월드 모델이란 무엇인가
최근 몇 년 사이 AI 커뮤니티의 관심사가 눈에 띄게 바뀌었습니다. 텍스트를 이해하는 AI를 넘어, 세상을 이해하는 AI로의 전환입니다.
월드 모델의 정의
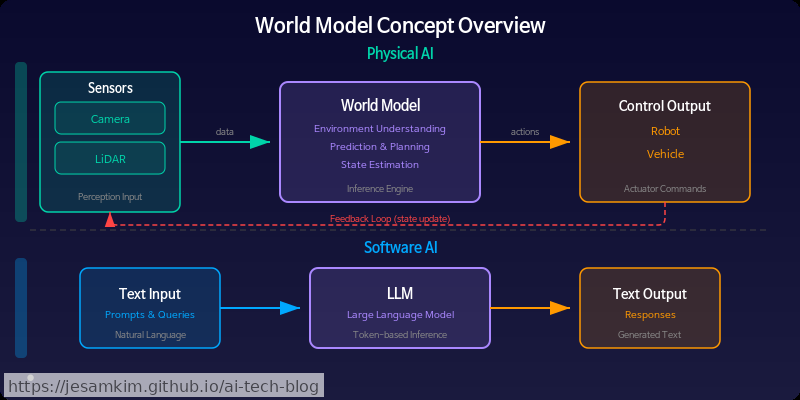
월드 모델(World Model)이란 환경의 내부 표상(Internal Representation)을 학습해서, 주어진 행동(action)에 대한 미래 상태(future state)를 예측하고 시뮬레이션하는 모델입니다. 핵심 아이디어는 단순합니다. AI가 머릿속에 “세상의 축소판"을 만들고, 그 안에서 미리 시뮬레이션한 뒤 행동을 결정하는 것입니다.
LLM과의 결정적 차이
LLM(Large Language Model)은 본질적으로 언어 세계의 모델입니다. 토큰 시퀀스의 통계적 패턴을 학습합니다. 반면 월드 모델은 물리 세계의 인과 관계(causality)와 역학(dynamics)을 모델링합니다.
| 구분 | LLM | 월드 모델(World Model) |
|---|---|---|
| 모델링 대상 | 언어의 통계적 구조 | 물리 세계의 인과·역학 |
| 입력 | 텍스트 토큰 | 상태 + 행동 (시각, 센서 등) |
| 출력 | 다음 토큰 예측 | 미래 상태 예측·시뮬레이션 |
| 핵심 능력 | 언어 이해·생성 | 결과 예측·계획 수립(Planning) |
간단한 개념 코드로 차이를 표현하면 이렇습니다:
# LLM: 다음 토큰을 예측
next_token = llm.predict(prompt="The cat sat on the")
# → "mat"
# World Model: 행동에 따른 미래 상태를 예측
next_state, reward = world_model.predict(
current_state=robot_camera_frame, # 현재 시각 관측
action=move_forward(0.5) # 0.5m 전진
)
# → 전진 후 예상되는 시각 장면 + 충돌 여부
왜 지금인가
월드 모델이 갑자기 주목받는 이유는 비교적 명확합니다. 자율주행(Autonomous Driving), 로보틱스(Robotics), 영상 생성(Video Generation) 등 실세계와 상호작용하는 AI 응용이 빠르게 늘고 있습니다. 단순 패턴 매칭만으로는 한계가 분명하고, 물리 법칙을 이해하는 AI가 필요해진 것입니다.
*“공을 던지면 포물선을 그리며 떨어진다”*를 데이터로만 외우는 게 아니라, 중력이라는 인과 구조를 내재화하는 것. 이것이 월드 모델이 추구하는 방향입니다.
Yann LeCun이 “AI의 다음 도약"이라 부르고, NVIDIA가 Cosmos라는 플랫폼을 공개한 것도 같은 맥락입니다. 개인적으로도 LLM의 한계를 체감하는 순간이 늘면서 월드 모델 쪽 논문을 더 자주 찾아보게 됐습니다. 이제 구체적인 이론과 구현을 하나씩 살펴보겠습니다.
Yann LeCun의 JEPA — 생성이 아닌 표현 학습으로 세상 이해하기
앞서 월드 모델을 “세상의 작동 원리를 내재화한 시뮬레이터"라고 정의했습니다. 그렇다면 AI는 이 시뮬레이터를 어떻게 구축해야 할까요? Yann LeCun이 제안한 JEPA(Joint Embedding Predictive Architecture)는 이 질문에 대한 근본적인 답 중 하나입니다.
핵심 아이디어: 픽셀이 아닌 의미 공간에서 예측하라
기존 생성 모델(GAN, Diffusion Model 등)은 미래 프레임의 모든 픽셀을 예측합니다. 바람에 흔들리는 나뭇잎 하나하나, 배경의 미세한 노이즈까지 전부 재현해야 하죠. LeCun은 이 방식이 근본적으로 비효율적이라고 봤습니다. 인간은 “공이 던져지면 포물선을 그리며 떨어진다"는 추상적 역학을 이해하지, 공 표면의 텍스처 변화를 프레임 단위로 시뮬레이션하지 않습니다.
JEPA는 이 직관을 그대로 구현합니다. 입력을 인코더(Encoder)로 추상 표현 공간(Latent Space)에 매핑한 뒤, 그 표현 공간 안에서 예측을 수행합니다.
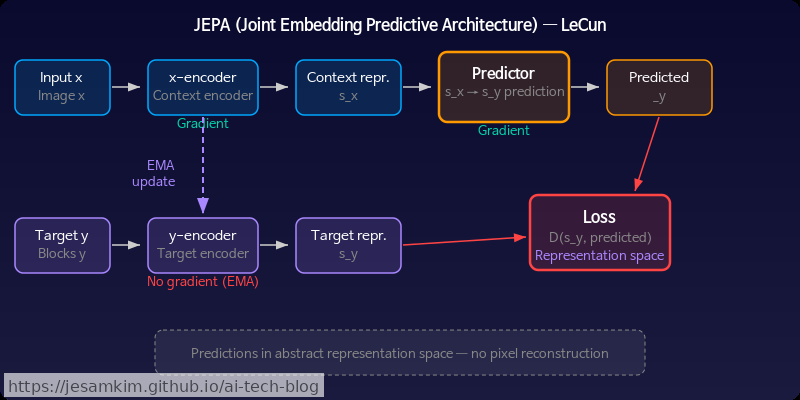 여기서 결정적인 차이는 디코더가 없다는 점입니다. 픽셀로 되돌릴 필요 없이, 표현 간의 일관성(consistency)만 학습합니다. 덕분에 모델은 “무엇이 의미적으로 중요한가"를 스스로 판별하게 됩니다.
여기서 결정적인 차이는 디코더가 없다는 점입니다. 픽셀로 되돌릴 필요 없이, 표현 간의 일관성(consistency)만 학습합니다. 덕분에 모델은 “무엇이 의미적으로 중요한가"를 스스로 판별하게 됩니다.
생성 모델과의 결정적 차이
| 구분 | 생성 모델 (GAN, Diffusion) | JEPA |
|---|---|---|
| 예측 공간 | 픽셀/토큰 공간 (고차원) | 추상 표현 공간 (저차원) |
| 목표 | 입력을 완벽히 재구성 | 의미적 관계를 포착 |
| 불확실성 처리 | 모든 가능한 디테일을 생성 | 불필요한 디테일을 자연스럽게 무시 |
| 붕괴(Collapse) 방지 | Adversarial loss, noise 주입 | 비대칭 구조 + EMA + VICReg 등 |
구체적 구현: I-JEPA와 V-JEPA
I-JEPA(Image JEPA)는 이미지의 일부 패치를 마스킹하고, 나머지 패치의 표현으로부터 마스킹된 영역의 표현을 예측합니다. MAE(Masked Autoencoder)가 픽셀 복원을 목표로 하는 것과 대조적입니다.
V-JEPA(Video JEPA)는 이를 시간 축으로 확장한 것입니다. 영상에서 시공간 블록을 마스킹하고, 보이는 프레임의 표현만으로 가려진 구간의 표현을 예측합니다. 이 과정에서 모델은 물체의 움직임, 인과 관계, 물리적 상호작용 같은 시간적 추상화(temporal abstraction)를 학습하게 됩니다. 개인적으로 이 부분이 JEPA의 가장 흥미로운 지점이라고 생각하는데, 명시적으로 물리 법칙을 가르치지 않아도 표현 공간의 예측 압력만으로 그런 구조가 떠오른다는 점이 인상적입니다.
# V-JEPA 학습 루프의 핵심 구조 (개념적 pseudo-code)
import torch
import torch.nn.functional as F
# 구성 요소
x_encoder = VisionTransformer() # context encoder (학습 대상)
y_encoder = VisionTransformer() # target encoder (EMA 업데이트)
predictor = LatentPredictor() # 표현 공간 예측기
for video_batch in dataloader:
# 1) 시공간 마스킹 전략
context_blocks, target_blocks = stochastic_masking(video_batch)
# 2) Context 인코딩 (학습 대상)
context_repr = x_encoder(context_blocks)
# 3) Target 인코딩 (EMA, gradient 차단)
with torch.no_grad():
target_repr = y_encoder(target_blocks)
# 4) 표현 공간에서 예측
predicted_repr = predictor(context_repr)
# 5) 손실 계산 — 픽셀이 아닌 표현 간 거리
loss = F.smooth_l1_loss(predicted_repr, target_repr)
# 6) x_encoder + predictor 업데이트
loss.backward()
optimizer.step()
# 7) y_encoder는 EMA로만 업데이트 (붕괴 방지)
ema_update(y_encoder, x_encoder, momentum=0.996)
비디오 생성 모델은 월드 시뮬레이터인가 — Sora, Genie, UniSim의 등장
2024년 2월, OpenAI가 Sora를 공개하며 기술 보고서에 적은 한 문장이 업계를 뜨겁게 달궜습니다: “Video generation models as world simulators.” 텍스트로부터 물리적으로 그럴듯한 영상을 생성할 수 있다면, 이 모델이 세상의 물리 법칙을 이해한 것일까요? 이 질문이 논쟁의 핵심입니다.
주요 연구 흐름
Sora만이 아닙니다. Google DeepMind의 Genie는 단일 이미지로부터 인터랙티브하게 조작 가능한 2D 환경을 생성합니다. 액션 레이블 없이도 잠재 액션 공간(Latent Action Space)을 스스로 학습한다는 점이 흥미롭습니다. UniSim은 여기서 한 걸음 더 나아갑니다. 텍스트, 액션, 카메라 움직임 등 다양한 입력을 받아 시뮬레이션 결과를 생성하는 범용 시뮬레이터(Universal Simulator)를 목표로 합니다.

진정한 월드 모델과의 간극
비판은 명확합니다. 이 모델들은 픽셀 수준의 통계적 패턴을 학습할 뿐, 내부에 물리 법칙의 명시적 표현(Explicit Representation)을 갖고 있지 않습니다.
| 기준 | 비디오 생성 모델 | 진정한 월드 모델 |
|---|---|---|
| 물리 일관성(Physical Consistency) | ❌ 프레임 간 객체 질량·관성 불일치 | ✅ 일관된 물리 시뮬레이션 |
| 장기 예측(Long-horizon Prediction) | ❌ 시간이 길어질수록 붕괴 | ✅ 안정적 롤아웃 |
| 인과 추론(Causal Reasoning) | ❌ 상관관계 기반 생성 | ✅ 인과 구조 모델링 |
| 환각(Hallucination) | ⚠️ 그럴듯하지만 물리적으로 불가능한 장면 빈번 | ✅ 제약 조건 내 예측 |
실제로 Sora가 생성한 영상을 보면, 의자가 공중에 떠 있거나 물이 거꾸로 흐르는 장면이 종종 발견됩니다. LeCun이 반복적으로 지적하듯, 픽셀을 예측하는 것과 세상을 이해하는 것은 다릅니다. 비디오 생성 모델은 월드 모델을 향한 인상적인 출발점이긴 합니다. 하지만 그 자체를 월드 시뮬레이터라고 부르기엔 아직 거리가 멉니다. 이 간극을 메우려는 시도 중 하나가 NVIDIA의 Cosmos입니다.
NVIDIA Cosmos — 산업용 월드 모델 플랫폼의 탄생
앞서 살펴본 Sora와 Genie가 “영상을 생성하는 모델이 세상을 이해하는가?“라는 질문을 던졌다면, NVIDIA Cosmos는 이 질문에 대한 산업계의 실용적 답변에 해당합니다. 2025년 초 공개된 Cosmos는 스스로 월드 파운데이션 모델(World Foundation Model, WFM) 플랫폼이라 정의합니다. 단일 모델이 아니라, 물리 법칙을 이해하는 AI를 구축하기 위한 파이프라인 전체를 제공하겠다는 선언입니다.
아키텍처 구성
Cosmos는 크게 세 계층으로 구성됩니다.
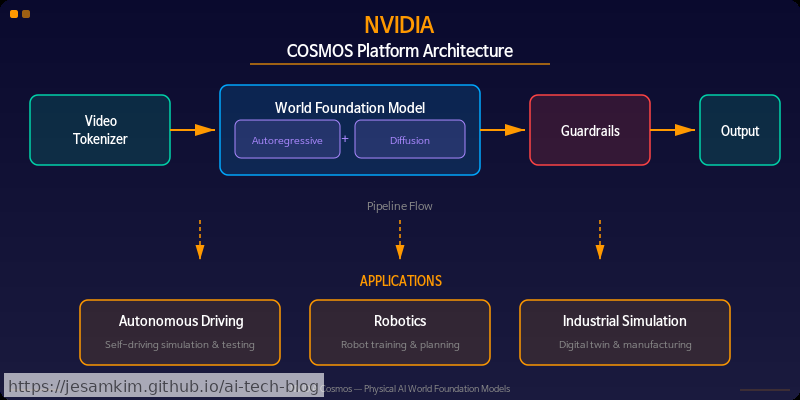 Cosmos Tokenizer는 비디오를 시공간(spatial-temporal) 토큰으로 압축합니다. 연속(continuous) 토큰과 이산(discrete) 토큰을 모두 지원하기 때문에, 후속 모델이 Diffusion이든 Autoregressive든 유연하게 연결할 수 있습니다. NVIDIA에 따르면 기존 대비 8배 이상의 압축률을 달성하면서도 재구성 품질을 유지한다고 합니다.
Cosmos Tokenizer는 비디오를 시공간(spatial-temporal) 토큰으로 압축합니다. 연속(continuous) 토큰과 이산(discrete) 토큰을 모두 지원하기 때문에, 후속 모델이 Diffusion이든 Autoregressive든 유연하게 연결할 수 있습니다. NVIDIA에 따르면 기존 대비 8배 이상의 압축률을 달성하면서도 재구성 품질을 유지한다고 합니다.
월드 생성 모델은 두 가지 패러다임을 병렬로 제공합니다.
- Cosmos-Diffusion: 연속 토큰 위에서 노이즈 제거 과정을 거쳐 미래 프레임을 생성합니다. 물리적으로 그럴듯한(physically plausible) 장면을 만들어내는 데 강점이 있습니다.
- Cosmos-Autoregressive: 이산 토큰을 순차적으로 예측하는 GPT 스타일 접근입니다. 긴 시퀀스에서 일관성을 유지하는 데 유리합니다.
Cosmos Guardrail은 생성된 시뮬레이션이 안전 기준을 충족하는지 사전·사후로 필터링합니다. 산업 환경에서 실제 배포를 염두에 둔 설계입니다.
자율주행·로보틱스 시뮬레이션에의 적용
Cosmos의 진짜 가치는 합성 데이터(synthetic data) 생성에 있습니다. 자율주행 차량(AV)이 실제 도로에서 마주칠 수 있는 엣지 케이스, 예를 들어 갑작스러운 보행자 출현이나 악천후 상황 같은 시나리오를 물리적으로 타당한 시뮬레이션으로 거의 무한히 만들어낼 수 있습니다. 실제로 이런 희귀 상황은 실도로 데이터만으로 수집하기가 거의 불가능하기 때문에, 합성 데이터의 가치가 큽니다.
# Cosmos 활용 개념 예시 (pseudo-code)
from cosmos_sdk import CosmosWorldModel, TokenizerConfig
# 1. 토크나이저 설정 — 자율주행 시나리오용
tokenizer = TokenizerConfig(mode="continuous", spatial_downsample=8, temporal_downsample=4)
# 2. Diffusion 기반 월드 모델 로드
world_model = CosmosWorldModel.from_pretrained(
"nvidia/cosmos-diffusion-7b",
tokenizer_config=tokenizer
)
# 3. 초기 주행 장면 + 텍스트 조건으로 미래 시뮬레이션
simulation = world_model.generate(
initial_frames=driving_scene[:16], # 초기 16프레임
prompt="heavy rain, pedestrian crossing", # 조건부 생성
num_future_frames=48, # 미래 48프레임 예측
guidance_scale=7.5
)
# 4. 가드레일 검증
validated = world_model.guardrail.check(simulation) # 안전성 필터링
JEPA가 표현 학습의 관점에서, Sora가 생성 모델의 관점에서 월드 모델을 탐색했다면, Cosmos는 이를 산업용 인프라로 끌어올린 셈입니다. 토크나이저, 생성 모델, 가드레일을 하나의 파이프라인으로 묶어 자율주행과 로보틱스 기업이 바로 가져다 쓸 수 있는 플랫폼을 만들었다는 점에서, Physical AI 시대의 본격적인 인프라 경쟁이 시작되었다고 볼 수 있습니다.
References
LeCun, Y. (2022). “A Path Towards Autonomous Machine Intelligence.” Meta AI Technical Report. https://openreview.net/pdf?id=BZ5a1r-kVsf
Ha, D. & Schmidhuber, J. (2018). “World Models.” arXiv preprint arXiv:1803.10122. https://arxiv.org/abs/1803.10122
NVIDIA. (2025). “Cosmos: A World Foundation Model Platform for Physical AI.” NVIDIA Research. https://arxiv.org/abs/2501.03575
Assran, M. et al. (2023). “Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture (I-JEPA).” Meta AI, CVPR 2023. https://arxiv.org/abs/2301.08243
Bardes, A. et al. (2024). “V-JEPA: Video Joint Embedding Predictive Architecture.” Meta AI Technical Report. https://arxiv.org/abs/2404.16930
Yang, M. et al. (2024). “Learning Interactive Real-World Simulators (UniSim).” Google DeepMind, ICLR 2024. https://arxiv.org/abs/2310.06114
Hu, A. et al. (2023). “GAIA-1: A Generative World Model for Autonomous Driving.” Wayve Technologies. https://arxiv.org/abs/2309.17080
Bruce, J. et al. (2024). “Genie: Generative Interactive Environments.” Google DeepMind. https://arxiv.org/abs/2402.15391