1. 왜 모델 성능만으로는 코딩 에이전트를 설명할 수 없는가
AI 코딩 에이전트의 성능을 이야기할 때, 우리는 습관적으로 “어떤 모델을 쓰느냐"부터 묻게 됩니다. 하지만 SWE-bench 리더보드를 조금만 주의 깊게 살펴보면, 같은 기반 모델(base model)을 사용하면서도 에이전트 시스템에 따라 상당한 성능 격차가 발생하는 사례를 어렵지 않게 발견할 수 있습니다. 동일한 모델인데 결과가 크게 달라진다면, 그 차이는 어디에서 오는 걸까요?
핵심은 하니스(Harness), 즉 모델이 코드를 읽고, 수정하고, 실행 결과를 받아보는 도구 인터페이스(tool interface) 설계에 있습니다. 구체적으로 분해하면 다음 요소들이 실질적 병목으로 작용합니다.
- 프롬프트 포맷(Prompt Format): 파일 내용을 모델에 전달할 때 unified diff로 보여줄지, 전체 파일을 넘길지, 줄 번호를 어떤 방식으로 표기할지에 따라 모델의 편집 정확도가 크게 달라집니다.
- 파일 편집 방식(Edit Format): 모델이
search/replace블록을 출력하느냐, whole-file rewrite를 하느냐, 함수 단위 패치를 생성하느냐에 따라 적용 성공률이 눈에 띄게 변합니다. - 컨텍스트 주입 전략(Context Injection Strategy): 리포지토리 구조, 관련 테스트 파일, 에러 트레이스백(traceback) 중 무엇을 얼마나 포함시키느냐가 모델의 문제 이해도를 좌우합니다.
# 같은 모델, 다른 하니스 — 편집 포맷만 바꿔도 결과가 달라지는 예시
harness_a = {"edit_format": "search/replace", "context": "full_file"}
harness_b = {"edit_format": "unified_diff", "context": "function_only"}
# 동일 모델에 동일 태스크를 주더라도
# harness_a vs harness_b의 패치 적용 성공률은 상당한 차이를 보입니다
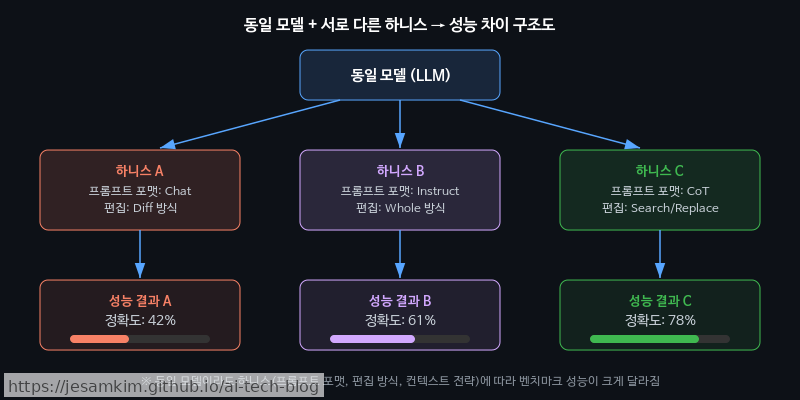
그렇다면 왜 하니스는 그동안 과소평가되어 왔을까요? 개인적으로 가장 큰 원인은 벤치마크 자체의 구조적 편향이라고 생각합니다. SWE-bench를 비롯한 대부분의 코딩 벤치마크는 “모델 A vs. 모델 B"라는 프레임으로 결과를 발표하도록 설계되어 있습니다. 리더보드의 행(row)은 모델 이름이고, 하니스 구성은 부록이나 코드 저장소 깊숙한 곳에 묻혀 있는 경우가 대부분입니다. 이런 구조에서는 모델 교체가 유일한 성능 개선 수단처럼 보이기 쉽습니다.
실제로 써보면, 모델을 한 단계 업그레이드하는 것보다 편집 포맷을 최적화하는 편이 더 즉각적이고 안정적인 개선을 가져오는 경우가 적지 않습니다. 이 포스트에서는 바로 이 “숨은 병목"을 체계적으로 파헤쳐 보겠습니다.
2. 하니스(Harness)란 무엇인가: 코딩 에이전트의 도구 인터페이스 해부
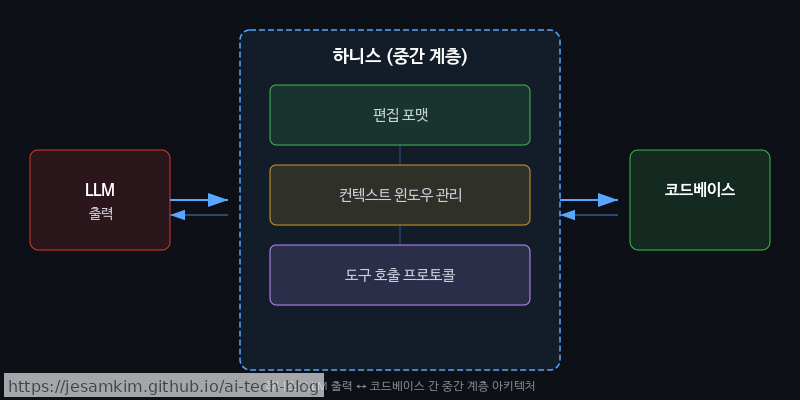
그렇다면 모델 성능 외에 코딩 에이전트의 실력을 좌우하는 요소는 무엇일까요? 바로 하니스(Harness)입니다. 하니스란, 에이전트가 코드베이스를 읽고, 수정하고, 실행하는 전체 인터페이스 계층을 가리킵니다. 파일 탐색, diff 적용, 테스트 실행, 셸 명령(shell command) 호출 등 LLM의 출력을 실제 코드 변경으로 변환하는 모든 중간 과정이 여기에 해당합니다.
하니스의 핵심 구성 요소
하니스는 크게 세 가지 축으로 분류할 수 있습니다.
첫째, **편집 포맷(Edit Format)**입니다. 모델이 코드 수정 의도를 어떤 형식으로 표현하느냐의 문제입니다. search/replace 블록, unified diff, whole-file rewrite 등의 방식이 대표적입니다.
# search/replace 방식 예시 (Aider 스타일)
<<<<<<< SEARCH
def hello():
print("hello")
=======
def hello():
print("hello, world!")
>>>>>>> REPLACE
둘째, **컨텍스트 윈도우 관리(Context Window Management)**입니다. 수만 줄짜리 리포지토리에서 어떤 파일의 어떤 부분을 모델에게 보여줄지 결정하는 전략으로, 에이전트 성능에 직접적인 영향을 줍니다.
셋째, **도구 호출 프로토콜(Tool-call Protocol)**입니다. 모델이 파일 읽기, 검색, 터미널 실행 같은 도구를 호출하는 방식과 순서를 정의합니다.
대표 하니스의 설계 철학 비교
흥미로운 점은 주요 코딩 에이전트들이 서로 상당히 다른 설계 철학을 채택하고 있다는 것입니다. Aider는 search/replace 기반의 경량 편집 포맷에 집중하며, 편집 정확도를 극한까지 끌어올리는 방향을 택했습니다. SWE-agent는 커스텀 셸 환경을 구축해 에이전트가 리눅스 명령어처럼 코드베이스를 탐색하도록 설계했고, OpenDevin은 브라우저·터미널·코드 에디터를 통합한 샌드박스 환경을 제공합니다. Cursor는 IDE 내장형으로 LSP(Language Server Protocol) 정보를 적극 활용하는 쪽을 선택했습니다.
개인적으로 실제로 써보면, 동일한 모델이라도 어떤 하니스 위에서 동작하느냐에 따라 체감 성능 차이가 놀라울 정도로 큽니다. 하니스 설계는 단순한 엔지니어링 디테일이 아니라 에이전트 아키텍처의 핵심 설계 결정입니다.
3. Hashline과 편집 포맷 벤치마크: 라인 식별의 작은 차이가 만드는 큰 성능 격차
앞서 하니스의 구조를 살펴보았으니, 이번에는 하니스 설계에서 가장 미묘하면서도 영향이 큰 요소 하나를 짚어보겠습니다. “모델이 파일의 특정 라인을 어떻게 가리키는가"라는 문제입니다.
라인 번호의 함정과 Hashline 접근법
코딩 에이전트가 파일을 편집할 때, 가장 흔한 실패 원인은 의외로 단순합니다. 모델이 “35번째 줄을 수정해"라고 지시했는데, 직전 편집으로 라인이 밀려 실제로는 37번째 줄이 대상인 경우입니다. 오프-바이-원(off-by-one) 에러, 그리고 라인 드리프트(line drift) 문제입니다.
Hashline은 이 문제를 근본적으로 우회합니다. 각 라인의 내용을 기반으로 짧은 해시 식별자를 생성하고, 라인 번호 대신 이 해시로 편집 위치를 지정합니다.
import hashlib
def generate_hashlines(file_content: str) -> dict:
"""각 라인에 내용 기반 해시 식별자를 부여합니다."""
hashlines = {}
for idx, line in enumerate(file_content.splitlines()):
# 라인 내용 + 인접 컨텍스트로 고유성 확보
raw = f"{line.strip()}:{idx}"
short_hash = hashlib.sha256(raw.encode()).hexdigest()[:8]
hashlines[short_hash] = {"line": idx, "content": line}
return hashlines
# 모델이 "라인 35"가 아니라 "a3f7c2d1" 해시를 참조하여 편집 지시
edit_instruction = {
"target": "a3f7c2d1", # 내용 기반 식별자 — 라인이 밀려도 추적 가능
"action": "replace",
"new_content": " return processed_result"
}
편집 포맷 벤치마크: 무엇이 실제로 더 잘 작동하는가
편집 포맷 간 성능 차이는 개인적으로 예상보다 훨씬 크게 느껴졌습니다. 주요 포맷을 비교하면 다음과 같습니다.
| 포맷 | 정확도 | 토큰 효율성 | 롤백 용이성 |
|---|---|---|---|
| Search/Replace | 컨텍스트 매칭 실패 시 급격히 하락 | 중간 (검색 블록 반복 필요) | 낮음 |
| Unified Diff | 라인 드리프트에 취약 | 높음 (변경분만 표현) | 중간 |
| Line-hash 기반 | 드리프트에 강건 | 중간 | 높음 (해시로 원본 추적 가능) |
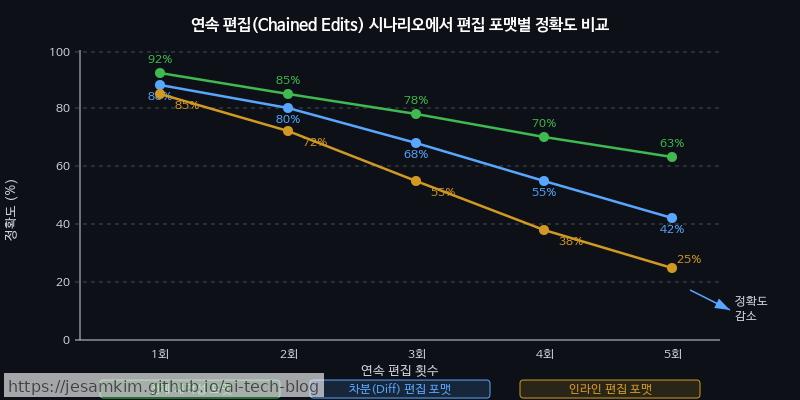
실패 모드: 해시 충돌과 중복 라인
물론 Hashline이 만능은 아닙니다. 실제로 써보면 동일 내용의 라인이 반복되는 경우에 해시 충돌이 발생합니다. 빈 줄이나 pass, 반복되는 import 구문 같은 것들입니다. 이를 보완하려면 인접 라인의 컨텍스트를 해시 생성에 포함시키거나, 순서 인덱스를 솔트(salt)로 추가하는 전략이 필요합니다.
결국 핵심은 이겁니다. 모델 자체의 코딩 능력이 동일하더라도, 편집 포맷이라는 하니스 레이어의 선택만으로 멀티스텝 편집의 성공률이 크게 달라질 수 있습니다. 모델이 “무엇을 고칠지” 아는 것과 “정확히 어디를 고칠지” 전달하는 것은 완전히 별개의 문제이고, 후자는 전적으로 하니스의 몫입니다.
References
can1357. “oh-my-pi: AI Coding agent for the terminal — hash-anchored edits, optimized tool harness” — GitHub. https://github.com/can1357/oh-my-pi
Jimenez, C. E. et al. “SWE-bench: Can Language Models Resolve Real-World GitHub Issues?” — arXiv, 2023. AI 코딩 에이전트의 실제 소프트웨어 엔지니어링 태스크 수행 능력을 평가하는 대표적 벤치마크. https://arxiv.org/abs/2310.06770
Gauthier, P. “Aider: AI pair programming in your terminal” — GitHub. 다양한 LLM에 대해 diff 포맷(unified diff, whole-file, search/replace 등) 편집 하니스의 성능 차이를 체계적으로 실험한 오픈소스 프로젝트. https://github.com/Aider-AI/aider
Yang, J. et al. “SWE-agent: Agent-Computer Interfaces Are All You Need for Software Engineering” — arXiv, 2024. 에이전트-컴퓨터 인터페이스(ACI) 설계가 코딩 에이전트 성능의 핵심 변수임을 실증한 논문. https://arxiv.org/abs/2405.15793
Anthropic. “Claude Code: Best practices for agentic coding” — Anthropic Docs, 2025. Claude Code의 도구 인터페이스 설계 철학과 str_replace 편집 포맷의 구현 근거. https://docs.anthropic.com/en/docs/claude-code