비정형 문서 파싱이 어려운 이유
엔터프라이즈 환경에서 RAG(Retrieval-Augmented Generation) 파이프라인을 구축해 보신 분이라면, 가장 먼저 부딪히는 벽이 “원본 문서에서 의미 있는 구조를 살려 텍스트를 뽑아내는 것"이라는 데 공감하실 겁니다. 전통적 접근법이 왜 한계에 부딪히는지, 그리고 구조 보존이 왜 중요한지 정리해 보겠습니다.
PDF 내부 구조의 복잡성
PDF는 본질적으로 화면 렌더링을 위한 포맷이지, 시맨틱 구조를 전달하기 위한 포맷이 아닙니다. 스캔된 PDF는 텍스트 레이어 자체가 존재하지 않습니다. 디지털 네이티브 PDF조차 다단(multi-column) 레이아웃이나 표·차트·이미지가 혼재된 페이지에서는 텍스트 추출 순서가 뒤엉키기 일쑤입니다. 실제로 써보면 PyPDF2나 pdfplumber 같은 라이브러리는 단순 문서에서는 잘 동작하지만, 복잡한 레이아웃 앞에서는 금세 무너집니다.
import pdfplumber
with pdfplumber.open("complex_report.pdf") as pdf:
page = pdf.pages[0]
text = page.extract_text()
# 다단 레이아웃의 경우: 왼쪽 칼럼과 오른쪽 칼럼 텍스트가
# 줄 단위로 뒤섞여 의미 파악이 불가능한 결과가 반환됩니다
print(text[:500])
개인적으로 금융 보고서나 학술 논문처럼 표와 각주가 밀집된 문서에서 이 문제를 가장 심하게 체감했습니다.
OCR 기반 접근의 한계
Amazon Textract이나 Tesseract 같은 OCR 엔진은 스캔 PDF 문제를 해결해 주지만, 레이아웃 읽기 순서(reading order) 보존과 표 구조 복원에서는 여전히 아쉬운 점이 많습니다. 셀 병합이 포함된 복잡한 표는 행·열 경계를 잘못 인식하고, 수식이나 특수문자(≥, ∑, → 등)는 오인식률이 눈에 띄게 높습니다. 후처리 없이 다운스트림 LLM에 그대로 넘기기엔 품질이 부족한 경우가 대부분입니다.
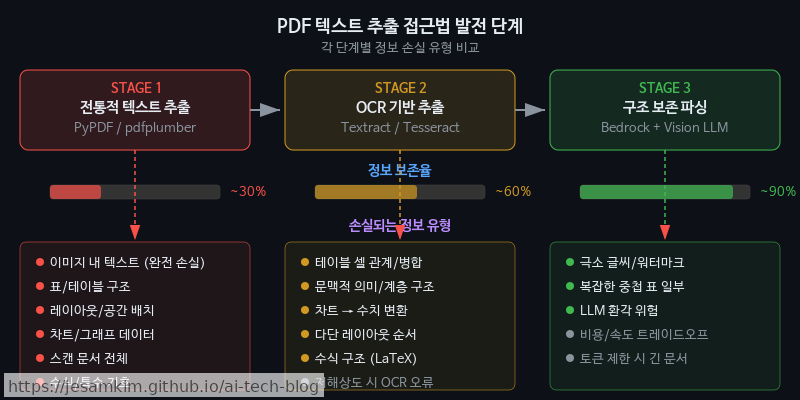
왜 “구조 보존 Markdown 변환"이 중요한가
RAG 파이프라인에서 청킹(chunking)의 품질은 곧 검색 품질이고, 검색 품질은 곧 최종 응답 품질입니다. 원본 문서의 헤딩 계층, 표 구조, 리스트 중첩 관계 같은 시맨틱 구조가 평문(plain text)으로 붕괴되면, 청킹 경계가 의미 단위와 어긋납니다. LLM은 맥락을 잃은 단편만 받아보게 되고, 응답 품질도 함께 떨어집니다.
Markdown은 이런 시맨틱 구조를 LLM이 잘 이해할 수 있는 경량 포맷으로 보존해 줍니다. 그래서 비정형 문서를 구조화된 Markdown으로 변환하는 단계가 전체 파이프라인 성능을 좌우한다고 봐도 과언이 아닙니다.
이어지는 섹션에서는 이 문제를 해결하기 위해 Amazon Bedrock이 제공하는 도구들을 어떻게 조합할 수 있는지 살펴보겠습니다.
Amazon Bedrock Data Automation(BDA) 개요와 문서 파싱 기능
이런 기존 접근법의 한계를 해결하기 위해 AWS가 내놓은 서비스가 Amazon Bedrock Data Automation(BDA)입니다. BDA는 S3에 업로드된 비정형 문서를 입력받아, Blueprint 기반으로 자동 분류·추출을 수행한 뒤 구조화된 JSON 또는 Markdown 형태로 출력하는 완전 서버리스(Serverless) 파이프라인입니다.
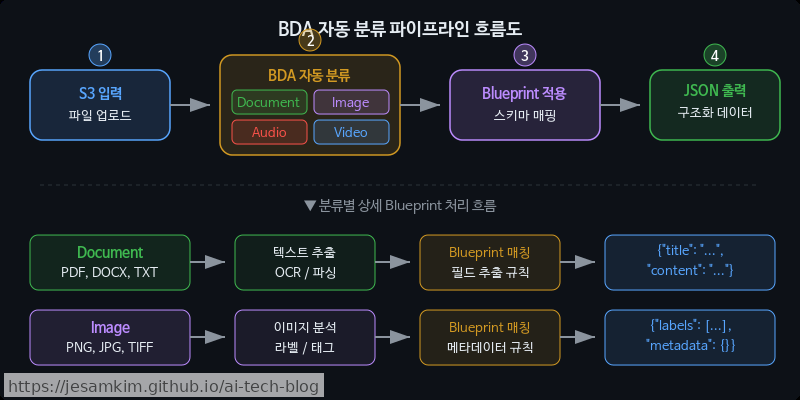
Standard Output vs Custom Output(Blueprint)
BDA의 출력 모드는 크게 두 가지로 나뉩니다. Standard Output은 별도 설정 없이 문서 유형을 자동 감지하여 텍스트, 표, 키-값 쌍 등을 추출합니다. 반면 Custom Output은 Blueprint라는 커스텀 스키마를 정의하여 특정 필드만 선택적으로 추출할 수 있습니다. 송장(Invoice)에서 공급자명, 합계 금액, 품목 리스트만 뽑아내는 식입니다.
import boto3
client = boto3.client("bedrock-data-automation", region_name="us-east-1")
# Blueprint 생성 — 송장에서 특정 필드만 추출하는 커스텀 스키마
response = client.create_blueprint(
blueprintName="invoice-parser",
type="DOCUMENT",
schema={
"description": "Invoice data extraction",
"properties": {
"vendor_name": {"type": "string", "description": "공급자 회사명"},
"total_amount": {"type": "number", "description": "합계 금액"},
"line_items": {
"type": "array",
"items": {
"type": "object",
"properties": {
"description": {"type": "string"},
"quantity": {"type": "number"},
"unit_price": {"type": "number"}
}
}
}
}
}
)
blueprint_arn = response["blueprint"]["blueprintArn"]
레이아웃 분석과 Textract 대비 개선점
개인적으로 BDA에서 가장 인상적인 부분은 내부적으로 수행되는 레이아웃 분석(Layout Analysis) 메커니즘입니다. BDA는 단순 OCR을 넘어 페이지 내 시각적 블록을 감지하고, 다단(Multi-column) 레이아웃의 읽기 순서(Reading Order)를 결정하며, 병합 셀이 포함된 복잡한 표 구조까지 파싱합니다. 기존 Amazon Textract가 개별 API(AnalyzeDocument, AnalyzeExpense 등)를 조합해야 했던 것과 달리, BDA는 이 모든 과정을 단일 호출로 통합 처리합니다.
실제로 써보면 Textract에서 별도로 처리해야 했던 문서 분류, 페이지 분할, 후처리 로직이 BDA 안에서 자동으로 이루어지기 때문에 파이프라인 복잡도가 눈에 띄게 줄어듭니다. 다만 BDA의 Standard Output만으로는 원본 문서의 시각적 계층 구조, 즉 헤더 깊이나 리스트 중첩, 캡션과 본문의 관계를 완벽히 보존하기 어려운 경우가 있습니다. 이 지점에서 Claude Vision과의 앙상블이 의미를 갖게 됩니다.
Claude Vision을 활용한 페이지 단위 시각적 문서 이해
BDA가 AWS 네이티브 서비스로서 문서 파싱의 기본기를 제공한다면, Claude Vision은 한 단계 더 깊은 시각적 맥락 이해를 가능하게 합니다. 특히 복잡한 레이아웃이 섞인 비정형 문서에서는 페이지 이미지를 통째로 모델에 넘기는 접근법이 생각보다 잘 동작합니다.
Sonnet 4.5 vs Opus 4.6: Vision 능력 트레이드오프
두 모델 모두 고해상도 이미지 입력을 지원하지만, 실제로 써보면 체감 차이가 분명합니다. Sonnet 4.5는 토큰 소비가 상대적으로 적고 응답 속도가 빠르기 때문에 단순 텍스트 중심 문서나 정형화된 표에서 비용 효율이 좋습니다. 반면 Opus 4.6은 다단 컬럼, 중첩 표, 캡션이 포함된 그래프처럼 시각적 복잡도가 높은 레이아웃에서 구조 인식 정확도가 눈에 띄게 올라갑니다. 개인적으로는 문서 복잡도에 따라 모델을 동적으로 선택하는 라우팅 전략을 권장합니다.
페이지별 이미지 변환과 프롬프트 엔지니어링
앞서 모델 선택을 정했다면, 이제 실제 파이프라인을 구성할 차례입니다. 핵심은 PDF를 페이지별 이미지로 변환한 뒤, Claude Vision API에 DOM 트리 구조의 Markdown 출력을 유도하는 프롬프트와 함께 전달하는 것입니다.
import fitz # PyMuPDF
import boto3, json, base64
def pdf_to_page_images(pdf_path, dpi=300):
doc = fitz.open(pdf_path)
for page in doc:
pix = page.get_pixmap(dpi=dpi)
yield base64.standard_b64encode(pix.tobytes("png")).decode()
def call_claude_vision(b64_image, model_id="anthropic.claude-sonnet-4-5-20250514"):
client = boto3.client("bedrock-runtime", region_name="us-east-1")
prompt = (
"이 문서 페이지를 분석하여 DOM 트리 구조의 Markdown으로 변환하세요. "
"표는 HTML <table> 태그로, 제목 계층은 #/##/### 헤더로, "
"이미지 영역은 [IMAGE: 설명] 플레이스홀더로 표현하세요. "
"원본의 읽기 순서와 계층 구조를 반드시 보존하세요."
)
body = json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 4096,
"messages": [{"role": "user", "content": [
{"type": "image", "source": {"type": "base64", "media_type": "image/png", "data": b64_image}},
{"type": "text", "text": prompt}
]}]
})
resp = client.invoke_model(modelId=model_id, body=body)
return json.loads(resp["body"].read())["content"][0]["text"]
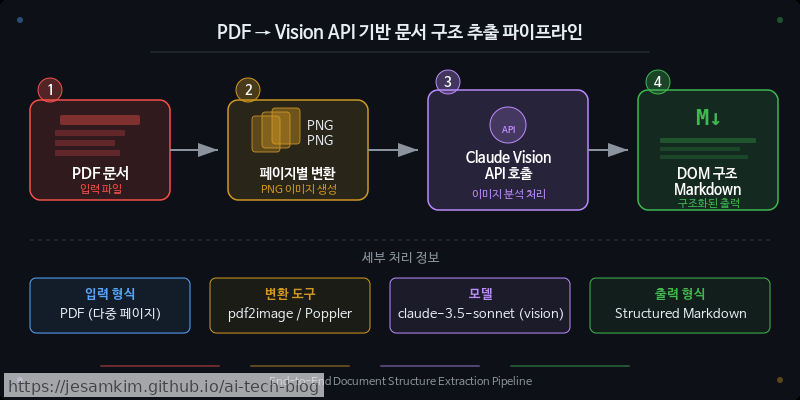
단독 Vision 접근의 강점과 한계
이 방식의 가장 큰 강점은 시각적 맥락을 온전히 보존한다는 점입니다. OCR 파이프라인이 놓치기 쉬운 컬럼 간 읽기 순서, 표와 본문의 경계, 각주의 계층 관계 같은 것들을 모델이 이미지 전체를 보고 판단합니다. 그래서 구조적 정확도가 상당히 높습니다.
다만 페이지 수가 많은 문서에서는 API 호출 비용이 누적되고, 순수 텍스트 영역에서는 기존 텍스트 추출 대비 불필요한 토큰을 소비하게 됩니다. 이런 한계가 바로 다음 섹션에서 다룰 앙상블 전략이 필요한 이유이기도 합니다.
References
Amazon Bedrock 공식 개발자 문서 — Amazon Bedrock 서비스의 전체 아키텍처, API 레퍼런스 및 모델 호출 가이드. https://docs.aws.amazon.com/bedrock/
Amazon Bedrock Data Automation 공식 문서 — Bedrock Data Automation(BDA)의 문서 처리 파이프라인, Blueprint 구성 및 비정형 데이터 자동화 기능 상세 안내. https://docs.aws.amazon.com/bedrock/latest/userguide/bda.html
Amazon Textract 공식 개발자 문서 — PDF 및 이미지 기반 문서에서 텍스트, 테이블, 폼 데이터를 추출하는 OCR 서비스의 API 가이드. https://docs.aws.amazon.com/textract/
Anthropic Claude 모델 공식 문서 — Vision 기능 — Claude 모델의 멀티모달(Vision) 입력 처리 방식, 이미지 인코딩 규격 및 프롬프트 설계 가이드. https://docs.anthropic.com/en/docs/build-with-claude/vision
Amazon Bedrock의 Anthropic Claude 모델 사용 가이드 — Bedrock 환경에서 Claude 모델을 호출할 때의 파라미터 설정, 멀티모달 메시지 구성 및 Converse API 활용법. https://docs.aws.amazon.com/bedrock/latest/userguide/model-parameters-anthropic-claude-messages.html
Amazon Bedrock Converse API 공식 문서 — 다양한 파운데이션 모델을 통합 인터페이스로 호출하기 위한 Converse API의 요청/응답 스펙 및 멀티모달 입력 처리. https://docs.aws.amazon.com/bedrock/latest/userguide/conversation-inference-call.html
AWS Blog — Amazon Bedrock Data Automation 소개 — BDA를 활용한 비정형 문서(PDF, 이미지, 오디오, 비디오) 처리 자동화의 아키텍처 및 실전 적용 사례. https://aws.amazon.com/bedrock/bda/
PyMuPDF(fitz) 공식 문서 — Python 기반 PDF 파싱 라이브러리로, 텍스트 블록 좌표 추출, 페이지 렌더링(이미지 변환) 및 메타데이터 접근 API 레퍼런스. https://pymupdf.readthedocs.io/en/latest/
pdfplumber GitHub 저장소 — PDF에서 테이블, 텍스트, 라인 등의 구조적 요소를 정밀하게 추출하기 위한 Python 라이브러리. https://github.com/jsvine/pdfplumber
Nougat: Neural Optical Understanding for Academic Documents (Meta AI, 2023) — 학술 PDF 문서를 Markdown으로 직접 변환하는 Vision Transformer 기반 end-to-end 모델. 비정형 문서의 구조적 마크다운 변환 접근법의 핵심 선행 연구. https://arxiv.org/abs/2308.13418
LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking (Microsoft, 2022) — 문서의 텍스트, 레이아웃, 이미지를 통합 학습하는 사전훈련 모델. 문서 AI 분야의 멀티모달 표현 학습 기반 연구. https://arxiv.org/abs/2204.08387 사전 학습된 이미지 트랜스포머(DiT)를 활용한 문서 이해 모델로, 비정형 문서의 레이아웃 인식 및 정보 추출에 활용되는 핵심 논문이다.