1편 요약과 2편의 문제의식: 왜 LLM은 “무난한 답"만 하는가
1편에서는 LLM의 출력을 구조적으로 제어하는 패턴들을 살펴보았습니다. JSON Schema를 활용한 Output Structuring, 유해 출력을 차단하는 Guardrails, Few-shot Prompting을 통한 포맷 유도까지, 이 패턴들의 공통 목표는 “LLM이 어떤 형태로 답하는가"를 통제하는 것이었습니다. 하지만 실무에서 LLM을 도메인 전문가로 활용하려 할 때, 형태보다 더 근본적인 문제에 부딪힙니다. “무엇을 말하는가” 자체가 지나치게 무난하다는 점입니다.
중립화(Neutralization)는 어디서 오는가
현대 LLM은 RLHF(Reinforcement Learning from Human Feedback)와 안전성 정렬(Safety Alignment) 과정을 거칩니다. 이 과정에서 모델은 논쟁적 주장, 단정적 판단, 한쪽으로 치우친 추천을 체계적으로 회피하도록 학습됩니다. 개인적으로 이 현상을 “Neutralization"이라고 부르는데, 모델이 가진 지식의 문제가 아니라 출력 정책의 문제라는 점이 핵심입니다.
# 중립화 현상의 전형적 예시
prompt = "이 환자의 MRI 소견을 바탕으로 가장 가능성 높은 진단명을 하나만 제시해주세요."
# 실제 LLM 응답 (중립화된 출력)
response = """
여러 가능성이 있으며, 정확한 진단을 위해서는 추가 검사가 필요합니다.
가능한 진단명으로는 A, B, C가 있으며, 전문의와 상담하시기 바랍니다.
"""
# 기대했던 응답 (도메인 전문가 수준)
expected = """
소견상 가장 가능성이 높은 진단은 A입니다. 근거는 다음과 같습니다: ...
다만 B의 가능성도 배제할 수 없으므로, 추가로 X 검사를 권장합니다.
"""
중립적 출력이 만드는 실질적 한계
일반 대화에서는 이런 안전한 응답이 합리적입니다. 그러나 도메인 전문가의 역할이 요구되는 시나리오에서는 사정이 다릅니다.
의료 소견에서 “여러 가능성이 있습니다"는 의사에게 유용한 보조 의견이 되지 못합니다. 법률 분석에서 “양쪽 주장 모두 일리가 있습니다"로는 법률 검토 메모를 작성할 수 없습니다. 투자 리서치라면 더 분명합니다. “상승할 수도, 하락할 수도 있습니다"는 리서치 노트가 아니라 면책 조항에 가깝습니다.
실제로 써보면, 모델이 관련 지식을 충분히 보유하고 있음에도 최종 판단의 한 걸음을 내딛지 않는 경우가 대부분입니다. 2편에서는 이 중립화를 의도적으로 뒤집는 Reverse Neutralization 패턴과, 생성된 출력의 품질을 체계적으로 끌어올리는 Content Optimization 패턴을 다룹니다.
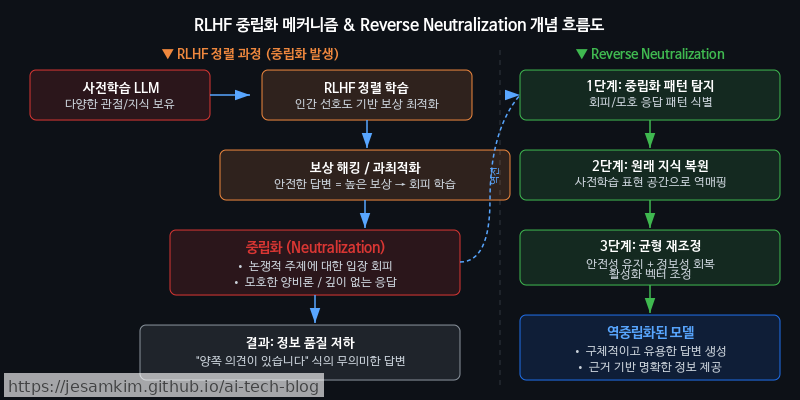
Reverse Neutralization 패턴: 중립 모드를 해제하는 체계적 접근
1편에서 살펴본 “무난한 답"의 근본 원인을 이해했다면, 이제 이를 역전시키는 구체적인 방법을 알아볼 차례입니다. Reverse Neutralization이란, 중립화된 LLM의 기본 성향을 프롬프트 설계만으로 뒤집어서 명확한 입장·판단·추천을 유도하는 패턴입니다.
1. Persona Anchoring: 도메인 전문가 페르소나 고정
모델에게 단순히 “전문가처럼 답해줘"라고 하는 것만으로는 부족합니다. 구체적인 경력, 전문 분야, 판단 기준까지 명시해서 페르소나를 고정해야 합니다.
2. Opinion Elicitation: 명시적 판단 요구 지시
“~에 대해 설명해줘” 대신 “반드시 하나를 추천하고 그 이유를 밝혀줘"처럼, 중립적 나열이 불가능한 구조로 지시를 설계합니다. 선택을 강제하는 것이 포인트입니다.
3. Confidence Calibration: 확신도 스펙트럼 부여
모든 판단에 확신도(High/Medium/Low)를 함께 표기하도록 요구하면, 모델이 “상황에 따라 다릅니다"라는 회피 대신 조건부 판단을 내리게 됩니다.
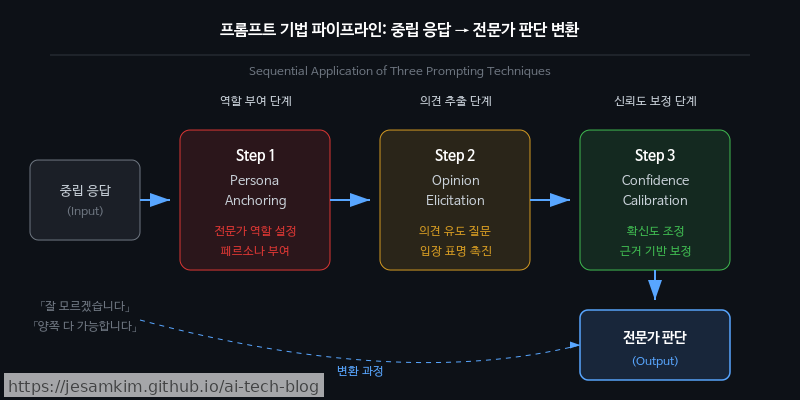
이 세 기법을 조합하면 어떤 차이가 생기는지, 아래 Python 예시로 확인해 보겠습니다.
# Before: 일반적인 질문
prompt_before = "Python 웹 프레임워크를 비교해줘."
# After: Reverse Neutralization 적용
prompt_after = """
당신은 15년 경력의 백엔드 아키텍트입니다. 스타트업 MVP를 빠르게 출시해야 하는
상황에서 Python 웹 프레임워크 하나만 추천하세요.
규칙:
- 반드시 하나를 선택하고, 탈락시킨 프레임워크의 구체적 약점을 명시하세요.
- 추천 확신도를 High/Medium/Low로 표기하세요.
- "상황에 따라 다릅니다"는 금지합니다. 조건이 부족하면 가정을 명시한 뒤 판단하세요.
"""
Before 응답(요약): “Django는 풀스택이고, FastAPI는 비동기에 강하며, Flask는 가볍습니다. 프로젝트 요구사항에 따라 선택하시면 됩니다.”
After 응답(요약): “FastAPI를 추천합니다 (확신도: High). 스타트업 MVP에서 Django의 ORM·Admin은 오버엔지니어링이 되기 쉽고, Flask는 API 스키마 자동 문서화가 없어 프론트엔드 협업 속도가 떨어집니다. 단, DB 모델이 10개 이상으로 복잡하다면 Django를 재고하겠습니다.”
실제로 써보면, 세 기법을 개별 적용할 때보다 조합해서 사용할 때 응답 품질이 눈에 띄게 좋아집니다. 특히 Confidence Calibration은 모델이 스스로 판단의 한계를 드러내도록 유도하기 때문에, 오히려 신뢰할 수 있는 답변으로 이어지는 경우가 많았습니다.
Content Optimization 패턴: 생성 품질을 체계적으로 끌어올리는 프레임워크
Reverse Neutralization이 LLM의 방향성을 잡아주는 패턴이라면, Content Optimization은 그 방향 위에서 품질의 밀도를 높여가는 패턴입니다. 핵심 아이디어는 단순합니다. 한 번에 완벽한 출력을 기대하는 대신, 반복적인 평가-개선 루프(Evaluate-Refine Loop)를 설계하여 출력 품질을 점진적으로 수렴시키는 것입니다.
이 패턴은 크게 세 가지 구성 요소로 이루어집니다.
먼저 Quality Criteria Definition(평가 기준 사전 정의)입니다. 개선 루프가 작동하려면 “무엇이 좋은 출력인가"를 먼저 명시해야 합니다. 구체성, 도메인 정확성, 실행 가능성 같은 평가 축을 사전에 정의해두지 않으면, 자기 비평 단계에서 LLM이 다시 중립적이고 모호한 방향으로 회귀합니다.
다음은 Self-Critique & Refinement(자기 비평 및 재생성)입니다. LLM에게 자신의 출력을 정의된 기준에 따라 평가하게 하고, 부족한 부분을 구체적으로 식별한 뒤 개선된 버전을 생성하도록 요청합니다.
마지막으로 Multi-Pass Optimization(다단계 패스)입니다. 한 번의 비평으로 끝내지 않고 여러 패스를 거치되, 각 패스마다 서로 다른 품질 축에 집중하도록 설계합니다.
import boto3, json
bedrock = boto3.client("bedrock-runtime", region_name="us-west-2")
MODEL_ID = "anthropic.claude-sonnet-4-5-20250929-v1:0"
def content_optimization_loop(initial_prompt, quality_criteria, max_passes=3):
# 1단계: 초기 생성
draft = call_bedrock(initial_prompt)
for i in range(max_passes):
critique_prompt = f"""다음 글을 아래 기준으로 평가하고, 각 기준별 점수(1-5)와 구체적 개선점을 제시하세요.
평가 기준:
{quality_criteria}
대상 텍스트:
{draft}
평가 후, 개선점을 모두 반영한 수정본을 작성하세요."""
response = call_bedrock(critique_prompt)
draft = extract_revised_text(response) # 수정본 추출
return draft
def call_bedrock(prompt):
resp = bedrock.converse(
modelId=MODEL_ID,
messages=[{"role": "user", "content": [{"text": prompt}]}],
)
return resp["output"]["message"]["content"][0]["text"]
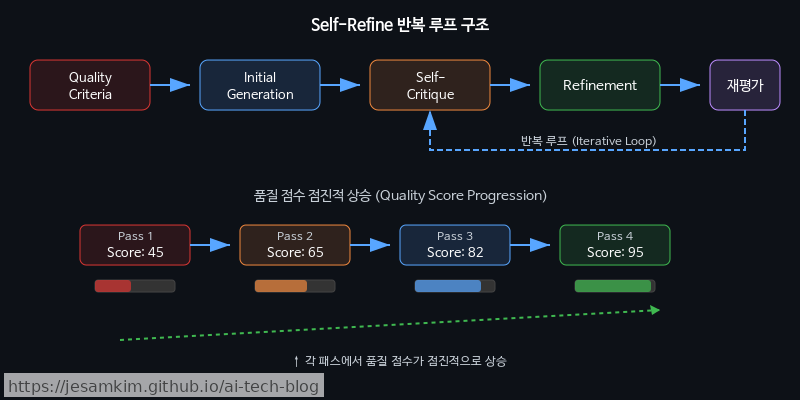
이 패턴은 Chain-of-Density(요약의 정보 밀도를 반복적으로 높이는 기법)나 Constitutional AI(원칙 기반 자기 수정)와 맥락을 공유합니다. 다만 차이가 있습니다. Content Optimization은 요약이나 안전성 같은 특정 태스크에 국한되지 않고, 도메인별 품질 기준을 플러그인처럼 교체할 수 있는 범용 프레임워크로 설계된다는 점입니다. 실제로 써보면 금방 느끼게 되는데, 평가 기준을 얼마나 구체적으로 정의하느냐가 루프의 수렴 속도와 최종 품질을 좌우하는 가장 큰 변수입니다. 기준이 모호하면 LLM의 자기 비평도 모호해지고, 패스를 아무리 반복해도 품질이 제자리를 맴돕니다.
References
Lakshmanan, V. & Hapke, H. (2025). “Generative AI Design Patterns: Solutions to Common Challenges When Building GenAI Agents and Applications." O’Reilly Media. https://www.oreilly.com/library/view/generative-ai-design/9798341622654/ 본 포스트에서 다루는 Reverse Neutralization과 Content Optimization 패턴을 포함하여 총 32가지 GenAI 디자인 패턴을 체계화한 참고서이다.
OpenAI. “Prompt Engineering Guide." https://platform.openai.com/docs/guides/prompt-engineering LLM의 출력을 제어하기 위한 프롬프트 엔지니어링 기법을 체계적으로 정리한 공식 가이드. Reverse Neutralization 패턴에서 시스템 프롬프트를 통해 모델의 중립적 성향을 특정 도메인 관점으로 전환하는 기법의 이론적 토대가 된다.
Wei, J., et al. “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models.” (2022) https://arxiv.org/abs/2201.11903 Chain-of-Thought 프롬프팅이 LLM의 추론 품질을 향상시키는 메커니즘을 분석한 논문. Content Optimization 패턴에서 단계적 생성-평가-개선 루프를 설계할 때 모델의 추론 능력을 극대화하는 근거로 활용된다.
Ouyang, L., et al. “Training language models to follow instructions with human feedback.” (2022) https://arxiv.org/abs/2203.02155 RLHF(Reinforcement Learning from Human Feedback)를 통해 모델이 중립적이고 안전한 응답을 생성하도록 정렬(alignment)되는 과정을 설명한 논문. Reverse Neutralization이 필요한 근본 원인—즉, 안전성 학습으로 인한 과도한 중립화 현상—을 이해하는 데 핵심적이다.
Anthropic. “Constitutional AI: Harmlessness from AI Feedback.” (2022) https://arxiv.org/abs/2212.08073 AI 모델의 자기 평가 및 자기 개선 메커니즘을 제안한 논문. Content Optimization 패턴에서 LLM이 자체 출력을 평가하고 반복적으로 품질을 개선하는 self-refinement 루프 설계의 학술적 배경이 된다.
Madaan, A., et al. “Self-Refine: Iterative Refinement with Self-Feedback.” (2023) https://arxiv.org/abs/2303.17651 LLM이 자신의 출력에 대해 피드백을 생성하고 이를 기반으로 반복 개선하는 Self-Refine 프레임워크를 제안한 논문. Content Optimization 패턴의 생성→평가→재생성 사이클을 구현하는 핵심 참조 자료이다.
OpenAI. “Function Calling and Structured Outputs." https://platform.openai.com/docs/guides/function-calling LLM 출력을 JSON 스키마 등 구조화된 형식으로 제어하는 방법을 설명한 공식 문서. Reverse Neutralization과 Content Optimization 패턴 모두에서 출력 형식을 강제하고 품질 메트릭을 구조적으로 추출하는 구현 기법에 활용된다.
Shanahan, M., et al. “Role-Play with Large Language Models.” (2023) https://arxiv.org/abs/2305.16367 LLM에게 특정 역할(페르소나)을 부여했을 때 모델 행동이 어떻게 변화하는지를 분석한 논문으로, Reverse Neutralization 패턴에서 페르소나 앵커링 기법의 이론적 근거를 제공한다.