1. 추천 시스템, 무엇이 부족한가
추천 시스템(Recommendation System)은 디지털 서비스의 핵심 인프라입니다. Netflix의 콘텐츠 추천, Amazon의 상품 추천, YouTube의 영상 추천까지, 사용자 경험의 상당 부분을 추천 알고리즘이 결정합니다.
이 중 가장 널리 사용되는 방식이 협업 필터링(Collaborative Filtering, CF)입니다. “나와 비슷한 행동을 보인 사용자가 좋아한 아이템을 추천한다"는 단순하지만 강력한 원리입니다. 수십 년간 검증된 이 접근법은 여전히 대규모 프로덕션 시스템의 근간이며, 필자가 이전에 다룬 Amazon Personalize 하이브리드 추천 아키텍처도 이 패러다임 위에 설계된 것입니다.
그러나 CF에는 구조적 한계가 존재합니다.
콜드스타트 문제(Cold-Start Problem)는 가장 근본적인 약점입니다. 신규 사용자에 대한 행동 데이터가 없으면, 시스템은 문자 그대로 “추천할 근거"가 없습니다. 신규 아이템도 마찬가지입니다. 아무도 클릭하지 않은 상품은 추천 후보에서 사실상 배제됩니다.
데이터 의존성도 문제입니다. CF가 제대로 작동하려면 사용자-아이템 간 충분한 인터랙션(클릭, 구매, 평점) 데이터가 필요합니다. 데이터가 희소한(sparse) 도메인에서는 성능이 급격히 저하됩니다.
가장 근본적인 문제는 플랫폼 중심 최적화입니다. Zhang et al.(2026)은 이 점을 정면으로 지적합니다. 현재 추천 시스템은 사용자의 진짜 필요가 아닌, 플랫폼의 engagement와 conversion 지표에 최적화되어 있습니다.
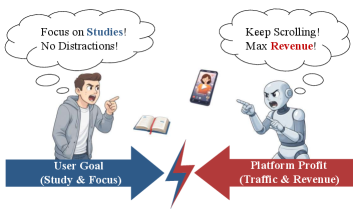 사용자는 집중해서 공부하고 싶지만, 플랫폼은 스크롤을 유도해 광고 수익을 극대화합니다. 출처: Zhang et al. (2026), Figure 1
사용자는 집중해서 공부하고 싶지만, 플랫폼은 스크롤을 유도해 광고 수익을 극대화합니다. 출처: Zhang et al. (2026), Figure 1
사용자가 공부에 집중하고 싶어도 플랫폼은 끊임없이 영상을 추천해 체류 시간을 늘리려 합니다. 이 구조적 이해충돌이 CF 기반 추천의 본질적 한계입니다.
2. LLM이 추천을 바꾸는 방식 - 2026년 최신 연구
2026년 들어 추천 시스템 분야에서 LLM을 활용한 연구가 폭발적으로 증가하고 있습니다. 특히 주목할 만한 연구 5편을 살펴보겠습니다.
2.1 플랫폼에서 사용자로: User-Centric Agent
Zhang et al.(2026)의 “The Next Paradigm Is User-Centric Agent"는 추천 시스템의 근본적 구조 전환을 제안합니다. 핵심 주장은 명확합니다. 추천의 주체를 플랫폼에서 사용자의 에이전트로 옮겨야 한다는 것입니다.
이 논문이 제시하는 User-Centric Agent의 세 가지 원칙은 다음과 같습니다.
- Privacy-by-Design: 민감한 개인 정보는 사용자 측에 보관하고, 플랫폼에는 최소한만 공유합니다.
- Goal Alignment: 에이전트의 의사결정은 플랫폼 지표가 아닌 사용자가 정의한 목표에 따릅니다.
- User Agency: 사용자가 자신의 선호와 제약을 직접 제어하고 재정의할 수 있습니다.
LLM의 의도 추론(intent reasoning) 능력과 온디바이스 AI의 발전으로 이 비전이 현실화 가능해졌다고 논문은 주장합니다.
2.2 인터랙션 없이 아이템 이해하기: AgenticTagger
Google DeepMind의 Xie et al.(2026)은 AgenticTagger를 통해 LLM이 아이템 표현(item representation)을 자동으로 생성하는 프레임워크를 제안합니다.
 전통적 아이템 표현(ID 기반)과 AgenticTagger의 시맨틱 표현 비교. LLM이 아이템 설명에서 해석 가능한 태그를 자동 생성합니다. 출처: Xie et al. (2026), Figure 1
전통적 아이템 표현(ID 기반)과 AgenticTagger의 시맨틱 표현 비교. LLM이 아이템 설명에서 해석 가능한 태그를 자동 생성합니다. 출처: Xie et al. (2026), Figure 1
핵심은 multi-agent reflection mechanism입니다. Architect LLM이 태그 체계(vocabulary)를 설계하고, 병렬화된 Annotator LLM들이 실제 아이템 데이터에 대해 검증하며 반복적으로 개선합니다. 이 과정에서 사용자 인터랙션 데이터는 필요하지 않습니다. 아이템의 메타데이터와 설명만으로 고품질 표현을 생성할 수 있습니다.
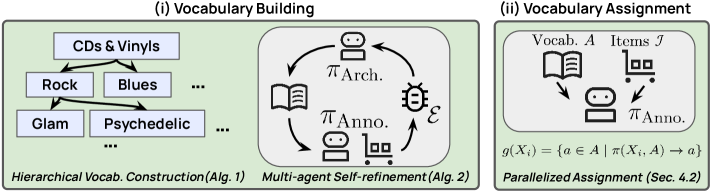 AgenticTagger의 전체 프레임워크. Vocabulary Building → Assignment → 다양한 다운스트림 활용(retrieval, ranking, critique-based recommendation). 출처: Xie et al. (2026), Figure 2
AgenticTagger의 전체 프레임워크. Vocabulary Building → Assignment → 다양한 다운스트림 활용(retrieval, ranking, critique-based recommendation). 출처: Xie et al. (2026), Figure 2
이것이 시사하는 바는 큽니다. 신규 아이템이 등록되는 순간, LLM이 설명문만으로 풍부한 시맨틱 태그를 생성할 수 있으므로 콜드스타트 문제가 근본적으로 완화됩니다.
2.3 추론하며 추천하기: R2Rank
Tencent의 Zheng et al.(2026)은 R2Rank(Reasoning to Rank)를 통해 LLM에 강화학습(RL)을 결합한 end-to-end 추천 프레임워크를 제안합니다.
전통적 추천이 통계적 패턴 매칭에 의존한다면, R2Rank는 LLM의 단계별 추론(step-by-step reasoning)을 활용합니다. 사용자의 과거 행동에서 단서를 추출하고, 논리적으로 다음 선호를 추론하는 방식입니다. 특히 cold-start regime에서 가장 큰 성능 향상을 보여, 인터랙션 데이터가 부족한 상황에서 LLM reasoning의 가치를 입증했습니다.
2.4 행동 로그를 언어로: Netflix의 접근
Netflix의 Shi et al.(2026)은 “From Logs to Language"라는 매우 실용적인 문제를 다룹니다. 사용자의 행동 로그(시청 기록, 클릭, 체류 시간)를 LLM이 이해할 수 있는 자연어로 어떻게 변환할 것인가?
이들은 강화학습으로 학습된 Verbalization Agent를 제안합니다. 이 에이전트는 원시 로그에서 노이즈를 제거하고, 관련 메타데이터를 추가하며, 정보를 재구조화해서 LLM이 더 잘 이해할 수 있는 형태로 변환합니다. 실험 결과, 템플릿 기반 대비 최대 93% 상대 정확도 향상을 달성했습니다.
이 연구는 기존 CF 시스템의 데이터를 LLM에 효과적으로 전달하는 “다리(bridge)” 역할을 합니다. CF를 대체하는 것이 아니라 CF의 신호를 LLM이 활용할 수 있게 하는 접근입니다.
2.5 설명과 추천의 공동 최적화
Wang et al.(2026)은 추천 정확도와 설명 품질을 동시에 최적화하는 프레임워크를 제안합니다. “왜 이 아이템을 추천하는가?“에 대한 자연어 설명이 다시 추천 모델에 피드백되어 정확도를 높이는 선순환 구조입니다. Google Maps 데이터에서 SOTA 대비 3-4% 정확도 향상을 달성하면서, 학습 데이터의 12%만으로 동등한 성능을 보여줬습니다. 이는 데이터 효율성 측면에서 LLM의 가치를 보여주는 결과입니다.
3. 그래도 Collaborative Filtering이 필요한 이유
앞선 논문들의 결과는 인상적이지만, LLM이 CF를 완전히 대체할 수 있다고 결론짓기엔 이릅니다.
규모의 문제가 있습니다. Netflix는 수억 명의 사용자가 남긴 수십억 건의 시청 기록을 보유합니다. 이런 대규모 implicit feedback 패턴에서 “목요일 저녁에 로맨스 영화를 보는 사용자는 금요일에 코미디를 본다” 같은 미묘한 패턴을 학습하는 것은 CF의 강점이며, LLM이 프롬프트만으로 이런 통계적 규칙성을 재현하기는 어렵습니다.
레이턴시와 비용은 현실적인 장벽입니다. 이커머스 추천은 수천만 개 아이템 중 밀리초 단위로 후보를 선별해야 합니다. LLM inference는 이에 비해 수백 배 느리고 비쌉니다. RecSys After LLMs(Verma, 2026)에서도 지적한 것처럼, “LLM이 수십억 파라미터로 인코딩하는 패턴을 전통 RecSys 모델은 훨씬 저렴하게 처리할 수 있습니다.”
Hallucination 문제도 있습니다. LLM은 카탈로그에 없는 아이템을 추천하거나, 존재하지 않는 속성을 만들어낼 수 있습니다. 실제 이커머스에서 없는 상품을 추천하면 사용자 경험이 크게 훼손됩니다.
검증된 파이프라인의 가치도 무시할 수 없습니다. A/B 테스트, 실시간 피드백 루프, MAB(Multi-Armed Bandit) 기반 탐색/활용 밸런싱 등 수십 년간 축적된 RecSys 엔지니어링은 하루아침에 LLM으로 대체되지 않습니다.
4. 유저 라이프사이클별 역할 분담
그렇다면 LLM과 CF는 어떻게 공존해야 할까요? 답은 사용자의 라이프사이클에 있습니다.
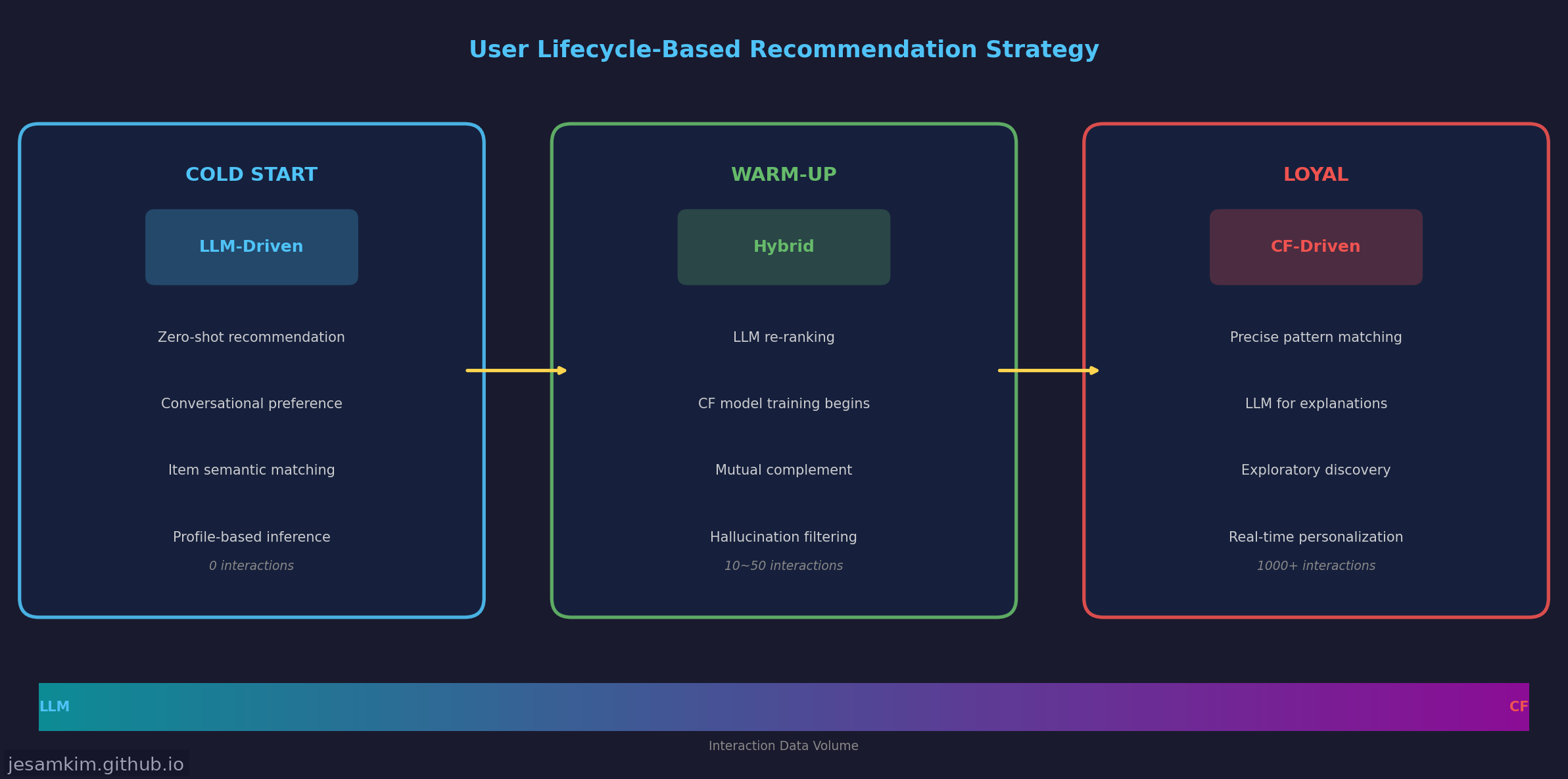
4.1 콜드스타트 구간: LLM이 주도합니다
신규 사용자가 서비스에 처음 접속했을 때, 인터랙션 데이터는 전무합니다. 이때 LLM은 세 가지 방식으로 추천을 수행할 수 있습니다.
첫째, 아이템 시맨틱 매칭입니다. AgenticTagger처럼 아이템의 텍스트 설명에서 풍부한 시맨틱 표현을 생성하고, 사용자가 입력한 검색어나 선호 설명과 매칭합니다.
둘째, 대화형 선호 파악입니다. “어떤 장르를 좋아하세요?”, “최근에 재밌게 본 영화가 있나요?” 같은 자연어 대화를 통해 선호를 파악하고, zero-shot으로 추천합니다.
셋째, 프로필 기반 추론입니다. 연령대, 가입 경로 같은 최소한의 프로필 정보에서 LLM의 world knowledge로 초기 선호를 추론합니다.
4.2 웜업 구간: 하이브리드가 최적입니다
사용자가 10~50건의 인터랙션을 축적하면, 두 시스템을 병행 운영합니다. CF 모델이 학습을 시작하되, 아직 데이터가 부족하므로 LLM이 보조합니다. LLM의 re-ranking이 CF의 부족한 부분을 보완하고, CF가 LLM의 hallucination을 필터링하는 상호 보완 구조입니다.
4.3 충성 고객 구간: CF가 주도합니다
수백~수천 건의 인터랙션이 축적된 충성 고객에게는 CF의 정밀한 패턴 매칭이 LLM보다 효과적입니다. 이 구간에서 LLM은 보조 역할을 합니다. “이 상품을 추천하는 이유"를 자연어로 설명하거나, “오늘은 평소와 다른 걸 추천해 줘” 같은 탐색적 요청에 대응합니다.
5. AWS 하이브리드 추천 아키텍처
이론을 실제 AWS 서비스로 구현하면 다음과 같은 아키텍처가 됩니다.
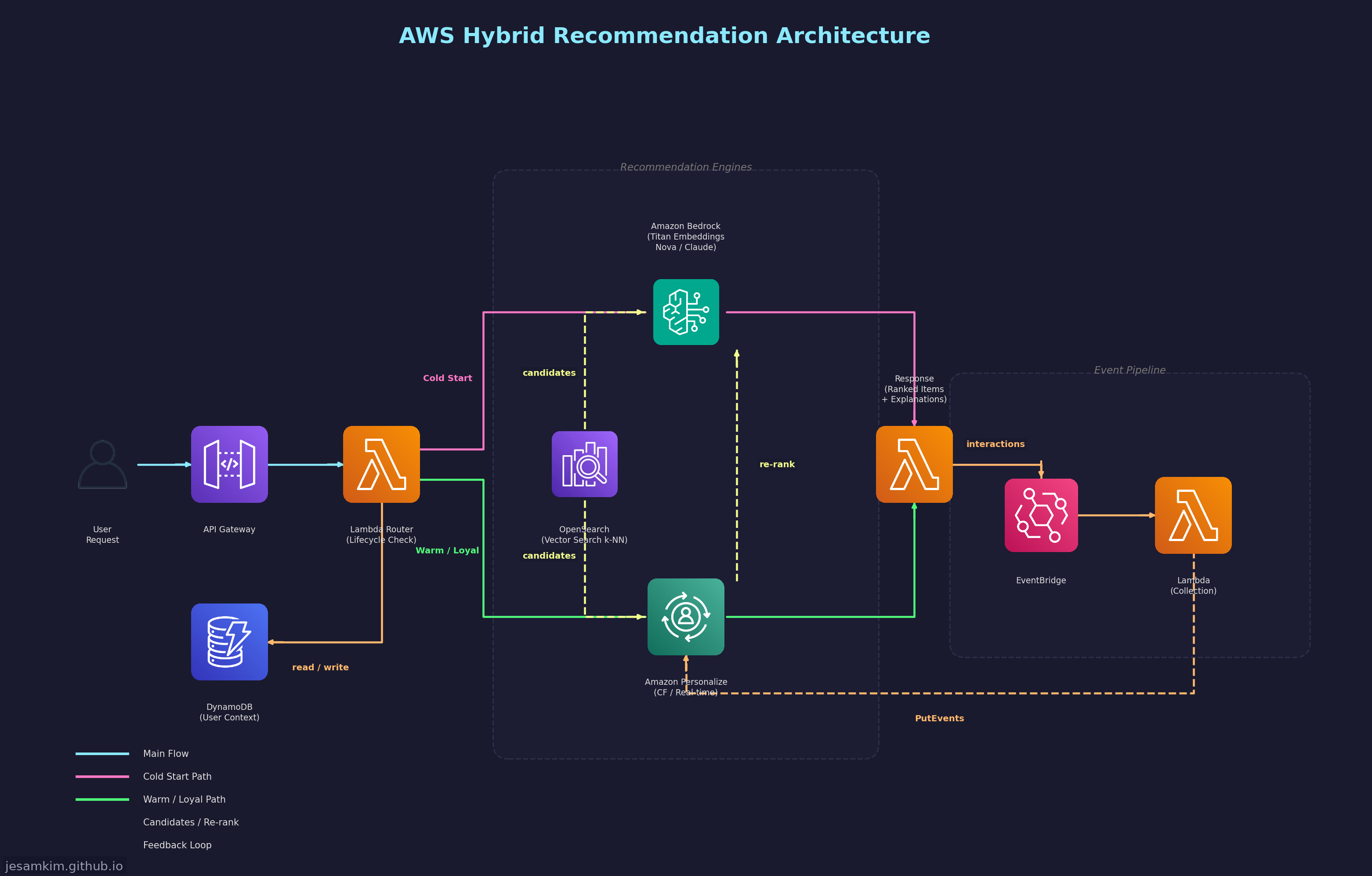
5.1 핵심 서비스 구성
Amazon Bedrock은 세 가지 역할을 수행합니다.
첫째, 아이템 표현 생성입니다. Titan Embeddings 모델로 상품 설명과 리뷰에서 시맨틱 벡터를 생성하여 OpenSearch에 인덱싱하고, Nova/Claude 같은 생성 모델로 아이템의 구조화된 태그와 메타데이터를 추출합니다. 둘째, 사용자 의도 파악입니다. 검색어나 대화에서 사용자의 진짜 의도를 추론합니다. “가벼운 노트북"이라는 검색어에서 “휴대성 우선, 1.5kg 이하” 같은 구조화된 필터를 추출합니다. 셋째, Re-ranking과 설명 생성입니다. CF/검색이 반환한 후보군을 사용자 컨텍스트에 맞게 재정렬하고, 추천 이유를 자연어로 생성합니다.
이전에 다룬 Amazon Bedrock의 비정형 문서 파싱이나 Agent SDK 활용의 패턴을 추천 도메인에 그대로 적용할 수 있습니다.
Amazon Personalize는 행동 기반 추천의 핵심 엔진입니다. User Personalization, Similar Items, Personalized Ranking 세 가지 레시피를 상황에 따라 활용합니다. 실시간 이벤트 수집(PutEvents API)으로 사용자 행동을 즉시 반영하며, 별도의 ML 인프라 없이 관리형 서비스로 운영할 수 있습니다.
Amazon OpenSearch Service는 후보 retrieval 계층입니다. k-NN 벡터 검색으로 시맨틱 유사도 기반 후보군을 빠르게 추출하고, 키워드 검색과 벡터 검색을 결합한 하이브리드 검색으로 정밀도와 재현율을 동시에 확보합니다.
5.2 데이터 흐름
전체 파이프라인의 데이터 흐름은 다음과 같습니다.
- 사용자 요청 수신 (API Gateway)
- 사용자 컨텍스트 조회 (DynamoDB - 최근 행동, 세션 정보)
- 라이프사이클 판단 (인터랙션 수 기반)
- 콜드스타트: Bedrock으로 의도 파악 → OpenSearch 벡터 검색 → Bedrock re-ranking
- 웜업: Personalize 추천 + OpenSearch 검색 → Bedrock re-ranking + 설명 생성
- 충성고객: Personalize 추천 (주도) + Bedrock 설명 생성 (보조)
- 인터랙션 이벤트 수집 (EventBridge → Lambda → Personalize PutEvents)
5.3 Bedrock Re-ranking 프롬프트 예시
당신은 이커머스 추천 전문가입니다.
사용자 프로필과 추천 후보를 분석하여 최적의 순서로 재배열하세요.
[사용자 컨텍스트]
- 최근 구매: 캠핑 텐트, 침낭
- 검색어: "가벼운 등산화"
- 계절: 봄
[추천 후보 (Personalize 결과)]
1. 트레킹화 A - 320g, 고어텍스, 89,000원
2. 등산 배낭 B - 35L, 1.2kg, 125,000원
3. 경량 등산화 C - 280g, 메쉬, 69,000원
4. 캠핑 의자 D - 접이식, 1.5kg, 45,000원
재배열 기준:
- 검색 의도와의 관련성
- 이전 구매와의 보완성
- 계절 적합성
JSON 형식으로 순위와 추천 이유를 반환하세요.
6. 실전 적용 가이드
6.1 어디서부터 시작할 것인가
이미 Personalize를 운영 중이라면, 기존 파이프라인에 Bedrock re-ranking 단계를 추가하는 것이 가장 효율적인 시작점입니다. Personalize가 생성한 Top-50 후보를 Bedrock이 사용자 컨텍스트에 맞게 Top-10으로 재정렬하는 방식입니다.
새로 시작한다면, OpenSearch 벡터 검색 + Bedrock으로 시맨틱 추천 시스템을 먼저 구축하고, 인터랙션 데이터가 축적되면 Personalize를 추가하는 접근을 권합니다.
6.2 비용 최적화
LLM 호출은 CF 대비 비용이 높으므로, 호출 시점을 전략적으로 결정해야 합니다.
| 상황 | 추천 방식 | 비용 |
|---|---|---|
| 콜드스타트 (필수) | Bedrock | 높음 |
| 홈 피드 (대량) | Personalize | 낮음 |
| 상세 페이지 (설명) | Bedrock | 중간 |
| 검색 결과 | OpenSearch | 낮음 |
Nova 모델군을 활용하면 Claude 대비 비용을 대폭 절감할 수 있으며, 캐싱 전략(동일 아이템 설명 재사용)으로 추가 최적화가 가능합니다.
6.3 향후 전망: Agentic Recommender
Transformer의 확률적 생성 원리에서 살펴본 것처럼, LLM의 생성 과정 자체가 확률적 탐색입니다. 이 특성이 추천의 “탐색(exploration)“과 자연스럽게 맞닿아 있습니다.
Zhang et al.(2026)이 제시한 User-Centric Agent 비전, 그리고 Verma(2026)가 정리한 “Agentic Recommender” 패러다임이 실현되면, 추천 시스템은 단순한 랭킹 엔진을 넘어 사용자를 대신해 여러 플랫폼을 탐색하고, 비교하고, 최적의 선택을 제안하는 자율적 에이전트로 진화할 것입니다.
AWS 아키텍처 관점에서는 Bedrock Agent + Personalize + OpenSearch의 조합이 이 미래를 구현하는 가장 현실적인 경로입니다. 중요한 것은 LLM이 CF를 “대체"하는 것이 아니라, 사용자 라이프사이클의 각 단계에서 최적의 도구를 선택하는 오케스트레이션입니다.
References
Zhang, L., Lv, H., Pan, Q., et al. (2026). The Next Paradigm Is User-Centric Agent, Not Platform-Centric Service. arXiv:2602.15682. https://arxiv.org/abs/2602.15682
Xie, Z., Peng, B., He, Z., et al. (2026). AgenticTagger: Structured Item Representation for Recommendation with LLM Agents. arXiv:2602.05945. https://arxiv.org/abs/2602.05945
Zheng, K., Hong, D., Li, Q., et al. (2026). Reasoning to Rank: An End-to-End Solution for Exploiting Large Language Models for Recommendation. arXiv:2602.12530. https://arxiv.org/abs/2602.12530
Shi, Y., Li, Y., Wang, Y., et al. (2026). From Logs to Language: Learning Optimal Verbalization for LLM-Based Recommendation in Production. arXiv:2602.20558. https://arxiv.org/abs/2602.20558
Wang, Y., Li, P., Chen, M., et al. (2026). Can Explanations Improve Recommendations? A Joint Optimization with LLM Reasoning. arXiv:2502.16759. https://arxiv.org/abs/2502.16759
Sah, C.K., Lian, X., Zhang, L., et al. (2026). Uncertainty and Fairness Awareness in LLM-Based Recommendation Systems. arXiv:2602.02582. https://arxiv.org/abs/2602.02582
Verma, J. (2026). RecSys After LLMs: Four Paradigms for What Comes Next. https://januverma.substack.com/p/recsys-after-llms-four-paradigms
AWS. Amazon Personalize Developer Guide. https://docs.aws.amazon.com/personalize/latest/dg/what-is-personalize.html
AWS. Amazon Bedrock User Guide. https://docs.aws.amazon.com/bedrock/latest/userguide/what-is-bedrock.html