1. Mechanistic Interpretability란 무엇인가?
대규모 언어 모델(LLM)의 성능이 올라갈수록, “이 모델은 왜 이런 답을 내놓는가?“라는 질문이 점점 절실해지고 있습니다. Mechanistic Interpretability(기계적 해석 가능성)는 바로 이 질문에 가장 근본적인 수준에서 답하려는 연구 분야입니다.
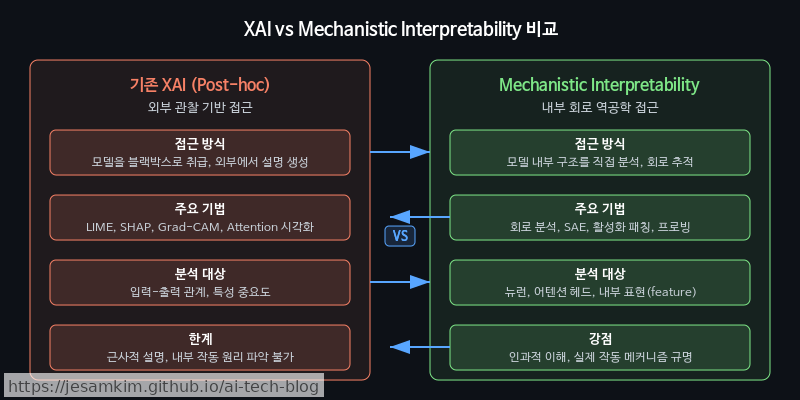
기존 XAI와 무엇이 다른가?
우리가 익숙한 Explainable AI(XAI) 기법들, 이를테면 SHAP, LIME, Attention Visualization 같은 것들은 대부분 사후 설명(post-hoc explanation) 방식입니다. 모델을 블랙박스로 두고, 입력과 출력의 관계를 외부에서 근사적으로 해석하는 것이죠. 반면 Mechanistic Interpretability는 신경망 내부의 가중치(weight)와 활성화(activation) 패턴을 직접 분석합니다. 모델이 실제로 학습한 알고리즘 자체를 역공학(reverse engineering)하려는 접근입니다.
질문의 프레임 자체가 다릅니다. “이 뉴런이 왜 활성화되었는가?“라는 개별 뉴런 수준의 물음에서, “이 모델이 내부적으로 어떤 계산 회로(circuit)를 구성하여 특정 태스크를 수행하는가?“로 초점이 옮겨갑니다.
꼭 알아야 할 핵심 용어
이 분야를 이해하려면 몇 가지 개념을 먼저 정리해야 합니다.
- Feature(특징): 모델이 내부적으로 표현하는 의미 있는 개념 단위입니다. “한국어 텍스트”, “코드의 들여쓰기”, “부정적 감정” 같은 추상적 개념이 각각 하나의 feature가 될 수 있습니다.
- Superposition(중첩): 모델이 뉴런 수보다 훨씬 많은 feature를 표현하기 위해, 여러 feature를 하나의 뉴런 공간에 겹쳐서 인코딩하는 현상입니다. 개인적으로 이 개념을 처음 접했을 때, 왜 개별 뉴런 분석이 그토록 어려웠는지 단번에 이해가 되었습니다.
- Polysemanticity(다의성): Superposition의 직접적인 결과로, 하나의 뉴런이 서로 무관한 여러 개념에 동시에 반응하는 현상입니다. 예를 들어 특정 뉴런이 “학술 인용"과 “한국 지명"에 모두 활성화되는 식입니다.
결국 Mechanistic Interpretability가 풀어야 할 과제는, 이렇게 얽혀 있는 뉴런 공간에서 개별 feature를 분리(disentangle)해내고, feature들이 연결되어 형성하는 회로(circuit)의 로직을 해독하는 것입니다. Anthropic이 Sparse Autoencoder(SAE)를 통해 이 문제에 본격적인 돌파구를 열었는데, 다음 섹션에서 자세히 살펴보겠습니다.
2. Anthropic의 주요 연구 흐름과 브레이크스루
이런 Mechanistic Interpretability의 이론적 토대 위에서, Anthropic은 지난 몇 년간 가장 체계적인 연구 흐름을 이어왔습니다.
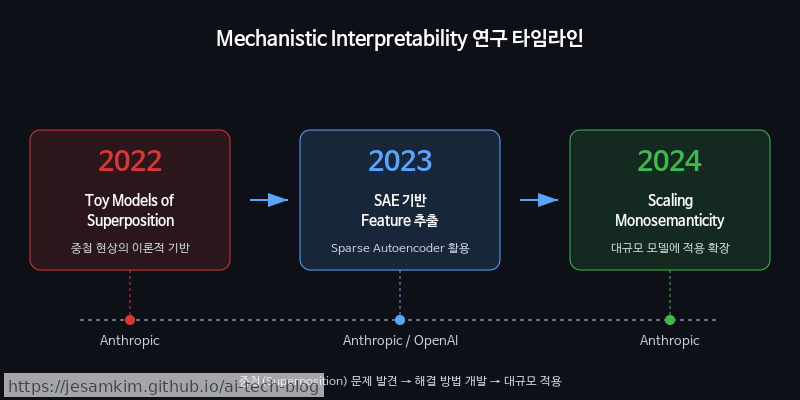
연구 타임라인: Toy Models에서 실제 LLM 해부까지
시작점은 2022년 발표된 “Toy Models of Superposition” 논문입니다. 이 연구는 신경망의 뉴런 하나가 왜 여러 개념을 동시에 인코딩하는지(Superposition), 그 메커니즘을 소규모 모델에서 수학적으로 규명했습니다. 문제는 이 중첩된 Feature를 어떻게 분리하느냐였고, 그 해답으로 등장한 것이 Sparse Autoencoder(SAE) 기반 Feature 추출 기법입니다.
2023~2024년에 걸쳐 Anthropic은 SAE를 점진적으로 스케일업하며, 실제 Claude 모델의 내부 활성화(Activation)에서 해석 가능한 Feature를 추출하는 데 성공했습니다. 개인적으로 이 과정이 인상적이었던 이유는, 단순히 “분리할 수 있다"는 가능성을 넘어 산업용 LLM 규모에서 실제로 작동함을 증명했기 때문입니다.
Scaling Monosemanticity: 수백만 Feature의 의미
2024년 발표된 “Scaling Monosemanticity” 연구는 이 분야의 결정적 전환점이었습니다. Claude 3 Sonnet 모델에서 수백만 개의 해석 가능한 Feature를 추출했는데, 각 Feature가 상당히 구체적인 개념에 대응했습니다. 예를 들어, 특정 Feature는 “Golden Gate Bridge"라는 개념에만 반응하고, 또 다른 Feature는 “코드 내 보안 취약점"이라는 추상적 개념에 활성화되었습니다.
# SAE를 활용한 Feature 추출의 개념적 흐름 (간소화)
# 실제 Anthropic 구현은 훨씬 복잡하지만 핵심 아이디어를 보여줍니다
import torch
import torch.nn as nn
class SparseAutoencoder(nn.Module):
def __init__(self, d_model, n_features):
super().__init__()
# n_features >> d_model (overcomplete basis)
self.encoder = nn.Linear(d_model, n_features)
self.decoder = nn.Linear(n_features, d_model)
self.relu = nn.ReLU()
def forward(self, x):
# 희소한 Feature 활성화를 학습
features = self.relu(self.encoder(x)) # 대부분 0, 소수만 활성화
reconstructed = self.decoder(features)
return reconstructed, features
# 모델 중간 레이어의 활성화를 입력으로 사용
# sae = SparseAutoencoder(d_model=4096, n_features=4_000_000)
Circuit-level 분석: 행동의 내부 회로를 추적하다
Feature 추출에서 한 걸음 더 나아가, Anthropic은 특정 행동을 담당하는 내부 회로(Circuit)를 식별하는 연구도 진행하고 있습니다. 모델이 거짓말을 하거나, 사회적 편향을 드러내거나, 위험한 응답을 생성할 때 어떤 Feature들이 어떤 경로로 활성화되는지 추적하는 것입니다. 실제로 특정 Feature를 인위적으로 증폭하거나 억제하면 모델의 행동이 예측 가능하게 변화한다는 점이 확인되었고, 이는 AI 안전성(AI Safety) 관점에서 상당히 의미 있는 결과입니다.
개인적으로 이 Circuit-level 분석이야말로 Mechanistic Interpretability가 학술 연구를 넘어 실용적 AI 거버넌스 도구로 진화하는 핵심 지점이라고 생각합니다.
3. MIT Technology Review 2026 10대 기술 선정의 의미
Anthropic의 연구 성과가 학계를 넘어 주목받기 시작한 가운데, MIT Technology Review는 2026년 10대 돌파 기술(10 Breakthrough Technologies) 목록에 Mechanistic Interpretability를 포함시켰습니다. 해석 가능성 연구가 순수 연구 단계를 넘어 산업적·정책적으로 공식 인정받았다는 신호로 읽을 수 있습니다.
왜 지금인가?
선정 배경에는 뚜렷한 정책적 수요가 있습니다. EU AI Act는 고위험 AI 시스템에 설명 가능성(Explainability) 요건을 명시하고 있고, 미국도 AI 안전 관련 행정명령을 통해 대규모 모델의 내부 동작 검증 필요성을 언급해 왔습니다. 규제 기관 입장에서 “모델이 왜 이런 출력을 생성하는가"라는 질문에 답할 수 있는 기술적 도구가 절실해진 겁니다. Mechanistic Interpretability는 그 질문에 가장 직접적으로 응답할 수 있는 접근법이라는 점에서 시의성이 맞아떨어졌습니다.
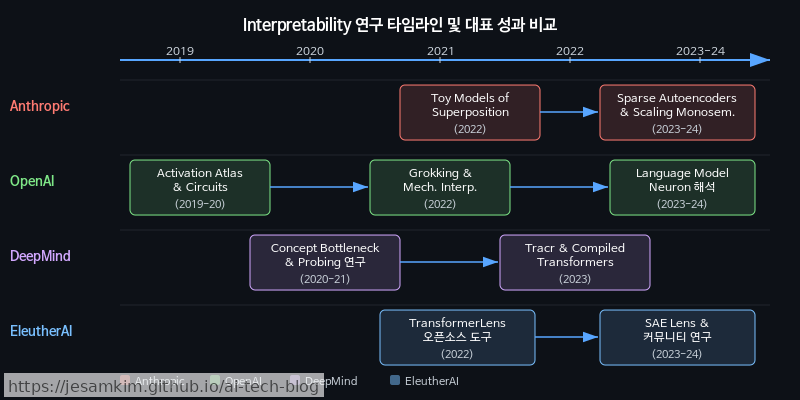
경쟁 연구 그룹의 투자 확대
이 분야에 주요 연구 그룹들이 빠르게 합류하고 있습니다. OpenAI는 자체 Interpretability 팀을 통해 Sparse Autoencoder 기반 피처 추출 연구를 공개했고, Google DeepMind도 대규모 모델의 내부 표상(Internal Representation) 분석에 상당한 리소스를 투입하고 있습니다. EleutherAI 같은 오픈소스 커뮤니티에서는 TransformerLens 등의 도구를 중심으로 해석 연구의 진입 장벽을 낮추는 데 기여하고 있습니다.
# TransformerLens를 활용한 간단한 활성화 분석 예시
import transformer_lens as tl
model = tl.HookedTransformer.from_pretrained("gpt2-small")
logits, cache = model.run_with_cache("The capital of France is")
# 특정 레이어의 잔차 스트림(Residual Stream) 활성화 확인
residual = cache["resid_post", 11] # 마지막 레이어
print(f"Residual stream shape: {residual.shape}")
개인적으로, 이번 선정이 갖는 가장 큰 의미는 “해석 가능성은 있으면 좋은 것"에서 “반드시 갖춰야 할 것"으로 인식이 전환되고 있다는 점이라고 생각합니다. AI Safety 논의가 추상적 우려에서 구체적 기술 요건으로 옮겨가고 있고, 그 흐름 속에서 Mechanistic Interpretability는 단순한 연구 주제를 넘어 AI 시스템의 신뢰를 뒷받침하는 기반 기술로 자리를 잡아가고 있습니다.
4. 최신 연구 동향: 표현 공간의 기하학과 컨텍스트 한계
MIT의 선정이 학계의 관심을 끌면서, 2024~2025년에는 Mechanistic Interpretability의 외연을 넓히는 연구들이 빠르게 나오고 있습니다.
언어 통계의 대칭성과 표현 기하학
최근 주목할 만한 흐름 중 하나는 언어 통계의 대칭성(Symmetry in Language Statistics)이 모델 내부 표현의 기하학적 구조를 직접 형성한다는 연구입니다. 핵심 아이디어는 단순합니다. 자연어 코퍼스에 내재된 통계적 규칙성, 예를 들어 공출현 빈도의 패턴 같은 것이 임베딩 공간에서 특정 기하학적 대칭으로 나타난다는 겁니다. Anthropic이 추구해 온 특징 사전(feature dictionary) 접근법과도 자연스럽게 연결됩니다. SAE로 추출한 개별 특징들이 왜 그런 방향(direction)으로 정렬되는지를 언어 자체의 구조에서 설명할 수 있는 이론적 토대를 제공하기 때문입니다.
Long Context의 주의력 분산 문제
컨텍스트 윈도우가 수십만 토큰으로 확장되면서, 해석 가능성 관점에서 새로운 난제도 떠오르고 있습니다. Long Context 환경에서 어텐션(Attention)이 극도로 분산되면, 모델이 실제로 어떤 정보에 의존해 답변을 생성하는지 추적하기가 훨씬 어려워집니다. 개인적으로, 이 문제는 단순한 성능 이슈가 아니라 해석 가능성의 근본적 한계와 연결된다고 봅니다. “Lost in the Middle” 현상처럼 중간 위치 정보가 무시되는 패턴을 메커니즘 수준에서 규명하는 작업이 앞으로 더 중요해질 것입니다.
Parameter-efficient Fine-tuning의 내부 추적
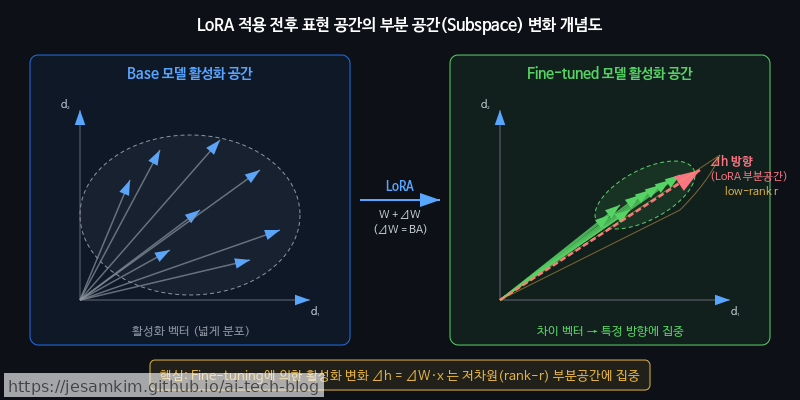
LoRA 같은 Parameter-efficient Fine-tuning(PEFT) 기법이 모델 내부 표현을 어떻게 바꾸는지 추적하는 연구도 활발합니다. 예를 들어 스타일 전이(style transfer) 태스크에서, LoRA 어댑터가 수정하는 저랭크(low-rank) 업데이트가 표현 공간의 어떤 부분 공간(subspace)에 작용하는지를 시각화할 수 있습니다.
# LoRA 적용 전후 표현 변화 추적 (개념 코드)
base_acts = model.get_activations(input_ids, layer=16) # 원본 모델
lora_acts = lora_model.get_activations(input_ids, layer=16) # LoRA 적용 후
# 변화 방향의 주성분 분석
diff = lora_acts - base_acts
U, S, V = torch.svd(diff)
# S의 상위 성분 → 미세조정이 집중적으로 변형한 표현 방향
이런 분석을 통해 미세조정이 모델의 어떤 메커니즘을 건드리는지 파악할 수 있습니다. 실제로 써보면 스타일 관련 특징과 사실 지식 관련 특징이 상당히 분리된 부분 공간에서 변화하는 경향을 확인할 수 있습니다.
이처럼 최신 연구들은 Mechanistic Interpretability를 단순히 “모델 내부 들여다보기"에서, 언어의 본질적 구조와 아키텍처의 한계, 나아가 학습 역학을 이해하는 방향으로 확장하고 있습니다.
5. 실무 적용과 한계
학술적 성과가 쌓이고 있지만, 실무 현장에서 Mechanistic Interpretability를 바로 활용하기에는 아직 넘어야 할 산이 많습니다.
현재 가능한 실무 적용 영역으로는 모델 디버깅과 안전성 감사(Safety Auditing)가 대표적입니다. 특정 프롬프트에서 모델이 유해한 출력을 생성할 때, Sparse Autoencoder(SAE)로 추출한 피처를 활용하면 어떤 내부 표현이 활성화되었는지 추적할 수 있습니다.
# SAE를 활용한 피처 활성화 추적 (개념적 예시)
from transformer_lens import HookedTransformer
from sae_lens import SAE
model = HookedTransformer.from_pretrained("gpt2-small")
sae = SAE.from_pretrained("gpt2-small-res-jb")
# 특정 입력에 대한 잔차 스트림(residual stream) 추출
_, cache = model.run_with_cache("The capital of France is")
residual = cache["blocks.8.hook_resid_post"]
# SAE를 통해 해석 가능한 피처로 분해
feature_acts = sae.encode(residual)
# 가장 강하게 활성화된 피처 상위 10개 확인
top_features = feature_acts.topk(10, dim=-1)
print("Top activated feature indices:", top_features.indices)
print("Activation values:", top_features.values)
개인적으로 이런 파이프라인을 실제로 써보면, 피처 인덱스가 무엇을 의미하는지 해석하는 과정이 가장 큰 병목이 됩니다. Anthropic의 Neuronpedia 같은 피처 사전이 있어야 비로소 “이 피처가 지리적 수도 개념에 반응한다"는 식의 해석이 가능해집니다.
한계도 분명합니다.
- 확장성(Scalability): 현재 SAE 기반 분석은 수십억 파라미터 규모에서도 상당한 연산 비용이 발생합니다. 수천억 파라미터급 모델에 적용하기는 더 어렵습니다.
- 피처 완전성(Feature Completeness): 추출된 피처가 모델 행동 전체를 설명한다는 보장이 없습니다. 중요한 회로(circuit)가 누락될 가능성이 항상 존재합니다.
- 인과성 검증의 어려움: 피처 활성화와 출력 사이의 상관관계를 발견해도, 이것이 실제 인과 경로인지 확인하려면 정교한 개입 실험(intervention experiment)이 추가로 필요합니다.
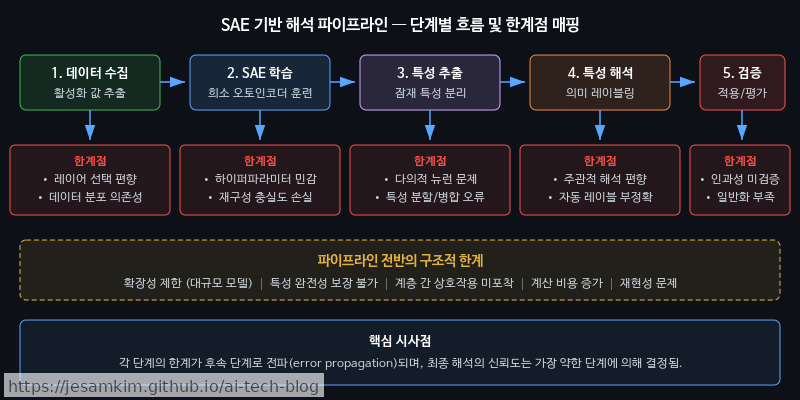
이런 한계에도 불구하고, 모델 안전성 팀에서는 이미 이 기법들을 탐색적 도구로 활용하고 있습니다. EU AI Act 등 규제 프레임워크가 설명 가능성(Explainability) 요건을 요구하면서, 이를 뒷받침할 기술적 기반으로서 관심도 높아지는 추세입니다.
References
“Symmetry in language statistics shapes the geometry of model representations” — 언어 통계의 대칭성이 모델 내부 표현의 기하학적 구조를 형성하는 메커니즘을 분석한 논문. http://arxiv.org/abs/2602.15029v1
“Long Context, Less Focus: A Scaling Gap in LLMs Revealed through Privacy and Personalization” — 긴 컨텍스트에서 LLM의 주의(attention) 집중도가 감소하는 스케일링 갭을 프라이버시·개인화 관점에서 밝힌 논문. http://arxiv.org/abs/2602.15028v1
“Text Style Transfer with Parameter-efficient LLM Finetuning and Round-trip Translation” — 파라미터 효율적 파인튜닝을 통한 텍스트 스타일 변환 연구로, LLM 내부 표현 조작과 관련된 논문. http://arxiv.org/abs/2602.15013v1
Bricken, T. et al., “Towards Monosemanticity: Decomposing Language Models With Dictionary Learning” (2023) — Anthropic 연구팀이 Sparse Autoencoder(SAE)를 활용하여 트랜스포머의 다의적(polysemantic) 뉴런을 단의적(monosemantic) 피처로 분해하는 방법론을 제시한 논문. 본문의 SAE 기반 피처 추출 파이프라인의 이론적 기초. https://transformer-circuits.pub/2023/monosemantic-features/
Olah, C. et al., “Zoom In: An Introduction to Circuits” (2020) — 신경망 내부의 개별 뉴런과 회로를 체계적으로 분석하는 Mechanistic Interpretability 연구의 기초를 놓은 Anthropic/OpenAI 계열 연구. 본문에서 다루는 회로 발견(circuit discovery) 접근법의 출발점. https://distill.pub/2020/circuits/zoom-in/
Anthropic, “Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet” (2024) — Anthropic 연구팀이 Claude 3 Sonnet에서 수백만 개의 해석 가능한 특징(feature)을 추출하여 대규모 언어 모델의 내부 작동을 해부한 핵심 연구. https://transformer-circuits.pub/2024/scaling-monosemanticity/
Conmy, A. et al., “Towards Automated Circuit Discovery for Mechanistic Interpretability” (2023) — 신경망 내부의 회로(circuit)를 자동으로 발견하는 방법론을 제시하여 Mechanistic Interpretability 연구의 체계적 접근을 가능하게 한 논문. http://arxiv.org/abs/2304.14997
MIT Technology Review, “10 Breakthrough Technologies 2026” — MIT 테크놀로지 리뷰가 선정한 2026년 10대 혁신 기술 목록으로, AI 모델 해석 가능성(Mechanistic Interpretability)이 포함되어 해당 분야의 산업적 중요성을 보여주는 자료이다.