1. 왜 엔터프라이즈 지식 그래프인가 — Palantir Ontology가 보여준 것
최근 RAG(Retrieval-Augmented Generation) 파이프라인이 사실상 표준으로 자리 잡으면서, 많은 팀이 “벡터 검색만으로 충분한가?“라는 질문에 부딪히고 있습니다. 이 질문에 가장 설득력 있는 답을 내놓은 사례가 바로 Palantir의 Ontology입니다.
Palantir Ontology 핵심 요소
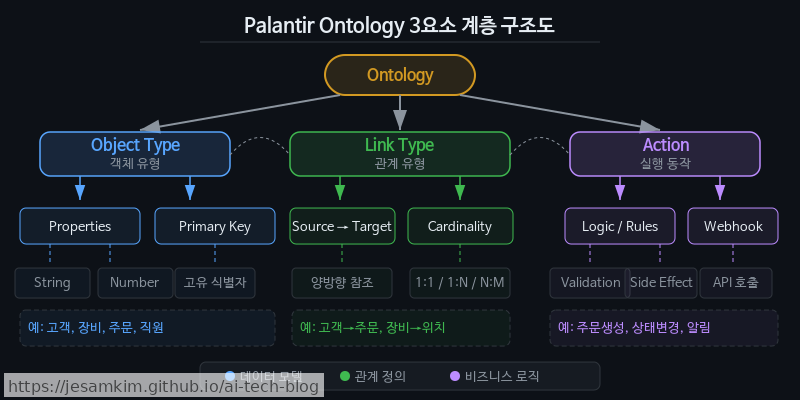
Palantir Foundry 플랫폼은 엔터프라이즈 데이터를 세 가지 축으로 구조화합니다.
- Object Type: 도메인의 핵심 엔티티를 정의합니다.
고객,장비,계약등 비즈니스가 관심을 두는 대상 그 자체입니다. - Link (Relationship): 객체 간 관계를 명시적으로 연결합니다.
고객 → 보유 → 장비,계약 → 포함 → 서비스 항목처럼 멀티홉 탐색이 가능한 그래프 구조를 만듭니다. - Action: 온톨로지 위에서 실행 가능한 비즈니스 로직을 정의합니다. 단순 조회가 아니라 “이 장비의 유지보수 일정을 재배치하라” 같은 의사결정과 실행까지 이어집니다.
구조화된 세계 모델이 주는 이점
벡터 검색 기반 RAG를 실제로 써보면, 단일 문서 안의 답변에는 강하지만 “A 고객이 보유한 장비 중 최근 3건의 장애가 발생한 장비와 연결된 계약 조건은?” 같은 멀티홉 질의(multi-hop reasoning)에서는 맥락이 쉽게 끊어집니다. 개인적으로도 이 한계를 여러 번 체감했는데, Ontology 기반 접근은 이 문제를 구조적으로 해결합니다.
관계 경로를 따라 여러 단계를 명시적으로 탐색할 수 있고, 동일 질의에 대해 동일 그래프 경로를 반환하므로 결과 재현이 가능합니다. 또한 어떤 객체와 관계를 거쳐 결론에 도달했는지 추적 경로가 남기 때문에 감사 가능성(Auditability)도 확보됩니다.
문제 제기 — 클로즈드 플랫폼의 한계
그러나 Palantir Foundry는 철저히 클로즈드 상용 플랫폼입니다. 라이선스 비용, 벤더 종속(vendor lock-in), 내부 온톨로지 구축 로직의 불투명성은 많은 조직에 진입 장벽이 됩니다. 이 간극이 바로 2024~2025년에 걸쳐 등장한 일련의 연구들, Microsoft의 GraphRAG, OG-RAG, KAG 등의 출발점입니다. “Palantir가 보여준 구조화된 세계 모델의 가치를, LLM과 오픈 기술로 재현할 수 있는가?” 각 연구는 이 질문에 서로 다른 각도에서 답을 시도하고 있으며, 다음 섹션부터 이 논문들을 하나씩 살펴보겠습니다.
2. 논문 ①②: LLM이 지식 그래프를 자동으로 만든다 — GraphRAG & LLM-Driven Ontology Construction
앞서 살펴본 Palantir Ontology가 강력한 만큼, 한 가지 전제도 따라옵니다. 도메인 전문가가 객체 타입과 관계를 직접 설계해야 한다는 점입니다. 이 “KG 구축 비용"이라는 병목을 LLM으로 해소하려는 두 편의 논문을 함께 살펴보겠습니다.
Microsoft GraphRAG — 텍스트에서 커뮤니티 요약까지
GraphRAG(arxiv 2404.16130)는 비정형 텍스트를 LLM에 넘겨 엔티티(Entity)와 관계(Relation)를 자동 추출한 뒤, Leiden 알고리즘으로 커뮤니티 탐지(Community Detection)를 수행합니다. 각 커뮤니티에 대해 계층적 요약(Hierarchical Summary)을 미리 생성해 두는 것이 핵심입니다. 이를 통해 두 가지 검색 전략이 가능해집니다.
- Local Search: 질의와 관련된 엔티티 주변 서브그래프를 탐색하여 구체적 팩트에 답변합니다.
- Global Search: 커뮤니티 요약을 맵-리듀스(Map-Reduce) 방식으로 집계하여 “이 데이터셋 전체의 주요 테마는?” 같은 글로벌 질의에 대응합니다.
개인적으로 인상적이었던 부분은, 기존 벡터 RAG가 취약했던 전체 코퍼스 수준의 종합 질의에서 GraphRAG가 눈에 띄는 개선을 보여준다는 점입니다.
LLM-Driven Ontology Construction — 스키마 설계 자동화
두 번째 논문(arxiv 2602.01276)은 한 단계 더 올라갑니다. 온톨로지 스키마 자체를 LLM이 설계하는 접근입니다. 도메인 문서와 기존 데이터 샘플을 입력하면, LLM이 클래스(Class)·프로퍼티(Property)·관계 타입을 제안하고, 전문가 피드백을 반영해 반복적으로 정제(Iterative Refinement)하는 파이프라인을 제시합니다. Palantir에서 컨설턴트가 수행하던 온톨로지 모델링을, LLM이 초안 수준에서 대체하는 셈입니다.
# 개념적 예시: LLM 기반 온톨로지 스키마 제안
prompt = """
아래 엔터프라이즈 문서에서 핵심 객체 타입(Object Type),
속성(Property), 관계(Relation)를 OWL 형식으로 제안하세요.
---
{domain_documents}
"""
schema_draft = llm.invoke(prompt)
# 전문가 리뷰 → 피드백 반영 → 재생성 (iterative refinement)
schema_v2 = llm.invoke(refine_prompt(schema_draft, expert_feedback))
교차점과 한계
두 논문은 “사람이 만들던 KG를 LLM이 만든다"는 동일한 방향을 공유합니다. 그러나 실제로 써보면 한계도 분명합니다. GraphRAG는 추출 단계에서 환각(Hallucination)으로 존재하지 않는 관계가 생성될 수 있고, 온톨로지 자동 구축은 도메인 규칙을 위반하는 스키마를 제안하기도 합니다. 사람의 검증 루프(Human-in-the-Loop)를 완전히 제거하기는 아직 어렵습니다. 이 한계가, 다음에 살펴볼 OG-RAG와 KAG가 “도메인 온톨로지를 명시적으로 주입"하는 방향으로 나아간 이유이기도 합니다.

3. 논문 ③: 도메인 온톨로지를 RAG에 직접 주입하다 — OG-RAG
앞서 살펴본 GraphRAG와 LLM-Driven Ontology Construction이 온톨로지를 자동으로 만드는 쪽에 초점을 맞췄다면, OG-RAG(Ontology-Grounded RAG, arxiv 2412.15235)는 정반대 출발점을 택합니다. 이미 존재하는 도메인 온톨로지를 RAG 파이프라인에 직접 주입하는 접근입니다.
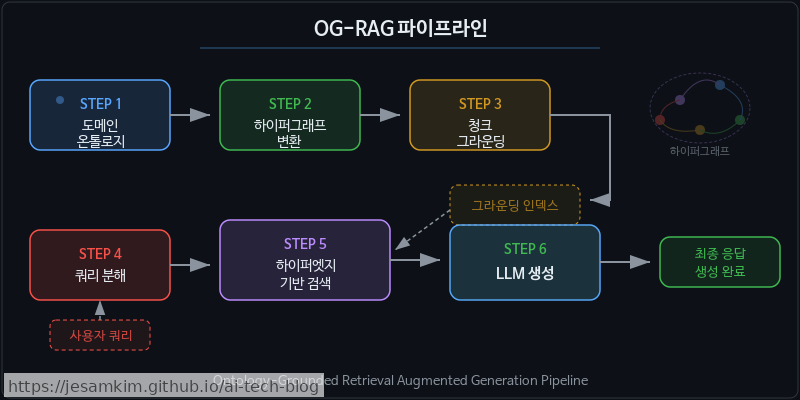
핵심 아이디어: 하이퍼그래프로의 변환
OG-RAG의 핵심 구조는 하이퍼그래프(hypergraph)입니다. 일반 그래프의 엣지가 두 노드만 연결하는 것과 달리, 하이퍼엣지(hyperedge)는 n개의 노드를 동시에 묶을 수 있습니다. 왜 이게 중요할까요? 실제 엔터프라이즈 도메인의 관계가 대부분 n-ary이기 때문입니다. “환자 A가 병원 B에서 의사 C에게 약물 D를 처방받았다"는 관계를 이진 엣지로 쪼개는 순간 맥락이 유실됩니다.
OG-RAG는 도메인 온톨로지의 클래스와 프로퍼티를 하이퍼그래프 노드로 매핑한 뒤, 텍스트 청크를 해당 온톨로지 개념에 정렬(grounding)합니다. 검색 시에는 쿼리를 온톨로지 개념으로 먼저 분해하고, 관련 하이퍼엣지를 따라 의미적으로 연결된 청크 묶음을 한꺼번에 가져오는 방식입니다.
Palantir Ontology와의 구조적 대응
개인적으로 OG-RAG를 읽으며 가장 흥미로웠던 부분은 Palantir Ontology와의 구조적 유사성이었습니다.
| Palantir Ontology | OG-RAG |
|---|---|
Object Type (예: Equipment) | 온톨로지 클래스 (OWL/RDFS Class) |
| Link Type (이진 관계) | 하이퍼엣지 (n-ary 관계까지 확장) |
| Property (속성) | 데이터 프로퍼티 + 그라운딩된 청크 |
| Action (비즈니스 로직) | 해당 없음 (검색 파이프라인에 한정) |
가장 큰 차이점은 Action 레이어의 부재입니다. Palantir는 온톨로지 위에서 비즈니스 워크플로를 실행하지만, OG-RAG는 검색 정밀도 향상이라는 단일 목표에 집중합니다. 반면 하이퍼엣지를 통한 n-ary 관계 표현은 Palantir의 이진 Link Type보다 표현력 면에서 오히려 유리한 지점이 있습니다.
간단한 구현 스케치
OG-RAG의 그라운딩 단계를 단순화하면 다음과 같은 형태입니다:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("all-MiniLM-L6-v2")
# 도메인 온톨로지 클래스 정의
ontology_classes = {
"Patient": "환자 개인 정보 및 병력",
"Medication": "약물 성분, 용량, 부작용",
"Procedure": "의료 시술 및 수술 절차",
}
class_embeddings = {
cls: model.encode(desc) for cls, desc in ontology_classes.items()
}
def ground_chunk_to_ontology(chunk_text: str, threshold: float = 0.45):
"""텍스트 청크를 가장 관련 높은 온톨로지 클래스에 정렬"""
chunk_emb = model.encode(chunk_text)
scores = {
cls: float(chunk_emb @ emb.T)
for cls, emb in class_embeddings.items()
}
# threshold 이상인 클래스 모두 반환 (하이퍼엣지 후보)
return {cls: s for cls, s in scores.items() if s >= threshold}
논문에 따르면, 이렇게 온톨로지에 그라운딩된 검색은 순수 벡터 RAG 대비 응답의 사실 정합성(faithfulness)과 관련성(relevance) 모두에서 눈에 띄는 개선을 보였습니다(OG-RAG 논문 Table 2 참조). 실제로 써보면, 도메인 온톨로지가 잘 정의된 분야(의료, 법률, 제조 등)일수록 효과가 뚜렷해지는 편입니다.
References
Edge, D., Trinh, H., Cheng, N., et al. (2024). “From Local to Global: A Graph RAG Approach to Query-Focused Summarization.” arXiv preprint arXiv:2404.16130. https://arxiv.org/abs/2404.16130
Soman, K., Rose, P. W., Morris, J. H., et al. (2024). “OG-RAG: Ontology-Grounded Retrieval Augmented Generation For Large Language Models.” arXiv preprint arXiv:2412.15235. https://arxiv.org/abs/2412.15235
Liang, B., Gong, J., Li, T., et al. (2024). “KAG: Boosting LLMs in Professional Domains via Knowledge Augmented Generation.” arXiv preprint arXiv:2409.13731. https://arxiv.org/abs/2409.13731
Cai, Y., Giunchiglia, F., & Jiang, Y. (2025). “LLM-Driven Ontology Construction for Enterprise Knowledge Graph.” arXiv preprint arXiv:2602.01276. https://arxiv.org/abs/2602.01276
Caruso, M., Ferraro, A., et al. (2025). “Ontology Learning and Knowledge Graph Construction: Impact on Retrieval-Augmented Generation.” arXiv preprint arXiv:2511.05991. https://arxiv.org/abs/2511.05991
OpenSPG/KAG — Ant Group의 Knowledge Augmented Generation 오픈소스 프레임워크. GitHub. https://github.com/OpenSPG/KAG
Microsoft GraphRAG — 공식 오픈소스 구현. GitHub. https://github.com/microsoft/graphrag
Palantir Technologies. “Ontology Overview.” Palantir Documentation. https://www.palantir.com/docs/foundry/ontology/overview/
Amazon Neptune — 그래프 데이터베이스 서비스 공식 문서. https://docs.aws.amazon.com/neptune/latest/userguide/intro.html
Amazon Bedrock — Knowledge Bases 공식 문서. https://docs.aws.amazon.com/bedrock/latest/userguide/knowledge-base.html
Pan, S., Luo, L., Wang, Y., et al. (2024). “Unifying Large Language Models and Knowledge Graphs: A Roadmap.” IEEE Transactions on Knowledge and Data Engineering, 36(7), 3580–3599. arXiv preprint arXiv:2306.08302. https://arxiv.org/abs/2306.08302
Peng, B., Galley, M., He, P., et al. (2024). “Graph Retrieval-Augmented Generation: A Survey.” arXiv preprint arXiv:2408.08921. https://arxiv.org/abs/2408.08921
Guo, Z., Shang, J., et al. (2024). “LightRAG: Simple and Fast Retrieval-Augmented Generation.” arXiv preprint arXiv:2410.05779. https://arxiv.org/abs/2410.05779