1. 1M 시대의 도래
Anthropic은 2025년 Claude Sonnet 4.5에서 처음 1M 토큰 컨텍스트 윈도우를 도입했고, 이후 Opus 4.6(2025), Sonnet 4.6(2026년 2월)까지 이어지며 1M 컨텍스트가 표준으로 자리 잡았습니다. 단일 요청으로 약 750페이지 분량의 문서를 처리할 수 있습니다. Amazon Bedrock에서도 context-1m 베타 기능이 활성화되면서, 기업 환경에서도 대규모 문서 처리가 가능해졌습니다.
200K 토큰으로도 충분히 넓다고 생각했던 시절이 불과 1년 전입니다. 그런데 1M 토큰이 주어진 지금, 과연 모든 작업에 긴 컨텍스트를 사용하는 것이 최선일까요? 많은 개발자들이 “길면 길수록 좋다"는 직관을 따르지만, 실제로는 컨텍스트 길이가 늘어날수록 성능이 떨어지는 현상이 연구를 통해 확인되었습니다.
이번 글에서는 Context Rot, Lost in the Middle, BABILong 같은 벤치마크 연구 결과를 통해 긴 컨텍스트의 실체를 파악하고, 언제 200K를 쓰고 언제 1M을 써야 하는지, 그리고 RAG와 어떻게 조합해야 하는지를 정리했습니다.
2. 길면 다 좋다의 함정: Context Rot
Chroma Research가 2025년에 발표한 연구에 따르면, LLM의 컨텍스트 윈도우가 길어질수록 입력 토큰 증가에 비례해 성능이 저하되는 현상이 관찰되었습니다. 이를 “Context Rot"이라고 부릅니다.
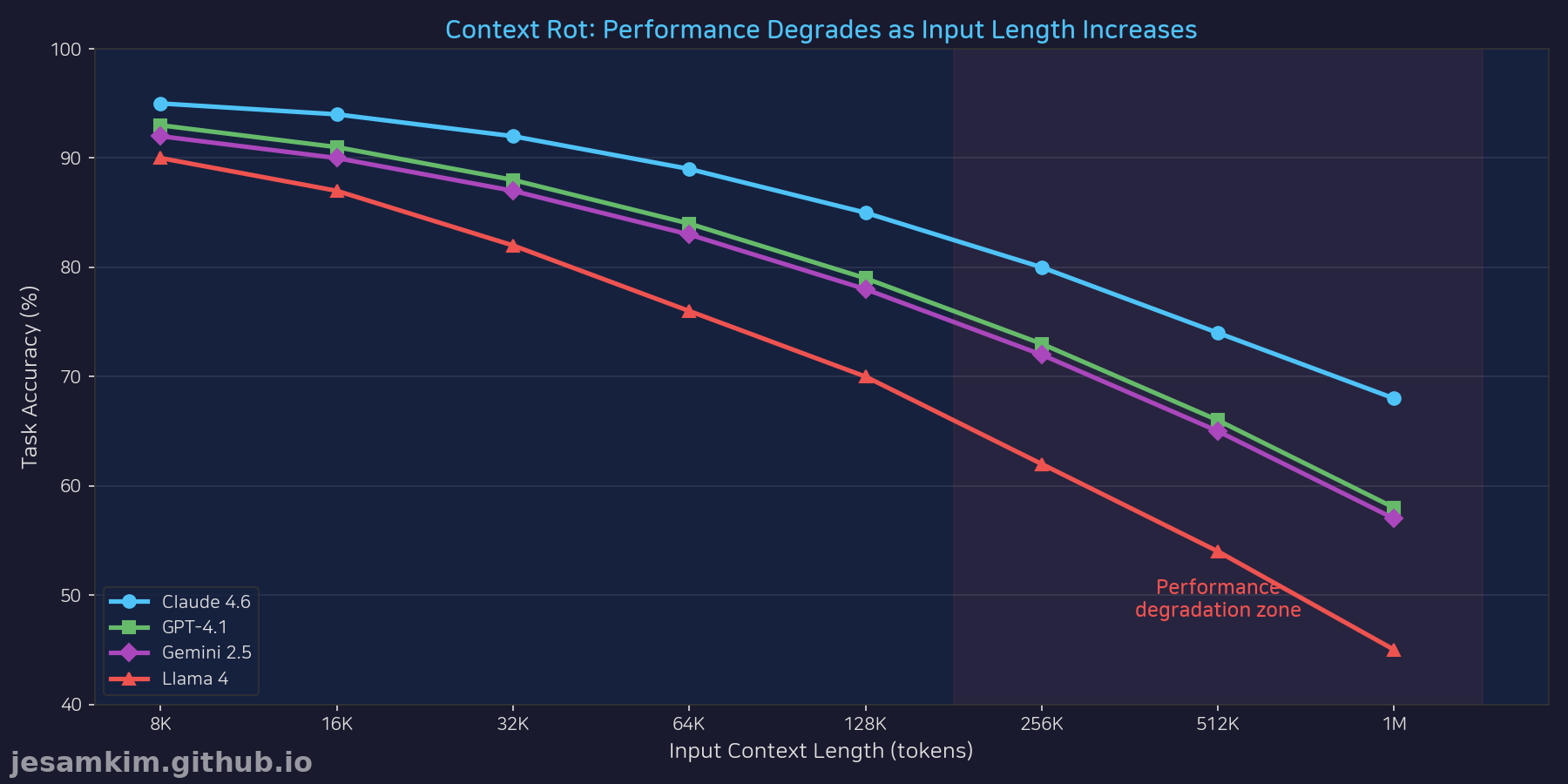 Chroma Research (2025) 데이터를 참고한 시각화
Chroma Research (2025) 데이터를 참고한 시각화
위 차트는 Claude, GPT-4, Gemini 등 주요 LLM들이 컨텍스트 크기가 증가할수록 어떻게 성능이 떨어지는지를 보여줍니다. 특히 주목할 점은:
- 50K 토큰까지는 대부분 모델이 안정적인 성능을 유지합니다.
- 100K 토큰을 넘어서면 정확도가 눈에 띄게 감소하기 시작합니다.
- 200K 이상에서는 일부 모델이 20~30% 성능 저하를 겪습니다.
이는 단순히 “긴 컨텍스트를 지원한다"는 것과 “긴 컨텍스트를 효과적으로 활용한다"는 것이 다르다는 점을 시사합니다. 1M 토큰 지원이 곧 1M 토큰 전체를 동일한 정확도로 처리한다는 의미는 아닙니다.
3. 중간에서 길을 잃다: Lost in the Middle
스탠포드 대학 연구팀이 2023년 발표한 “Lost in the Middle” 논문은 LLM이 컨텍스트의 중간 부분에 있는 정보를 제대로 인식하지 못하는 현상을 밝혀냈습니다.
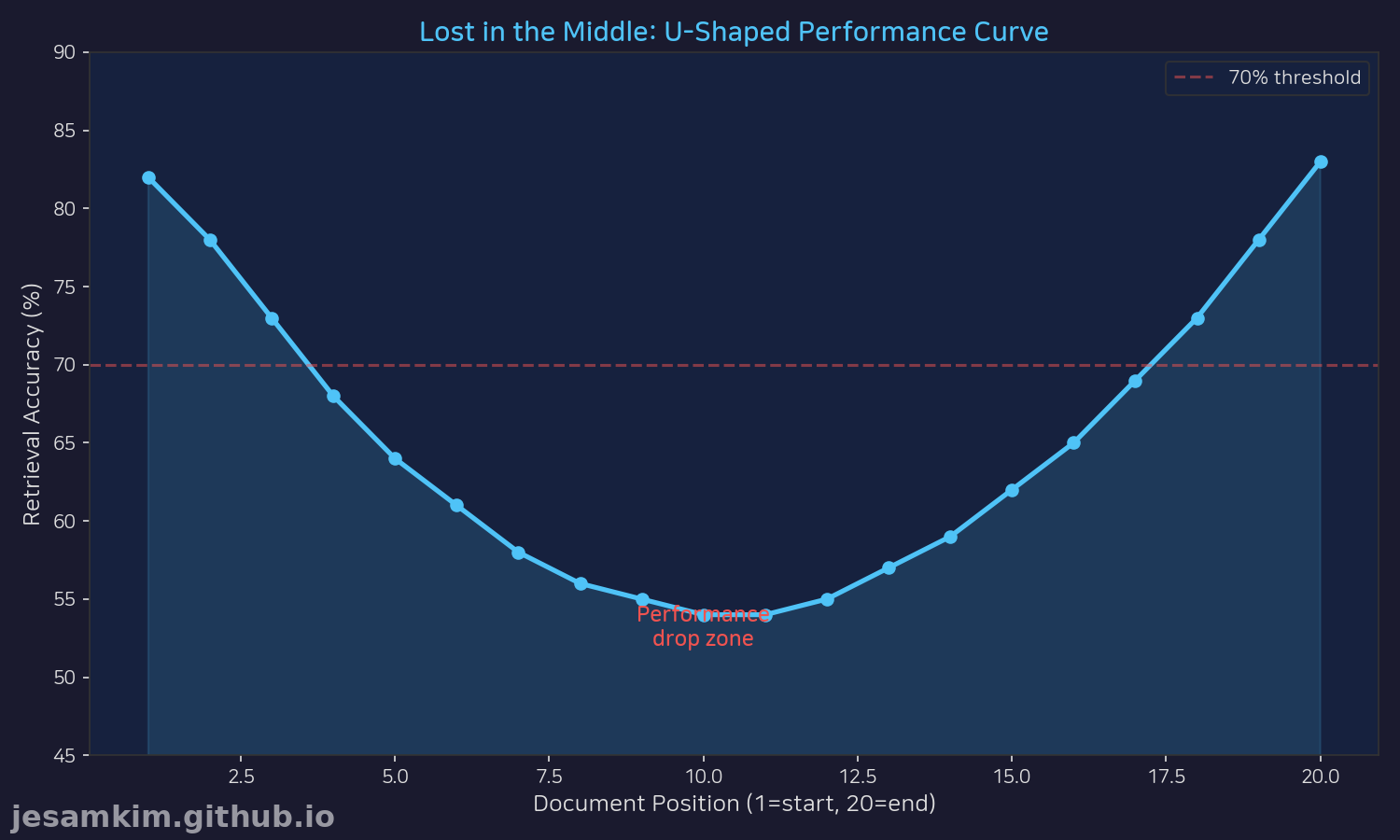
실험 결과, LLM은 문서의 시작 부분과 끝 부분에 있는 정보는 잘 찾아내지만, 중간 부분(50% 지점)에 배치된 정보는 정확도가 60% 수준으로 급격히 떨어졌습니다. 사람이 책을 읽을 때 서론과 결론은 기억하지만 중간 내용은 흐릿해지는 것과 비슷합니다.
실무에서 이게 문제가 되는 경우:
- 200K 토큰 문서를 입력하면 100K 토큰 지점(중간)의 정보를 놓칠 수 있습니다.
- RAG로 검색한 청크를 단순히 나열하면 중간 청크가 무시됩니다.
- 다중 문서 요약 시 중간에 삽입된 문서 내용이 누락됩니다.
해결책은 두 가지입니다. 중요한 정보를 컨텍스트의 앞이나 뒤에 배치하거나, 청크를 재정렬하세요.
4. 검색 너머의 추론: BABILong
Needle-in-a-Haystack(NIAH) 테스트는 “긴 문서에서 특정 정보를 찾을 수 있는가"를 측정하는 단순 검색 벤치마크입니다. 하지만 실제 업무는 단순 검색이 아니라 추론을 요구합니다.
NeurIPS 2024에서 발표된 BABILong 벤치마크는 이 문제를 해결하기 위해 설계되었습니다. NIAH가 “특정 문장이 있는가?“를 묻는다면, BABILong은 “문서 전체를 읽고 논리적 추론을 수행할 수 있는가?“를 측정합니다.
차이를 보시죠:
- NIAH: “John이 사무실로 갔다"는 문장이 10만 토큰 어딘가에 있습니다. 찾으세요.
- BABILong: John, Mary, Bob이 각각 다른 시간에 다른 장소로 이동했습니다. 오후 3시에 John과 Mary가 같은 장소에 있었나요?
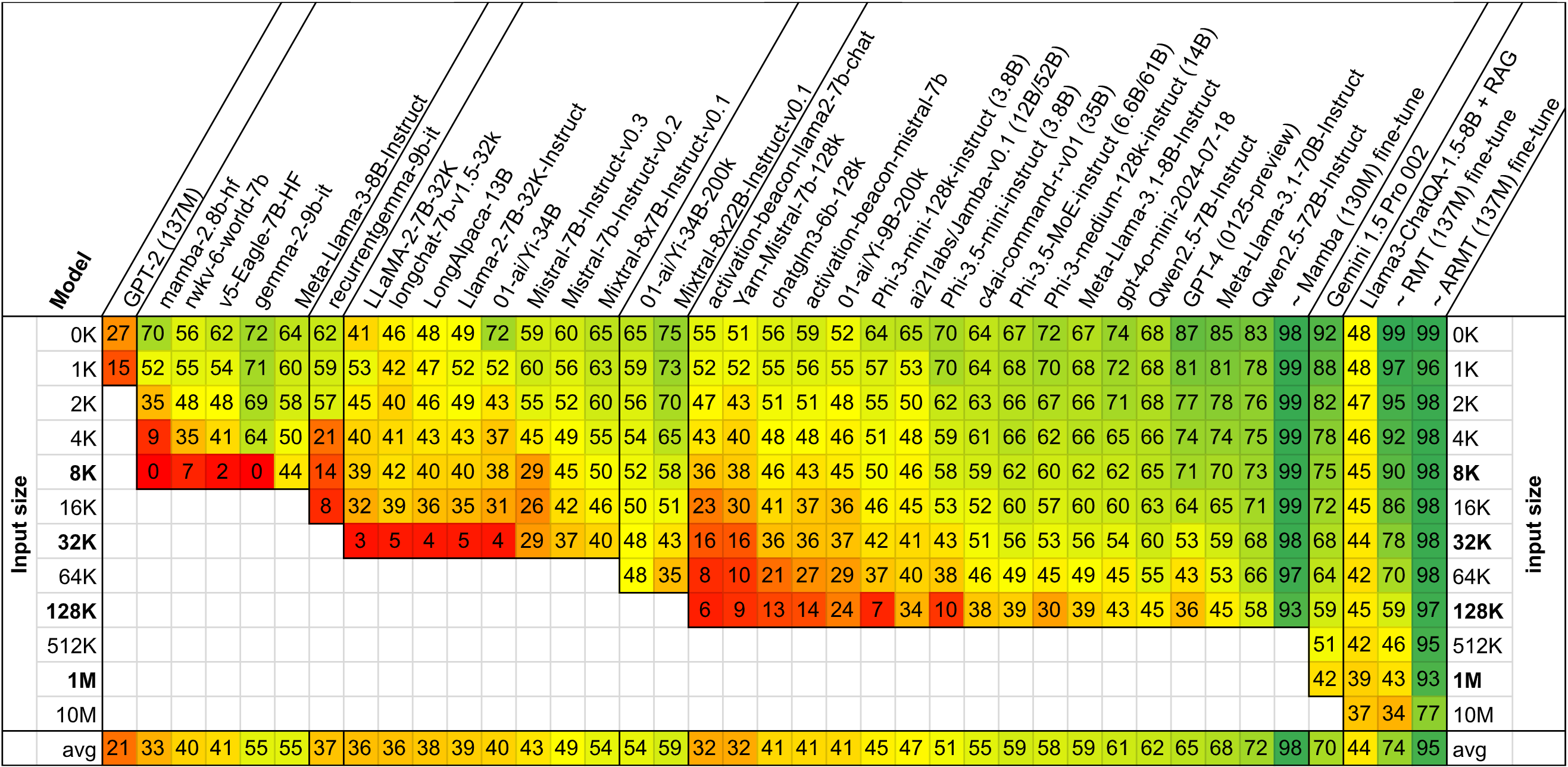 BABILong 벤치마크 결과. 컨텍스트가 길어질수록 대부분 모델의 정확도가 급격히 하락합니다 (녹색=높은 정확도, 빨간색=낮은 정확도). 출처: Kuratov et al., NeurIPS 2024
BABILong 벤치마크 결과. 컨텍스트가 길어질수록 대부분 모델의 정확도가 급격히 하락합니다 (녹색=높은 정확도, 빨간색=낮은 정확도). 출처: Kuratov et al., NeurIPS 2024
BABILong 결과, 대부분 LLM은 100K 토큰을 넘어서면 추론 정확도가 50% 이하로 떨어졌습니다. 단순 검색은 잘하지만, 컨텍스트 전체를 이해하고 논리적 결론을 도출하는 능력은 여전히 제한적입니다.
이는 긴 컨텍스트가 “모든 것을 기억하는 마법"이 아니라, 추론 작업에는 여전히 한계가 있음을 보여줍니다.
5. RAG vs Long Context: 대립이 아닌 보완
긴 컨텍스트가 등장하면서 “RAG는 이제 필요 없다"는 주장이 나왔습니다. 하지만 최근 연구들은 RAG와 Long Context가 상호 보완적이라는 것을 입증했습니다.
LaRA: Long Context RAG 하이브리드
2025년 2월 발표된 LaRA(Long-context Retrieval-Augmented) 논문은 RAG와 Long Context를 결합한 아키텍처를 제안했습니다:
- 1단계: RAG로 관련 문서를 검색 (상위 10~20개 청크)
- 2단계: 검색된 청크를 Long Context에 입력
- 3단계: LLM이 전체 맥락을 고려해 추론
이 방식은 RAG의 효율성(전체 문서를 입력하지 않음)과 Long Context의 추론 능력(청크 간 관계 파악)을 결합합니다.
U-NIAH: 중간 손실 문제 해결
2025년 3월 발표된 U-NIAH(Unbiased Needle-in-a-Haystack) 연구는 Lost in the Middle 문제를 해결하기 위해 청크 재정렬 전략을 제안했습니다:
- 중요도가 높은 청크를 컨텍스트 앞쪽과 뒤쪽에 배치
- 보조 정보는 중간에 배치
- 이를 통해 U자형 성능 곡선을 평탄화
의사결정 플로우
언제 RAG를 쓰고, 언제 Long Context를 써야 할까요?
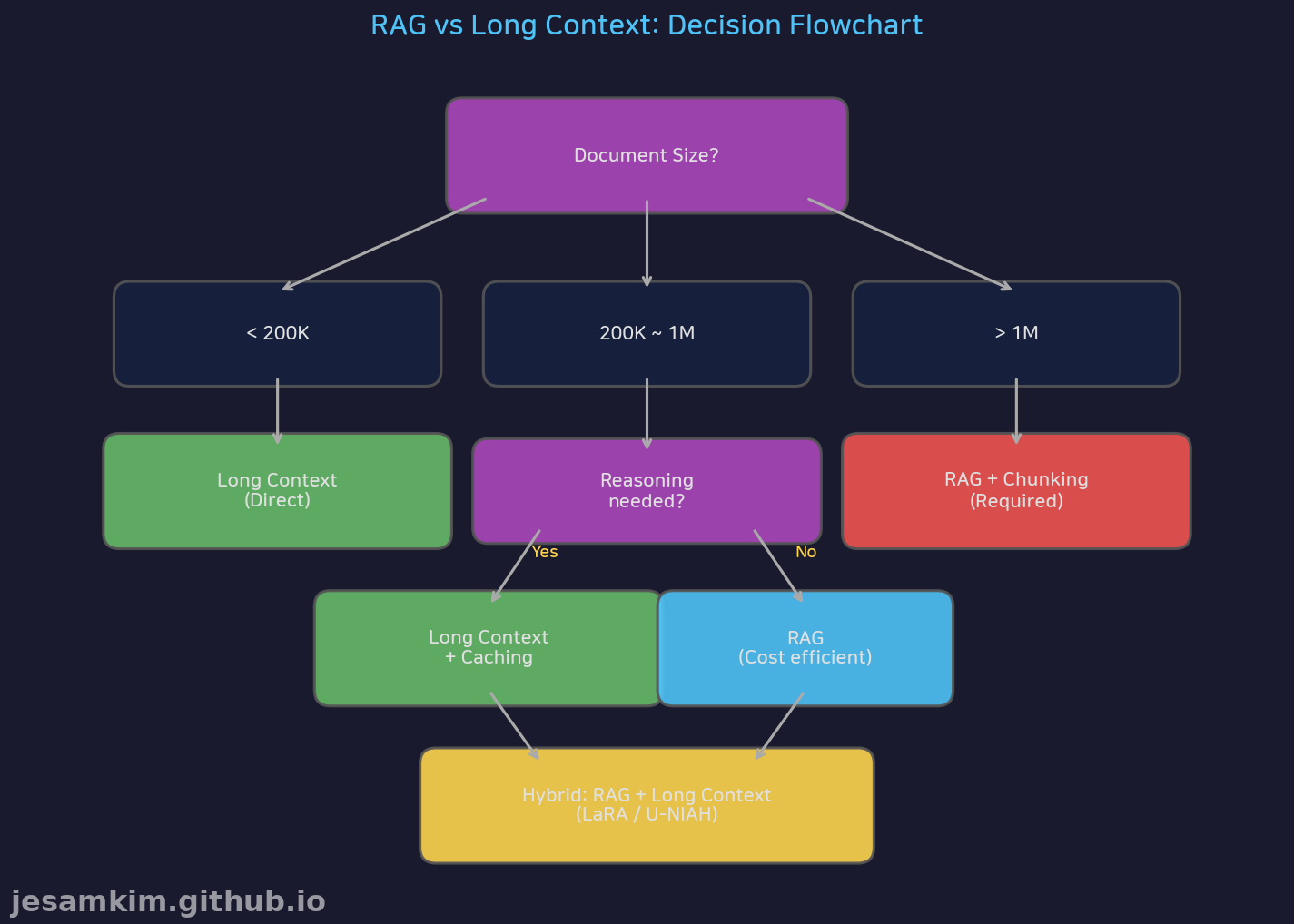
판단 기준은 간단합니다:
- 200K 이하: Long Context 직접 사용
- 200K~1M: 추론이 필요하면 Long Context + Caching, 단순 검색이면 RAG
- 1M 초과: RAG + 청킹 필수
6. 비용과 레이턴시의 현실
긴 컨텍스트의 가장 큰 장벽은 비용과 레이턴시입니다.
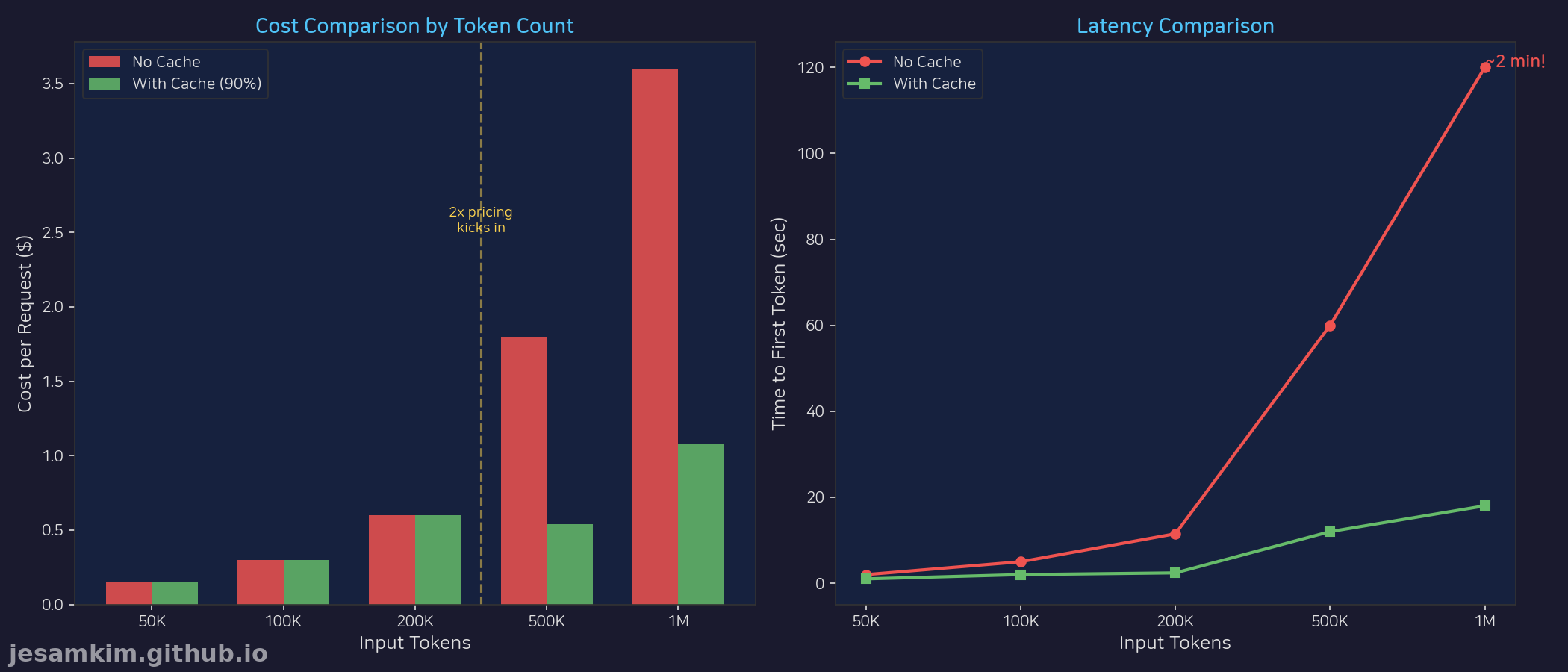
비용 구조
Claude Sonnet 4.6 기준:
- 200K 이하: Input $0.003 / 1K tokens, Output $0.015 / 1K tokens
- 200K 초과: Input $0.006 / 1K tokens (2x), Output $0.0225 / 1K tokens (1.5x)
500K 토큰을 입력하면 (input 기준):
- 전체 일반 가격 적용 시: $1.50 (500K x $3/1M)
- 실제 가격: $2.40 (200K x $3 + 300K x $6)
약 60% 비용 증가가 발생합니다. 매일 수백 건의 요청을 처리하는 서비스라면 월 비용이 수천 달러 증가할 수 있습니다.
레이턴시 문제
1M 토큰 입력 시:
- Prefill 시간: 약 2분 (첫 토큰 생성까지)
- Caching 적용 시: 약 18초 (85% 감소)
Prompt Caching을 사용하면 레이턴시를 대폭 줄일 수 있지만, 캐시가 없는 첫 요청은 여전히 느립니다. 실시간 챗봇이나 대화형 애플리케이션에서는 사용자 경험에 치명적일 수 있습니다.
7. 실전 가이드: 언제 200K, 언제 1M?
실무에서 어떻게 판단해야 할까요?
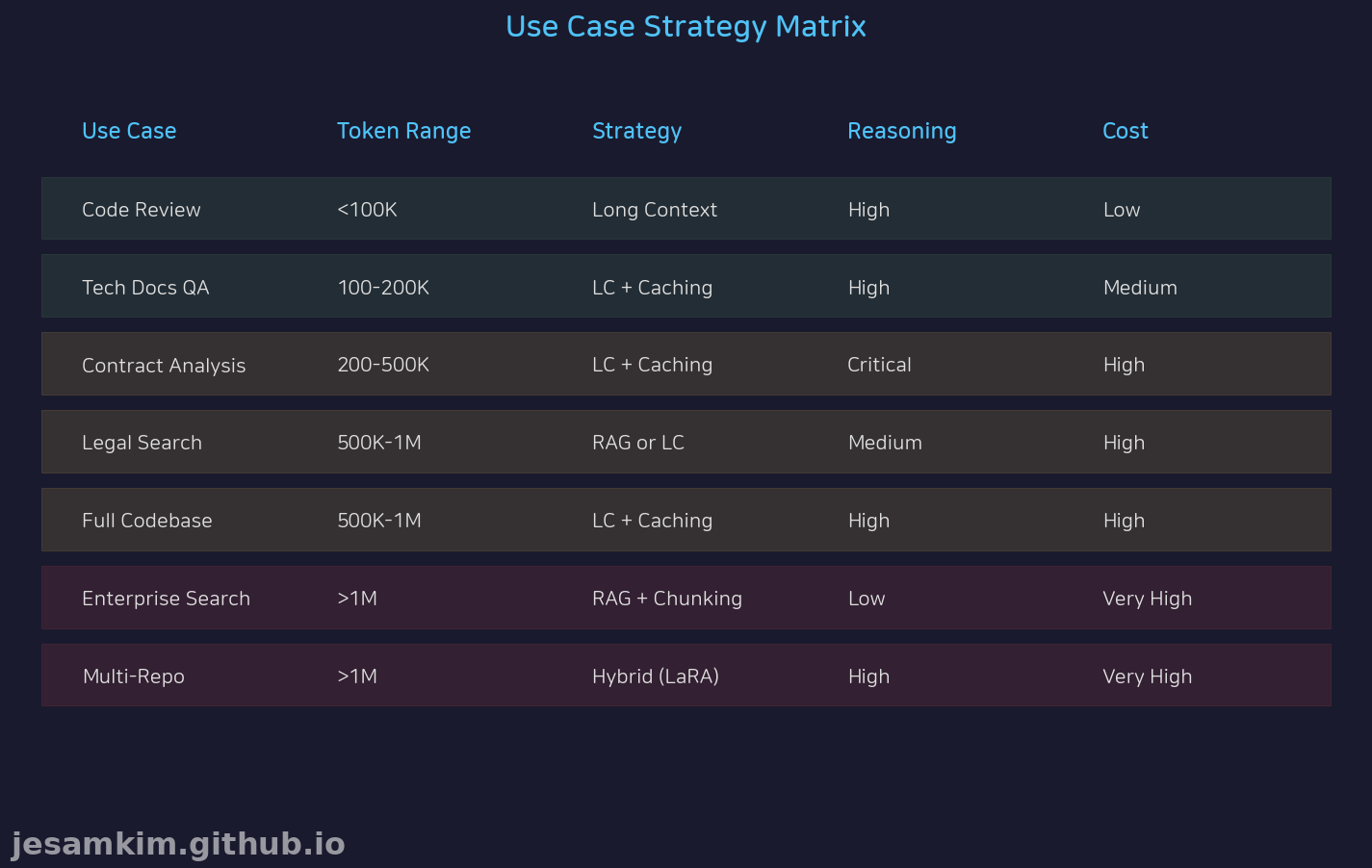
시나리오별 권장 전략
코드 리뷰 (100K 이하) 단일 Pull Request는 대부분 100K 이하입니다. 추론이 중요하므로 전체 맥락을 유지하기 위해 Long Context를 직접 사용하세요. Caching은 필요 없습니다.
기술 문서 QA (100-200K) API 문서 전체를 입력하면 맥락 기반 답변이 가능합니다. Long Context + Caching 조합을 사용하면 반복 질문 시 85% 레이턴시를 절감할 수 있습니다.
계약서 분석 (200-500K) 계약 조항 간 상호 참조가 많아 추론이 필요합니다. Long Context + Caching을 필수로 사용하세요. 2배 비용이 발생하지만 정확도를 우선해야 하는 영역입니다.
법률 판례 검색 (500K-1M) 단순 키워드 검색이라면 RAG가 비용 효율적입니다. 추론이 필요한 경우에만 Long Context를 적용하세요.
대규모 코드베이스 (500K-1M) 파일 간 의존성 추론이 필요하므로 Long Context + Caching(LaRA 패턴)을 사용합니다. 초기 비용은 높지만 장기적으로 효율적입니다.
기업 문서 검색 (1M 초과) 1M을 넘어가면 RAG + 청킹을 사용할 수밖에 없습니다. 벡터 DB로 분산 저장하세요.
멀티 리포지토리 분석 (1M 초과) RAG로 관련 파일만 추출한 후 Long Context로 추론하는 하이브리드 방식(U-NIAH 패턴)을 사용합니다. 청크 재정렬로 Lost in the Middle을 방지할 수 있습니다.
체크리스트
다음 질문에 답해보세요:
문서가 200K 미만인가? → Long Context 직접 사용
추론이 필요한가? → 필요하면 Long Context, 단순 검색이면 RAG
같은 문서에 반복 질문하나? → Prompt Caching 필수
실시간 응답이 중요한가? → 200K 이하로 제한하거나 RAG
비용이 민감한가? → 200K를 넘지 않도록 청킹 또는 RAG
마무리
1M 컨텍스트 윈도우가 가능해졌지만, “길면 다 좋다"는 생각은 위험합니다. Context Rot, Lost in the Middle, BABILong 연구들이 보여주듯이, 100K를 넘어서면 성능이 떨어지고 중간 정보를 놓치며 추론 능력이 50% 이하로 떨어집니다.
제가 추천하는 접근법은 간단합니다. 200K를 기준점으로 삼으세요. 200K 이하라면 Long Context를 직접 쓰고, 200K~1M이라면 추론 여부에 따라 선택하며, 1M을 넘어가면 RAG로 돌아가세요.
비용도 무시할 수 없습니다. 500K 토큰 하나에 $1.80이 들고, 매일 수백 건 처리하면 월 수천 달러가 됩니다. Prompt Caching을 쓰면 레이턴시를 85% 줄일 수 있지만, 첫 요청은 여전히 2분이 걸립니다.
긴 컨텍스트는 강력하지만, 모든 문제의 해답은 아닙니다. 상황에 맞게 선택하세요.
References
- Chroma Research (2025). “Context Rot: How Increasing Input Tokens Impacts LLM Performance.” https://research.trychroma.com/context-rot
- Liu, N. F., Lin, K., Hewitt, J., Paranjape, A., Bevilacqua, M., Petroni, F., & Liang, P. (2023). “Lost in the Middle: How Language Models Use Long Contexts.” arXiv:2307.03172. https://arxiv.org/abs/2307.03172
- Kuratov, Y., Bulatov, A., Anokhin, P., Rodkin, D., Sorokin, D., Sorokin, A., & Burtsev, M. (2024). “BABILong: Testing the Limits of LLMs with Long Context Reasoning-in-a-Haystack.” NeurIPS 2024. https://arxiv.org/abs/2406.10149
- Li, K., Zhang, L., Jiang, Y., Xie, P., & Huang, F. (2025). “LaRA: Benchmarking Retrieval-Augmented Generation and Long-Context LLMs – No Silver Bullet for LC or RAG Routing.” arXiv:2502.09977. https://arxiv.org/abs/2502.09977
- Gao, Y., Xiong, Y., Wu, W., Huang, Z., & Li, B. (2025). “U-NIAH: Unified RAG and LLM Evaluation for Long Context Needle-In-A-Haystack.” arXiv:2503.00353. https://arxiv.org/abs/2503.00353
- Anthropic (2026). “Claude Sonnet 4.6 Model Card.” https://docs.anthropic.com/en/docs/about-claude/models
- Amazon Web Services (2026). “Amazon Bedrock Pricing.” https://aws.amazon.com/bedrock/pricing/