왜 하이브리드 추천인가 — 단일 추천 엔진의 한계
개인화 추천 시스템을 설계할 때 가장 먼저 부딪히는 질문은 “어떤 엔진 하나로 충분하지 않을까?“입니다. 결론부터 말씀드리면, 단일 엔진만으로는 실서비스 수준의 추천 품질을 달성하기 어렵습니다. 각 접근법의 한계를 짚어 보겠습니다.
협업 필터링(Collaborative Filtering) — Amazon Personalize
Amazon Personalize는 사용자-아이템 상호작용 데이터를 기반으로 개인화 추천을 제공합니다. 그러나 신규 사용자나 신규 아이템처럼 상호작용 이력이 부족한 콜드스타트(Cold Start) 상황에서는 추천 품질이 눈에 띄게 떨어집니다. “왜 이 아이템을 추천했는지"에 대한 콘텐츠 맥락(Content Context)도 부족해서, 사용자가 지금 검색하거나 관심을 보이는 주제와 동떨어진 결과가 나올 수 있습니다.
키워드/시맨틱 검색(Keyword & Semantic Search) — OpenSearch
OpenSearch의 BM25 키워드 검색이나 k-NN 기반 시맨틱 검색은 콘텐츠 자체의 관련성을 잘 포착합니다. 하지만 검색은 본질적으로 **쿼리 중심(query-centric)**이기 때문에, 개별 사용자의 과거 행동 패턴이나 선호도를 반영한 개인화가 어렵습니다. 같은 쿼리를 입력하면 모든 사용자에게 동일한 결과가 반환되는 것이 대표적인 예입니다.
LLM 단독 추천
최근 GPT 계열 모델을 직접 추천에 활용하려는 시도가 늘고 있지만, 실제로 써보면 근본적인 제약에 부딪힙니다. 우선 환각(Hallucination) 문제로 존재하지 않는 상품이나 콘텐츠를 그럴듯하게 생성해 버립니다. 실시간 사용자 행동 데이터나 최신 카탈로그 정보를 모델 내부에 반영할 수 없어 추천의 신선도(freshness)도 떨어집니다. 대규모 카탈로그 전체를 프롬프트에 담는 것 역시 토큰 제한과 비용 측면에서 비현실적입니다.

개인적으로 이 세 엔진은 각각의 약점이 다른 엔진의 강점으로 보완되는 구조라고 생각합니다. 협업 필터링의 콜드스타트는 콘텐츠 검색이 메워주고, 검색의 비개인화는 협업 필터링이 커버합니다. 두 엔진 모두 부족한 자연어 이해와 설명력은 LLM이 채워줄 수 있습니다. 다음 섹션에서는 이 세 엔진을 실제로 어떻게 조합하는지 아키텍처 수준에서 살펴보겠습니다.
핵심 구성 요소별 역할과 강점 분석
단일 엔진의 한계를 극복하기 위해, 이 아키텍처에서는 세 가지 구성 요소가 각자의 강점을 살려 서로의 약점을 보완합니다. 각 컴포넌트가 어떤 역할을 담당하는지 살펴보겠습니다.
Amazon Personalize: 행동 기반 협업 필터링
Amazon Personalize는 사용자-아이템 상호작용(Interaction) 데이터를 기반으로 실시간 협업 필터링(Collaborative Filtering)을 수행합니다. 핵심 레시피인 User-Personalization은 클릭, 구매, 평점 등의 행동 패턴에서 사용자 잠재 선호를 학습하고, Similar-Items 레시피는 아이템 간 관계를 모델링하여 연관 추천을 생성합니다. 개인적으로 가장 강력하다고 느끼는 부분은, 실시간 이벤트 수집을 통해 세션 내 행동 변화를 즉시 추천에 반영한다는 점입니다.
# Amazon Personalize 실시간 추천 호출 예시
import boto3
personalize_runtime = boto3.client('personalize-runtime')
response = personalize_runtime.get_recommendations(
campaignArn='arn:aws:personalize:ap-northeast-2:123456789012:campaign/my-campaign',
userId='user_001',
numResults=20
)
personalize_items = [item['itemId'] for item in response['itemList']]
Amazon OpenSearch: 하이브리드 시맨틱 검색
OpenSearch는 콘텐츠 속성 기반의 후보 생성(Candidate Generation)을 담당합니다. k-NN 벡터 검색으로 의미적 유사도를 포착하고, BM25 텍스트 검색으로 키워드 정확도를 보장하는 하이브리드 쿼리를 구성할 수 있습니다. 이 조합 덕분에 Personalize가 커버하지 못하는 신규 아이템이나 롱테일 콘텐츠도 효과적으로 검색할 수 있습니다.
# OpenSearch 하이브리드 검색 쿼리 예시
hybrid_query = {
"query": {
"hybrid": {
"queries": [
{"match": {"description": "무선 노이즈캔슬링 헤드폰"}},
{"knn": {"embedding": {"vector": query_vector, "k": 20}}}
]
}
}
}
LLM (Amazon Bedrock): 지능형 오케스트레이터
실제로 써보면 가장 체감 효과가 큰 부분이 바로 LLM의 역할입니다. Bedrock 기반 LLM은 크게 두 가지 일을 합니다. 먼저, Personalize와 OpenSearch에서 각각 생성된 후보 목록을 사용자 맥락에 맞게 Re-ranking합니다. 그리고 “이 상품은 최근 구매하신 A와 스타일이 유사하여 추천드립니다"와 같은 자연어 설명(Explanation)을 생성합니다. 여기에 더해, 모호한 사용자 쿼리를 분석하여 의도를 파악하고 쿼리를 확장(Query Expansion)하는 역할도 수행하므로 검색 품질이 한층 올라갑니다.
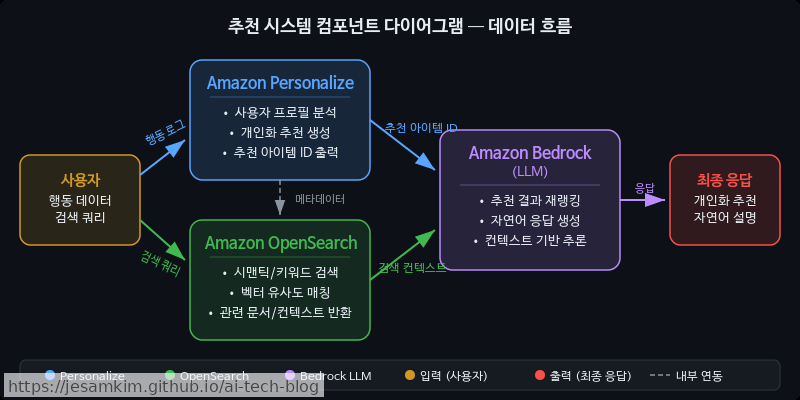
이 세 요소는 독립적으로도 충분히 쓸모가 있지만, 파이프라인으로 결합했을 때 각각의 한계를 상쇄하며 추천 품질이 확연히 좋아집니다. 다음 섹션에서는 이들을 실제로 어떻게 연결하는지 전체 아키텍처를 살펴보겠습니다.
하이브리드 추천 아키텍처 설계
앞서 살펴본 각 구성 요소의 강점을 실제 시스템으로 엮으려면, 명확한 파이프라인 설계가 필요합니다. 개인적으로 가장 효과적이라고 느낀 구조는 3단계 파이프라인입니다.
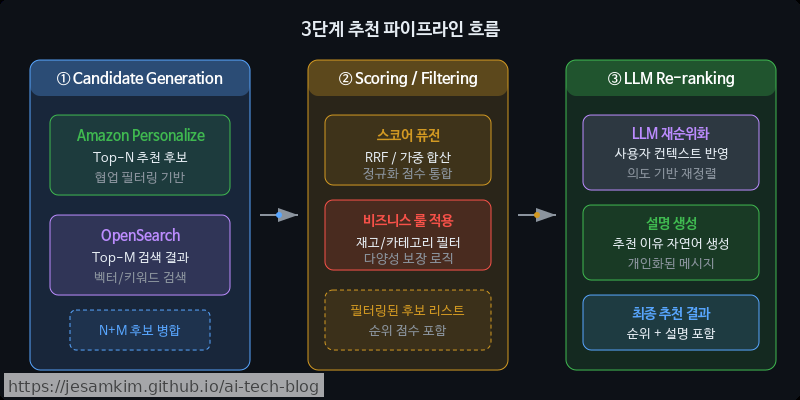
1단계: 후보 생성 (Candidate Generation)
Amazon Personalize에서 협업 필터링(Collaborative Filtering) 기반 Top-N 후보를, OpenSearch 시맨틱 검색(k-NN)으로 Top-M 후보를 동시에 가져옵니다. 두 소스를 병렬 호출하면 레이턴시 증가를 최소화할 수 있습니다.
2단계: 스코어링 및 필터링
두 후보 리스트를 하나로 병합할 때는 Reciprocal Rank Fusion(RRF) 전략을 추천합니다. 실제로 써보면 구현이 간단하면서도 결과가 상당히 안정적입니다. 각 아이템의 순위 역수를 합산해 최종 스코어를 산출하는 방식입니다.
def reciprocal_rank_fusion(ranked_lists: list[list[str]], k: int = 60) -> dict[str, float]:
"""
Reciprocal Rank Fusion (Cormack et al., 2009)
ranked_lists: 각 소스별 아이템 ID의 순위 리스트
k: 스무딩 상수 (기본값 60)
"""
fused_scores: dict[str, float] = {}
for ranked_list in ranked_lists:
for rank, item_id in enumerate(ranked_list, start=1):
fused_scores[item_id] = fused_scores.get(item_id, 0.0) + 1.0 / (k + rank)
return dict(sorted(fused_scores.items(), key=lambda x: x[1], reverse=True))
# 사용 예시
personalize_candidates = ["item_A", "item_B", "item_C", "item_D"]
opensearch_candidates = ["item_C", "item_E", "item_A", "item_F"]
final_ranking = reciprocal_rank_fusion([personalize_candidates, opensearch_candidates])
비즈니스 룰(재고 없는 상품 제외, 연령 제한 등)은 이 단계에서 필터링합니다.
3단계: LLM 기반 Re-ranking 및 설명 생성
퓨전된 상위 후보를 LLM(예: Amazon Bedrock의 Claude)에 전달하여, 사용자 컨텍스트에 맞게 최종 순서를 조정하고 “이 상품을 추천하는 이유” 설명을 자연어로 생성합니다.
오케스트레이션 설계
실시간 추천은 AWS Lambda로 처리하고, 대규모 사용자 대상 배치 추천은 Step Functions로 분리하는 편이 운영 안정성 면에서 낫습니다. 실시간 경로에서는 1·2단계 결과를 캐싱(ElastiCache)해서 LLM 호출 빈도를 줄이고, 배치 경로에서는 Step Functions가 Personalize 배치 추론, RRF 병합, LLM 설명 생성을 순차적으로 오케스트레이션합니다.
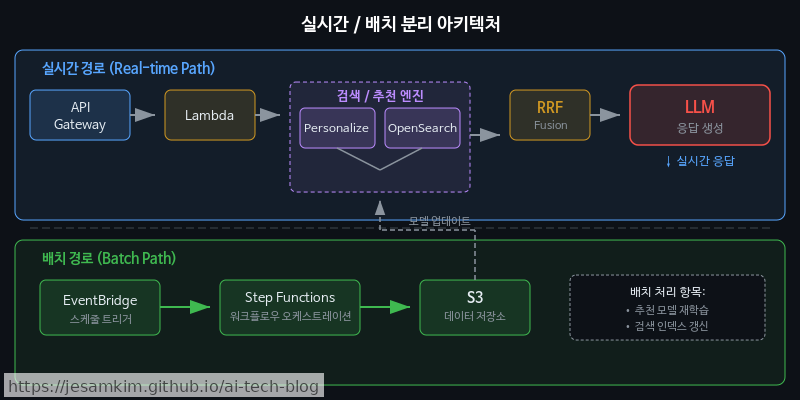
이렇게 파이프라인을 명확히 분리해 두면 각 단계를 독립적으로 튜닝하거나 교체할 수 있어서, 장기적으로 유지보수가 훨씬 수월해집니다.
LLM 통합 전략 — RAG 기반 추천 강화
앞서 설계한 하이브리드 아키텍처가 어떤 아이템을 추천할지 결정하는 단계였다면, 이번 섹션에서는 LLM을 활용해 추천 결과를 더 정교하게 다듬고 설명하는 전략을 다룹니다.
컨텍스트 주입을 통한 개인화 Re-ranking
핵심 아이디어는 간단합니다. Amazon Personalize와 OpenSearch가 생성한 추천 후보 리스트와 사용자 프로필을 RAG(Retrieval-Augmented Generation) 컨텍스트로 LLM에 주입하여, 최종 순위를 재조정하는 것입니다.
import json
from langchain.prompts import PromptTemplate
from langchain_aws import ChatBedrock
llm = ChatBedrock(model_id="anthropic.claude-sonnet-4-20250514", region_name="us-east-1")
rerank_prompt = PromptTemplate.from_template("""
당신은 개인화 추천 전문가입니다.
## 사용자 프로필
- 선호 장르: {preferred_genres}
- 최근 시청 이력: {recent_items}
- 시청 시간대: {watch_time_pattern}
## 추천 후보 아이템
{candidate_items}
## 지시사항
1. 위 사용자 프로필을 기반으로 후보 아이템의 순위를 재조정하세요.
2. 각 아이템에 대해 추천 이유를 한 문장으로 설명하세요.
3. 결과를 JSON 배열로 반환하세요. 각 객체는 "item_id", "rank", "reason" 키를 포함합니다.
""")
def rerank_with_llm(user_profile: dict, candidates: list[dict]) -> list[dict]:
chain = rerank_prompt | llm
response = chain.invoke({
"preferred_genres": ", ".join(user_profile["genres"]),
"recent_items": json.dumps(user_profile["recent_items"], ensure_ascii=False),
"watch_time_pattern": user_profile["watch_time"],
"candidate_items": json.dumps(candidates, ensure_ascii=False),
})
return json.loads(response.content)
Explainable Recommendation 구현
개인적으로 이 부분이 LLM 통합에서 가장 큰 가치를 느끼는 지점입니다. 기존 추천 시스템은 “왜 이 아이템을 추천했는지” 사용자에게 전달하기 어려웠습니다. LLM을 통하면 “최근 시청한 SF 영화와 유사한 세계관의 작품입니다” 같은 자연어 설명을 생성할 수 있습니다. 실제로 써보면, 단순히 아이템을 나열하는 것보다 추천 이유가 함께 제공될 때 사용자의 클릭률이 눈에 띄게 올라가는 걸 체감할 수 있습니다.
프롬프트 엔지니어링 핵심 패턴
효과적인 Re-ranking 프롬프트를 설계할 때 두 가지 패턴을 짚어보겠습니다.
- 페르소나 설정:
"당신은 10년 경력의 콘텐츠 큐레이터입니다"처럼 역할을 명시하면 도메인에 맞는 판단 기준이 적용됩니다. - 아이템 속성 구조화: 장르, 감독, 평점 등 메타데이터를 정형화된 포맷으로 전달해야 LLM이 속성 간 비교를 정확히 수행합니다.
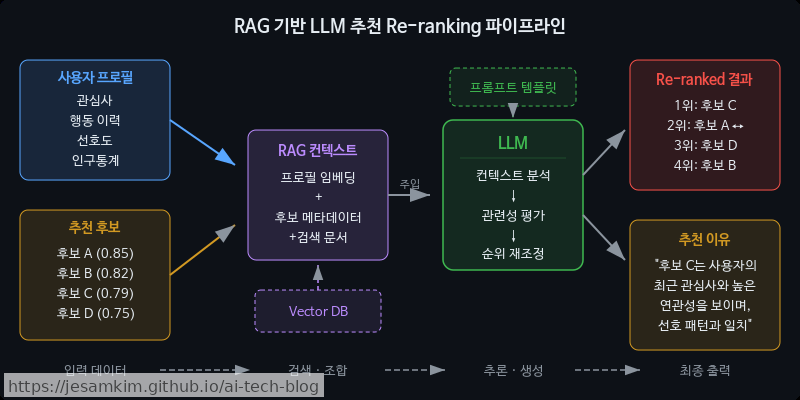
한 가지 주의할 점이 있습니다. LLM 호출은 레이턴시(Latency)와 비용을 수반하므로, 모든 요청에 적용하기보다는 상위 N개 후보에 대해서만 Re-ranking을 적용하는 편이 실용적입니다.
References
Amazon Personalize 개발자 가이드 — Amazon Personalize 공식 문서 https://docs.aws.amazon.com/personalize/latest/dg/what-is-personalize.html
Amazon OpenSearch Service 개발자 가이드 — Amazon OpenSearch Service 공식 문서 https://docs.aws.amazon.com/opensearch-service/latest/developerguide/what-is.html
Amazon Bedrock 사용자 가이드 — Amazon Bedrock 공식 문서 https://docs.aws.amazon.com/bedrock/latest/userguide/what-is-bedrock.html
Amazon Personalize 레시피(Recipes) 가이드 — 추천 알고리즘 레시피 선택에 관한 공식 문서 https://docs.aws.amazon.com/personalize/latest/dg/working-with-predefined-recipes.html
Amazon OpenSearch Service의 k-NN 검색 — 벡터 유사도 검색(k-NN) 공식 문서 https://docs.aws.amazon.com/opensearch-service/latest/developerguide/knn.html
Amazon Personalize를 활용한 실시간 개인화 추천 — AWS Blog https://aws.amazon.com/blogs/machine-learning/creating-a-recommendation-engine-using-amazon-personalize/
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks — RAG 기법의 기초가 되는 논문 (Lewis et al., 2020) https://arxiv.org/abs/2005.11401
Amazon OpenSearch Service에서의 시맨틱 검색 구현 — AWS Blog https://aws.amazon.com/blogs/big-data/amazon-opensearch-services-vector-database-capabilities-explained/
Recommender Systems Handbook (3rd Edition) — 추천 시스템의 협업 필터링, 콘텐츠 기반 필터링, 하이브리드 접근법에 관한 종합 참고서 (Ricci, Rokach, Shapira 저) https://link.springer.com/book/10.1007/978-1-0716-2197-4
A Survey on Large Language Models for Recommendation — LLM을 추천 시스템에 적용하는 최신 연구 동향을 정리한 서베이 논문 (Wu et al., 2024) https://arxiv.org/abs/2305.19860
AWS Well-Architected Framework — Machine Learning Lens — ML 워크로드의 아키텍처 모범 사례 공식 문서 https://docs.aws.amazon.com/wellarchitected/latest/machine-learning-lens/machine-learning-lens.html AWS Well-Architected Framework의 머신러닝 렌즈로, 하이브리드 추천 시스템 아키텍처 설계 시 참고할 수 있는 모범 사례를 제공한다.