1. 들어가며: LLM API 호출만으로는 부족한 이유
최근 개발 워크플로우에 LLM을 도입하는 팀이 빠르게 늘고 있습니다. 대부분의 첫 시도는 Anthropic API를 직접 호출하는 아래와 같은 형태일 것입니다.
import anthropic
client = anthropic.Anthropic()
response = client.messages.create(
model="global.anthropic.claude-sonnet-4-6",
max_tokens=1024,
messages=[{"role": "user", "content": "Fix the bug in my auth module"}],
)
print(response.content.text)
코드 한 줄의 버그를 잡거나 간단한 유틸 함수를 생성할 때는 이 단순 프롬프트-응답 루프(Single-turn Prompt-Response Loop)만으로도 충분합니다. 하지만 실제로 써보면, 프로덕션 수준의 코딩 작업에서는 금세 벽에 부딪힙니다.
먼저 컨텍스트 유실(Context Loss) 문제가 있습니다. 프로젝트의 디렉터리 구조, 의존성 그래프, 기존 코드 컨벤션 같은 정보가 매 호출마다 사라집니다. 개발자가 매번 수동으로 컨텍스트를 재구성해야 하고, 이는 토큰 낭비이자 품질 저하로 이어집니다.
도구 연동(Tool Integration)도 빠져 있습니다. 실제 코딩 작업에는 파일 읽기/쓰기, 테스트 실행, 린터 확인, Git 커밋 등 외부 도구와의 상호작용이 필수입니다. 단순 API 호출은 텍스트를 반환할 뿐, 이런 도구를 직접 실행할 수 없습니다.
피드백 루프(Feedback Loop)도 마찬가지입니다. 생성된 코드가 컴파일에 실패하거나 테스트를 통과하지 못했을 때, 그 결과를 자동으로 모델에 되돌려 수정하는 반복 메커니즘이 없습니다. 결국 개발자가 오류 메시지를 복사해서 붙여넣는 작업을 반복하게 됩니다.
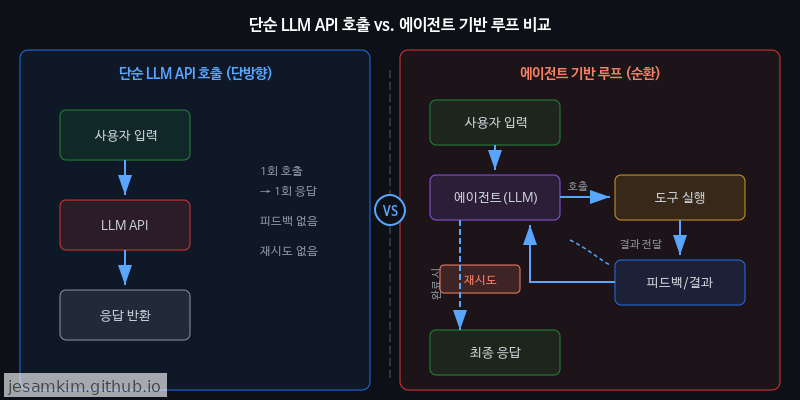
개인적으로 이런 한계를 겪으면서, LLM을 단순한 “텍스트 생성기"가 아니라 애플리케이션의 런타임 엔진(Runtime Engine)으로 격상시켜야 한다고 느꼈습니다. 모델이 자체적으로 환경을 인식하고, 도구를 호출하며, 결과를 평가해 다음 행동을 결정하는 것. 즉 에이전트(Agent)로서 동작해야 비로소 프로덕션 수준의 자동화가 가능해집니다.
이 포스트에서는 이러한 패러다임 전환을 세 가지 축으로 살펴봅니다. 1부에서는 Claude Agent SDK, OpenHands 등 최신 기술 트렌드를 짚고, 2부에서는 Agentic Programming과 코드 생성 에이전트 서베이 논문을 통해 학술적 근거를 확인합니다. 마지막 3부에서는 Amazon Bedrock 환경에서 이를 실전 적용하는 구체적인 시나리오를 다루겠습니다.
2. [1부] 최신 기술 트렌드: API에서 Agent SDK/CLI 엔진으로
그렇다면 단순 API 호출의 한계를 넘어서기 위해 업계는 어떤 방향으로 움직이고 있을까요? 핵심 키워드는 “에이전트의 프로그래밍 가능한 런타임화(Programmable Runtime)"입니다.
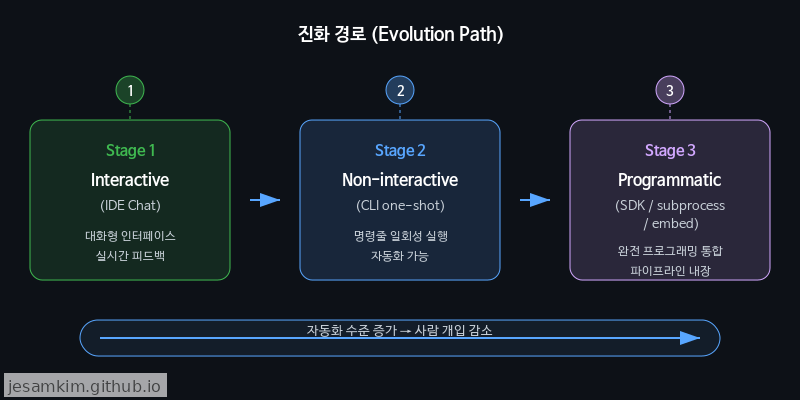
Interactive → Non-interactive → Programmatic 진화
코딩 에이전트의 활용 방식은 세 단계로 진화해 왔습니다. 첫 번째는 GitHub Copilot Chat처럼 사용자가 IDE 안에서 대화하며 코드를 받는 Interactive 단계입니다. 두 번째는 Claude Code CLI처럼 터미널에서 프롬프트 하나로 작업을 위임하는 Non-interactive 단계입니다. 그리고 세 번째가 바로 지금 열리고 있는 Programmatic 단계, 에이전트를 서브프로세스(subprocess)로 임베드하여 애플리케이션 로직의 일부로 구동하는 방식입니다.
Claude Agent SDK: 에이전트를 서브프로세스로
Anthropic이 2025년 출시한 Claude Code SDK(현 Claude Agent SDK)는 이 Programmatic 단계를 정조준합니다. 설계 철학의 핵심은 Headless 모드와 멀티턴 오케스트레이션(Multi-turn Orchestration)입니다. 개인적으로 가장 인상적이었던 부분은, 에이전트를 사람이 지켜보는 대화 상대가 아니라 CI/CD 파이프라인 안의 엔진으로 쓸 수 있도록 설계했다는 점입니다.
import subprocess, json
result = subprocess.run(
["claude", "-p", "Fix the failing test in test_auth.py and explain the root cause",
"--output-format", "json", "--allowedTools", "Edit,Bash"],
capture_output=True, text=True
)
response = json.loads(result.stdout)
print(response["result"]) # 수정 내용 + 원인 분석 반환
위 예시처럼 --output-format json 플래그 하나로 에이전트의 출력을 구조화된 데이터로 받을 수 있고, --allowedTools로 에이전트가 사용할 도구 범위를 제한할 수도 있습니다. 실제로 써보면, 사람이 터미널 앞에 없어도 에이전트가 파일을 편집하고 테스트를 돌린 뒤 결과를 JSON으로 반환하는 흐름이 상당히 매끄럽습니다.
OpenHands SDK: 오픈소스와 샌드박스의 힘
OpenHands(구 OpenDevin) 역시 SDK를 공개하며 Programmatic 에이전트 시장에 합류했습니다(arXiv 2511.03690). Claude Agent SDK와 비교했을 때 눈에 띄는 차별점은 다음과 같습니다.
- Docker 기반 샌드박스 실행 환경, 에이전트의 코드 실행이 격리된 컨테이너 안에서 이루어지기 때문에 호스트 시스템의 안전성을 확보할 수 있습니다.
- 멀티 LLM 라우팅(Multi-LLM Routing), Claude, GPT-4o, DeepSeek 등 여러 모델을 태스크 특성에 따라 전환할 수 있습니다.
- 오픈소스 생태계, 커스텀 에이전트 정의, 도구 확장, 자체 호스팅이 모두 가능해서 엔터프라이즈 환경에서 유연하게 운영할 수 있습니다.
결국 두 SDK 모두 같은 방향을 가리키고 있습니다. 코딩 에이전트는 더 이상 개발자가 ‘대화하는’ 도구가 아니라, 애플리케이션이 ‘호출하는’ 런타임 엔진이 되고 있다는 것입니다. 다음 장에서는 이 흐름을 뒷받침하는 학술적 근거를 살펴보겠습니다.
3. [1부 보충] 에이전트 아키텍처의 핵심 구성 요소
앞서 살펴본 SDK/CLI 엔진화 흐름이 왜 가능해졌는지를 이해하려면, 에이전트 내부의 루프 구조를 한 단계 더 깊이 들여다볼 필요가 있습니다.
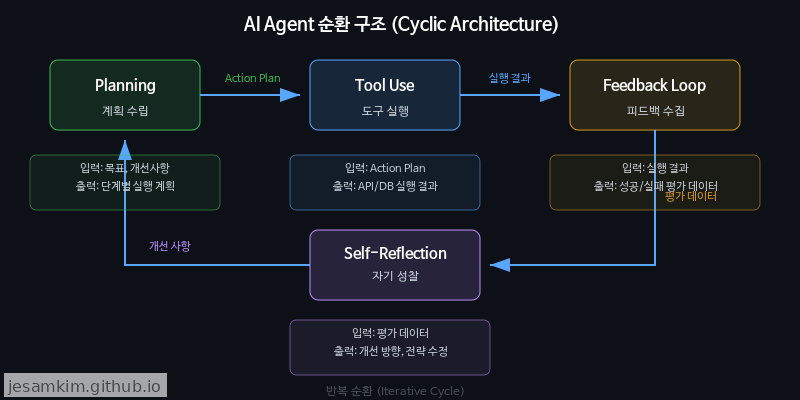
4단계 에이전트 루프
현재 대부분의 코딩 에이전트는 공통된 실행 사이클을 따릅니다.
Planning → Tool Use → Feedback Loop → Self-Reflection
사용자의 요청을 받으면 먼저 작업 계획(Planning)을 수립하고, 파일 편집이나 터미널 실행 같은 도구(Tool Use)를 호출합니다. 그 결과, 즉 테스트 통과 여부나 린트 에러 메시지 등을 피드백(Feedback Loop)으로 수집한 뒤, 자체적으로의 출력을 평가(Self-Reflection)하여 다음 행동을 결정합니다. 개인적으로, 이 루프가 단순한 “LLM에게 코드 짜달라고 하기"와 결정적으로 다른 지점이라고 생각합니다.
에이전트 구성 요소 분류 체계
코드 생성 에이전트 서베이(arXiv 2508.00083)에서는 이 루프를 더 체계적으로 네 가지 축으로 분류합니다.
- Perception: 코드베이스, 이슈, 테스트 결과 등 컨텍스트를 인식하는 계층
- Memory: 대화 히스토리, 파일 변경 이력 등을 유지하는 단기/장기 메모리
- Action: 코드 생성, 파일 수정, 명령어 실행 등 실제 환경에 영향을 미치는 행위
- Learning: 피드백을 통해 전략을 조정하거나 프롬프트를 개선하는 자기 학습
실제로 써보면, Claude Code나 OpenHands 같은 SDK가 내부적으로 이 네 가지를 어떻게 구현했느냐에 따라 체감 성능 차이가 상당합니다.
“Agentic Software Engineering"이라는 구분
DeepCode(arXiv 2512.07921)는 기존의 단발성 코드 생성 자동화(Code Generation)와 구별하기 위해 “Agentic Software Engineering"이라는 용어를 명시적으로 제안합니다. 핵심 차이는 명확합니다. 기존 방식이 프롬프트 한 번에 코드 스니펫 하나를 반환하는 stateless 호출이라면, Agentic 방식은 환경을 탐색하고, 실행하고, 실패하면 자체적으로 수정하는 stateful 루프를 전제로 합니다.
# 개념적 비교: 기존 vs. Agentic
# 기존: 단발 호출
response = llm.generate("Fix the bug in auth.py")
# Agentic: 루프 기반 실행 (Amazon Bedrock 연동)
import os
os.environ["CLAUDE_CODE_USE_BEDROCK"] = "1" # Bedrock을 모델 프로바이더로 사용
from claude_agent_sdk import query, ClaudeAgentOptions
async for msg in query(
prompt="Fix the failing test in auth.py",
options=ClaudeAgentOptions(
model="global.anthropic.claude-sonnet-4-6",
allowed_tools=["Edit", "Bash"],
max_turns=10, # 자기 수정 루프 허용
),
):
result = msg
이 구분이 중요한 이유는, 2부에서 다룰 학술적 실효성 측정의 기준선이 되기 때문입니다. 단순 코드 생성 정확도가 아니라, 루프를 통한 최종 문제 해결률이 진짜 지표가 됩니다.
4. [2부] 논문 기반 학술적 근거, Agentic Programming 패러다임과 실효성
1부에서 살펴본 기술 트렌드가 업계의 실무적 흐름이었다면, 이번 2부에서는 이러한 변화를 뒷받침하는 학술적 근거를 짚어보겠습니다.
Agentic Programming 패러다임의 정의
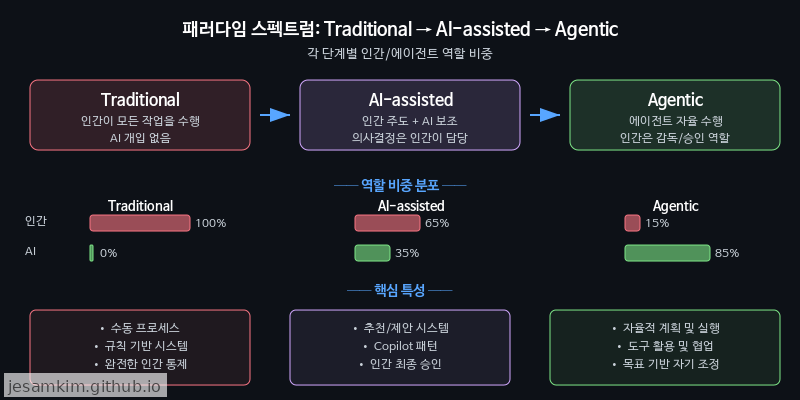
최근 발표된 논문(arxiv 2508.11126)은 프로그래밍 패러다임을 세 단계 스펙트럼으로 정의합니다.
| 단계 | 특징 |
|---|---|
| Traditional Programming | 개발자가 모든 로직을 직접 작성 |
| AI-assisted Programming | Copilot 등이 코드 조각을 제안, 최종 판단은 인간 |
| Agentic Programming | 에이전트가 목표를 받아 자율적으로 계획·실행·검증을 반복 |
핵심은 자율성 수준(Level of Autonomy)의 차이입니다. AI-assisted 단계에서는 인간이 루프의 중심에 있지만, Agentic 단계에서는 에이전트가 루프를 주도하고 인간은 목표 설정과 최종 승인만 담당합니다. 1부에서 다룬 Interactive에서 Non-interactive, 그리고 Programmatic으로의 진화가 이 스펙트럼 위의 이동에 해당합니다.
코딩 에이전트 실효성의 인과 추정
“에이전트가 정말 생산성을 높이는가?“라는 질문에 대해, 단순 전후 비교가 아닌 Difference-in-Differences(DiD) 방법론을 적용한 연구(arxiv 2601.13597)가 주목할 만합니다. 이 연구는 코딩 에이전트 도입 전후 시점에서 처치군(Treatment Group)과 대조군(Control Group)의 생산성 변화 차이를 비교하여, 에이전트 도입의 인과적 효과(Causal Effect)를 추정했습니다.
# DiD 추정의 개념적 구조 (간소화)
effect = (treat_after - treat_before) - (control_after - control_before)
# 단순 전후 비교의 편향(bias)을 제거하는 것이 핵심
결과적으로 코딩 에이전트 도입이 커밋 빈도, 이슈 해결 속도 등에서 통계적으로 유의미한 개선을 보였다고 보고합니다. 개인적으로 이 연구가 중요하다고 느끼는 이유는, 업계에서 흔히 인용되는 “체감 생산성 향상"을 넘어 인과 추론 프레임워크로 효과를 검증했다는 점입니다.
다만 SWE-bench 등 벤치마크 기반 평가의 한계도 함께 인식할 필요가 있습니다. SWE-EVO 같은 진화적 벤치마크 연구를 보면, 에이전트가 정형화된 태스크에서는 높은 성능을 보이지만 실제 프로덕션 환경의 복잡한 의존성과 암묵적 요구사항 앞에서는 성능이 크게 떨어질 수 있습니다. 실제로 써보면 벤치마크 점수와 실무 체감 사이의 간극은 여전합니다.
이러한 학술적 근거를 바탕으로, 3부에서는 AWS 환경에서 이 패러다임을 실제로 어떻게 적용할 수 있는지 구체적인 시나리오를 살펴보겠습니다.
5. [3부] AWS에서 실전 적용하기: Bedrock 기반 Self-Healing CI/CD
왜 AWS Bedrock인가
앞서 1부와 2부에서 살펴본 AI 에이전트의 자율적 코드 수정 능력을 실제 프로덕션 CI/CD 파이프라인에 적용하려면, 안정적인 인프라와 보안 체계가 뒷받침되어야 합니다. Amazon Bedrock은 Claude를 포함한 다양한 파운데이션 모델을 완전관리형으로 제공하며, IAM 기반 네이티브 인증을 통해 API 키 관리 부담 없이 엔터프라이즈 수준의 보안을 확보할 수 있습니다.
특히 2025년 출시된 Bedrock AgentCore는 에이전트의 세션 관리, 도구 호출, 메모리 유지 등을 플랫폼 차원에서 지원하여, 복잡한 멀티스텝 워크플로우를 별도 오케스트레이션 없이 구성할 수 있게 해줍니다.
Claude Agent SDK는 Bedrock과 네이티브로 연동됩니다. CLAUDE_CODE_USE_BEDROCK=1 환경 변수를 설정하면 SDK가 내부적으로 AWS 자격 증명 체인(환경 변수, IAM 역할, 인스턴스 프로파일)을 자동으로 활용하므로, CodeBuild나 Lambda 같은 AWS 서비스 내에서 추가 인증 설정 없이 바로 에이전트를 호출할 수 있습니다.
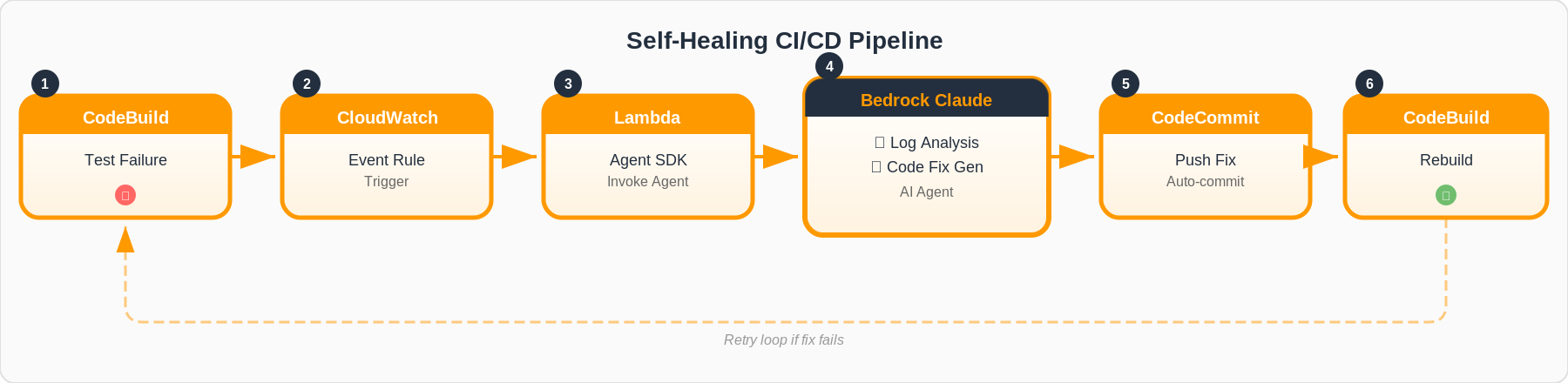
가상 시나리오: Self-Healing 빌드 파이프라인
다음과 같은 시나리오를 구성해 보겠습니다.
- CodeBuild에서 테스트 실패 발생:
pytest실행 중 테스트 케이스가 실패합니다. - Lambda 트리거: CloudWatch Events가 빌드 실패를 감지하고 Lambda 함수를 호출합니다.
- Bedrock 기반 에이전트 분석 및 수정: Lambda 내에서 Claude Agent SDK가 실패 로그를 분석하고, 소스 코드를 자동 수정합니다.
- 수정 커밋 및 재빌드: 에이전트가 수정된 코드를 커밋하고 CodeBuild를 재트리거합니다.
Elastic 엔지니어링 팀이 공개한 사례에서도 유사한 접근을 확인할 수 있습니다. Elastic은 CI 파이프라인에서 발생하는 flaky 테스트와 빌드 실패를 Claude 에이전트가 분석하고 수정하도록 구성하여, 엔지니어의 수동 개입 시간을 크게 줄였다고 보고했습니다.
코드 예시
buildspec.yml (CodeBuild 설정)
version: 0.2
phases:
install:
runtime-versions:
python: 3.12
commands:
- pip install pytest
build:
commands:
- echo "Running tests..."
- pytest tests/ --tb=long --junitxml=reports/result.xml 2>&1 | tee test_output.log
post_build:
commands:
- |
if [ "$CODEBUILD_BUILD_SUCCEEDING" = "0" ]; then
echo "Test failed. Uploading logs for self-healing agent."
aws s3 cp test_output.log s3://${ARTIFACT_BUCKET}/failed-logs/${CODEBUILD_BUILD_ID}.log
fi
artifacts:
files:
- reports/**/*
Lambda 핸들러 (Python, Agent SDK + Bedrock 연동)
import asyncio
import json
import os
import boto3
from claude_agent_sdk import query, ClaudeAgentOptions
s3 = boto3.client("s3")
codebuild = boto3.client("codebuild")
BUCKET = "my-cicd-artifact-bucket"
REPO_PATH = "/tmp/repo"
PROJECT_NAME = "my-app-build"
async def run_agent(prompt: str) -> list:
"""Bedrock 기반 Claude Agent를 실행하고 메시지를 수집합니다."""
messages = []
async for message in query(
prompt=prompt,
options=ClaudeAgentOptions(
model="global.anthropic.claude-sonnet-4-6",
max_turns=10,
allowed_tools=["Read", "Write", "Bash"],
cwd=REPO_PATH,
),
):
messages.append(message)
return messages
def handler(event, context):
build_id = event["detail"]["build-id"]
log_key = f"failed-logs/{build_id}.log"
# 1. 실패 로그 가져오기
log_obj = s3.get_object(Bucket=BUCKET, Key=log_key)
failure_log = log_obj["Body"].read().decode("utf-8")
# 2. Bedrock 네이티브 인증 활성화 (환경 변수)
os.environ["CLAUDE_CODE_USE_BEDROCK"] = "1"
os.environ["AWS_REGION"] = "us-east-1"
# 3. 에이전트에게 분석 및 수정 요청
prompt = (
"다음은 CI/CD 파이프라인에서 발생한 테스트 실패 로그입니다.\n\n"
+ failure_log + "\n\n"
+ "실패 원인을 분석하고, 해당 소스 코드를 수정해 주세요.\n"
+ "수정 후 pytest를 다시 실행하여 테스트가 통과하는지 확인해 주세요."
)
messages = asyncio.run(run_agent(prompt))
last = messages[-1] if messages else None
# 4. 수정 성공 시 재빌드 트리거
if last and last.type == "result":
codebuild.start_build(projectName=PROJECT_NAME)
return {"status": "self-healed", "build_triggered": True}
return {"status": "manual_review_needed", "messages": len(messages)}
위 코드에서 CLAUDE_CODE_USE_BEDROCK=1 환경 변수를 설정하면 Claude Agent SDK가 내부적으로 Bedrock을 모델 프로바이더로 사용합니다. Lambda에 부여된 IAM 실행 역할의 권한만으로 Bedrock API를 호출하므로, 별도의 API 키를 환경 변수에 저장하거나 Secrets Manager에서 가져올 필요가 없어 보안 관리가 한결 간결해집니다.
실제 프로덕션 적용 시에는 에이전트의 수정 범위를 제한하는 가드레일 설정, 자동 수정 횟수 상한(무한 루프 방지), 그리고 수정 내역에 대한 사람의 최종 승인 단계를 반드시 포함하시기를 권장합니다. Bedrock AgentCore의 세션 관리 기능을 활용하면 이러한 멀티스텝 승인 워크플로우도 체계적으로 구현할 수 있습니다.
6. 마치며
이번 포스트에서는 AI 코딩 에이전트의 최신 트렌드부터 학술적 근거, 그리고 AWS 환경에서의 실전 적용까지 세 단계에 걸쳐 살펴보았습니다.
SWE-bench에서 70%를 넘나드는 벤치마크 수치나, ICSE와 arXiv에 발표된 연구 결과들은 분명 인상적입니다. 하지만 그 이면에는 환각으로 인한 잘못된 수정, 보안 취약점 유입, 그리고 개발자의 코드 이해도 저하라는 현실적인 위험이 함께 존재합니다.
결국 핵심은 “자동화할 수 있는 것"과 “사람이 판단해야 하는 것"의 경계를 명확히 설정하는 데 있습니다. CI/CD 파이프라인의 반복적인 실패 수정처럼 패턴이 명확한 영역에서 에이전트를 활용하되, 아키텍처 결정이나 보안 민감 코드에는 반드시 사람의 리뷰를 거치는 구조가 바람직합니다.
AI 에이전트는 개발자를 대체하는 도구가 아니라, 개발자가 더 중요한 문제에 집중할 수 있도록 돕는 동료입니다. 이 균형 감각을 유지하면서 기술을 도입하신다면, 팀의 생산성과 코드 품질 모두를 한 단계 끌어올릴 수 있을 것입니다.
References
AI Agentic Programming: A Survey of Techniques, Challenges, and Opportunities, 논문, 2025 https://arxiv.org/abs/2508.11126 Agentic Programming 패러다임의 정의, 기법 분류, 도전과제를 포괄적으로 정리한 서베이 논문으로, 2부에서 LLM 기반 에이전트가 소프트웨어 개발 워크플로를 어떻게 재편하는지에 대한 학술적 근거로 활용.
A Survey on Code Generation with LLM-based Agents, 논문, 2025 https://arxiv.org/abs/2508.00083 LLM 기반 코드 생성 에이전트의 아키텍처, 벤치마크(SWE-bench 등), 한계(SWE-EVO 포함)를 체계적으로 분석한 서베이로, 2부에서 코드 생성 에이전트의 현재 수준과 실효성 논의의 핵심 참고 자료.
The OpenHands Software Agent SDK, 논문, 2025 https://arxiv.org/abs/2511.03690 OpenHands SDK의 설계 철학과 프로그래매틱 에이전트 활용 방식을 소개한 논문으로, 1부에서 Interactive → Non-interactive → Programmatic 진화 흐름을 설명하고 Agent SDK 엔진화 트렌드를 뒷받침하는 데 직접 인용.
AI IDEs or Autonomous Agents? Measuring the Impact of Coding Agents on Software Development, 논문, 2025 https://arxiv.org/abs/2601.13597 코딩 에이전트의 실제 개발 생산성 영향을 Difference-in-Differences(DiD) 기법으로 측정한 실증 연구로, 2부에서 에이전트 도입의 실효성과 한계를 논증하는 핵심 근거.
Claude Agent SDK, Anthropic 공식 문서 https://platform.claude.com/docs/en/agent-sdk/overview Claude Agent SDK의 프로그래매틱 사용법(서브프로세스 호출, JSON 스트리밍 출력 등)을 설명하는 공식 문서로, 1부의 Agent SDK/CLI 엔진화 흐름과 3부의 Bedrock 연동 시나리오에서 핵심 참조.
Amazon Bedrock 개발자 가이드, AWS 공식 문서 https://docs.aws.amazon.com/bedrock/latest/userguide/what-is-bedrock.html Amazon Bedrock의 모델 호출, 인증, 에이전트 기능을 설명하는 공식 문서로, 3부에서 Bedrock 인증을 통한 Claude Agent SDK 네이티브 연동 아키텍처를 구성하는 데 활용.
AWS CodePipeline 사용자 가이드, AWS 공식 문서 https://docs.aws.amazon.com/codepipeline/latest/userguide/welcome.html CodePipeline의 파이프라인 구성 및 액션 통합 방법을 설명하는 공식 문서로, 3부에서 테스트 실패 → Bedrock Agent 자동 수정 → 재빌드로 이어지는 CI/CD self-healing 시나리오 설계에 활용.