들어가며 - LLM은 아는 것을 말하는 게 아니라 확률적으로 생성한다
ChatGPT나 Claude에 같은 질문을 두 번 던져 보신 적 있으신가요? 분명 동일한 프롬프트인데, 돌아오는 답변의 문장 구조나 단어 선택이 미묘하게 달라집니다. 처음에는 버그처럼 느껴질 수 있지만, 이것은 LLM의 근본적인 작동 원리에서 비롯된 의도된 설계입니다.
LLM은 질문에 대한 정답을 데이터베이스에서 꺼내오는 시스템이 아닙니다. 주어진 문맥을 바탕으로 다음에 올 토큰의 확률 분포를 계산하고, 그 분포에서 하나를 샘플링하는 과정을 반복합니다. 면이 수만 개인 주사위를 매 토큰마다 새로 깎아서 굴리는 셈입니다.
이 관점의 전환이 실무에서 꽤 중요합니다. “왜 매번 답이 다르지?“라는 의문이 “어떻게 하면 이 확률 분포를 원하는 방향으로 조건화할 수 있을까?“로 바뀌는 순간, 프롬프트 엔지니어링과 파라미터 튜닝에 대한 이해가 근본적으로 달라지기 때문입니다.
이번 글에서는 Transformer 아키텍처가 이 확률 분포를 어떻게 계산하는지, 그리고 샘플링 전략이 출력의 다양성을 어떻게 결정하는지 살펴보겠습니다.
Transformer 핵심 구조 리뷰
확률적 생성 과정을 이해하려면, 입력 텍스트가 어떤 경로를 거쳐 다음 토큰 예측에 도달하는지 먼저 짚어야 합니다.
토큰화와 임베딩
사용자가 입력한 텍스트는 먼저 토크나이저(Tokenizer)에 의해 서브워드 단위로 쪼개집니다. “확률적"이라는 단어가 하나의 토큰이 될 수도, “확률” + “적"으로 나뉠 수도 있습니다. 각 토큰은 고차원 벡터로 변환(임베딩)되어 모델에 입력됩니다. 이 임베딩 벡터에는 Positional Encoding이 더해져, 토큰의 의미뿐 아니라 시퀀스 내 위치 정보까지 함께 인코딩됩니다. Transformer가 RNN과 달리 시퀀스를 병렬로 처리하기 때문에, 위치 정보를 별도로 주입해야 하는 것입니다.
Self-Attention - 문맥을 파악하는 장치
Transformer의 핵심은 Self-Attention 메커니즘입니다. 시퀀스 내 각 토큰이 다른 모든 토큰과의 관련도를 계산하여, 문맥에 따라 자신의 표현을 동적으로 조정합니다. Scaled Dot-Product Attention 수식은 다음과 같습니다.
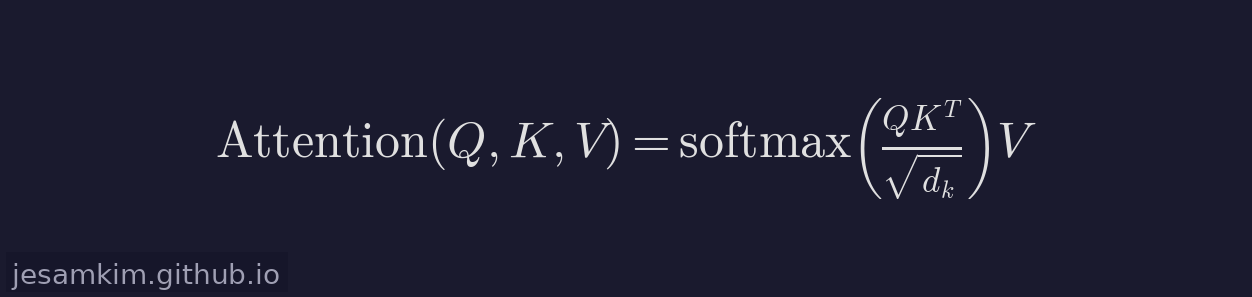
Q(Query), K(Key), V(Value)는 입력 임베딩에서 선형 변환을 통해 만들어집니다. sqrt(d_k)로 나누는 이유는 차원이 커질수록 내적 값이 지나치게 커져 softmax의 그래디언트가 소실되는 것을 방지하기 위함입니다.
실제 Transformer에서는 이 Attention을 하나만 쓰지 않습니다. 여러 개의 헤드(head)로 병렬 수행하는 Multi-Head Attention을 사용합니다. 한 헤드는 문법적 의존 관계(주어-동사 일치)를, 다른 헤드는 의미적 유사성(동의어, 문맥상 관련 단어)을 각각 포착하고, 그 결과를 concat 후 선형 변환으로 합칩니다.
Feed-Forward Network
Attention 출력은 토큰별로 독립적인 Feed-Forward Network(FFN)을 통과합니다. FFN은 Attention이 포착한 문맥 정보를 비선형 변환하여, 더 추상적인 표현으로 가공합니다. 최근 연구에서는 FFN이 사실상 거대한 키-값 메모리처럼 동작하며, 학습 데이터에서 추출한 지식 패턴을 저장하는 역할을 한다는 해석도 있습니다.
이 Attention + FFN 블록이 수십에서 수백 레이어로 쌓여 최종 출력 표현을 만들어냅니다. GPT-4 규모의 모델이라면 이 블록이 수십 겹 반복되며, 초기 레이어에서는 구문적 패턴을, 후기 레이어에서는 의미적 추론을 주로 처리하는 것으로 알려져 있습니다.
Next Token Prediction의 본질
LLM이 텍스트를 생성하는 방식은 의외로 단순합니다. 전체 시퀀스의 확률을 조건부 확률의 곱으로 분해하는 것입니다.
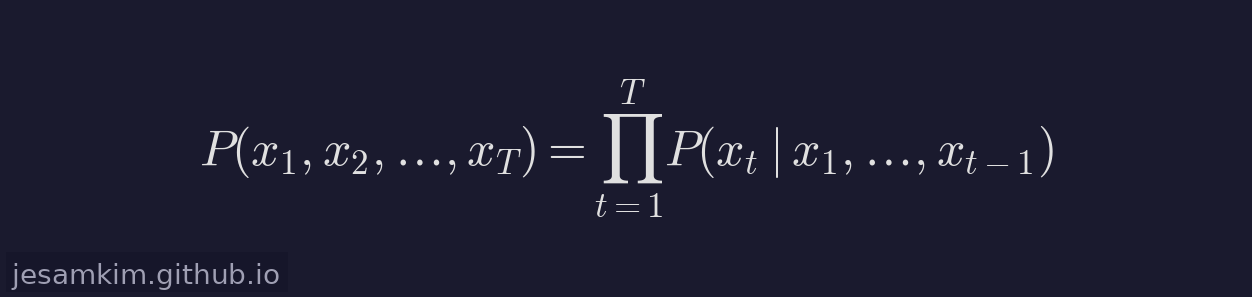
모델은 한 번에 문장 전체를 만들어내지 않습니다. 매 스텝마다 “다음 토큰 하나"의 확률 분포를 계산하고, 거기서 하나를 골라낸 뒤, 그 결과를 다시 입력에 붙여 다음 스텝을 진행합니다. 종료 토큰(End-of-Sequence)이 나올 때까지 이 과정이 반복됩니다.
Logit에서 확률 분포로
Transformer 마지막 레이어를 통과한 은닉 상태(hidden state)는 선형 변환을 거쳐 어휘 크기만큼의 logit 벡터로 변환됩니다. 여기에 softmax를 적용하면 전체 어휘에 대한 확률 분포가 됩니다.
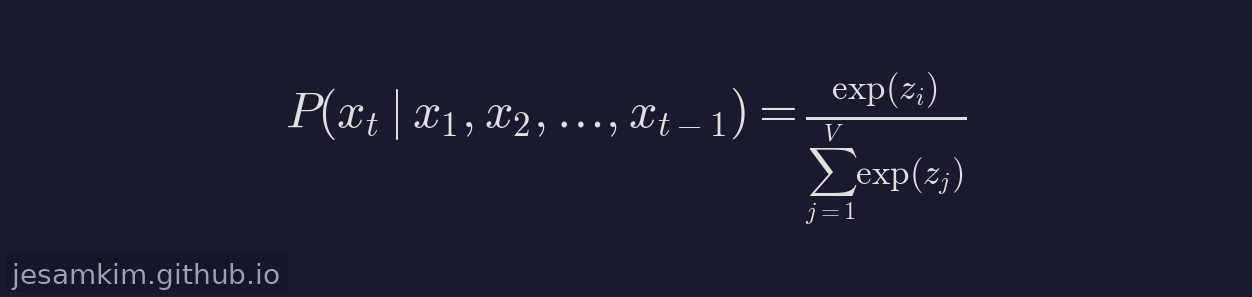
z_i는 시점 t에서 토큰 i의 logit, V는 전체 어휘 크기입니다. 어휘가 수만에서 십만 개에 달하므로, 이 분포는 매우 고차원적입니다.
import torch
import torch.nn.functional as F
# 모델이 출력한 logit 벡터 (간소화 예시)
logits = torch.tensor([2.0, 1.0, 0.5, -1.0, 0.1])
# Softmax로 확률 분포 변환
probs = F.softmax(logits, dim=-1)
# tensor([0.4466, 0.1642, 0.0996, 0.0222, 0.0668])
# 이 분포에서 토큰 하나를 샘플링
next_token = torch.multinomial(probs, num_samples=1)
가장 높은 확률이 정답이 아닌 이유
“오늘 날씨가"라는 프롬프트에서 “좋다"가 0.25, “맑다"가 0.22, “흐리다"가 0.15의 확률을 갖는다면, 셋 모두 자연스러운 후속 토큰입니다. 특히 자연어는 같은 의미를 표현하는 방법이 여러 가지이므로, 상위 토큰들 사이의 확률 차이가 크지 않은 경우가 빈번합니다.
항상 최고 확률만 선택하면 판에 박힌 문장만 생성되고, 사람이 실제로 쓰는 것과 같은 표현의 다양성이 사라집니다. 이 문제를 해결하는 것이 바로 샘플링 전략입니다.
4. 샘플링 전략과 출력의 다양성
이전 섹션에서 Softmax가 만들어낸 확률분포 위에서 토큰을 “뽑는다"는 사실을 확인했습니다. 그런데 이 뽑기 과정을 어떻게 설계하느냐에 따라 출력의 성격이 극적으로 달라집니다. 대표적인 샘플링 전략 네 가지를 살펴보겠습니다.
Greedy Decoding: 가장 단순한 선택
가장 직관적인 방법은 매 스텝에서 확률이 가장 높은 토큰을 무조건 선택하는 것입니다.
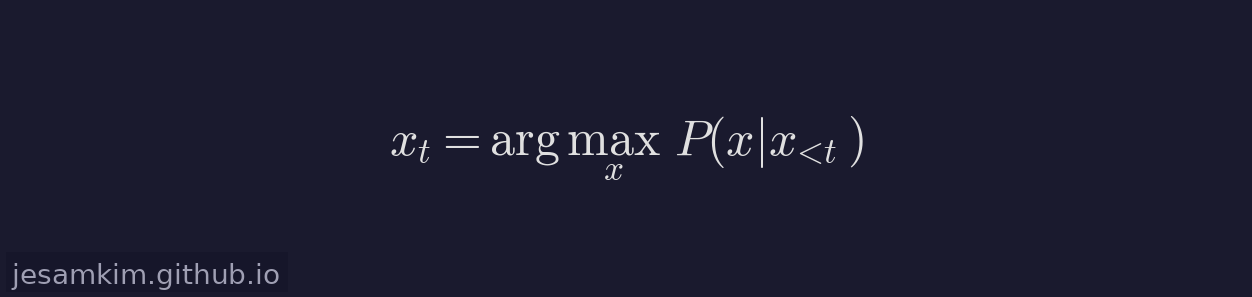
이 방식을 Greedy Decoding이라 합니다. 완전히 결정적(deterministic)이므로 동일한 입력에 대해 항상 동일한 출력이 나옵니다. 그러나 실제로 사용해 보면, 같은 표현이 반복되거나 안전하고 무난한 토큰만 계속 선택되면서 텍스트가 단조로워지는 현상(degeneration)이 빈번하게 발생합니다. 확률 2위인 토큰이 1위와 거의 차이가 없는 상황에서도 Greedy는 항상 1위만 고집하기 때문입니다.
Temperature Scaling: 분포의 날카로움을 조절하는 다이얼
Temperature는 Softmax에 들어가기 전 로짓을 스케일링하는 하이퍼파라미터 T입니다.
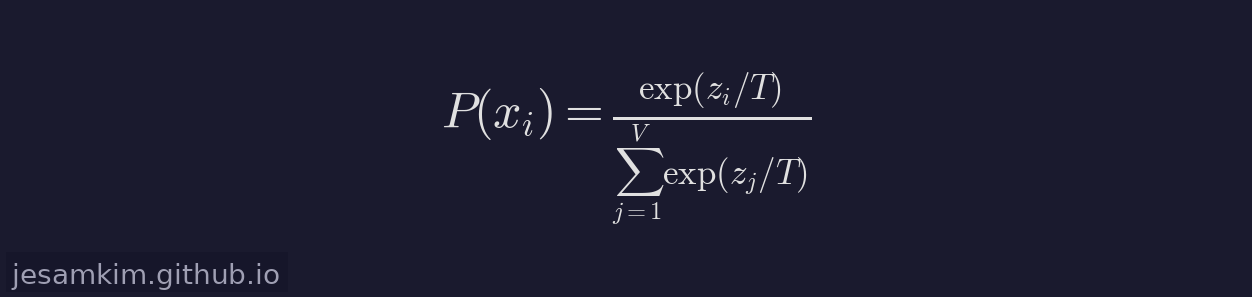
T의 값에 따른 직관은 다음과 같습니다.
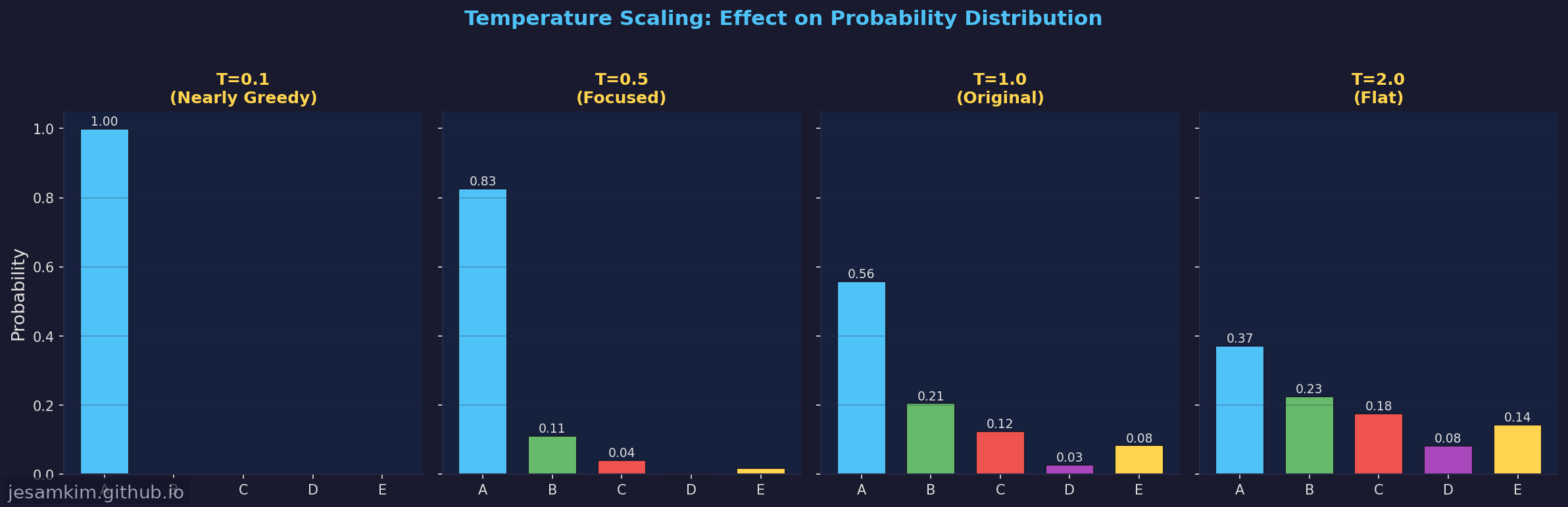
- T → 0: 분포가 극도로 날카로워집니다. 가장 높은 로짓을 가진 토큰의 확률이 1에 수렴하므로, 사실상 Greedy Decoding과 동일해집니다.
- T = 1: 모델이 학습 시 사용한 원래 분포 그대로입니다.
- T > 1: 분포가 평평(flat)해집니다. 낮은 확률의 토큰들도 선택될 가능성이 높아져 출력이 다양해지지만, 너무 높이면 일관성 없는 텍스트가 생성됩니다.
비유하자면, Temperature는 주사위의 형태를 바꾸는 다이얼입니다. T를 낮추면 한 면이 압도적으로 큰 찌그러진 주사위가 되고, T를 높이면 모든 면이 비슷한 정육면체에 가까워집니다.
import torch
import torch.nn.functional as F
logits = torch.tensor([2.0, 1.0, 0.5, -1.0, 0.1])
# Temperature에 따른 확률분포 변화
for T in [0.1, 0.5, 1.0, 2.0]:
probs = F.softmax(logits / T, dim=-1)
print(f"T={T:<3} → {probs.numpy().round(4)}")
# T=0.1 → [1. 0. 0. 0. 0. ] ← 거의 Greedy
# T=0.5 → [0.8360 0.1131 0.0416 0.0010 0.0083]
# T=1.0 → [0.4466 0.1642 0.0996 0.0222 0.0668] ← 원래 분포
# T=2.0 → [0.2966 0.1802 0.1398 0.0662 0.1147] ← 평평한 분포
Top-k Sampling: 상위 후보만 남기기
Top-k Sampling은 확률이 높은 상위 k개의 토큰만 후보로 남기고, 나머지 토큰의 확률을 0으로 설정한 뒤 재정규화(renormalization)하는 방식입니다.
def top_k_sampling(logits, k=10):
top_k_values, top_k_indices = torch.topk(logits, k)
# 상위 k개 외의 토큰은 -inf로 마스킹
filtered_logits = torch.full_like(logits, float('-inf'))
filtered_logits.scatter_(0, top_k_indices, top_k_values)
probs = F.softmax(filtered_logits, dim=-1)
return torch.multinomial(probs, num_samples=1)
이 방식의 장점은 꼬리(tail) 부분의 비합리적인 토큰이 선택되는 것을 원천 차단한다는 점입니다. 그러나 고정된 k 값이 모든 상황에 적합하지는 않습니다. 어떤 스텝에서는 후보가 3개면 충분한데 k=50이 적용되어 불필요한 잡음이 포함될 수 있고, 반대로 후보가 100개쯤 필요한 스텝에서 k=50이 유망한 토큰을 잘라낼 수도 있습니다.
Top-p (Nucleus) Sampling: 누적확률 기반의 적응적 필터링
Top-p Sampling은 Top-k의 한계를 해결하기 위해 고안된 방식입니다. 고정된 개수 대신, 확률을 내림차순으로 정렬한 뒤 누적합이 p에 도달할 때까지의 토큰만 후보로 남깁니다.
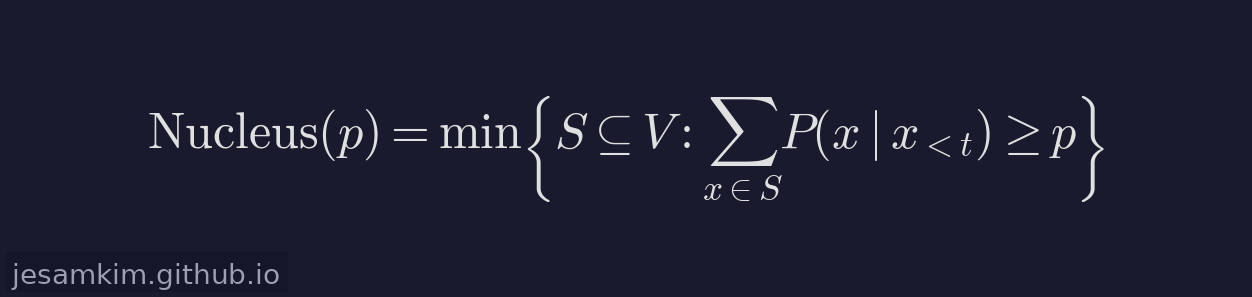
p=0.9로 설정하면, 누적확률의 상위 90%를 차지하는 토큰들만 후보가 됩니다. 분포가 뾰족한 스텝에서는 후보가 자연스럽게 줄어들고, 분포가 평평한 스텝에서는 후보가 자동으로 늘어나는 적응적(adaptive) 특성이 핵심 강점입니다.
def top_p_sampling(logits, p=0.9, temperature=0.7):
# Temperature 적용
scaled = logits / temperature
probs = F.softmax(scaled, dim=-1)
# 확률 내림차순 정렬
sorted_probs, sorted_indices = torch.sort(probs, descending=True)
# 누적 확률 계산
cumulative = torch.cumsum(sorted_probs, dim=-1)
# 누적 확률 p 초과 토큰 제거
mask = cumulative - sorted_probs > p
sorted_probs[mask] = 0.0
# 재정규화 후 샘플링
sorted_probs /= sorted_probs.sum()
token = sorted_indices[torch.multinomial(sorted_probs, 1)]
return token
실무에서는 Temperature와 Top-p를 함께 조합하는 경우가 많습니다. Temperature로 분포의 전반적인 날카로움을 조절한 뒤, Top-p로 꼬리를 잘라내는 방식입니다.
나비효과: 한 토큰이 모든 것을 바꾼다
이 모든 전략에서 공통적으로 작동하는 원리가 하나 있습니다. 자기회귀 생성에서는 각 토큰이 이후 모든 토큰의 조건이 된다는 점입니다.
첫 번째 스텝에서 “해당"이 아닌 “이"가 선택되었다고 가정해 보겠습니다. 단 하나의 토큰 차이지만, 다음 스텝의 조건부 확률 P(x2 | x1) 자체가 완전히 달라집니다. “해당” 뒤에는 “기술은”, “방식은” 같은 토큰이 높은 확률을 갖겠지만, “이” 뒤에는 “문제를”, “과정에서” 같은 전혀 다른 토큰들이 상위권을 차지합니다. 이 차이가 스텝마다 누적되면서, 초기의 미세한 분기가 완전히 다른 문장으로 갈라지는 것입니다.
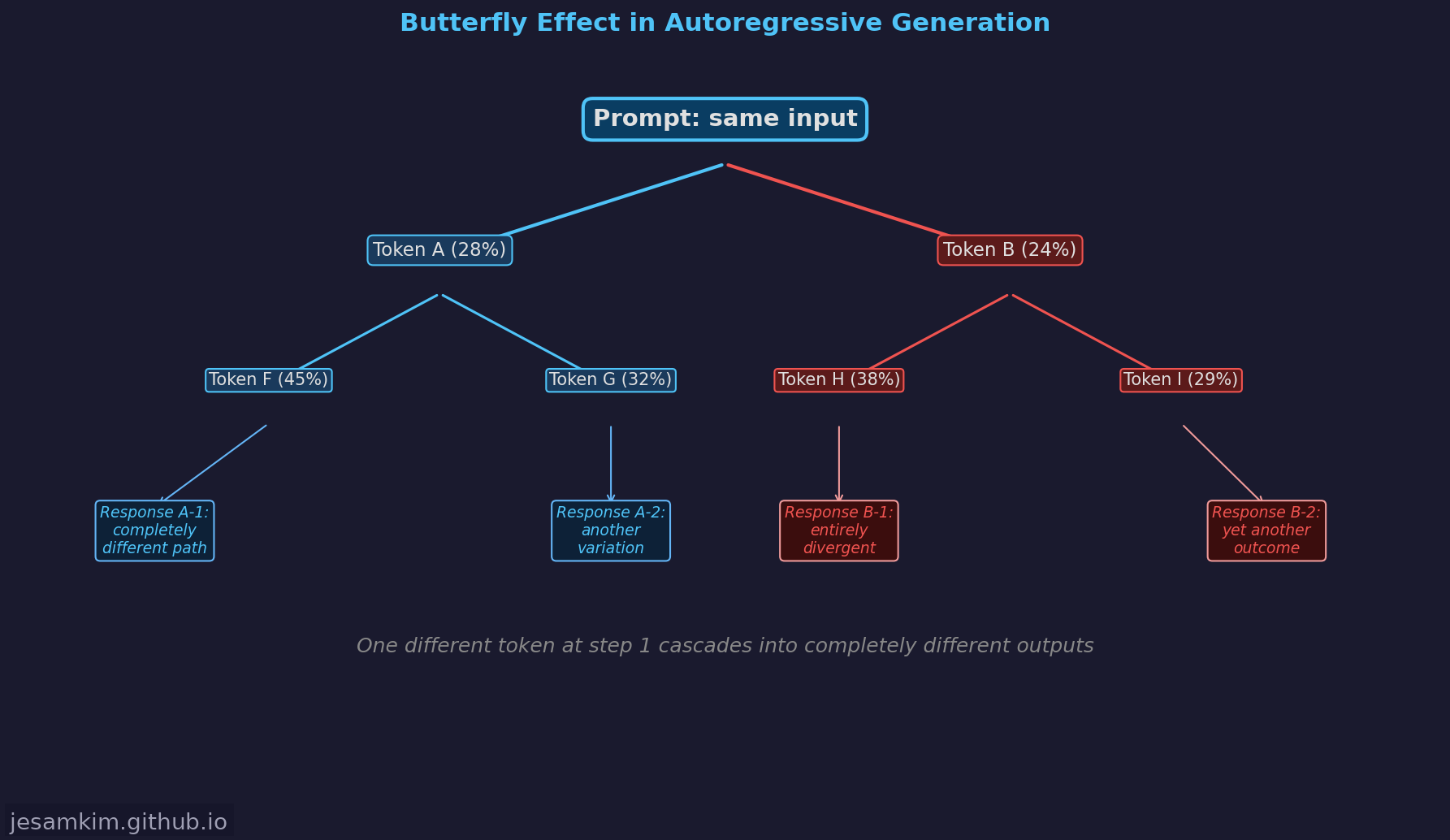
카오스 이론의 나비효과와 구조적으로 동일합니다. 초기 조건의 미세한 차이가 시스템의 궤적을 완전히 바꿔놓는 것입니다. LLM에서 “같은 프롬프트, 다른 답변"이 발생하는 근본 원인이 바로 여기에 있습니다.
5. 실무에서 고민할 점들
원리를 이해했으니, 이제 실무에서 자주 마주치는 질문들을 하나씩 짚어 보겠습니다.
Temperature=0이면 정말 동일한 출력이 나오는가?
이론적으로는 그렇습니다. Temperature를 0으로 설정하면 사실상 Greedy Decoding과 동일하므로 결정론적 출력이 보장되어야 합니다. 그런데 실제 환경에서는 미세한 차이가 발생할 수 있습니다.
- 부동소수점 연산 순서: GPU에서 행렬 곱셈의 덧셈 순서가 달라지면 부동소수점 반올림 오차가 누적됩니다. 두 로짓 값이 극도로 가까운 경우, 이 오차만으로도 argmax의 결과가 뒤바뀔 수 있습니다.
- GPU 배치 구성: 동시에 처리되는 요청의 수나 배치 크기가 달라지면, 내부 연산의 병렬화 패턴이 변하면서 수치적 결과에 미세한 차이가 생깁니다.
- 분산 추론: 여러 GPU나 노드에 걸쳐 모델을 분할(tensor parallelism, pipeline parallelism)하면, 통신 및 집계 순서에 따른 비결정성이 추가됩니다.
결론적으로 Temperature=0은 “거의 동일한 출력"을 보장하지만, “완벽히 동일한 출력"까지는 보장하지 못합니다. 비트 단위의 재현성이 필요한 경우에는 추가적인 조치가 필요합니다.
재현성 확보를 위한 전략
완전한 재현성이 필요한 시나리오(테스트 자동화, 평가 벤치마크, 규제 대응 등)에서는 다음 방법들을 조합해서 사용합니다.
- Temperature 0 고정: Temperature를 0으로 설정하면 사실상 Greedy Decoding이 되어, 대부분의 경우 동일한 출력을 얻을 수 있습니다. 앞서 설명한 부동소수점 비결정성이 있지만, 실무적으로는 가장 간단하고 효과적인 첫 번째 조치입니다.
- 모델 버전 고정:
anthropic.claude-sonnet-4-5-20250929-v1:0처럼 날짜가 포함된 스냅샷 모델 ID를 지정하면, 제공자의 모델 업데이트와 무관하게 동일한 가중치를 사용할 수 있습니다. Amazon Bedrock에서는 이러한 버전 지정 모델 ID를 통해 특정 시점의 모델을 고정할 수 있습니다. - Response Caching: API 응답 자체를 캐싱해서, 동일한 요청에 대해 저장된 결과를 반환합니다. 재현성이 100% 보장되지만, 캐시 미스 시에는 새로운 응답이 생성됩니다.
실무에서는 이 세 가지를 함께 적용하는 것이 가장 안정적입니다. Temperature를 0으로 고정하고, 모델 버전을 명시하며, 중요한 응답은 캐싱하는 구조입니다.
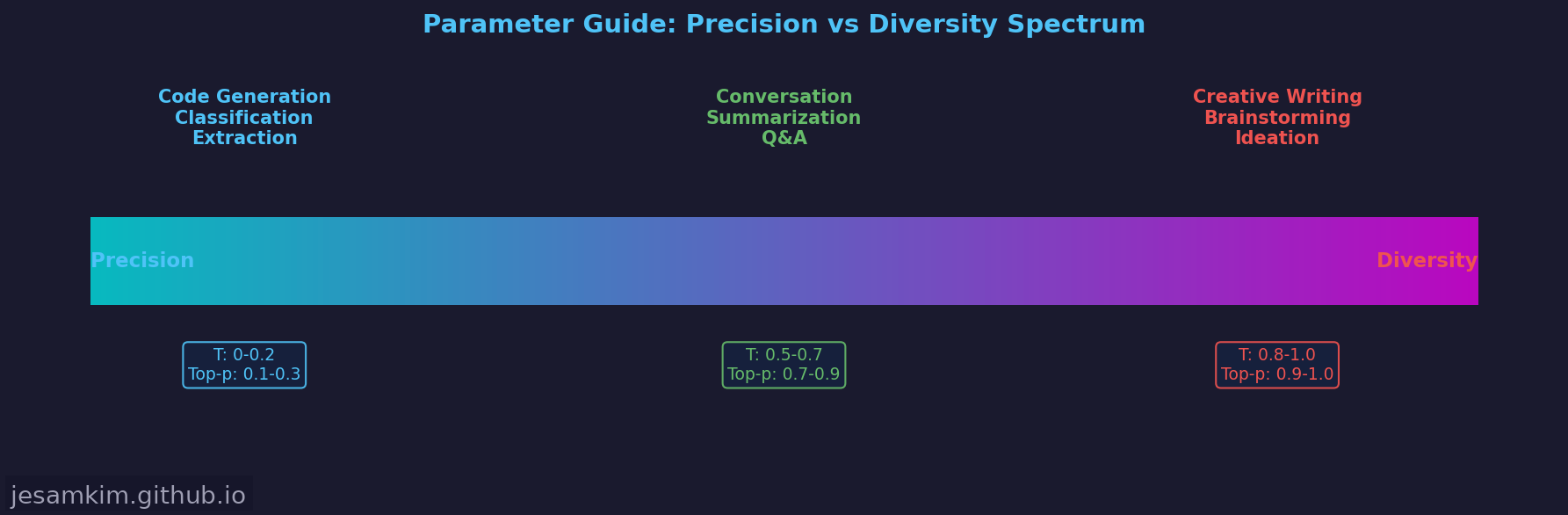
용도별 추천 파라미터
Temperature와 샘플링 파라미터의 선택은 결국 “정확성과 다양성 사이의 트레이드오프"입니다. 실무에서 자주 사용하는 구간을 정리하면 다음과 같습니다.
| 용도 | Temperature | Top-p | 설계 의도 |
|---|---|---|---|
| 코드 생성, 분류, 정보 추출 | 0 ~ 0.2 | 0.1 ~ 0.3 | 정확성 우선. 편차를 최소화하고 일관된 출력 필요 |
| 일반 대화, 요약, Q&A | 0.5 ~ 0.7 | 0.7 ~ 0.9 | 자연스러움과 정확성의 균형 |
| 창작, 브레인스토밍, 아이디어 생성 | 0.8 ~ 1.0 | 0.9 ~ 1.0 | 다양성 우선. 예상치 못한 조합에서 가치 발견 |
이 값들은 출발점일 뿐이며, 실제 프로젝트에서는 평가 데이터셋을 기반으로 파라미터를 튜닝하는 과정이 반드시 필요합니다.
프롬프트 엔지니어링의 본질: 확률분포 조건화
여기까지 이해하셨다면, 프롬프트 엔지니어링이 왜 효과적인지도 자연스럽게 설명됩니다.
프롬프트를 바꾼다는 것은 조건부 확률 P(xt | x<t)에서 조건 x<t를 바꾸는 행위입니다. “요약해 줘"라는 프롬프트와 “3문장으로 핵심만 요약해 줘"라는 프롬프트는 모델에게 서로 다른 조건을 제공하고, 이에 따라 완전히 다른 확률분포가 형성됩니다. 좋은 프롬프트란, 원하는 토큰이 높은 확률을 갖도록 분포를 조건화하는 입력입니다.
이 관점에서 보면, few-shot 예시를 추가하는 것도, 역할을 지정하는 것도, 출력 형식을 명시하는 것도 모두 확률분포의 형태를 원하는 방향으로 편향시키는 작업입니다. Temperature가 분포의 모양을 조절한다면, 프롬프트는 분포의 위치 자체를 옮깁니다.
6. 마무리: 비결정성은 버그가 아니라 설계다
이 글에서 따라온 흐름을 정리해 보겠습니다.
Transformer의 Attention 메커니즘이 문맥을 인코딩하고, 그 위에서 Next Token Prediction이 어휘 전체에 대한 확률분포를 생성합니다. Temperature, Top-k, Top-p 같은 샘플링 전략은 이 분포의 형태를 조절하는 도구이며, 자기회귀 구조의 나비효과가 초기의 미세한 차이를 완전히 다른 문장으로 증폭시킵니다.
같은 프롬프트에 다른 답변이 나오는 현상은, 이 모든 메커니즘이 설계 의도대로 동작한 결과입니다. 확률적 생성이야말로 LLM이 단순 검색 엔진이 아닌 생성 모델일 수 있는 근본적인 이유이기 때문입니다.
실무에서 이 원리를 활용하는 방법은 명확합니다. 정확성이 필요하면 Temperature를 낮추고, 다양성이 필요하면 높이세요. 재현성이 중요하면 Temperature를 0으로 고정하고 모델 버전을 명시하세요. 그리고 가장 강력한 제어 수단은 파라미터 조정이 아니라, 원하는 확률분포를 만들어내는 좋은 프롬프트를 설계하는 것입니다.
References
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention Is All You Need. Advances in Neural Information Processing Systems 30 (NeurIPS 2017). https://arxiv.org/abs/1706.03762
- Holtzman, A., Buys, J., Du, L., Forbes, M., & Choi, Y. (2020). The Curious Case of Neural Text Degeneration. International Conference on Learning Representations (ICLR 2020). https://arxiv.org/abs/1904.09751
- Fan, A., Lewis, M., & Dauphin, Y. (2018). Hierarchical Neural Story Generation. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL 2018). https://arxiv.org/abs/1805.04833
- Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language Models are Unsupervised Multitask Learners. OpenAI Technical Report. https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
- OpenAI. (2023). GPT-4 Technical Report. https://arxiv.org/abs/2303.08774
- Meister, C., Cotterell, R., & Vieira, T. (2023). Locally Typical Sampling. Transactions of the Association for Computational Linguistics (TACL). https://arxiv.org/abs/2202.00666