1. 왜 지금 동물 AI인가
테마파크와 동물원, 야생 보전 현장에서 동물 개체 단위의 행동 모니터링 수요가 빠르게 늘고 있습니다. 동물 복지 규제가 강화되고 멸종위기종 보전 프로젝트가 확대되면서, “지금 이 개체가 어디서 무엇을 하고 있는가"를 실시간으로 파악해야 하는 상황이 일상이 되었습니다.
하지만 사육사와 현장 연구자의 수작업 관찰(Manual Observation)에는 분명한 병목이 있습니다. 야행성 동물의 심야 행동이나 넓은 사파리 구역의 동시 모니터링은 인력만으로 물리적으로 불가능합니다. 같은 행동을 두고도 관찰자마다 기록이 달라지는 관찰자 간 변이(Inter-observer Variability) 문제도 있고, 개체 수가 수십에서 수백으로 늘어나면 개체 식별과 행동 분류를 동시에 수행하는 것 자체가 비현실적입니다. Nature Communications에 게재된 동물 행동 자동 분석 서베이 논문에서도 이러한 수작업 한계를 지적하며 딥러닝 기반 자동화의 필요성을 강조한 바 있습니다.
현장에서 자주 나오는 이야기가 “카메라는 이미 충분히 달려 있는데, 영상을 볼 사람이 없다"는 것입니다. 인프라는 갖춰져 있지만, 영상에서 의미 있는 정보를 자동으로 뽑아내는 AI 파이프라인이 빠져 있는 셈입니다.
2025~2026년에 걸쳐 이 퍼즐의 핵심 조각들이 동시에 성숙기에 접어들었습니다. 단일 프레임만으로 행동을 인식하는 YORU, 종(Species)에 무관하게 개체를 구별하는 MegaDescriptor, 대규모 다개체 트래킹의 정확도를 끌어올린 idtracker.ai가 대표적입니다. 셋을 결합하면 “누가(Re-ID), 어디서(Tracking), 무엇을(Behavior)"이라는 완전한 질문에 답할 수 있게 됩니다.
2. 객체 탐지와 행동 인식: YORU
기존 파이프라인의 문제
전통적인 동물 행동 인식은 두 단계를 거칩니다. 먼저 pose estimation으로 관절 좌표를 추출하고, 이를 시계열 분류 모델에 넣어 행동을 판별하는 방식입니다. 문제는 오류 전파(error propagation)입니다. 골격 추정이 틀리면 행동 분류도 틀리고, 종마다 skeleton model을 새로 정의해야 하므로 확장성도 떨어집니다.
YORU의 접근
2026년 2월 Science Advances에 발표된 YORU(You Only Recognize Units of behavior)는 이 2단계를 과감히 걷어냅니다. 단일 프레임 이미지만으로 동물의 행동 단위(unit of behavior)를 직접 인식하며, body-part tracking이 전혀 필요하지 않습니다. 객체 탐지(object detection)와 행동 분류(action classification)를 하나의 네트워크에서 동시에 처리하는 구조입니다.
논문에서 보고된 주요 성과는 다음과 같습니다:
- 정확도: 90~98% (종과 행동 범주에 따라 차이)
- 속도: 기존 multi-stage 파이프라인 대비 약 30% 빠른 처리
- 각 프레임을 독립적으로 처리하므로 실시간 스트리밍 환경에 적합
실무 관점
YORU의 가장 큰 매력은 새로운 종으로의 확장 속도입니다. 사전에 골격 모델을 정의할 필요가 없으니, 테마파크나 동물원처럼 수십 종을 동시에 관리하는 환경에서 종별 커스터마이징 부담이 크게 줄어듭니다. 프레임 단위 독립 추론이라는 특성 덕분에 영상 스트림의 중간 프레임이 유실되더라도 인식 결과에 영향이 없다는 점도 엣지 환경에서 실용적입니다.
# YORU 스타일 단일 프레임 추론 (개념 코드)
from yoru import YORUDetector
model = YORUDetector.load("yoru_zoo_v2.pt")
frame = capture_frame(camera_id="habitat_cam_01")
detections = model.predict(frame, conf_threshold=0.85)
for det in detections:
print(f"종: {det.species}, 행동: {det.behavior}, "
f"신뢰도: {det.confidence:.2f}, bbox: {det.bbox}")
다만 YORU는 “지금 이 순간 무엇을 하는가"에 특화되어 있습니다. “저 개체가 어제 본 그 개체인가?“라는 개체 식별 문제는 별도의 접근이 필요합니다.
3. 개체 Re-ID: MegaDescriptor
동물 Re-ID가 어려운 이유
사람의 re-identification은 옷, 체형, 걸음걸이 등 단서가 풍부합니다. 동물은 다릅니다. 같은 종 내 외형 차이가 미묘하고, 계절에 따라 털 색이 바뀌기도 하며, 자세나 조명 변화에 따른 외형 변동이 큽니다. 종마다 특성이 달라서 “호랑이용 Re-ID 모델"이 “펭귄"에는 전혀 작동하지 않는 문제도 있었습니다.
MegaDescriptor의 접근
CVPR 2025 Workshop(FGVC)에서 발표된 MegaDescriptor는 이 문제를 파운데이션 모델(Foundation Model) 방식으로 해결합니다. 50개 이상의 야생동물 데이터셋에서 사전 학습하여, 별도의 종별 파인튜닝 없이도 다양한 종에서 개체 구별이 가능한 임베딩을 생성합니다.
핵심 성과를 정리하면:
- 종 무관(Species-agnostic): 학습에 포함되지 않은 새로운 종에서도 zero-shot Re-ID 가능
- 기존 모델 압도: 동일 벤치마크에서 CLIP, DINOv2 기반 접근 대비 우수한 성능
- 경량 변형 제공: ViT-Tiny 기반 MegaDescriptor-T-224가 Hugging Face에 공개되어 있어 엣지 배포에 유리
함께 발표된 WildlifeReID-10k 데이터셋은 10,000개체 이상의 야생동물을 포함하며, Re-ID 모델의 표준 벤치마크로 자리 잡고 있습니다.
실무 활용
MegaDescriptor의 실질적 가치는 “신규 종 도입 시 파인튜닝 없이 바로 테스트할 수 있다"는 점에 있습니다. 동물원에 새로운 종이 들어왔을 때, 기존 모델을 그대로 돌려서 개체 구별이 되는지 먼저 확인하고, 필요한 경우에만 소량의 데이터로 파인튜닝하는 접근을 설계할 수 있습니다.
# MegaDescriptor를 활용한 개체 임베딩 추출 (개념 코드)
from transformers import AutoModel, AutoProcessor
import torch
model = AutoModel.from_pretrained("BVRA/MegaDescriptor-T-224")
processor = AutoProcessor.from_pretrained("BVRA/MegaDescriptor-T-224")
# 두 이미지의 임베딩 비교로 동일 개체 여부 판단
img_a = processor(images=load_image("panda_cam1.jpg"), return_tensors="pt")
img_b = processor(images=load_image("panda_cam2.jpg"), return_tensors="pt")
emb_a = model(**img_a).last_hidden_state[:, 0]
emb_b = model(**img_b).last_hidden_state[:, 0]
similarity = torch.cosine_similarity(emb_a, emb_b)
print(f"개체 동일 확률: {similarity.item():.3f}")
개체를 식별했다면 다음 과제는 “이 개체들이 시간에 따라 어떻게 이동하는가”, 즉 트래킹입니다.
4. 다개체 트래킹: idtracker.ai
기존 트래킹의 한계
전통적인 다개체 트래킹(Multi-Object Tracking, MOT)은 프레임 간 외형 매칭이나 움직임 예측에 의존합니다. 동물이 서로 겹치거나(occlusion) 빠르게 이동할 때 ID 스왑이 빈번하게 발생하는 것이 고질적인 문제입니다. 특히 물고기 떼나 곤충 군집처럼 외형이 거의 동일한 대규모 집단에서는 기존 접근이 사실상 무용지물이었습니다.
idtracker.ai의 표현 학습 기반 접근
eLife에 발표된 새로운 idtracker.ai는 표현 학습(representation learning)을 핵심 메커니즘으로 사용합니다. 각 개체의 고유한 시각적 특징을 학습하여, 겹침이나 빠른 이동 상황에서도 개체 ID를 유지하는 방식입니다.
보고된 핵심 수치는 놀랍습니다:
- 99.92% 정확도: 대규모 집단(수십 개체)에서도 거의 완벽한 ID 유지
- DeepLabCut, SLEAP 연동: 트래킹 결과를 기존 pose estimation 프레임워크에 직접 연결 가능
- 별도의 마커나 태그 없이 순수 영상만으로 작동
YORU, MegaDescriptor와의 결합
세 모델의 역할을 정리하면 이렇습니다:
| 모델 | 역할 | 핵심 능력 |
|---|---|---|
| YORU | “무엇을 하는가” | 단일 프레임 행동 인식 |
| MegaDescriptor | “누구인가” | 종 무관 개체 식별 |
| idtracker.ai | “어디로 이동하는가” | 다개체 궤적 추적 |
idtracker.ai가 프레임 간 궤적을 추적하고, MegaDescriptor가 장기간(일, 주 단위) 개체 동일성을 보장하며, YORU가 각 시점의 행동을 분류합니다. 이 조합으로 “A 개체가 오전 10시에 먹이 활동을 했고, 오후 2시에 수면 구역으로 이동했다"는 수준의 자동 리포팅이 가능해집니다.
5. AWS 위 구현 아키텍처
이론적으로 좋은 모델이 있어도, 실제 현장에 배포하려면 학습부터 엣지 추론까지 이어지는 파이프라인이 필요합니다. 2026년 2월 기준 AWS에서 사용 가능한 서비스들로 아키텍처를 설계해 보겠습니다.
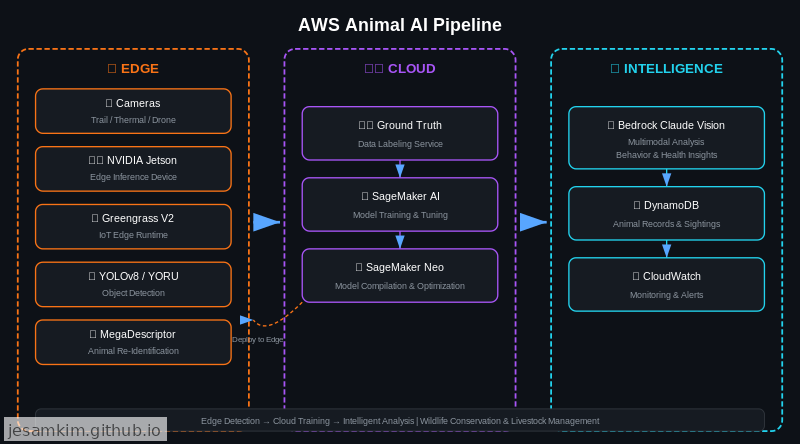
데이터 라벨링: SageMaker Ground Truth
동물 이미지 라벨링은 전문 지식이 필요한 작업입니다. 일반 크라우드 워커는 종이나 행동을 구별하기 어렵기 때문에, SageMaker Ground Truth의 프라이빗 워크포스(Private Workforce) 기능으로 사육사나 연구자를 라벨러로 참여시킬 수 있습니다. 바운딩 박스, 행동 라벨, 개체 ID를 동시에 어노테이션하는 커스텀 템플릿을 구성하면 됩니다.
모델 학습과 파인튜닝: SageMaker AI
SageMaker AI에서 YORU와 MegaDescriptor를 학습하거나 파인튜닝합니다. MegaDescriptor의 경우 Hugging Face 모델 허브에 공개된 가중치를 SageMaker JumpStart 커스텀 모델로 가져와 시작할 수 있습니다. 학습 인스턴스는 ml.g5.xlarge(NVIDIA A10G) 정도면 ViT-Tiny 기반 파인튜닝에 충분하고, 대규모 학습에는 ml.p4d.24xlarge(A100)를 활용합니다.
모델 최적화: SageMaker Neo
학습된 모델을 Jetson 등 엣지 디바이스에서 실행하려면 최적화가 필수입니다. SageMaker Neo로 모델을 컴파일하면 타겟 하드웨어(Jetson Xavier, Orin 등)에 맞는 최적화된 바이너리를 생성할 수 있습니다. TensorRT 백엔드를 활용하여 추론 지연 시간을 줄이고 처리량을 높입니다.
엣지 추론: IoT Greengrass V2
현장의 카메라와 연결된 엣지 디바이스(NVIDIA Jetson 시리즈)에 IoT Greengrass V2를 설치하고, SageMaker Neo로 최적화된 모델을 컴포넌트로 배포합니다. Greengrass의 컴포넌트 관리 기능으로 모델 버전 업데이트를 OTA(Over-the-Air)로 처리할 수 있어, 현장에 직접 가지 않고도 모델을 갱신할 수 있습니다.
# Greengrass V2 컴포넌트 레시피 예시 (YAML)
# recipe.yaml
RecipeFormatVersion: "2020-01-25"
ComponentName: "com.zoo.animal-detector"
ComponentVersion: "2.1.0"
Manifests:
- Platform:
os: linux
architecture: aarch64
Artifacts:
- URI: "s3://zoo-models/yoru-neo-jetson/v2.1.0/model.tar.gz"
Lifecycle:
Install: "pip3 install -r {artifacts:path}/requirements.txt"
Run: "python3 {artifacts:path}/inference.py --model {artifacts:path}/model"
행동 해석: Amazon Bedrock Claude Sonnet 4.6 Vision
YORU가 “foraging”, “resting” 같은 행동 라벨을 출력하지만, 실제 운영에서는 더 풍부한 맥락 해석이 필요합니다. Amazon Bedrock의 Claude Sonnet 4.6 Vision을 활용하면, 탐지 결과와 원본 이미지를 함께 입력하여 “이 행동이 정상 범위인지”, “수의사 관심이 필요한 패턴인지” 같은 고차원 판단을 자연어로 받을 수 있습니다.
예를 들어, YORU가 “abnormal_posture"를 탐지하면 해당 프레임을 Bedrock Claude Vision으로 보내 상세 분석을 요청하고, 판단 결과에 따라 CloudWatch 알람을 트리거하는 방식입니다.
💡 빠른 프로토타이핑이 필요한 경우, Amazon Rekognition Custom Labels로 소규모 이미지 분류 모델을 먼저 만들어 컨셉을 검증한 뒤, 본격적인 커스텀 모델로 전환하는 전략도 있습니다.
6. 실전 고려사항
모델과 아키텍처가 갖춰졌더라도, 실제 배포 과정에서 만나는 현실적인 과제들이 있습니다.
데이터 라벨링
동물 행동 라벨링에는 도메인 전문가가 필요합니다. “foraging"과 “exploring"의 경계가 모호한 경우가 많아서, 라벨링 가이드라인을 세밀하게 정의하고 라벨러 간 일치도(Inter-annotator Agreement)를 측정하는 과정이 필수입니다. 일반적으로 이 단계에 전체 프로젝트 시간의 상당 부분이 소요되는 것으로 알려져 있습니다.
야간과 가림(Occlusion)
동물원의 실내 전시관은 조명이 어둡고, 야생 환경에서는 야간 촬영이 필수입니다. 적외선(IR) 카메라 영상에서는 동물의 색상 정보가 사라지므로, Re-ID 모델의 성능이 크게 저하될 수 있습니다. MegaDescriptor를 IR 이미지로 파인튜닝하거나, 체형과 움직임 패턴에 더 의존하는 보조 모델을 병행하는 전략이 필요합니다. 나뭇잎이나 바위에 가려지는 부분 가림(partial occlusion)은 idtracker.ai의 표현 학습이 어느 정도 대응하지만, 완전 가림(full occlusion) 상황에서는 Re-ID를 통한 재연결이 불가피합니다.
실시간 요건
테마파크 환경에서 “이상 행동 감지 후 30초 이내 알림"같은 SLA가 걸리면, 엣지에서의 추론 지연 시간이 핵심입니다. YORU의 단일 프레임 구조는 이 요건에 유리하지만, Re-ID 임베딩 비교까지 포함하면 Jetson Orin 급 하드웨어가 필요할 수 있습니다. 모델 경량화(SageMaker Neo)와 추론 배치 크기 조절로 지연 시간과 정확도 사이의 균형을 찾아야 합니다.
비용
GPU 인스턴스 학습 비용, 엣지 디바이스 구매 비용, Bedrock API 호출 비용이 주요 비용 항목입니다. 학습은 Spot 인스턴스를 활용하면 온디맨드 대비 상당한 비용 절감이 가능하고, Bedrock Claude Vision 호출은 모든 프레임에 보내는 것이 아니라 이상 행동 탐지 시에만 트리거하는 방식으로 비용을 통제할 수 있습니다. 엣지 디바이스는 초기 투자가 필요하지만, 클라우드로 모든 영상을 전송하는 것 대비 장기적으로 네트워크 비용과 지연 시간 모두에서 유리합니다.
결국 동물 AI 파이프라인은 단일 모델의 성능보다 “탐지, 식별, 트래킹을 어떻게 연결하고, 어디서 추론하며, 어떻게 운영할 것인가"라는 시스템 설계의 문제입니다. YORU, MegaDescriptor, idtracker.ai라는 2025~2026년의 최신 연구 성과를 AWS 인프라 위에서 엮으면, 과거에는 수십 명의 인력이 필요했던 동물 모니터링을 자동화할 수 있는 현실적인 기반이 마련됩니다.
References
Hsu, A. I. et al. “YORU: You Only Recognize Units of behavior — single-frame action recognition for animal behaviors.” Science Advances (2026년 2월). https://www.science.org/doi/10.1126/sciadv.adw2109
Čermák, V. et al. “MegaDescriptor: Foundation Model for Fine-Grained Wildlife Re-Identification.” arXiv preprint (2023), CVPR 2025 Workshop on FGVC. https://arxiv.org/abs/2311.09118
BVRA. “MegaDescriptor-T-224.” Hugging Face Model Hub. https://huggingface.co/BVRA/MegaDescriptor-T-224
Romero-Ferrero, F. et al. “New idtracker.ai: tracking all individuals in large collectives.” eLife Reviewed Preprint (2025–2026). https://elifesciences.org/reviewed-preprints/107602
Adam, L. et al. “WildlifeReID-10k: Wildlife re-identification dataset with 10k individual animals.” CVPR 2025 Workshop on FGVC. https://openaccess.thecvf.com/content/CVPR2025W/FGVC/papers/Adam_WildlifeReID-10k_Wildlife_re-identification_dataset_with_10k_individual_animals_CVPRW_2025_paper.pdf
Pereira, T. D. et al. “Sleap: A deep learning system for multi-animal pose tracking.” Nature Methods (2022). 및 Tuia, D. et al. “Perspectives in machine learning for wildlife conservation.” Nature Communications 13, 792 (2022). https://www.nature.com/articles/s41467-022-27980-y
AWS. “Run machine learning inference on AWS IoT Greengrass V2.” AWS IoT Greengrass V2 Developer Guide. https://docs.aws.amazon.com/greengrass/v2/developerguide/perform-machine-learning-inference.html
AWS. “Build a generative AI image description application with Anthropic’s Claude on Amazon Bedrock.” AWS Machine Learning Blog. https://aws.amazon.com/blogs/machine-learning/build-a-generative-ai-image-description-application-with-anthropics-claude-3-5-sonnet-on-amazon-bedrock-and-aws-cdk/