1. 코딩 에이전트 시대, 왜 비교가 필요한가
2025년 하반기부터 AI 코딩 에이전트 시장이 급격히 달라졌습니다. 단순 코드 자동완성을 넘어, 프로젝트 구조를 설계하고 테스트를 작성하며 배포까지 수행하는 에이전틱(agentic) 코딩 도구가 본격적으로 등장했습니다.
문제는 선택지가 너무 많다는 것입니다. Cursor, Windsurf, Claude Code, Kiro, Copilot, Devin, Google Antigravity 등 수십 개의 도구가 저마다 “최고의 코딩 에이전트"를 표방하고 있습니다. 벤치마크 숫자만 보면 어떤 도구가 좋은지 판단하기 어렵습니다. SWE-bench에서 80%를 달성한 모델이 실제 프로젝트에서도 80%의 문제를 해결해 주는 것은 아니기 때문입니다.
저는 AWS Solutions Architect로 일하면서 Kiro와 Claude Code를 모두 실전에서 사용하고 있습니다. 이 글에서는 벤치마크 수치 비교를 넘어, 동일한 태스크를 두 에이전트에 맡겼을 때 실제로 어떤 차이가 나는지 공유하려 합니다.
2. Claude Code: Anthropic의 에이전틱 코딩 도구
Claude Code는 Anthropic이 2025년 초 리서치 프리뷰로 공개하고 지속적으로 업데이트해 온 터미널 기반 코딩 에이전트입니다. Claude 모델의 코딩 능력을 터미널 환경에서 직접 활용할 수 있도록 설계되었습니다.
핵심 특징
- 1M 토큰 컨텍스트 윈도우: 대규모 코드베이스 전체를 한 번에 읽고 이해할 수 있습니다. 수만 줄의 레거시 코드를 분석할 때 특히 유용합니다.
- 확장 사고(Extended Thinking): 복잡한 문제에 대해 단계별로 추론하는 기능입니다. 코드 리뷰나 아키텍처 분석에서 깊이 있는 결과를 보여줍니다.
- 멀티 에이전트 구조: 서브에이전트를 생성하여 병렬로 작업을 처리할 수 있습니다. Claude Sonnet 4.5 기준 SWE-bench Verified에서 77.2%를 기록했고, 고연산(high compute) 설정에서는 82.0%까지 달성했습니다.
- Claude Agent SDK: Claude Code의 내부 인프라를 개발자에게 공개한 SDK로, 커스텀 에이전트를 구축할 수 있습니다.
SWE-bench 성능
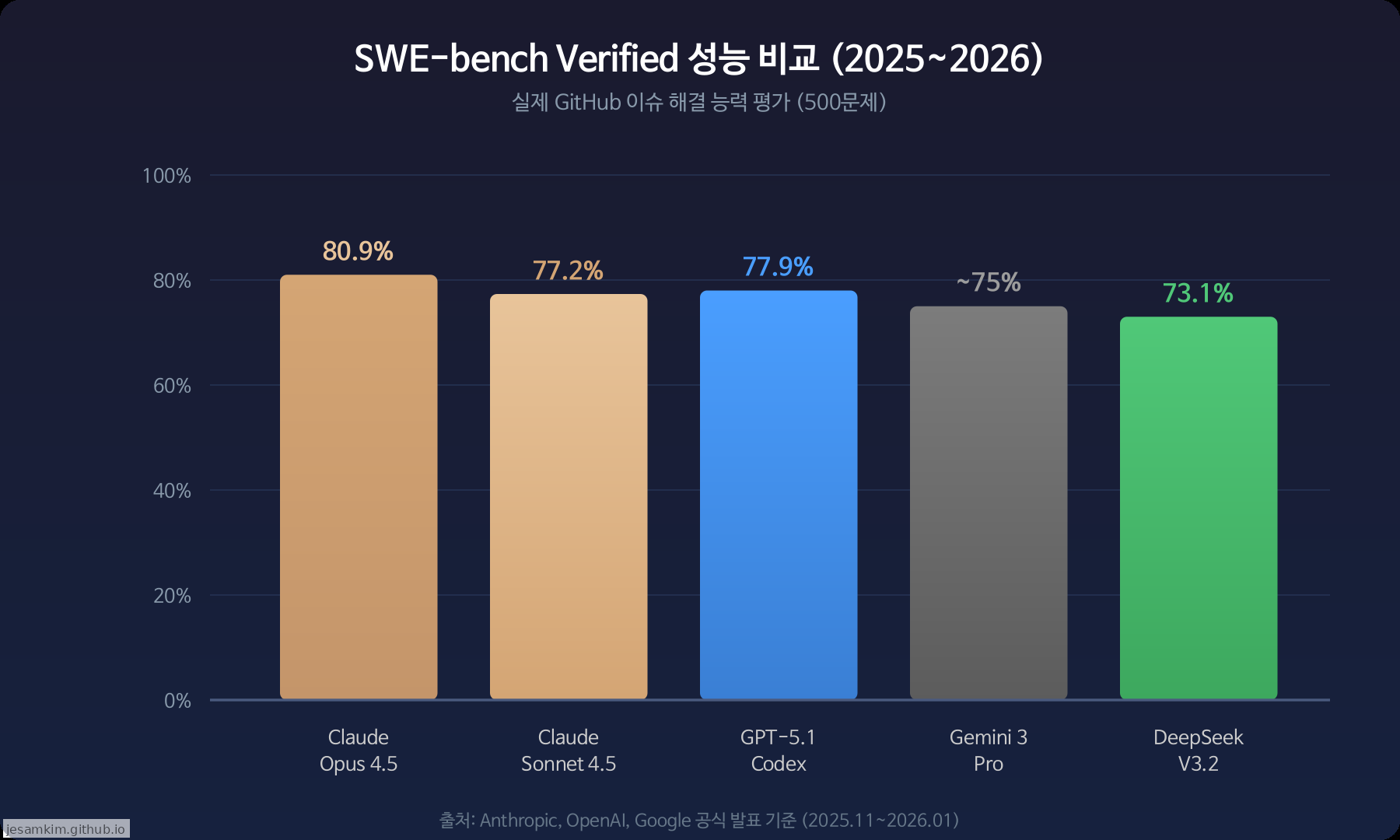
주요 프론티어 모델의 SWE-bench Verified 성능 비교. Claude Opus 4.5가 80.9%로 선두, Sonnet 4.5는 77.2%(기본 설정 기준). 출처: Anthropic, OpenAI, Google 공식 발표 종합.
SWE-bench Verified는 실제 GitHub 이슈 500개를 AI가 해결하는 벤치마크입니다. 2024년 공개 이후 코딩 에이전트 평가의 사실상 표준(de facto standard)으로 자리 잡았으며, 장기 태스크 평가(SWE-Bench Pro), 지속 학습 평가(SWE-Bench-CL) 등 다양한 변형 벤치마크로 확장되고 있습니다. Claude 모델이 상위권을 차지하고 있지만, 이 수치가 곧 실전 성능을 의미하지는 않습니다. 벤치마크는 단일 이슈 해결에 초점을 맞추고 있어서, 프로젝트를 처음부터 구축하는 능력과는 차이가 있습니다.
3. Kiro: AWS의 스펙 기반 에이전틱 IDE
Kiro는 AWS가 2025년 7월 프리뷰로 공개하고, 같은 해 11월 정식 출시한 에이전틱 IDE입니다. “바이브 코딩(vibe coding)을 바이어블 코드(viable code)로” 바꾸겠다는 목표를 내세우며, 구조화된 개발 프로세스를 핵심 차별점으로 삼고 있습니다.
핵심 특징
- Spec 기반 개발: 자연어 프롬프트를 EARS 표기법의 요구사항과 수용 기준으로 변환합니다. 아키텍처 설계, 구현 계획, 태스크 분해까지 자동으로 진행됩니다.
- Steering 파일: 프로젝트별 코딩 규칙, 선호 워크플로우, 컨텍스트를
.kiro/steering/디렉토리에 정의합니다. 에이전트가 프로젝트의 맥락을 일관되게 유지하도록 돕습니다. - Agent Hooks: 파일 저장 같은 이벤트에 반응하여 자동으로 문서 생성, 테스트 작성, 코드 최적화를 수행하는 백그라운드 에이전트입니다.
- Kiro CLI: 터미널에서 Kiro 에이전트를 사용할 수 있는 CLI 도구입니다. SSH 환경에서도 동작하며, MCP(Model Context Protocol) 서버와 네이티브로 통합됩니다.
- Powers: Stripe, Figma, Datadog 등 외부 도구와의 통합을 제공하는 기능으로, 에이전트에게 특정 도구에 대한 전문성을 부여합니다.
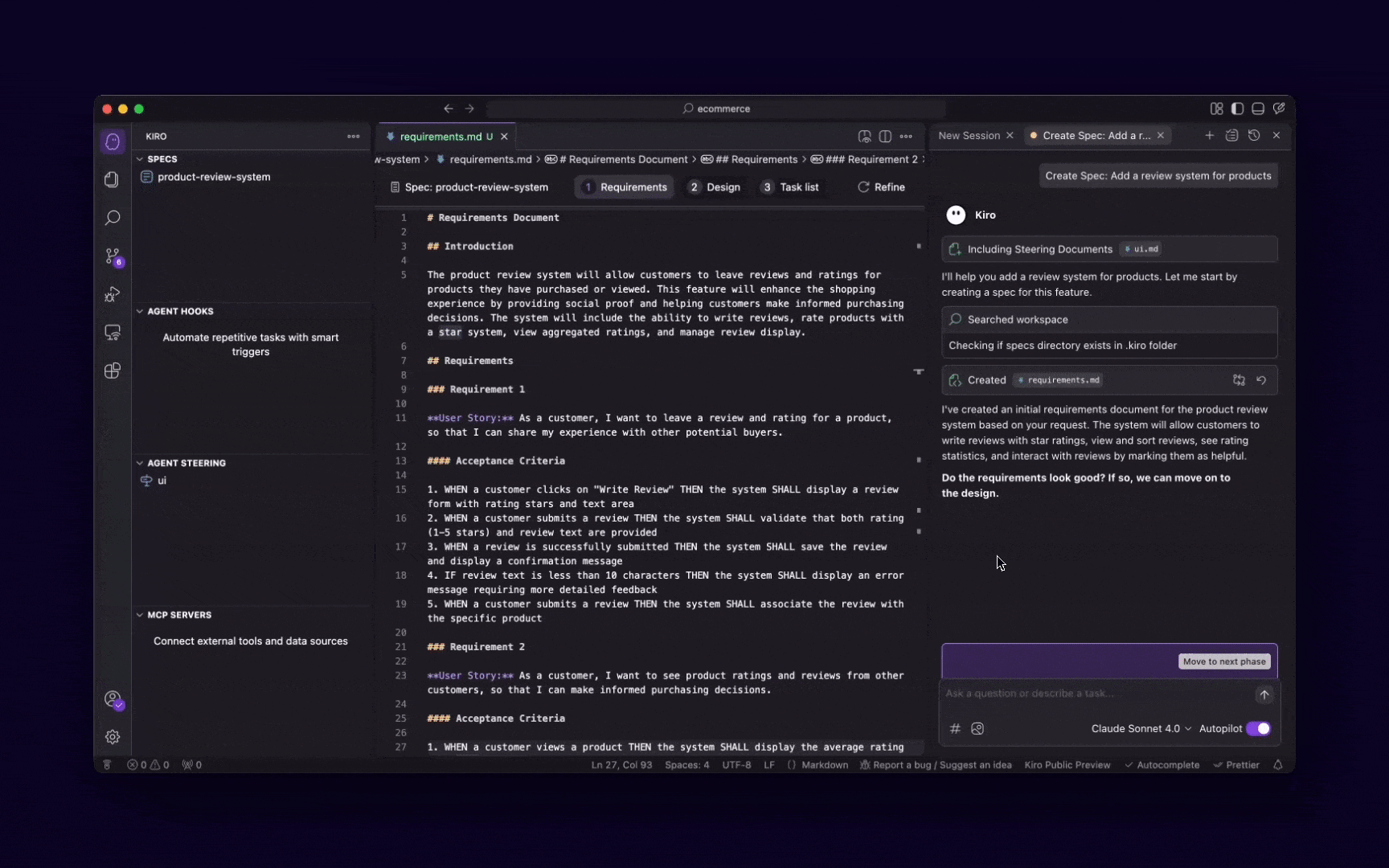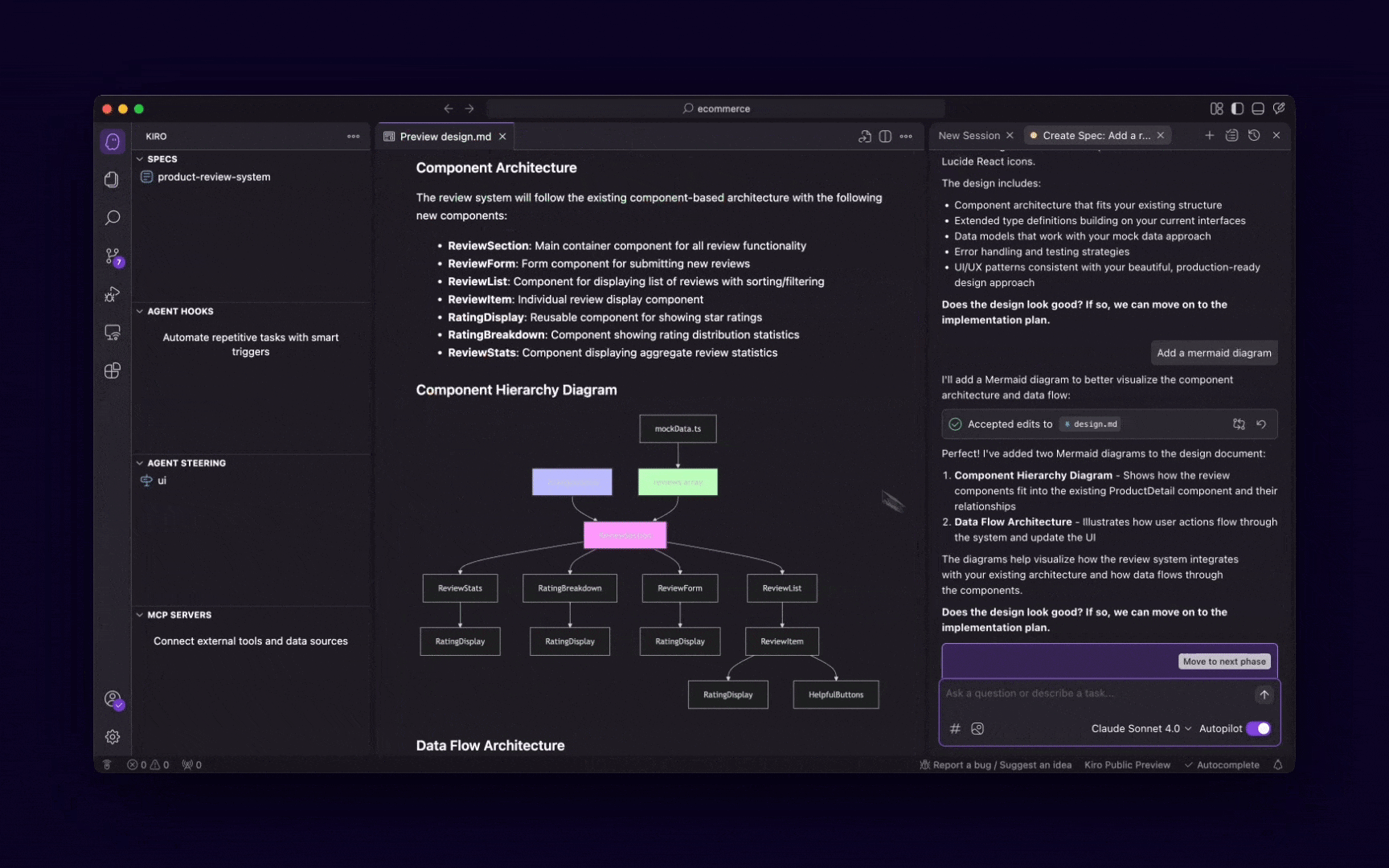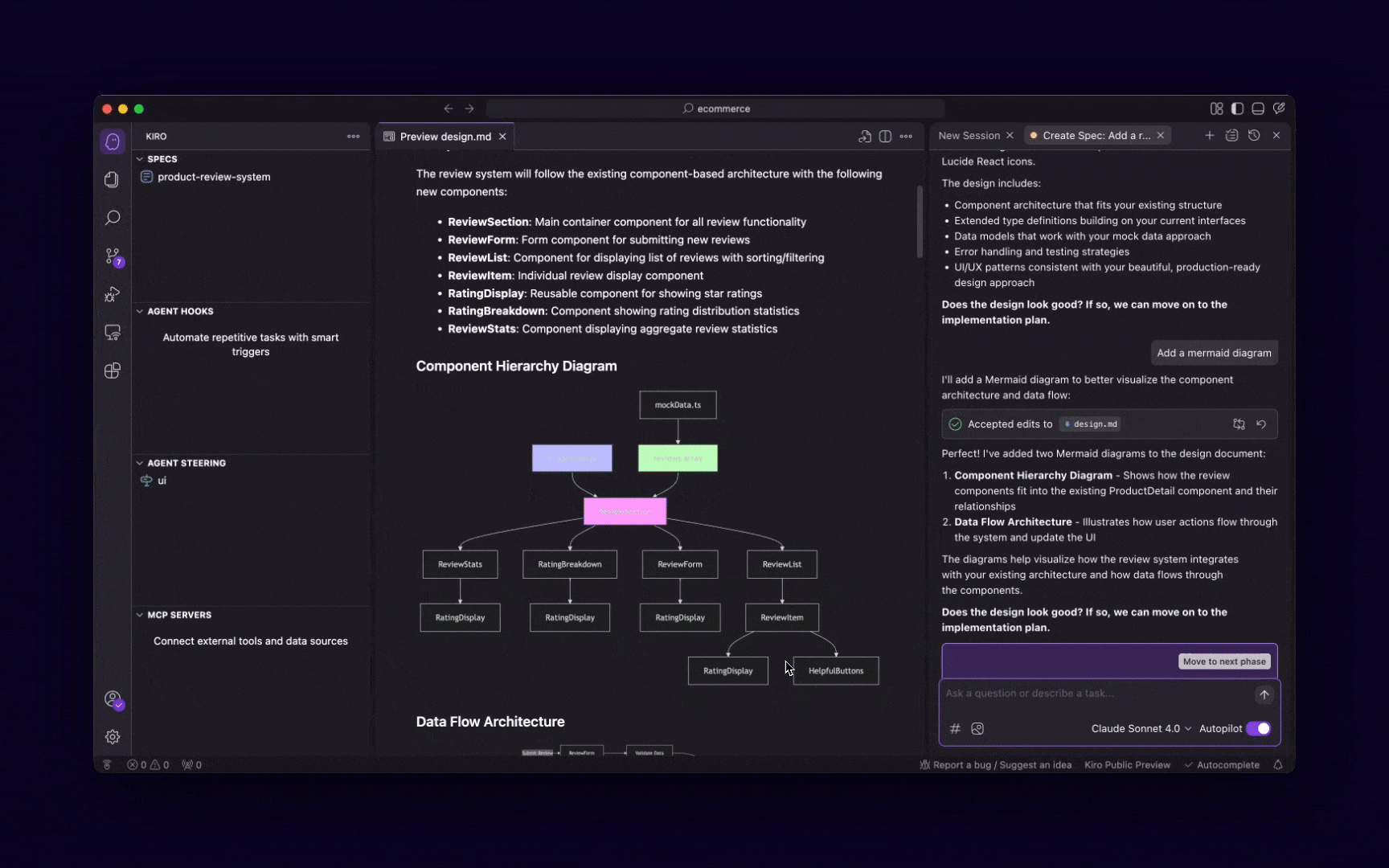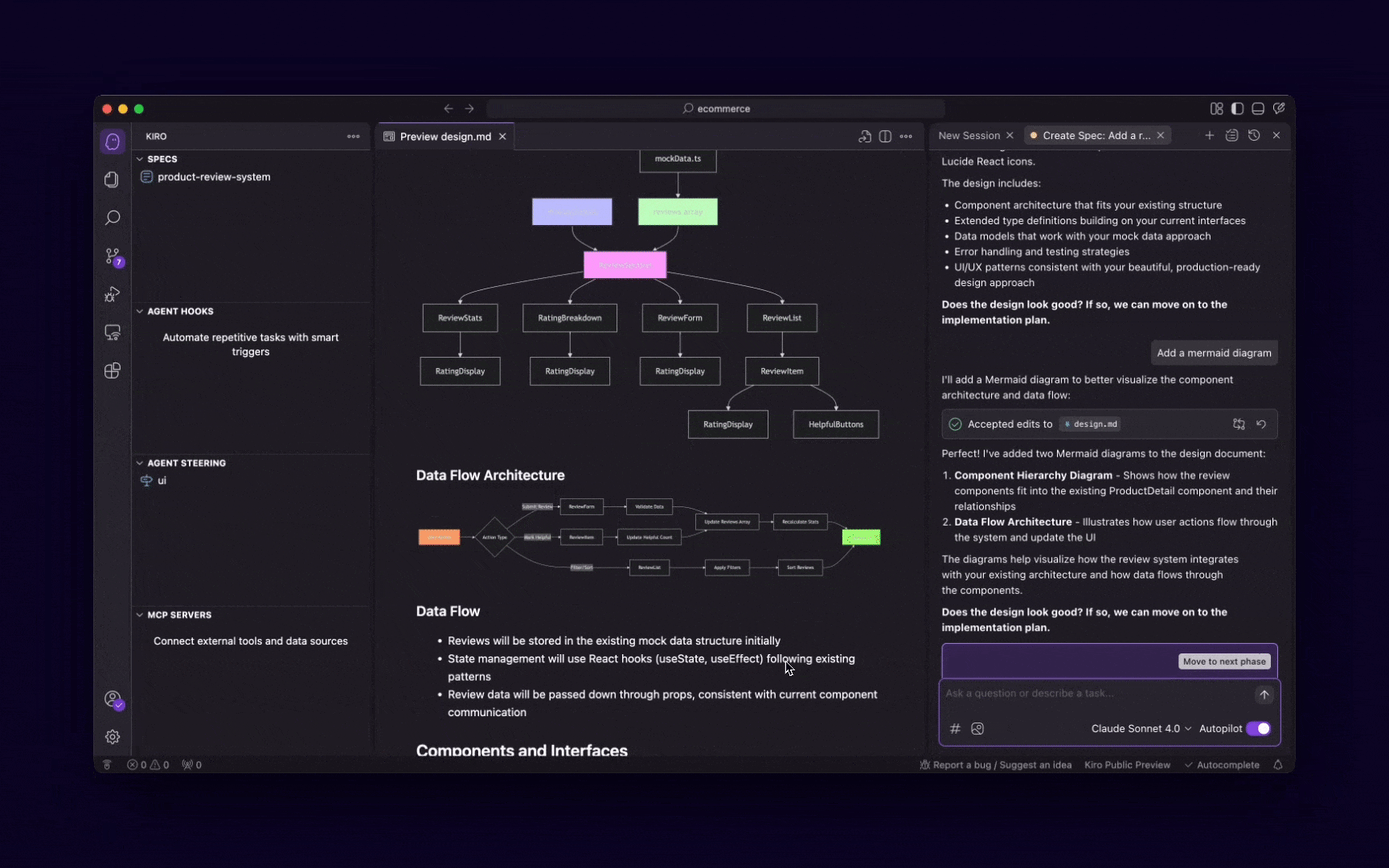
Kiro가 자연어 프롬프트를 요구사항 → 설계 → 태스크로 자동 분해하는 과정. 출처: Kiro 공식 블로그
설계 철학의 차이
Claude Code가 모델의 원시 능력을 최대한 활용하는 방향이라면, Kiro는 프로세스와 구조로 에이전트의 행동을 가이드하는 방향입니다. 비유하자면, Claude Code는 뛰어난 프리랜서 개발자에게 자유롭게 맡기는 것이고, Kiro는 체계적인 프로젝트 매니저가 개발자를 관리하는 것에 가깝습니다.
4. 실전 비교: 백테스트 환경 구축
벤치마크 수치보다 중요한 것은 실제 작업에서의 성능입니다. 동일한 태스크를 두 에이전트에 맡기고 결과를 비교했습니다.
태스크 정의
목표: Python 기반 퀀트 백테스트 환경 구축. 데이터 수집 파이프라인, 전략 엔진, 시뮬레이션 실행기, 테스트 코드를 포함하는 프로젝트를 처음부터 생성합니다.
동일한 프롬프트, 동일한 코드베이스 컨텍스트, 동일한 요구사항을 사용했습니다.
Kiro (kiro-cli) 결과
Kiro는 steering 파일을 로드한 뒤 곧바로 실행에 들어갔습니다.
- 0~1분: 요구사항 분석, 프로젝트 구조 설계
- 1~4분: 디렉토리 구조 생성, 핵심 모듈 코드 작성 (8개 파일)
- 4~7분: 데이터 파이프라인 구현, 전략 엔진 연결
- 7~9분: 테스트 코드 29개 작성 및 실행
- 9~11분: 시뮬레이션 실행, 결과 확인, 완료
총 소요 시간: 11분. 생성 파일: 8개. 테스트: 29개 통과. 시뮬레이션: 정상 실행.
Claude Code 결과
Claude Code는 다른 패턴을 보였습니다.
- 0~3분: 코드베이스 Read 반복. 기존 파일 구조를 여러 차례 읽음
- 3~6분: 아키텍처 분석 계속. 의존성 관계를 파악하는 데 집중
- 6~10분: 추가 Read 작업. 더 많은 컨텍스트를 수집하려는 시도
- 10분 이후: 여전히 분석 단계. 파일 생성 없음
총 소요 시간: 10분 이상. 생성 파일: 0개. 상태: 분석 반복(Analysis Paralysis).
타임라인 비교
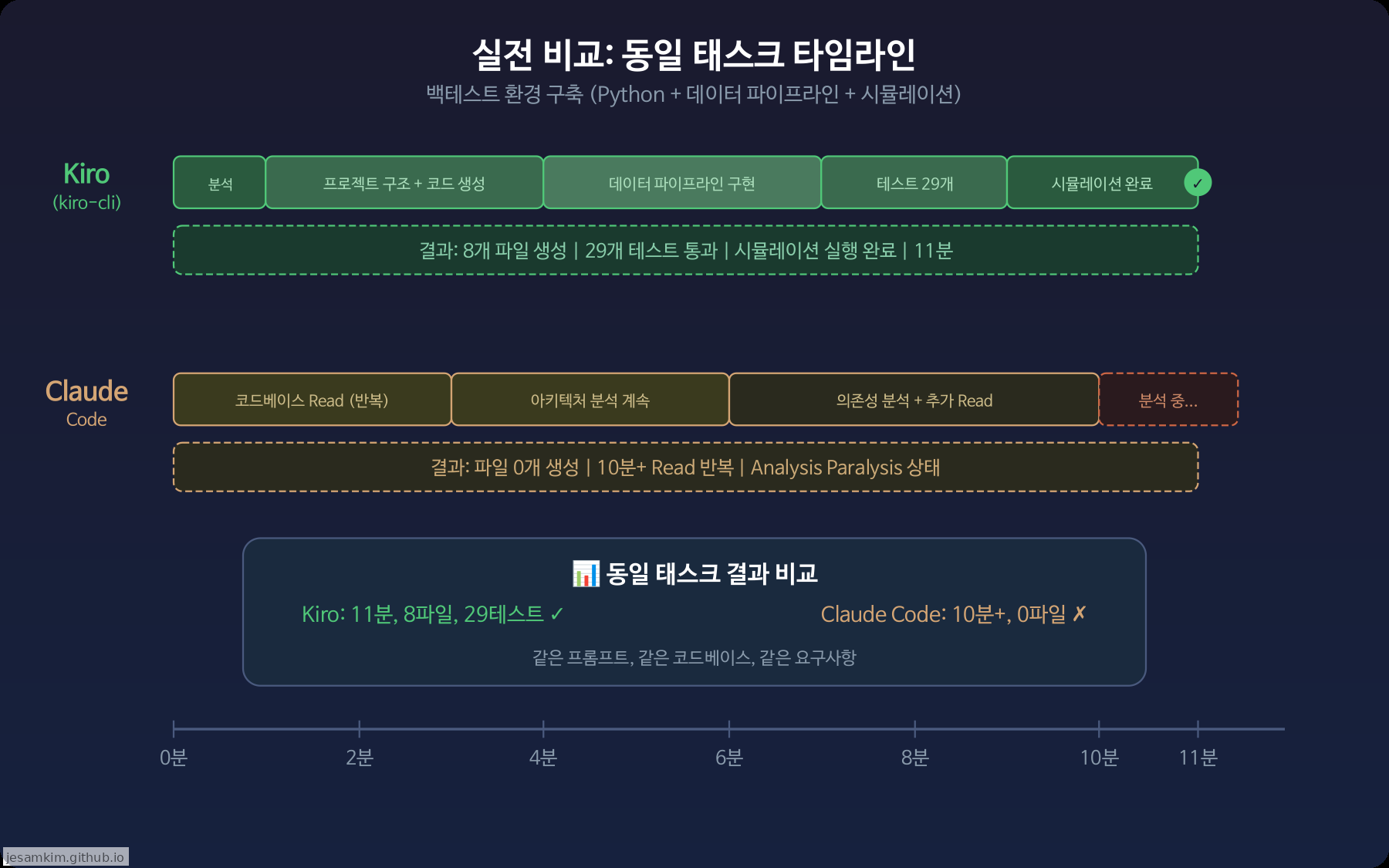
동일한 백테스트 환경 구축 태스크에서 Kiro는 11분 만에 완료한 반면, Claude Code는 10분 넘게 분석만 반복했습니다.
왜 이런 차이가 발생했나
이 결과가 “Kiro가 Claude Code보다 낫다"는 뜻은 아닙니다. 두 도구의 설계 철학 차이가 특정 태스크 유형에서 다른 결과를 만든 것입니다.
- Kiro의 강점이 드러난 이유: Steering 파일이 프로젝트 컨텍스트를 미리 제공하고, spec 기반 접근이 “분석 후 즉시 구현"으로 이어지는 워크플로우를 만들었습니다. 에이전트가 무엇을 해야 하는지 명확히 알고 있었습니다.
- Claude Code가 어려움을 겪은 이유: 1M 컨텍스트 윈도우의 장점이 이 태스크에서는 오히려 단점이 되었습니다. 더 많은 정보를 수집하려는 경향이 “충분히 분석한 뒤 구현하자"는 패턴으로 이어졌고, 구현 시작 시점이 계속 늦어졌습니다.
반대로, 수만 줄의 레거시 코드를 분석하고 리팩터링하는 태스크에서는 Claude Code의 깊은 분석 능력이 Kiro보다 유리할 수 있습니다. 도구의 우열이 아니라 태스크와 도구의 궁합이 핵심입니다.
5. 에이전트 선택 가이드: 상황별 추천
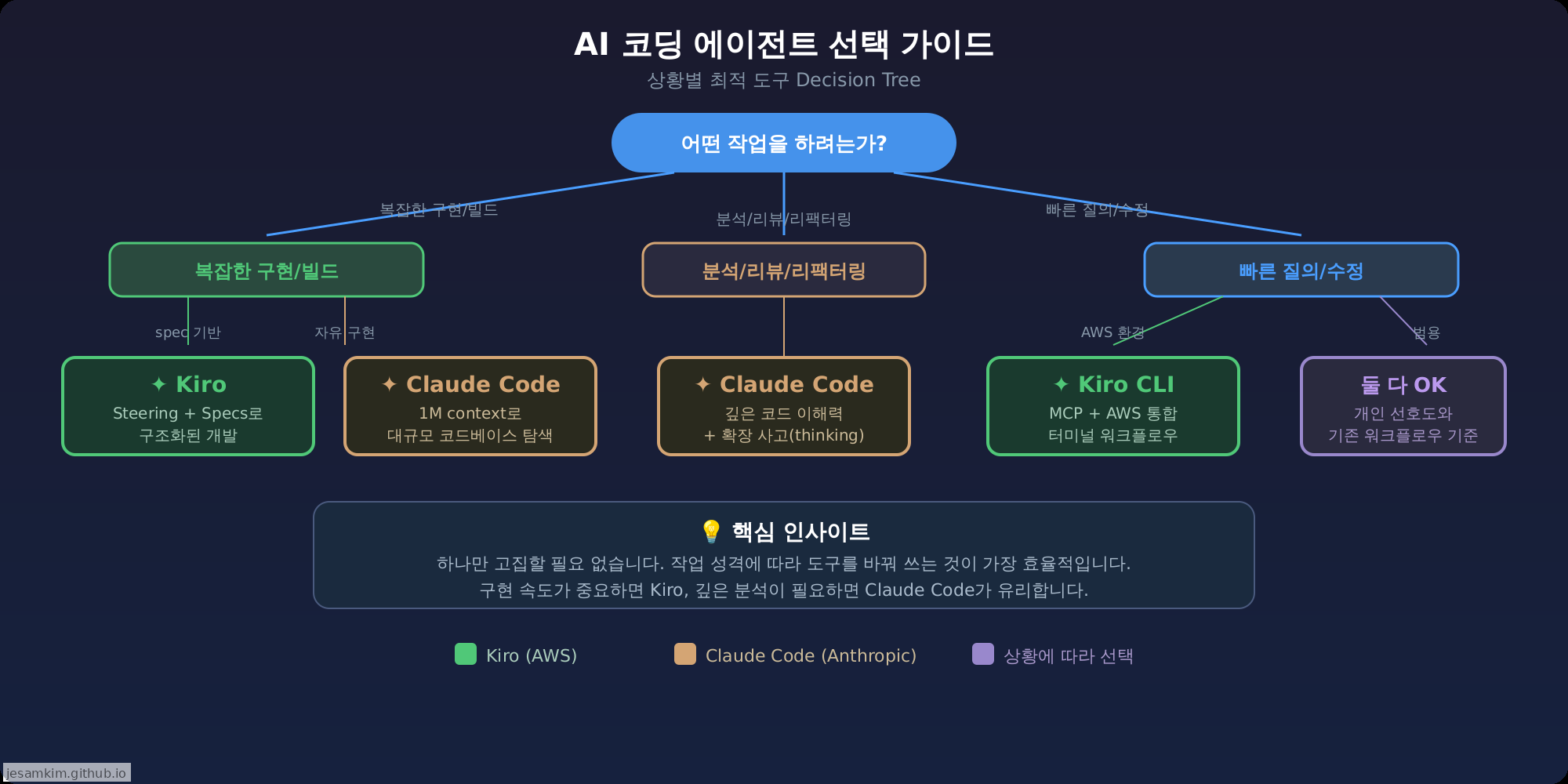
작업 성격에 따른 에이전트 선택 가이드. 하나만 고집할 필요 없이, 상황에 맞게 도구를 바꿔 쓰는 것이 효율적입니다.
실전에서 두 도구를 번갈아 사용하면서 정리한 가이드입니다.
프로젝트를 처음부터 구축할 때
추천: Kiro
Steering 파일로 프로젝트 규칙을 정의하고, spec 기반으로 요구사항을 구조화한 뒤 구현에 들어가는 흐름이 효과적입니다. 특히 AWS 서비스와 연동하는 프로젝트에서는 MCP 통합이 큰 도움이 됩니다.
대규모 코드베이스 분석/리팩터링
추천: Claude Code
1M 토큰 컨텍스트로 전체 코드베이스를 한 번에 파악하고, 확장 사고로 복잡한 의존성을 추적하는 데 강점이 있습니다. 코드 리뷰, 버그 추적, 아키텍처 분석에서 깊이 있는 결과를 보여줍니다.
빠른 수정/질의
추천: 둘 다 가능
간단한 버그 수정이나 코드 질의는 두 도구 모두 잘 처리합니다. AWS 환경이라면 Kiro CLI가 편리하고, 이미 Claude Code를 사용 중이라면 굳이 전환할 필요가 없습니다.
팀 협업 환경
추천: Kiro
Steering 파일과 spec이 팀 전체의 코딩 규칙과 프로젝트 컨텍스트를 공유하는 역할을 합니다. 새로운 팀원이 합류해도 에이전트가 동일한 규칙을 따르므로 일관성을 유지하기 쉽습니다.
주목할 만한 에이전트: Google Antigravity
Google이 2025년 11월 Gemini 3 출시와 함께 공개한 에이전틱 IDE입니다. VS Code를 포크한 에디터에 Agent Manager(Mission Control)를 탑재하여, 에이전트가 에디터-터미널-브라우저를 자율적으로 넘나들며 작업을 수행합니다.
Antigravity의 Agent Manager. 에이전트가 코드 작성, 터미널 실행, 브라우저 테스트를 자율적으로 오케스트레이션합니다. 출처: Google Developers Blog
Kiro가 spec/steering으로 구조를 잡아주는 방식이라면, Antigravity는 에이전트의 자율성을 극대화하는 방향입니다. 멀티 에이전트 협업, 웹 브라우징을 통한 실시간 테스트 검증 등 Kiro나 Claude Code와는 또 다른 접근을 보여줍니다. Gemini 3.1 Pro를 기본 모델로 사용하며, 무료 티어를 제공하고 있어 진입 장벽이 낮습니다.
그 외 에이전트
Cursor와 Windsurf는 에디터 통합 경험이 뛰어나고, Devin은 장시간 자율 작업에 특화되어 있습니다. 시장이 빠르게 변하고 있어서, 6개월 뒤에는 이 가이드도 달라질 수 있습니다.
6. 마무리: 하나만 쓸 필요 없다
AI 코딩 에이전트를 “어떤 것이 최고인가"의 프레임으로 바라보면 답이 나오지 않습니다. 실전에서 중요한 것은 작업 성격에 맞는 도구를 선택하는 능력입니다.
정리하면 이렇습니다.
- 구조화된 구현이 필요할 때: Kiro의 spec 기반 접근이 빠른 결과를 만들어 냅니다.
- 깊은 분석이 필요할 때: Claude Code의 대용량 컨텍스트와 확장 사고가 유리합니다.
- 팀 일관성이 중요할 때: Kiro의 steering과 hooks가 규칙을 자동으로 적용합니다.
- 빠른 반복이 필요할 때: 익숙한 도구가 최고의 도구입니다.
코딩 에이전트는 개발자를 대체하는 것이 아니라, 개발자의 의사결정 능력을 증폭시키는 도구입니다. 어떤 에이전트를 쓰느냐보다, 에이전트에게 무엇을 어떻게 시키느냐가 결과를 결정합니다. Steering 파일 하나, 프롬프트 한 줄의 차이가 11분 완료와 10분 분석의 차이를 만들 수 있습니다.
두 도구 모두 빠르게 진화하고 있습니다. 오늘의 약점이 다음 업데이트에서 강점이 될 수 있습니다. 중요한 것은 도구에 대한 충성이 아니라, 문제에 대한 집중입니다.
References
- Anthropic, “Introducing Claude Sonnet 4.5,” Sep 2025. https://www.anthropic.com/news/claude-sonnet-4-5
- Anthropic, “Raising the bar on SWE-bench Verified with Claude 3.5 Sonnet,” Jan 2025. https://www.anthropic.com/engineering/swe-bench-sonnet
- Anthropic, “Enabling Claude Code to work more autonomously,” Sep 2025. https://www.anthropic.com/news/enabling-claude-code-to-work-more-autonomously
- AWS, “Kiro: Agentic AI development from prototype to production.” https://kiro.dev
- SiliconANGLE, “AWS launches Kiro into general availability with team features and CLI support,” Nov 2025. https://siliconangle.com/2025/11/17/aws-launches-kiro-code-general-availability-team-features-cli-support/
- Kiro Documentation, “Steering.” https://kiro.dev/docs/steering/
- Kiro Documentation, “CLI.” https://kiro.dev/docs/cli/
- Kiro Documentation, “Specs.” https://kiro.dev/docs/specs/
- SWE-bench Official. https://www.swebench.com/
- Vals AI, “SWE-bench Leaderboard.” https://www.vals.ai/benchmarks/swebench
- Jimenez, C. E., Yang, J., Wettig, A., Yao, S., Pei, K., Press, O., & Narasimhan, K., “SWE-bench: Can Language Models Resolve Real-World GitHub Issues?” arXiv:2310.06770, 2024. https://arxiv.org/abs/2310.06770
- “SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?” arXiv:2509.16941, Nov 2025. https://arxiv.org/abs/2509.16941
- “A Survey on Code Generation with LLM-based Agents,” arXiv:2508.00083, Sep 2025. https://arxiv.org/abs/2508.00083
- “SWE-Bench-CL: Continual Learning for Coding Agents,” arXiv:2507.00014, Jun 2025. https://arxiv.org/abs/2507.00014
- “UTBoost: Rigorous Evaluation of Coding Agents on SWE-Bench,” arXiv:2506.09289, Jun 2025. https://arxiv.org/abs/2506.09289
- Google Developers Blog, “Build with Google Antigravity, our new agentic development platform,” Nov 2025. https://developers.googleblog.com/build-with-google-antigravity-our-new-agentic-development-platform/
- Google Antigravity Official. https://antigravityai.org/