왜 프루닝인가 — 모델 압축의 필요성과 프루닝의 위치
GPT-3의 175B 파라미터가 세상을 놀라게 한 것이 불과 몇 년 전인데, 이제는 LLaMA 70B를 “비교적 작은 모델"이라 부르는 시대가 되었습니다. 모델 크기가 폭증하면서 추론 비용, GPU 메모리, 응답 지연(latency) 문제는 더 이상 연구실만의 고민이 아니라 서비스 전체의 병목이 되고 있습니다. 개인적으로 70B 모델을 단일 A100 80GB에 올려보려 할 때마다 OOM(Out of Memory)을 마주치는데, 이럴 때 압축의 필요성을 절실히 느끼게 됩니다.
모델 압축 기법의 전체 지형도
이 문제를 해결하기 위한 대표적인 모델 압축(Model Compression) 기법은 다음과 같습니다.
- 프루닝(Pruning): 중요도가 낮은 가중치나 뉴런을 제거하여 모델을 희소(sparse)하게 만듭니다.
- 양자화(Quantization): FP16 → INT8 → INT4처럼 가중치의 비트 수를 줄여 메모리와 연산량을 절감합니다.
- 지식 증류(Knowledge Distillation): 큰 교사 모델(teacher)의 지식을 작은 학생 모델(student)로 전이합니다.
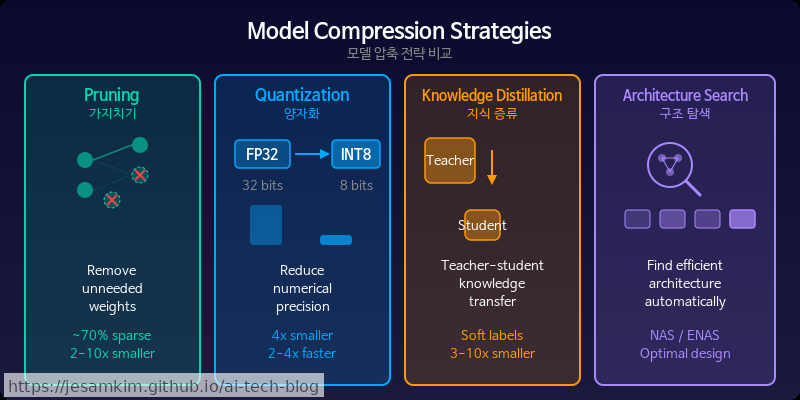
이 세 기법은 경쟁 관계가 아니라 상호 보완적입니다. 실제로 써보면, 프루닝으로 50% 희소화한 모델에 INT4 양자화를 함께 적용했을 때 단독 기법 대비 훨씬 공격적인 압축률을 달성할 수 있습니다. SparseGPT + GPTQ 조합이 대표적인 사례입니다.
구조적 프루닝 vs 비구조적 프루닝
프루닝은 제거 단위에 따라 두 갈래로 나뉩니다.
| 구분 | 구조적 프루닝 (Structured) | 비구조적 프루닝 (Unstructured) |
|---|---|---|
| 제거 단위 | 필터, 헤드, 레이어 등 블록 단위 | 개별 가중치(weight) 단위 |
| 하드웨어 친화성 | 높음 — 별도 커널 없이 속도 향상 | 낮음 — 희소 행렬 연산 지원 필요 |
| 압축률 대비 정확도 | 상대적으로 낮음 | 상대적으로 높음 |
import torch
# 비구조적 프루닝: 크기가 작은 개별 가중치를 0으로
def unstructured_prune(weight: torch.Tensor, sparsity: float):
threshold = torch.quantile(weight.abs(), sparsity)
mask = weight.abs() >= threshold
return weight * mask # 임계값 미만 → 0
# 구조적 프루닝: L2 노름이 작은 출력 채널(행) 전체를 제거
def structured_prune(weight: torch.Tensor, prune_ratio: float):
n_prune = int(weight.shape[0] * prune_ratio)
norms = weight.norm(dim=1)
keep_idx = norms.topk(weight.shape[0] - n_prune).indices
return weight[keep_idx]
비구조적 프루닝은 이론적 압축률이 뛰어나지만, 실제 속도 이득을 얻으려면 NVIDIA의 2:4 희소성 같은 하드웨어 수준 지원이 필요합니다. 반면 구조적 프루닝은 기존 dense 커널만으로도 즉시 추론 속도가 빨라집니다. 어떤 쪽을 택할지는 타겟 하드웨어와 허용 가능한 정확도 손실에 따라 달라집니다.
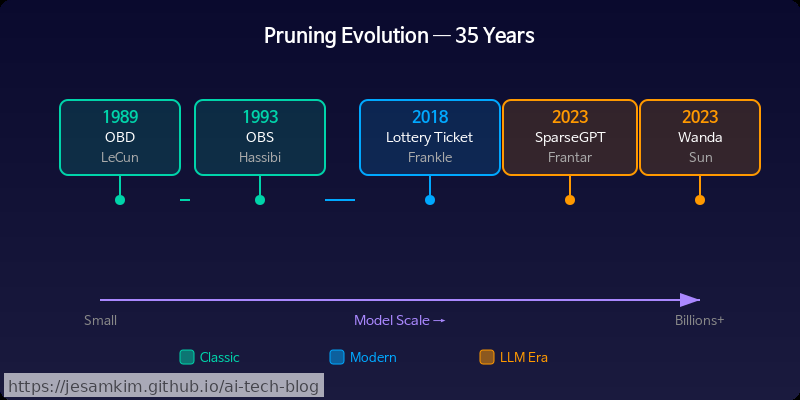
이처럼 프루닝은 모델 압축 도구 상자에서 모델 구조 자체를 깎아내는 가장 직접적인 수단이며, 그 역사는 무려 35년 전으로 거슬러 올라갑니다.
원조 — Optimal Brain Damage (1989)와 Optimal Brain Surgeon (1993)
프루닝이 왜 필요한지를 살펴봤으니, 이제 어떻게 가중치를 골라 잘라낼 것인가라는 질문으로 넘어가 보겠습니다. 이 질문에 최초로 체계적인 답을 내놓은 두 논문이 바로 Optimal Brain Damage(OBD)와 Optimal Brain Surgeon(OBS)입니다.
OBD — 대각 Hessian으로 “중요도"를 매기다
LeCun 등이 1989년에 제안한 OBD는 놀라울 정도로 직관적인 아이디어에서 출발합니다. 손실 함수 L을 가중치 w_i 주변에서 2차 테일러 전개하면, 특정 가중치 하나를 0으로 만들었을 때 손실이 얼마나 변하는지를 추정할 수 있습니다.
δL ≈ ½ · h_ii · w_i², h_ii = ∂²L/∂w_i²
여기서 핵심 가정은 Hessian의 비대각 항을 무시(대각 근사)하는 것입니다. 이 근사 덕분에 각 가중치의 중요도(saliency)를 독립적으로, 저렴하게 계산할 수 있게 됩니다. saliency가 작은 가중치부터 순서대로 제거하면 손실 증가를 최소화하면서 네트워크를 압축할 수 있다는 것이 OBD의 골자입니다.
# OBD saliency 계산 (개념 코드)
import torch
def obd_saliency(weight: torch.Tensor, hessian_diag: torch.Tensor):
"""각 가중치의 saliency = 0.5 * h_ii * w_i^2"""
return 0.5 * hessian_diag * weight ** 2
OBS — 잘라낸 뒤 “나머지를 보정"하다
Hasselmo & Stork(1993)가 제안한 OBS는 OBD의 대각 근사가 지나치게 거칠다는 점을 지적하며 한 걸음 더 나아갑니다. Full Hessian의 역행렬 H⁻¹을 활용해, 가중치 w_q를 제거한 뒤 나머지 가중치를 다음과 같이 보정합니다.
δ w = -w_q[H⁻¹]_1 , H⁻¹ e_q
이 보정(weight update) 덕분에 OBD보다 훨씬 적은 정확도 손실로 가중치를 제거할 수 있습니다. 다만 H⁻¹을 구하는 데 O(n^3) 연산이 필요하다는 치명적인 비용 문제가 있었습니다. 당시 수백~수천 파라미터 규모의 네트워크에서도 부담스러운 수준이었습니다.
두 논문이 남긴 유산
개인적으로 이 두 논문의 가장 큰 기여는 특정 알고리즘 자체보다 프루닝의 기본 패러다임을 확립했다는 점이라고 생각합니다. 정리하면 다음 두 축입니다.
- 2차 근사 기반 중요도 측정 — 단순히 절댓값이 작은 가중치를 자르는 magnitude pruning이 아니라, 손실 함수의 곡률(curvature) 정보까지 고려합니다.
- 제거 후 보정(post-pruning compensation) — 가중치를 잘라내고 끝이 아니라, 남은 가중치를 재조정해 정확도 하락을 최소화합니다.
이후 35년간 등장하는 거의 모든 프루닝 기법은, 곧 살펴볼 SparseGPT까지 포함해, 결국 이 두 축 위에서 “Hessian 계산을 어떻게 효율화할 것인가"와 “보정을 얼마나 정밀하게 할 것인가"를 개선하는 방향으로 발전해 왔습니다.
전환점 — Lottery Ticket Hypothesis (2018)
OBD와 OBS가 “어떤 가중치를 잘라야 하는가"에 집중했다면, 2018년 Frankle & Carlin이 제시한 Lottery Ticket Hypothesis(LTH)는 질문 자체를 뒤집었습니다. “왜 sparse network가 처음부터 학습되지 않는가?“라는 물음이었습니다.
핵심 주장
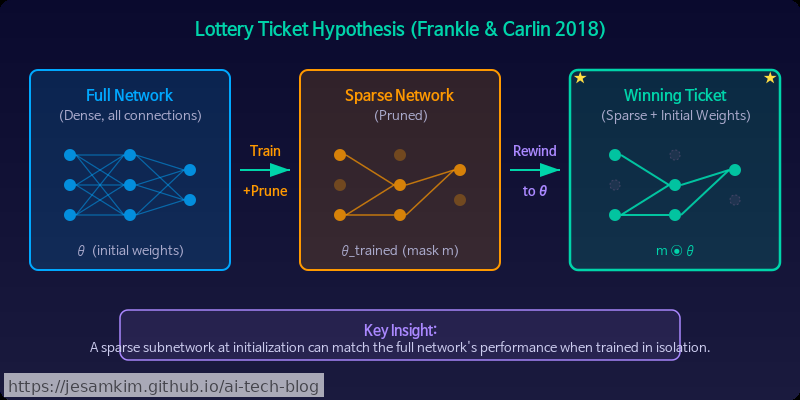
LTH의 핵심은 직관적입니다. 랜덤 초기화된 dense 네트워크 안에는, 독립적으로 학습시켰을 때 원래 네트워크와 동일한 성능에 도달할 수 있는 sparse subnetwork, 이른바 “winning ticket"이 이미 존재한다는 것입니다. 복권처럼 초기화 시점에 이미 당첨 번호가 숨어 있다는 비유가 논문 제목의 유래입니다.
실험 설계: Iterative Magnitude Pruning (IMP)
Winning ticket을 찾는 과정은 Iterative Magnitude Pruning(IMP)으로 구성됩니다. 프루닝 후 남은 가중치를 현재 값이 아닌 **초기 가중치(initial weights)로 되감기(rewinding)**한 뒤 재학습한다는 점이 핵심입니다.
# LTH — Iterative Magnitude Pruning 의사코드
import copy
model = initialize_model()
initial_weights = copy.deepcopy(model.state_dict()) # θ_0 저장
mask = k: torch.ones_like(v) for k, v in model.named_parameters()
for round in range(num_rounds):
# 1) 현재 mask 적용 + 초기 가중치로 되감기
apply_mask_and_rewind(model, mask, initial_weights)
# 2) 학습
train(model, mask)
# 3) magnitude 기준 하위 p%를 추가 프루닝
mask = prune_lowest_magnitude(model, mask, prune_ratio=0.2)
# 최종 남은 subnetwork = winning ticket
실험 결과는 꽤 놀라웠습니다. MNIST나 CIFAR-10 수준의 네트워크에서 원래 파라미터의 10–20%만으로도 full network와 동등하거나 더 나은 성능이 나왔습니다. 단, 반드시 초기 가중치로 되감아야만 이 현상이 재현되었습니다.
왜 전환점인가
개인적으로 LTH가 프루닝 연구사에서 가장 중요한 논문이라고 생각합니다. 프루닝을 단순한 후처리 압축 기법이 아니라 학습 역학(training dynamics)의 문제로 끌어올렸기 때문입니다. 이후 연구 방향이 눈에 띄게 달라졌습니다.
처음부터 sparse 상태로 학습하는 연구(RigL, SET 등)가 본격화되었고, SNIP이나 GraSP처럼 학습 없이 초기화 시점에 winning ticket을 찾으려는 시도도 이어졌습니다. 초기 가중치가 아닌 학습 초기 시점으로 되감는 변형(early-bird ticket)도 등장했습니다.
실제로 써보면 IMP는 반복 학습 비용이 막대해서 대규모 모델에 직접 적용하기는 어렵습니다. 그러나 “올바른 구조를 찾는 것이 올바른 가중치를 찾는 것만큼 중요하다"는 통찰은, 이후 구조화 프루닝과 LLM 시대의 효율적 프루닝 기법들에 결정적인 영감을 주게 됩니다.
LLM 시대의 프루닝: SparseGPT (2023)
Lottery Ticket Hypothesis가 “좋은 서브네트워크는 존재한다"는 희망을 보여줬다면, 현실적인 질문은 따로 있었습니다. 수십억~수천억 개 파라미터를 가진 LLM에서, 재학습(fine-tuning) 없이 단 한 번의 프루닝(one-shot pruning)으로 성능을 유지할 수 있을까요? GPT-175B 규모의 모델을 반복 학습하며 프루닝하는 건 비용상 사실상 불가능합니다.
Frantar & Alistarh (2023)가 제안한 SparseGPT는 이 문제에 꽤 실용적인 답을 내놓았습니다. 핵심 아이디어는 OBS(Optimal Brain Surgeon)의 Hessian 기반 가중치 보정을 대규모로 확장하는 데 있습니다. 전체 모델의 Hessian을 한꺼번에 다루는 대신 레이어별(row-wise)로 분리하고, 각 레이어의 가중치 행렬을 column 단위로 순차 처리하면서 Hessian inverse를 점진적으로 업데이트하는 방식입니다.
구체적으로 보면, 각 열 j에서 프루닝할 가중치를 선택한 뒤 OBS 공식에 따라 남아 있는 가중치들을 보정하여 레이어 출력 오차를 최소화합니다. Hessian inverse의 업데이트가 column 제거 시 닫힌 형태(closed-form)로 계산되기 때문에, 별도의 역행렬 재계산 없이 O(d_col · d_row · d_col) 수준의 비용으로 처리할 수 있습니다.
# SparseGPT 핵심 루프 (간소화된 의사 코드)
for j in range(n_columns):
# 현재 열에서 프루닝할 인덱스 선택 (magnitude / Hessian 기준)
prune_mask = select_prune_indices(W[:, j], H_inv[j, j], sparsity)
# 프루닝된 가중치의 오차를 남은 열들에 보정
error = W[:, j] * prune_mask
W[:, j][prune_mask] = 0.0
W[:, j+1:] -= error.unsqueeze(1) @ H_inv[j, j+1:].unsqueeze(0) / H_inv[j, j]
결과는 꽤 인상적입니다. SparseGPT는 OPT-175B, BLOOM-176B 같은 초대형 모델에서 50~60% 비구조적 희소성(unstructured sparsity)을 달성하면서도 perplexity 저하가 미미했습니다. 단일 GPU에서 수 시간이면 프루닝이 끝납니다.
개인적으로 가장 의미 있다고 느끼는 지점은, 1993년 OBS에서 제안된 Hessian inverse 기반 보정이라는 아이디어가 30년 만에 프로덕션 규모의 LLM에 적용 가능해졌다는 사실입니다. 이론적 우아함이 엔지니어링적 스케일링을 만나 비로소 실용성을 갖추게 된 셈입니다.
References
LeCun, Y., Denker, J. S., & Solla, S. A. (1989). “Optimal Brain Damage.” Advances in Neural Information Processing Systems (NeurIPS) 2. https://proceedings.neurips.cc/paper/1989/file/6c9882bbac1c7093bd25041881277658-Paper.pdf
Hassibi, B. & Stork, D. G. (1993). “Second Order Derivatives for Network Pruning: Optimal Brain Surgeon.” IEEE International Conference on Neural Networks. https://proceedings.neurips.cc/paper/1992/file/303ed4c69846ab36c2904d3ba8573050-Paper.pdf
Frankle, J. & Carlin, M. (2019). “The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks.” ICLR 2019. https://arxiv.org/abs/1803.03635
Frantar, E. & Alistarh, D. (2023). “SparseGPT: Massive Language Models Can Be Accurately Pruned in One-Shot.” ICML 2023. https://arxiv.org/abs/2301.00774
Sun, M., Liu, Z., Bair, A., & Kolter, J. Z. (2024). “A Simple and Effective Pruning Approach for Large Language Models.” ICLR 2024. https://arxiv.org/abs/2306.11695
Hoefler, T., Alistarh, D., Ben-Nun, T., Dryden, N., & Peste, A. (2021). “Sparsity in Deep Learning: Pruning and Growth for Efficient Inference and Training in Neural Networks.” Journal of Machine Learning Research, 22(241), 1–124. 딥러닝 희소성 기법 전반을 체계적으로 정리한 서베이 논문. https://arxiv.org/abs/2102.00554
Zhu, M. & Gupta, S. (2017). “To Prune, or Not to Prune: Exploring the Efficacy of Pruning for Model Compression.” NeurIPS 2017 Workshop. 점진적(gradual) magnitude pruning의 효과를 실증적으로 분석한 연구. https://arxiv.org/abs/1710.01878
Frantar, E., Ashkboos, S., Hoefler, T., & Alistarh, D. (2022). “GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers.” ICLR 2023. SparseGPT와 동일한 연구 그룹에서 제안한 LLM 양자화 기법으로, 프루닝과 결합하여 모델 압축에 활용 가능. https://arxiv.org/abs/2210.17323