왜 LLM 출력 제어가 프로덕션의 핵심 과제인가
프로덕션 환경에서 LLM 기반 애플리케이션을 운영해 보신 분이라면, 프롬프트 엔지니어링(Prompt Engineering)만으로는 출력 품질을 안정적으로 보장하기 어렵다는 사실을 체감하셨을 것입니다.
“JSON으로 응답해 주세요"라고 명시했는데도 중괄호가 빠지거나, 고객 응대 챗봇이 갑자기 반말로 전환되거나, 민감한 콘텐츠가 필터 없이 그대로 노출되는 상황. 실제로 써보면 이런 문제는 예외가 아니라 일상입니다. 특히 하루 수만 건의 요청을 처리하는 서비스에서는 낮은 확률의 실패도 곧 대규모 장애로 이어집니다.
이런 문제를 체계적으로 해결하기 위해, 출력 제어 패턴을 크게 두 가지 축으로 나눠볼 수 있습니다.
첫 번째는 디코딩 타임 개입(Decode-time Intervention)입니다. 토큰이 생성되는 바로 그 순간에 확률 분포를 조작해서, 애초에 잘못된 출력이 만들어지지 않도록 원천 차단하는 방식입니다. Logits Masking과 Grammar Constraint가 여기에 해당합니다.
두 번째는 생성 후 변환(Post-generation Transformation)입니다. LLM이 일단 출력을 생성한 뒤, 별도의 파이프라인 단계에서 톤을 교정하거나 유해 요소를 제거하는 접근입니다. Style Transfer, Reverse Neutralization, Content Optimization이 이 범주에 속합니다.
# 출력 제어 패턴의 적용 지점을 개념적으로 표현하면:
pipeline = {
"1_prompt": "입력 구성",
"2_decoding": ["Logits Masking", "Grammar Constraint"], # 디코딩 타임
"3_raw_output": "LLM 원본 출력",
"4_post_process": ["Style Transfer", "Reverse Neutralization", # 생성 후 변환
"Content Optimization"],
"5_final_output": "최종 사용자 응답"
}

개인적으로 이 두 축의 구분이 중요하다고 생각하는 이유는, 각 패턴의 트레이드오프가 근본적으로 다르기 때문입니다. 디코딩 타임 개입은 지연 시간(Latency) 증가가 미미하지만 모델 내부 접근이 필요합니다. 반면 생성 후 변환은 모델에 구애받지 않는 대신 추가 처리 비용이 발생합니다. 프로덕션에서는 이 다섯 가지 패턴을 상황에 맞게 조합하는 것이 관건이며, 이어지는 섹션에서 각 패턴의 구현 방법과 실전 적용 전략을 하나씩 살펴보겠습니다.
패턴 1 — Logits Masking: 디코딩 단계에서 토큰 확률 직접 제어
앞서 살펴본 출력 제어 문제를 해결하는 가장 직접적인 방법은, 모델이 다음 토큰을 선택하는 바로 그 순간에 개입하는 것입니다. 이것이 Logits Masking 패턴의 핵심 아이디어입니다.
원리: softmax 직전, 확률 분포를 직접 조작하기
LLM은 매 디코딩 스텝(decoding step)마다 전체 어휘(vocabulary)에 대한 logits 벡터를 생성하고, 이를 softmax에 통과시켜 확률 분포로 변환합니다. Logits Masking은 이 softmax 이전 단계에서 특정 토큰의 logit 값을 -inf(음의 무한대)로 설정하여, 해당 토큰의 선택 확률을 사실상 0으로 만드는 방식입니다.
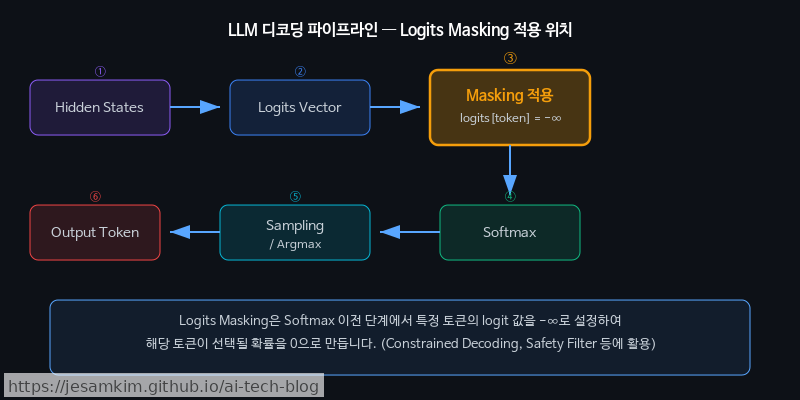
활용 사례: 하드 제약이 필요한 곳
이 패턴은 “절대로 생성되면 안 되는” 하드 제약(hard constraint) 시나리오에서 특히 유용합니다.
- 금칙어 필터링: 욕설, 브랜드명, 민감 정보 관련 토큰을 원천 차단
- 언어 제한: 한국어 전용 서비스에서 영어·일본어 토큰을 마스킹하여 단일 언어 출력 보장
- 포맷 강제: 숫자만 허용하거나 특수문자를 제한하는 등 출력 형식 통제
구현: HuggingFace LogitsProcessor 활용
HuggingFace Transformers에서는 LogitsProcessor를 상속하여 간결하게 구현할 수 있습니다.
import torch
from transformers import LogitsProcessor, AutoModelForCausalLM, AutoTokenizer
class BanTokensProcessor(LogitsProcessor):
def __init__(self, tokenizer, banned_words: list[str]):
self.banned_ids = set()
for word in banned_words:
token_ids = tokenizer.encode(word, add_special_tokens=False)
self.banned_ids.update(token_ids)
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
scores[:, list(self.banned_ids)] = float("-inf")
return scores
tokenizer = AutoTokenizer.from_pretrained("your-model")
model = AutoModelForCausalLM.from_pretrained("your-model")
processor = BanTokensProcessor(tokenizer, banned_words=["비밀번호", "password"])
outputs = model.generate(
tokenizer("사용자 정보:", return_tensors="pt").input_ids,
logits_processor=[processor],
max_new_tokens=128,
)
vLLM에서는 --guided-decoding-backend 옵션을 통해 유사한 제어를 서빙 레벨에서 지원하므로, 프로덕션 배포 시에도 비교적 수월하게 적용할 수 있습니다.
고려사항: 단순하지만 만능은 아닙니다
개인적으로 Logits Masking을 적용할 때 가장 주의해야 할 부분은 서브워드 토크나이제이션(subword tokenization) 문제입니다. “비밀번호"라는 단어가 ["비밀", "번호"]로 분리될 수 있기 때문에, 단순 단어 단위 매핑만으로는 완벽한 차단이 어렵습니다. 모든 가능한 토큰 조합을 사전에 열거하거나, n-gram 기반 후처리를 병행해야 합니다.
vocabulary 크기가 큰 모델(예: 128K+ 토큰)에서는 매 스텝마다 마스킹 연산이 추가되므로, 배치 크기가 클수록 성능 오버헤드가 체감될 수 있습니다. 실제로 써보면 단일 요청 수준에서는 거의 무시할 만하지만, 높은 동시성(concurrency) 환경에서는 프로파일링을 통해 검증해 보는 편이 좋습니다.
결국 Logits Masking은 “이 토큰은 절대 안 된다"는 확실한 제약에는 최적이지만, “JSON 형식으로 출력하라"와 같은 구조적 제약까지 다루기는 어렵습니다. 이런 구조적 제약을 해결하는 것이 다음에 다룰 Grammar Constraint 패턴입니다.
패턴 2 — Grammar Constraint: 형식적 문법으로 구조화된 출력 보장
Logits Masking이 개별 토큰 수준의 제어라면, Grammar Constraint는 한 단계 위에서 토큰 시퀀스 전체의 구조적 유효성을 보장하는 패턴입니다.
원리: Constrained Decoding
핵심 아이디어는 간단합니다. CFG(Context-Free Grammar)나 JSON Schema 같은 형식적 문법(Formal Grammar)을 정의해두고, 디코딩의 매 스텝마다 현재 문법 상태에서 유효한 토큰만 샘플링 후보로 허용하는 것입니다. 예를 들어 JSON 출력을 기대하는 상황에서 { 다음에 올 수 있는 토큰은 " (키 시작) 또는 } (빈 객체 종료)뿐이므로, 나머지 토큰의 확률을 0으로 마스킹합니다. 패턴 1의 Logits Masking을 문법 규칙에 따라 자동으로, 매 스텝 동적으로 적용하는 셈입니다.
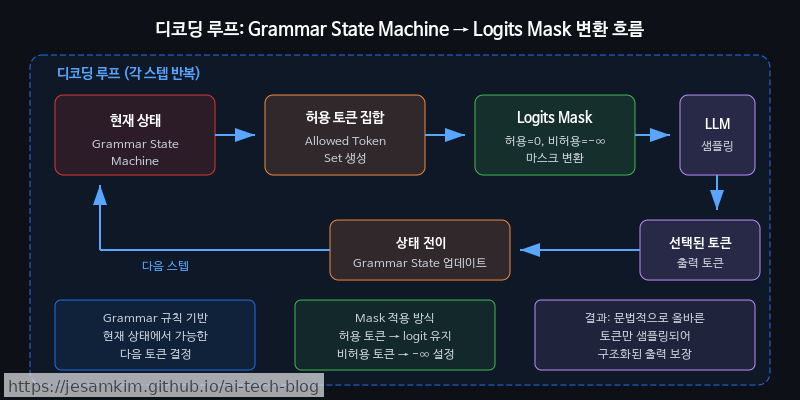
주요 도구 비교
| 도구 | 접근 방식 | 특징 |
|---|---|---|
| Outlines | 정규식/JSON Schema → FSM 변환 | 임의의 HuggingFace 모델에 적용 가능, 인덱스 프리컴파일로 성능 최적화 |
| Guidance (Microsoft) | 템플릿 기반 인터리빙 생성 | 자유 텍스트와 구조화 영역을 하나의 템플릿에서 혼합 가능 |
| llama.cpp GBNF | BNF 문법 파일 직접 정의 | C++ 레벨 통합으로 오버헤드가 작음 |
| Instructor | Pydantic 모델 → API 레벨 강제 | OpenAI 등 API 기반 서비스에서 바로 활용 가능, 내부적으로 재시도 로직 포함 |
실제로 써보면, 로컬 모델 기반이라면 Outlines나 GBNF가, API 기반이라면 Instructor가 가장 빠르게 프로덕션에 적용할 수 있는 선택지입니다.
# Outlines를 활용한 JSON Schema 기반 구조화 출력
import outlines
model = outlines.models.transformers("mistralai/Mistral-7B-v0.1")
schema = {
"type": "object",
"properties": {
"sentiment": {"type": "string", "enum": ["positive", "negative", "neutral"]},
"confidence": {"type": "number", "minimum": 0, "maximum": 1},
"keywords": {"type": "array", "items": {"type": "string"}, "maxItems": 5}
},
"required": ["sentiment", "confidence", "keywords"]
}
generator = outlines.generate.json(model, schema)
result = generator("Analyze the sentiment of: 'This product is amazing!'")
# 반환값은 항상 스키마를 만족하는 유효한 dict입니다
프로덕션 적용 팁
Latency 최소화: Grammar Constraint는 매 디코딩 스텝마다 문법 상태를 체크하므로 오버헤드가 발생합니다. Outlines의 경우 FSM 인덱스를 사전 컴파일(pre-compile)해두면 런타임 비용을 크게 줄일 수 있습니다. 스키마가 복잡할수록 상태 공간이 급격히 커지므로, 가능하면 출력 스키마를 평탄하게(flat) 유지하는 것이 좋습니다.
스키마 설계 시 참고할 점을 몇 가지 정리하면 다음과 같습니다.
enum을 적극 활용하여 허용 값 범위를 명시적으로 제한합니다.- 깊은 중첩(nested) 구조보다는 최상위 레벨에 필드를 배치합니다.
additionalProperties: false를 설정하여 예상치 못한 필드 생성을 차단합니다.- 개인적으로는 optional 필드를 최소화하는 편을 권합니다. 모델이 optional 필드의 포함 여부를 “판단"하는 과정에서 출력 품질이 불안정해지는 경우가 있기 때문입니다.
SQL이나 XML처럼 JSON보다 복잡한 문법이 필요한 경우도 있습니다. 이때는 GBNF 문법을 직접 작성하거나, 해당 언어의 서브셋(subset)만 허용하는 축소된 문법을 정의하는 방식이 실용적입니다. 전체 SQL 문법을 지원하려 하기보다, 프로덕션에서 실제로 필요한 쿼리 패턴만 커버하는 문법을 설계하는 편이 안정성과 성능 모두에서 유리합니다.
패턴 3 — Style Transfer: 톤·문체·페르소나의 일관성 제어
앞선 두 패턴이 무엇을 출력할 수 있는가(토큰/구조)를 제어했다면, Style Transfer는 어떻게 말하는가를 제어하는 패턴입니다. 핵심 아이디어는 단순합니다. 콘텐츠(Content)의 의미는 그대로 보존하면서, 톤(Tone)·격식 수준(Formality)·페르소나(Persona)만 변환하는 것입니다.
왜 프로덕션에서 중요한가
고객 응대 챗봇이 어떤 질문에는 반말로, 어떤 질문에는 존댓말로 답한다면 브랜드 신뢰도는 금방 무너집니다. 법률 문서 요약 서비스가 캐주얼한 구어체를 섞어 쓴다면 서비스 자체의 신뢰성이 의심받게 됩니다. Style Transfer 패턴은 이런 문체 일관성(Stylistic Consistency) 문제를 체계적으로 다룹니다.
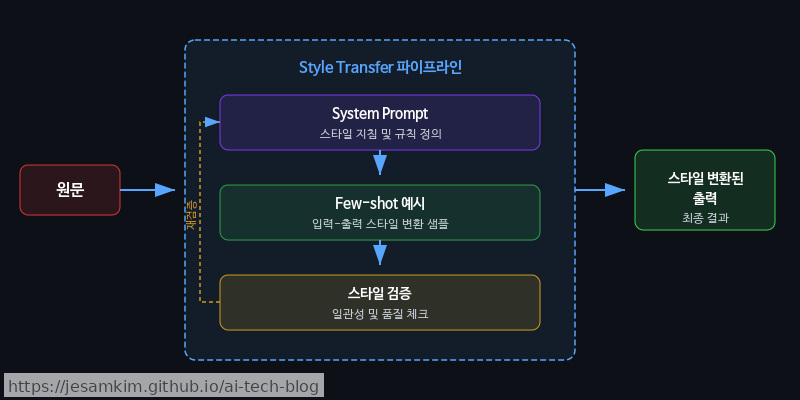
접근 방식
1) System Prompt 기반 — 가장 빠르게 적용할 수 있지만, 긴 대화에서 스타일 드리프트(Style Drift)가 발생하기 쉽습니다.
Few-shot 예시 기반 — 원하는 스타일의 입출력 쌍을 프롬프트에 포함시켜 모델이 패턴을 모방하도록 유도합니다.
Fine-tuning 기반 — 가장 안정적이지만 데이터 구축 비용이 큽니다. 스타일 쌍(pair) 데이터셋으로 모델 자체를 조정합니다.
실제로 써보면, 프로덕션 초기에는 System Prompt + Few-shot 조합으로 시작하고, 스타일 일관성이 비즈니스 크리티컬한 영역에서 Fine-tuning으로 전환하는 흐름이 가장 현실적입니다.
구현 예시: Few-shot 기반 톤 변환
def build_style_transfer_prompt(content: str, target_style: str, examples: list[dict]) -> list[dict]:
"""콘텐츠는 보존하고 스타일만 변환하는 프롬프트 생성"""
messages = [
{
"role": "system",
"content": (
f"당신은 텍스트 스타일 변환 전문가입니다. "
f"원문의 의미와 정보를 100% 보존하면서, "
f"'{target_style}' 스타일로만 변환하세요. "
f"정보를 추가하거나 삭제하지 마세요."
),
}
]
# Few-shot 예시 주입
for ex in examples:
messages.append({"role": "user", "content": ex["input"]})
messages.append({"role": "assistant", "content": ex["output"]})
messages.append({"role": "user", "content": content})
return messages
# 사용 예: 캐주얼 → 비즈니스 격식체 변환
examples = [
{
"input": "이 기능 좀 별로인데, 고쳐주면 안 될까요?",
"output": "해당 기능에 대해 개선 요청을 드립니다. 검토 부탁드리겠습니다.",
},
{
"input": "서버 또 터졌어요, 빨리 확인해주세요.",
"output": "서버 장애가 재발한 것으로 확인됩니다. 긴급 점검을 요청드립니다.",
},
]
prompt = build_style_transfer_prompt(
content="배포 일정 좀 뒤로 미뤄야 할 것 같아요, QA가 아직 안 끝났거든요.",
target_style="비즈니스 격식체",
examples=examples,
)
스타일 드리프트 방지 팁
개인적으로 가장 효과적이었던 방법은 스타일 검증 레이어(Style Validation Layer)를 후처리에 추가하는 것이었습니다. 출력 텍스트의 격식 수준을 분류 모델(Classifier)로 판정하고, 기준에 미달하면 재생성을 트리거하는 방식입니다. 구조는 단순하지만 멀티턴 대화에서 스타일 일관성을 유지하는 데 꽤 효과가 있었습니다.
이어지는 2편에서는 Style Transfer의 역방향 활용인 Reverse Neutralization과, 생성 품질 전반을 끌어올리는 Content Optimization 패턴을 다룹니다.
References
Lakshmanan, V. & Hapke, H. (2025). “Generative AI Design Patterns: Solutions to Common Challenges When Building GenAI Agents and Applications." O’Reilly Media. https://www.oreilly.com/library/view/generative-ai-design/9798341622654/ 본 포스트에서 다루는 Logits Masking, Grammar Constraint, Style Transfer, Reverse Neutralization, Content Optimization의 5가지 출력 제어 패턴을 포함하여 총 32가지 GenAI 디자인 패턴을 체계화한 참고서이다.
Willard, B. T. & Louf, R. (2023). “Efficient Guided Generation for Large Language Models." arXiv preprint. https://arxiv.org/abs/2307.09702 LLM 디코딩 단계에서 유한 상태 머신(FSM)을 활용한 logits masking 및 구조화된 출력 생성의 이론적 기반을 제시한 핵심 논문으로, Logits Masking 패턴과 Grammar Constraint 패턴의 학술적 근거를 제공한다.
Outlines — Structured Text Generation library (GitHub) https://github.com/dottxt-ai/outlines 정규표현식, JSON Schema, 문맥 자유 문법(CFG) 등을 활용하여 LLM 출력을 토큰 레벨에서 제약하는 오픈소스 라이브러리로, Logits Masking과 Grammar Constraint 패턴의 대표적 프로덕션 구현체이다.
LMQL — A Programming Language for Large Language Models (GitHub) https://github.com/eth-sri/lmql ETH Zürich에서 개발한 LLM 쿼리 언어로, 타입 제약과 디코딩 제어를 프로그래밍 언어 수준에서 선언적으로 표현할 수 있어 Grammar Constraint 패턴의 실용적 접근 방식을 보여준다.
Guidance — A guidance language for controlling LLMs (GitHub) https://github.com/guidance-ai/guidance Microsoft에서 공개한 LLM 출력 제어 프레임워크로, 템플릿 기반의 구조화된 생성, 토큰 레벨 제약, 선택적 분기 등을 지원하며 본 포스트에서 다루는 다수의 출력 제어 패턴을 통합적으로 구현할 수 있는 도구이다.
Reif, E. et al. (2022). “A Recipe for Arbitrary Text Style Transfer with Large Language Models." ACL 2022. https://arxiv.org/abs/2109.03910 LLM을 활용한 텍스트 스타일 변환의 체계적 방법론을 제시한 논문으로, Style Transfer 패턴에서 프롬프트 기반 스타일 제어와 역방향 스타일 분리 기법의 이론적 토대를 제공한다.
OpenAI API — Structured Outputs (공식 문서) https://platform.openai.com/docs/guides/structured-outputs OpenAI API에서 JSON Schema 기반으로 LLM 출력 형식을 강제하는 Structured Outputs 기능의 공식 문서로, 프로덕션 환경에서 Grammar Constraint 패턴을 API 레벨에서 적용하는 실무적 참고 자료이다.
Mudgal, S. et al. (2024). “Controlled Decoding from Language Models." ICML 2024. https://arxiv.org/abs/2310.17022 보상 모델이나 가치 함수를 디코딩 단계에 통합하여 LLM 출력의 속성(안전성, 스타일, 품질 등)을 제어하는 Controlled Decoding 프레임워크를 제안한 논문으로, Content Optimization과 Reverse Neutralization 패턴의 학술적 근거를 제공한다.