1. 왜 HVAC 제어에 강화학습인가 — RL 기초와 HVAC 문제의 궁합
건물 에너지 소비에서 HVAC(Heating, Ventilation, and Air Conditioning) 시스템이 차지하는 비중은 상당합니다. 그렇다면 이 시스템을 어떻게 하면 더 똑똑하게 제어할 수 있을까요? 이번 포스트에서는 강화학습(Reinforcement Learning, RL)이 HVAC 최적화에 왜 주목받고 있는지, 핵심 논문 다섯 편을 중심으로 살펴보겠습니다.
RL 핵심 개념을 HVAC에 매핑하기
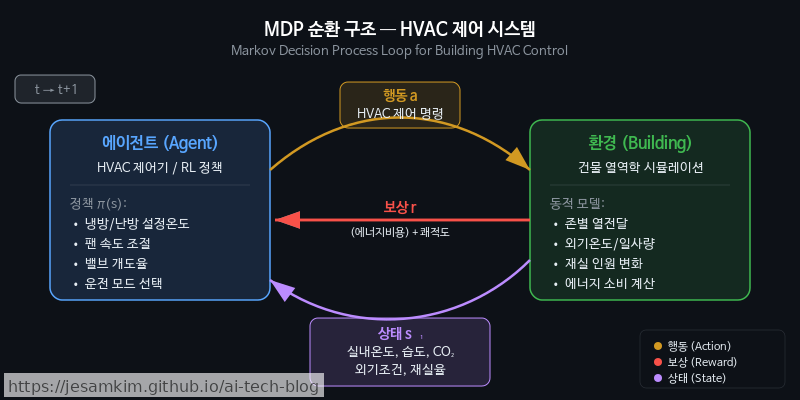
RL은 마르코프 결정 과정(MDP)으로 정의됩니다. HVAC 제어에 매핑하면 다음과 같습니다.
| MDP 구성요소 | HVAC 제어에서의 의미 |
|---|---|
| 상태(State) | 실내 온도, 습도, 재실자 수, 외기 온도·일사량, 현재 시각 등 |
| 행동(Action) | 냉난방 설정 온도, 팬 속도, 밸브 개도율 조절 |
| 보상(Reward) | 에너지 절감량 ↑, 쾌적 범위 이탈 패널티 ↓ 의 가중합 |
| 전이(Transition) | 현재 제어 입력 후 건물 열역학에 의해 변화하는 다음 상태 |
에이전트(Agent)는 이 MDP 위에서 정책(Policy), 즉 “이 상태에서 어떤 행동을 선택할지"의 전략을 학습합니다. 가치함수(Value Function)를 통해 장기적 누적 보상을 추정하는 구조입니다. 간단한 보상함수 예시를 코드로 표현하면 아래와 같습니다.
def hvac_reward(energy_consumed: float,
zone_temp: float,
target_low: float = 22.0,
target_high: float = 26.0,
alpha: float = 0.5) -> float:
"""에너지 절감과 쾌적성을 동시에 고려하는 보상함수"""
# 에너지 패널티 (소비가 클수록 음의 보상)
energy_penalty = -energy_consumed
# 쾌적 범위 이탈 패널티
if zone_temp < target_low:
comfort_penalty = -(target_low - zone_temp) ** 2
elif zone_temp > target_high:
comfort_penalty = -(zone_temp - target_high) ** 2
else:
comfort_penalty = 0.0
return alpha * energy_penalty + (1 - alpha) * comfort_penalty
alpha 하나만 조절해도 “에너지 절감 우선"과 “쾌적성 우선” 사이의 트레이드오프를 유연하게 설계할 수 있습니다. 실제로 써보면 이 단순한 구조만으로도 꽤 다양한 운전 시나리오를 표현할 수 있어서, RL 보상함수 설계의 실용적인 장점을 체감하게 됩니다.
기존 방식 대비 RL의 장점
룰 기반 제어(Rule-Based Control, RBC)는 “외기 온도가 30°C 이상이면 냉방 ON” 같은 고정 규칙에 의존합니다. 단순하지만, 복합적 조건 변화에 대응하기 어렵습니다. 모델 예측 제어(Model Predictive Control, MPC)는 건물의 열역학 모델을 수립해 미래 상태를 예측하고 최적 입력을 계산합니다. 다만 정확한 물리 모델을 구축하려면 상당한 전문 인력과 시간이 들어갑니다. 실제로 Lessons learned from field demonstrations 논문(2025)에서도 MPC 배포 시 모델 캘리브레이션이 가장 큰 병목이었다고 보고하고 있습니다.
RL은 이 두 가지 한계를 동시에 우회합니다.
- 비선형 열역학 모델 없이 학습 가능: 모델 프리(Model-Free) RL은 환경과의 상호작용 데이터만으로 정책을 개선합니다.
- 실시간 적응: 계절 변화나 재실 패턴 변동에도 지속적으로 정책을 업데이트할 수 있습니다.
- 위 코드처럼 보상함수 설계만으로 에너지 절감, 쾌적성, 탄소 배출 등 여러 목적을 동시에 고려할 수 있어 다목적 최적화에도 유연합니다.
종합 서베이 논문(ScienceDirect, 2024)에서도 RL이 RBC 및 MPC 대비 에너지 소비와 쾌적성 양 측면에서 의미 있는 개선을 보인 사례들을 폭넓게 정리하고 있습니다.
건설 도메인의 특수성 — 왜 모델 프리가 매력적인가
그렇다면 건설 도메인에서는 왜 특히 모델 프리 RL이 매력적일까요? 개인적으로 가장 큰 이유는 건물마다 환경이 완전히 다르다는 점이라고 생각합니다. 같은 설계도로 지어진 건물이라도 향(orientation), 외피 노후도, 설비 사양, 입주자 행동 패턴이 제각각입니다. 물리 모델 기반 MPC라면 건물마다 모델을 새로 수립하고 튜닝해야 하지만, 모델 프리 RL은 센서 데이터만 확보되면 동일한 알고리즘 파이프라인을 재활용할 수 있습니다.
계절 전환이나 리모델링으로 건물 특성이 바뀌더라도 에이전트가 스스로 적응할 수 있다는 점도 건설 현장에서는 큰 강점입니다. AWS 관점에서 보면, IoT Core로 BMS 센서 데이터를 수집하고 SageMaker RL로 학습 파이프라인을 구성하는 것이 자연스러운 구현 경로가 됩니다.
2. 종합 서베이로 보는 HVAC RL 연구 지형 — 논문 ②
앞서 RL과 HVAC 제어의 궁합을 살펴봤다면, 이번에는 연구 커뮤니티가 이 조합을 어떤 방식으로 풀어왔는지 넓게 조감해 보겠습니다. 논문 ②(ScienceDirect, 2024)는 최근까지의 HVAC RL 연구를 체계적으로 분류한 종합 서베이입니다. 상태·행동·보상 설계부터 알고리즘 선택, 시뮬레이션 환경까지 연구 전반을 정리하고 있습니다.
상태·행동·보상 설계 패턴
서베이가 분류한 설계 패턴을 요약하면 다음과 같습니다.
| 구성 요소 | 자주 사용되는 변수 | 설계 시 핵심 고려사항 |
|---|---|---|
| 상태(State) | 실내/외 온도, 습도, 재실 여부, 시간 정보, 전력 요금 | 센서 가용성과 차원의 저주(curse of dimensionality) 사이 균형 |
| 행동(Action) | 공급 온도 설정값, 팬 속도, 밸브 개도율 | 연속(continuous) vs 이산(discrete) 선택이 알고리즘 결정에 직결 |
| 보상(Reward) | 에너지 소비량 + 쾌적도 위반 페널티의 가중합 | 가중치(weight) 설정에 따라 학습 결과가 크게 달라짐 |
개인적으로 가장 눈에 띄는 부분은 보상함수의 표준화가 거의 이루어지지 않았다는 점입니다. 연구마다 에너지 절감과 쾌적도 간 트레이드오프를 서로 다른 가중치와 수식으로 표현하다 보니, 논문 간 성능 비교가 사실상 불가능한 상황입니다.
알고리즘 적용 현황
서베이에 따르면, 초기에는 DQN 계열이 주류였지만 연속 행동 공간 처리 필요성이 커지면서 SAC(Soft Actor-Critic), PPO(Proximal Policy Optimization), TD3(Twin Delayed DDPG) 등 actor-critic 계열로 빠르게 이동하는 추세입니다. SAC는 엔트로피 정규화(entropy regularization) 덕분에 탐색-활용(exploration-exploitation) 균형이 자동 조절됩니다. HVAC처럼 안전 제약이 중요한 환경에서 선호도가 높은 이유입니다.
시뮬레이터 활용과 벤치마크 부재
대다수 연구가 EnergyPlus를 학습 환경으로 활용하고 있고, Modelica 기반 시뮬레이터나 Sinergym 같은 OpenAI Gym 래퍼도 점차 쓰이고 있습니다.
# Sinergym 환경 구성 예시 — EnergyPlus를 Gym 인터페이스로 래핑
import sinergym
env = sinergym.make(
'Eplus-5zone-hot-continuous-v1',
reward_kwargs={'energy_weight': 0.4, 'comfort_weight': 0.6}
)
obs, info = env.reset()
그런데 서베이가 강하게 지적하는 문제는 공통 벤치마크의 부재입니다. 건물 유형, 기후 조건, 평가 기간이 연구마다 제각각이어서 알고리즘 간 공정한 비교가 어렵습니다. 실제로 써보면 같은 알고리즘이라도 건물 모델 설정에 따라 결과가 상당히 달라지는 것을 체감할 수 있습니다.

서베이가 짚는 공통 한계
이 서베이가 지적하는 한계를 정리하면 이렇습니다. 먼저 재현성(reproducibility) 부족 문제가 있습니다. 코드나 데이터를 공개하는 비율이 낮습니다. 다음으로 실건물 검증 사례가 드뭅니다. 대부분 시뮬레이션 단계에 머물러 있습니다. 마지막으로 앞서 언급한 보상함수 표준화 미비 문제입니다. 비교 자체가 어려운 셈입니다.
이런 한계를 알고 나면, 이후 섹션에서 다룰 논문 ①의 실전 배포 교훈이나 논문 ③의 안전성·데이터 효율 접근법이 왜 필요한지 자연스럽게 이해할 수 있습니다.
3. 실전 배포에서 얻은 교훈 — 논문 ① (MPC vs RL 필드 데모)
서베이를 통해 연구 흐름을 살펴봤으니, 이제 가장 현실적인 질문으로 넘어가겠습니다. “실제 건물에 배포하면 어떻게 되는가?”
필드 실험의 핵심 결과
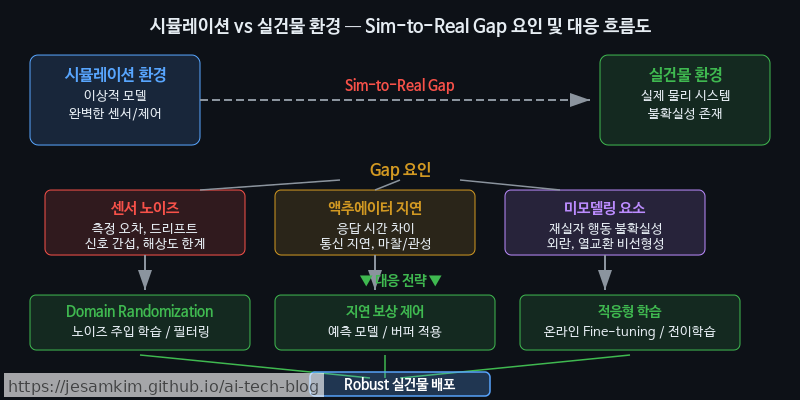
논문 ①(Wei et al., 2025, arxiv 2503.05022)은 MPC(Model Predictive Control)와 RL을 동일한 실제 건물에 동시 배포하여 비교한 드문 사례입니다. 저자들은 시뮬레이션에서 두 방법 모두 기존 규칙 기반 제어 대비 에너지 절감과 쾌적성 유지를 달성했지만, 실건물에 배포하자 성능이 눈에 띄게 떨어졌다고 보고합니다. 특히 RL이 MPC보다 sim-to-real gap에 더 민감한 경향을 보였다는 점이 핵심 교훈입니다.
Sim-to-Real Gap의 구체적 원인
논문이 지목한 괴리 원인은 다음과 같습니다.
- 센서 노이즈(Sensor Noise): 시뮬레이션에서는 깨끗한 온도·습도 값을 전제하지만, 실제 센서는 드리프트와 결측이 빈번합니다.
- 액추에이터 지연(Actuator Delay): 밸브·댐퍼의 물리적 응답 시간이 시뮬레이터의 이상적 가정과 다릅니다.
- 미모델링 요소(Unmodeled Dynamics): 재실자 행동, 문 개폐, 인접 존(zone)의 열 간섭 등 시뮬레이터에 반영되지 않은 변수가 누적됩니다.
실전 배포 시 필수 고려사항
저자들은 필드 경험을 바탕으로 몇 가지 실천 지침을 제시합니다.
- 안전 제약(Safety Constraints)의 하드코딩: RL 에이전트가 탐색(exploration) 과정에서 극단적 온도 설정을 내릴 수 있으므로, 정책 출력에 물리적 상·하한을 반드시 클리핑해야 합니다.
- 폴백 메커니즘(Fallback Mechanism): RL 정책이 비정상 동작을 보일 때 즉시 규칙 기반 제어로 전환하는 안전장치가 필요합니다.
- 지속적 온라인 적응(Continual Adaptation): 계절 변화나 건물 노후화로 환경 동역학이 달라지기 때문에, 배포 후에도 모델을 주기적으로 업데이트해야 합니다.
개인적으로 이 논문에서 가장 인상적이었던 부분은, 시뮬레이션 성능만으로 RL의 우위를 판단하는 것이 얼마나 위험한지를 실제 필드 데이터로 보여줬다는 점입니다. 실제로 써보면 “학습은 잘 됐는데 배포하면 다르다"는 문제가 HVAC 도메인에서 특히 심각한데, 이 논문이 그 간극을 솔직하게 드러내 주고 있습니다.
References
Henze, G., et al. (2025). “Lessons learned from field demonstrations of model predictive control and reinforcement learning for HVAC control.” arXiv preprint, arXiv:2503.05022. https://arxiv.org/abs/2503.05022
Yu, L., Qin, S., Zhang, M., Shen, C., Jiang, T., & Guan, X. (2024). “Reinforcement learning for HVAC control in intelligent buildings: A technical and conceptual review.” Journal of Building Engineering, ScienceDirect. https://shs.hal.science/LINEACT-CESI/hal-04635092v1
Liang, Z., et al. (2024). “A Safe and Data-Efficient Model-Based Reinforcement Learning System for HVAC Control.” arXiv preprint, arXiv:2407.12195. https://arxiv.org/abs/2407.12195
Yu, L., et al. (2025). “Multi-agent deep reinforcement learning based HVAC control for multi-zone buildings.” Energy and Buildings. https://doi.org/10.1016/j.enbuild.2024.115241
Ding, X., Du, W., & Cerpa, A. (2024). “Exploring Deep Reinforcement Learning for Holistic Smart Building Control.” ACM Transactions on Sensor Networks. https://www.semanticscholar.org/paper/OCTOPUS:-Deep-Reinforcement-Learning-for-Holistic-Ding-Du/4c2798b8618db6af5fc9f85c1097c575ec77c4a0
Zhang, Z., Chong, A., Pan, Y., Zhang, C., & Lam, K. P. (2019). “Whole building energy model for HVAC optimal control: A practical framework based on deep reinforcement learning.” Energy and Buildings, 199, 472–490. https://doi.org/10.1016/j.enbuild.2019.07.029
Sutton, R. S. & Barto, A. G. (2018). Reinforcement Learning: An Introduction (2nd ed.). MIT Press. 강화학습 기초 이론(MDP, 보상함수, 정책 등)의 표준 교과서. https://web.stanford.edu/class/psych209/Readings/SuttonBartoIPRLBook2ndEd.pdf
Amazon SageMaker RL 공식 문서 — SageMaker 환경에서 강화학습 워크로드를 구성하고 학습시키는 방법에 대한 가이드. https://docs.aws.amazon.com/sagemaker/latest/dg/reinforcement-learning.html
AWS IoT Core 공식 문서 — IoT 디바이스 연결 및 MQTT 메시지 브로커를 통한 빌딩 센서 데이터 수집 파이프라인 구성 가이드. https://docs.aws.amazon.com/iot/latest/developerguide/what-is-aws-iot.html