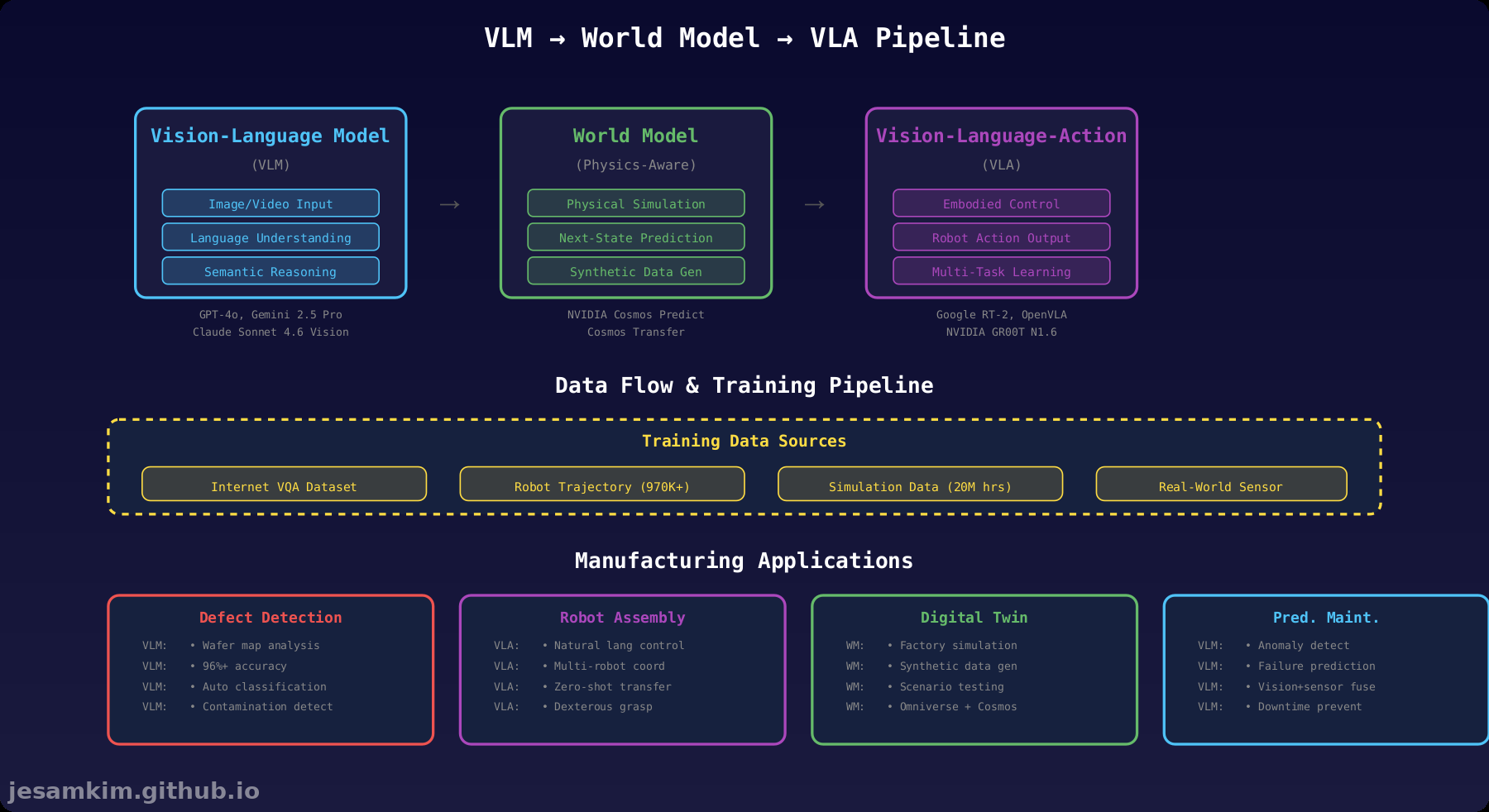
2. World Model: AI가 물리 법칙을 학습하는 방법
VLM은 이미지를 이해하지만, “다음에 무슨 일이 일어날까?"를 예측하지는 못합니다. World Model은 이 간극을 메웁니다.
NVIDIA Cosmos 플랫폼
NVIDIA Cosmos는 물리 법칙을 학습한 World Foundation Model(WFM) 플랫폼입니다. 2025년 8월 공개된 Cosmos는 세 가지 핵심 모델로 구성됩니다.
- Cosmos Predict: 현재 상태에서 다음 프레임을 예측합니다. 로봇이 물체를 집으면 어떻게 움직일지 시뮬레이션합니다.
- Cosmos Transfer: 시뮬레이션 환경과 실제 환경 간 도메인 갭을 줄입니다. 가상 공장에서 학습한 로봇이 실제 공장에서도 작동하도록 돕습니다.
- Cosmos Reason 2: 7B 파라미터 규모의 추론 VLM입니다. Physical AI 작업에 특화되어 있습니다.
Cosmos는 20만 시간 분량의 실제 데이터로 학습되었으며, 자율주행(Uber, Waabi), 로봇(1X, Agility Robotics) 같은 분야에서 활용됩니다.
World Model의 역할
World Model은 합성 데이터를 생성해 학습 데이터 부족 문제를 해결합니다. 예를 들어, 드문 불량 유형(연간 10건 미만)도 시뮬레이션에서 수천 건을 생성해 AI를 학습시킬 수 있습니다.
3. VLA (Vision-Language-Action): 이미지를 로봇 동작으로 변환
Vision-Language-Action(VLA) 모델은 VLM에 로봇 제어 능력을 더한 것입니다. VLM이 “무엇을 해야 하는지” 이해한다면, VLA는 “어떻게 할지"를 로봇 제어 신호로 출력합니다.
VLA의 작동 원리
VLA는 세 가지 인코더를 병렬로 처리합니다.
- Vision Encoder: RGB/Depth 카메라 입력을 시각 특징으로 변환
- Language Encoder: 자연어 명령을 임베딩으로 변환
- State Encoder: 로봇의 관절 각도, 그리퍼 상태 같은 proprioceptive 데이터를 처리
이 세 가지 정보를 통합해 Action Decoder가 로봇 제어 신호(관절 속도, 토크)를 생성합니다.
주요 VLA 모델
Google RT-2 (Robotic Transformer)
Problem: 기존 로봇은 사전 정의된 동작만 수행하며, 새로운 물체나 상황에 일반화할 수 없었습니다.
Contribution: 인터넷 VQA 데이터와 로봇 궤적 데이터를 공동 학습해 zero-shot 일반화를 달성했습니다.
Method: PaLI-X/PaLM-E 백본에 로봇 액션을 텍스트 토큰으로 변환해 autoregressive 방식으로 학습합니다.
RT-2는 “가장 작은 물체를 집어줘” 같은 학습하지 않은 명령도 처리할 수 있습니다.
OpenVLA
Problem: 기존 VLA(RT-2 등)는 폐쇄형으로 재현과 확장이 불가능했습니다.
Contribution: 7B 파라미터 규모의 오픈소스 VLA로, 970K 에피소드로 학습하며 LoRA 1.4% 파인튜닝만으로 풀 튜닝 성능을 달성했습니다.
Method: Prismatic VLM 백본에 Open X-Embodiment 데이터셋을 사용하고, diffusion action decoder로 액션을 생성합니다.
OpenVLA는 여러 로봇 플랫폼을 지원하므로, 제조사가 자사 환경에 빠르게 배포할 수 있습니다.
NVIDIA GR00T N1.6
CES 2026에서 공개된 휴머노이드 로봇용 VLA입니다. Cosmos와 통합되어 시뮬레이션에서 학습 후 실제 로봇으로 전이됩니다.
4. 제조 산업에서의 Physical AI 활용
Physical AI는 이미 제조 현장에서 실제 가치를 만들고 있습니다.
불량 검출 (Defect Detection)
NVIDIA Cosmos Reason VLM은 반도체 웨이퍼 맵 불량 분류에서 96% 이상의 정확도를 달성했습니다. 이전에는 수천 장의 라벨링 이미지가 필요했지만, Few-shot 학습으로 수십 장만으로도 새로운 불량 유형을 학습합니다.
NV-DINOv2 같은 Vision Foundation Model은 대량의 라벨 없는 이미지로 자기지도 학습(SSL) 기반 도메인 적응을 수행한 후, 최소한의 라벨링 데이터로 다이 레벨 불량 검출 정확도를 최대 8.9% 향상시켰습니다. 이는 생산성 기준 최대 9.9% 개선에 해당합니다.
제조 도메인에 특화된 VLM도 등장하고 있습니다. MaViLa(Manufacturing Vision-Language Model)는 비정형 불량 검출, 공정 모니터링, 품질 보고서 자동 생성을 통합합니다.
Problem: 범용 VLM은 제조 도메인 특화 지식이 부족하고, 동적 생산 환경에 대응하기 어렵습니다.
Contribution: 제조 특화 VLM으로 비정형 불량 검출, 공정 모니터링, 품질 보고서 자동 생성을 통합 지원합니다.
Method: 제조 도메인 이미지-텍스트 데이터로 파인튜닝하고 multi-task learning을 적용합니다.
로봇 조립 및 피킹 (Robot Assembly & Picking)
VLA 기반 산업용 로봇은 자연어 명령으로 제어됩니다. “파란색 부품을 집어서 왼쪽 슬롯에 조립해줘” 같은 지시를 이해하고 실행합니다.
RT-2와 OpenVLA는 이러한 작업에 실제로 활용되고 있습니다. RT-2는 Zero-shot 전이가 가능해서 학습하지 않은 물체도 조작할 수 있으며, OpenVLA는 여러 로봇 플랫폼을 지원해 제조사가 자사 환경에 빠르게 배포할 수 있습니다.
디지털 트윈 + World Model
NVIDIA Omniverse와 Cosmos를 결합하면 공장 전체를 디지털 트윈으로 구축할 수 있습니다. World Model이 물리 시뮬레이션을 수행하며, 다음 상황을 테스트할 수 있습니다.
- 생산 라인 재배치 시 처리량 변화 예측
- 새 로봇 도입 전 시뮬레이션 테스트
- 드문 장애 시나리오 합성 데이터 생성
디지털 트윈은 실제 공장과 실시간 동기화되어, Sim-to-Real 갭을 줄입니다.
예지 보전 (Predictive Maintenance)
VLM은 비전(열화상, RGB 카메라)과 센서 데이터(진동, 온도)를 융합해 장비 이상을 조기 감지합니다. 예를 들어, 컨베이어 벨트의 미세한 진동 패턴과 열화상 이미지를 분석해 72시간 내 고장을 예측하고 자동으로 정비 요청을 생성할 수 있습니다.
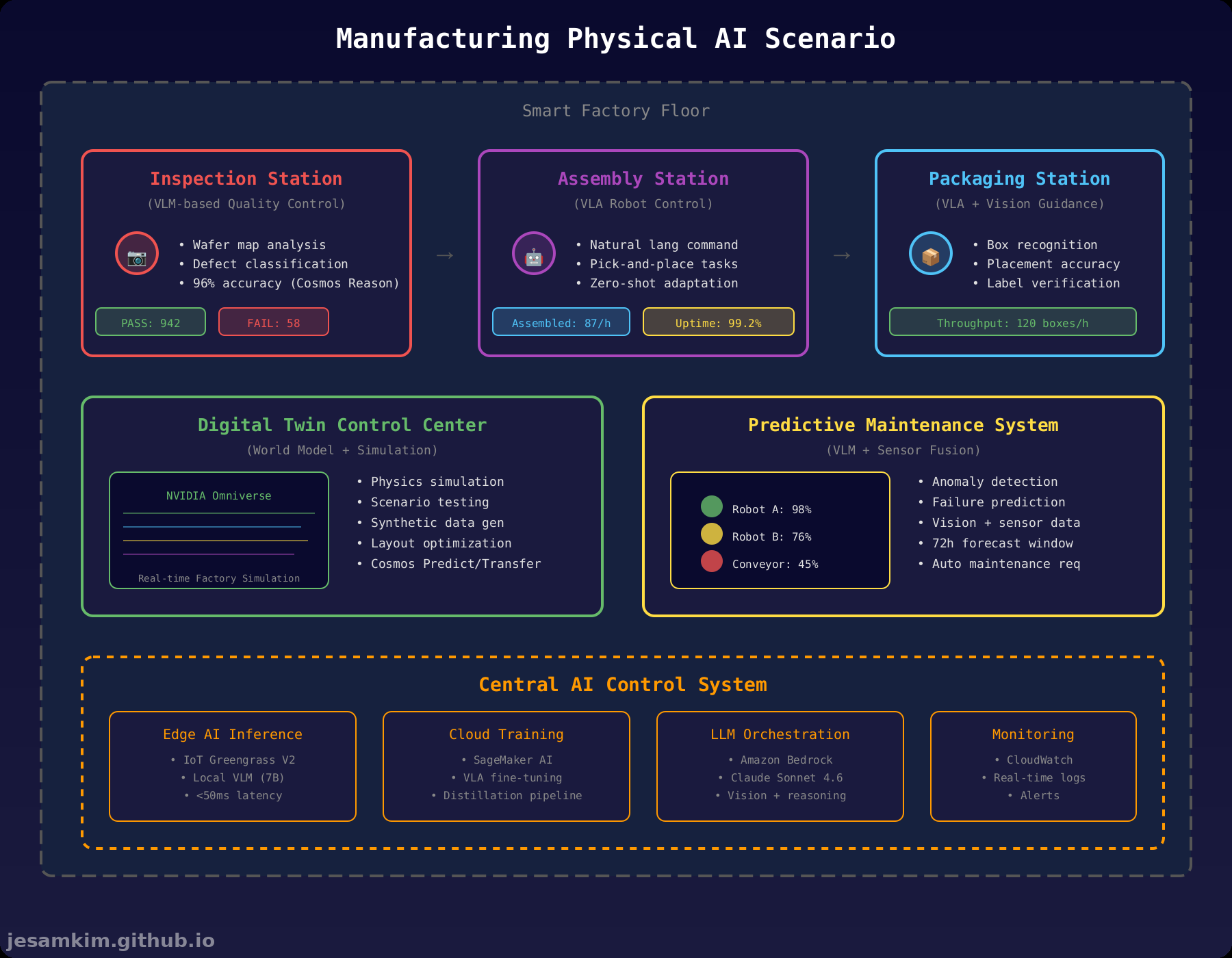
5. AWS 기반 Physical AI 아키텍처 제안
제조 현장에 Physical AI를 배포하려면 엣지와 클라우드를 통합한 아키텍처가 필요합니다. AWS 서비스를 활용한 구성안을 소개합니다.
엣지 레이어 (Factory Floor)
AWS IoT Greengrass V2가 공장 현장의 엣지 AI 엔진 역할을 합니다.
- 로컬 VLM 추론: 7B 파라미터 모델을 FP8 양자화해 엣지에서 실행합니다. 50ms 미만 레이턴시로 실시간 불량 검출이 가능합니다.
- 오프라인 동작: 네트워크 단절 시에도 로컬 추론을 계속합니다.
- 데이터 전처리: 원시 센서 데이터를 압축하고 중요한 이벤트만 클라우드로 전송해 대역폭을 절약합니다.
클라우드 처리 레이어
AWS IoT Core는 MQTT 브로커로 동작하며 초당 50만 건의 메시지를 처리합니다. Device Shadow로 로봇 상태를 추적하고, Rules Engine으로 이벤트 기반 워크플로를 실행합니다.
Amazon Bedrock (Claude Sonnet 4.6 Vision)은 서버리스 VLM 추론을 제공합니다. 엣지에서 처리하기 어려운 복잡한 추론 작업(예: 불량 원인 설명, 다단계 조립 계획)을 처리하며, 토큰당 과금으로 비용 효율적입니다.
SageMaker AI는 커스텀 VLA 파인튜닝 환경입니다. P5.48xlarge 인스턴스(H100 GPU 8개)에서 OpenVLA 같은 모델을 자사 로봇 궤적 데이터로 학습합니다. LoRA 기법으로 학습 비용을 줄이고, 학습된 모델을 증류해 엣지용 경량 모델을 만듭니다.
AWS IoT TwinMaker는 공장의 디지털 트윈을 구축합니다. 3D 모델과 실시간 센서 데이터를 통합하고, Grafana 대시보드로 시각화합니다. What-if 시나리오 테스트로 레이아웃 최적화를 지원합니다.
데이터 & 분석 레이어
- Amazon S3: 페타바이트급 원시 센서 데이터와 학습 데이터셋을 저장합니다.
- Amazon Timestream: 시계열 DB로 센서 메트릭과 장비 건강 점수를 저장합니다.
- Amazon Kinesis Streams: 초당 8K FPS 비디오 스트림과 이벤트를 실시간 처리합니다.
- Amazon CloudWatch: 모델 성능 메트릭과 이상 감지 알람을 관리합니다.
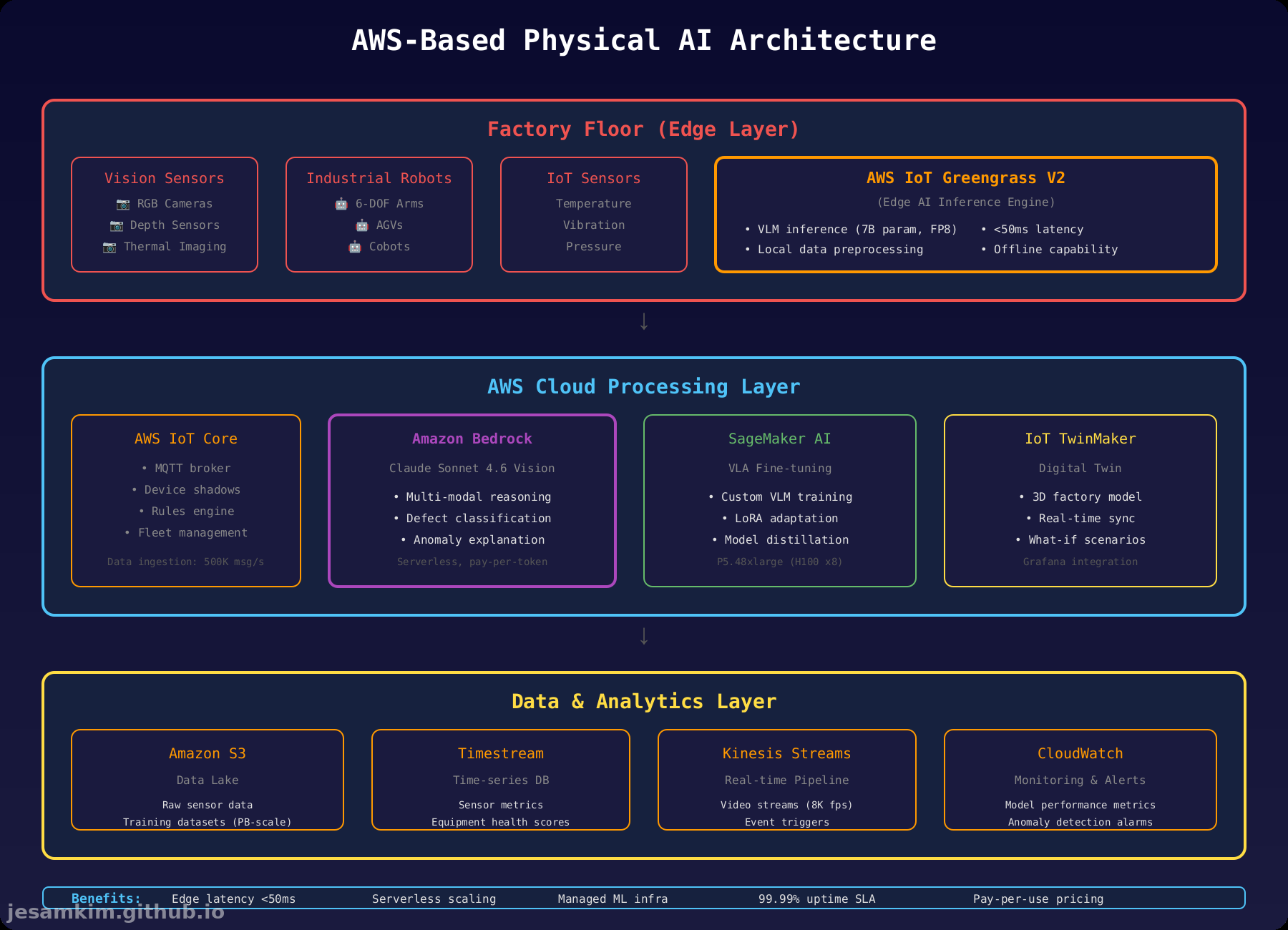
아키텍처의 장점
- 엣지 레이턴시 50ms 미만: 실시간 제어가 필요한 로봇 작업에 적합
- 서버리스 스케일링: Bedrock과 IoT Core가 트래픽에 따라 자동 확장
- 관리형 ML 인프라: SageMaker AI가 학습, 배포, 모니터링을 통합 관리
- 99.99% 가동률 SLA: 미션 크리티컬한 제조 환경에 적합
- 사용량 기반 과금: Bedrock 토큰 과금, Greengrass 디바이스당 과금으로 초기 투자 비용 절감
6. 전망과 과제
Physical AI는 제조 산업을 바꿀 잠재력이 있지만, 넘어야 할 산도 많습니다.
Sim-to-Real Gap
시뮬레이션에서 학습한 AI가 실제 환경에서 제대로 작동하지 않는 문제입니다. NVIDIA Cosmos Transfer 같은 도메인 적응 기술이 이 갭을 줄이고 있지만, 완전히 해결되지는 않았습니다. 특히 조명 변화, 마모된 부품, 예상 밖의 물체 같은 현실의 변수는 여전히 어렵습니다.
안전성과 신뢰성
로봇이 사람과 함께 일하는 환경에서 AI의 실수는 부상으로 이어질 수 있습니다. VLA 모델이 잘못된 액션을 출력하면 어떻게 막을까요? 안전 가드레일, 비상 정지 메커니즘, 사람 개입 프로토콜이 필수입니다.
학습 데이터 부족
제조 현장마다 환경이 다르고, 특히 드문 불량 유형이나 고장 시나리오는 데이터가 거의 없습니다. Few-shot 학습과 합성 데이터 생성이 도움이 되지만, 실제 데이터를 완전히 대체하지는 못합니다.
도입 비용과 인프라
엣지 AI 하드웨어, 클라우드 인프라, 모델 파인튜닝 비용이 만만치 않습니다. 중소 제조사에게는 초기 투자 부담이 큽니다. AWS 같은 클라우드 플랫폼의 관리형 서비스와 사용량 기반 과금이 진입 장벽을 낮추고 있지만, ROI를 명확히 계산해야 합니다.
숙련 인력 부족
Physical AI 시스템을 운영할 수 있는 인력이 부족합니다. VLM, VLA, World Model, 로봇 공학, 클라우드 인프라를 모두 이해하는 인재는 드뭅니다.
현실적인 접근
제조 현장 도입 시 다음을 고려해야 합니다.
- 작은 파일럿부터 시작: 전체 공장을 한 번에 바꾸지 말고, 한 라인이나 한 작업부터 테스트합니다.
- 명확한 KPI 설정: 불량률 감소율, 생산량 증가율 같은 측정 가능한 목표를 정합니다.
- 기존 시스템과 통합: MES, ERP, SCADA 같은 레거시 시스템과의 연동 계획을 세웁니다.
- 사람과 AI 협업: AI가 사람을 대체하는 게 아니라, 사람의 판단을 돕는 방향으로 설계합니다.
Physical AI는 아직 초기 단계입니다. 하지만 VLM에서 World Model, VLA로 이어지는 기술 스택은 빠르게 발전하고 있습니다. AWS 같은 클라우드 플랫폼이 인프라 장벽을 낮추고, NVIDIA Cosmos와 OpenVLA 같은 오픈 플랫폼이 접근성을 높입니다.
References
- NVIDIA Cosmos World Foundation Models (2025). https://blogs.nvidia.com/blog/cosmos-world-foundation-models/
- NVIDIA Cosmos Reason & new models (2025). https://techcrunch.com/2025/08/11/nvidia-unveils-new-cosmos-world-models-other-infra-for-physical-applications-of-ai/
- NVIDIA GR00T at CES 2026. https://techcrunch.com/2026/01/05/nvidia-wants-to-be-the-android-of-generalist-robotics/
- NVIDIA Semiconductor Defect Classification with VLM (2024). https://developer.nvidia.com/blog/optimizing-semiconductor-defect-classification-with-generative-ai-and-vision-foundation-models/
- Brohan et al., “RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control” (2023). https://arxiv.org/abs/2307.15818
- Pertsch et al., “OpenVLA: An Open-Source Vision-Language-Action Model” (2024). https://openvla.github.io/
- Hu et al., “MaViLa: Manufacturing Vision Language Model for integrated defect detection, process monitoring, and quality reporting” (2025). https://www.sciencedirect.com/science/article/pii/S0278612525000470
- Liang et al., “Vision-Language-Action Models: A Survey” (2025). https://arxiv.org/html/2507.10672v1