왜 지금 ‘통합 데이터·AI 플랫폼’ 전쟁인가
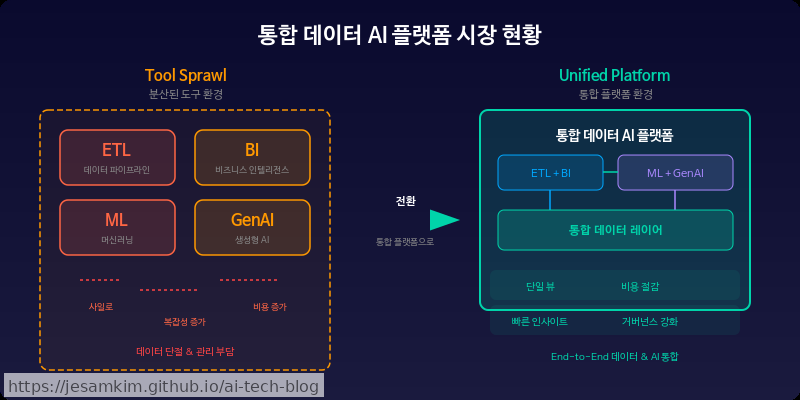
2024년 하반기, 엔터프라이즈 데이터 팀의 주요 고민 중 하나은 “도구가 너무 많다"는 것이었습니다. 데이터 엔지니어링(Data Engineering)은 Spark 클러스터에서, 분석(Analytics)은 SQL 웨어하우스에서, ML 학습은 또 다른 노트북 환경에서 돌아갑니다. 이렇게 파편화된 워크플로를 하나로 엮으려는 수요가 폭발적으로 늘고 있습니다.
개인적으로 여러 엔터프라이즈 프로젝트를 지켜보면, ETL에서 분석, ML 모델링, GenAI 서빙까지 이어지는 파이프라인에서 컨텍스트 스위칭(context switching) 비용이 전체 생산성의 상당 부분 이상을 잡아먹는 경우가 흔합니다. 바로 이 지점을 두 거인이 동시에 노리고 있습니다.
AWS re:Invent 2024에서 발표된 SageMaker Unified Studio는 단순한 제품 업데이트가 아니었습니다. 기존에 각각 독립적으로 운영되던 SageMaker, Glue, Athena, Redshift를 단일 프로젝트 공간(single project space) 안에 통합하겠다는 전략적 선언이었습니다. 실제로 써보면, 하나의 노트북에서 Glue 카탈로그를 탐색하고 Redshift 쿼리를 날린 뒤 바로 SageMaker 학습 잡(training job)을 트리거할 수 있다는 점이 가장 체감되는 변화입니다.
반대편에서 Databricks(데이터브릭스)는 이미 Data Intelligence Platform 비전 아래 Unity Catalog를 중심으로 데이터 거버넌스·분석·ML·GenAI를 하나의 레이크하우스(Lakehouse)에서 처리하는 구조를 수년간 다져왔습니다. Mosaic AI 인수 이후에는 LLM 파인튜닝(fine-tuning)과 서빙까지 플랫폼 안으로 끌어들인 상태이기도 합니다.
결국 양쪽 모두 “데이터가 있는 곳에서 바로 AI를 만든다"는 동일한 명제를 향해 달려가고 있습니다. 이것이 2025년 현재 가장 뜨거운 플랫폼 전쟁의 본질입니다. 다음 섹션에서는 이 두 플랫폼의 아키텍처를 구체적으로 뜯어보겠습니다.
아키텍처 철학 비교: 통합의 방식이 다르다
통합 플랫폼에 대한 시장의 요구가 뚜렷해진 가운데, AWS와 Databricks는 서로 다른 철학으로 이 문제를 풀고 있습니다.
SageMaker Unified Studio — “AWS 서비스들의 단일 관제탑”
SageMaker Unified Studio는 기존에 흩어져 있던 AWS 네이티브 서비스들을 프로젝트 기반 워크스페이스(Project-based Workspace) 하나로 묶는 접근입니다. Amazon Bedrock, EMR, Redshift, Glue, Athena 등 이미 성숙한 서비스들을 개별 콘솔을 오가며 쓰는 대신, 단일 UI에서 연결해 사용할 수 있습니다.
Databricks — “레이크하우스 위의 멀티클라우드 단일 플랫폼”
반면 Databricks는 Lakehouse Architecture 위에 Unity Catalog를 중심으로 데이터, 모델, 피처, 권한을 하나의 거버넌스 레이어로 통합합니다. AWS, Azure, GCP 어디에서든 동일한 경험을 제공하는 것이 핵심 전략입니다.
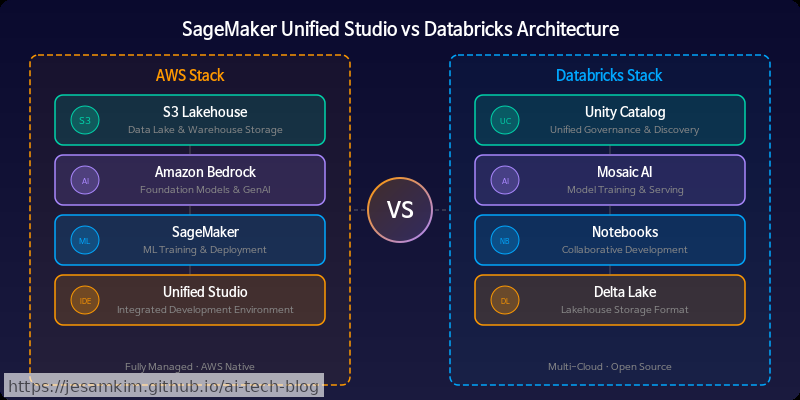
핵심 차이: 통합의 축이 다릅니다
| 비교 항목 | SageMaker Unified Studio | Databricks |
|---|---|---|
| 통합 방식 | AWS 서비스 오케스트레이션 | 자체 엔진 + Unity Catalog |
| 클라우드 전략 | AWS 네이티브 (Single Cloud) | 멀티클라우드 (Cloud-agnostic) |
| 거버넌스 중심 | AWS Lake Formation + IAM | Unity Catalog |
| AI 통합 | Bedrock 직접 연결 | Mosaic AI + MLflow |
| 락인(Lock-in) 수준 | 높음 (AWS 생태계 종속) | 낮음 (클라우드 이식 가능) |
개인적으로 이 차이를 한 문장으로 요약하면, SageMaker Unified Studio는 “이미 AWS에 올인한 조직을 위한 최적의 통합"이고, Databricks는 “클라우드를 선택지로 남겨두고 싶은 조직을 위한 추상화 레이어"라고 생각합니다.
실제로 써보면 이 철학 차이가 가장 체감되는 순간은 프로젝트 초기 설정입니다. SageMaker Unified Studio에서는 프로젝트 생성 시 연결할 AWS 서비스를 프로파일(Profile)로 선택하는 구조입니다. Databricks에서는 Unity Catalog의 메타스토어(Metastore)를 어느 클라우드 리전에 배치할지를 먼저 결정하게 됩니다. 같은 “통합"이라는 단어를 쓰지만, 통합의 축 자체가 다른 셈입니다.
데이터 거버넌스와 카탈로그 전략
아키텍처 철학이 다르면 거버넌스를 구현하는 방식도 달라질 수밖에 없습니다. 두 플랫폼 모두 “중앙 집중식 거버넌스"를 표방하지만, 그 설계 원리는 상당히 다릅니다.
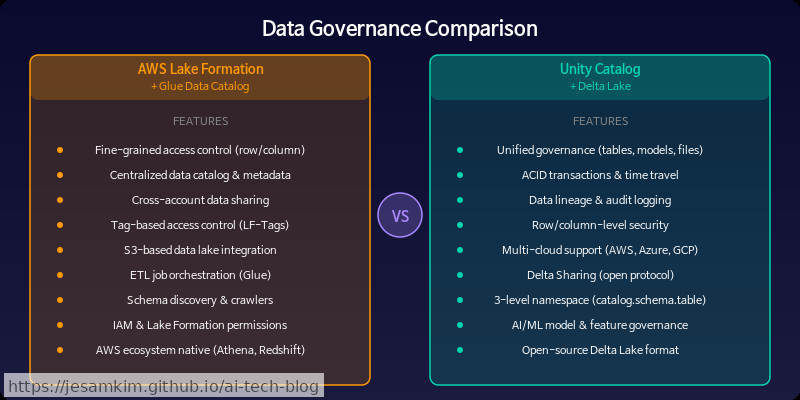
Amazon DataZone 기반 거버넌스: 퍼블리싱·구독 모델
SageMaker Unified Studio는 Amazon DataZone을 거버넌스 레이어로 활용합니다. 핵심 개념은 도메인(Domain) 단위로 데이터 자산을 퍼블리싱(publishing)하고, 다른 팀이 이를 구독(subscribe)하는 마켓플레이스형 모델입니다. 데이터 소유권은 생산 팀에 남아 있되, 소비 팀에게 제어된 접근을 허용하는 구조입니다. 대규모 엔터프라이즈에서 조직 간 데이터 공유가 빈번한 환경에 적합합니다.
Unity Catalog: 단일 네임스페이스 통합 거버넌스
Databricks는 Unity Catalog를 통해 테이블, ML 모델, 피처(Feature), 볼륨(파일)까지 catalog.schema.asset 형태의 3-레벨 네임스페이스 하나로 관리합니다. 실제로 써보면, 데이터 엔지니어가 만든 테이블과 ML 엔지니어가 등록한 모델이 동일한 권한 체계 안에서 검색·제어된다는 점이 상당히 편리합니다.
오픈 포맷 전쟁: Delta Lake vs Iceberg
거버넌스 전략은 테이블 포맷 선택과도 밀접하게 연결됩니다. Databricks는 자체 개발한 Delta Lake를 기본 포맷으로 사용하고, AWS 진영은 Apache Iceberg를 사실상 표준으로 밀고 있습니다. SageMaker Unified Studio에서 Athena, Redshift, EMR 등이 모두 Iceberg를 네이티브 지원하는 것이 대표적인 사례입니다.
개인적으로 주목하는 부분은, Databricks가 2024년 Delta Lake UniForm을 통해 Iceberg 호환 메타데이터를 자동 생성하기 시작했다는 점입니다. 포맷 전쟁이 “양자택일"에서 “상호 호환"으로 방향을 틀고 있다는 신호로 읽힙니다.
# Databricks: UniForm으로 Iceberg 호환 테이블 생성
spark.sql("""
CREATE TABLE catalog.schema.sales_data (
id BIGINT,
amount DOUBLE,
event_date DATE
)
USING DELTA
TBLPROPERTIES (
'delta.universalFormat.enabledFormats' = 'iceberg'
)
""")
# AWS Athena: 동일 데이터를 Iceberg 테이블로 직접 쿼리
# SELECT * FROM sales_data WHERE event_date > DATE '2025-01-01'
결국 거버넌스 전략의 선택은 조직 구조와 맞닿아 있습니다. 도메인 자율성과 승인 기반 공유를 중시한다면 DataZone 모델이, 자산 유형 전반을 하나의 권한 체계로 단순하게 묶고 싶다면 Unity Catalog가 더 자연스러운 선택입니다.
AI/ML 및 GenAI 워크플로 비교
거버넌스와 카탈로그가 데이터의 신뢰성을 담보한다면, 결국 그 데이터 위에서 가치를 만들어내는 건 AI/ML 워크플로입니다. 두 플랫폼 모두 GenAI 시대에 맞춰 엔드투엔드(End-to-End) ML 경험을 제공하지만, 접근 전략은 뚜렷하게 갈립니다.
SageMaker Unified Studio: AWS 생태계 원스톱
SageMaker Unified Studio는 SageMaker 노트북(Notebook), SageMaker 파이프라인(Pipelines), Amazon Bedrock IDE를 하나의 작업 환경에 통합합니다. 파운데이션 모델(Foundation Model) 미세조정(Fine-tuning)부터 엔드포인트 배포(Endpoint Deployment)까지 콘솔을 벗어나지 않고 진행할 수 있습니다.
# SageMaker Unified Studio에서 Bedrock 모델 호출 예시
import boto3, json
bedrock = boto3.client("bedrock-runtime", region_name="us-east-1")
response = bedrock.invoke_model(
modelId="anthropic.claude-3-sonnet-20240229-v1:0",
body=json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 512,
"messages": [{"role": "user", "content": "Summarize the quarterly report."}]
})
)
print(json.loads(response["body"].read()))
Bedrock을 통해 Claude, Titan, Llama 등 다양한 모델을 API 한 줄로 호출할 수 있고, SageMaker JumpStart에서 미세조정한 모델도 동일 파이프라인에서 서빙(Serving)할 수 있습니다.
Databricks: 오픈소스 중심 Mosaic AI
Databricks는 자체 개발한 DBRX 모델과 Mosaic AI 스택을 중심으로, MLflow 네이티브 통합과 Feature Serving, Function Serving까지 ML 라이프사이클 전반을 커버합니다. 실제로 써보면, MLflow Experiment Tracking이 노트북과 자연스럽게 연결되는 경험이 상당히 매끄럽습니다.
# Databricks Mosaic AI — Model Serving 엔드포인트 호출 예시
import requests
response = requests.post(
"https://docs.databricks.com/aws/en/machine-learning/model-serving/score-custom-model-endpoints",
headers={"Authorization": "Bearer <token>"},
json={"messages": [{"role": "user", "content": "Summarize the quarterly report."}]}
)
print(response.json())
GenAI 전략의 핵심 분기점
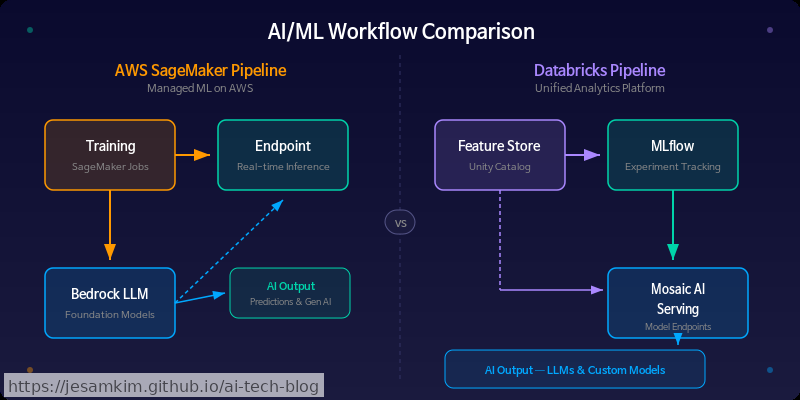
개인적으로 가장 큰 차이라고 느끼는 부분은 모델 소싱(Model Sourcing) 철학입니다.
| 비교 항목 | SageMaker Unified Studio | Databricks |
|---|---|---|
| 모델 접근 | Bedrock 마켓플레이스 (관리형 API) | 오픈소스 모델 직접 호스팅 + DBRX |
| 실험 추적 | SageMaker Experiments | MLflow (네이티브) |
| 서빙 | SageMaker Endpoint + Bedrock | Model Serving + Function Serving |
| 프롬프트 관리 | Bedrock IDE Prompt Flows | MLflow AI Gateway |
| 벤더 종속 | AWS 생태계 의존도 높음 | 멀티클라우드, 오픈소스 지향 |
AWS 올인(All-in) 환경에서 Bedrock의 상용 모델을 빠르게 활용하고 싶다면 SageMaker Unified Studio가 유리합니다. 반면 오픈소스 모델을 직접 커스터마이징하고 멀티클라우드 유연성까지 확보하려면 Databricks Mosaic AI 쪽이 자유도가 높습니다. 결국 조직이 관리형 편의성과 오픈소스 자유도 중 어디에 무게를 두느냐에 따라 선택이 달라집니다.
개발자 경험(DX)과 협업 모델
AI/ML 워크플로를 효과적으로 운영하려면 결국 개발자가 얼마나 매끄럽게 작업할 수 있는가가 플랫폼 선택의 기준이 됩니다. 거버넌스와 모델 학습 파이프라인이 아무리 잘 갖춰져 있어도, 일상적인 개발 경험(Developer Experience)이 불편하면 팀 전체의 생산성이 떨어지기 때문입니다.
SageMaker Unified Studio: 페르소나 기반 단일 워크스페이스
SageMaker Unified Studio는 하나의 프로젝트 안에서 SQL 에디터, 주피터 노트북(Jupyter Notebook), 비주얼 ETL 빌더, AI 앱 빌더를 모두 제공합니다. 데이터 엔지니어는 비주얼 ETL로 파이프라인을 구성하고, 데이터 분석가는 SQL 에디터에서 바로 쿼리를 실행합니다. ML 엔지니어는 노트북에서 모델을 개발합니다. 개인적으로 인상적이었던 부분은, 이 모든 도구가 동일한 프로젝트 컨텍스트와 IAM 권한을 공유한다는 점입니다. 도구를 전환해도 별도 인증이나 설정 없이 같은 데이터에 접근할 수 있습니다.
# SageMaker Unified Studio 프로젝트 내 노트북 예시
# 같은 프로젝트의 카탈로그 데이터에 바로 접근
import boto3
session = boto3.session.Session()
# 프로젝트 내 공유 데이터 카탈로그에서 직접 테이블 참조
df = spark.sql("""
SELECT * FROM unified_catalog.sales_db.transactions
WHERE event_date >= '2025-01-01'
""")
Databricks: 노트북 중심의 협업 모델
Databricks는 노트북(Notebook)을 협업의 중심축으로 삼습니다. 실시간 공동 편집(Google Docs 스타일)과 내장 버전 관리를 지원하고, 노트북 내에서 Python·SQL·Scala·R을 셀 단위로 전환할 수 있습니다. 실제로 써보면, 데이터 탐색부터 시각화, 모델 프로토타이핑까지 노트북 하나에서 끝낼 수 있어 초기 실험 속도가 빠릅니다.
협업 모델 비교
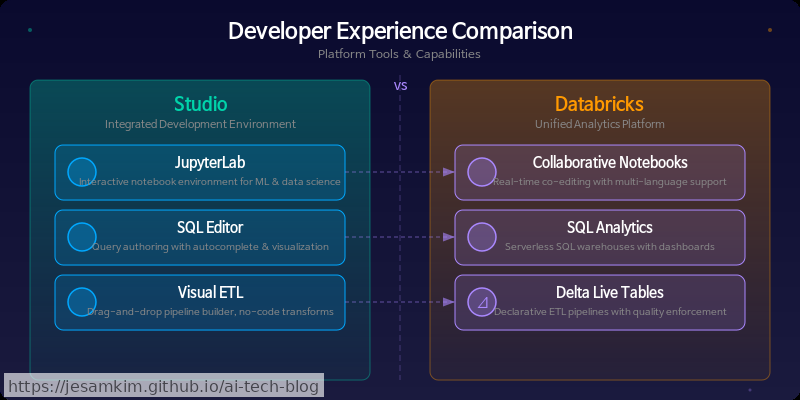
두 플랫폼의 접근 방식은 꽤 다릅니다. SageMaker Unified Studio는 역할(페르소나)별로 최적화된 도구를 하나의 프로젝트에 묶어주는 방식이고, Databricks는 노트북이라는 단일 인터페이스의 유연성을 높이는 방식입니다. 조직 내 역할 분담이 명확하고 비개발 직군까지 포함해야 한다면 SageMaker Unified Studio가 유리합니다. 반면 소규모 팀에서 빠른 반복 실험과 프로토타이핑에 집중한다면 Databricks의 노트북 중심 모델이 더 직관적일 수 있습니다.
References
AWS Blog, “Introducing Amazon SageMaker Unified Studio (Preview),” AWS Machine Learning Blog, 2024. https://docs.aws.amazon.com/sagemaker-unified-studio/latest/userguide/what-is-sagemaker-unified-studio.html
AWS Blog, “Introducing Amazon SageMaker Lakehouse: Unify all your data for AI and analytics,” AWS Big Data Blog, 2024. https://aws.amazon.com/blogs/aws/simplify-analytics-and-aiml-with-new-amazon-sagemaker-lakehouse/
AWS Blog, “Amazon Bedrock IDE in Amazon SageMaker Unified Studio,” AWS Machine Learning Blog, 2024. https://aws.amazon.com/bedrock/unifiedstudio/
Databricks 공식 문서, “What is the Databricks Data Intelligence Platform,” Databricks Documentation. https://docs.databricks.com/en/introduction/index.html
Databricks 공식 문서, “What is Unity Catalog?,” Databricks Documentation. https://docs.databricks.com/en/data-governance/unity-catalog/index.html
Databricks 공식 문서, “What is Databricks Mosaic AI?,” Databricks Documentation. https://docs.databricks.com/en/machine-learning/index.html
AWS 공식 문서, “What is Amazon SageMaker?,” Amazon SageMaker Developer Guide. https://docs.aws.amazon.com/sagemaker/latest/dg/whatis.html
AWS 공식 문서, “What is AWS Lake Formation?,” AWS Lake Formation Developer Guide. https://docs.aws.amazon.com/lake-formation/latest/dg/what-is-lake-formation.html
Databricks Blog, “Announcing the Databricks Data Intelligence Platform,” Databricks, 2024. https://www.databricks.com/company/newsroom/press-releases/databricks-announces-data-intelligence-platform-communications
AWS Blog, “Announcing Amazon SageMaker Unified Studio,” AWS re:Invent 2024. https://aws.amazon.com/about-aws/whats-new/2025/03/amazon-sagemaker-unified-studio-generally-available/
Zaharia, M., Ghodsi, A., Xin, R., & Gonzalez, J., “Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics,” Proceedings of CIDR, 2021. https://www.cidrdb.org/cidr2021/papers/cidr2021_paper17.pdf
Armbrust, M. et al., “Delta Lake: High-Performance ACID Table Storage over Cloud Object Stores,” Proceedings of the VLDB Endowment, Vol. 13, No. 12, 2020. https://www.vldb.org/pvldb/vol13/p3411-armbrust.pdf
Apache Iceberg 공식 문서, “Apache Iceberg – Table Format for Huge Analytic Datasets.” https://iceberg.apache.org/docs/latest/ 대규모 분석 데이터셋을 위한 오픈 테이블 포맷으로, SageMaker Unified Studio와 Databricks 모두 지원하는 핵심 데이터 레이크 기술이다.